有个比喻特别贴切:绝大多数人使用 AI 的方式,就像每次打开电脑都要重新安装系统、不装任何驱动程序,然后抱怨电脑运行卡顿。你每天花 30 秒重复输入 “我是做市场营销的,帮我写个方案”,一年下来就是近两个小时的无效重复劳动。更重要的是,冷启动状态下 AI 的输出质量,和加载了完整上下文的 AI 相比,完全不在一个维度上。
我们这篇文章的价值在于:不是在教你”怎么写更好的提示词”,而是在教你怎么搭建一个让 AI 自动变聪明的系统。一次搭建,长期受益。
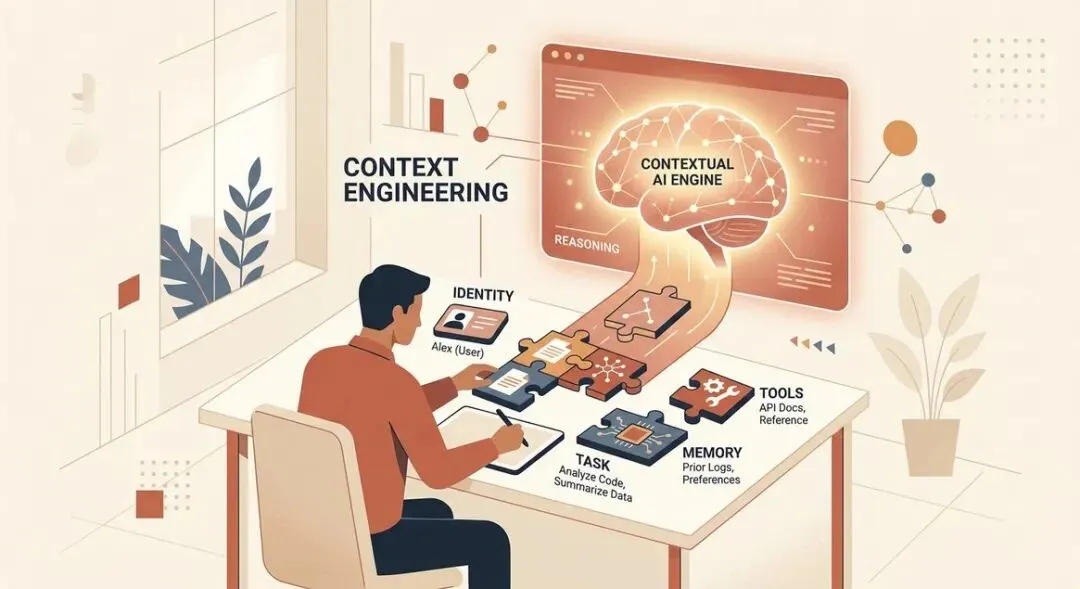
上下文工程的核心:你不是在”写提示词”,而是在为 AI 组装操作环境
02 五层架构
:::
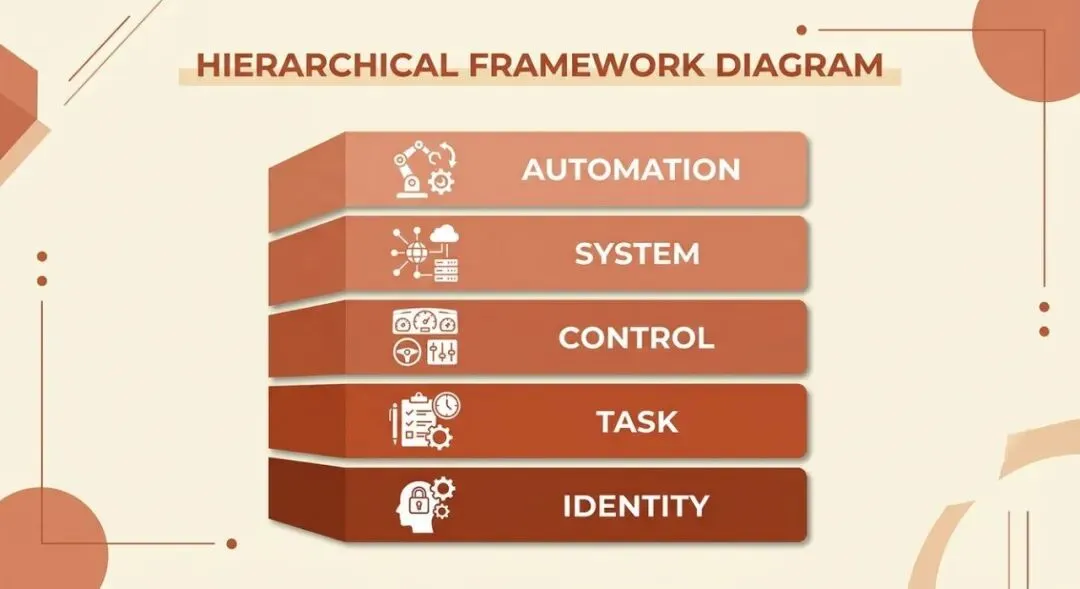
我们把 15 个模板分成了五层,从底到顶依次是:
第一层 · 身份层(模板 1-3)——AI 让 AI 认识你第二层 · 任务层(模板 4-6)——AI 让 AI 明确需求第三层 · 控制层(模板 7-9)——让 AI 不跑偏第四层 · 系统层(模板 10-12)——把对话变成工作流第五层 · 自动化层(模板 13-15)——让系统自主运行
层层叠加。底层设一次,长期生效;顶层按需调用,越用越顺。
上下文工程的五层体系:从身份到自动化,逐级构建
03 身份层:一劳永逸
:::
这一层专门解决 AI 的冷启动问题 —— 每次开启新对话,AI 对你的背景一无所知。模板 1:个人上下文档案。把你的职业身份、工作领域、服务对象、沟通风格偏好等信息整理成一段文字,保存到 ChatGPT 的自定义记忆、Claude 的系统指令或者 Gemini 的 Gems 功能中。一次设置,之后所有对话都会自动加载这些信息。Anthropic 的工程团队曾公开表示,系统指令是控制 Claude 行为最有效的杠杆,而个人上下文档案就是这个杠杆的核心。模板 2:品牌 / 个人风格档案。最实用的技巧是直接粘贴两段你自己写的优质文字样本,AI 会通过模式匹配精准复刻你的写作风格,效果远比你用一千个字描述 “我的语气简洁有力” 要好得多。同时列出你绝对不想出现的词汇,比如 “赋能”“抓手”“闭环” 这类行业黑话,AI 就会自动规避。我们自己一直在用这个方法,在 Claude 的项目指令里贴了几篇我们写的公众号文章后,它再也没给我写过 “让我们深入探讨一下……” 这种生硬的开头。这个技巧对中文写作尤其有效,因为 AI 默认的中文表达往往偏书面化、官腔重,而真实的写作样本能让它快速校准到你的语言习惯。两段文字就够了,比写十条规则管用得多。模板 3:通用工作规则。有句话我特别认同:你对 AI 输出的每一次不满,本质上都是一条还没写下来的规则。比如 “执行前先向我确认”“给出建议时优先说明推荐方案”“不要使用占位符”“不知道就直接说不知道,不要编造信息”“默认输出 300-500 字”“我说‘缩短’就删减 40% 的内容”。把这些抱怨转化为明确的约束条件,写一次就能避免以后重复出现同样的错误。这三个模板的共同特点是 “一次设置,终身受益”。你不需要每次对话都重复告诉 AI 你是谁、你喜欢什么风格、你讨厌什么行为,把它们存入系统指令,就像给你的 AI 操作系统安装好了所有必要的驱动程序。
04 任务层:结构化提问
:::
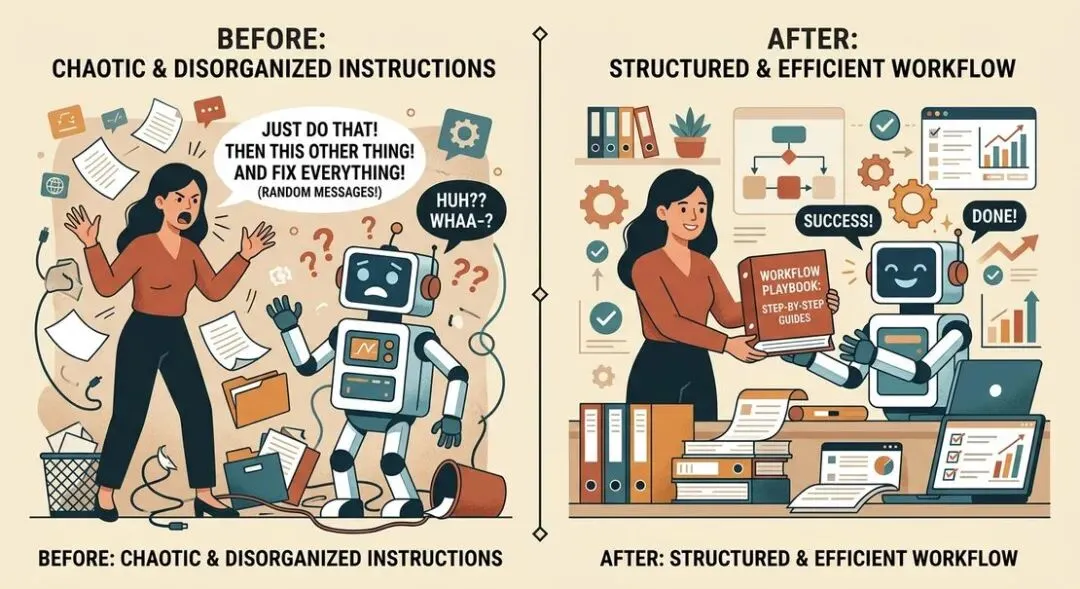
身份层是长期生效的基础设置,任务层则是每次使用时的即时指令。这一层的核心是把模糊的口语化请求,转化为清晰的结构化指令。三个模板分别对应工作中最常见的三个场景:调研、写作和决策。你可能觉得 “只是随便问问” 没必要这么正式,但试过一次就会发现差距有多大。同样是让 AI 调研竞品,“帮我看看 Notion 和 Coda 哪个好” 和一份写明了评估维度、目标受众、输出格式的结构化简报,得到的结果完全是两个级别。前者只能给你五百字泛泛而谈的介绍,后者能直接生成一份可以拿去开会的专业对比分析报告。模板 4:调研简报。最关键的一句话是 “不要复述我已经了解的行业背景知识”。绝大多数 AI 生成的调研内容,前三分之一都是毫无价值的废话 —— 你问某个行业的发展趋势,它先花几百字给你科普这个行业是什么。加上这一句话,就能直接砍掉这部分冗余内容。模板 5:写作简报。最容易被忽略的一个字段是 “需要排除的内容”。大多数人只会告诉 AI 要写什么,而真正的上下文工程师还会明确告诉它不能写什么。约束带来聚焦,聚焦才能产生高质量的输出。模板 6:决策辅助框架。里面有一句堪称神来之笔的指令:“不要保持中立,明确给出你的推荐立场”。没有这句话,AI 默认会给你一段 “各有利弊” 的和稀泥式总结,看完你还是不知道该选哪个。加上这句话之后,你会得到一个明确的建议 —— 你可以不同意它的观点,但一个可以被反驳的具体建议,远比一篇谁也不得罪的空泛报告有用一百倍。我们亲自测试过,同样的决策场景,加不加这句话输出结果天差地别。不加的话你会得到四段四平八稳的论述,加了之后 AI 会直接说 “我推荐方案 B,原因有三点”,同时还会列出反对方案 B 的最强论据供你参考,这才是真正有价值的决策辅助。左:随意提问 = 混乱输出。右:结构化上下文 = 高效结果
05 控制层:防跑偏
:::
这一层专门解决使用 AI 时最让人崩溃的三个问题:模型忘记了最初的指令、回答跑偏了、开始编造虚假数据。模板 7:会话预加载器。每次开始复杂任务之前,先把项目背景、当前进度、上次的成果、本次的目标、参考文件、所有约束条件一次性全部输入进去。这就是所谓的上下文预加载 —— 在模型生成第一个字符之前,把它需要的所有信息都塞进上下文窗口。模板 8:反幻觉防护栏。核心是引入 [待验证] 标签机制。与其祈祷 AI 不编造数据,不如给它一个明确的出口:不确定的信息就标注出来。Anthropic 官方文档也推荐这种方法,当模型被允许表达不确定性时,它编造虚假信息的概率会大幅降低。这是我们最推荐的一个模板,现在我们写任何需要引用数据的内容,都会加上这条规则。效果立竿见影 —— 加了之后,AI 会在不确定的数据旁边老老实实标上 [待验证],而不是像以前那样自信满满地给你编一个精确到小数点后两位的假数字。模板 9:上下文重置。指令长对话会产生研究者所说的 “上下文腐蚀” 现象 —— 模型的注意力会逐渐漂移到最近的几条消息上,慢慢忘记最初的核心指令。Claude Code 在上下文窗口占用率达到 95% 时会自动触发内容压缩,把所有历史对话总结成一段保持聚焦。这个模板让你可以在任何 AI 工具里手动执行同样的操作。一次彻底的上下文重置,远比十条纠正消息更有效。说到这里你可能已经发现,这三个模板的核心逻辑是一致的:它们都是在主动管理 AI 的注意力。会话预加载器告诉 AI 应该关注什么,反幻觉防护栏告诉 AI 不确定的时候该怎么做,上下文重置告诉 AI 应该忘掉什么。其实管理 AI 和管理人类团队的底层逻辑完全一样:分配任务、设定边界、及时纠偏。
06 系统层:从聊天到工作流
:::
这一层的目标是把 AI 从一个聊天工具升级为专业的工程工具。模板 10:项目规则文件(CLAUDE.md)。如果你在使用 Claude Code、Cursor 或者任何 AI 编程工具,这个文件就是整个项目的核心。项目使用的编程语言、技术框架、数据库类型、代码规范、常见错误及解决方案…… 全部写在这个文件里。每次开启新会话时自动加载,所有规则自动生效。这就是上下文工程在开发者领域的最佳实践:同一个错误永远不需要纠正第二遍。把纠正措施编码进规则文件,它就变成了永久生效的约束。模板 11:多步骤任务规划器。最关键的指令是 “不要立即开始执行”。AI 最常见的失败模式就是急于输出 —— 你给它一个复杂任务,它二话不说就开始写,写完才发现方向完全错了。强制它先制定详细的执行计划,等你批准之后再分步执行,输出质量会有质的飞跃。这本质上就是 “规划 – 执行 – 验证” 的闭环:先想清楚要做什么,做完一步确认一步,验证通过后再进入下一步。所有成熟的 AI 智能体工作流都是按照这个逻辑设计的。你不会让一个刚入职的实习生拿到需求就直接写代码,你会让他先出方案评审,管理 AI 也是同样的道理。模板 12:自我评估循环。让 AI 在把输出结果交给你之前,先用一套明确的标准进行自检:是否完整回答了所有需求?有没有未验证的事实?语气是否符合要求?有没有冗余的废话?如果任何一项不达标,先自行修改再提交。Anthropic 把这种模式称为 “思维链自我验证”。只用这一个模板,就能帮你砍掉一半的编辑时间 —— 因为你看到的不再是粗糙的初稿,而是 AI 自己修改过一遍的二稿。这三个模板的共性是什么?它们把 AI 从一个 “聊天对象” 升级成了一套 “工程系统”。聊天是随意的一问一答,而系统是有规范、有流程、有质检的。用上这三个模板,你的 AI 就拥有了代码规范(CLAUDE.md)、项目管理流程(任务规划器)和质量保证体系(自我评估),构成了一个完整的软件工程体系。
07 自动化层:让系统自己跑
:::
最后这三个模板,是整个体系中最具复利价值的部分 —— 它们把一次性的对话变成了可复用的系统,而且会随着你的使用变得越来越好用。模板 13:自动化周报系统。设置一个固定模板,每周一自动运行:本周优先行动项、重要会议准备、未完成事项跟进、行业资讯精选。AI 会从你连接的工具(日历、邮件、浏览器历史)中自动拉取信息,组装出一份你手动写需要 30 分钟的工作简报。模板 14:会议笔记处理器。把杂乱无章的会议录音转写稿,压缩成五个结构化部分:已达成的决议、责任人及截止时间、待解决的问题、重要原话记录、下一步行动。关键细节是加入了 [不清楚] 标签 —— 和反幻觉护栏的逻辑一样,不确定的内容就标注出来,不要主观猜测。模板 15:技能生成器。这是整套体系中最 “元” 的一个模板 —— 用 AI 来构建你自己的上下文模板。每完成一个任务之后,问 AI 三个问题:这次哪些地方做得好?哪些地方需要我手动修改?下次怎么改进才能做得更好?然后让它根据这些反馈生成一个可保存、可复用的指令模板。只要坚持几周积累模板,你的整个工作流就会被编码进这些可复用的文件里。系统变得更聪明了,但模型本身并没有任何变化,这才是最关键的一点。这让我想到一个很贴切的类比:你不需要等英特尔推出更快的 CPU 才能让电脑变快。你可以先优化操作系统、配置好常用软件、自动化工作流 —— 在同一块芯片上,使用体验可以有天壤之别。上下文工程做的就是这件事:在同一个大模型的基础上,通过优化 “软件层” 来提升 “硬件” 的实际表现。
 夜雨聆风
夜雨聆风