 夜雨聆风
夜雨聆风





ETH Zurich实锤:一群AI Agent连「选个数字」都谈不拢,成功率仅41%!多Agent神话要碎了?
你以为把一堆AI Agent放在一起,它们就能自动变成一支高效团队?ETH Zurich的最新论文《Can AI Agents Agree?》给了所有人一记重拳——在一个没有任何利益冲突的极简共识任务里,一群LLM Agent的有效共识率只有41.6%。更离谱的是,它们失败的方式压根跟”选错了”没关系——就是一直在聊、一直在拖、最后超时出不了结果。Agent越多,越容易瘫痪。
一个最简单的问题,AI Agent都答不好
先说清楚这篇论文到底在测什么。
它设计的场景极其简单:一群Agent,每人拿到一个0到50之间的数字,目标只有一个——大家商量出一个共同值。没有对错之分,没有谁的数字更好,纯粹就是”你们聊聊,统一一下”。
注意,这里甚至没有恶意搅局者。所有Agent都在真心实意地想达成一致。
结果呢?
只有41.6%的实验跑出了有效共识。
换句话说,超过一半的情况下,这群Agent要么超时,要么卡在某个环节动弹不得,就是聊不出一个结论。

▲ AI研究者Rohan Paul在X上总结这篇论文,引发开发者热议(109赞、30条评论)
模型越强帮助越大,但离”靠谱”还差得远
论文测了两组模型:Qwen3-8B和Qwen3-14B。
数据很直白:
-
Qwen3-14B的有效共识率:67.4% -
Qwen3-8B的有效共识率:15.8%
14B确实比8B强了四倍多。但67%是什么概念?三次里还有一次谈崩。你敢把一个三分之一概率失败的系统放到生产环境里吗?
更有意思的是另一组数据——
如果在prompt里告诉Agent”可能有人在捣乱”,14B的共识率直接从75.4%掉到59.1%。
什么意思?只要让Agent进入”怀疑模式”,它们就算面对的全是友军,也更容易陷入犹豫和内耗,最后把自己拖死。
这像不像你见过的那种——开会前领导说了句”大家畅所欲言”,然后三个小时过去了,什么也没定下来?
Agent越多,越容易”开会开不完”
很多人直觉上会觉得:Agent多一点,分工细一点,互相审查一下,效果应该更好吧?
论文的数据说:反着来的。
-
4个Agent时,有效共识率:46.6% -
16个Agent时,有效共识率:33.3%
人数翻了四倍,成功率反而掉了近三分之一。
这跟过去两年行业里最流行的叙事完全矛盾。从2024年开始,multi-agent创业圈的标准话术是这样的:
一个Agent找资料,一个Agent做规划,一个Agent负责执行,再来一个Agent审核——最后自然就会涌现出”AI团队协作能力”。
但这篇论文揭示了一个残酷事实:协调能力不会自动涌现。Agent多了,先涌现的往往是混乱。
▲ ETH Zurich论文《Can AI Agents Agree?》,2026年3月发布于arXiv
最大的失败模式:连决定都做不出来
这是整篇论文里最值得传播的发现。
当研究者在8个Agent的基础上额外加入1到4个Byzantine(恶意)代理后,系统表现继续下滑。但下滑的方式出人意料——
主要失败形态压根跟”被带偏做了错误决定”无关——就是彻底谈不拢、停不下来、一直拖到超时。
论文原文的说法是:
“Failures are dominated by loss of liveness, such as timeouts and stalled convergence, rather than subtle value corruption.”
「失败主要来自活性丧失——超时和收敛停滞,而非隐蔽的数值污染。」
很多人以为multi-agent最大的风险是”被坏Agent洗脑”,结果真正的风险是组织性瘫痪——大家都想帮忙,但就是出不了结果。
开发者吵起来了:到底是谁的锅?
这条帖子在X上引发了一波很有质量的讨论。几个代表性观点值得拎出来看:
“锅在LLM本身”派:
“We have to remember that if the agents are built on an LLM platform, they are never going to be deterministic… The probabilistic nature of the platform makes it highly likely that agents will NOT agree.”
「别忘了,只要Agent建在LLM平台上,它们就永远做不到确定性输出……平台的概率性天然就会让Agent极难达成一致。」
——Michael Waitze
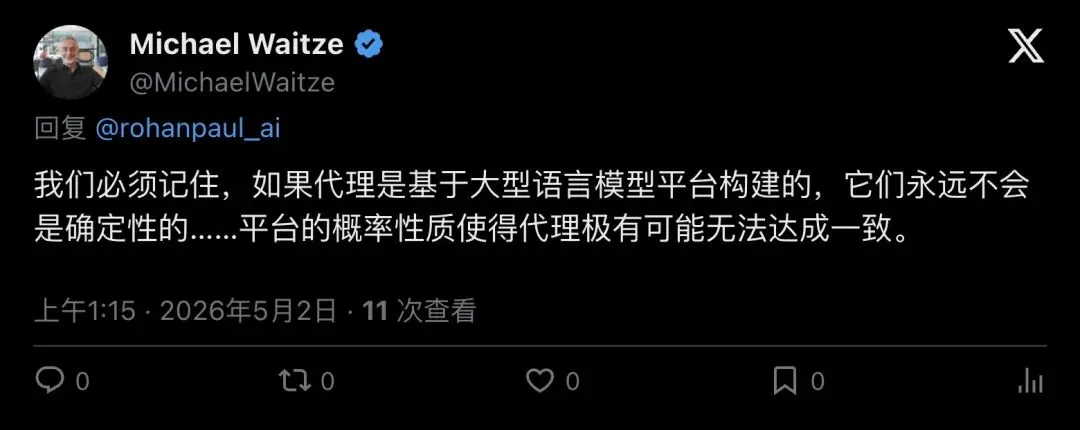
▲ Michael Waitze认为问题出在LLM的概率性本质
“锅在没有调度权”派:
“more agents mostly means more ways to hang unless one thing owns the next move”
「更多Agent往往只意味着更多的挂起方式,除非系统里有某个东西明确掌握下一步的主动权。」
——hanzi
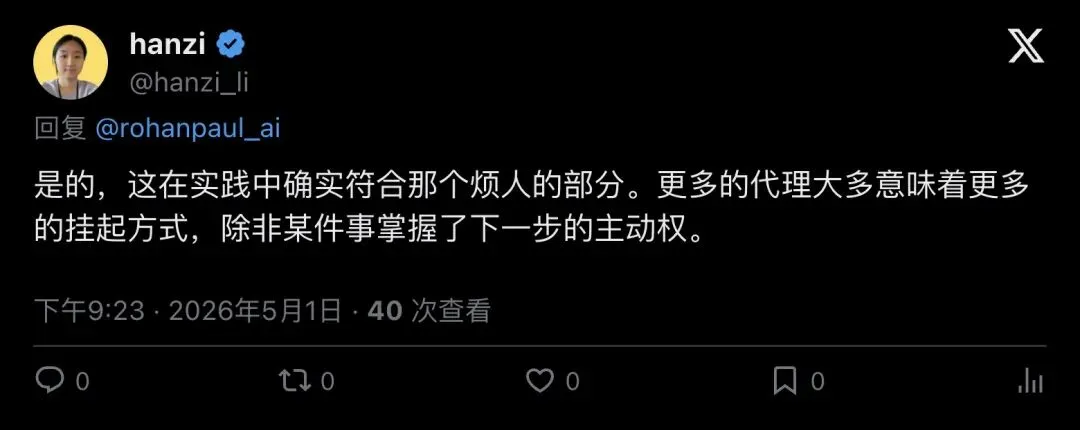
▲ 开发者hanzi指出:关键在于谁来拍板
这话说得非常工程化。翻译一下就是:你堆再多Agent,如果没有一个明确的”指挥官”来决定谁先做、做完谁接、什么时候收工,系统就会卡在”大家都在等别人先动”的死循环里。
“锅在实验设计”派:
“They tested agents without shared state. Our 12 coordinate daily via shared context directories and explicit scope boundaries. Coordination isn’t an intelligence problem – it’s a state problem.”
「他们测的是没有共享状态的Agent。我们的12个Agent每天通过共享上下文目录和明确的范围边界来协调。协调的核心不在智力,在状态管理。」
——Chen Avnery
▲ Chen Avnery认为:给Agent一个共同的”真相来源”,冲突就会降到接近零
这条反驳很关键。它给出了一个工程层面的修补路线:纯靠对话式协商确实容易漂,但如果你给Agent一个共享上下文目录、一套显式的任务边界、一个单一真相源(single source of truth),情况可能完全不同。
论文打的是哪面墙?
有人可能会说:只测了Qwen3-8B和14B,能说明什么?换成更大的模型不就好了?
这个质疑是合理的。评论区里也有人直接说:
“I’ve stopped reading after ‘We test agents based on the Qwen3-8B/14B model family'”
确实,更强的模型可能会表现更好。但论文里14B比8B已经强了一大截,共识率还是只有67%。能力提升在缓解问题,但离解决问题还有很长的路。
更关键的一点是:论文测的是一个无利害冲突的极简场景。Agent对最终选哪个数字毫无偏好,重点纯粹在于”能不能达成一致”。
如果连这种条件都搞不定,真实世界里那些带偏好、带资源竞争、带风险约束的任务呢?
只会更难。
多Agent的真正短板,可能是大家一直在忽略的东西
这篇论文最大的价值,在于它戳破了一个行业默认假设:把多个LLM放在一起,协调能力会自然发生。
事实证明,不会。
至少在缺少共享状态、缺少明确调度权、缺少终止机制的情况下——不会。
Agent的能力天花板,可能从来都不在”会不会想”。真正的瓶颈在”能不能稳定收敛”。
这意味着,multi-agent赛道接下来最该投入的方向,重点可能在这几件事上:
- 共享状态层
:让所有Agent操作同一份现实 - 显式调度权
:谁先做、谁审核、谁拍板,写死在协议里 - 强制终止机制
:聊到第N轮必须投票,投票必须出结果
分布式系统几十年前就解决过类似的问题。只不过那时候节点是服务器,现在节点换成了LLM。
技术变了,工程原理没变。
— END —