 夜雨聆风
夜雨聆风





个人 AI 开发配置(2605-1):你跑不动 70B 模型,不是因为算力不够,是因为内存放不下
很多人拿到 AI 硬件的第一反应是看 TFLOPS——RTX 5070 的 FP16 算力 30.9 TFLOPS,M4 Pro 的 GPU 算力 Apple 从未官方公布,第三方基于实测反推的估算大约在 10-14 TFLOPS 左右,前者有明显优势。然后他们买了台式机,装好驱动,发现 Qwen3.6-27B 这样的主流模型跑不起来,速度慢得像爬——不是驱动问题,是 12GB 显存根本放不下一个 27B 的量化模型。个人 AI 开发的核心瓶颈从来不是算力,是内存装得下多大的模型。搞清楚这件事,选硬件就不会踩坑。
个人跑模型,和机构的问题完全不同
机构运营一个推理平台,关心的是吞吐量——每秒能服务多少个并发请求,每百万 token 成本多少钱。硬件利用率 70% 还是 85%,决定了几百万的成本差距。
个人开发者关心的是两个更简单的问题:这个模型我能不能跑起来,以及速度够不够用。
后者其实门槛很低。写代码的时候,20 tokens/s 已经是流畅的流式输出——你的眼睛跟不上。如果你是在做批量文档处理,5 tokens/s 也够用,等得住。真正的死亡线是:模型根本装不进内存,被迫用 CPU 搬运,速度掉到 1-2 tokens/s,那才叫不可用。
所以个人 AI 选硬件,第一个问题不是”多少算力”,而是”装得下多大的模型”。
模型大小 = 内存需求,有一张速查表
语言模型加载到内存里,参数就是主要的空间占用。用最常见的 Q4_K_M 量化精度(大约每参数 4.5 bit),各个主流模型尺寸的内存需求大约是:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
注意:KV Cache(推理中间状态)也要占内存,实际运行时还需要额外预留 1-4 GB,具体取决于上下文长度。超长上下文(32K+)的 KV Cache 会占用更多,这也是为什么 48GB 比 24GB 在实际使用中更有余量——KV Cache 的增长往往超出预期。
如果内存有压力,可以降到 Q3 量化(如 Unsloth UD-Q3 动态量化):内存需求减少约 25%,27B 约 13-14 GB,70B 约 30-33 GB。Unsloth 的动态量化对重要层保留更高精度,精度损失比标准 Q3 更小,是 24GB 设备跑 27B 的实用选项。
这张表说明了一个很残酷的事实:想流畅运行 70B 模型,你需要至少 45-50 GB 可用内存。这也是为什么 12GB 显存的显卡注定被排除在 70B 推理之外——不是差一点点,是差了将近四倍。
两种内存,差别在哪
买显卡,看到的是 VRAM(显存);买 Mac,看到的是统一内存(Unified Memory)。两者都是内存,但有本质区别:
VRAM(独立显卡显存)
-
GPU 专属,带宽极高——RTX 5070 的 GDDR7 带宽 672 GB/s,5070 Ti 达 896 GB/s -
容量硬封顶,买了就定死——笔记本 RTX 5070 Ti / 5080 均为 16GB;台式机 RTX 4090 24GB,RTX 5090 32GB -
GPU 需要的数据如果不在 VRAM 里,就要从系统内存搬过来,走 PCIe 总线,最快约 64 GB/s(实测通常 30-50 GB/s)
统一内存(Apple Silicon)
-
CPU 和 GPU 共享同一块物理内存,没有搬运开销——GPU 直接访问 -
带宽比 VRAM 低——M4 Pro 273 GB/s,M4 Max 546 GB/s -
容量大,Mac mini M4 Pro 最高 64GB,M4 Max 可到 128GB -
不可升级,买的时候选定就定死了
CPU Offload:速度的悬崖
当模型超出 VRAM 容量,llama.cpp、ollama 这类工具会自动把超出部分「卸载」到系统内存(DDR5),GPU 每次需要时再去取。这叫 CPU offload,听起来是个合理的折中方案,但实际效果是速度悬崖。
原因:数据走 PCIe 总线,带宽约 30-50 GB/s,比 VRAM 带宽慢了 10-20 倍。
实际影响(以 RTX 5080 笔记本 16GB + 系统 DDR5 为例):
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
27B 这一档即便是 16GB 笔记本也已经从”流畅”掉到”勉强能用”,70B 则是真正的不可用——你能在屏幕上看着光标一个字一个字地出现,体验约等于按照秒来数。台式机配 RTX 4090(24GB)则可以把 27B 完整装入显存,彻底消灭这道悬崖;RTX 5090(32GB)更进一步,连 34B 都能全速运行。
Offload 是应急方案,不是正式解决方案。如果你的主要需求需要跑 27B 以上的模型,从一开始就应该选内存够大的设备,而不是事后再靠 offload 弥补。
各硬件平台的模型能力边界
综合上面的数字,五个主流配置的能力边界一目了然:
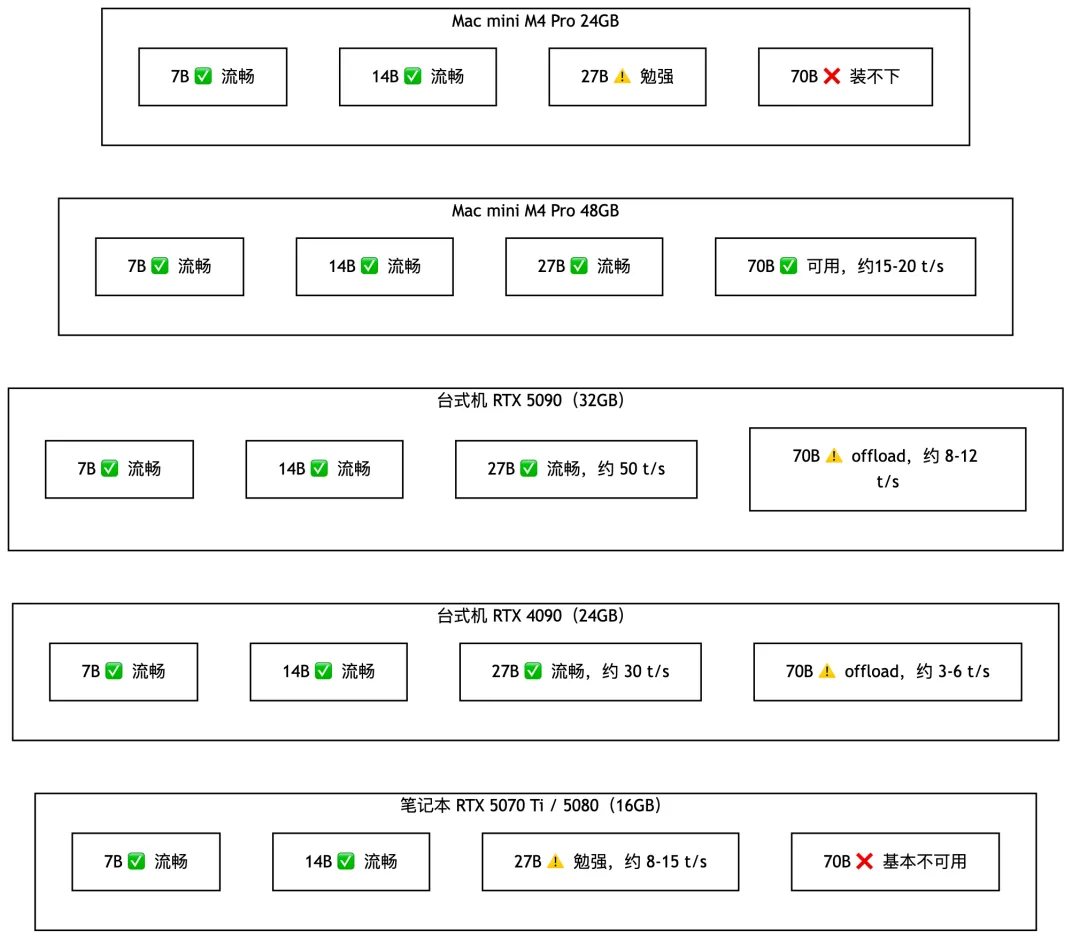
几个容易误判的点:
M4 Pro 速度比笔记本 RTX 5080 慢,但「能跑」比「跑得快」更重要。对于个人用途,27B 模型 15 tokens/s 完全够用,但 8 tokens/s 已经有明显等待感。台式机配 RTX 4090 则把 27B 的速度推到 30 t/s,差距又拉开了一档。
「显存大小 > 算力高低」是个人AI硬件选型的第一原则。在模型装得进的前提下,再比较速度差异才有意义。
16GB 笔记本(5070 Ti / 5080)和台式机 RTX 4090(24GB)之间的差距,不只是速度。16GB 跑 27B 是勉强应付,24GB 跑 27B 是完全不费力——这是体验质量上的差距,不只是数字上的差距。
一句话结论
选个人 AI 硬件的顺序是:先确认能装下目标模型(内存容量),再看带宽决定跑多快,算力是最后考虑的。
-
主要跑 14B 以内,需要 CUDA,便携优先:笔记本 RTX 5070 Ti / 5080(16GB),速度快 -
主要跑 Qwen3.6-27B,台式机 CUDA 路线:RTX 4090(24GB,二手约 8000-12000 元)全流畅约 30 t/s,性价比首选;RTX 5090(32GB)新品约 16000 元,余量更大 -
主要跑 27B-70B,优先 macOS 生态:Mac mini M4 Pro 48GB,是当前个人最具性价比的大模型推理机 -
需要跑 128K+ 长上下文的 70B:Mac mini M4 Max 128GB,或者直接租云
下一篇聚焦 Mac mini——它的统一内存不只是容量大,还有一些你未必知道的工程限制。
数据来源:Wikipedia GeForce RTX 50 series(2026年4月)、Apple M4 规格表(Wikipedia 2026年4月);推理速度数据来自 llama.cpp/ollama 社区实测,因配置和量化方式不同会有波动。