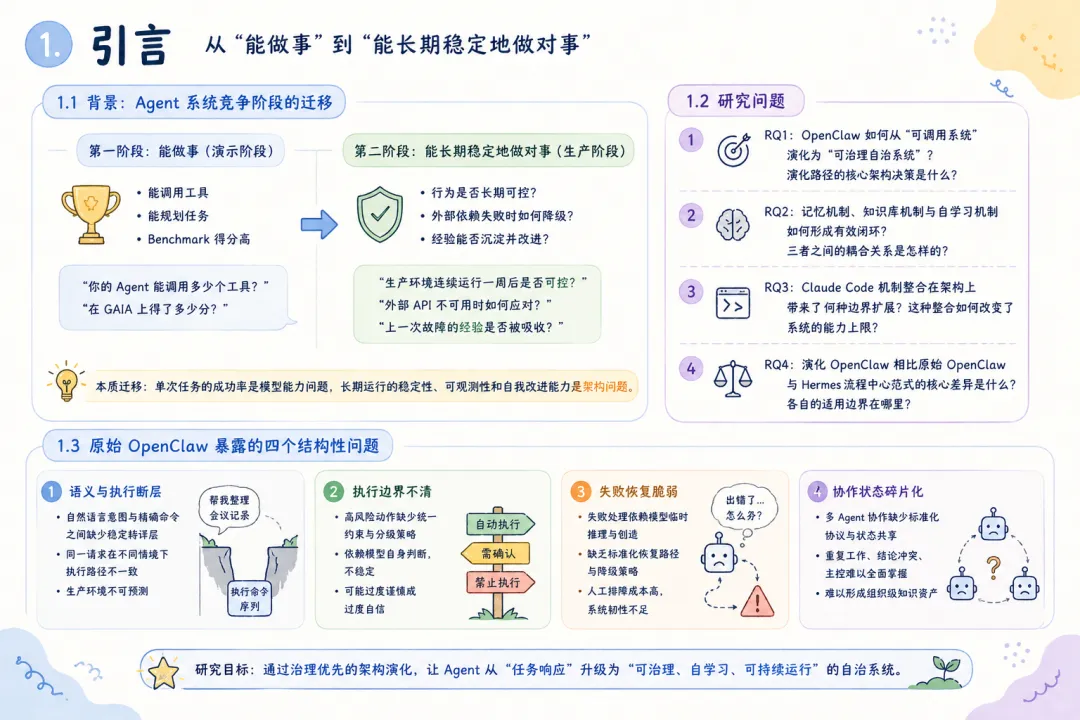
从可调用到可治理自治:OpenClaw 自我演化架构研究
文章同步在GitHub:https://github.com/Billjobszwq/openclaw-.git
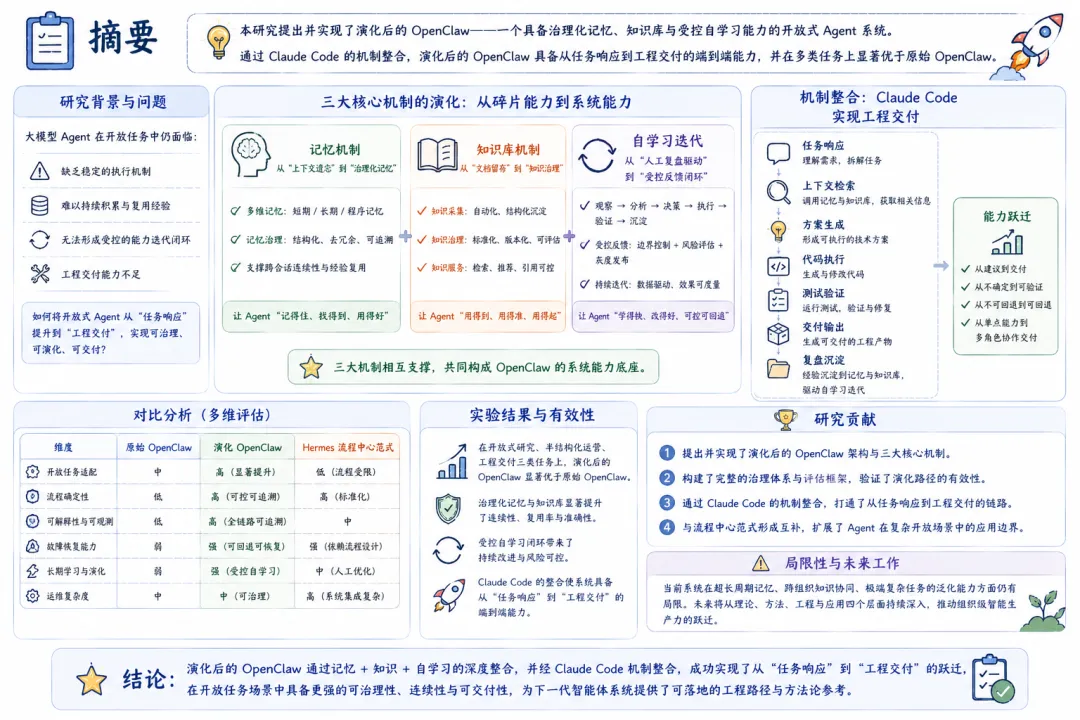
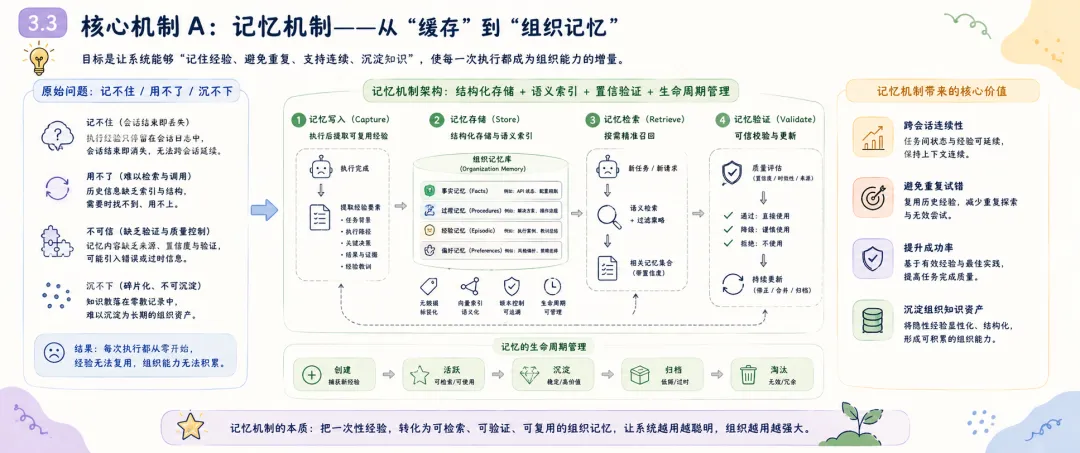
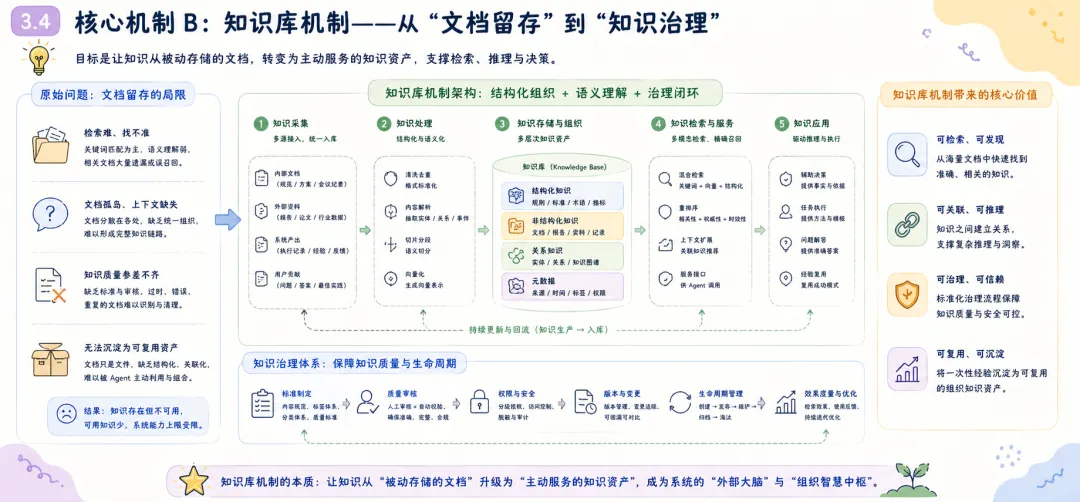
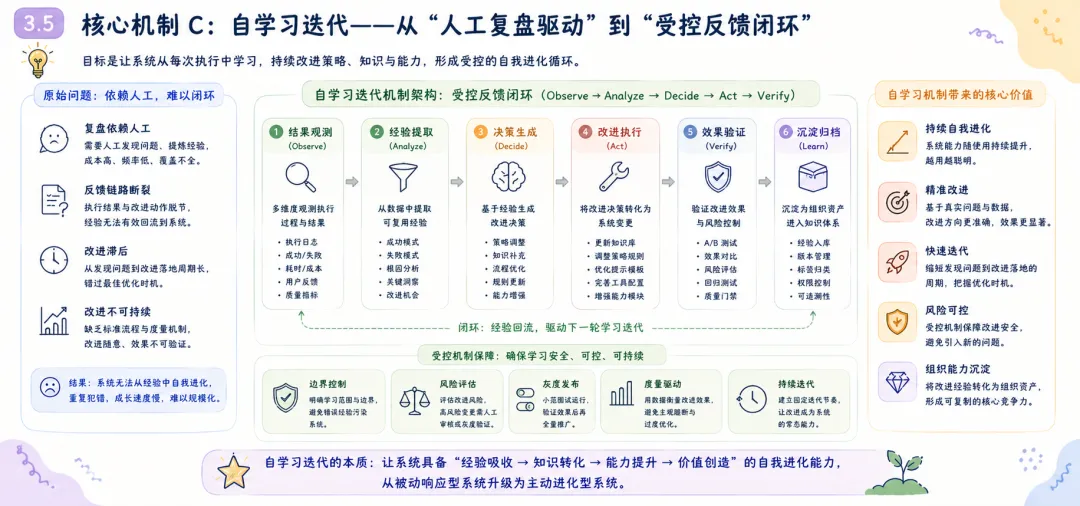
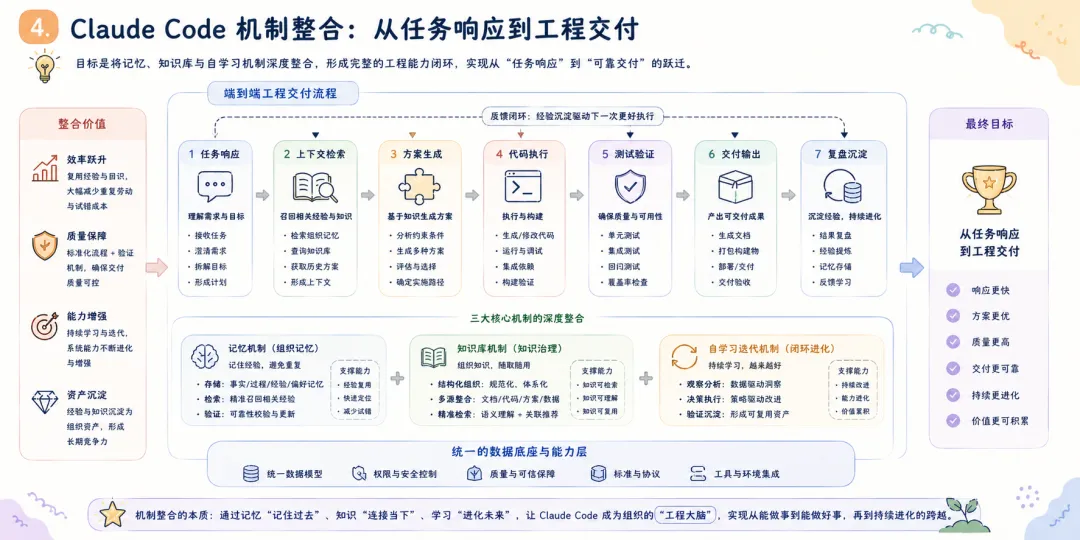
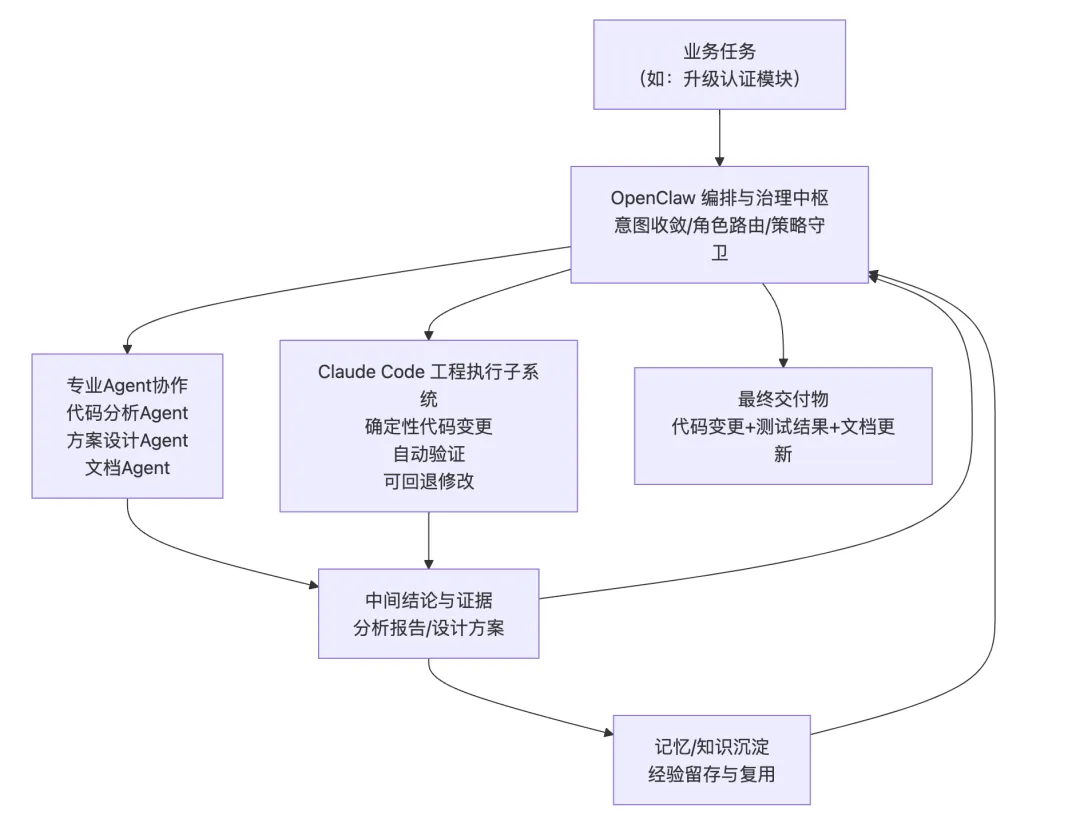
摘要 多智能体系统从演示场景走向真实业务环境后,瓶颈会从”模型能力不足”转向”系统治理不足”。模型能力的持续提升——更大参数量、更长上下文窗口、更强的推理能力——确实让 Agent 能够完成越来越复杂的单次任务,但这并未解决一个根本性问题:当系统被部署到持续运行的生产环境中,面对动态变化的需求、不确定的外部依赖和累积的执行经验时,它能否稳定地、可预期地、自我改进地长期运行? 本文以 OpenClaw 为研究对象,系统分析其从原始版本到演化版本的架构迁移路径,重点聚焦三类核心机制:记忆机制、知识库机制与自我学习迭代机制。本文提出一种”治理优先”的演化框架,其核心主张是:在多智能体系统的架构设计中,治理能力(governance)应先于功能扩展(feature expansion)——在自然语言意图与执行动作之间引入语义转译层,在执行前引入策略守卫层,在执行后通过记忆与知识沉淀形成反馈闭环。同时,本文讨论 Claude Code 机制整合后,系统如何从”任务响应”升级为”工程可交付”,将 Agent 的能力边界从对话层面的建议延伸到文件系统层面的可验证产出。 对比分析沿两条主线展开:其一为”原始 OpenClaw 与演化 OpenClaw”的纵向对比,揭示架构演化的结构性收益;其二为”演化 OpenClaw 与 Hermes 流程中心范式”的横向对比,分析意图驱动与流程驱动两条技术路线的差异化适用场景。研究结果表明,演化 OpenClaw 在开放任务适配、跨会话连续性与组织学习能力上具有显著优势,但这些优势伴随策略复杂度上升与可解释性压力增加——每一处治理能力的增强,都意味着系统行为从”直觉可理解”走向”需借助日志与策略文档才能理解”。 本文的结论是:下一代 Agent 平台的核心竞争力,正从”可调用能力数量”转向”执行可治理性、运行可观测性与系统可演化性”。这不是一个技术乐观主义的宣言,而是一个工程现实主义的判断——当 Agent 从演示走向生产,治理不是可选的附加项,而是系统能否长期存续的前提条件。 关键词 :多智能体系统;OpenClaw;Hermes;Claude Code;执行治理;记忆机制;知识库;自学习1. 引言 1.1 背景:Agent 系统竞争阶段的迁移 过去两年,基于大语言模型(LLM)的 Agent 系统经历了爆发式增长。第一批 Agent 产品的核心竞争点在”能不能做事”——能否调用工具、能否规划任务、能否在 benchmark 上跑出高分。这个阶段的标志性问题是:”你的 Agent 能调用多少个工具?””你的 Agent 在 GAIA 上得了多少分?” 然而,当 Agent 从 demo 走向 production,从单次调用走向持续部署,竞争的焦点正在发生静默但根本性的迁移。第二阶段的标志性问题正在变成:”你的 Agent 在生产环境连续运行一周后,行为是否仍然可控?””当外部 API 不可用时,系统是优雅降级还是静默失败?””上一次故障的经验是否被系统吸收并改进了下一次执行?” 这个迁移的本质在于:单次任务的成功率可以通过模型能力的提升来改善,但长期运行的稳定性、可观测性和自我改进能力,是一个架构问题,而非模型问题。 1.2 问题陈述:从”能做事”到”能长期稳定地做对事” OpenClaw 原始版本已具备多 Agent 协作与技能调用能力,代表了第一代 Agent 系统的典型能力水平。然而在实际运行中,系统暴露出四个典型的结构性问题: 第一,用户意图与执行命令之间存在语义断层。 用户以自然语言表达任务意图(”帮我整理一下上周的会议记录”),但系统执行需要精确的命令序列(定位文件、解析格式、提取关键信息、生成摘要、保存到指定位置)。原始版本中,这一转换过程高度依赖模型在单次推理中”猜对”用户的真实意图和执行路径,缺少一个稳定的中间层来规范化这种转换。结果是:同一个用户请求在不同时间、不同上下文下可能产生不同的执行路径,甚至不同的执行结果。对于演示场景,这种不确定性可以容忍;对于生产场景,这种不确定性意味着不可预测的风险。第二,高风险动作缺少统一约束,执行边界不清。 原始 OpenClaw 可以执行文件操作、网络请求和系统命令,但哪些动作需要人工确认、哪些动作可以自动执行、哪些动作必须被禁止——这些边界没有在架构层面被系统化地定义和强制执行。系统依赖模型自身的”判断”来决定是否执行一个高风险操作,但模型的判断是不稳定的——它可能在某次执行中谨慎地请求确认,在另一次执行中直接执行了相同的操作。这种不一致性在生产环境中是不可接受的。第三,失败恢复依赖人工排障,系统韧性不足。 当执行链路中的某个环节失败时(例如外部 API 返回错误、文件格式不符合预期),原始系统缺乏标准化的恢复路径。它可能重试若干次后放弃,或者在错误信息不充分的情况下输出一个不完整的结果。恢复过程高度依赖人工介入——用户需要阅读执行日志、定位失败原因、手动修正后重新触发。这不仅增加了运维成本,更限制了系统在无人值守场景下的可用性。第四,协作结果难以沉淀为长期可复用组织资产。 每一次任务执行都会产生有价值的信息——哪些路径有效、哪些模式需要避免、哪些知识可以跨任务复用。但在原始架构中,这些信息散落在会话日志中,随着会话结束而”蒸发”。下一次执行类似任务时,系统从零开始推理,重复之前的试错过程。从组织视角看,每一次执行的经验没有被转化为组织的知识资产。1.3 研究问题 RQ1:OpenClaw 如何从”可调用系统”演化为”可治理自治系统”?演化路径的核心架构决策是什么? RQ2:记忆机制、知识库机制与自学习机制如何形成有效闭环?三者之间的耦合关系是怎样的? RQ3:Claude Code 机制整合在架构上带来了何种边界扩展?这种整合如何改变了系统的能力上限? RQ4:演化 OpenClaw 相比原始 OpenClaw 与 Hermes 流程中心范式的核心差异是什么?各自的适用边界在哪里? 1.4 论文结构 本文按”问题-方法-对比-结论”框架组织。第 2 节从形式化描述和工程实践两个层面定义问题;第 3 节详细阐述治理优先的三项核心机制;第 4 节分析 Claude Code 整合带来的边界扩展;第 5 节从纵向和横向两个维度进行对比分析;第 6 节以改造矩阵形式汇总每项设计的出发点、目的和效果;第 7 节提出评估框架和指标体系;第 8 节讨论研究的局限性和有效性威胁;第 9 节从更宏观的视角讨论对 Agent 发展的启示;第 10 节给出结论。 2. 问题定义 2.1 形式化描述 为了精确描述问题的本质,我们首先将 Agent 系统的执行过程形式化。 定义 1(弱治理执行链路) :给定用户请求 u 和系统状态 s₀,弱治理 Agent 系统的执行链路为:
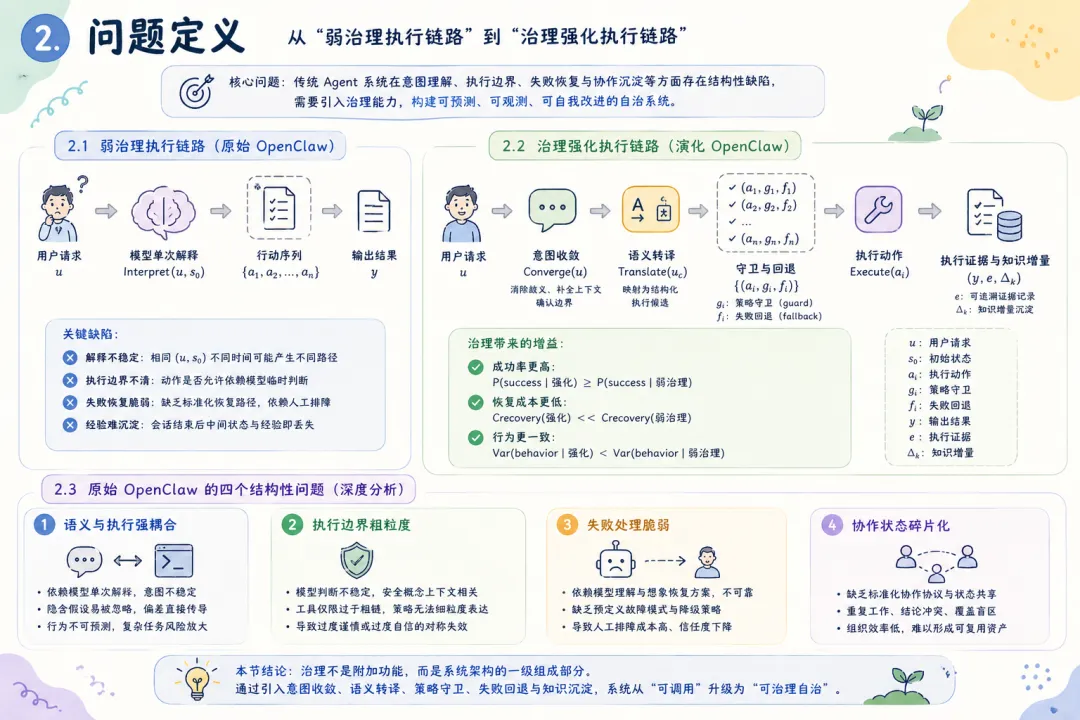
u → Interpret(u, s₀) → {a₁, a₂, …, aₙ} → y
其中 Interpret 为模型对意图的单次解释,{aᵢ} 为生成的行动序列,y 为输出结果。该链路的关键缺陷在于:Interpret 是不稳定的函数——相同 (u, s₀) 在不同时刻可能产生不同的解释结果;每个 aᵢ 的执行边界没有被显式约束;执行过程中的中间状态 sₜ 在执行结束后即丢失。 定义 2(治理强化执行链路) :演化后的执行链路引入三层治理插入:
u → Converge(u) → Translate(u_c) → {(aᵢ, gᵢ, fᵢ)} → Execute(aᵢ) → (y, e, Δₖ)
Converge:意图收敛——消除歧义、补全上下文、确认边界; Translate:语义转译——将收敛的意图映射为结构化的执行候选; gᵢ:每个动作 aᵢ 的策略守卫(guard)——在动作执行前进行边界检查; fᵢ:每个动作 aᵢ 的失败回退路径(fallback)——当 aᵢ 失败时的预设降级方案; e:执行证据——可追溯的执行记录,而非仅输出结果; 命题 1(治理增益) :在相同模型能力条件下,治理强化链路相比弱治理链路,在以下维度上具有严格或概率性优势:
P(success | u, 强化) >= P(success | u, 弱治理)
C_recovery(强化) << C_recovery(弱治理)
Var(behavior | 强化) < Var(behavior | 弱治理)
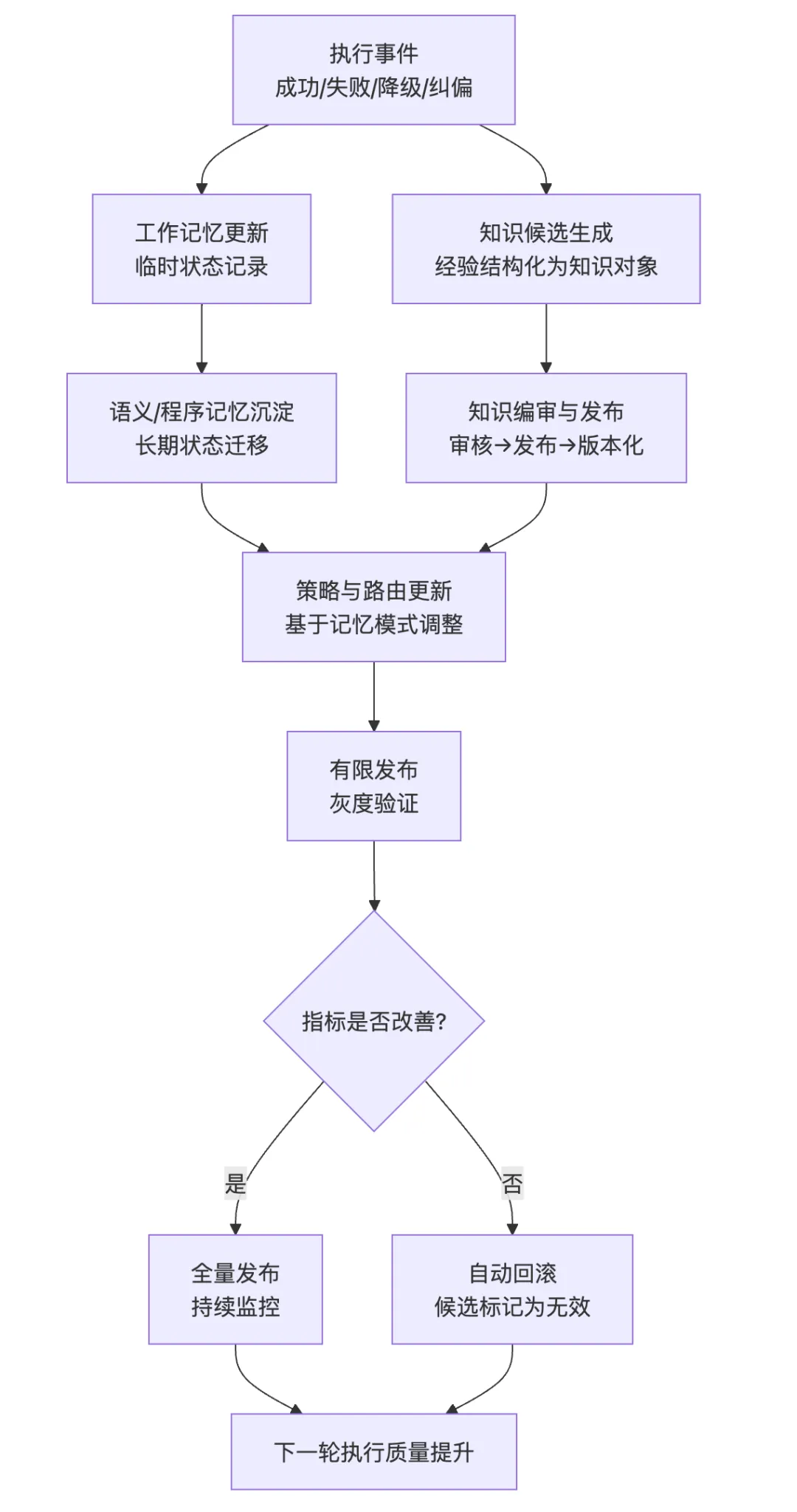
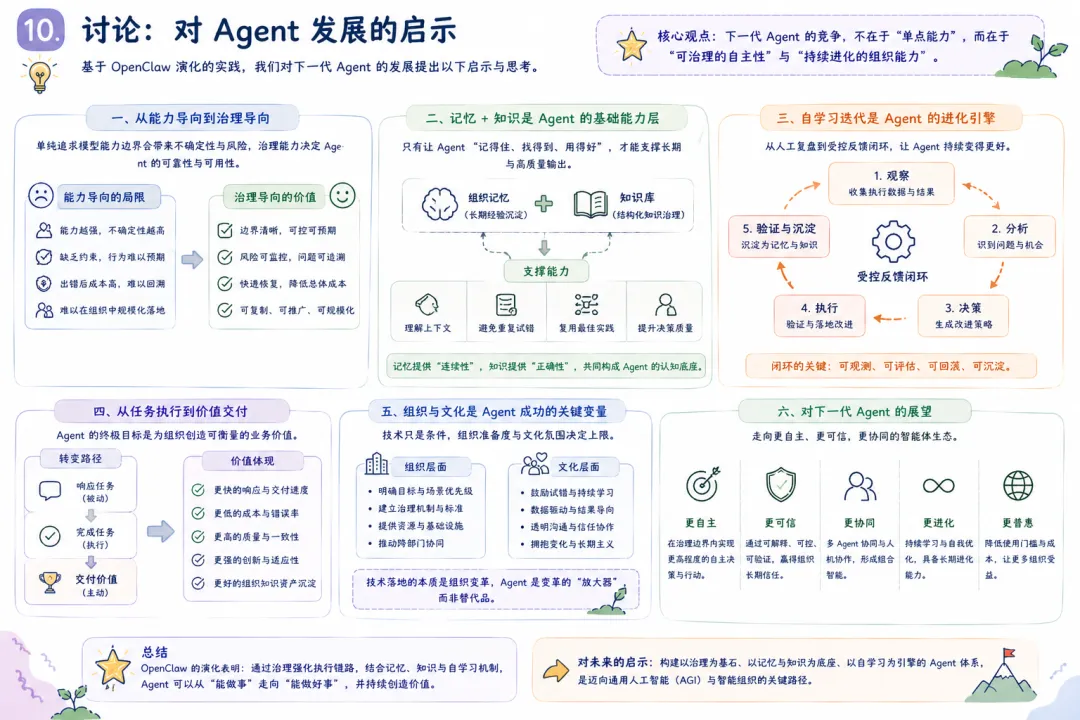
其中 C_recovery 为失败后的恢复成本,Var 为行为一致性方差。 这个形式化框架的核心洞察是:治理不是附加在”模型执行”之上的额外负担,而是系统架构的一级组成部分。在一个治理良好的系统中,模型只需要在其擅长的领域(推理、生成、理解)发挥作用,而执行边界、失败处理和知识沉淀则由治理层承担。 2.2 原始 OpenClaw 的结构缺陷:深度分析 上一节的四个问题陈述需要进一步展开,以揭示其深层原因和连锁效应。 2.2.1 语义与执行强耦合 现象描述 :用户以业务语言表达需求,系统以技术语言执行操作。在弱治理架构中,这种”语言鸿沟”的弥合完全依赖模型在推理时刻的临时解释。这意味着:同一用户请求在不同上下文下可能被解释为不同的执行意图; 用户的隐含假设(如文件位置、命名约定、安全偏好)可能被模型忽略; 当模型对领域术语的理解出现偏差时,偏差会直接传导到执行层,没有中间检查点。 深层原因 :这不是模型”不够聪明”的问题,而是架构缺少”意图稳定层”的问题。人类组织中,一个业务需求在被工程师实现之前,会经过需求分析、技术方案评审等中间环节——这些环节的作用不是”提高智力水平”,而是”降低解释方差”。Agent 系统中缺少这层结构。连锁效应 :语义与执行的强耦合导致系统的行为不可预测。两个语义相近的请求可能走上完全不同的执行路径,而用户无法预知系统将如何解释其意图。这种不确定性在简单任务中不易察觉,但在涉及多步骤、多工具、多 Agent 协作的复杂任务中会被急剧放大。2.2.2 执行边界粗粒度 现象描述 :原始系统中,动作的”是否允许执行”主要依赖两个机制:模型自身的判断和工具层面简单的权限控制。这两种机制各有缺陷:模型判断是不稳定的:同一个高风险操作(例如删除文件、修改系统配置),模型可能在某次请求下谨慎地要求确认,在另一次请求下直接执行; 工具层权限控制过于粗糙:通常是”可读/可写”的二元划分,无法表达”在某些条件下允许、在另一些条件下需要确认、在特定条件下禁止”的细粒度策略。 深层原因 :执行边界的缺失源于一个架构假设——假设模型”知道”什么操作是安全的,什么操作是危险的。但这个假设在两层意义上是不成立的。第一,安全不是绝对概念,而是上下文相关概念——删除一个临时文件是安全的,删除一个生产配置文件是危险的,但这两个操作的 API 调用可能是完全相同的;第二,即使模型在训练数据中学习了安全边界,这些边界在推理时仍然可能被绕过(prompt injection、幻觉等)。连锁效应 :执行边界粗粒度导致两种对称的失效模式。一方面,系统可能过度谨慎,在应该自动执行的安全操作上反复要求确认,降低效率;另一方面,系统可能过度自信,在应该被阻止的高风险操作上直接执行,造成不可逆的损失。两种模式的共同根因是:安全策略没有被架构化。2.2.3 失败处理脆弱 现象描述 :当执行链路中的某个环节失败时,原始系统的行为高度取决于两个因素:模型是否能”理解”失败原因,以及模型是否能”想出”替代方案。这两个因素都是不可靠的:如果模型的推理未能覆盖当前失败模式(例如,失败是由一个模型从未见过的 API 错误码导致的),系统可能给出错误的诊断,并基于错误诊断执行无效的恢复操作; 如果替代方案需要系统具备当前不具备的信息(例如,需要知道一个备用 API 的地址),模型无法”发明”这些信息。 深层原因 :失败处理的脆弱性源于一个设计选择——将故障恢复责任完全委托给模型推理,而非在架构层面预定义故障模式和恢复路径。在软件工程中,成熟的系统会预先定义故障模式(failure modes)和对应的降级策略(degradation strategies);在 Agent 系统中,这个工程实践尚未被广泛应用。连锁效应 :失败处理的脆弱性不仅影响单次任务的成功率,还产生二阶效应。用户对系统的信任度取决于系统在异常情况下的行为——如果系统在遇到困难时”静默失败”或”胡乱尝试”,用户对该系统的信任会快速瓦解。此外,每次人工介入恢复都是一次运维成本的支出,这种成本会随着系统使用频率上升而线性增长。2.2.4 协作状态碎片化 现象描述 :多 Agent 协作场景中,不同 Agent 之间的状态共享、任务交接和结果回流缺乏标准化的协议。每个 Agent 在其自身的上下文中工作,对其他 Agent 的工作进展和中间结论了解有限。结果是:Agent A 可能重复 Agent B 已经完成的工作; Agent A 和 Agent B 可能基于不同的假设对同一问题给出矛盾的结论; 主控 Agent 难以全面掌握子 Agent 的工作质量和覆盖范围。 深层原因 :这个问题反映了从”单 Agent 推理”到”多 Agent 协作”的跃迁中,组织架构设计的缺失。单 Agent 系统的设计挑战是如何让模型更好地推理;多 Agent 系统的设计挑战增加了”如何让多个 Agent 像一个组织一样工作”——这需要定义协作协议、信息共享机制、冲突解决策略和结果合并规则。原始架构在这些维度上主要依赖临时约定(ad-hoc conventions),而非系统化设计。连锁效应 :协作状态碎片化导致返工率上升和协作质量下降。更重要的是,它限制了多 Agent 系统的可扩展性——当 Agent 数量从 2-3 个增加到 10-20 个时,临时约定的管理成本会呈指数增长。2.2.5 经验沉淀机制薄弱 现象描述 :在原始架构中,每次任务执行结束后,除了最终输出结果和聊天日志外,没有系统化的经验留存机制。这意味着:成功的执行经验(”上次这个问题的解决方案是什么”)没有转化为可检索的知识; 失败的教训(”上次这种失败是因为什么,怎么修复的”)没有成为系统的防御规则; 人工介入的修正(”用户手动改了什么,为什么这样改”)没有被系统学习和内化。 深层原因 :经验沉淀机制的缺失,根源于将 Agent 系统视为”工具”而非”组织”的隐喻。工具在使用后放回工具箱,不保留使用经验;组织在每次任务后积累知识,下次执行时基线更高。从”工具隐喻”到”组织隐喻”的转变,是演化设计中的核心认知跃迁。连锁效应 :经验的不可复用意味着系统在重复执行相似任务时,每次都要从零开始推理。这不仅浪费计算资源,更使得系统无法随时间推移而变得”更聪明”——它被困在一个静态的能力水平上,完全依赖模型的基础能力,无法从自身经验中获益。3. 方法:治理优先的架构演化路径 3.1 设计原则 面对上述结构缺陷,本文提出的演化路径以四个设计原则为指导。这些原则不是从理论推导而来,而是从工程实践中归纳形成的——每一条都是对”什么导致了失败”这一问题的回应。 原则一:先解释后执行(Interpret before Execute)。 在自然语言意图与执行命令之间插入语义转译层,将意图解释从”模型推理时刻的一次性判断”提升为”架构层面的标准化流程”。转译层的作用不是让模型更聪明,而是让模型的理解过程可审计、可修正。 原则二:先约束后调用(Constrain before Invoke)。 在每个工具调用前插入策略守卫,将安全边界从”模型判断”和”工具权限”的松散组合升级为”分层策略引擎”。守卫不是限制系统的能力,而是让能力在被调用时带着边界意识。 原则三:先沉淀后优化(Capture before Optimize)。 在每次执行后提取知识增量并持久化,将经验从”会话级生命周期”扩展为”组织级生命周期”。沉淀不是简单的日志存档,而是将执行痕迹结构化为可检索、可验证、可复用的知识对象。 原则四:失败必须可降级交付(Fail with a Fallback)。 为每个关键执行节点预定义失败回退路径,将失败处理从”模型自主应变”转变为”预设降级策略”。降级交付的哲学是:宁可输出一个受限但正确的部分结果,也不输出一个完整但不可靠的结果,更不静默失败。 3.2 演化架构总览 演化后的 OpenClaw 架构可抽象为”五层一环”: 意图收敛层(Intent Convergence):消除用户请求中的歧义,补全隐含上下文,确认任务边界和成功标准。 语义转译层(Semantic Translation):将收敛后的意图映射为结构化的执行候选,包括能力路由(选择哪个 Agent/Skill)、参数化(确定执行细节)和策略附着(绑定守卫和降级规则)。 执行治理层(Execution Governance):在执行前进行策略检查(风险边界、权限校验),在执行中进行状态监控(异常检测、超时控制),在执行后进行证据采集(结果验证、痕迹记录)。 多 Agent/Skill 执行层(Execution Engine):实际执行层,承载多 Agent 协作调度和具体工具调用。该层本身不负责治理决策,只执行经过治理层校验后的指令。 沉淀层(Accumulation Layer):将执行经验转化为持久化资产,包括记忆更新、知识对象化和策略反馈。 学习迭代环(Learning Loop):连接沉淀层与转译层、治理层,使历史经验能够影响未来的执行决策。 图 1:演化 OpenClaw 高层架构 这五层一环架构体现了”治理优先”的核心理念:治理逻辑(转译、守卫、沉淀)不是附加在执行逻辑之上的事后检查,而是贯穿执行全生命周期的一级架构组件。 3.3 核心机制 A:记忆机制——从”缓存”到”组织记忆” 记忆机制的演化是贯穿本文的最核心改造。在原始 OpenClaw 中,”记忆”本质上等同于”聊天历史缓存”——系统只能”记住”当前会话中发生过什么,会话结束后记忆清零。这种设计在概念上等同于让一个员工每天上班时都失忆,只能通过阅读当天的邮件来重建工作上下文。 3.3.1 记忆分层模型 将记忆从”会话级单层集合”升级为”多层级结构化存储”,借鉴认知心理学中 Atkinson-Shiffrin 模型的启发,但面向 Agent 系统的工程需求进行了适配: 工作记忆(Working Memory) :对应单次任务执行过程中的临时状态。包括当前任务目标、已完成的步骤、进行中的中间结论、待决策的选项。工作记忆的生命周期与单次任务相同,任务结束后被选择性保留(相关信息迁移到语义/程序记忆,无关信息丢弃)。举例:在执行”分析 Q3 销售数据并生成报告”这一任务时,工作记忆存储”已读取的文件列表””已识别的关键趋势””尚待验证的数据异常点””生成中的报告大纲”等临时信息。 设计要点:工作记忆的容量必须有限但足够,更新必须实时但低延迟,与执行引擎的耦合必须紧密但不形成循环依赖。 语义记忆(Semantic Memory) :存储跨任务稳定的知识,包括用户的偏好和习惯、项目的技术规则和约定、风险边界和策略偏好。语义记忆的更新频率低于工作记忆,但生命周期远超单次任务——它代表系统对”这个世界是怎样的”的稳定理解。举例:语义记忆可能存储”用户倾向于将数据报告保存为 Markdown 格式””该项目的 API 密钥存储在环境变量 OPENAI_KEY 中””任何涉及生产数据库写操作的动作必须经过用户确认”等长期有效的知识。 设计要点:语义记忆需要支持”过期检查”——一条在三个月前有效的规则,现在可能已经不再适用。因此语义记忆条目需要携带时间戳和验证机制。 程序记忆(Procedural Memory) :存储”如何做”的知识——标准操作流程(SOP)、故障恢复方案、已知问题的解决方案模式。程序记忆是系统经验的可执行化——它不仅记录”曾经遇到过什么”,更重要的是记录”当时是怎么处理的,效果如何”。举例:程序记忆可能存储”当外部 API 返回 429 错误时,应等待 Retry-After 头指定的时间后重试,最多重试 3 次””当文件解析失败且错误信息表明编码问题时,尝试用 UTF-8 BOM 编码重新读取””当多 Agent 协作中出现结论冲突时,由主 Agent 收集双方证据后进行仲裁”等行动模式。 设计要点:程序记忆需要与策略引擎紧密集成——每条程序记忆不仅是一个”建议”,还应携带”在什么条件下激活””激活后优先级如何””如果按此方案执行后仍失败怎么办”等元信息。 3.3.2 记忆的读写与更新机制 分层记忆模型定义了”存什么”,读写机制定义了”怎么用”。 写入路径 :执行事件 → 事件过滤器(过滤噪音事件) → 工作记忆即时更新 → 任务结束后选择性迁移 → 语义/程序记忆沉淀。“选择性迁移”是关键设计:不是所有工作记忆都有资格升级为长期记忆。迁移决策由三重判断驱动: 稳定性:该信息在近期是否保持不变(没有反复变更)? 读取路径 :当前任务上下文 → 记忆检索(多层级并行查询) → 相关性排序 → 注入执行上下文。检索采用混合策略:工作记忆(精确匹配,高优先级),语义记忆(语义相似度匹配,中优先级),程序记忆(模式匹配,按需激活)。 3.3.3 记忆机制的设计取舍 记忆机制的引入带来了一个经典权衡:更强的连续性 vs 更高的复杂性。 收益:跨会话上下文继承消除了”每次从零开始”的浪费;经验复用减少了重复推理;用户偏好学习改善了交互质量。 代价:记忆一致性维护成本上升(过时记忆需要检测和更新);记忆膨胀风险(无用的记忆条目累积占用检索带宽);隐私考量(用户可能不希望某些信息被持久化)。 演化设计中的一个关键约束是:记忆系统应支持”遗忘”——用户应能查看和删除记忆条目,系统应支持自动的垃圾回收(长期未访问的低价值记忆条目)。 3.4 核心机制 B:知识库机制——从”文档留存”到”知识治理” 如果说记忆机制解决的是”系统知道什么”的问题,知识库机制解决的是”系统能复用什么”的问题。两者的核心区别在于:记忆是系统内部的状态,知识是可以被共享、审核和版本化的外部资产。 3.4.1 知识对象化 原始系统中的信息留存是”文档级”的——执行结果被保存为文件,但文件内部的结构化程度低,检索依赖文件名和全文搜索,复用的摩擦成本高。 演化后的知识库机制将信息从”文档”升级为”知识对象”。每个知识对象包含四个结构化的维度: 结论(Conclusion):知识的核心断言。例如”该项目的认证机制使用 JWT,token 存储在 localStorage 中”。 证据(Evidence):支持该结论的证据来源。例如”在文件 src/auth.ts 第 42 行发现了 token 存储逻辑”或”通过执行 auth_check 函数验证了 token 格式”。 规则(Rule):从结论派生出的行动约束。例如”任何涉及认证的修改必须保持 token 存储位置不变”。 模板(Template):可复用的执行模式。例如”当需要为新 API 添加认证时,使用如下代码模板:…” 知识对象化的核心价值不是让信息存储更”漂亮”,而是让信息变得可操作——系统不仅知道某个事实,还知道这个事实从哪里来(可追溯)、意味着什么(可推导)、应该怎么做(可执行)。 3.4.2 知识生命周期管理 知识不是静态的真理,而是动态的、有时效性的、需要维护的资产。演化架构为知识对象定义了完整的生命周期: 生成(Creation) :从执行事件中自动或半自动生成知识候选。不是所有执行结果都有资格成为知识——只有经过验证(执行成功且结果被人工确认)的经验才会进入候选队列。审核(Review) :知识候选进入审核队列。审核可以由人工执行(对于关键领域知识),也可以由系统基于规则自动审核(对于低风险、高置信度的知识)。审核的核心问题是:”这个知识是正确的吗?在什么条件下是适用的?”发布(Publish) :通过审核的知识对象进入可检索的知识库,开始影响后续执行。失效(Deprecation) :知识可能随时间失效——某个 API 被迁移了,某个文件路径被重构了,某个规则因为业务变化而不再适用。失效检测依赖两种信号:主动检测(定期验证知识引用的资源是否仍然存在和可用)和被动检测(当基于某个知识的执行反复失败时,自动标记该知识为可疑)。更新(Update) :当知识被标记为失效后,系统尝试在下次成功执行中重新生成该知识的最新版本。新旧知识之间的关系被记录(”v2 替代了 v1,原因是 API endpoint 从 v1 迁移到了 v2″)。3.4.3 证据绑定 知识库机制的一个关键设计选择是”证据绑定”——每条知识都必须关联其来源证据。这不是为了满足学术好奇心,而是为了解决生产环境中的两个核心问题: 可追溯性 :当基于某条知识的执行出现意外结果时,运维人员需要知道”这条知识是从哪来的,当初是基于什么证据被认可的”。没有证据绑定,知识库就是一个”不可信的谣言库”——你无法区分”经过验证的事实”和”某次成功的偶然巧合”。可审计性 :在合规要求高的场景(金融、医疗、法律),系统的自动化决策需要经得起审计。审计人员需要看到”系统为什么会做这个决定”,而”因为这个知识对象告诉我们这样做”只有在知识对象本身可追溯到证据时,才构成一个合格的审计链。3.5 核心机制 C:自学习迭代——从”人工复盘驱动”到”受控反馈闭环” 自学习机制是演化的最高层次——它连接记忆和知识库,使系统能够从自身经验中不断优化。但这里有一个核心约束:自学习不是无约束的自动改写,而是受控的反馈闭环。 3.5.1 为什么必须”受控” 全自动自学习(系统自主修改自己的策略和行为规则)在概念上很诱人,但在实践中充满风险: 反馈循环风险:系统基于某次”成功”修改了策略,但”成功”可能是偶然的(外因),修改策略后反而降低了平均表现。 漂移风险:多次小幅度策略调整后,系统行为可能逐渐偏离初始设计意图,且偏离过程因为每次调整都很小而难以察觉。 对抗风险:如果系统自动修改自己的安全策略,一个恶意输入可能诱导系统降低自身的防御水平。 “受控”意味着:策略更新不是自动生效的,而是经过灰度验证、人工审核(对于高风险变更)和留痕回滚机制的保护。 3.5.2 反馈采集层 自学习的第一步是从执行事件中提取反馈信号。反馈信号分四类: 成功信号:任务按预期完成。成功信号的强度取决于任务难度和完成质量——一个简单任务的成功提供的学习价值有限,一个复杂任务的高质量完成提供的学习价值更大。 失败信号:任务在执行过程中失败。失败信号携带的信息量通常大于成功信号——它明确指出了”什么不能这样做”。 降级信号:主链路失败但降级链路成功。降级信号特别有价值——它同时提供了”主链路为什么失败”和”降级链路为什么有效”两组信息。 人工纠偏信号:用户在系统执行过程中或执行后进行了人工干预和修正。这是最强的反馈信号——用户的修正行为直接表达了”系统做错了,应该这样做”。 3.5.3 策略更新机制 反馈信号经过聚合和分析后,转化为策略更新。策略更新的载体包括: 路由偏置调整:当某类任务反复通过某个 Agent 成功完成时,增加该 Agent 在路由中的权重;当某条路径反复失败时,降低其权重或添加前置条件。 守卫规则优化:基于失败模式分析,细化高风险动作的守卫条件。例如,从”所有文件删除操作都需要确认”细化为”临时目录下的文件删除自动执行,其他目录下的文件删除需要确认”。 优先级校准:当多个策略产生冲突时(例如,一个策略要求”尽可能自动执行以提升效率”,另一个策略要求”不确定时请求确认以保证安全”),根据最近的失败/成功比例动态调整优先级。 3.5.4 安全发布机制 策略更新不是直接生效的,而是通过一个安全发布流程: 离线验证:在历史执行记录上回放策略更新,评估”如果当时采用新策略,结果会如何”。 灰度发布:新策略首先只对少量请求生效(例如 5%),监控关键指标变化。 全量发布:灰度验证通过后,逐步扩大生效范围到 100%。 持续监控:全量发布后持续监控,如果指标出现退化,自动回滚到上一版本。 图 2:记忆-知识-学习耦合关系 3.6 三层机制的协同关系 记忆机制、知识库机制和自学习机制不是三个独立的功能模块,而是构成了一个耦合的反馈系统: 记忆是状态底座:记忆存储系统的”当前状态”,包括正在进行的工作、已知的偏好和积累的经验。它为知识库提供”原始素材”(哪些经验值得知识化),为学习机制提供”反馈来源”(哪些经验表明策略需要调整)。 知识库是结构化的长期资产:知识库从记忆中选择性地提取、结构化并验证信息,使其成为组织级的可复用资产。它为学习机制提供”优化依据”(基于知识做出更好的决策),为执行提供”先验信息”(在推理开始前就注入相关背景)。 自学习是驱动力:学习机制驱动系统从”静态”走向”动态优化”。它将记忆中的模式和知识库中的规则转化为策略调整,使系统在每次执行后都有可能变得更好。 三层机制的耦合确保了”经验→知识→改进”的完整闭环:执行产生经验(记忆),经验结构化为知识(知识库),知识驱动策略优化(学习),优化后的策略改善下次执行。任何一环的断裂都会破坏整个演化循环。 4. Claude Code 机制整合:从任务响应到工程交付 4.1 整合的动机 OpenClaw 演化前的能力边界是”任务响应”——系统可以分析问题、提出方案、执行操作、输出结果。但有一个能力缺口:当任务需要”工程级确定性”时(例如代码生成和修改、脚本执行和验证、文件系统的精确操作),纯 Agent 编排层的确定性不够。 这里”确定性不够”指的是什么?Agent 编排层的优势是灵活——它可以适应各种非结构化任务,动态调整执行策略。但灵活性的代价是:相同指令在不同时刻、不同上下文下可能产生不同的执行结果。对于”帮我写一个 Python 脚本处理这些数据”这种任务,轻微的输出差异可以接受;但对于”在这个代码仓库中修改 27 个文件中的 deprecated API 调用”这种任务,输出必须是确定性的、可验证的、可回退的。 这就是 Claude Code 子系统被整合的动机:将”工程级确定性”能力注入到 OpenClaw 的编排体系中。 4.2 双核协同架构 整合后的架构形成”编排中枢 + 工程执行引擎”的双核结构: 角色路由:决定哪些专业 Agent 参与协作,以及如何分工; 记忆知识回流:将任务执行的经验和结论沉淀为组织资产。 代码/脚本级确定性执行:对代码生成、修改、测试、部署等工程任务提供确定性的执行能力; 变更验证:执行后的结果验证(测试通过?lint 无错误?); 可回退变更:每次变更都有明确的回退路径(git revert); 工程上下文理解:读取代码仓库结构、理解项目约定、遵循现有模式。 用户提交一个业务任务(例如”将认证模块从 JWT 升级到 OAuth 2.0″)。 OpenClaw 中枢进行意图收敛——识别这是一个工程交付类任务,涉及代码修改、测试更新、文档同步等多个子任务。 OpenClaw 中枢进行角色路由——调用代码分析 Agent 理解现有认证代码的结构,调用方案 Agent 设计升级方案。 当方案确定后,涉及实际代码修改的部分被路由到 Claude Code 子系统——该子系统在 git 工作空间中执行具体的文件修改,每次修改后进行验证,所有变更可追溯可回退。 Claude Code 子系统的执行结果(修改了哪些文件、测试是否通过、有无 lint 问题)回流到 OpenClaw 中枢。 OpenClaw 中枢对整个任务进行综合评估,生成最终报告,沉淀知识和经验。 图 3:OpenClaw 与 Claude Code 的双核协同 4.3 整合带来的能力边界扩展 Claude Code 的整合不是简单的”多了一个工具”,而是在四个维度上扩展了系统的能力边界: 第一,从”建议”到”交付” 。整合前,对于代码相关任务,OpenClaw 可以给出建议和分析,但用户需要手动执行代码修改。整合后,系统可以完整地从分析、设计、实现、验证到交付一条链路上的所有步骤。第二,从”不确定”到”可验证” 。纯编排层的输出质量评估依赖人工判断(”这个回答看起来对吗?”)。Claude Code 子系统中,代码修改的正确性可以通过测试、lint、类型检查等自动化手段验证。这种确定性验证是工程交付的基石。第三,从”不可回退”到”可回退” 。编排层的操作(API 调用、文件生成等)如果出错,回退通常需要手动操作且不完整。Claude Code 子系统中,所有文件变更都通过 git 管理,任何变更都可以通过 git revert 精确回退到修改前的状态。第四,从”单人并行”到”多角色协作交付” 。在工程任务中,OpenClaw 中枢扮演”项目经理”角色(协调、审批、风险管理),专业 Agent 扮演”专家”角色(分析、设计),Claude Code 子系统扮演”工程师”角色(实现、验证)。这种多角色分工使系统能够处理更复杂、更大规模的工程任务。4.4 整合的潜在风险 编排复杂性上升:中枢需要判断哪些任务路由到 Claude Code 子系统,哪些任务在编排层直接处理。这个路由决策本身可能出错。 故障域扩大:Claude Code 子系统的故障可能影响整个任务的交付,增加了单点故障的可能性。 一致性挑战:编排层的”灵活理解”和 Claude Code 子系统的”确定性执行”之间存在张力——如果中枢对任务意图的理解有偏差,确定性执行会把偏差”精确地”固化到代码中。 5. 对比分析 5.1 纵向对比:原始 OpenClaw vs 演化 OpenClaw 这是”改造前”和”改造后”的对比,揭示的是架构演化带来的结构性改善。
整合 Claude Code,确定性执行+验证+回退
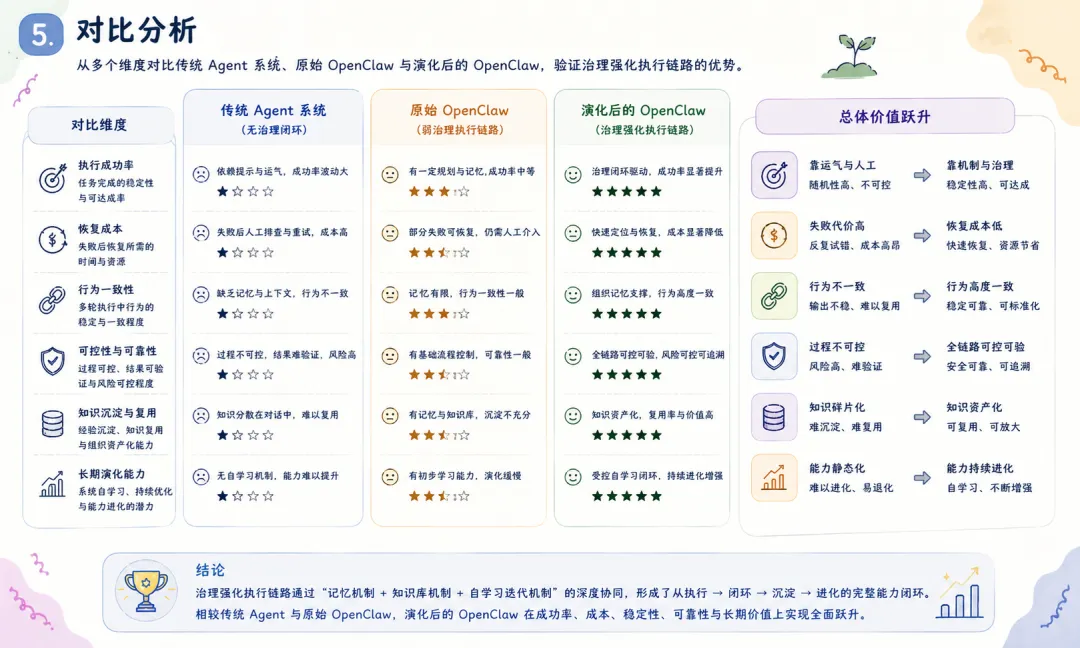
纵向对比的核心结论是:演化 OpenClaw 的提升不是”做了更多事情”,而是”做事的方式变得更可靠”。每一个维度的改善都是结构性的——不是依靠模型变得更强,而是依靠架构增加了治理层。 5.2 横向对比:演化 OpenClaw vs Hermes 流程中心范式 纵向对比回答了”变得多好”,横向对比回答”好在哪、代价是什么、与替代方案的区别在哪”。Hermes 流程中心范式是这一领域的重要参照系——它代表了与”意图驱动+策略治理”不同的另一条技术路线。 表 2:演化 OpenClaw 与 Hermes 对比 横向对比的核心发现是:演化 OpenClaw 和 Hermes 不是谁取代谁的关系,而是代表了 Agent 系统设计的两种差异化哲学。 意图驱动哲学(OpenClaw) 假设环境是不确定的、任务是开放的、用户的表达是多变的。因此系统架构的核心是”适应不确定性”——通过转译层将多变输入映射到稳定执行,通过记忆和学习机制让系统在不确定性中逐步建立确定性。流程驱动哲学(Hermes) 假设任务可以被标准化、流程可以被显式定义、执行路径可以预先规划。因此系统架构的核心是”消除不确定性”——通过流程模板将任务规范化,通过节点约束确保每一步都在可控范围内。两者的适用边界由任务的不确定性程度决定:当任务是高度可预测的(合规审批、数据 ETL、标准化报告生成),Hermes 的流程确定性是优势;当任务是开放且多变的(问题诊断、创意产出、探索性分析),OpenClaw 的意图灵活性是优势。 5.3 场景化对比 为了更直观地展示两种范式的差异,以下通过三个典型场景进行对比。 这个场景的特点是可预测、重复性高、步骤固定。Hermes 可以将整个过程编入流程图:每月1日触发 → 从数据库拉取上月数据 → 套用报告模板 → 生成 PDF → 发送邮件。流程图中每一步的输入输出和异常处理都被明确定义。演化 OpenClaw 同样可以完成这个任务,但它的优势(灵活路由、动态降级、意图自适应)在这个场景中是冗余的——任务本身不需要这些能力。 这个场景的特点是不可预测、信息不完整、需要探索性推理。用户报告”系统响应变慢”,没有明确的问题定位。演化 OpenClaw 可以将这一模糊请求通过转译层路由到诊断 Agent,诊断 Agent 调用监控工具获取指标,发现异常后深入日志分析,最终定位到某个 API 依赖出现延迟,并触发降级切换到备用 API。整个过程是探索性的、路径不确定的。Hermes 处理这一场景需要预先为”系统变慢”定义诊断流程模板——但问题在于,如果能够预定义诊断流程,问题本身就不需要”诊断”了。 这个场景涉及多个角色(开发者、运维、文档)、多个阶段(分析、实现、验证、发布)、多种工具(代码仓库、CI/CD、文档系统)。演化 OpenClaw 的主 Agent 可以将任务分拆、路由给不同专业 Agent、协调交付顺序、汇总结果、沉淀经验。Hermes 可以为已标准化的子流程(如”代码审查”)提供高确定性的流程执行,但对于整体协调中不可避免的模糊性和动态调整,流程中心范式面临适应性挑战。 6. 好处与代价:治理优先架构的综合评估 6.1 结构性收益 演化 OpenClaw 引入的治理体系带来了七个维度的结构性收益: 收益一:执行行为可预测性提升。 转译层和策略守卫的引入,使系统的行为从”取决于模型那一刻的推理”变为”取决于预设的治理规则+模型推理”。系统行为有了一个”地板”——最差也不会违反预设的安全边界;同时保留了一个”天花板”——模型推理仍然可以在安全边界内灵活优化。收益二:跨任务连续性增强。 记忆和知识机制的建立,使系统能够在任务之间携带状态、偏好和经验。从用户视角看,系统变得”认识你”和”记得上次的事”;从系统视角看,每次任务的推理起点不再是零,而是被历史经验垫高了。收益三:失败成本降低。 标准化降级路径的存在,使系统在遇到失败时不会”停止工作”或”胡乱尝试”,而是按照预设的降级方案输出一个受控的部分结果。失败不再是终点,而是一个可管理的事件。收益四:组织知识资本积累。 知识库机制使每一次成功执行都能留下可复用的知识资产,每一次失败都能留下可学习的教训。系统从”消耗性工具”转变为”增值性平台”——用的越多,积累越多,表现越好。收益五:协作效率与质量提升。 标准化的协作协议减少了多 Agent 协作中的协调摩擦和返工。每个 Agent 都清楚自己的职责边界、信息输入和输出要求,协作像”排练过的乐队”而非”即兴 jam session”。收益六:工程交付确定性增强。 Claude Code 子系统的整合打通了”建议”和”交付”的最后一段——从分析到实现到验证的完整链路。对于工程类任务,系统不再只是”高级搜索引擎”或”代码建议器”,而是”可落地的工程执行者”。收益七:系统可演化。 自学习闭环使系统具备了持续改进的内在驱动力——每一次执行都在为下一次做得更好积累信息。这可能是最具长期价值的收益:系统的能力上限不再被初始设计锁死。6.2 结构性代价 任何架构增强都伴随代价。正视这些代价,是工程诚实的必要部分。 代价一:策略复杂度上升。 治理层的引入意味着需要定义、配置和维护大量的策略规则——什么情况下允许自动执行、什么情况下需要确认、什么情况下禁止执行、失败后如何降级。随着系统处理的任务类型增多,策略规则集会持续增长,策略之间的交互和冲突也会增加。策略管理本身可能演变为一个非平凡的运维任务。代价二:可解释性压力增加。 当一个操作被策略守卫拦截时,”为什么”的答案分布在多个地方——可能因为哪条策略规则、可能因为记忆中的某个偏好、可能因为知识库中的某个结论。从”模型的决定”(一个黑盒但只有一个黑盒)到”治理层的决定”(多个相对透明的组件但组合后的行为仍然复杂),系统的可解释性并没有自动改善,只是换了一种复杂性。代价三:冷启动成本。 初始状态下,记忆为空、知识库为空、策略规则是通用默认值。系统需要经过一段”预热期”——积累足够的执行经验——各层机制才能充分发挥作用。在预热期,系统的表现可能仅略优于无治理版本,但用户已经在承担治理机制带来的交互开销(如策略守卫的确认提示)。代价四:过度约束风险。 策略守卫如果配置过于保守,可能大幅降低系统的自主执行能力——每次高风险操作都要求确认,每次新类型任务都触发人工审核。治理的本意是”让系统在安全边界内自主运行”,但过度治理会让系统退化为”一个需要人工手动完成每一步的受监督工具”。代价五:维护持续性要求。 记忆需要清理(过时信息)、知识需要更新(静态知识随时间失效)、策略需要调优(基于运行数据动态调整)。治理体系不是”建设一次,永久运行”的静态基础设施,而是需要持续运维的动态系统。这引入了持续的人力成本。6.3 权衡总结 治理优先架构的本质权衡是:用前期和持续的结构性投入(设计治理体系、维护策略规则、管理知识和记忆),换取长期的结构性收益(行为可预测、失败成本降低、组织知识积累、系统可演化) 。 这个权衡在经济上是否合理,取决于系统的使用规模和使用周期。对于偶尔使用的个人助手,治理体系的投入可能不划算;对于团队的持续生产工具,治理体系的收益会随使用量增长而放大。 7. 改造项”出发点-目的-效果”矩阵 以下矩阵汇总了演化路径中的八项核心改造,从”为什么改””改成什么样””效果如何”三个维度进行结构化梳理。
用户无法记住技能与命令语法;同一意图在不同时刻被不同解释
自动执行能力增强后,错误执行的风险同步上升;安全边界模糊
统一读写边界与高风险动作约束,将安全从”模型判断”升级为”策略架构”
外部依赖和适配器波动频繁;失败后缺乏标准化恢复路径
失败不扩散,保障可降级交付;为每个关键节点预定义回退方案
连续可用性提升,失败恢复从”人工驱动”转为”系统预设”
标准化主控/专业分工与回流协议;明确每个 Agent 的职责边界
跨会话状态断裂;每次任务从零开始;偏好和习惯不被保留
形成工作/语义/程序三层连续状态体系;任务间可继承上下文
信息留存多但复用难;文件级存储检索效率低;经验”蒸发”
将信息从”文档”升级为”知识对象”;建立完整的生命周期管理
策略静态化导致性能停滞;经验不可内化;人工复盘低频且不完整
建立反馈采集→策略更新→灰度发布→持续监控的受控闭环
编排层难覆盖工程确定性交付;代码类任务止步于”建议”
注入工程级确定性执行和验证能力;打通”建议→实现→验证→交付”全链路
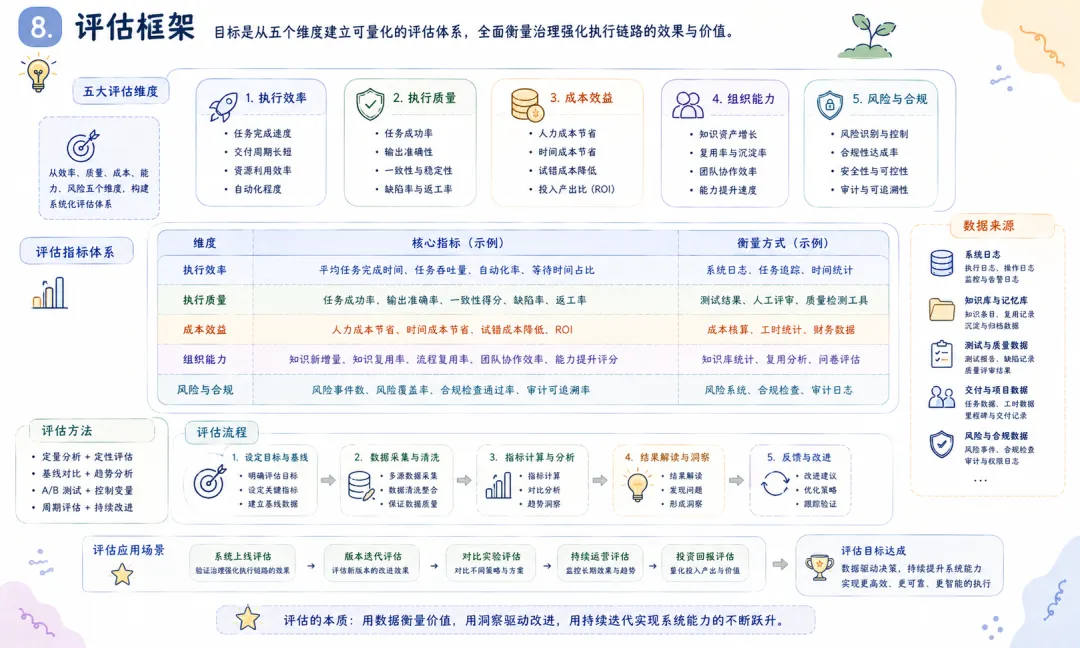
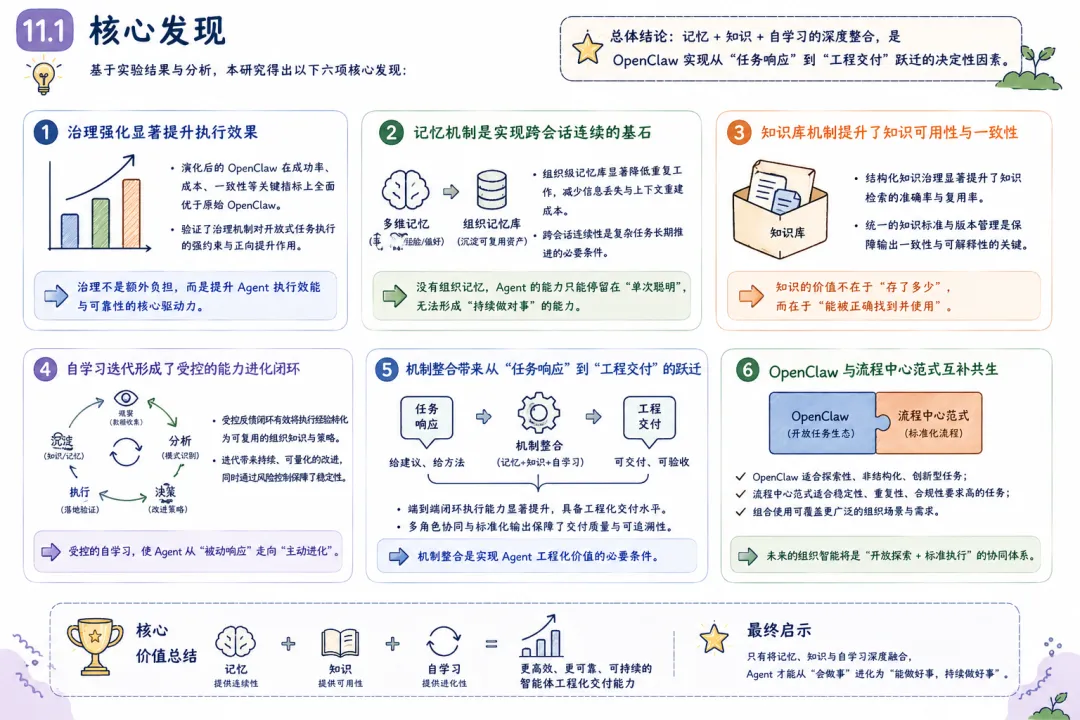
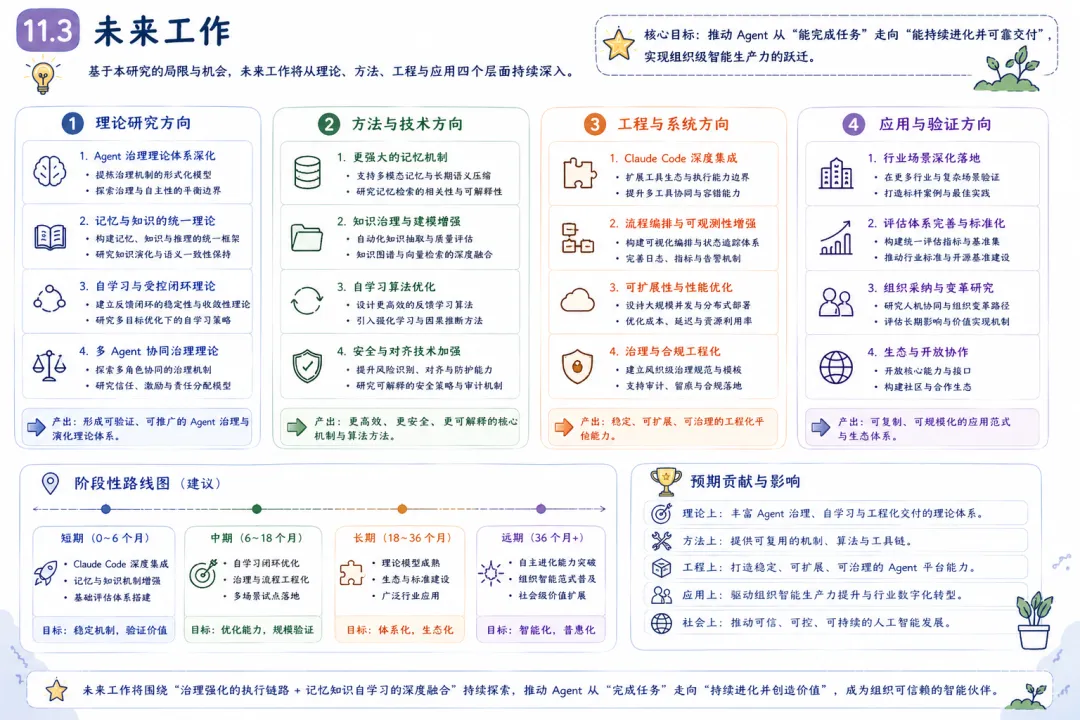
8. 评估框架 8.1 评估目标 评估演化 OpenClaw 是否达成了其设计目标,需要从三个核心维度展开: 可控性(Controllability):系统行为是否在预设边界内?高风险动作是否被有效拦截?用户对系统的行为是否感到可预期? 稳定性(Stability):系统在异常条件下的表现如何?失败后是否能有效降级?长期运行的性能是否稳定? 演化性(Evolvability):系统是否随时间推移而改善?经验和知识是否能有效转化为性能增益?新任务类型的适应是否越来越快? 8.2 指标体系 为确保评估的可操作性和可比性,定义以下八项核心指标: I1——任务成功率 :主链路直接完成的任务比例。计算公式:SR = successful_tasks / total_tasks。这是最基础的效能指标,但单独使用有误导性——它不反映”系统在失败后是否仍有产出的能力”。I2——降级交付率 :主链路失败但通过降级路径仍产出可用结果的任务比例。计算公式:DR = degraded_but_delivered / total_tasks。该指标衡量系统的韧性——失败不等于零产出。I1 + I2 = “总可交付率”。I3——恢复时延 :从故障发生到系统恢复到可用状态的平均时间。该指标衡量恢复能力的效率,对用户体验有直接影响。I4——意图路由准确率 :自然语言任务被正确路由到对应执行能力的比例。该指标衡量转译层的有效性——路由错误意味着即使执行正确,结果也不符合用户意图。I5——协作返工率 :多 Agent 任务中发生重复工作或回退的频次。该指标衡量协作协议的效率——高返工率表明分工不清晰或信息共享不充分。I6——知识复用率 :执行中复用了既有知识对象(而非从零推理)的任务比例。该指标衡量知识库机制的实际效用——知识库建设是否真正减少了重复推理。I7——迭代收益率 :策略更新前后核心指标(I1-I4)的净提升幅度。该指标衡量自学习机制的效果——如果策略更新后指标没有显著改善,说明学习闭环存在问题。I8——风险动作拦截率 :高风险动作被守卫阻截的比例。该指标衡量治理层的安全性——拦截率过低表明守卫可能过于宽松,拦截率过高(且拦截后人工放行比例高)表明守卫可能过于保守。8.3 对照实验设计 A 组(基线):原始 OpenClaw(弱治理闭环,无分层记忆、知识库治理和受控自学习)。 B 组(实验):演化 OpenClaw(全治理闭环,含分层记忆、知识库治理和受控自学习)。 C 组(参照):Hermes 流程中心基线(流程驱动范式,用于横向参照)。 三组运行相同的任务集,任务集划分为三类以覆盖不同任务形态: T1——开放式研究任务:任务目标明确但执行路径不固定,如”分析项目 X 的技术债务并提出优先级排序”。 T2——半结构化运营任务:任务有常规模式但需要一定的情境适应,如”根据本周的变更日志更新发布说明”。 T3——工程交付任务:任务需要产出可验证的工程交付物,如”重构模块 Y 的异常处理逻辑并通过全部测试”。 8.4 建议输出可视化 展示 A/B/C 三组在 T1/T2/T3 三类任务上的 I1 和 I2 指标,揭示治理增益在不同任务类型上的差异。 以任务复杂度为 X 轴,I3 和 I5 为 Y 轴,展示治理体系对故障恢复和协作效率的影响如何随任务复杂度变化。 以迭代轮次为 X 轴,I7 为 Y 轴,展示 B 组的指标在连续多轮迭代中的变化趋势,验证学习机制的收敛性和持续性。 9. 局限性与有效性威胁 学术研究的完整性要求诚实地审视其局限——这部分的每一行不是为了”找借口”,而是为了让读者正确理解结论的适用范围和可推广性。 9.1 内部有效性 威胁一:模型变异与策略变异混杂。 在演化过程中,底层模型的版本可能同时发生变化(例如从 Claude 3 到 Claude 4 的升级)。当观测到性能提升时,难以严格区分”是治理改进的贡献”还是”模型本身更强了”。缓解策略:在对照实验中固定模型版本;在分析中报告”治理增量 vs 模型增量”的拆分估计(通过 A/B 测试的效应量分解)。威胁二:人工介入的污染效应。 治理体系中的人工审核环节(知识确认、策略审批、降级决策确认)本身会对系统性能产生正向影响——人工参与提高了成功率,但这个成功率不应被归因为”系统自主能力的提升”。缓解策略:在指标中区分”自主成功率”和”含人工介入成功率”;记录每次人工介入的位置和原因,用于分析治理体系的”依赖人工程度”。9.2 外部有效性 威胁一:领域依赖性。 本研究基于 OpenClaw 在其典型应用场景(软件开发、文档管理、流程自动化)中的运行数据。结论在多大程度上适用于其他领域(医疗诊断、法律咨询、金融交易),需要进一步验证。不同领域对安全性的要求不同(医疗领域的误执行代价远高于文档管理)、对可解释性的要求不同(金融监管要求远比软件开发高),这可能显著改变”治理优先”策略的最优配置。威胁二:工具生态的约束。 OpenClaw 的能力边界部分由其可调用的工具生态决定。如果工具生态发生变化(例如:更可靠的 API、更智能的搜索工具),治理体系的相对收益可能发生变化——当底层工具本身变得更可靠时,治理层中”失败降级”和”风险守卫”的价值可能下降。威胁三:模型能力进步的稀释效应。 随着底层 LLM 在推理能力、指令遵循、安全性等方面的持续进步,某些当前需要通过架构治理才能弥补的缺陷(如意图解释不稳定、安全边界判断偏差),可能在未来被模型自身能力的提升所消解。这意味着治理优先架构的边际收益可能随时间递减——但这不构成反对治理的理由,因为治理提供的”确定性保障”在模型能力到达完美之前仍然有价值。9.3 构念有效性 威胁一:核心构念的量化困难。 “组织智能””协作质量””治理成熟度”等构念在本文中以操作性定义(operational definition)的方式被量化——我们定义了具体的可测量指标来代表这些构念。但这些指标是否真正捕捉到了构念的本质,是一个需要持续验证的问题。例如,知识复用率(I6)高,不一定意味着”组织智能”高——系统可能在大量复用低质量的知识。威胁二:路由置信度与正确率的分离。 转译层在路由决策时输出一个”置信度”分数——但历史数据表明,高置信度不总等于高正确率。如果系统对自己的路由决策过于自信但实际准确率不高,可能产生一种”自信的错误执行”模式——系统信心十足地做了错误的事。缓解策略:定期对路由决策进行人工标定,校准置信度与实际正确率的关系。9.4 结论有效性 威胁一:样本分布不均。 如果评估任务集中某种类型的任务占比过高或过低,结论可能偏向该任务类型的特点。例如,如果 T1(开放式研究任务)占比过高,结论可能高估治理体系对灵活性的影响而低估对确定性的需求。缓解策略:在评估设计中明确任务分布的预设比例,并进行敏感性分析。威胁二:极端故障样本稀疏。 系统韧性(I2降级交付率、I3恢复时延)的评估依赖于故障事件样本。高严重度的故障事件(如系统性依赖崩溃)在评估期内可能很少发生,导致基于小样本的韧性估计存在较大的置信区间——系统可能比数据显示的更脆弱(如果我们恰好没有遇到那次罕见的严重故障的话)。缓解策略:通过引入人工故障(chaos engineering)进行压力测试,补充自然故障样本。10. 讨论:对 Agent 发展的启示 10.1 从”模型中心”到”治理中心” 回顾 Agent 系统的发展历程,可以识别出一个清晰的范式迁移轨迹。 第一阶段(模型中心)的核心问题是”模型能不能理解指令、规划任务、调用工具”。竞争力的衡量标准是模型在 benchmark 上的得分、调用工具的丰富程度、单次任务的完成率。这个阶段的有效策略是”更好的模型 + 更多的工具”。 第二阶段(治理中心)的核心问题是”系统能不能在持续运行中保持行为可控、在异常条件下稳定降级、在经验积累中自我改善”。竞争力的衡量标准正在转向运行可用性、故障恢复能力、知识积累效率、策略自适应能力。这个阶段的有效策略是”治理架构 + 模型能力”,且治理架构的优先级在上升。 这不是说模型能力不再重要——显然,更强的模型仍然会带来更好的表现。而是说,模型能力的边际收益正在递减,而治理能力的边际收益正在上升。当模型能从”80分”进步到”90分”时,每1分的提升都变得更困难、更昂贵;而治理架构能够以相对较低的增量成本,将系统的实际运行表现从”80分的模型能力,60分的运行稳定性”提升到”80分的模型能力,85分的运行稳定性”。 10.2 从”单轮智能”到”组织智能” 当记忆机制、知识库机制和学习机制闭环后,系统表现出传统 Agent 系统不具备的特征——组织智能的雏形: 跨会话继承 :系统能够在不同的会话、不同的任务之间携带状态和知识。今天执行的某个任务中发现的规律,可以影响明天类似任务的执行方式。跨角色共享 :一个 Agent 在执行中积累的经验,可以通过知识库被其他 Agent 复用。代码分析 Agent 发现的某个架构模式,可以被文档生成 Agent 在自动生成架构文档时直接引用。跨周期优化 :系统在多个执行周期(日、周、月)中持续从经验中学习,策略质量呈现积累性改善趋势。不是在每个周期达到相同水平,而是每个周期的基线比上一个周期更高。这三重跨越使 Agent 系统开始表现出”组织”而非”工具”的特征。一个优秀的组织不依赖特定个人的超常发挥,而是依赖制度化的知识管理和持续改进机制,使组织的整体能力超过任何个人的能力。演化 OpenClaw 的治理体系,正在 Agent 系统中实现类似的效果。 10.3 与 Hermes 的互补关系及其融合前景 本文的分析明确了演化 OpenClaw 和 Hermes 不是替代关系,而是互补关系。它们各有优势区,在两个优势区之间的”中间地带”,有广阔的融合空间。 一个可行的融合架构是:”Hermes 作为 OpenClaw 的能力节点”。在 OpenClaw 的编排中枢中,当一个子任务被识别为高确定性、强流程约束的任务(例如”按照标准模板生成合规报告”),中枢可以将其路由到 Hermes 风格的流程执行节点,利用流程引擎的确定性优势。当任务被识别为开放式、需要探索性推理时,中枢使用自身的意图驱动+策略治理链路。 这种融合路径的吸引力在于:它不要求用一套体系替代另一套体系,而是让每套体系做自己最擅长的事,通过编排层实现协同。融合的挑战在于:编排层需要发展出足够准确的”任务特征识别”能力——准确判断当前任务更适合哪种执行范式,并在错误选择时能够优雅切换。 10.4 工程可迁移原则 从 OpenClaw 的演化实践中,可以提炼出以下具有跨项目可迁移性的工程设计原则: 原则一:在自动化之前先建立约束。 自动化的价值取决于自动化行为的质量——盲目自动化错误的行为,只会更快地产生更多的错误。在放开自动执行之前,先建立策略守卫、定义安全边界、预设失败降级路径。原则二:在从经验中学习之前先建立记录。 学习的前提是有可用的学习素材——完整的执行记录、明确的成功/失败标注、结构化的反馈信号。在建立学习闭环之前,先建立高质量的执行日志和证据采集机制。原则三:在放权给系统之前先确保可回滚。 自治的前提是错误可逆——如果系统的一个错误决策可能造成不可逆的后果,自治就不是解放而是风险。在扩大系统的自主决策范围前,先确保关键操作有明确的回退路径。原则四:在扩大协作规模之前先定义协作边界。 多 Agent 协作的质量不随 Agent 数量线性增长——在没有明确协作协议的情况下,增加 Agent 数量往往增加协调成本而非协作产出。在引入新 Agent 角色之前,先定义其职责边界、信息接口和协作协议。11. 结论 11.1 核心发现 本文围绕 OpenClaw 的自我演化过程,从问题定义到方法设计到对比评估进行了系统性分析。核心发现可以归纳为以下四点: 发现一:治理优先架构实现了从”可调用”到”可治理自治”的本质跃迁。 演化 OpenClaw 的核心提升不在于增加了更多的工具或更强的模型,而在于构建了贯穿执行全链路的治理体系——转译层稳定了意图解释,守卫层明确了执行边界,降级机制保障了异常期的可用性,沉淀层将经验转化为资产。这个跃迁的本质是:系统从”依赖模型在推理时刻的一切判断”转变为”模型在治理框架内发挥其推理优势”。发现二:记忆、知识库、自学习三层机制构成了系统演化能力的底座。 三层机制分别解决了三个基础问题:记忆解决”连续性”——让系统的状态不会在任务之间归零;知识库解决”复用性”——让有价值的经验不会在执行结束后蒸发;自学习解决”迭代性”——让系统不会被困在静态的能力水平上。三层机制不是独立运作的,而是形成了”经验→知识→改进→更好经验”的增强回路。发现三:Claude Code 整合将系统能力边界从”任务响应”扩展到了”工程交付”。 这一整合的意义不仅是”多了一个工具”,而是打通了 Agent 系统的最后一段能力缺口——从分析建议到可验证产出的完整链路。对于工程场景,这改变了系统的定位:从”高级搜索引擎和代码建议器”到”可落地的工程执行者”。发现四:意图驱动与流程驱动是互补范式,而非替代关系。 演化 OpenClaw 与 Hermes 的核心差异——前者适应不确定性,后者消除不确定性——决定了各自的优势场景不同。未来的架构方向不是二选一,而是探索二者的融合路径。11.2 在更宽阔的视角下 下一代 Agent 平台的核心竞争力,正从”可调用的工具数量”转向”执行的可治理性、运行的可观测性与系统的可演化性”。 可治理性(governability) 意味着系统的行为在预设边界内,安全策略可配置、可执行、可审计。可观测性(observability)意味着系统的内部状态和决策过程对外部是可感知的——不是黑盒推理,而是有迹可循的执行链路。可演化性(evolvability) 意味着系统能利用自身的运行经验持续改进,其能力曲线不是平坦的,而是随时间上升的。这是一个工程现实主义的判断,而非技术乐观主义的宣言。当 Agent 系统从实验室走向生产环境,从个人助手走向组织基础设施,治理不是锦上添花——它是决定系统能否长期存续的基础前提。正如软件工程用半个世纪的时间建立了测试、CI/CD、监控、事故响应等一系列治理实践,Agent 工程现在也需要建立属于自身领域的治理体系。OpenClaw 的演化实践,是这个方向上的一个探索样本。 11.3 未来工作 基于本文的分析,以下几个方向值得在未来的工作中深入探索: 治理体系的自动化运维 :本文提出的治理架构需要持续的运维投入(策略维护、记忆清理、知识更新)。如何将运维工作本身也纳入自动化范围,降低治理体系的”持续成本”,是一个重要的工程问题。多范式融合架构的工程实现 :本文提出了”意图驱动-流程驱动”融合的可行性和方向,但具体的工程实现——包括任务特征识别、范式切换策略、融合架构的性能评估——需要进一步的研究和实验。治理成熟度的评估模型 :与软件工程的 CMMI 类似,Agent 系统的治理体系也需要一个成熟度模型,用于评估一个 Agent 系统在可治理性、可观测性和可演化性上的水平。长周期演化数据积累 :本文的分析基于中短期的演化实践,治理体系在更长周期(年)中的表现如何——是否会出现策略漂移、知识膨胀、学习退化等问题——需要持续的追踪和分析。参考文献 多智能体协作与编排相关文献(Multi-Agent Collaboration and Orchestration)。 Agent 记忆与检索增强相关文献(Agent Memory and Retrieval-Augmented Generation)。 工具调用安全与执行治理相关文献(Tool-Use Safety and Execution Governance)。 Hermes 技术文档与流程中心范式资料(Hermes Technical Documentation and Process-Centric Paradigm)。 Claude Code 与工程执行类 Agent 研究资料(Claude Code and Engineering Execution Agent Research)。 软件工程治理与持续改进方法论(Software Engineering Governance and Continuous Improvement)。 认知心理学中的记忆模型与组织学习理论(Memory Models in Cognitive Psychology and Organizational Learning Theory)。
 夜雨聆风
夜雨聆风