 夜雨聆风
夜雨聆风





「18到24个月后,前沿级AI就跑在你自己的笔记本里」一条58赞的小众推文,戳穿了云端最贵的护城河
2026年4月28日深夜,一位叫 Adrian Morris 的开发者在 X 上发了一条推文:「Frontier 模型很厉害,但真正的未来,是『前沿级』模型直接跑在你自己的硬件上。我认为这件事最多只剩 18 到 24 个月。」这条推文只拿到 7,356 次浏览和 58 个点赞——按 X 的标准几乎是「沉底贴」。但底下评论区瞬间撕成两派:一派说「太乐观,散热墙都过不去」;一派说「Adrian 还说保守了」。Google 的 Gemma 3、Hugging Face 的 1.58-bit 极限量化、Apple Silicon 的统一内存——三股力量正在同时往同一个方向推。如果他赌对了,OpenAI、Anthropic 这些公司花几百亿美金砸出来的「云端护城河」,也许只剩一年半的保质期。
一条「沉底」的推文,为什么值得认真看
先把这条推文拎出来。Adrian 的核心句只有两段,但每一句都踩在 AI 行业最敏感的神经上:
“Frontier models are fantastic, but the real future is frontier-level models (in every way) running locally on your own hardware. I think this is 18-24 months away at most.”
「Frontier 模型确实牛,但真正的未来,是和它同等水平的模型直接跑在你的硬件上。我觉得这件事最多还剩 18 到 24 个月。」
“Vector quantization, architecture advances & leaps in personal computer power (I’m looking at you @Apple Silicon) are happening fast. Soon we will have local parity, lower long term cost, near-zero latency, with full privacy.”
「向量量化、架构进步、个人计算机算力的跃升(@Apple Silicon,说的就是你)——这些都在飞速发生。很快我们就会拥有本地对等的能力、更低的长期成本、接近零的延迟,以及完全的隐私。」
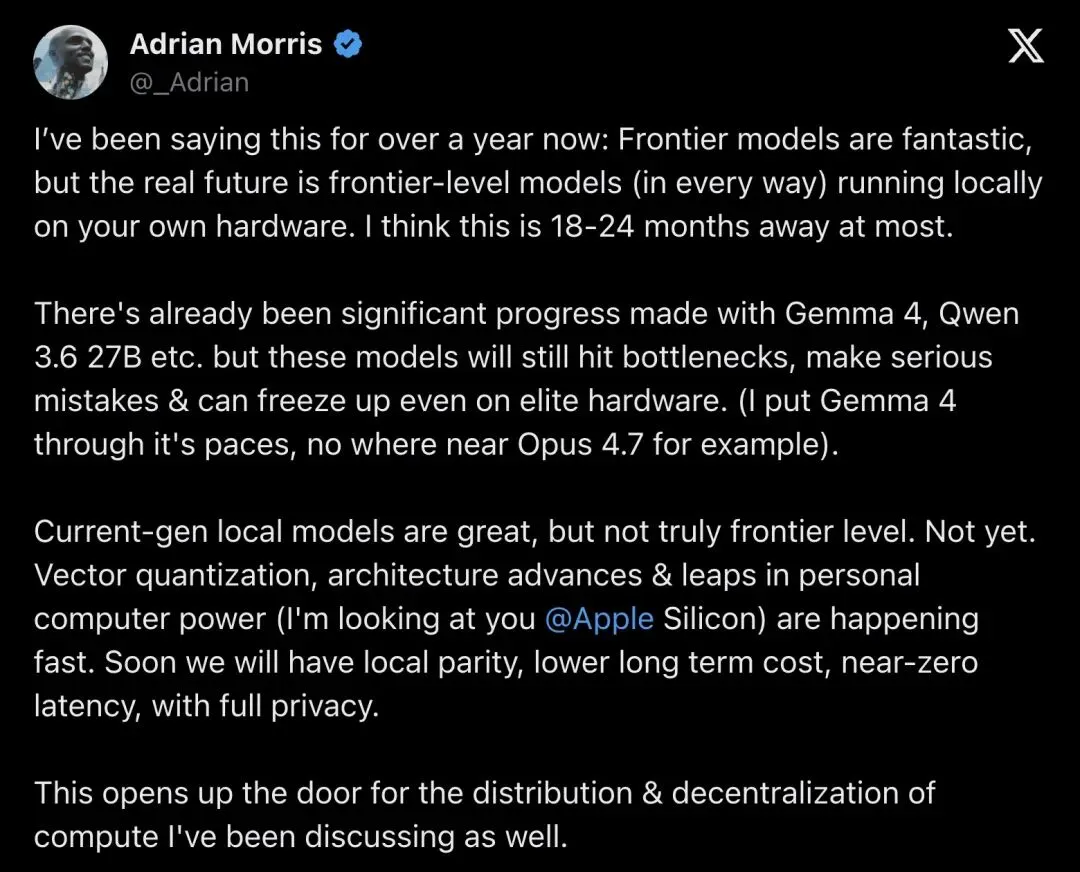
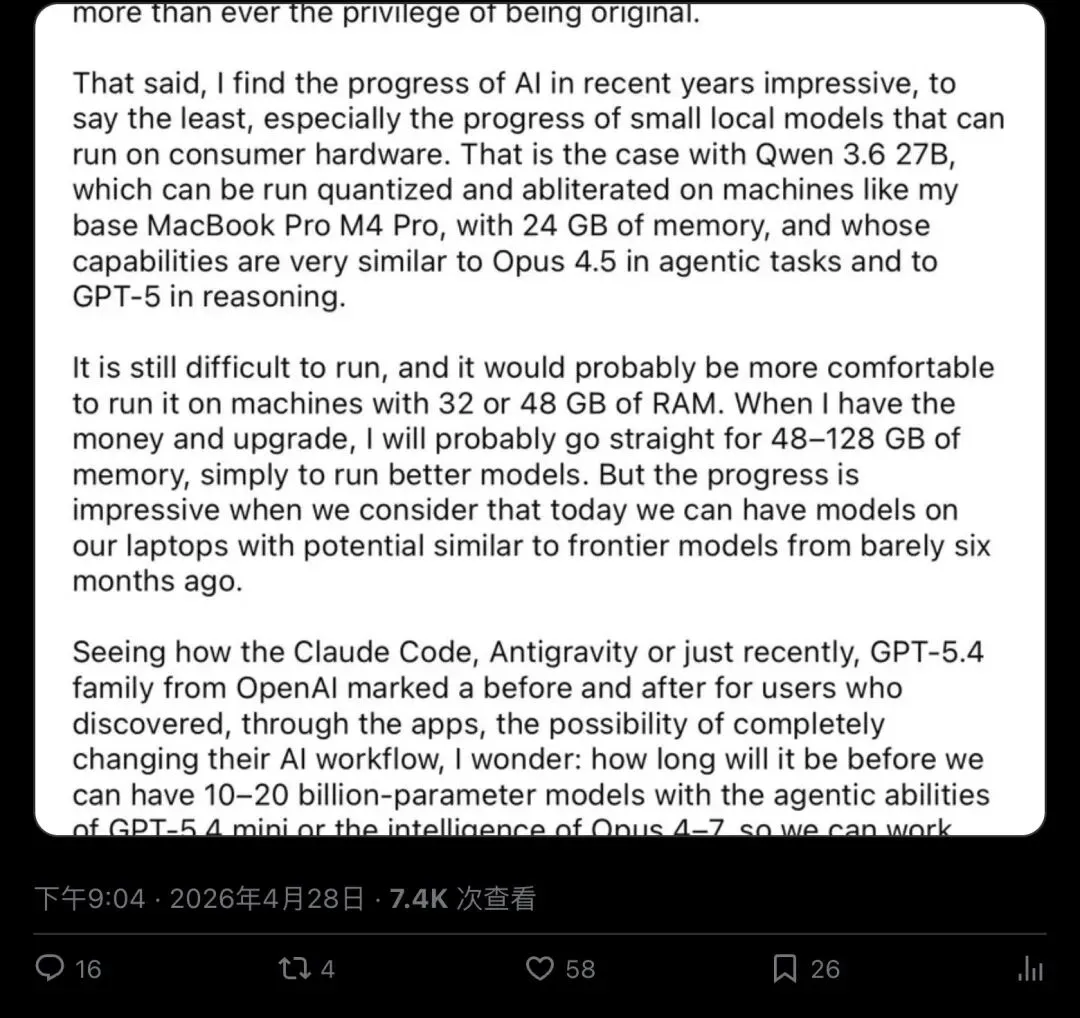
▲ Adrian Morris(@_Adrian)2026年4月28日发布。截图里底部那条蓝色长推甚至点名了具体型号——Gemma 4、Qwen 3.6 27B,并直接拿来对比 Opus 4.5 / Opus 4.7。互动数据:7,356 次浏览,58 个赞,4 次转发,16 条回复。
注意他在推文下半段补的细节:他自己已经把Gemma 4用在 base MacBook Pro M4 Pro 的 24GB 内存上跑日常活;他说这台机器在 agentic 任务上「very similar to Opus 4.5」,在推理任务上接近 GPT-5.1。
这是不是营销话术?很难说。但他至少给出了一个可证伪的具体预测:18 到 24 个月。
第一把火:Google 自己在帮「本地化」铺路
很多人没意识到——「本地能跑」这条路线,是大厂自己在推的,不是开源社区一厢情愿。
Google 在 Gemma 3 的官方发布博客里,一句话给整个产品定了调:
“Gemma 3 is designed to run fast, directly on devices—from phones and laptops to workstations.”
「Gemma 3 的设计目标就是直接在设备上跑——从手机、笔记本一路到工作站。」
更狠的是,Gemma 3 一开始就给了官方量化版本。这个细节很关键:以前量化是社区在折腾(GPTQ、AWQ、GGUF 这些),精度损失开发者自己背锅;现在 Google 直接出官方版本,相当于把「能不能小到塞进消费级硬件」这件事,写进了模型出厂的默认 SKU。
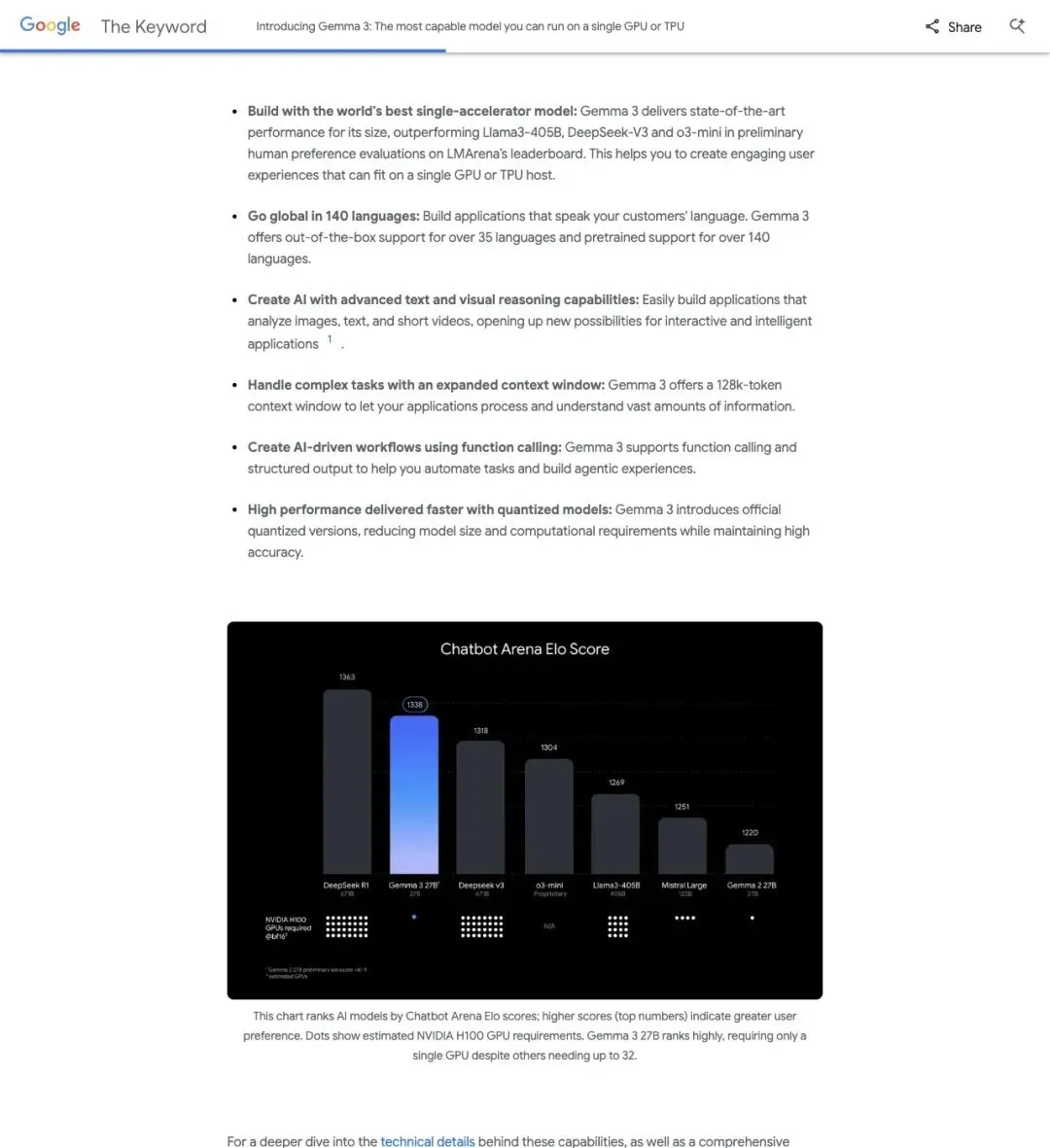
▲ Google The Keyword 的 Gemma 3 发布页面。注意右栏第一条直接写「为单 GPU/TPU 加速器优化」;同一页还附了 Chatbot Arena Elo 排名,27B 版本紧贴在 DeepSeek-V3 和 LLaMA 3 405B 之间。
128k 的上下文、多模态、140 种语言、function calling……Gemma 3 把过去只在云端旗舰才有的能力,一次性塞进了一组 1B 到 27B 的小模型里。Adrian 推文里那句「现在的本地模型已经很强了,但还没到真正的 frontier」,对应的就是这个观察——大厂在主动往「单卡可跑」的方向卷。
第二把火:1.58-bit 极限量化,把内存墙往外推
第二股力量更激进:用更少的比特表示一个参数。
Hugging Face 在一篇专门讲 BitNet b1.58 的博客里,直接亮了底牌:
“BitNet … represents each parameter with only three values: -1, 0, and 1 … 1.58 bits per parameter.”
「BitNet 用三个值表示一个参数:-1、0、1——平均每个参数只占 1.58 个比特。」
什么概念?传统 FP16 一个参数占 16 个比特。从 16 降到 1.58,相当于把同一个模型的权重体积压到原来的十分之一以下。原本要 80GB 显存才能装下的 70B 模型,理论上有机会塞进 8GB 量级的内存。
当然,1.58-bit 不会一夜之间替代 4-bit、8-bit。HF 的博客里花了大篇幅讲为什么把现成模型 fine-tune 到三值表示「比想象中难」——梯度怎么传、kernel 怎么写、benchmark 在哪些任务上掉点。这条路线代表的,是「量化还远没到天花板」这个事实本身。
每往下压一个比特,本地能装下的模型就大一档。Adrian 把「vector quantization」放在他三大抓手的第一位,逻辑就在这里。
第三把火:Apple Silicon 把「本地推理」变成可能
第三股力量是硬件。Adrian 在推文里点名 @Apple——这不是巧合。
Apple Silicon 最反直觉的优势,叫做统一内存架构。一台 128GB 的 M4 Max,CPU 和 GPU 共用同一块高带宽内存,权重不用在「系统内存」和「显卡显存」之间来回拷贝。在一条 Show HN 帖子下面,作者把这件事讲得很直白:
“An M4 Max with 128GB can run models that would require a dedicated GPU workstation elsewhere. At laptop wattages. Offline.”
「128GB 的 M4 Max,能跑一些在其他平台上必须靠专用 GPU 工作站才能跑的模型。功耗只有笔记本级别,而且离线。」
▲ Hacker News 上的一条 Show HN:作者发起了一个真实世界 LLM 性能数据集项目(Anubis OSS),专门收集不同 Apple Silicon 机型 / 不同量化方案 / 不同推理后端的实测数据。光这个项目本身的存在,就已经回答了「本地推理算不算个真问题」。
生态侧已经开始接力。一条来自 Locally AI 的推文显示,Qwen 3.5 9B 已经直接登陆 Mac,明确标注「Optimized for Apple Silicon with MLX」——一个赞数破千的本地推理 App,在不到一年里把开源旗舰模型搬到了 macOS 桌面:
▲ Locally AI – Local AI Chat(@LocallyAIApp)2026年3月7日发布,1.1K 点赞、682 次收藏。一句话:在你自己的设备上、隐私模式跑 9B 参数。
更工程化的信号来自 Red Hat。这家以企业级开源闻名的公司,公开演示了用 vLLM 在 Apple Silicon 上跑 OpenAI 的 Whisper 模型,并对外暴露一个 OpenAI 兼容的 `/v1/audio/transcriptions` 端点:
▲ Red Hat Developer(@rhdevelopers)2026年3月8日发布。意思很直白:原本只在云端跑的 Whisper,今天可以在 MacBook 上完整跑起来,并且和 OpenAI API 接口对齐。
▲ Red Hat Developer 博客文章原文(2026年3月6日)。标题《From local prototype to enterprise production: Private speech transcription with Whisper and Red Hat AI》——「本地」「私有」「企业生产」三个关键词同时出现在 Red Hat 这种级别的厂商博客里,本身就是一个信号。
云端旗舰的 API 形态,开始被一台 MacBook 完整复刻。
反方意见:为什么有人觉得「18 个月」太乐观
把火吹得太大也不公平。Adrian 自己在推文里就承认了一件事:
“Current-gen local models are great, but not truly frontier level. Not yet. … they can freeze up even on elite hardware.”
「当前这一代本地模型已经很好用了,但还称不上真正的 frontier。还没到。……即便在顶配硬件上也会卡死。」
社区里 Jimmy Apple 这类硬件分析师的反驳更尖锐:就算把一个 2T 参数的 MoE 模型用 1.58-bit 塞进 256GB 内存,要在桌面上跑出 30 t/s 而不让屋子变成烤箱,是「fantasy」。他押注「真正可用的本地模型,至少落后前沿 1 到 2 代,要等到 2029 之后」。
具体的瓶颈有三层:
- 内存带宽墙
:token 生成速度被「权重从内存搬到计算单元有多快」死死卡住。消费级 GPU 大约 1–2 TB/s 带宽,数据中心动辄上 10 TB/s。 - KV cache 爆炸
:长上下文是杀手。128k 上下文的 KV cache 体积本身就能吃掉几十个 GB,量化它又要再掉一档精度。 - 散热和稳定性
:Adrian 自己说本地模型「会卡死」。这不是黑屏 bug——长任务下 thermal throttling 会让 tokens/s 直接腰斩。
换句话说:「能跑」和「能用」之间,还有一条很现实的护城河。
真正的赌注:能不能让「智能」本身搬家
读到这里,最值得停下来想一秒的,其实是 Adrian 那个略显古怪的措辞——「frontier-level (in every way)」。
他赌的并非「跑得动同样大的模型」。他赌的核心在另一处:同等智能可以用完全不同的算力分配方式实现。预训练规模、量化精度、推理时的「思考」时间——这三件事可以互相替换。一个 200B 的 MoE,加上 1000 倍的 test-time compute,加上极限量化,也许在你关心的任务上等同于云端 2T 参数旗舰。
如果赌赢了——
-
隐私从「你愿意用数据换便利」直接变成默认配置; -
延迟从 200ms 网络往返压到接近零; -
每月几十美金的 API 账单变成一次性的硬件折旧; -
AI 工业的权力结构从「几家超大规模云」重新回到桌面。
如果赌输了——本地模型继续追在前沿 1 到 2 代之后,云端继续印钞。两种结局都有可能。差别只在于:18 到 24 个月以后,你打开 MacBook 写代码、写报告、做 agent 的时候,要不要先连一根网线。
7,356 次浏览,58 个点赞——这条推文目前还没火。但它问的问题,已经在每一家芯片公司、每一个开源推理项目、每一份模型 release notes 里悄悄被回答。
— END —