 夜雨聆风
夜雨聆风





OpenClaw 插件 SmartContext 开发解析(下篇):工程踩坑、降级策略与可复用的设计启发
前两篇我们讨论了问题定位、架构决策和规则设计。这一篇聚焦工程实现——那些在文档里不会写、但实际开发中一定会遇到的事情。
01
—
错误隔离:一个 Skill 损坏,插件不能崩
在测试中,我们遇到了一个典型问题:某个 Skill 的 Markdown 格式写错了(比如缺少了一个必需章节),解析器抛出异常。如果这个异常没有被捕获,整个 before_prompt_build钩子就会失败,导致这次对话没有注入任何准则。
更严重的情况是:如果异常发生在插件加载阶段,OpenClaw 可能拒绝加载整个插件。
解决方案很简单,但必须严格执行:所有 Skill 加载和解析操作,都必须包裹在 try-catch 中。
try {const content = fs.readFileSync(skillPath, 'utf-8');return parser.parse(content, domainId);} catch (error) {logger.warn(`Failed to load skill ${domainId}: ${error.message}`);return null; // 跳过该 Skill,不影响其他}
同样,在 generate()主流程中,任何异常都要捕获,并返回一个基础的降级准则:
try {// 正常生成逻辑} catch (error) {logger.error(`Guideline generation failed: ${error}`);return this.promptBuilder.buildFallback(); // 返回通用准则}
这个原则可以推广到任何插件开发:单个扩展点的失败,不应导致整个扩展失效。优雅降级比完美主义更重要。
—
配置持久化:为什么不用 OpenClaw 的主配置
OpenClaw 有自己的配置系统,插件可以通过 api.config读写配置。但 SmartContext 选择了独立的磁盘文件 smartcontext-config.json,存放在 stateDir目录下。
原因是:SmartContext 的配置是运行时频繁修改的。用户通过 /smartcontext-add、/smartcontext-set-role等命令随时调整活跃领域和角色标签。如果每次修改都要写回 OpenClaw 的主配置文件,可能会触发配置重载,甚至需要重启服务。
独立的配置文件允许插件独立管理自己的状态,不影响主系统。ConfigStore类封装了读写逻辑:
classSmartContextConfigStore{private configPath: string;private currentConfig: SmartContextConfig;loadConfig(): SmartContextConfig { ... }saveConfig(config: Partial<SmartContextConfig>): void { ... }}
每次命令执行后立即 saveConfig,确保配置持久化。下次 OpenClaw 重启时,插件从磁盘加载,状态不丢失。
03
—
性能:缓存策略与懒加载
Skill 文件在每次 generate()时都会重新读取和解析吗?显然不是。
设计中有两层缓存:
1. Skill 规则缓存
SkillLoader使用 RuleCache缓存已解析的 Skill 对象,TTL 为 5 分钟。这意味着在 5 分钟内,同一个 Skill 不会被重复解析。
class RuleCache<K, V> {private cache = new Map<K, { value: V; expiresAt: number }>();get(key: K): V | undefined { ... }set(key: K, value: V): void { ... }}
2. 准则缓存
GuidelineEngine可以根据 activeDomains和 roleTags的组合生成缓存键,如果组合未变化,直接返回缓存的准则文本。这避免了重复的规则组合和 Prompt 拼接。
但有一个权衡:准则缓存会降低实时性。用户通过命令修改配置后,缓存必须立即失效。设计文档中给出了 invalidate方法,在配置变更时调用。
04
—
命令接口:为什么提供 10 个 CLI 命令
SmartContext 提供了 10 个用户命令:/smartcontext-config、/smartcontext-list、/smartcontext-use、/smartcontext-add、/smartcontext-remove、/smartcontext-set-role、/smartcontext-add-role、/smartcontext-remove-role、/smartcontext-clear-role、/smartcontext-pin、/smartcontext-unpin。
之所以提供上述命令,除了上篇提到的“即时性”和“可发现性”,还有一个更深层的设计考量:绕过 LLM。
用户修改配置(切换领域、添加角色标签、标记重要内容)是确定性操作,不需要 LLM 的理解和推理。如果用自然语言让 LLM 去执行,比如用户说“帮我切换到软件工程领域”,LLM 需要:
-
理解这句话的意图
-
调用对应的工具或 API
-
处理可能的歧义(“软件工程”是不是有效领域名?)
这个过程引入了不必要的复杂性和错误风险。而 CLI 命令是直接的:/smartcontext-use software-engineering命中命令处理器,直接修改配置文件,返回结果。没有 LLM 参与,没有歧义,没有额外的 token 消耗。
这个原则可以推广:凡是用户意图明确、操作确定性的场景,都应该提供绕过 LLM 的直接路径。LLM 擅长的是模糊理解和生成,不是执行确定性指令。
05
—
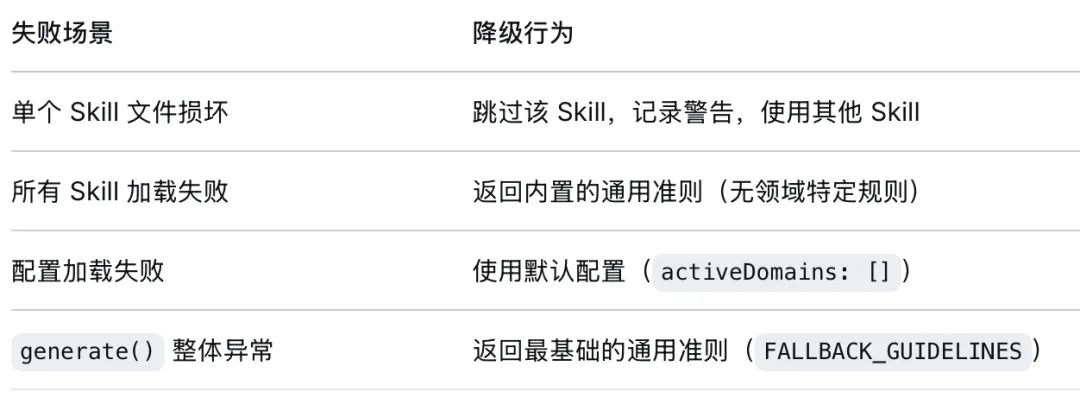
降级策略:当一切都不工作时
我们设计了多级降级:
06
—
可复用的设计启发
回顾 SmartContext 的整个设计过程,有几个模式可以复用到其他插件开发中:
1. 职责边界表
在开始编码之前,明确列出“我做”和“我不做”。这张表既是设计文档,也是未来维护的契约。当有人想往插件里加“上下文压缩”功能时,这张表会告诉他:这不是 SmartContext 该做的事。
2. 错误隔离优先于功能完整
一个扩展点失败,插件继续运行,只是少了那个功能。这个原则比“保证所有扩展点都稳定”更务实,也更健壮。
3. 配置独立于主系统
运行时频繁修改的配置,放到独立的存储中。不要依赖主配置系统的生命周期。
4. 命令是配置的可发现界面
为每个可配置项提供至少一个命令,让用户不需要读文档就知道怎么修改。同时也避免了反复的请求LLM,提供效率的同时,减少Tokens 的消耗。
5. 降级是设计的一部分
从一开始就设计“如果 X 失败怎么办”,而不是出了问题再补。降级准则不是临时方案,而是正式交付物。
6. 缓存要配合失效机制
缓存很好,但必须提供显式的失效接口。配置变更、Skill 文件更新时,缓存要能即时清空。
07
—
总结:从插件到模式
SmartContext 不是一个复杂的插件——它的核心代码只有几个模块,总计不到 2000 行。但它的设计过程反映了一个更深层的问题:当我们说“让 AI 更好用”时,我们到底在做什么?
答案不是“给 AI 加更多功能”,而是“给 AI 一个更好的工作框架”。SmartContext 不改变模型的能力,它改变的是模型对已有信息的注意力分配。这个思路可以推广到很多场景:代码审查助手、医疗对话系统、法律文档分析……本质上都是“在专业领域内,教会模型什么更重要”。
三篇文章到此结束。我们从痛点出发,走过架构决策、规则设计、工程实现,最后提炼出可复用的设计模式。希望这个复盘对正在构建智能体系统的你有所启发。
SmartContext 插件基于 OpenClaw Plugin SDK 实现,完整代码和文档可在 GitHub 上找到(https://github.com/hherosoul/Plugins/tree/main/SmartContext)。