 夜雨聆风
夜雨聆风





12nm AI SoC后端实战——专家1v1辅导
00
景芯SoC后端实战课汇总
-
实战课1:12nm CPU CORE flatten实战课
-
实战课2:12nm CPU TOP hierarchy实战课
-
实战课3::40nm TOP实战课 (入门级、全芯片、带IO PAD)
01
景芯12nm低功耗UPF 后端实战简介
02
景芯12nm CPU CORE flatten实战课
在每个阶段PR结束之后,对子模块或者TOP顶层进行Calibre DRC, LVS,EM,ERC,ANT,ESD等检查,StarRC抽参,STA,lc生成lib文件等。使用xtop/pt进行timing eco修复setup/hold违例,LEC逻辑等价性检查。VCLP低功耗设计静态检查,voltus功耗和压降评估,redhawk功耗和IR Drop分析,后仿真等等。课程的设置真的非常全面,涵盖了芯片DFT+后端物理实现直到tapout的全流程。
Part.01
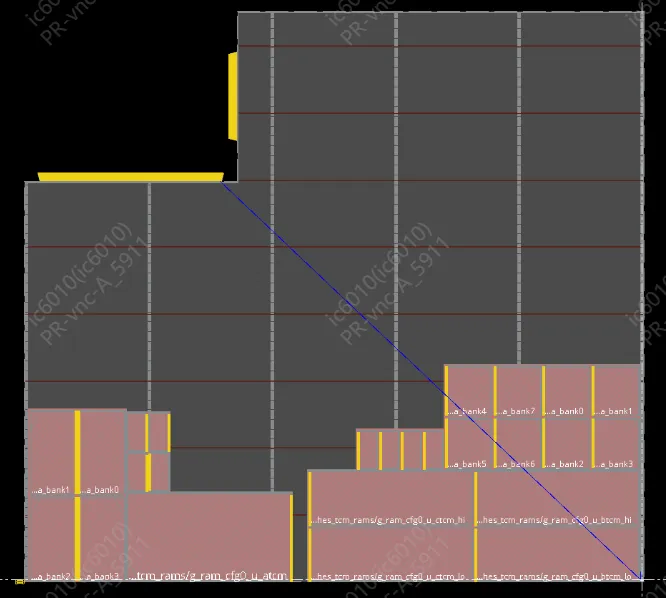
core flat实战课目录之pre-APR
课程的设置真的非常全面,涵盖了芯片DFT+后端物理实现直到tapout的全流程。


在每个阶段PR结束之后,对子模块/TOP顶层进行Calibre DRC, LVS,EM,ERC,ANT,ESD等检查。
Part.02
core flat实战课目录之APR+PV
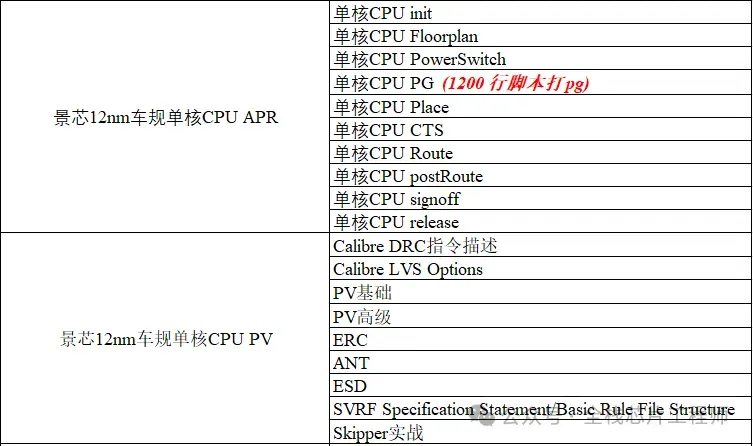
StarRC抽参,STA,lc生成lib文件等。使用xtop/pt进行timing eco修复setup/hold违例。
Part.03
core flat实战课目录之STA
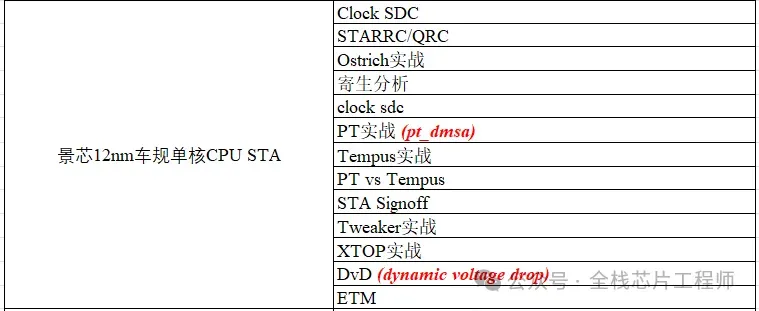
VCLP低功耗设计静态检查,LEC逻辑等价性检查
Part.04
core flat实战课目录之LEC

Part.05
core flat实战课目录之PA
03
景芯12nm CPU TOP hierarchy实战课
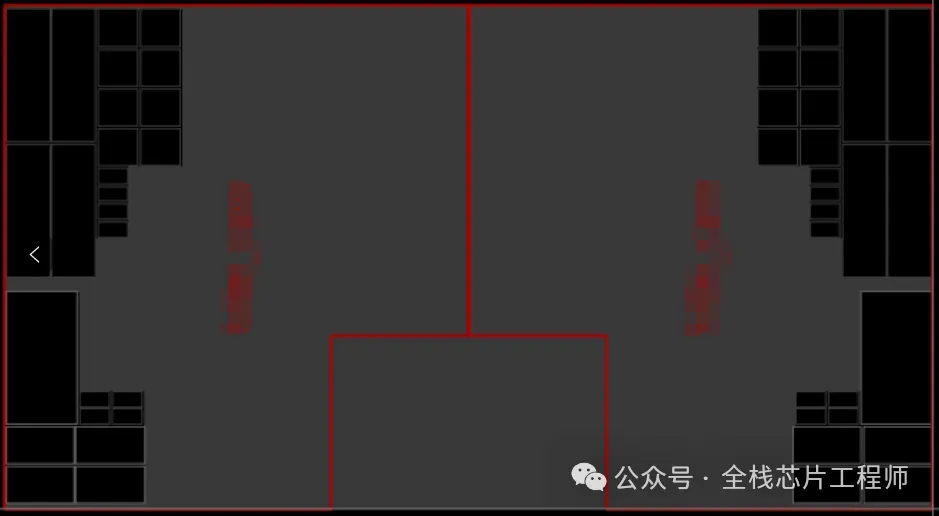
在每个阶段PR结束之后,对子模块或者TOP顶层进行Calibre DRC, LVS,EM,ERC,ANT,ESD等检查,StarRC抽参,STA,lc生成lib文件等。使用xtop/pt进行timing eco修复setup/hold违例,LEC逻辑等价性检查。VCLP低功耗设计静态检查,voltus功耗和压降评估,redhawk功耗和IR Drop分析,后仿真等等。课程的设置真的非常全面,涵盖了芯片DFT+后端物理实现直到tapout的全流程。
Part.06
TOP hierarchy实战之TOP

Part.07
TOP hierarchy实战之CTS基础
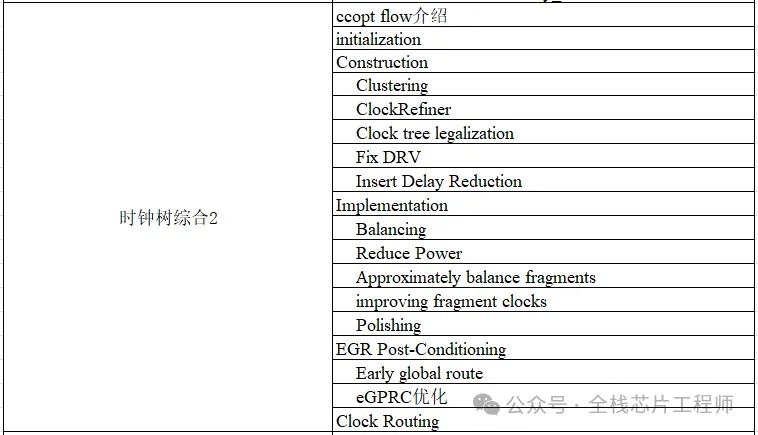
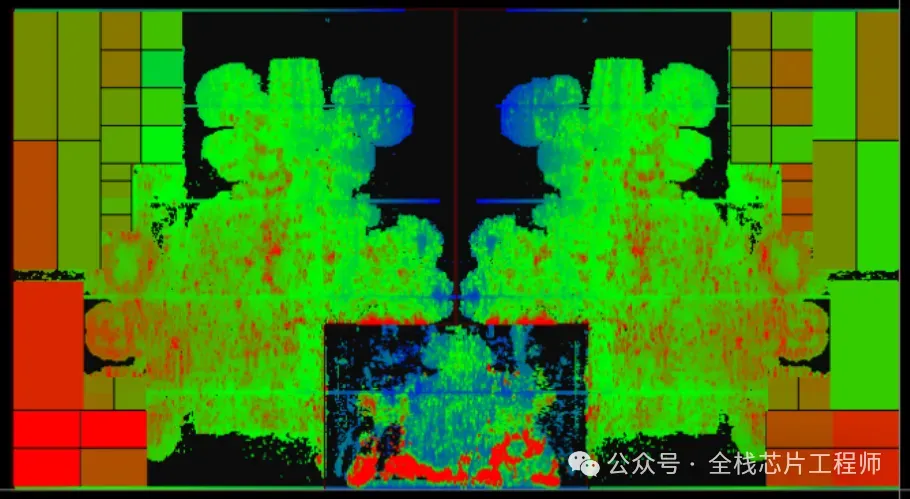
Part.08
TOP hierarchy实战之CTS高级



Part.09
TOP hierarchy实战之高级hierarchy实战

Part.10
TOP hierarchy实战之Tweaker
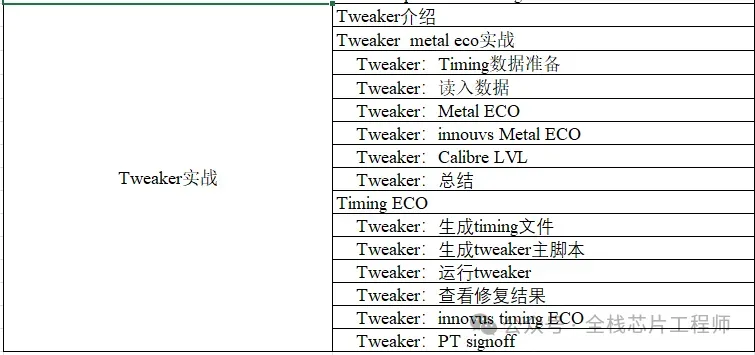
04
景芯SoC 40nm后端实战课
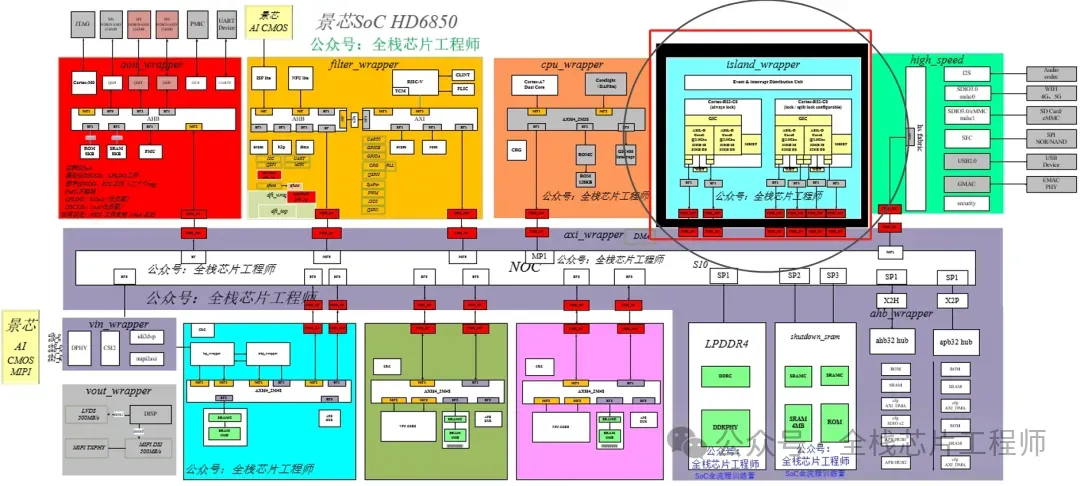
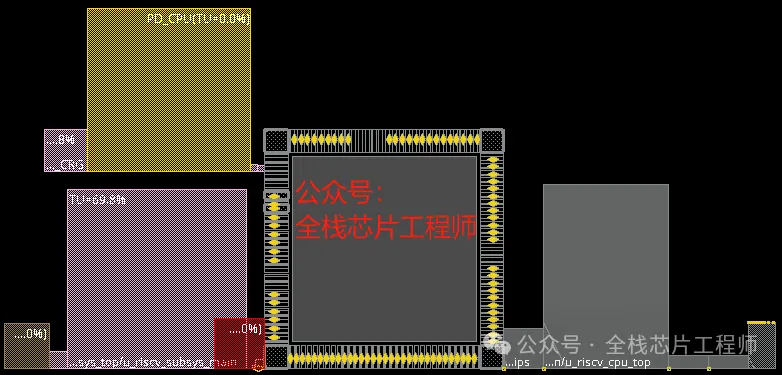
景芯团队专家老师1v1辅导学员,让您快速超越同龄人!景芯训练营主打文档+服务器实战,我们不卖视频,只提供免费导学视频!我们选取景芯HD6850项目中的橙色域子系统(下图橙色部分)进行全流程实战培训,实战内容包括设计、验证、中端、后端全流程。希望您成为公司的中流砥柱后,给景芯团队介绍design servie业务(有提成),共同进步!
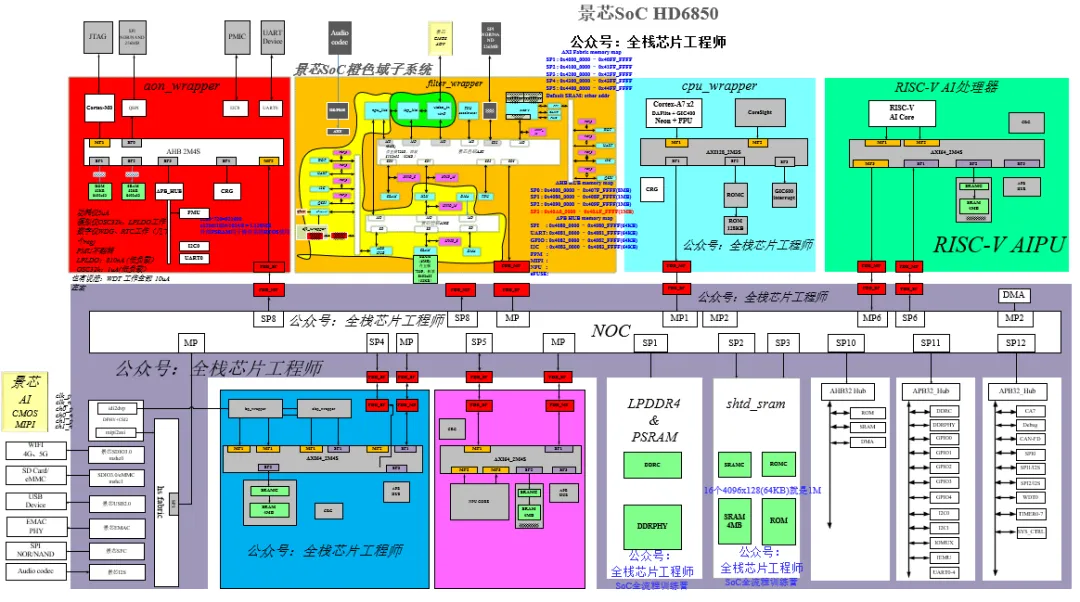
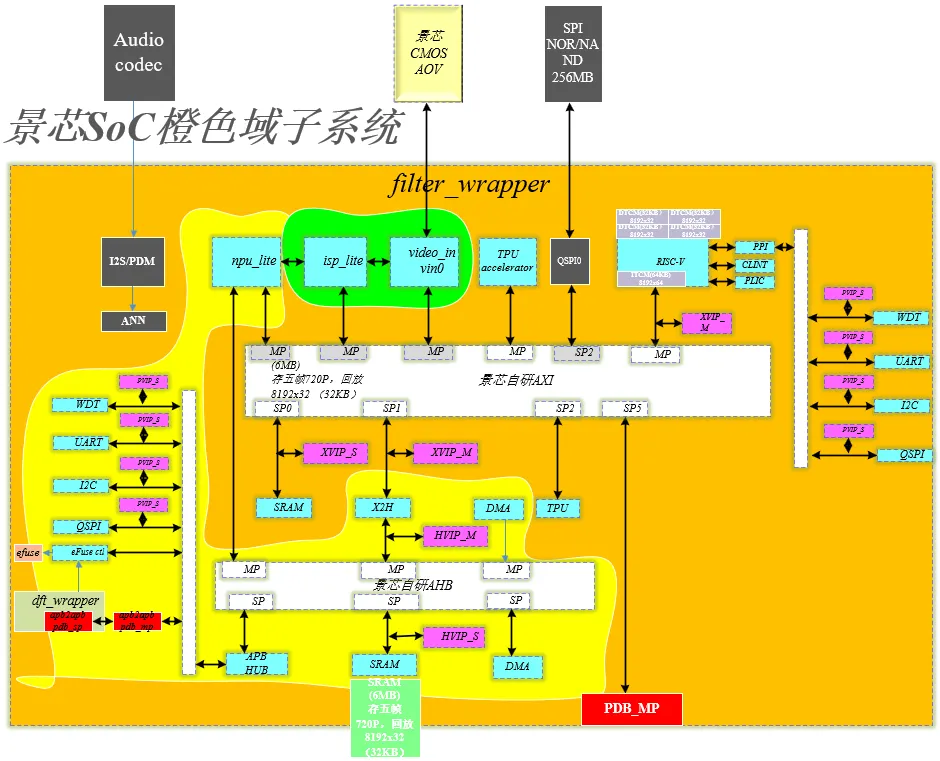
橙色子系统采用低功耗RISC-V自研架构,全部自研实现了AXI总线矩阵、AHB总线矩阵、MIPI DPHY软核、ISP-Lite、NPU-lite、SRAM、DMA、UART、I2C、QSPI/SPI等常用IP,项目设计验证架构如下:
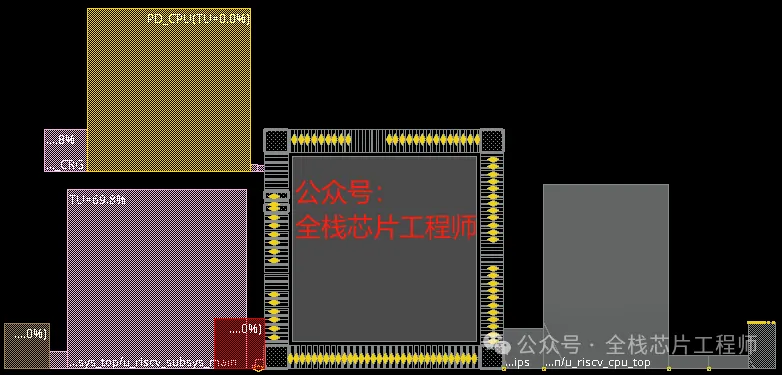
Part.01
后端实战目录
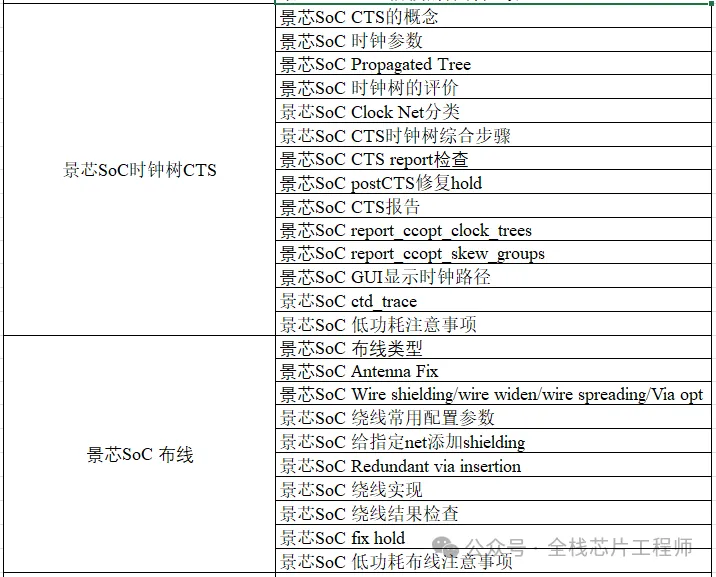
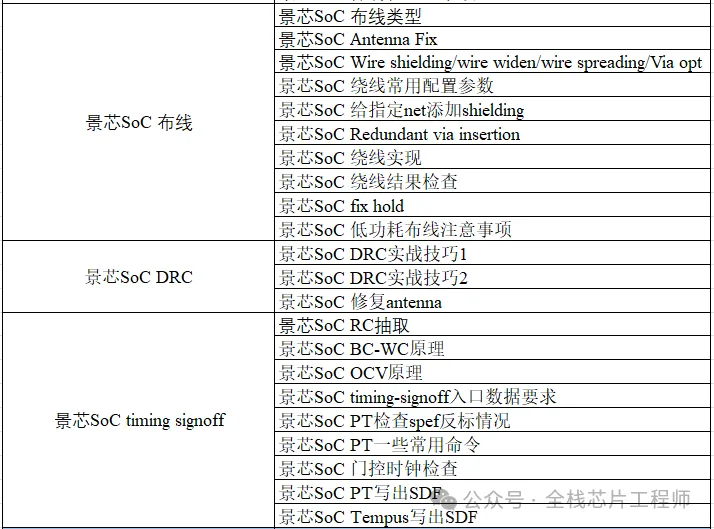
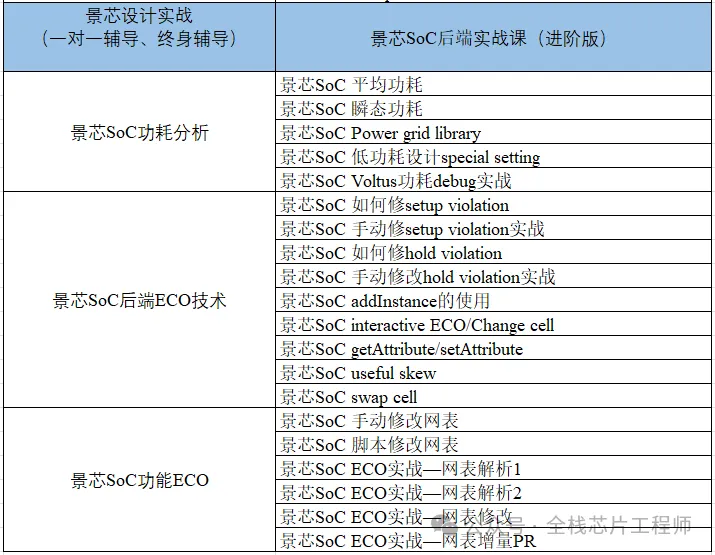
终身辅导、一对一辅导是景芯SoC训练营的特色!景芯SoC后端实战基础课最新课表如下:
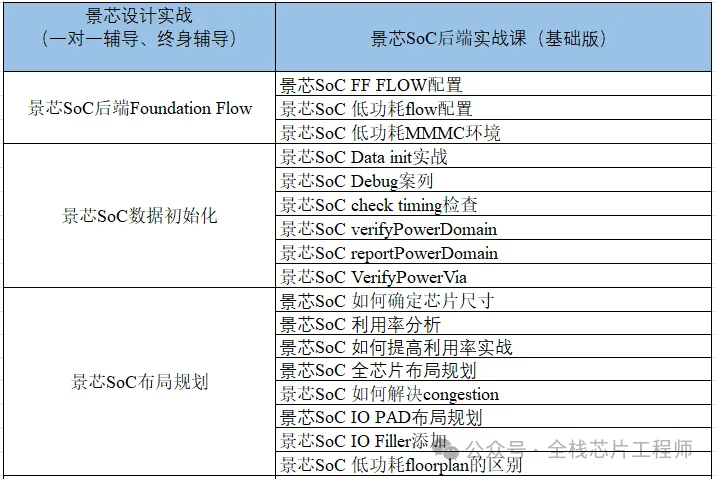
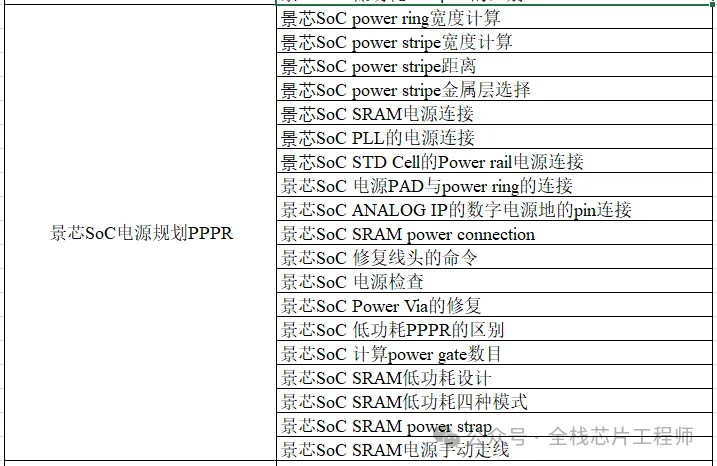
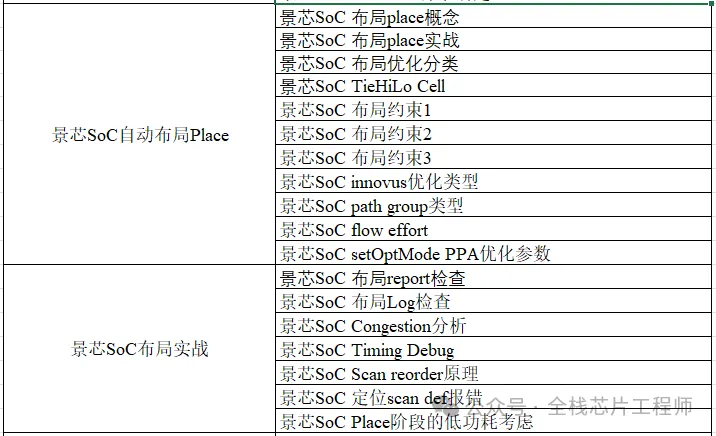
全芯片UPF低功耗设计(含DFT设计)
景芯SoC训练营培训项目,低功耗设计前,功耗为27.9mW。

低功耗设计后,功耗为0.285mW,功耗降低98.9%!

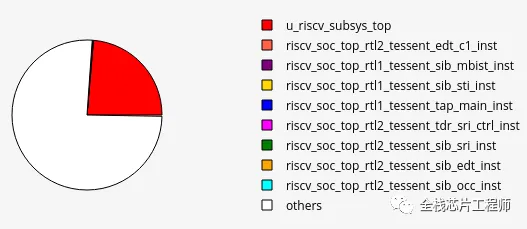
电压降检查:
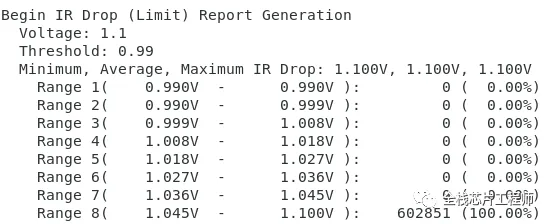
低功耗检查:
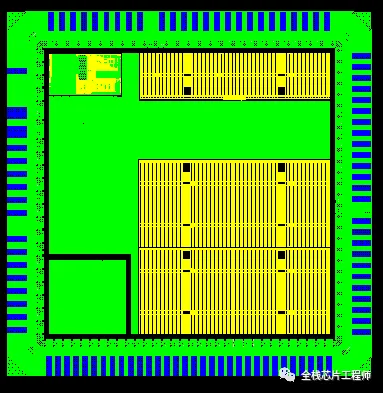
芯片的版图设计V4.0
低功耗设计的DRC/LVS,芯片顶层的LVS实践价值极高,具有挑战性!业界独一无二的经验分享。

Part.01
课程报名微信,扫描咨询我们吧

景芯SoC芯片全流程实战附属【知识星球】,一个包括设计、验证、DFT、后端全流程技术的交流平台,也是景芯学员的答疑平台!若您和我一样渴求技术,那欢迎扫下面二维码加入星球,共同进步!

09
学员好评
先说结论:课程内容非常全面,讲解到位,会有专门的工程师一对一答疑,整个项目跑下来提升非常大,绝对物超所值!

一些细节:
本人微电子专业研一在读,有过两次简单的数字芯片流片经历,出于学习和科研需要,报名了景芯SoC的12nm 高性能CPU UPF DVFS后端课程。
整个项目基于innovus实现,主要包括芯片partition、maia_cpu的PR和MAIA顶层的PR三个阶段。在每个阶段PR结束之后,对maia_cpu ip核/MAIA顶层进行Calibre DRC, LVS检查,StarRC抽参,pt抽参,lc生成lib文件,使用xtop/pt进行timing eco修复setup/hold违例,LEC逻辑等价性检查,VCLP低功耗设计静态检查,voltus功耗和压降评估,redhawk功耗和IR Drop分析等等。个人觉得课程的设置真的非常全面,涵盖了芯片后端物理实现直到tapout的全流程,本人在跑这套后端flow的过程中也了解到很多非常实用的后端EDA工具和功耗/时序的分析/修复方法。
项目整体流程和部分文档
在partition阶段,进行初步的floorplan,划分电压域,并实现顶层的电源网络。如下图所示,整颗芯片包含两颗高性能cpu核,若干L2 $,一些常开模块和PMU模块等等。整颗芯片共划分了6个电压域。(顺便提一句,我觉得整个项目唯一美中不足的地方是顶层芯片没加PAD,景芯的另一个soc项目有加PAD的流程)

MAIA before partition

MAIA partition
maia_cpu阶段实现单颗高性能CPU的PR,这部分流程就比较常规了,首先导入之前partition好的maia_cpu部分的def,随后进行单颗maia_cpu的floorplan、摆放powerswitch和各种tapcell, endcap、电源网络设计、摆放标准单元、时钟树综合、二级电源连线、信号布线、各种check和verify、release等。但是!让我眼前一亮的有两点,一个是12nm的电源网络的via pillar处理方式,另一个是ICG单元的特殊处理和整个时钟网络的balance,还是学到不少新东西的。
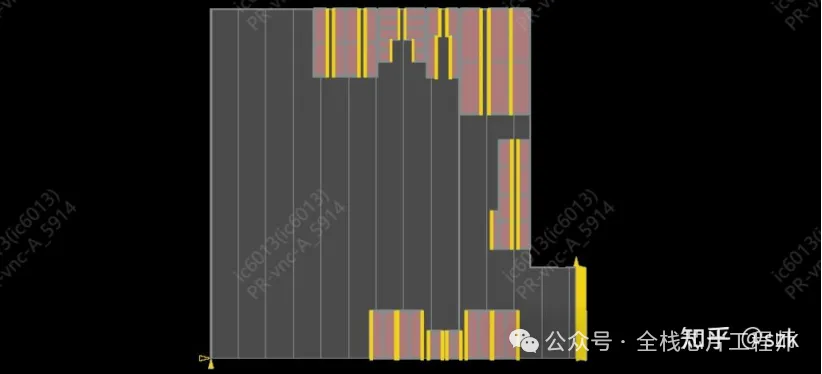
A72 maia_cpu floorplan
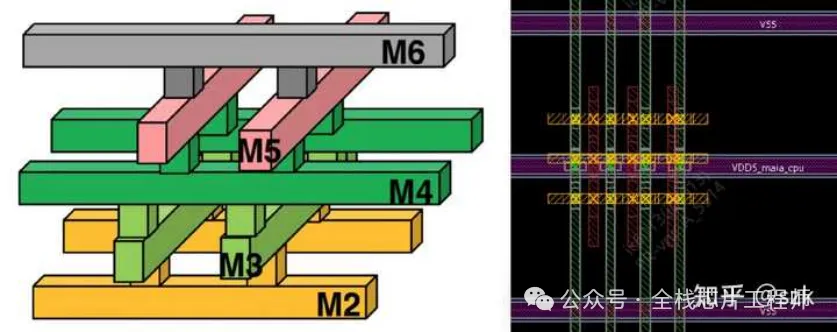
via pillar
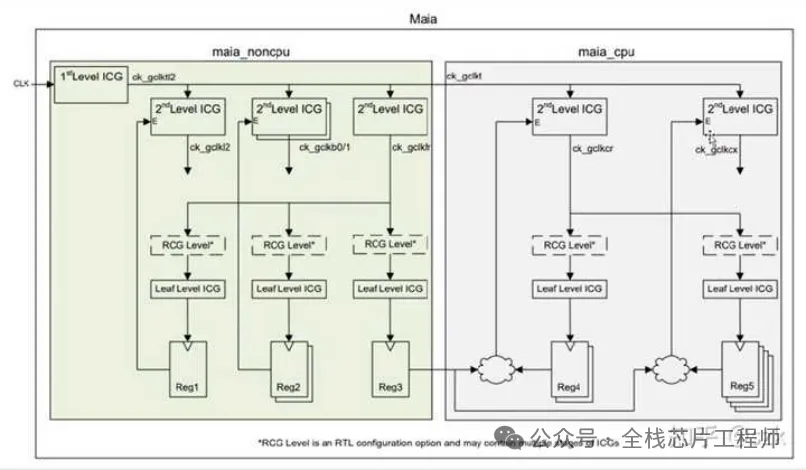
overview of ICGs
完成maia_cpu后,我先进行starRC、pt抽参,随后使用xtop优化setup和hold,并再次打开innovus使用xtop生成的脚本自动进行eco修复timing。确认时序没有违例后,使用Calibre进行DRC、LVS检查,不出所料有很多DRC违例,LVS不通过。但是!!!景芯的一对一辅导真的很靠谱,有几个较难的DRC和LVS问题,工程师会一步步帮忙找bug并进行eco,整个过程非常专业并且工程师真的非常非常有耐心。最后如愿DRC和LVS clean。
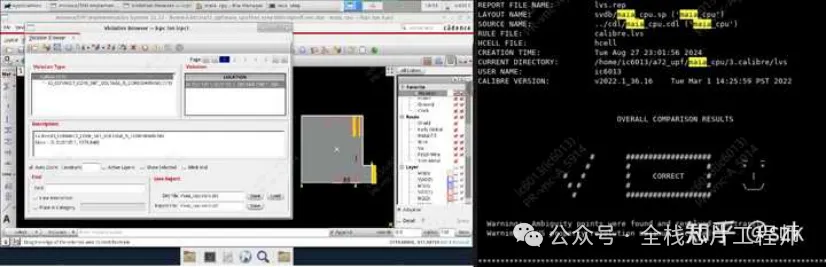
DRC/LVS results
对maia_cpu进行一系列LEC检查和功耗、压降检查后,就可以进行最后一步MAIA顶层的布局布线了。依次读入各种lib和lef文件、maia_cpu的def和partition阶段产生的MAIA顶层的def,随后与maia_cpu相同,进行floorplan、电源网络、时钟树综合等等,不再赘述。
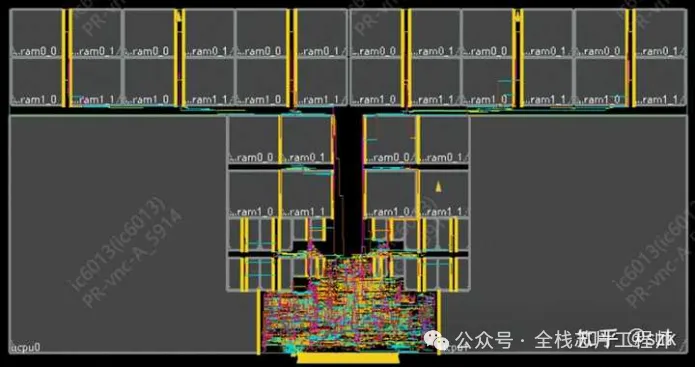
MAIA after CTS
整体来说我觉得这个项目是非常完善的,DRC、LVS、时序、功耗、压降等各种检查都有涉及;同时项目也非常有难度,不仅芯片规模大,制程先进(12nm),还涉及很多UPF的相关内容。景芯课程视频和实践相结合的授课方式也非常有效,课程的课程视频会大量讲解一些原理性的内容,比如MCMM、UPF的一些基本概念和环境配置、时钟树的基本理论和该项目的时钟树结构的设计方法、顶层模块的时序约束、POCV/SOCV时序报告解读等等,而上机实践的部分则需要自己动手跑脚本,发现bug并尝试解决,锻炼工程能力。此外,我觉得课程很贴心的一点是,上机实践的部分在关键步骤都准备了golden结果,如果当下bug不能立即解决可以先跳过,使用提供的golden先体验一下整个后端流程,回过头再来解决一些细节问题。跑完整个项目真的感觉收获满满,在理论和实践上都有很大提升,但是感觉依然有很多内容没有完全掌握,整个flow中的很多细节都没注意到,很多工具也只是马马虎虎跑了个脚本。
最后!我觉得这个课程最值的一点就是有专门的工程师全程答疑,工程师回消息特别快,解决方案也很细致,除了解决一些具体的bug之外,有时候还会讲解一些原理性的内容,分享一些工程经验等等,真的能学到很多除脚本之外的东西!非常推荐!
(另外: 我觉得景芯SoC的12nm 高性能CPU UPF项目整体难度有点大,如果是新手的话建议先报景芯的soc后端实践课,再来尝试景芯SoC的12nm 高性能CPU的进阶课程)
08
FinFET工艺的数字后端难在哪里?
掌握FinFET工艺的后端工程师是芯片公司的核心资源。12nm及以下项目经验成为求职时的“硬通货”,下一代工艺(如3nm的GAAFET)的许多挑战与FinFET一脉相承(如3D结构建模、复杂寄生参数提取),早期积累的经验对未来技术升级至关重要。若后端工程师不掌握12nm先进工艺,将无法参与主流芯片项目。
半导体行业长期遵循摩尔定律(晶体管密度每18-24个月翻倍),推动工艺节点不断缩小(如12nm、7nm、5nm等)。12nm及以下节点采用FinFET结构,FinFET通过三维立体结构(鳍片)增强栅极对沟道的控制,显著降低了漏电流(Leakage Power),同时提高了驱动电流(性能),解决了传统平面晶体管(Planar FET)在更小节点下的漏电流和功耗失控问题。FinFET工艺难点主要体现在:
-
物理效应加剧:在12nm及以下节点,量子效应、工艺波动(PVT)、寄生效应(RC Delay)、电迁移(EM)等问题更加显著,后端工程师需要应对更复杂的时序收敛(Timing Closure)、信号完整性(SI)和功耗优化(如动态IR Drop)。
-
设计规则复杂化:先进工艺的设计规则(DRC/LVS)和制造约束(DFM)成倍增加,例如多重曝光(Multi-Patterning)、Fin切割规则、金属层堆叠等,需要后端工具和流程的全面升级。
 。
。10
2.5GHz UPF hierarchy TOP实战问题分享
12nm 2.5GHz的高性能CPU实战训练营需要特别设置Latency,TOP结构如下,参加过景芯SoC全流程训练营的同学都知道CRG部分我们会手动例化ICG来控制时钟,具体实现参见40nm景芯SoC全流程训练项目,本文介绍下12nm 2.5GHz的A72实战训练营的Latency背景,欢迎加入实战。
时钟传播延迟Latency,通常也被称为插入延迟(insertion delay)。它可以分为两个部分,时钟源插入延迟(source latency)和时钟网络延迟(Network latency)。
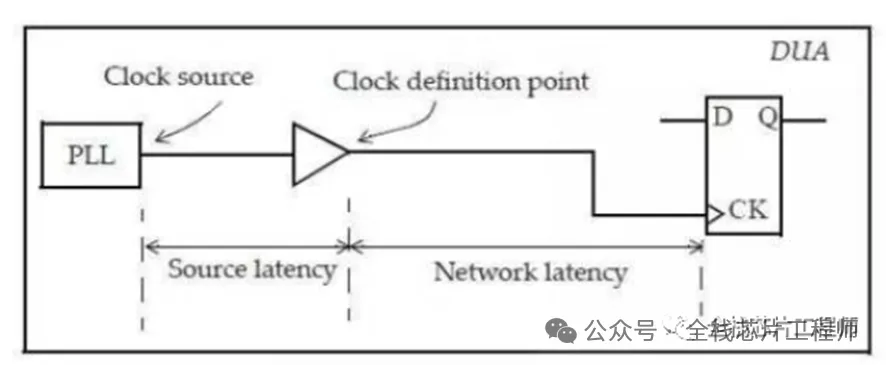
大部分训练营同学表示平时都直接将Latency设置为0了,那latency值有什么用呢?其实这相当于一个target值,CTS的engine会根据你设置的latency值来插入buffer来实现你的latency target值。
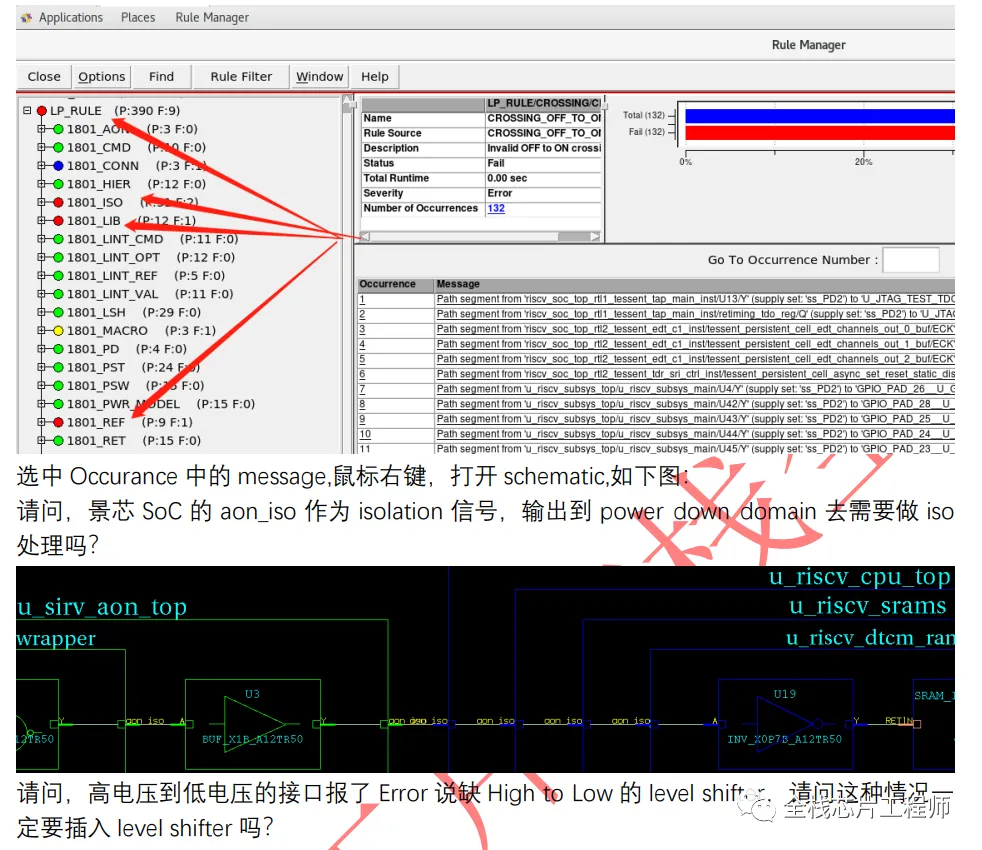
下图分为1st Level ICG和2nd Level ICG,请问这些ICG为什么要分为两层?
请问,为什么不全部把Latency设置为0?2nd Level ICG的latency应该设置为多少呢?
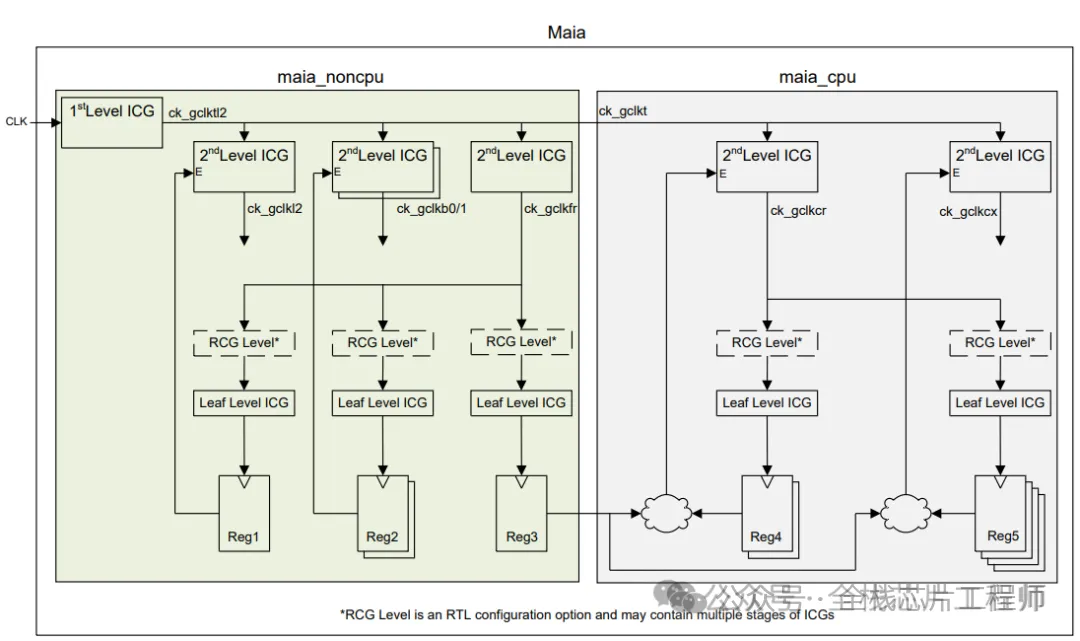
latency大小直接影响clock skew的计算。时钟树是以平衡为目的,假设对一个root和sink设置了400ps的latency值,那么对另外的sink而言,就算没有给定latency值,CTS为了得到较小的skew,也会将另外的sink做成400ps的latency。请问,为何要做短时钟树?因为过大的latency值会受到OCV和PVT等因素的影响较大,并有time derate的存在。
分享个例子,比如,景芯SoC的12nm 高性能CPU低功耗设计,DBG domain的isolation为何用VDDS_maia_noncpu供电而不是TOP的VDD?
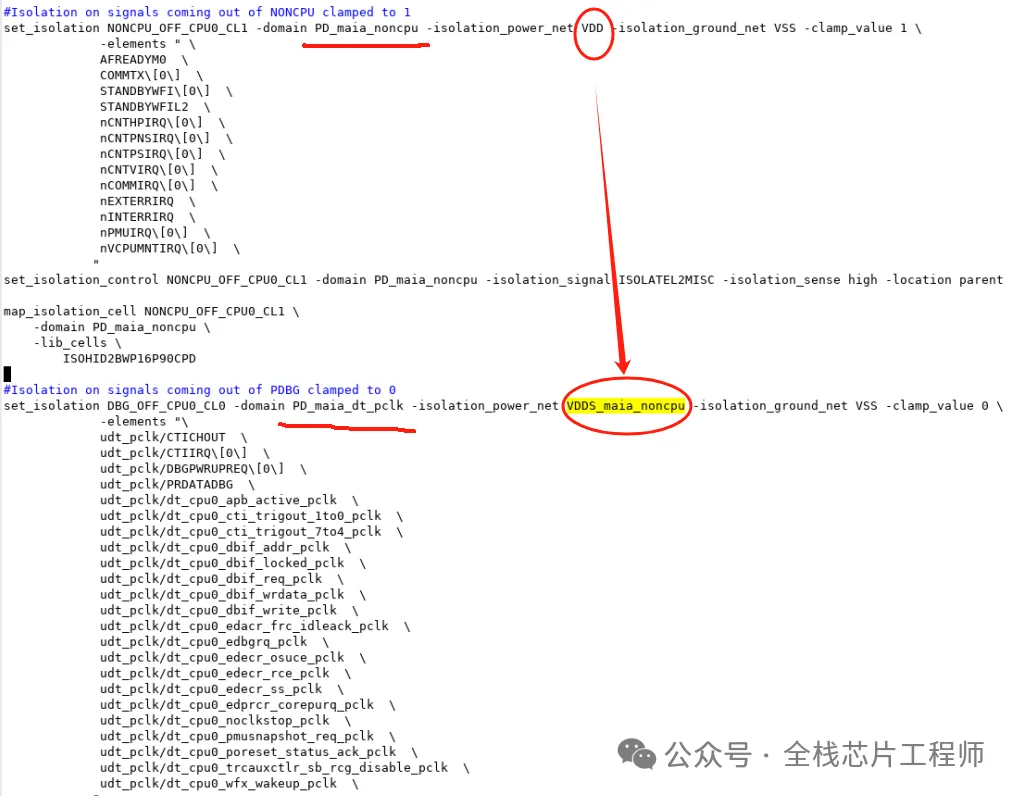
答:因为dbg的上一级是noncpu,noncpu下面分成dbg和两个tbnk。
再分享个例子,比如,景芯SoC的12nm 高性能CPU低功耗设计,这个switch cell是双开关吗?答:不是,之所以分trickle和hammer,是为了解决hash current大电流,先开trickle,然后再开hammer。
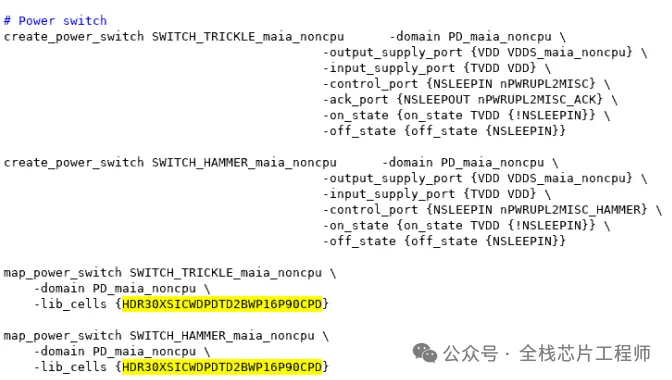
再分享个例子,比如,景芯SoC的12nm 高性能CPU课程的低功耗例子:请问,如果iso cell输出都要放parent,输入放self,那么下面-applies_to_outputs对应的-location为何是self?

答:这个需要了解CPU的内部设计架构,tbnk掉电 VDDS_maia_noncpu也必然掉电,pst如下,所以-applies_to_outputs对应的-location是可以的,那么注意下debug domain呢?

实际上,没有tbnk到debug domain的信号,因此脚本如下:

再分享个例子,比如,景芯SoC的12nm 高性能CPU课程的低功耗例子:为何non_cpu的SRAM的VDD VDDM都接的可关闭电源?SRAM的VDD VDDM分别是常开和retention电源吧?

答:本来是VDDM作为retention电源设计的,VDD关掉后 VDDM可以供电作为retention使用,但是此处没有去做memory的双电源,sram当成单电源使用,不然sram无法彻底断电。
再分享个例子,比如,景芯SoC的12nm 高性能CPU课程有学员的单核cpu LVS通过, 但是多核顶层LVS比对不过,我们来定位一下。
以FE_OFN4326_cfgend_cpu1_o为例,点击下图FE_OFN4326_cfgend_cpu1_o:
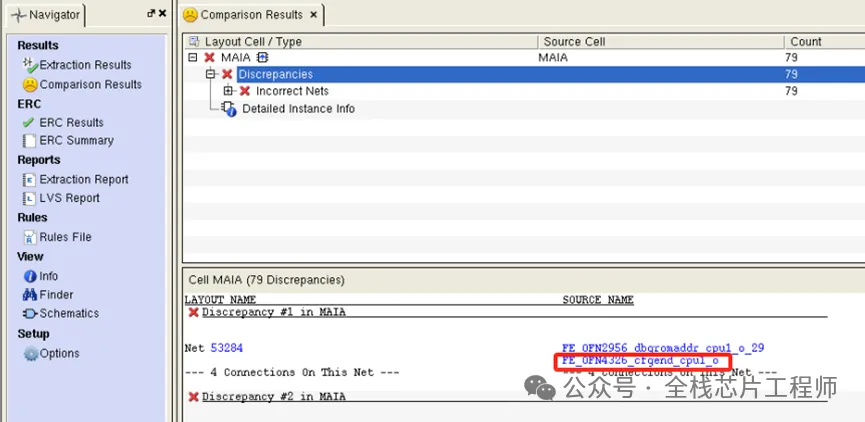
找到calibredrv错误坐标:(1949,139)
对应到innovus去看坐标:(1949,139)
看到maia_cpu的pin脚过于密集,造成顶层连接pin脚时候会无法绕线,从而导致innovus从maia_cpu上面走线,形成short。尽管maia_cpu带了blockage,但是invs没有足够的连接pin的routing resource,也就只能在maia_cpu上面去try了。
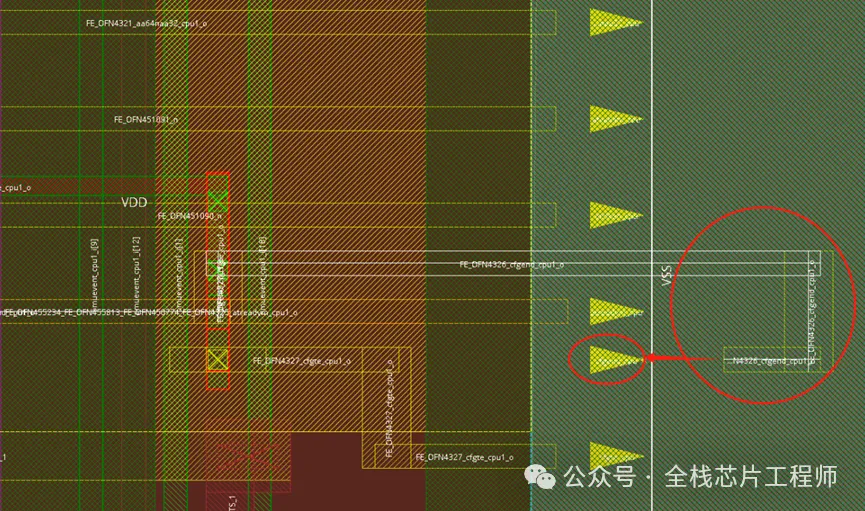
修改办法很简单,具体操作option参见知识星球。
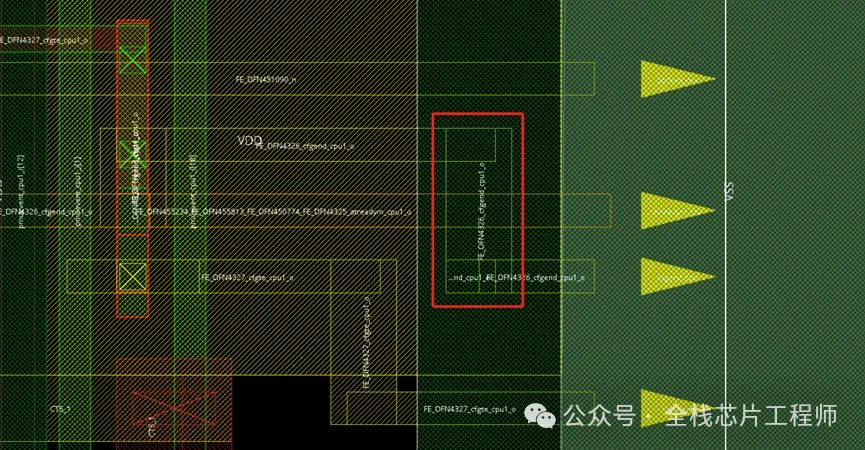
保存db,重新LVS,比对通过。

11
40nm TOP实战问题分享
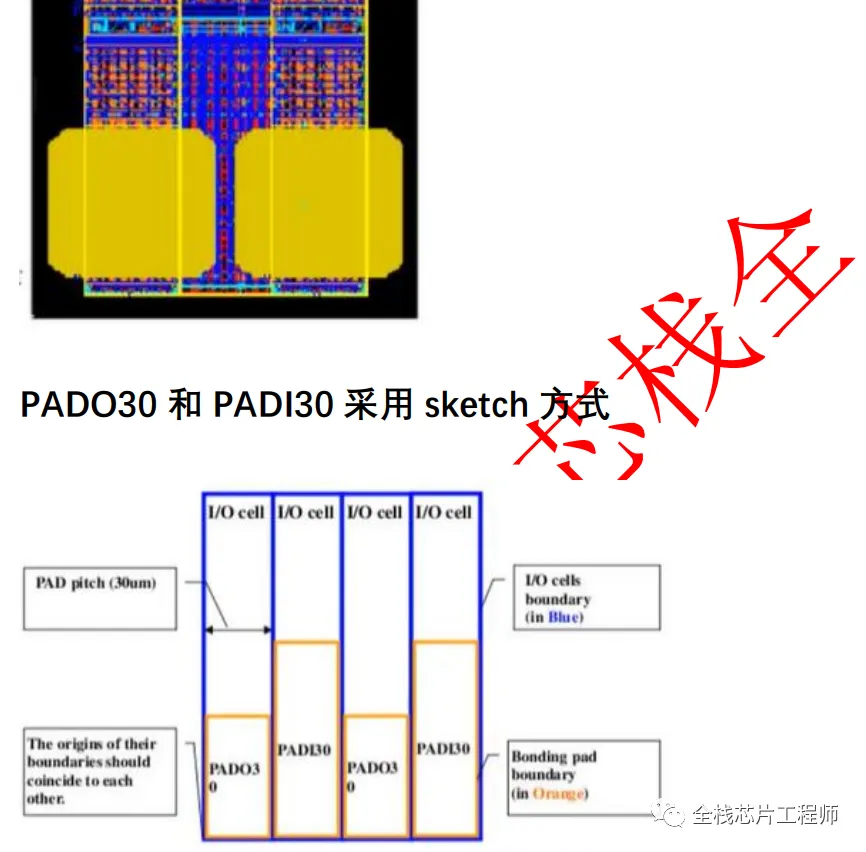
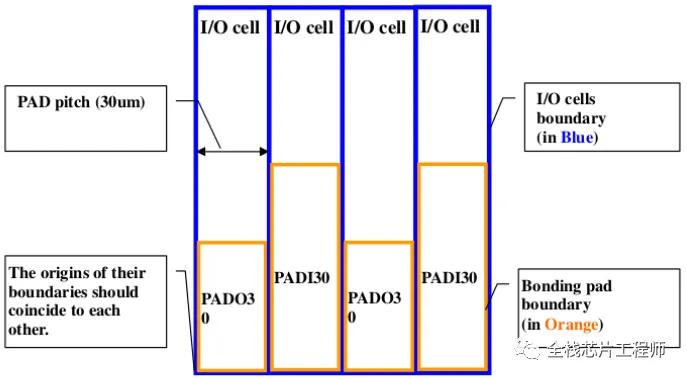
景芯训练营有同学问如何给IO添加PAD?请思考景芯SoC的IO和PAD如何实现最佳?
景芯训练营有同学问,同样的floorplan,有些同学很快跑完,有些同学则遇到大量DRC问题(EDA工具不停iteration)导致工具始终无法跑完,具体什么问题呢?
首先,小编发现该同学的stripe把TM2定义为了horizontal,而熟悉景芯工艺的同学知道,TM2的preference direction是VERTICAL。
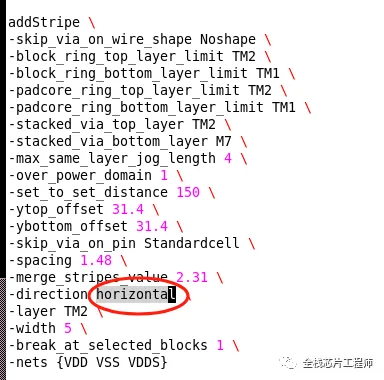
查询景芯的lef库文件也可以确认:

用错方向有多大影响呢?大家上景芯SoC的后端flow实践一下吧,实践出真知。
景芯训练营有同学问,为啥PR花了一天一夜24个小时完成布线还大量DRC错误?小编已经将设计规模尽可能减小以加速PR设计,实际上2小时就可以跑完routing,为何这么慢?原因就是低功耗单元的走线。具体原因及解决办法欢迎加入景芯训练营讨论。
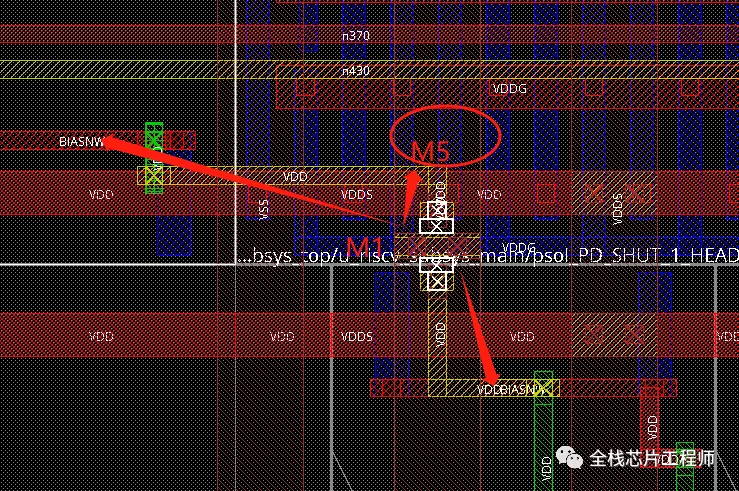
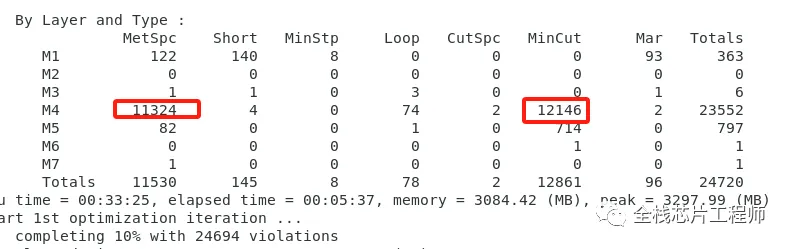
其错误主要集中在M4上,请思考如何解决。
景芯训练营有同学问,power switch cell的secondPG pin(VDDG)从M1接出的,而不是M2, 请思考有什么问题?如何解决?

景芯训练营有同学问,景芯SoC培训营同学遇到Corner Pad LVS不过怎么处理?

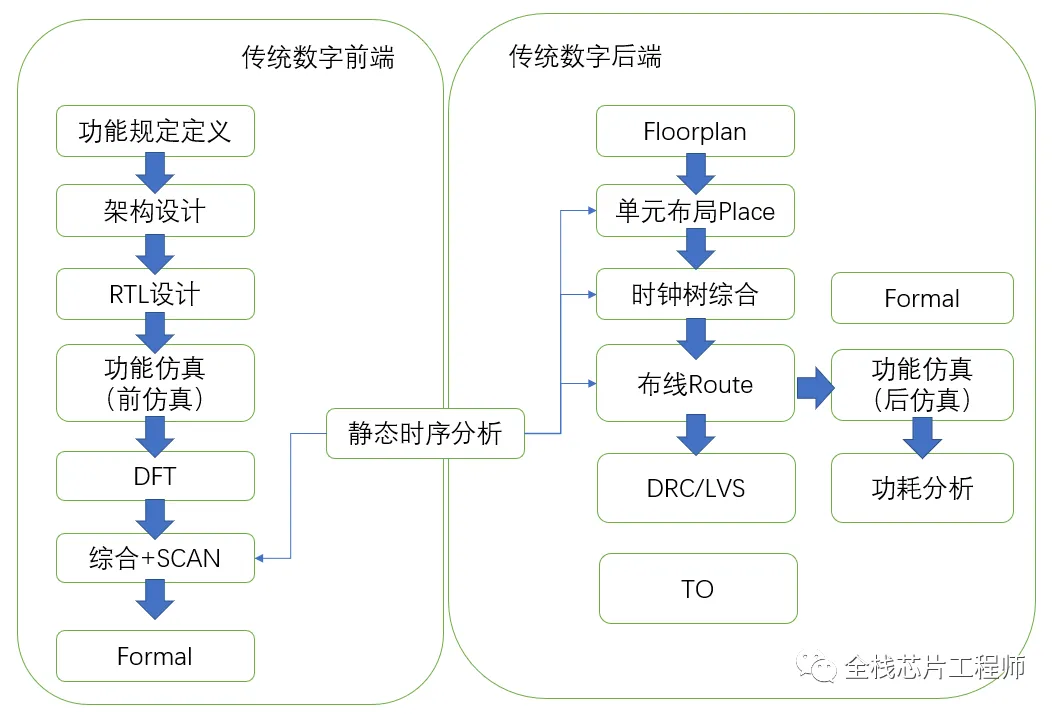
完成景芯SoC培训的前端设计仿真、DFT后,我们来到后端flow,本教程教你一键式跑完数字后端flow。
生成脚本命令如下:
tclsh ./SCRIPTS/gen_flow.tcl -m flat all
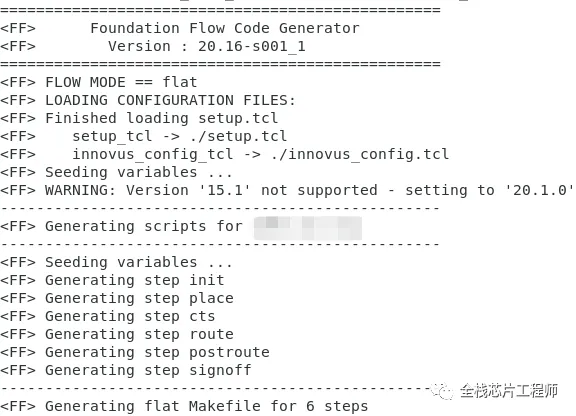
生成flow脚本之前需要配置setup.tcl等相关参数,具体参见【全网唯一】【全栈芯片工程师】提供自研的景芯SoC前端工程、DFT工程、后端工程,带你从算法、前端、DFT到后端全流程参与SoC项目设计。
景芯SoC训练营的同学问,为何innovus读取做好的floorplan def文件报Error? 首先看log:

Reading floorplan file – ./data_in/DIGITAL_TOP.def (mem = 1595.0M).
#% Begin Load floorplan data … (date=10/23 22:38:01, mem=1579.3M)
**ERROR: (IMPFP-710): File version unknown is too old.
以前EDI的时期,我们可以通过定义fp_file的方式来加载floorplan:
set vars(fp_file) “./data_in/DIGITAL_TOP.def”
但是现在innovus升级并放弃了fp_file的加载方式,当然也可以用老版本的EDI9.1及以前版本来加入fp_file,然后转存为新版本,这方式明显没有必要。正如下log提示所说,检查log是非常好的工程师习惯。
Input floorplan file is too old and is not supported in EDI 10.1 and newer.
You can use EDI 9.1 and before to read it in, then save again to create new version.
小编的直觉告诉我,先去看看同学保存的def文件是哪个def版本?
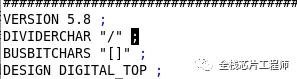
同学保存方式如下:
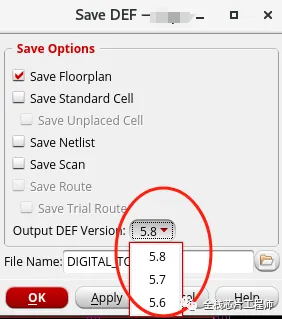
那么请问如何解决?请大家加入景芯训练营实践。
景芯SoC用了很多异步FIFO,关注异步RTL实现的同学,可以抓取异步FIFO出来看一下版图连线:
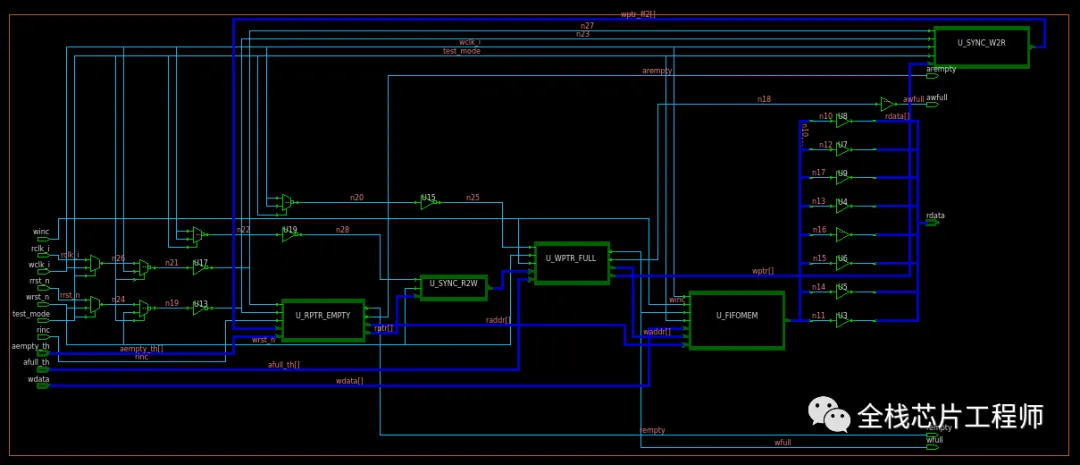
查看下所有异步FIFO cell的面积;
dbget [dbget top.insts.pstatus unplaced -p].area
查下所有异步FIFO的cell的名字:
dbget [dbget top.insts.pstatus unplaced -p].name
那么怎么抓出异步路径来观察版图走线呢?如何让report_timing呢?更多内容参见知识星球和SoC训练营。
Part.03
课程报名微信,扫描咨询我们吧

景芯SoC芯片全流程实战附属【知识星球】,一个包括设计、验证、DFT、后端全流程技术的交流平台,也是景芯学员的答疑平台!若您和我一样渴求技术,那欢迎扫下面二维码加入星球,共同进步!
