 夜雨聆风
夜雨聆风





中国AI真正的实力藏在水面下:一张冰山图看懂27家公司
你看到的AI世界,只有10%是真的
摩尔产业观察发了一张图,把中国AI产业链画成了一座冰山。
冰山水面之上,你看到的是DeepSeek、阿里、字节、腾讯——流量最大、曝光最高、最容易被人叫出名字的那几家。
但水面之下,藏着另外90%。
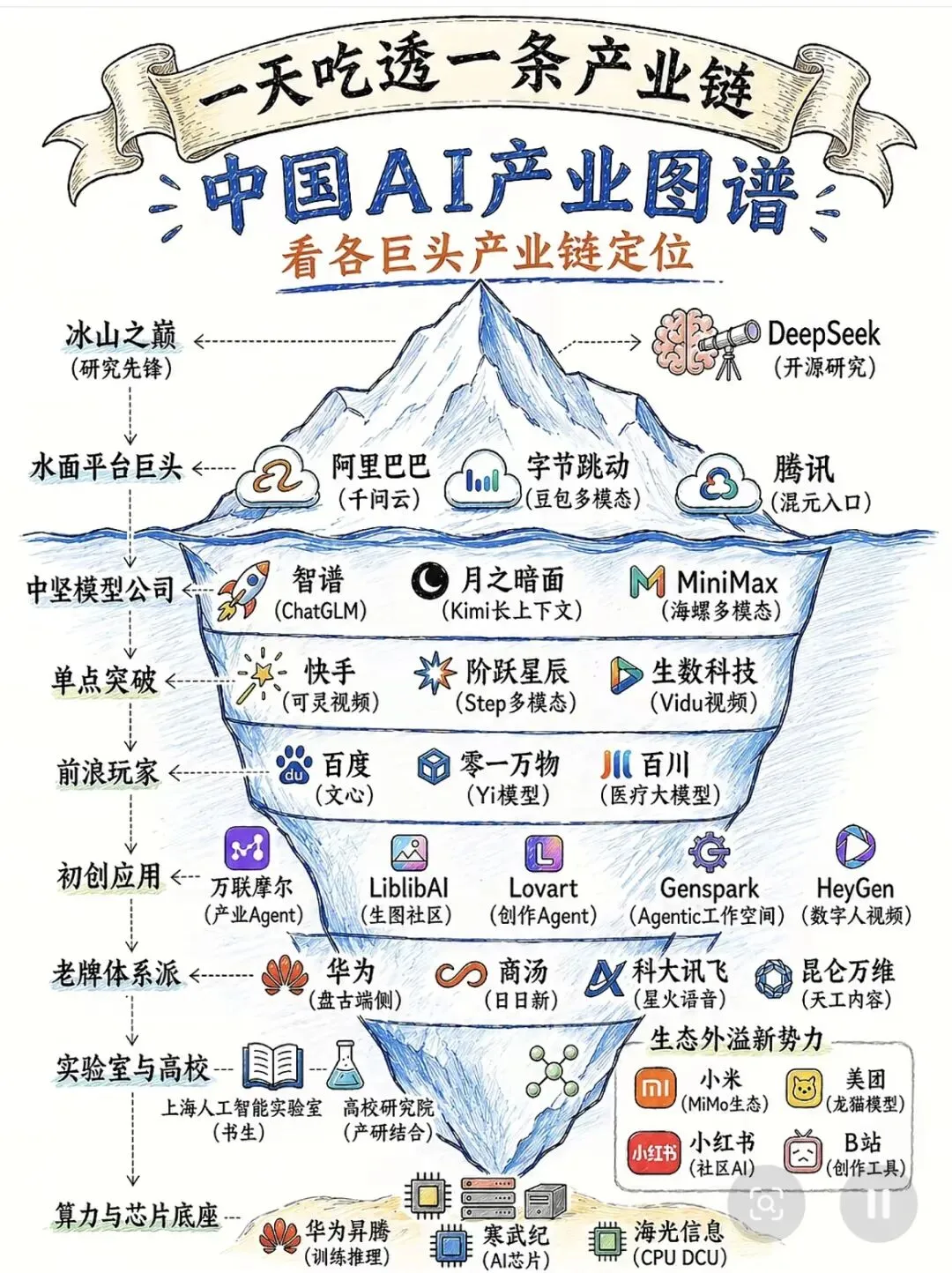
① 冰山之巅:DeepSeek一家独大,开源研究先锋
② 水面平台巨头:阿里千问云、字节豆包多模态、腾讯混元入口——三座流量大山
③ 中坚模型公司:智谱ChatGLM、月之暗面Kimi、MiniMax海螺——模型层的三驾马车
④ 单点突破:快手可灵视频、阶跃星辰Step多模态、生数科技Vidu视频——在垂直场景撕开口子
⑤ 前浪玩家:百度文心、零一万物Yi、百川医疗——先发的,不一定是领先的
⑥ 初创应用:万联泉尔产业Agent、LilyAI生图社、Lovyart创作Agent、Genspark Agent工作室、HeyGen数字人视频——应用层的野蛮生长
⑦ 老牌体系派:华为盘古端侧、商汤日日新、科大讯飞星火语音、昆仑万维天工内容——传统巨头的AI转身
⑧ 实验室与高校:上海人工智能实验室书生大模型、高校产学研结合——国家队底牌
⑨ 算力与芯片底座:华为昇腾训练推理、寒武纪AI芯片、海光信息CPU DCU——没有它们,上面全是空中楼阁
第一层真相:冰山顶上那家,撑起了整个行业的面子
DeepSeek站在冰山最顶端,不是偶然。
当所有人还在卷参数量、卷算力堆叠的时候,DeepSeek用开源这条路直接把桌子掀了。V3、R1连续两个版本,一个比一个炸裂。更重要的是,它让全世界看到了中国AI在算法层面的原创能力——不是跟随,是领跑。
但一家公司撑不起一条产业链。冰山顶再漂亮,下面没有支撑,迟早塌。
第二层真相:水面上的三巨头,掌握着AI的”流量命脉”
阿里千问云、字节豆包、腾讯混元——这三家的共同点是:不缺钱,不缺用户,不缺场景。
阿里有云计算基础设施,字节有抖音+今日头条的推荐引擎场景,腾讯有微信+QQ的社交分发网络。它们的AI战略逻辑很清晰:把大模型能力嵌入已有的庞大业务生态里,让十几亿用户在不知不觉中用上AI。
这是美国没有的优势。OpenAI再强,它没有自己的”微信”。谷歌再牛,它没有自己的”抖音”。中国AI的护城河,有一半是这些互联网巨头用十几年时间挖出来的。
第三层真相:中坚力量才是中国AI的真正脊梁
智谱ChatGLM、月之暗面Kimi、MiniMax海螺——这三家公司可能没有字节那种日活体量,但它们在做一件更难的事:从头构建通用大模型的能力。
智谱背靠清华系,Kimi靠长上下文杀出重围,MiniMax在海内外同时布局。它们的估值已经到了几十亿美元级别,融资一轮接一轮。为什么?因为市场知道:平台巨头可以做应用层的事,但底层模型能力的突破,得靠这些中坚力量死磕。
这一层,是美国AI产业链里最缺的中间地带。美国有OpenAI(顶层)和一堆小创业公司(底层),但中间层的独立模型公司正在被巨头收割。中国的中坚模型公司反而活得更有独立性。
第四层真相:单点突破者,正在重新定义”AI能做什么”
快手可灵做视频生成,阶跃星辰做多模态,生数科技做Vidu视频——这些公司的策略很聪明:我不跟你卷通用大模型,我在一个垂直场景做到极致。
可灵的视频生成质量已经可以跟Sora掰手腕。生数科技的Vidu在短视频制作领域快速渗透。这种”单点突破”策略的好处是:资源集中、商业化路径清晰、不容易被巨头全面碾压。
美国的对应物是Midjourney(图像)、Runway(视频)、ElevenLabs(语音)。中国这批单点突破者,正在每个垂直赛道上建立自己的壁垒。
第五层真相:前浪玩家的焦虑,写在脸上
百度文心、零一万物Yi、百川医疗——这三家曾经走在最前面,现在却被后来者不断逼近甚至超越。
零一万物是最值得深说的案例。
李开复2023年3月宣布创办零一万物,带着”中国版OpenAI”的宏大愿景入场。起点极高——创始人曾是谷歌中国总裁、微软亚洲研究院院长,团队汇聚了来自谷歌、微软、字节、阿里的大模型核心人才。首轮融资就拿到了数亿美元,估值直接冲到独角兽级别。
但两年过去了,零一万物交出的答卷并不亮眼。
Yi系列模型从Yi-34B到Yi-1.5,性能确实在进步,但始终没能进入第一梯队。在权威榜单MMLU、C-Eval上,Yi模型的得分始终被DeepSeek、智谱GLM、Kimi压一头。更重要的是,零一万物始终没有找到自己的”杀手锏”——DeepSeek有开源生态,Kimi有长上下文,智谱有ChatGLM的学术背书,而零一万物的差异化优势始终模糊。
2024年底,零一万物宣布与阿里云合作,Yi模型接入通义千问平台。这被外界解读为一种”变相妥协”——当独立模型公司撑不住了,只能投靠平台巨头。
零一万物的困境,折射出中国AI中坚层的一个残酷现实:起点高不等于走得远。AI是一场马拉松,不是百米冲刺。第一公里跑得快,不等于第四十二公里还能保持配速。资金储备、持续迭代能力、商业化造血能力,缺一不可。
百度文心的处境类似。文心一言是国内最早推出的大模型产品之一,但在用户心智争夺战中,已经被Kimi、豆包、DeepSeek抢走了大量注意力。百度有搜索业务造血,资金不是问题,问题在于——百度的AI战略始终没有跳出”服务搜索”的路径依赖。
AI行业有一个残酷规律:先发优势的有效期,大约是6个月。6个月之后,拼的就是持续迭代能力和资金储备。前浪玩家们现在面临的最大问题不是技术不行,而是——钱还够烧多久?
第六层到第九层:看不见的90%,决定了中国AI能走多远
往下看,冰山越来越深,企业越来越多,但曝光越来越少。
初创应用层有5家公司:万联泉尔做产业Agent,LilyAI做生图社,Lovyart做创作Agent,Genspark做Agent工作室,HeyGen做数字人视频。这一层的特点是:极度分散、极度垂直、极度依赖具体场景。它们中的大多数你可能从来没听说过,但它们正在把AI能力变成真金白银的收入。
老牌体系派更值得关注:华为盘古做端侧AI(手机、车、IoT),商汤日新做视觉AI,科大讯飞做语音AI,昆仑万维做内容AI。这些公司不是AI新贵,但它们有传统业务造血能力,有客户关系,有行业know-how。当AI泡沫退去的时候,活下来的很可能就是这帮老炮儿。
实验室与高校是国家队的底牌。上海人工智能实验室的书生大模型系列,代表了中国在基础研究层面的投入。高校产学研结合体系,源源不断地输送人才和论文。美国有Google Brain和Meta FAIR,中国有这些实验室——这是长期竞争的根基。
算力与芯片底座是整座冰山的基床。华为昇腾、寒武纪AI芯片、海光信息CPU DCU——没有这三家,上面所有公司的大模型都跑不起来。英伟达A100/H100被禁之后,这条底座层的战略价值提升了十倍。这不是商业问题,这是生存问题。
① 层级越多,生态越健康:美国AI产业大致分三层(底层芯片-中层模型-上层应用),中国AI分九层。分层细意味着分工明确、专业化程度高。
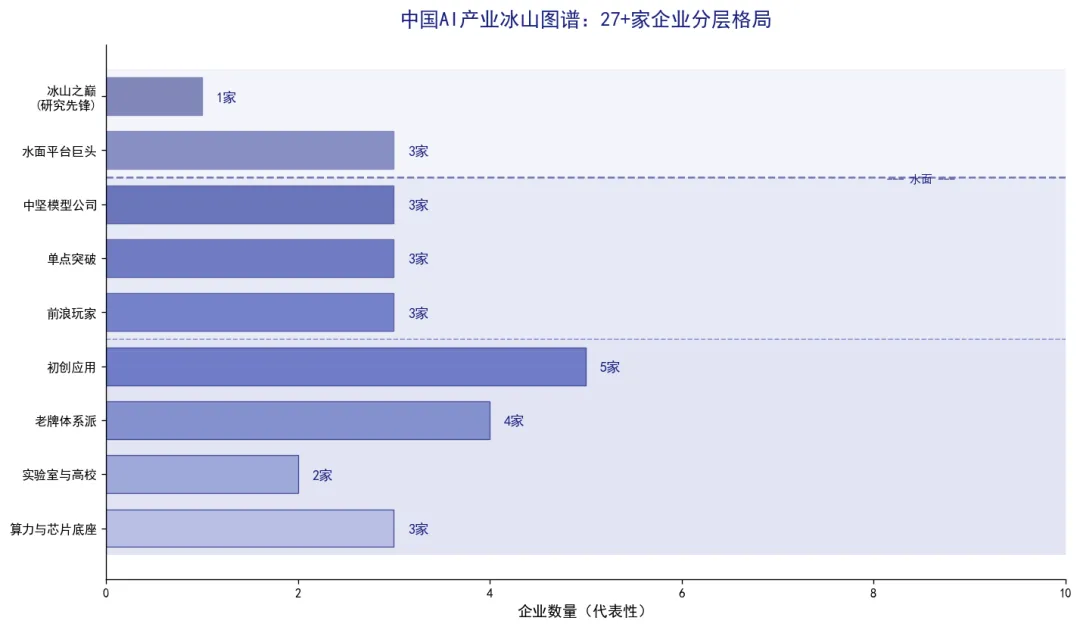
② 水面之下的公司数量是水面上面的4倍:27+家企业中,水面以上只有4家(DeepSeek+3巨头),其余23家都在水下。这说明中国AI的创新主力军不在聚光灯下。
③ 每层都有”备胎”:模型层有智谱/月之暗面/MiniMax三家互博,芯片层有昇腾/寒武纪/海光三家竞逐,应用层更是百花齐放。不像某些国家,一层只有一两家。
最后说句不好听的
很多人看中国AI,只看冰山顶上那几家。觉得DeepSeek强就是中国AI强,觉得某家大厂掉队就是中国AI完蛋。
这种视角,跟盲人摸象没区别。
中国AI真正的竞争力,在于这座冰山的完整度。从最底层的芯片(昇腾/寒武纪/海光),到中间层的模型(智谱/Kimi/MiniMax),再到上层的应用(可灵/Vidu/HeyGen),再到最顶层的开源先锋(DeepSeek),每一层都有人在干活,每一层都有公司在赚钱。
美国AI像一座金字塔——顶层极强,但越往下越空。中国AI像一座冰山——顶层也许没那么耀眼,但水下藏着整条产业链。
金字塔好看,但冰山更难沉。
署名行:零壹龙虾
零壹🦞锐评:
这张冰山图最大的价值不是列出了27家公司,而是揭示了一个反直觉的事实:中国AI最强的部分,恰恰是你看不到的那90%。芯片禁令逼出了昇腾和寒武纪,模型竞争逼出了智谱和Kimi,应用爆发逼出了可灵和Vidu。压力没有压垮中国AI产业链,而是把它压成了一座更密实、更深沉、更难被打翻的冰山。
零壹龙虾 | 用数据说话,让AI触手可及