 夜雨聆风
夜雨聆风





Google TPU 十年演进:从内部插件到推理时代底座
Google TPU 这十年的核心变化,不仅仅是芯片性能提升,更是它越来越接近 AI 时代真正需要的基础设施形态。
摘要
Google TPU 的价值,已经不能只用芯片代际来理解。它最早服务 Google 自身的在线推理负载,随后进入 Google Cloud,成为可对外交付的 AI 基础设施。大模型时代到来后,TPU 又从一套通用 AI 平台,逐步走向按工作负载分层设计。2025 年,Google 将 Ironwood(v7)定义为首个专为推理 (inference) 设计的 TPU;2026 年,又推出 TPU 8t 和 TPU 8i,分别面向训练与推理。沿着这条线看,TPU 的演进更像一部 Google 重写 AI 基础设施的历史。
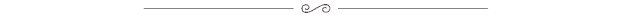
Google 在 2026 年 Cloud Next 上发布 TPU 8t 和 TPU 8i,这次最值得注意的地方,不只是第八代 TPU 又提升了多少性能,而是 Google 直接把训练和推理拆成了两条产品线。TPU 8i 面向低时延推理和 agent 工作流,TPU 8t 面向训练。这说明 Google 对 AI 基础设施的理解又往前走了一步:训练和推理已经需要不同的底层设计。
Google TPU 是怎么一步步演进成“推理时代基础设施”的?
如果今天再看 Google TPU,很容易陷入一种“编年史式”的理解:v1、v2、v3、v4、v5e、Trillium、Ironwood、TPU 8t、TPU 8i,一代代往后排,参数越做越高,系统越做越大。我试着往更深度看,TPU 真正值得写的地方,在于它的角色变化。过去十多年里,Google 并不只是把 TPU 做得更强,而是不断给 TPU 赋予新的任务:先服务内部推理,再进入云,再成为大模型时代的系统级平台,最后走向训练与推理分轨。
TPU 最早的起点,是 Google 数据中心里的内部 AI 加速器,核心任务是跑神经网络推理。Google 在介绍第一代 TPU 时提到,这颗芯片从 2015 年就已经部署在数据中心中,服务 Search、Street View、Photos 和 Translate 等产品背后的神经网络工作负载。也就是说,TPU 一开始面对的不是“怎么做一款对外销售的芯片产品”,而是“怎么把 Google 自己的在线 AI 服务跑得更稳、更快、更省”。
这一阶段的 TPU,有一个很鲜明的特点:它高度围绕生产环境来定义。Google 当时最关心的不是实验室里的极限性能,而是数据中心里的响应时间、能耗和单位成本。在线推理场景对尾延迟非常敏感,搜索、语音、翻译这类业务尤其如此。TPU 在这个背景下出现,本质上是 Google 给神经网络负载单独配了一套更合适的底层计算方式。今天回头看,这一步的重要性并不只在于它带来了硬件加速,更在于 Google 很早就意识到,AI 计算值得拥有专门为自己设计的架构。

真正的第一次跃迁发生在 2017 年。那一年,Google 宣布第二代 TPU 进入 Google Cloud,正式以 Cloud TPU 的形态对外提供服务。官方表述很直接:Cloud TPU 用来加速广泛的机器学习负载,同时支持训练和推理,并且最初通过 Google Compute Engine提供。这时,TPU 的身份已经开始转变。它不再只是 Google 内部使用的一块加速器,而是 Google Cloud 的一项基础设施能力。
这个变化带来的影响非常巨大。一旦进入云,TPU 要解决的问题就不再只是“Google 自己能不能用好”,而是“客户能不能接得上、用得起、扩得开”。从这时候开始,TPU 需要面对更复杂的要求:资源调度、框架适配、区域可用性、集群扩展、软件栈协同。它开始从一颗芯片,变成平台的一部分。今天 Google Cloud 的 TPU 页面仍然延续了这种定义:TPU 是 Google 自研的 AI 加速器,用于训练和推理,服务 Google 自身大规模 AI 业务,也通过 Google Cloud 对外开放。
如果说第一阶段解决的是“AI 能不能在生产环境里跑起来”,第二阶段解决的,就是“Google 能不能把内部 AI 能力商品化”。这件事的重要性在于它决定了 TPU 后来的方向。做内部基础设施,重点是把单个系统打磨好;做云基础设施,重点是把硬件、网络、编译器、框架和交付方式组织成一套可以稳定复制的能力。也就是从这里开始,TPU 的价值开始从“器件能力”转向“体系能力”。

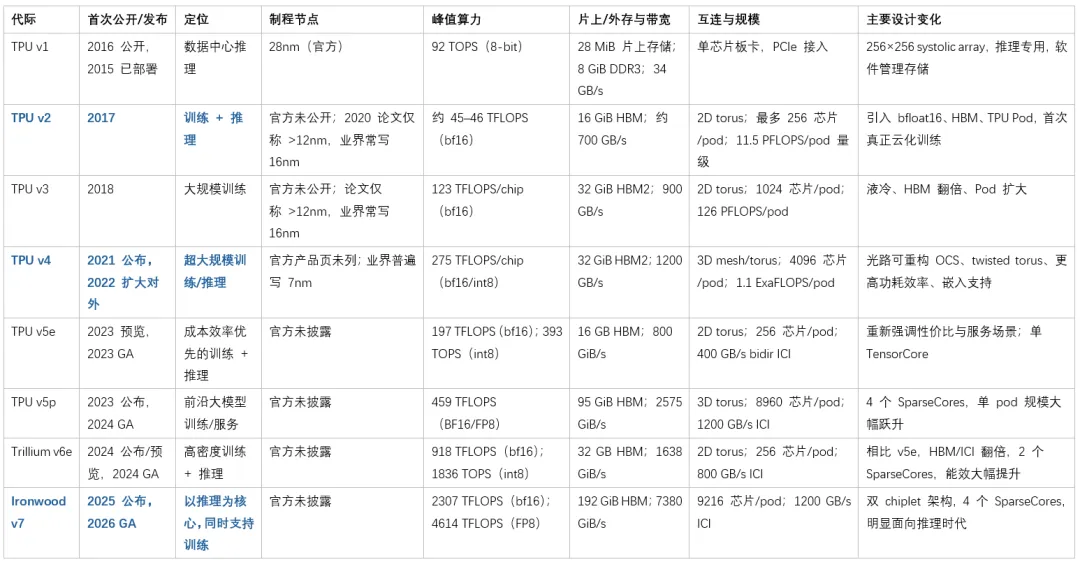
接下来,大模型时代把 TPU 推向了第三个阶段:系统级扩展。这一阶段的代表产品是 TPU v4。Google 官方文档显示,TPU v4 Pod 可以扩展到 4096 颗芯片,采用 3D mesh 互连,整 Pod 峰值算力达到 1.1 exaflops。这里最值得关注的,并不是单颗芯片多了多少算力,而是 Google 已经把 TPU 组织成一套大规模、可重构的 AI 系统。TPU 的竞争对象到了这个阶段,也不再只是某一张更快的卡,而是整个超算级 AI 基础设施。
但 Google 很快发现,把系统越做越大,只是问题的一部分。生成式 AI 爆发之后,训练和推理都在快速增长,可两者对资源的要求并不相同。训练更强调大规模并行和长时间吞吐,推理更强调时延、服务效率、内存和系统利用率。Google 接下来的几代 TPU,开始更清楚地回应这个变化。
v5e 是一个很重要的过渡节点。Google 在其公告中把它描述为面向成本效率的 Cloud TPU 平台,并特别强调它可以作为一套统一平台,同时服务训练和推理。官方给出的口径也很直接:在大语言模型场景中,v5e 相比 TPU v4 带来 2.3 倍训练 price-performance 提升,以及 2.7 倍推理 price-performance 提升。这个阶段,Google 的思路依然是用一套更成熟、更便宜的 TPU 平台,同时覆盖训练和 serving 两类负载。
Trillium 把这条路线继续向前推进。Google 在发布材料里提到,Trillium 相比 v5e 单芯片峰值计算性能提升 4.7 倍,HBM 容量和带宽翻倍,ICI 带宽也翻倍,同时能效提升超过 67%。官方还特别提到,更大的内存和更高的带宽有助于承载更大的模型权重和更大的 key-value cache,从而改善训练时间和 serving latency。这个信息很重要,因为它说明在 Trillium 这一代,Google 已经明显在围绕大模型的训练和推理共同优化整个平台。

真正的分水岭出现在 Ironwood。2025 年 4 月,Google 在官方博客中第一次明确写出:Ironwood 是其第七代 TPU,也是首个专为 inference 设计的 TPU。官方对它的描述也很有代表性,强调它面向 thinking models 和 inferential AI models at scale,并可扩展到 9216 颗芯片。到这一步,Google 的态度已经非常明确:推理不再只是训练完成后的一个附属环节,它已经成为足以驱动独立架构、独立产品和独立系统优化的主战场。
再到 2026 年,TPU 8t 和 TPU 8i 把这条路线彻底产品化了。Google 在 Cloud Next 上直接发布两种 specialized TPUs:TPU 8i 面向越来越复杂的 AI 推理负载和 autonomous AI agents,TPU 8t 面向训练,并强调其可在单一的大规模内存池中运行复杂模型。这里的信号已经非常清楚:Google 不再试图用一套芯片尽量兼顾所有场景,而是在产品层面正式承认训练与推理需要不同的底层组织方式。

沿着这条线往回看,Google TPU 十多年的变化可以浓缩成三次角色升级。
第一次,它是 Google 内部的推理加速器,帮助神经网络真正进入生产环境。第二次,它变成 Cloud TPU,成为 Google Cloud 对外提供的 AI 基础设施。第三次,它进一步演进为大模型时代的系统级平台,并最终走到训练与推理分轨。这个过程并不只是芯片代际升级,更像 Google 对 AI 工作负载理解不断加深后的结果。工作负载变了,芯片要变;芯片变了,系统要跟着变;系统变了,云产品形态也要变。
这也是为什么今天看 TPU,单独盯着参数表已经不够了。真正值得关注的是 Google 如何定义下一代 AI 基础设施。v4 让 TPU 成为超大规模系统,v5e 让 TPU 更适合兼顾训练和推理,Trillium 继续把性能、内存和能效往上推,Ironwood 把推理单独拉出来,TPU 8t/8i 则把训练和推理正式拆开。整条演进线说明一件事:AI 基础设施不会长期停留在一种形态上,它会随着模型、服务方式和商业需求变化而持续重构。
所以,Google TPU 这十年的重点,不只是算力越来越高,也不只是系统越来越大。更重要的是,Google 一直在把 TPU 从“加速器”推进为“基础设施”。当它走到今天这个阶段,TPU 已经不只是 Google 的一条芯片产品线,而是一种完整的 AI 底层组织方式。对于整个行业来说,这条线最大的启发也许是:真正有竞争力的 AI 基础设施,最终拼的往往不是单点器件,而是你能否按工作负载重构整套系统。