 夜雨聆风
夜雨聆风





AI写论文越来越容易,学术出版快扛不住了

2024年10月,arXiv收到24,226篇投稿,历史新高。同比增长17%。这不是什么好事。
三年前,高能物理理论版块每月收到634篇论文。到2025年12月,这个数字变成了1,192篇——三年翻了一倍。而且还在加速。
你以为这只是科研繁荣?不。这是一场正在发生的系统过载。
每七篇投稿,就有一篇可能是假的
Wiley开发了AI检测工具,在270多本期刊上试运行。每月约10,000篇投稿中,10%–13%被标记为疑似论文工厂产品。也就是说,每月有600-1,000篇投稿在进入同行评审之前就被拦截。
这是Wiley一家 publisher 的数据。全球学术期刊有数万本。
中华医学会杂志社也做了统计:近半年来,旗下期刊超过12%的投稿,AI撰写内容占比超过5%。《社会科学辑刊》的编辑更狠——AI创作疑似度超过20%直接退稿,主编个人认为超过10%就“很过分”。他们在2025年第4期就抓出3篇AI论文,作者全被拉黑。
Wiley旗下Hindawi因为论文工厂问题被迫撤稿超过11,300篇,亏损3500-4000万美元,CEO离职,品牌直接关停。
论文工厂2.0:成本归零,速度无限
以前的论文工厂,需要雇人写、买审稿人、手工伪造数据——成本高、速度慢。
现在?LLM几分钟生成一篇结构完整的论文,边际成本趋近于零。传统检测手段(语言错误、重复图像)全部失效。
Nature 2025年9月报道,一项对数万篇投稿的分析显示,AI生成文本的存在“急剧增加”。Elsevier调查了2,284名研究者,31%承认使用生成式AI做研究,93%认为LLM帮助了他们的写作和审稿。但Science报道的另一项研究发现:实际使用AI写论文的人数,是承认人数的四倍。
四倍。
这意味着,你看到的“31%”可能只是冰山一角。真实比例可能在60%–80%之间。没人愿意承认,但几乎所有人都在用。
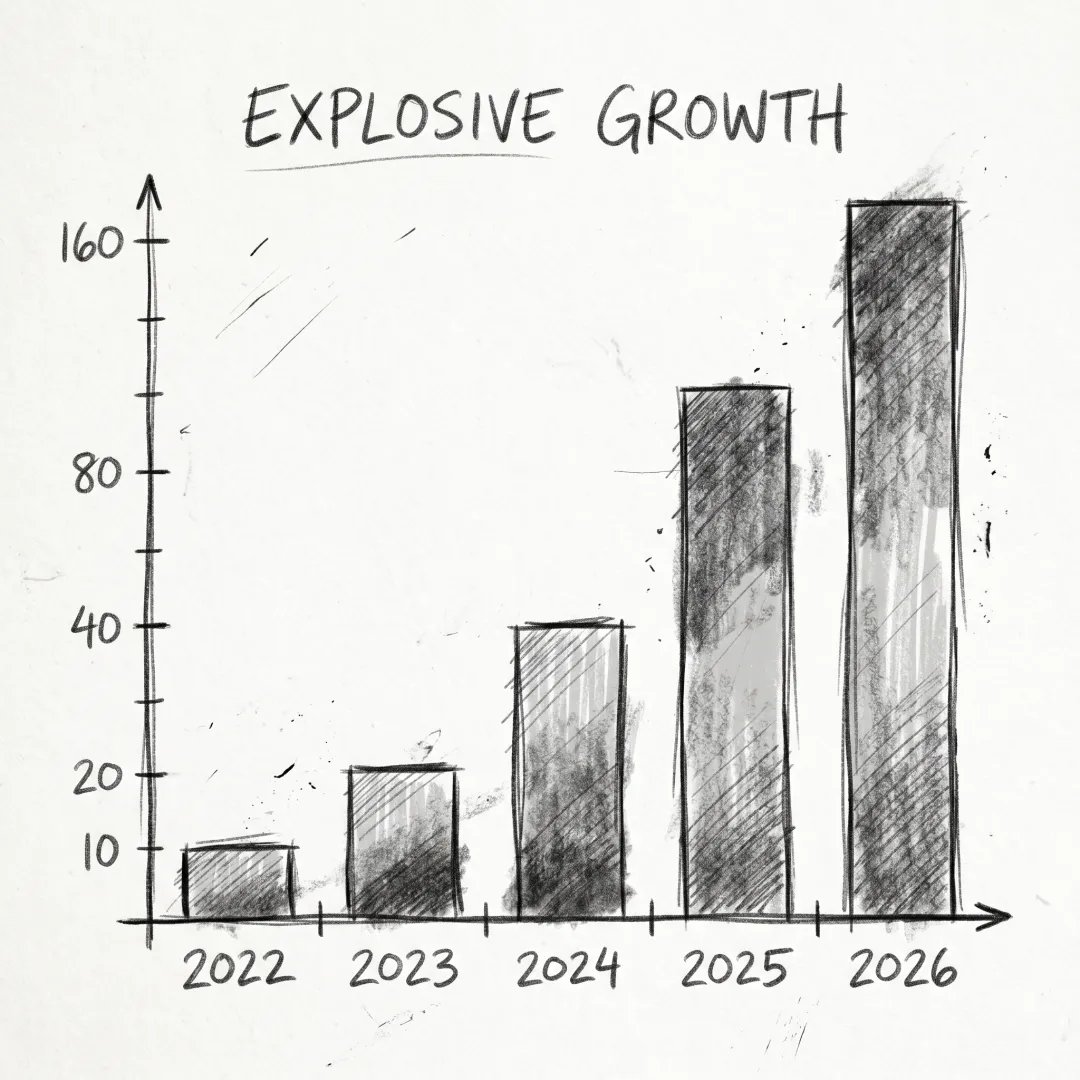
顶会也在被淹没
AAAI 2026收到23,680篇投稿,历史之最。录用率仅17.6%。一年前的AAAI 2025只有12,957篇——一年之间暴涨83%。这是AAAI有史以来最大的单年增幅。
CVPR 2025也破了纪录——12,008篇投稿,同比增长13%。ICLR 2025收到11,565篇投稿。
arXiv的情况更直观:2023年5月首次月度投稿突破2万篇,到2024年10月就到了24,226篇。计算机科学三个AI相关子类(机器学习、计算机视觉、NLP)一个月就贡献了6,000多篇,占总量近25%。
量在暴涨,质在暴跌。
AI检测的死循环
Springer Nature开发了两个AI检测工具,2024年6月上线。Wiley的检测系统包含六项功能,从论文工厂比对到生成式AI特征识别。
但问题是:AI检测工具本身就不靠谱。
一项研究评估了14款AI检测工具,所有工具准确率均低于80%,仅5款超过70%。约20%的AI生成文本会被错误归为人类写作。Frontiers在2025年7月发现了一个122篇操纵同行评审的文章网络。这122篇是怎么被发现的?不是AI检测工具发现的,是人工排查。
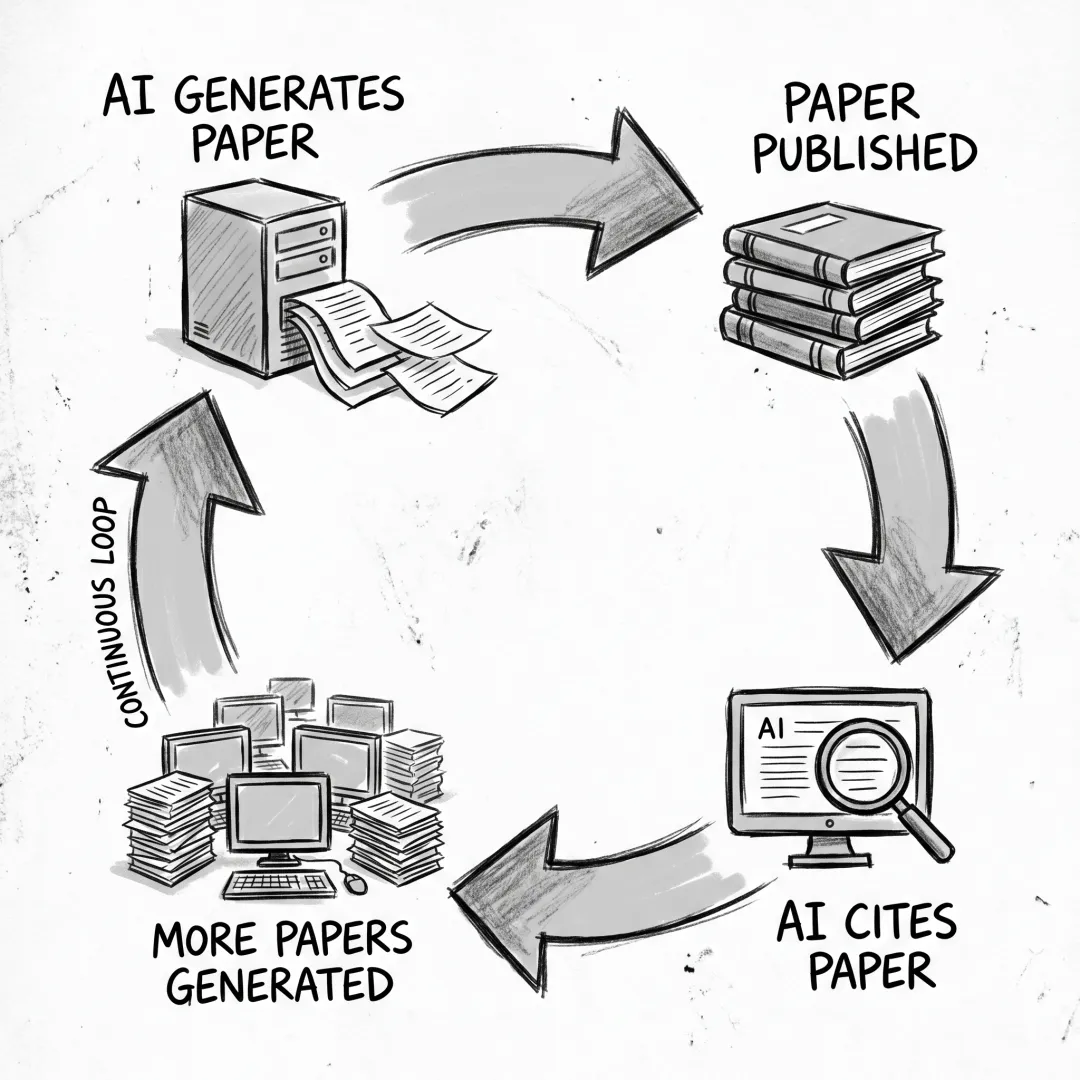
更可怕的是:AI研究工具本身成了虚假信息的放大器。一项研究发现,21篇被撤稿的虚假论文被Consensus引用了18次、Ai2 ScholarQA引用了17次、Perplexity引用了11次。没有任何一个AI工具在引用时发出过撤稿警告。
只有ChatGPT在3次引用中发出了警告。3次。
AI生成论文 → 发表 → AI引用 → 成为新论文的“依据” → 生成更多论文。这是一个正在形成的死循环。
出版商在做什么?
目前全球学术出版界的应对,基本分三派:
全面禁止派——以《社会科学辑刊》为代表,三种AI创作全部禁止,查实即拉黑。
有限允许派——以中华医学会杂志社为代表,允许AI做语言润色和翻译,但严禁用于整篇论文或核心部分的撰写。Elsevier、Springer Nature基本也是这个立场。
技术对抗派——开发AI检测工具,在投稿环节拦截。Wiley、Springer Nature都在这条路上投入巨资。
但这些措施有一个共同的盲区:它们只能对付“完全由AI生成”的论文。对于“人机协作”——研究者用AI辅助文献综述、数据处理、语言润色,但核心观点是人类提出的——目前的政策几乎无法界定,更无法检测。
这恰恰是大多数研究者的真实使用方式。
更深层的问题
764篇被撤稿的AI相关论文中,551篇来自中国——占72%。但正如Retraction Watch指出的,这不意味着问题出在中国本身。论文工厂在“发表或出局”压力最大、监管最滞后的地区找到了最大市场。
这套“发表或出局”的激励机制不变,AI只是让原来就存在的扭曲变得更极端。原来一年产出10篇论文的学者,现在可以产出50篇。原来需要3个月完成的论文,现在3天就行。
审稿人呢?还是那么多人。审稿周期呢?只会更长。
我们已经在上篇聊过,审稿接受率21年间从60%跌到40%以下,全球只有200-300万人参与评审。现在投稿量还在加速膨胀,审稿系统已经在崩溃边缘。
AI写论文让这个问题从“严重”变成了“无解”——除非系统本身发生根本性变革。
趋势判断
接下来3-5年,大概率会看到这些变化:
投稿量继续暴涨。arXiv的记录还会一再被打破。AAAI的投稿量可能突破4万。
接受率继续下跌。顶刊的接受率可能跌破15%。
AI检测成为标配。所有主流出版商都会在投稿环节部署检测工具,但检测效果永远落后于生成能力。
新的出版范式出现。注册报告制(Registered Reports)可能成为主流——在数据收集之前就通过方法论审查,而非在论文写完之后再判断质量。开源审稿、社区评审、AI辅助筛选会逐渐替代传统同行评审。
学术评价体系被倒逼改革。当论文数量不再有意义,“发了多少篇”这个指标就失效了。资助机构和大学不得不寻找新的评价方式。
这意味着什么
AI写论文越来越容易,这不是趋势预测,这是已经发生的事实。
投稿量暴增,审稿系统不堪重负,检测工具跟不上生成速度,虚假论文通过AI引用自我繁殖——这条链路上的每一环都在加速恶化。
学术出版作为一个运行了350年的系统,第一次面临存亡级别的冲击。不是因为AI太强,而是因为AI暴露了这个系统的根本脆弱性:它把“数量”当作“质量”的代理指标,而AI恰好擅长制造数量。
当数量不再可信,要么找到新的质量衡量方式,要么整个系统信用破产。
2027年前后,会是临界点。 (本文由大语言模型辅助完成)