夜雨聆风
夜雨聆风





AI 失业论战升级:图灵奖得主 LeCun 批 CEO 们对技术革命一无所知!| 【近期发声全汇总】
近期社媒动态
Yann LeCun
扬 · 勒 昆
专 题
本篇全景汇总 Yann LeCun(2026年4月17日—4月28日期间)在 X 平台(原推特)上的精选高价值发文与论战 。

三大板块 · 可按兴趣垂直进入
🎯 第一部分 · 观点聚焦(建议优先阅读)
聚焦讨论:
「AI 末日论」、
「AI 替代劳动力」
—— 在这些话题上,该听谁的?
适合:对 AI 与就业、AI 行业话语权、AI 大佬之间立场分歧 感兴趣的人。
🔬 第二部分 · 技术极客:LeWM 世界模型(选择性阅读)
技术核心:深入拆解LeCun 新论文的关键创新(涉及 JEPA、世界模型、表征学习、生成式 AI 路线分歧等)。
(内容结构:论文技术核心解读 → Yann 转发的代表性技术评论原文 → 围绕技术展开的评论区思辨。)
适合:对 AI 技术原理、模型路线、未来范式变化感兴趣的入门者。
💡小提示:对技术细节不敏感的朋友,第二部分可直接跳过——这完全不影响你理解 LeCun 的核心价值观。
🔖 第三部分 · 纯转发(建议第二优先)
核心:精选 LeCun 近期 14 条 纯转发,涵盖 AI 末日论、AI 安全性、监管争议、科学政策、地缘政治等议题。
适合:对长期趋势、认知框架、技术与社会关系感兴趣的读者。
透过「他转发什么」进一步读懂他的思维方式与价值立场,也能帮你把前面的观点放进更大的坐标系里理解。
📖 推荐阅读顺序(最低认知负荷版)
先看第一部分 → 再看第三部分 → 按兴趣精读注释部分 → 第二部分按需阅读
1️⃣ 先读第一部分 — 进入语境,把握 LeCun当下最鲜明的态度
2️⃣ 再读第三部分 — 看他认可哪些声音,立体地理解社会趋势
3️⃣ 对感兴趣或有理解门槛的内容,回看注释精读 — 注释里藏着大量背景知识
4️⃣ 第二部分按需阅读 — 对技术不感兴趣者可直接跳过
下面,让我们一起跟随这位图灵奖科学家的视角,看清当下 AI 喧嚣之下,那些真正值得思考的问题。在这场高密度的信息碰撞中,重塑我们对 AI 时代的底层直觉。
第一类 · 智源先驱
理论基石与学术拓荒者











4 月 20 日至 26 日期间,Yann LeCun密集转发了多篇长文评论。这些评论均围绕他及其团队最新发布的重磅论文——
《LeWorldModel:从像素端到端的稳定联合嵌入预测架构》(简称LeWM)展开。
在「技术极客」第一部分,
我会先用尽量通俗、小白易懂的方式,
“两步走” 为大家拆解:
- ▸ 这篇论文讲什么?
- ▸ 其核心创新在哪?
- ▸ 它对 AI 行业可能带来什么改变?
然后「第二部分」——
我将 Yann 转发的几篇评论原文一字不漏地附在后面,
方便大家对“这篇论文的技术含义”
与“它在产业中激起的回响”
有一次从点到面、从概念到全局的真切理解。
( 我的目标是:
我的目标是:
让 AI技术小白们 梳理完第一部分生活化讲解 后 ——
能无障碍阅读第二部分长文评论。)
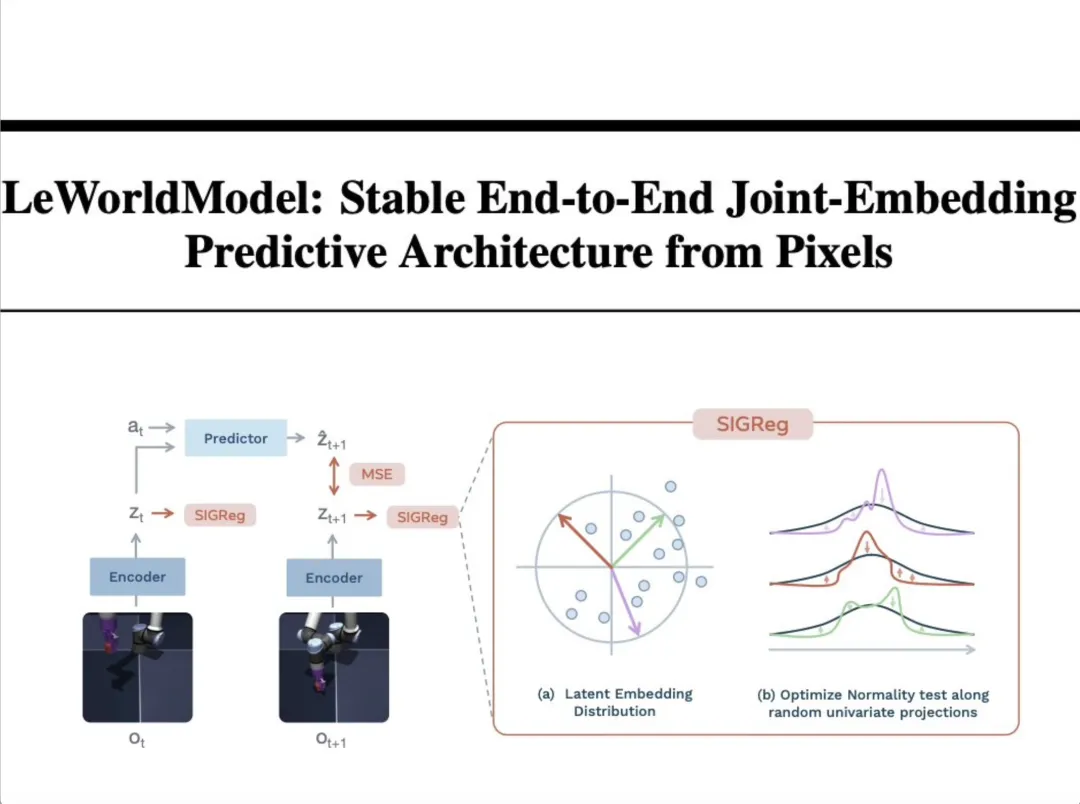
步骤1️⃣:先理解论文中的“流程图”——
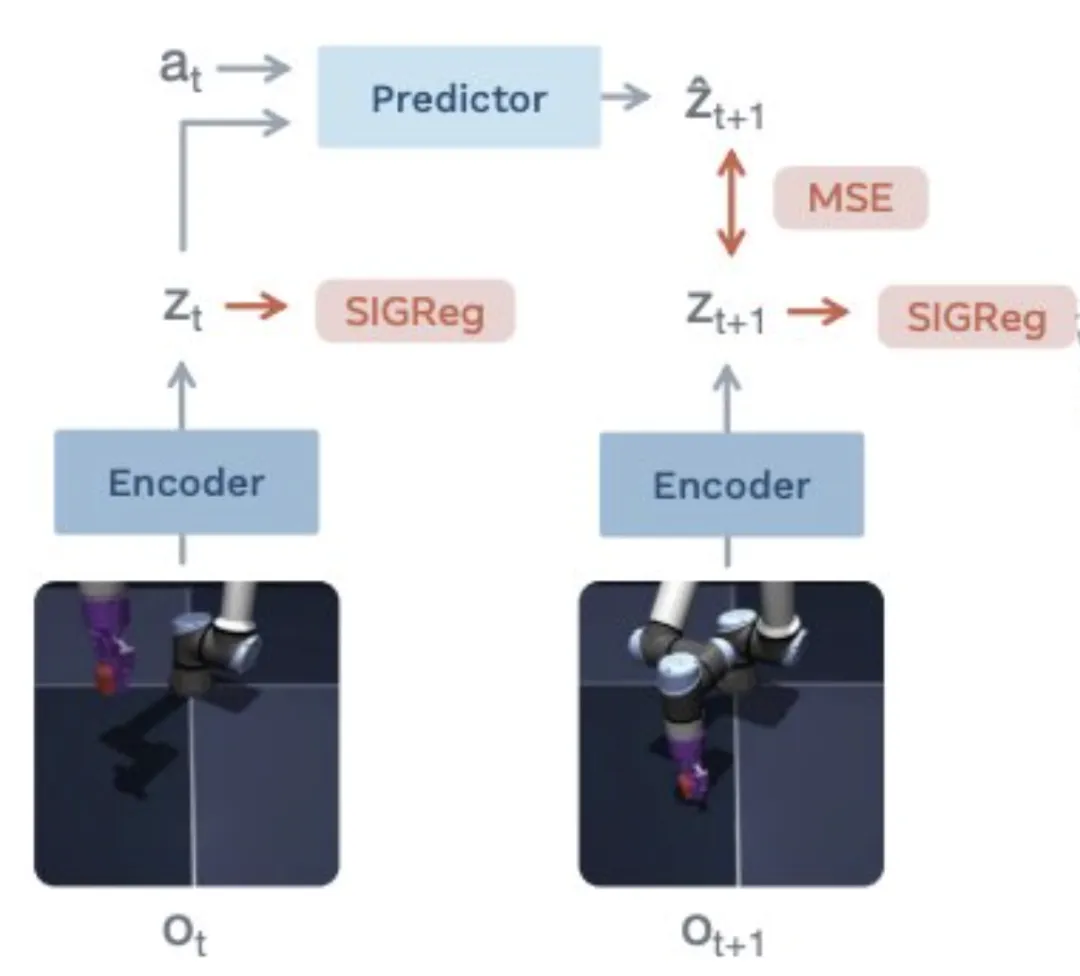
这部分展示了模型是如何”学习”世界的。
机器人”理解世界”的完整回路可以拆成:
⚙️
4 个主干步骤
+
1 个并行监督
- 第一步看(Observe)
机器人手臂在连续两个时刻拍到两张原始画面——当下这一帧ot,和下一帧ot+1。ot、ot+1:O是Observation的缩写,代表”观测”;t是time的缩写,代表”时刻”。用ot表示当下这一帧的原始像素图像,ot+1表示下一帧的原始图像。 - 第二步压(Encode)
它的任务是把复杂的图像“压缩”成简单的数学向量zt和zt+1。这就像是把一张高清照片简化成几个关键点(比如手臂的位置、物体的坐标)。1Encoder(编码器):负责执行这个”压缩”动作的神经网络模块——神经网络是一种模仿大脑神经元连接方式的计算结构,它靠海量数据训练出”看到什么输入就给出什么输出”的能力。举个例子:手机相册里的”人脸识别”就是一个通过海量数据训练出的神经网络模块——你喂它一张照片,它分辨后输出”这是狗”或”这是车”。2为什么叫”压缩”?(从冗余到精髓)想象一下,一张 1080P 的高清照片包含约 200 万个像素点。如果让 AI 直接去处理这 200 万个数字,计算量会爆炸。编码器(Encoder)像是一个极其老练的观察员,它扫一眼照片,只在笔记本上记下几个数字:[手臂角度: 45, 抓手状态: 开, 目标物坐标: (12, 35)]。这里的编码器也一样:你喂它一张机器人手臂的画面,它输出一串浓缩后的数字(zt),专门描述”手臂、物体现在在哪”。3zt、zt+1:Z是机器学习里常用来指代latent vector(潜变量 / 隐向量)的习惯字母;t依旧是time(时刻)。用zt表示当下这一帧压缩后得到的关键特征向量,用zt+1表示下一帧对应的特征向量。4“简单的数学向量zt“:(从视觉到语言)这里的”向量”其实就是一串数字。你可以把它理解为机器人眼中的”内部语言”。人类看图像:看到的是颜色和形状;AI 看向量:看到的是坐标和逻辑。zt:代表”现在的世界长什么样”;zt+1:代表”下一秒的世界长什么样”。通过把图像变成向量,AI 就不再是在”画图”,而是在做”数学预测”。在z的维度里,复杂的物理运动变成了数字的变化,这让计算变得极快。 - 第三步想(Predict)
这是”世界模型”的大脑。它根据当前的状况zt和动作at,去推测下一秒会发生什么,得到一个预测值ẑt+1。1Predictor(预测器):也是一段神经网络,可以类比成一个”物理直觉大脑”——它看完当前这一帧的压缩特征zt,再看一眼机器人在这一刻正在执行的动作at,就能”脑补”出下一帧应该长什么样,用ẑt+1(z 上面戴顶帽子 ^)表示。2at:a是action的缩写,代表”动作”;t是time(时刻)。at表示机器人在当下这一刻要执行的动作(比如”手向左移 3 厘米””抓手张开”)。 - 第四步核(Compare / MSE)
这是一个对比环节。模型会对比”它预测的情况ẑt+1“和”实际发生的情况zt+1“之间的差距。差距越小,说明模型对物理世界的理解越准确。1MSE(Mean Squared Error,均方误差):统计和机器学习里最常用的”差距测量尺“。2为什么要”对比”?这一步是 AI 学习的核心:先让 Predictor 猜一个ẑt+1,再看实际画面ot+1压缩后的zt+1,两者之间的差距(MSE)就是”它这一次猜错了多少”。AI 再根据这个差距反过来调整预测器(Predictor) 和 编码器(Encoder)的参数——猜得越准,模型越”懂物理”。 - 并行监督SIGReg
这是 LeCun 团队新加入的”监督员“,同时作用于zt和zt+1,防止模型偷懒。1SIGReg:是StochasticIsotropicGaussianRegularization 的缩写,直译为”随机各向同性高斯正则化”。”正则化”(Regularization)在机器学习里专指给模型加一个额外约束,逼它不走捷径、学得更扎实。2“偷懒”指什么?也叫”表征坍缩(Representation Collapse)“:压缩器(Encoder)如果图省事,可能把所有不同的图像都压缩成”几乎一样的z“——这样 MSE 表面上很小(预测和真实都差不多),但模型其实啥都没学到。SIGReg 的作用就是强制zt、zt+1的分布必须铺满整个”高斯云”(各向同性高斯分布)——可以把它想象成一个蓬松、均匀的立体”棉花球”:球心处点最密集,越往外越稀,而且从任何一个方向切开它,看到的形状都一样(这就是”各向同性”)。当 SIGReg 强制所有图片压缩出来的z必须均匀地散布在这个棉花球里时,编码器没法把两张不同的图挤到同一个点上——因为那样会破坏棉花球的均匀形状,SIGReg 立刻就会”报警”。于是编码器被逼着认真区分每一张图,给它们分配各自独立的位置(👇右图扩展说明SIGRrg)。
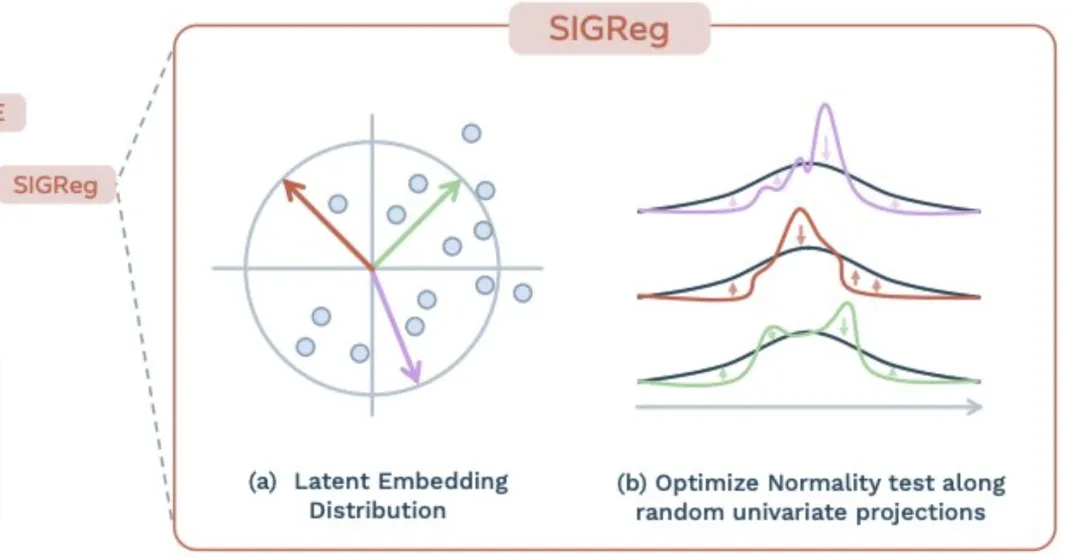
这是这篇论文最牛的地方。
在 AI 训练中,有一个经典问题叫“表征坍缩”(Representation Collapse)——简单说就是编码器为了省事,把所有不同的图像都映射成同一个简单的点。
为什么机器也图省事?
机器虽然没有“偷懒”的主观想法,但它受 梯度下降 驱动(一种让模型沿着误差减小的方向自动调整参数的方法),其 优化过程本质上是不断调整参数来降低损失函数(简单说,就是让模型的“误差分数”越小越好)。
最容易达到低损失的解往往是最“偷懒”的。
类似于:深谙“多做多错”的职场法则,于是自我训练出“不如少做”的处世逻辑。
如果把所有输入都输出成几乎一样的向量,模型就不需要学习复杂的特征提取逻辑——
既然分辨不准,干脆把所有图像都预测成它们的“平均值”。
这就像一个懒惰的考生发现:与其死记硬背,不如全选 C,这样虽然拿不到高分,但能以最快速度获得一个及格的“安全平均分”。
这样MSE 损失虽然很低,但模型变傻了。
SIGReg 就是为了解决这个问题。
- (a)Latent Embedding Distribution(隐嵌入分布)
图中的圆圈和散点代表数据在隐空间里的分布。SIGReg 的目标是让这些点不要聚成一团,而是像”高斯分布“(正态分布)一样,均匀且有规律地铺满空间。图中的彩色箭头代表不同的随机投影方向。 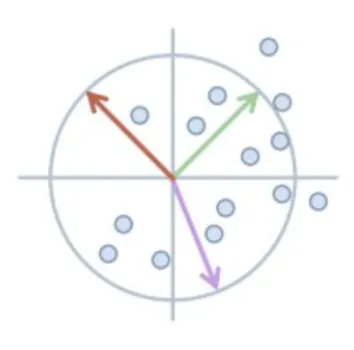
1什么是”隐空间”(Latent Space)? 隐空间是神经网络在内部用来表示数据的一个高维抽象空间。原始图像里有几十万个像素,信息又多又乱;编码器会把它们压缩成一组只有几百维的数字向量,每张图像都对应这个空间里的一个点。距离近的点意味着图像内容相似,距离远的则差别大——所以”隐空间”本质上是模型用来理解世界的”语义坐标系“。 数字图书馆比喻:可以把隐空间想象成一个巨大的、圆球形的数字图书馆——每一张原始图像(比如机械臂抓取的一个瞬间)被压缩后,就变成图书馆里的一个”书号”,对应书架上一个具体的位置。2散点和圆圈分别指什么? ·散点:每张图像压缩后的”书号”在图书馆里的位置。 ·圆圈:这个图书馆的理想边界(即 SIGReg 希望散点分布成的形状)。3彩色箭头 = 从不同角度”抽查” 在高维空间里,点长什么样很难直接看出来,所以用不同方向做抽查——比如红色箭头像”俯视看”,绿色像”侧面看”,紫色像”斜对角看”。 为什么必须多角度抽查?因为有的分布从正面看很散,从侧面看却缩成一条线——这也是一种坍缩。一次只看一个方向会被骗,所以要从随机多个方向都检查一遍。4“聚成一团” vs “均匀铺满” ·不加 SIGReg:几百万本书全堆在图书馆门口一小块地,位置”找得到”,但书与书之间完全分不开——这就是”坍缩”(聚成一团)。 ·加上 SIGReg(各向同性正则):强制要求无论从哪个角度(彩色箭头)看过去,这些点的排布都必须符合”中间密、边缘稀“的正态分布。”各向同性“意味着无论你从哪个角度(彩色箭头)看过去,这群散点的分布状态都符合“中间密、边缘稀”的正态分布,就像一个完美的球体,从任何方向看它的投影都是圆形。5通俗比喻:【操场上的早操方阵】 想象全校学生(数据点)在操场(隐空间)上站位—— ·没有 SIGReg:学生为了省事全挤在主席台下面,老师(模型)看过去黑压压一片,分不清谁是谁。 ·SIGReg 的彩色箭头:几个巡察老师站在操场四周不同位置。 ·SIGReg 的要求:”无论我从正前方看,还是从侧面围墙看,你们必须站成一个圆形的、有疏密节奏的方阵,不准聚堆!” ·结果:学生们为了满足”从任何角度看都要站得有规矩”的要求,不得不互相拉开距离,找到自己独特的位置。 结论:彩色箭头(随机投影)就是用来全方位监测有没有在”搞小团体”——只要强制每个方向的投影都符合高斯分布,这些点就必须铺满整个空间,把不同图像的特征拉开、区分出来。
- (b)Optimize Normality test along random univariate projections(沿随机单变量投影优化正态性检验)
图中的彩色波浪线代表实际的数据分布,黑色曲线是理想的正态分布。小箭头代表优化的方向:如果实际分布太尖了或者偏了,算法就会把它”推”向黑色曲线。 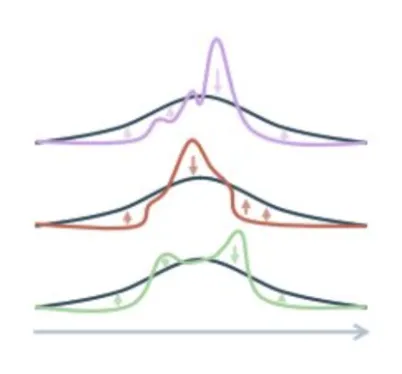
1Univariate projections(单变量投影):把高维的数据点投影到一根线(一维)上。2Normality test(正态性检验):检查这些投影出来的点是否符合正态分布(那条黑色的平滑曲线)。3为什么要这么做?如果数据在所有方向上的投影都符合正态分布,那么数据整体就符合各向同性的高斯分布。这样能保证模型学到的信息既丰富又稳定,不会产生”坍缩”。
左图告诉我们:模型通过“看图 → 预测动作后果 → 对比实际结果”来学习物理规律。
右图告诉我们:LeCun 发现了一种极其简单且优雅的数学方法(SIGReg),只需要确保数据分布长得像个“高斯分布”,就能让模型在不需要昂贵的预训练和复杂调参的情况下,稳定地学会理解世界。
步骤2️⃣:理解论文“标题”:
理解完上面所有概念后,最后再来看这篇论文的题目《LeWorldModel:Stable End-to-End Joint-Embedding Predictive Architecture from Pixels》(译:《LeWorldModel:从像素端到端的稳定联合嵌入预测架构》)——
-
1LeWorldModel(Le 世界模型) LeCun 团队给这个模型起的绰号。”Le“既是 LeCun 的姓氏缩写,同时呼应了他在 2022 年提出的“世界模型(World Model)”愿景。 -
2Stable End-to-End(稳定的端到端) 稳定:表示其训练过程不容易崩溃。 -
End-to-End(端到端)意味着从”原始像素输入”到”最后动作输出”,中间不需要任何人工辅助。 -
3Joint-Embedding Predictive Architecture(联合嵌入预测架构,简称 JEPA ) 不追求生成一张逼真的高清图,而是把图像和预测都变成一串”数学向量“(嵌入),通过预测下一秒会发生什么来理解世界的运行法则。 -
4From Pixels(基于像素) 证明模型不需要别人教它”这是手”、”这是杯子”,能直接从杂乱的像素点里自己悟出物理结构。
Yann LeCun 十余年押注的JEPA①路线,长期被批”理论漂亮但工程跑不动“——表征坍塌、需堆补丁、超参难调是业内反复提出的质疑。
LeWM 第一次让 JEPA 做到”从原始像素端到端跑通 + 小模型 + 快规划 + 懂物理“的工程实验交付。
🏅具体成果如下——
- 15M 参数
整个模型只有1500 万个参数,不到 GPT-3 的万分之一(GPT-3 为 175B)。大小相当于一张高清照片的文件体积。 - 1 GPU · 几小时
只需要一张普通 GPU(非 H100 集群)训练几个小时即可收敛。作为对比,训练一次大语言模型通常需要上千张 GPU、数周时间、烧掉数百万美元电费。1H100 集群:H100 是英伟达目前最顶级的 AI 训练显卡(单张约 25 万人民币),大模型公司通常要把几百到几千张 H100 串联起来组成”集群”才能训练 GPT、Llama 这类大模型。”非 H100 集群”意思是一张普通的消费级或上一代 GPU 就够用——成本差了几百倍。2收敛(Convergence):指模型在训练过程中,损失函数(预测误差)不断下降,最终稳定在一个低值不再明显变化的状态——也就是”学会了、训练完成了”。不收敛的模型就像学生怎么复习都考不及格,卡在高错误率上下不来;收敛快则意味着用很少的时间和数据就把这门课学明白了。 - 48× 规划提速
在 Push-T、3D 方块等机器人控制任务上,达到或超越基础模型性能的速度快了 48 倍。意味着原本机器人想一步要 47 秒,现在只需不到 1 秒。1Push-T:机器人领域最经典的二维推物块基准任务——桌面上放一个 T 字形物块,机器人需要用一个小圆柱把它推到指定位置和角度。看似简单,但 T 形边角多、推偏一点就翻转,非常考验模型对”接触面摩擦 + 物体受力后怎么动”的物理直觉。23D 方块(3D Cube Control):升级到三维场景的方块操控任务——机器臂要抓取、搬运、堆叠立方体。比 Push-T 多出一个维度,涉及抓握力度、重力、碰撞、堆叠稳定性等复杂物理关系,是评估“机器人是否真懂三维物理世界”的标准考题。3这两个任务是学界公认的”机器人世界模型能力试金石“——能在这两个任务上打败对手,基本等于证明模型真的学到了物理规律,而不是在死记硬背动作。 - 200× 数据减少
每份观测数据的Token 消耗比 DINO-WM 少 200 倍。Token 是模型处理信息的最小单位,少 200 倍意味着同样的训练数据能喂出 200 倍更高效的模型。1DINO-WM(DINO World Model):Meta 出品的另一条世界模型路线,基于DINO 视觉编码器(一个已经预训练好的图像特征提取器)搭建。它是 LeWM 直接对标的参照基线——学界和业界普遍把它当作”当前最强的世界模型之一“来对比。2为什么拿 DINO-WM 作对比?因为 DINO-WM 代表了“借助强大预训练编码器”这条传统思路的最好水平。LeWM 从原始像素端到端训练,没有用任何预训练权重却打赢了 DINO-WM——相当于新手一张白纸击败了拿着祖传秘籍的高手。 - 47s → 0.98s
单步规划耗时从47 秒压缩到 0.98 秒。机器人抓取、推动、避障等动作,从”卡顿思考“变成”近乎实时反应“——这是能否真正落地到工厂和家庭的门槛。 - 6 → 1
过去 JEPA 需要手动调6 个损失项 + 超参数(梯度停止、EMA、预训练编码器等”工程补丁”)才能不坍缩;LeWM 用单一 SIGReg 正则项一次性取代了所有这些,超参数搜索从 O(n⁶) 简化到 O(log n)——从”几乎不可调”变成”几十次试验即可”。1梯度停止、EMA、预训练编码器:所谓的”工程补丁”在 LeCun 看来,以前为了让 AI 模型不坍缩(不偷懒),工程师们不得不给模型打上一堆“补丁”。这就像是一个学步的孩子(模型)站不稳,你得给他加各种辅助工具:·预训练编码器(Pre-trained Encoder):给模型一个”外挂大脑”。直接拿别人训练好的现成模型来用,而不是让它自己从零学习。·EMA(指数移动平均):给模型装一个”稳定器”。让模型在更新时不要”急转弯”,而是参考一下之前的状态,平滑地过渡。·梯度停止(Stop-gradient):强行”堵住”某些知识流向,不让某些部分参与计算,防止它们把整个模型带偏。LeCun 的观点:这些都是“歪门邪道”,是因为你底层数学逻辑没设计好才需要的。LeWM 甩掉了这些拐杖,直接通过 SIGReg 站稳。2超参数(Hyperparameters):模型的”调节旋钮”如果把 AI 模型比作一台复杂的收音机,超参数就是面板上需要人手去拧的”旋钮”。·普通参数:是模型在训练过程中自己学会的(比如认出猫的胡须)。·超参数:是工程师在训练前必须手动设定的(比如:学习速度要多快?每一批处理多少数据?正则化的力度多大?)。论文价值:以往的方法有 6 个旋钮(超参数),只要有一个拧不对,模型就练废了;而 LeWM 简化到了 1 个旋钮。相当于从”手动挡”变成了”自动挡”,极大地降低了调试的难度。3O(n⁶) 简化到 O(log n):效率的”降维打击”这是计算机科学中描述算法复杂度(即随着任务变大,计算量增长有多快)的符号。·O(n⁶)(指数级爆炸式增长):如果任务难度(n)增加 2 倍,计算量就会增加 2⁶(64 倍)。这很容易”暴力计算”,当数据量稍大时,电脑就会卡死或烧掉。·O(log n)(对数级增长):这是一种近乎平坦的增长。即使任务规模(n)增加 1000 倍,计算量也仅增加约 10 倍。用一个例子理解:·O(n⁶):就像是在几百万本书的图书馆里,对每一本书都进行极其复杂的交叉比对和计算)。书的数量越多,工作量会以六次方的速度爆炸式增长。·O(log n):就像是在玩”猜数字”游戏,每次都从中间切一半排除掉错误选项。即使数字范围从 1 万扩大到 1 亿,多猜几次也就出答案了。





🐦LeWorldModel:从像素学物理——只用两个损失函数的稳定世界模型 三条主流世界模型路线: 1️⃣DINO-WM:用预训练好的 ViT 编码器(来自 ImageNet)→ 提特征 → 接预测器。但编码器是冻结的,没法端到端学习。它的”视觉基因”是为粗分类(猫 vs 狗)调出来的,不是为物理调的——难以分辨毫米级变化(比如 2 毫米的方块位移)。在一个”近视眼”编码器上面套再强的预测器,等于瞎子做物理推理。 2️⃣PLDM:能端到端,但训练不稳定、容易坍缩。它把”奖励”当作预测目标,所以只能在有明确奖励的环境(比如游戏)里用。 3️⃣JEPA(联合嵌入预测架构):预测下一时刻的隐向量,而不是预测像素。但有两个老大难问题: ·表征坍缩(编码器把所有输入都映射成同一个常向量,比如全 0) ·想同时做到”基于像素 + 端到端 + 稳定”几乎不可能 💡LeWM 解决了什么: 👉 让 JEPA 真正能从原始像素稳定地端到端训练 👉 只需一个超参 λ: · 下一帧嵌入预测损失 · SIGReg(高斯正则化) 🧠#1:真正的端到端 没有冻结的编码器。感知 + 动力学一起进化 → 学到的表征和细粒度物理对齐,而不是和 ImageNet 偏见对齐。 🧠#2:”只”一个超参数 PLDM 需要调 6 个。LeWM 只需要 1 个(λ)→ SIGReg 的权重。即插即用,训练稳定。 ⚠️坍缩问题 编码器可能把所有输入都映射成同一个向量 → 预测变得平凡 → 损失为零 → 模型废了。 🧩SIGReg(高斯积分签名正则化) 核心思路:通过分布约束防止坍缩。 · 随机采样 1024 个方向 · 把嵌入投影成 1024 条一维”影子” · 每条必须通过 Epps–Pulley 检验 (近似标准正态) · 损失推动检验统计量 → 0 · 只要有一个方向不达标 ⇒ 惩罚 为什么这样做有效: Cramér–Wold 定理 → 一个高维分布完全由它在所有一维方向上的投影决定。 👉 强制每个一维投影都是高斯,就能在投影约束下排除一切退化型坍缩 🧪物理探针实验 在 PushT(把方块推到目标位置)任务上训练,然后: 用 线性探针 就能从隐向量里还原出:方块位置、角度、末端执行器位置 👉 物理信息可以被线性解码 🚨 把方块”瞬移”到不合理的位置(违反物理): · 嵌入的异常分数瞬间飙升 👉 模型把”物体不能瞬移”这条约束内化了 👉 这不是从像素表层特征推出来的,而是作为隐空间约束编码进去的 📈时间一致性(轨迹直度) 没加任何平滑损失,但隐空间里的轨迹却近似直线 👉 没有先验,纯粹来自“预测下一个嵌入”这一个目标 👉 说明模型学到的是物理一致的运动,而不是模糊插值 ⚡性能 · 规划耗时:0.98 秒 vs DINO-WM 的 47 秒 · 成功率:96% vs PLDM 的 78% 为什么更快? · DINO-WM:编码器冻结 → 信息损失 → 还要额外在线推理几遍 · LeWM:端到端 → 表征本身就跟任务对齐了 👉 0.98 秒意味着足够快到应对动态障碍和实时控制
想象你雇了个图书管理员(编码器)整理一屋子书。你想测试他整理得好不好。
线性探针 ≈ 你派一个完全不懂书的实习生进去,告诉他:”桌子最左边那一摞就是历史书。” 如果实习生按这个简单规则就能准确找到所有历史书,说明管理员真的把书按类别摆好了。
非线性探针(比如多层 MLP)≈ 你派一个很聪明的研究生进去自己摸索。他可能也能找到历史书,但你不知道是因为管理员整理得好,还是研究生自己太聪明硬找出来的。
研究者用线性探针,就是为了把”探针的功劳”压到最低,让结果反映的纯粹是编码器的质量。
6️⃣ OGBench-Cube:一个机器人物理推理的基准测试集(benchmark),物理复杂度比 PushT(推方块)更高,它的核心任务通常是要求一个机械臂(或虚拟智能体)在三维空间中对立方体(Cube)进行精准的抓取、推移、堆叠或旋转等。LeWM 在 PushT 上表现优异,但参数量只有 ~15M(”蚂蚁规模”),所以在 OGBench-Cube 这种更难的场景上”还做不动”——这是论文坦诚的局限之一。

 “说到底,如果你真想造出一个具备——哪怕只是猫的智力水平,更不用说达到人类智力水平的系统,你都需要常识。你需要能够预测自己行为的后果的能力。 你需要具备规划的能力。你需要具备推理的能力。 而这些能力,你是无法通过 VLA(视觉-语言-动作模型)、VLM(视觉语言模型)、LLM(大语言模型)或者任何生成式架构获得的。”
“说到底,如果你真想造出一个具备——哪怕只是猫的智力水平,更不用说达到人类智力水平的系统,你都需要常识。你需要能够预测自己行为的后果的能力。 你需要具备规划的能力。你需要具备推理的能力。 而这些能力,你是无法通过 VLA(视觉-语言-动作模型)、VLM(视觉语言模型)、LLM(大语言模型)或者任何生成式架构获得的。”

 画面下方标题:“LLMs are hitting a wall.“(LLM 撞墙了),署名Benjamin Todd。
画面下方标题:“LLMs are hitting a wall.“(LLM 撞墙了),署名Benjamin Todd。


▸这三个模型都属于自监督或对比学习范畴,但侧重点不同:
-
MAE:重点是视觉表示学习(重建像素) -
VAE:重点是生成新数据(概率建模) -
CLIP:重点是视觉-语言对齐(跨模态理解) NIPS(2018年起更名为NeurIPS):神经信息处理系统大会(Neural Information Processing Systems),机器学习、人工智能和计算神经科学领域最顶尖的国际学术会议之一。
 画面下方标题:”See what world models can do!“(看看世界模型能做到什么!)。
画面下方标题:”See what world models can do!“(看看世界模型能做到什么!)。

我想说的是,大语言模型(LLM)目前主要掌握在工业界手中,很大程度是一项工程技术,而且需要极其庞大的计算资源,学术界很难做出实质性的贡献。
更重要的是,LLM 是当下的技术。学术研究者,尤其是博士生,应该致力于研发下一代技术,即下一个范式。

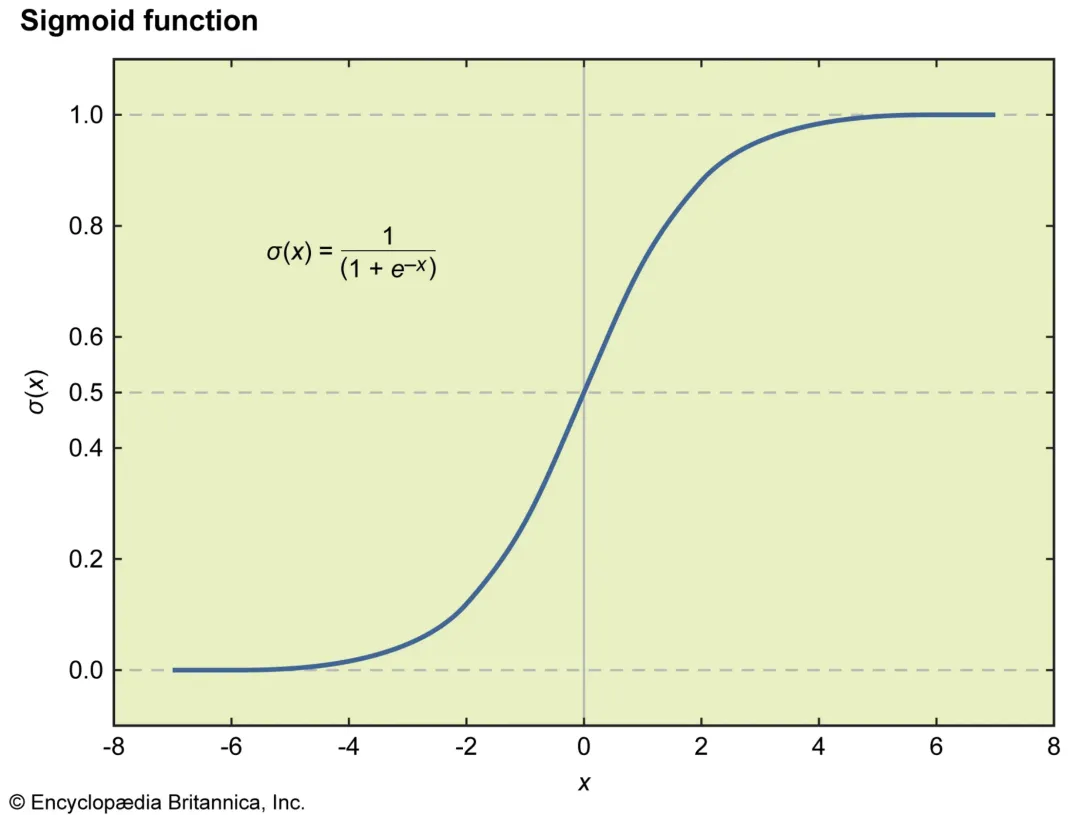
【Sigmoid 曲线的特点是:前期缓慢 → 中期快速指数式增长 → 后期逐渐放缓并趋于饱和。】


比如:一张猫的图片 → 编码成一个向量点;
一句 “一只可爱的橘色小猫坐在沙发上” → 编码成另一个向量点。
如果模型学得足够好,这两个向量点在这个空间里就会离得很近,离”狗”稍远,离”飞机”非常远。
▸ 怎么训练出来的?
然后训练目标是:让配对的图文向量在空间里靠近,让不配对的图文向量在空间里远离(即对比学习)。训练完之后,你给它一张从没见过的小狗照片,它能把这张照片编码成一个向量,而这个向量恰好会非常接近”一只狗”这句话的向量——所以模型”认出”了狗。达成的结果就是:它能通过文字“理解”图像,也能用图像“解释”文字。
▸LeCun 的论据:“坐标重合”不等于“逻辑理解”。这种架构学到的是”图像表面特征”和”文字标签”的统计关联,而不是物理世界的因果模型。即:它学的是相关性(哪些像素模式经常和哪些词共现),而不是因果性(物体之间的物理作用)。
总的来说,LeCun 认为下一代 AI 必须能预测世界状态的变化,而不只是匹配静态的图文对。

我不明白为什么我们要自动给那些所谓的”真诚观点”加分。
说真的,谁在乎啊?
如果我真心实意地认为一场”跨维度吸血鬼攻击”迫在眉睫,难道仅仅因为我对这种该死的妄想表现得足够真诚,这观点就变得理智了吗?
那个往萨姆·奥特曼(Sam Altman)家扔汽油弹的家伙,大概在他的妄想里也是极其”真诚”的。他在试图解决一个虚构的未来问题,代价是在真实世界里制造一个真问题。
历史上多的是在妄想中保持”真诚”的人。查理·曼森(连环杀手)很真诚。马克思、戈培尔以及历史上所有判断错误的人,在当时也都真诚。
这就是人类史——满眼妄念(Maya)。
在判断一个人的主张或预测是否正确时,”真诚”的参考价值绝对为零。
另一方面,我们也过度迷信——”某人在某领域工作,所以他一定能预测该领域的未来。”
凭什么?
如果我是一个造桥工程师,我怎么会知道桥梁在未来会如何影响社会?
答案是:我不知道。我只管修桥。
我预测了关于桥梁的事情,这一事实根本无关紧要,因为”造桥”和”预测未来”这两种技能完全不重合。
我也许拥有很强的预测未来的能力,但这种能力与我是否在这个领域工作完全、彻底无关。
事实是,我们大多数人对未来的预测纯属扯淡。
人类在长期预测方面,普遍做得烂透了。
如果你生活在 1440 年的德国,并对德国社会的未来做出预测,你注定会出错。因为你预测不到印刷术的出现,也预判不了它将如何改变社会的结构和轨迹。
我们默认给了太多人、太多能力去准确预测任何事情,这简直是过度授信。
只有极少数人擅长预测,绝大多数人对此都烂透了。
想知道为什么大语言模型(LLM)在表面语义上看起来很犀利,但在精细颗粒度的内容上却显得空洞吗?
论文:《From Tokens to Thoughts: How LLMs and Humans Trade Compression for Meaning》(《从 Token 到思想:LLM 与人类如何在”压缩”与”意义”之间取舍》)

我们认为原因在于:LLM 过度压缩了。人类会因为细微差别(nuance)而保留一些”低效”的概念;而 LLM 为了更干净、更符合信息论意义上的压缩,会丢弃这些差别。不同的优化目标,会产生不同的表征。
我们用“信息瓶颈“(Information Bottleneck)的视角分析了 40+ 个模型,还发现:编码器(encoder)在与人类对齐方面,往往比比它大几倍的解码器(decoder)做得更好;并且在训练过程中,语义处理会从深层迁移到中层网络——因为模型逐渐学会了更稀疏的编码方式。
“与人类对齐”:这里的”对齐”不是价值观对齐,而是指概念表征的对齐——也就是:模型脑子里”猫”这个概念的内部向量,和人类对”猫”的认知结构有多像?
为什么”编码器做得更好?”:正是因为上面训练目标的差异 —— 编码器的目标,如 BERT 的 MLM,需要随机遮住一些词,让模型猜。比如”小猫在喝***(遮住部分)”——要猜出”牛奶”。这个任务强迫模型把每个词的语义信息浓缩进它的向量表征,因为下游任务(分类、检索)需要直接读这些向量。表征本身就是产品。解码器的目标,是预测下一个词。这个任务只要求模型最后一层能输出正确的概率分布,中间表征长什么样无所谓——只要最后能算出”下一个词是 X”就行。表征只是手段,不是产品。
比如一个 70 层的 Transformer,信息从第 1 层流到第 70 层。研究者发现一个普遍规律:
- 浅层(前几层):处理词法、句法、表层模式(”这是个名词”、”主谓一致”)
- 中层:处理语义、概念关系(”猫和狗都是宠物”)
- 深层(最后几层):处理任务相关的输出格式(”下一个 token 应该是什么”)“Transformer” 这个词在 AI 语境里特指一种神经网络架构,它的核心操作是把一组向量”变换”成另一组向量——输入一段文字的向量表示,输出一段被理解过的、富含上下文信息的向量表示。现在所有主流大模型(GPT、Claude、Llama、BERT、Gemini……)的底层架构都是 Transformer 或它的变体。 再理解:信息怎么在层之间流动——
可以想象成一条流水线:输入”小猫在喝牛奶” → 第 1 层(识别这些是名词、动词)→ 第 2 层(开始组合:’小猫’是主语)→ … → 第 35 层(理解整句的语义:这是一个动物进食的场景)→ … → 第 70 层(准备输出:下一个词应该是句号 / “。”)。每过一层,向量里携带的信息就更”高级”一点。
最后,理解“语义处理从深层迁移到中层网络”——
-
前期:模型刚开始学,很笨,它需要动用所有层级(尤其是最后的深层)去死记硬背数据里的每一个细节。
-
后期:随着训练进行,模型找到了规律。它发现只要在中间层通过一些关键特征就能锁定语义了。
这说明,模型不再需要到最后一刻才思考,而是在信息处理的一半时,就已经通过稀疏编码(只动用最关键的神经元)锁定了核心意义。这说明模型学会了高效的抽象。
▸ 什么是“稀疏编码”:
-
稠密 (Dense) = 笨: 每个神经元都在乱动,试图记住所有细节。
-
稀疏 (Sparse) = 灵: 只有几个神经元亮起,但它们精准地击中了事物的本质。
总的来说,通过训练,模型变聪明了,学会了‘抓重点’(稀疏编码),所以它在处理信息的一半时就能‘秒懂’语义(从中层截获),而不需要像新手那样费劲地推导到最后。
《信息瓶颈》播客新一期上线,这次嘉宾是普林斯顿的 @liuzhuang1234。
我们聊了:
ConvNeXt 与“架构是否还重要”
数据集偏差 和“什么才算好数据”
ImageBind 与 “为什么视觉是跨模态的天然桥梁”
CLIP 的盲区
记忆——智能体热潮背后真正的瓶颈
LLM 是否拥有世界模型
以及 无归一化的 Transformer
视觉社区争论了多年:架构、归纳偏置、self-attention vs 卷积,到底哪个才重要。一番来回之后,我们落到了一个尴尬的位置:ViT 和 ConvNet 调好之后表现差不多。
我觉得有意思的是——
一旦达到某个性能水平,更换、调整组件就变得很容易,而结果几乎不变。
跟 Zhuang 聊这一期时,我一直在想:LLM 现在是不是也一样了?如果今天我们认真投入做一个替代架构,结果会得到一个本质不同的模型,还是只是绕一圈又落回同一条Pareto 曲线上?
我开始怀疑是后者。
架构远没有我们以为的那么重要。
数据、算力,加上几根关键支柱,做了大部分活。
因压制 AI 而死的人,会比因”想象中的 AI 末日”死的人更多。
他们会死于——被限制上路的自动驾驶汽车:这些车比人类司机安全 90%。
他们会死于——那些永远造不出来的疫苗和疗法。
他们会死于——本可预防的疾病;死于一个被减速的经济。
还会有人以”狂热分子”的身份死去——因为“反 AI 运动”正在激进化他们的追随者,怂恿其开枪伤人、投掷汽油弹。
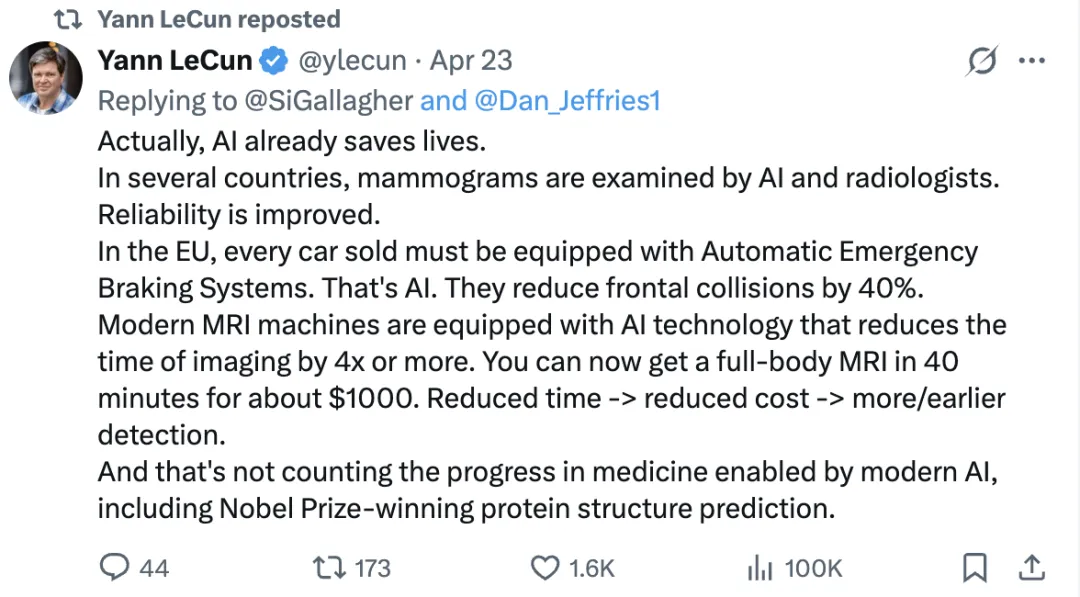
实际上,AI 已经在拯救生命了。
在多个国家,乳腺 X 光筛查已经由 AI 与放射科医生联合判读,可靠性显著提升。
在欧盟,每一辆出售的新车都必须配备自动紧急制动系统(AEB)——这就是 AI。它能将正面碰撞事故减少 40%。
现代 MRI 机器(MRI-Magnetic Resonance Imaging,磁共振成像)都搭载了 AI 技术,将成像时间缩短了 4 倍甚至更多。这还没把现代 AI 推动的医学进步算进来——包括获得诺贝尔奖的蛋白质结构预测(指 AlphaFold)。
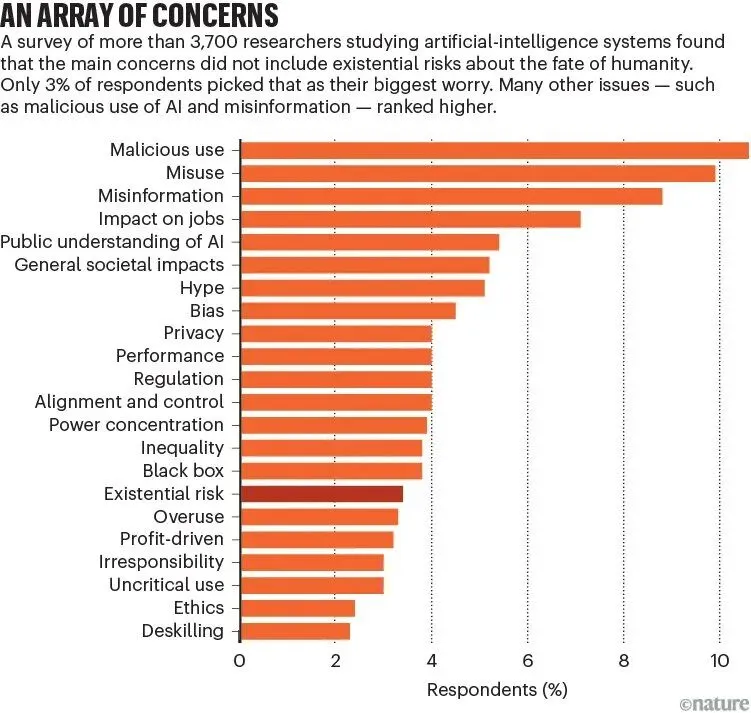
「关于 AI,最让你担忧的一件事是什么?」
在一项3,700 名 AI 研究者的调查里,只有 3% 的人把存在性风险列为最担忧的问题——尽管”媒体上对这些风险的渲染如此之大”。更多的研究者更担心恶意使用、错误信息、就业冲击、偏见等。
注:上图为原版(英文),下图为对照中译版。
“生存风险”论者(Existential risk mongers)是一个人数虽少、但嗓门极大的“邪教”组织,他们拥有极其高明的网络“草根营销”(astroturfing)技巧。
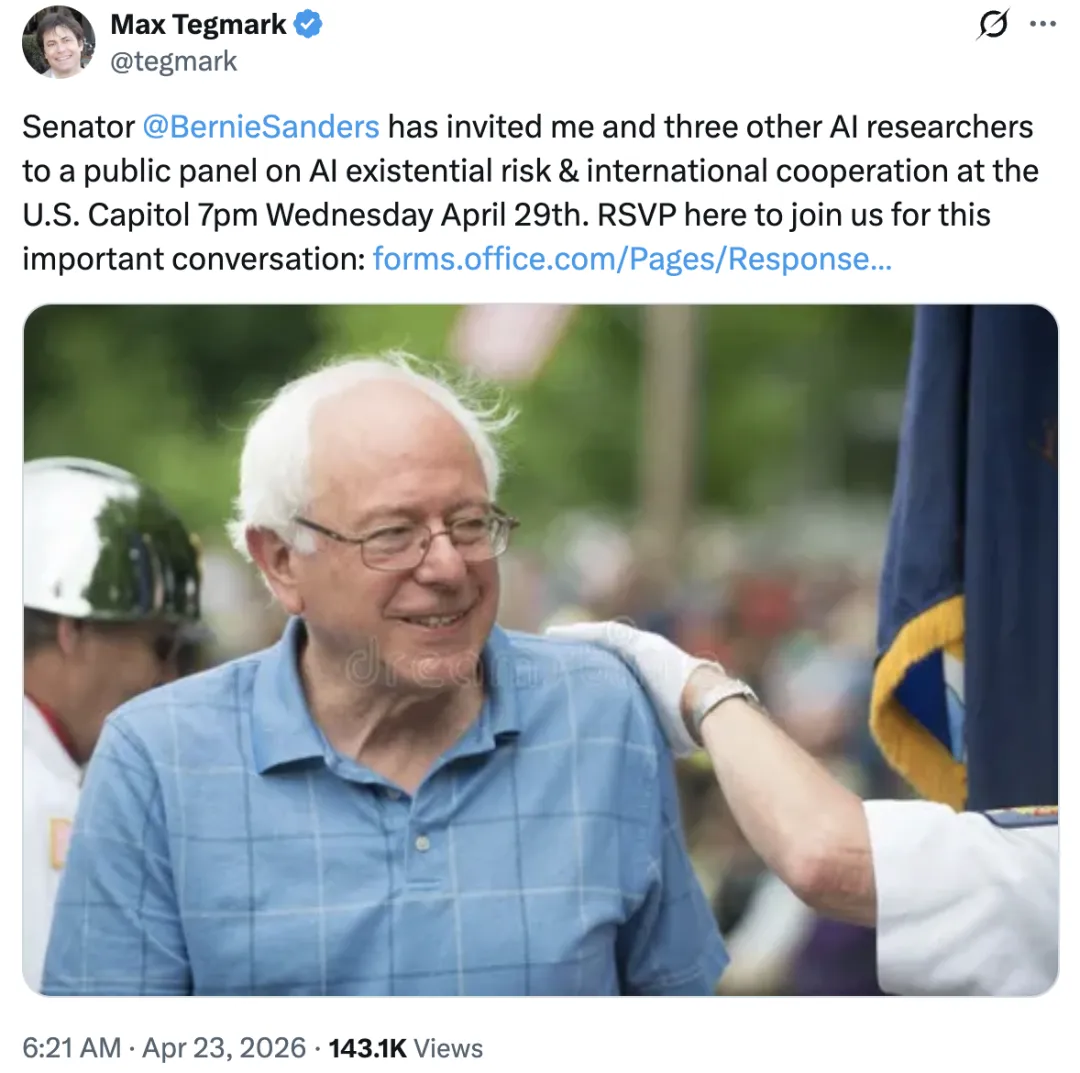
政客们从来不会放过任何一个绝佳的虚假危机,这正是为什么这种危机成了伯尼(指伯尼·桑德斯)试图从私有领域夺回生产资料控制权的完美借口。
想象一下,如果在 1997 年,有主流政客把“天堂之门”(Heaven’s Gate,美国著名的自杀邪教)请上政治舞台会怎样?
这就是当今美国政治边缘化的现状。
我们已经陷入了荒诞的深渊(jumped the shark),完全脱离了美国当下的现实主线。
而导致这种疯狂的并非 AI,而是人类那种老掉牙的幻觉、编故事能力和妄想症。
社会永远不该针对那些在现实中毫无依据的、虚幻的未来威胁制定政策。AI 已被数十亿人使用,它与人们想象的样子截然不同——我们现在都还活得好好的,而且即便按以往科技革命的标准衡量,AI 产生的问题也少得离谱。
如果我告诉你有一种技术每年会导致150 万人死亡、5000 万人受伤,你会支持这种技术吗?答案是肯定的,因为那就是汽车。你今天可能就坐过车,接受了这种风险,甚至连想都没想过。
相比之下,因 AI 而死亡或受伤的人数比例极其微小,甚至连那些案例充其量也只是似是而非。
事实上,AI 已经挽救了无数生命。它通过辅助研发新冠和流感疫苗,在药物发现领域救人无数;它通过防抱死制动系统(ABS)救人;它通过比人类驾驶员安全 10 倍的自动驾驶汽车救人——然而,你在新闻里读到的关于自动驾驶的唯一内容,却是那些极其罕见的撞了条狗或伤了人的故事。
如果这听起来很不理智、很疯狂,那是因为事实确实如此。
我们竟然在担心一种拥有近乎完美安全记录的技术,却对一种每天都在杀人的技术安之若素?
欢迎来到人类大脑的非理性世界!
如果那些叫嚣“暂停 AI”的邪教徒得逞了,我们现在还会困在 GPT-2 那个满口胡言的烂摊子里,根本无法取得如今这种更加稳健、高度对齐、既聪明又实用的模型进展。
这是因为,你不可能靠在脑子里空想,或者在Less Wrong论坛上给其他“精神自嗨者”写几篇愚蠢的文章就能取得进步。
解决现实世界中的问题,必须依靠不断尝试与纠错(trial and error)。
让 AI 变得安全的唯一途径,就是在现实世界中去建造它、迭代它。
别无他法。
人工智能(AI)经历了史上安全性最高的科技推广过程之一。
请再读一遍,因为这是事实。
它正被数十亿人使用,而实际出现问题的比例仅占极小的百分比。
然而,在许多人眼中,它依然被视为危险或不安全的。
不断有一群人大声疾呼它所谓的危险,但在最关键的地方——现实世界里——他们却拿不出任何证据。
那么,现实中到底发生了什么?
法庭上只有寥寥几起关于早期版本 ChatGPT 的诉讼,指控它过于谄媚、未能识别心理疾病或求助信号。这些案件仍在审理中,结果尚未定论(媒体披露的一些片段虽有负面影响,但并非定论)。
时间会证明一切。在被证明有罪之前,它是无罪的。诉讼的本质往往是寻找替罪羊,而这些指控在实际审理过程中经常会被驳回。
但除此之外,还有什么?
答案是:没多少。
如果透过历史上其他技术的镜头来看,AI 的事故率可能比割草机还要低。
当你联想到汽车和飞机等其他技术时,这种担忧就更显得毫无道理——这些技术早期的安全记录简直惨不忍睹。
AI 的安全记录甚至比核能还要好。
尽管核能总体上非常安全,但它也发生过三哩岛和福岛等举世震惊的严重事故。
而 AI 呢?完全没有发生过类似的事情,甚至边儿都沾不上。
我现在就能听到反对者在说:”那只是目前,走着瞧吧!“
然而,我们等了一等,再等一等。
对 AI 的恐惧是一种生命力极其顽强的怪兽。
尽管在”现实领地”中几乎从未出现过真正的伤害,这种恐惧依然挥之不去。
自动驾驶汽车显然比人类驾驶更安全。全球每年因人类驾驶导致120 万人死亡、500 万人受伤。
Waymo自动驾驶汽车的安全性大约是人类的10 倍,伤亡率极低。即便早期的自动驾驶汽车,其安全记录也远好于早期由人类驾驶的汽车——人类驾驶的糟糕记录甚至一直持续到 20 世纪 50 和 60 年代。
说到汽车,社会实际上曾抵制过让它变得更安全。人们因为要付钱而反对系安全带,他们曾将早期的酒驾法律视为对自由的侵害。
早期的飞机旅行极度危险。我们花了数十年时间才将其打造成为今天的安全奇迹。
那么工作岗位呢?
虽然 AI 高管们在谈论”工作的终结”,但他们却在被认为风险最高的职业——程序员——中招募更多人才,且起薪往往高达 50 万美元。
对优秀程序员的需求正在上升。
确实有高管声称因为 AI 而裁员。但深入观察会发现,这大多只是规避劳动法或讨好股东的借口,更多应归因于疫情期间的过度招聘。
告诉股东裁员是因为”AI”,你会被奖励”提高了效率”;如果说是因为自己招错人或决策失误,股价就会被重创。
事实是,任何在最前沿认真使用 AI 的人都能看到,你必须像哄小孩一样引导、照看它。它无法端到端地完成一份工作,它只能完成任务,仅此而已。
它当然会变得更好,但它会魔术般地从”任务”跨越到”工作”吗?也许吧。但在我们制定政策之前,我们需要在现实中看到证据。
那么现实中还有其他问题吗?
除了我在作品中详述过的两个问题外,别无其他:
监控与战争武器。
但这并非新鲜事。AI 只是增强了它们,就像计算机、材料科学和之前的历次科技革命所做的一样。
请再次拷问自己,真正的现实问题到底在哪?
又有一群人大声叫嚣着:”等着瞧,我在脑子里构思了这个难题,它是不可避免的,因为我说了算。”
然而,每天都有数十亿人在毫无障碍地使用这项技术。
你可能会引用”罗素的火鸡“理论:趋势在断裂前永远是趋势。但证明趋势即将断裂的责任在你。除了人们的臆想,目前没有任何证据。
人们到底什么时候才能清醒过来,意识到这一切根本毫无道理?
并不是说不会出问题。而是我们预想的问题(我们已经预想了 100 年的”工作终结”)往往与现实发生的并不相符。问题最后会以完全不同的面貌出现,而你只能在它们出现时再去解决。
今天的许多政客幻想着,如果当年能通过监管”走在互联网前面”,我们的处境会好得多。
纯属胡言乱语。当年通过《通信规范法》第 230 条时,国会问得最多的问题还是“什么是互联网?“难道指望这群人能预见到 25 年后的 TikTok?
不。
我们必须处理已经出现的问题,而不是处理某些嗓门很大的人承诺会发生的虚幻问题。举证责任在他们身上,写长篇大论、搞”第一性原理思考”或写几本吓人的书,都不能算作任何证据。
这种认知失调什么时候才会触底,让人们醒悟并说一句”也许我错了”?
可能永远不会。
信仰是一种微妙的东西,而错误的信仰在世界历史上造成的问题,远比 AI 将要造成的要多。
绝不要让批判性思维挡了你那些“极端幻想故事”的路。
如果你正处于这条滑块的任何一端——那么恭喜你,你可能只是个套在成年人皮囊里的孩子!
非黑即白的二元论思维,是小孩的专利。
长大成人之后,就该把这些幼稚玩意儿收起来了。
特朗普总统对美国盟友的滥用已经达到了临界点。
如今各国已开始做出长期政策转向——而这些转变很快将自成生命。

特朗普在其第二个任期的大部分时间里,一直把盟友政府当成“白吃白住”的租客,觉得他们理应因他没换掉门锁而感恩戴德。
结果不出所料:盟友们不再守着租约到期,而是开始买自己的房产了。
现在发生的事情与 2017 年至 2019 年间的那些牢骚有本质不同。
那时,欧洲领导人仍相信这种关系是周期性的 —— 相信美国最终会清醒过来,旧有的架构也会重新拼合。
这种信念已经幻灭。
格陵兰岛事件永久性地改变了一切。取而代之的是结构性的抉择:
德国进行了自统一前从未有过的规模化重整军备;法国主导的欧洲防务协作正刻意将华盛顿排除在外;韩国在悄然讨论自主核威慑;日本的国防开支也达到了五年前在政治上难以想象的水平。
这种转变的关键动力在于,它们会产生自身的惯性。
为了供应欧洲军队而重建的德国军工产业,不会在下一任美国总统打个电话时就刀枪入库;一代习惯了在没有美国指挥整合下运作的欧洲防务策划者,也不会轻易忘掉这套模式;那些改道新走廊的贸易关系,更不会仅仅因为华盛顿某人最终递出橄榄枝,就自发地回到旧路。
特朗普似乎将美国的力量视为一种静态资产 —— 一种可以为了短期筹码而不断挥霍,却不会削弱其底蕴的资产。
他的盟友们明白、但他却不明白的一点是:这种资产的核心始终在于“关系”。从盟友们不再相信它的那一刻起,资产负债表就发生了永久性的改变。
这其中的讽刺近乎古典主义:他本想让盟友为美国的保护支付更多费用,结果却成功说服了他们——从此不再需要这种保护。
疫苗曾经是如此没有争议的存在,以至于麦当劳餐厅都把儿童免疫接种时间表印在了餐盘垫纸上。
而如今,当美国政府开始播下怀疑的种子,那些原本可以预防的疾病,可能正卷土重来。
俄罗斯曾在白喉看似被彻底击败之后,放松了疫苗接种标准。结果——15.7 万人感染、5000 人死亡。
日本在公众信任崩溃后取消了强制接种。风疹卷土重来——新生儿先天失明、失聪。
尼日利亚抵制脊髓灰质炎疫苗。病毒让 2500 名儿童瘫痪,并扩散到 20 个国家。
而如今,肯尼迪(RFK Jr.)已从常规接种计划中移除了 6 种疫苗,并撤回了 16 亿美元的全球免疫资金。麻疹已在美国 46 个州出现疫情。
特朗普刚刚解雇了国家科学委员会(National Science Board)的全部 24 名成员。无一幸免。通过电子邮件告知。没有预警,也没有给出任何理由。该委员会自 1950 年 以来一直存在。
国家科学委员会是一个独立机构,负责监督国家科学基金会(NSF),而该基金会每年负责分发高达 90 亿美元的研究经费。
委员会成员是来自高校和工业界的科学家及工程师。他们的任期为六年且实行错时制,其目的正是为了跨越总统任期的更迭,确保独立于任何在位当权者。
就在周五,每一位成员都收到了来自总统人事办公室玛丽·斯普劳尔斯(Mary Sprowls)发出的同样一份模板式邮件:“我代表唐纳德·J·特朗普总统致函通知您,您作为国家科学委员会成员的职务已被终止,立即生效。感谢您的服务。”
仅此而已。这就是全部的辞退信。长达 76 年的机构独立性就此终结。

国家科学基金会(NSF)资助了核磁共振(MRI)、手机、准分子激光原位角膜磨镶术(LASIK 眼科手术)、全球定位系统(GPS)、互联网本身、南极研究站、深空望远镜,以及绘制海床图的研究船背后的基础科学。
在过去大半个世纪里,每一个让美国成为世界科学领导者的突破,都可以追溯到该机构提供的资助和该委员会批准的项目。
委员会主席维克多·麦克拉里(Victor McCrary)此前一直在就特朗普提议削减 NSF 55% 预算的计划向国会提供咨询。委员会曾协助抵制这一削减计划,于是特朗普解雇了整个委员会。
被解雇的成员之一马尔维·马托斯·罗德里格斯(Marvi Matos Rodriguez)告诉记者,就在被辞退的前几天,她还在履行委员会职责,审阅一份长达 80 页的报告。
范德比尔特大学的物理学家凯万·斯塔森(Keivan Stassun)表示,NSF 的领导层早在几个月前就停止响应委员会的监督要求了。“我们会问他们:‘你们是否在遵循委员会的管理指令?’而他们的回答实际上是:‘我们不再听你们的了。’”
现在,已经没有委员会可以对其进行约束了。
众议院科学委员会资深民主党人、加利福尼亚州众议员佐伊·洛夫格伦(Zoe Lofgren)称此举是“这位持续损害科学和美国创新的总统所做出的最新愚蠢举动。
总统是否会用那些不敢反抗他的‘马加’(MAGA)忠诚者来填补委员会空缺,从而将我们的科学领导权拱手让给竞争对手?”
这才是真正核心的问题。
因为就在特朗普解雇美国科学家的同时,中国正以我们无法匹敌的速度建设研究型大学。
美国疾控中心(CDC)刚刚掩埋了一项证明疫苗有效的研究。小罗伯特·F·肯尼迪(RFK Jr.)正掌管卫生与公众服务部(HHS)。环境保护署(EPA)被削弱,林务局正面临解体。半数美国儿童正呼吸着危险的空气。
而现在,这些决定美国科研方向的人选,在周五下午被一封电子邮件集体解雇了。

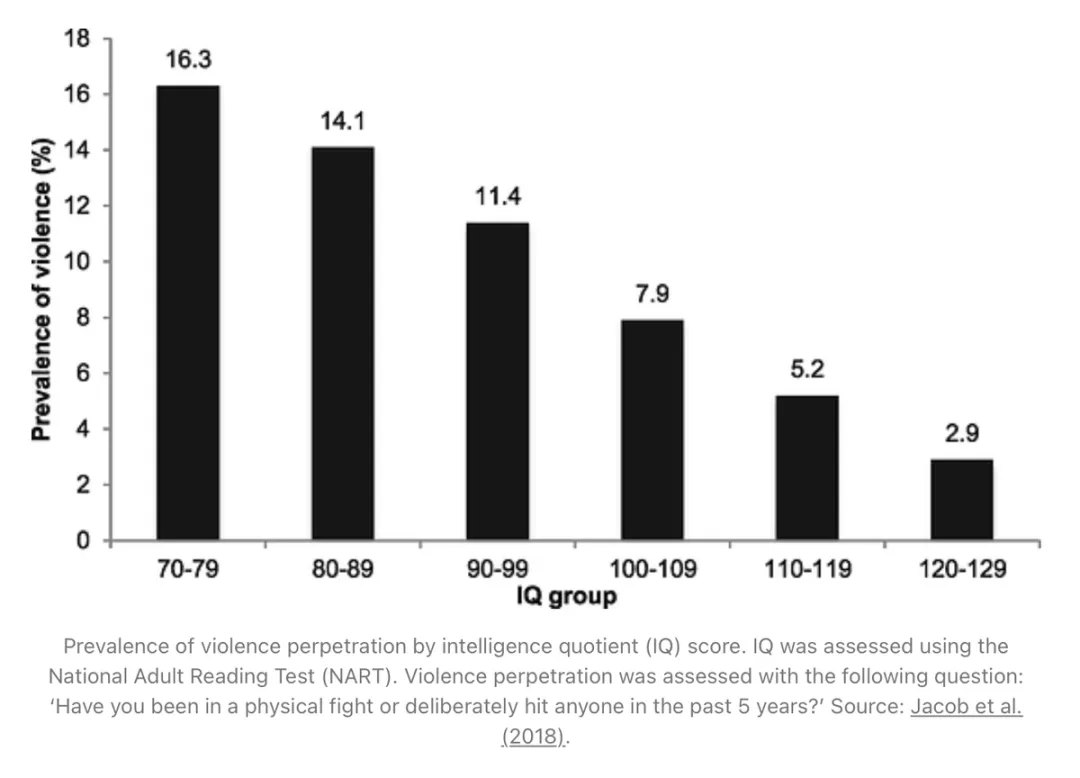
更聪明的人,更少使用暴力。
“暴力行为的发生率会随着智商升高而稳步下降:在 IQ 70–79 区间的个体中,有16.3%报告自己有暴力行为;而在 IQ 120–129 区间,这一比例仅为2.9%。”