夜雨聆风
夜雨聆风





【closerAI ComfyUI】GPT image2+LTX2.3四宫格分镜图视频生成法:高效生产漫剧/短剧的解决方案工作流!

更多AI前沿科技资讯,请关注我们:
【closerAI ComfyUI】GPT image2+LTX2.3四宫格分镜图视频生成法:高效生产AI漫剧/短剧的解决方案工作流!


输出一份上面分镜图的脚本给我,总分结构。直接以这样的结构输出给我,示例如下:
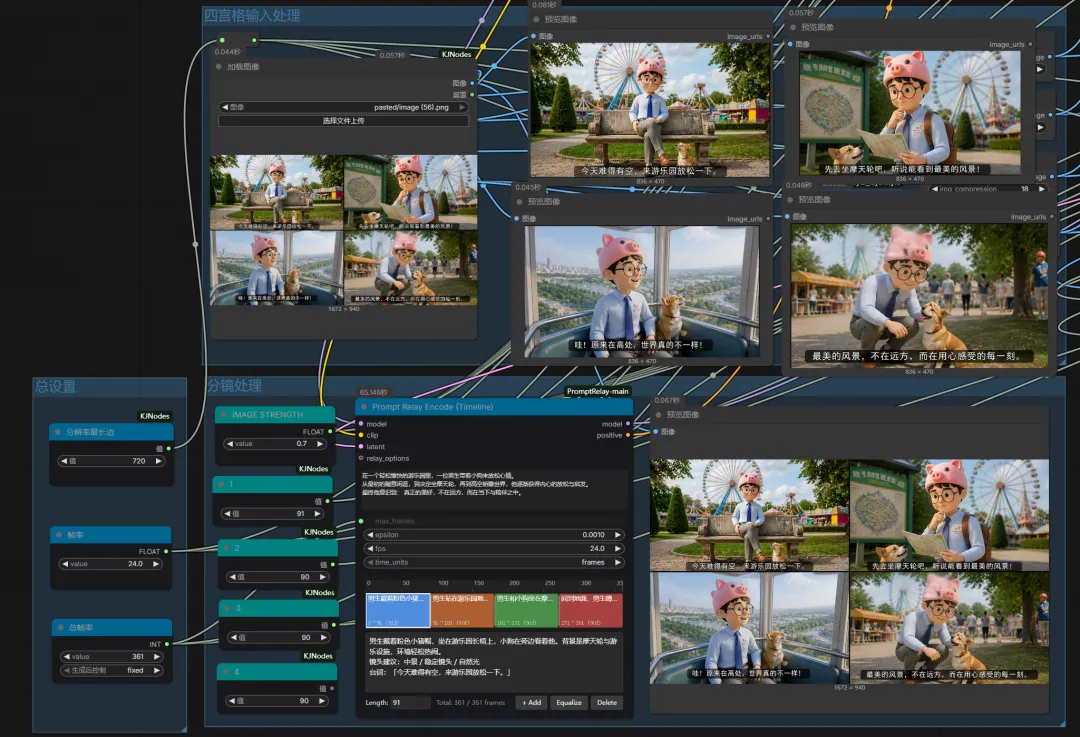
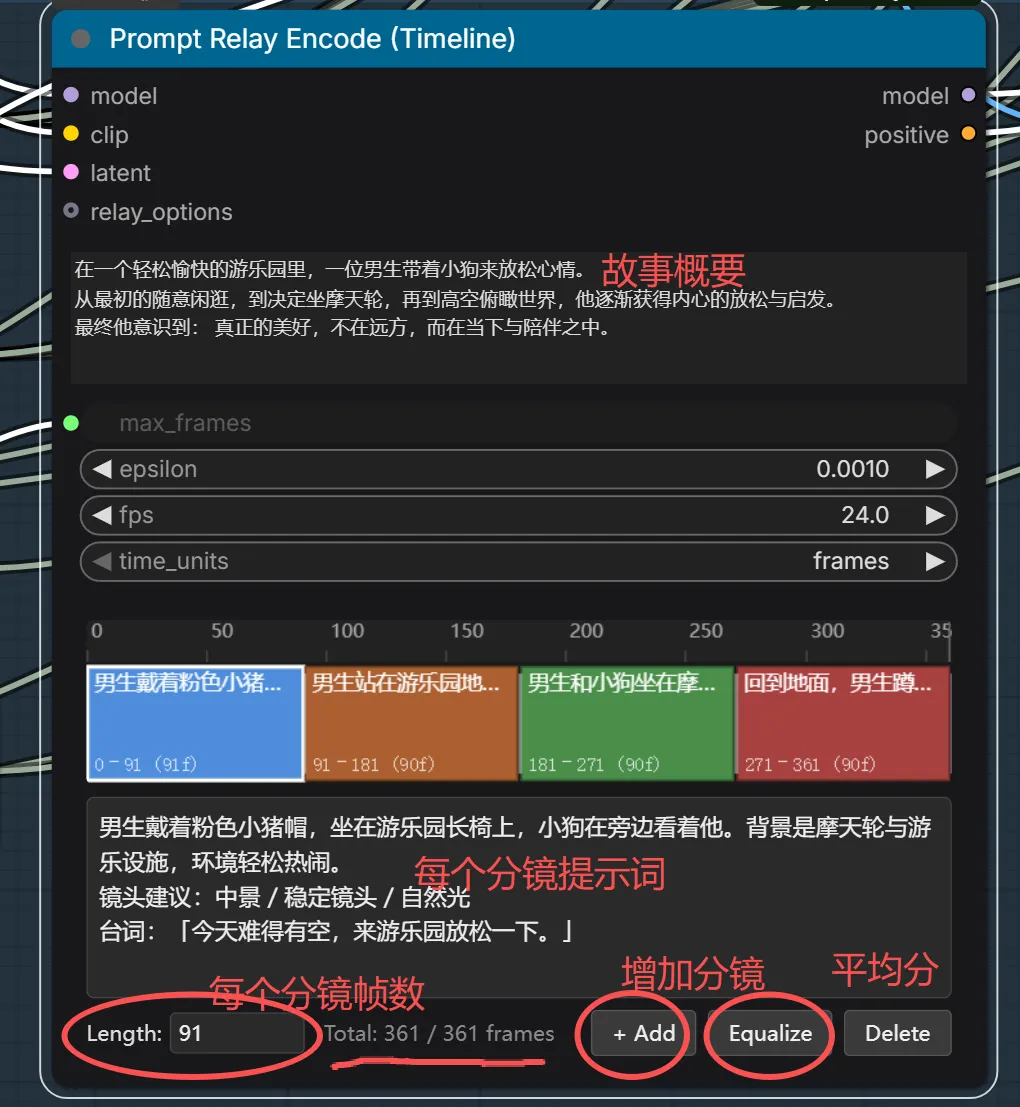
“男生戴着粉色小猪帽,坐在游乐园长椅上,小狗在旁边看着他。背景是摩天轮与游乐设施,环境轻松热闹。
镜头建议:中景 / 稳定镜头 / 自然光
台词:「今天难得有空,来游乐园放松一下。」”
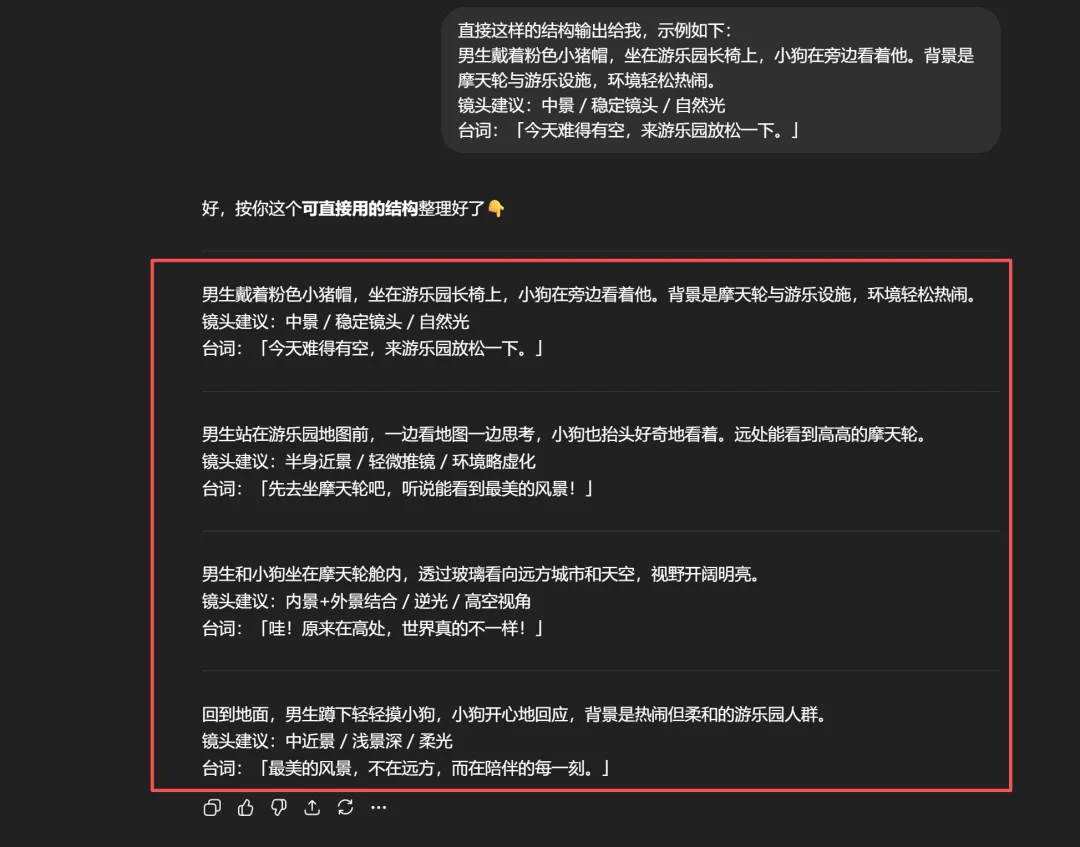
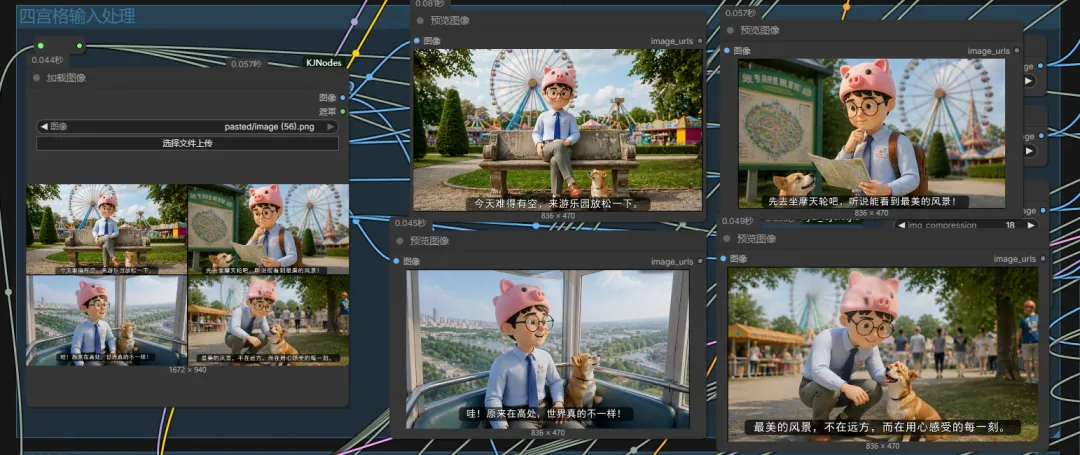
男生戴着粉色小猪帽,坐在游乐园长椅上,小狗在旁边看着他。背景是摩天轮与游乐设施,环境轻松热闹。镜头建议:中景 / 稳定镜头 / 自然光台词:「今天难得有空,来游乐园放松一下。」
男生站在游乐园地图前,一边看地图一边思考,小狗也抬头好奇地看着。远处能看到高高的摩天轮。镜头建议:半身近景 / 轻微推镜 / 环境略虚化台词:「先去坐摩天轮吧,听说能看到最美的风景!」
男生和小狗坐在摩天轮舱内,透过玻璃看向远方城市和天空,视野开阔明亮。镜头建议:内景+外景结合 / 逆光 / 高空视角台词:「哇!原来在高处,世界真的不一样!」
回到地面,男生蹲下轻轻摸小狗,小狗开心地回应,背景是热闹但柔和的游乐园人群。镜头建议:中近景 / 浅景深 / 柔光台词:「最美的风景,不在远方,而在陪伴的每一刻。」
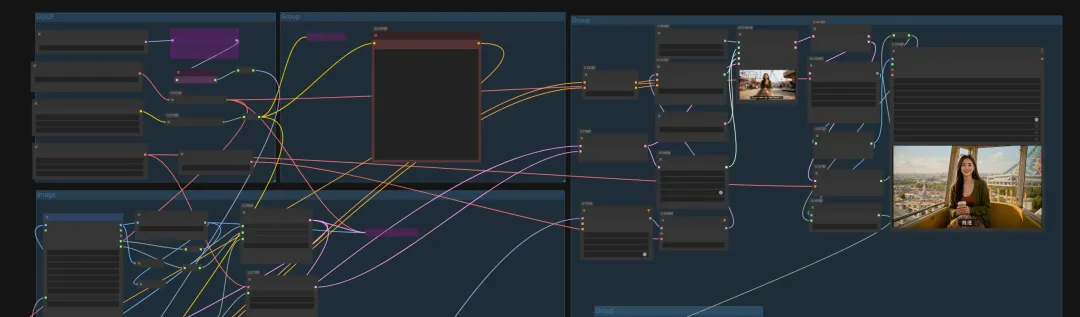
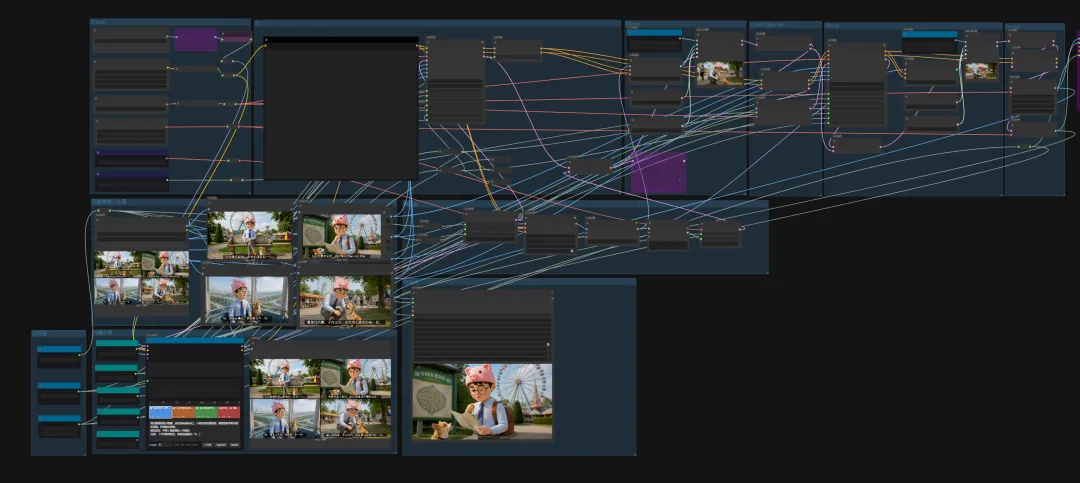
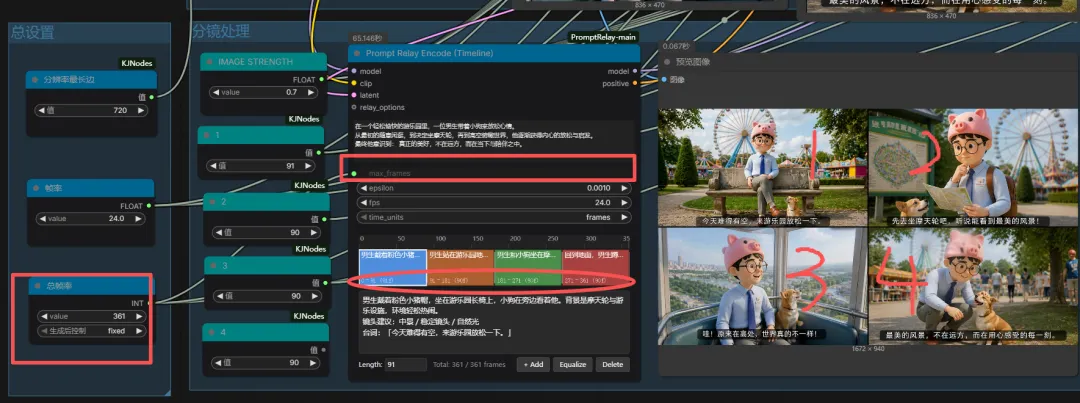
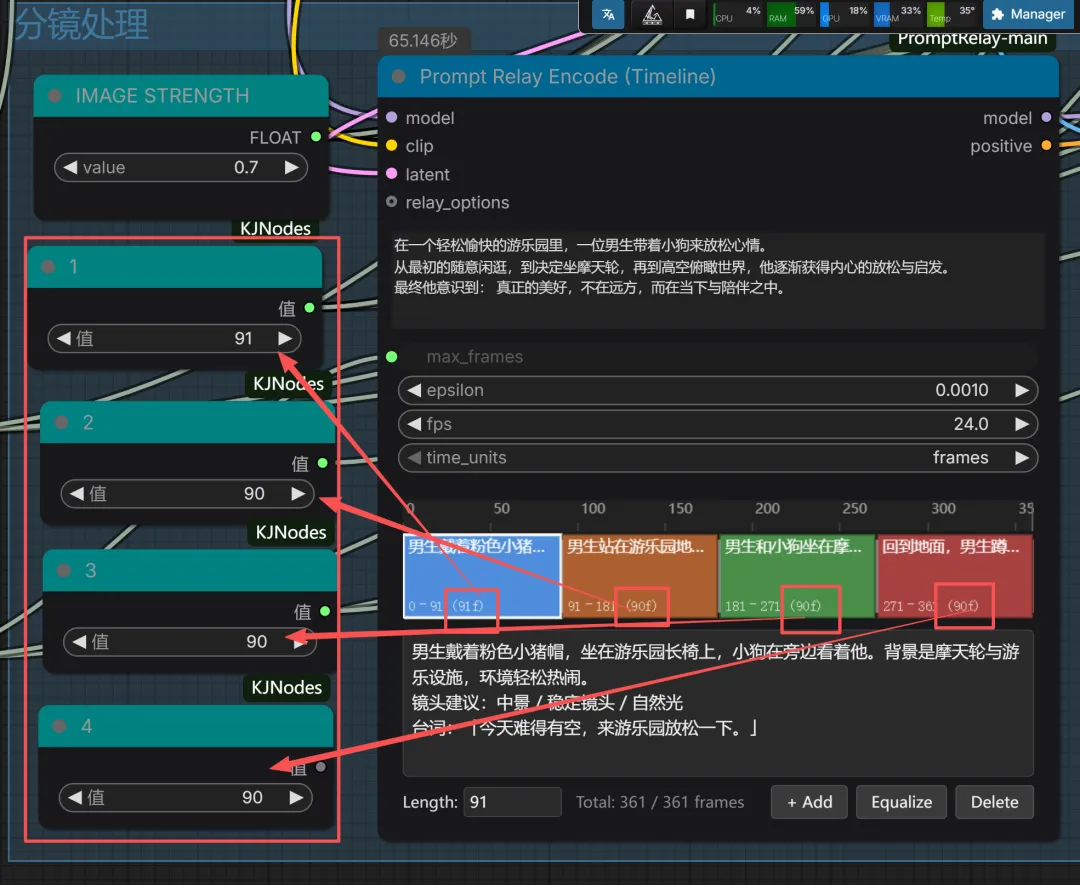
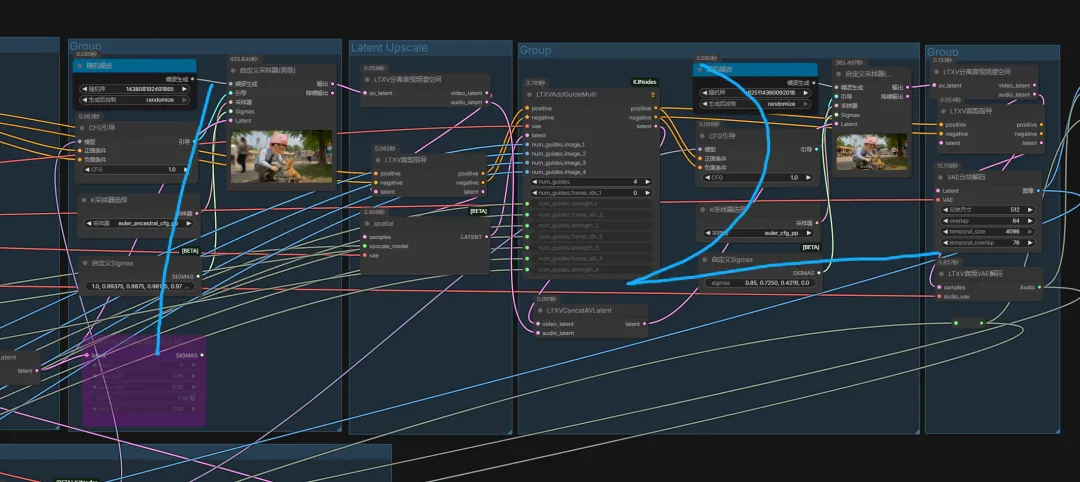
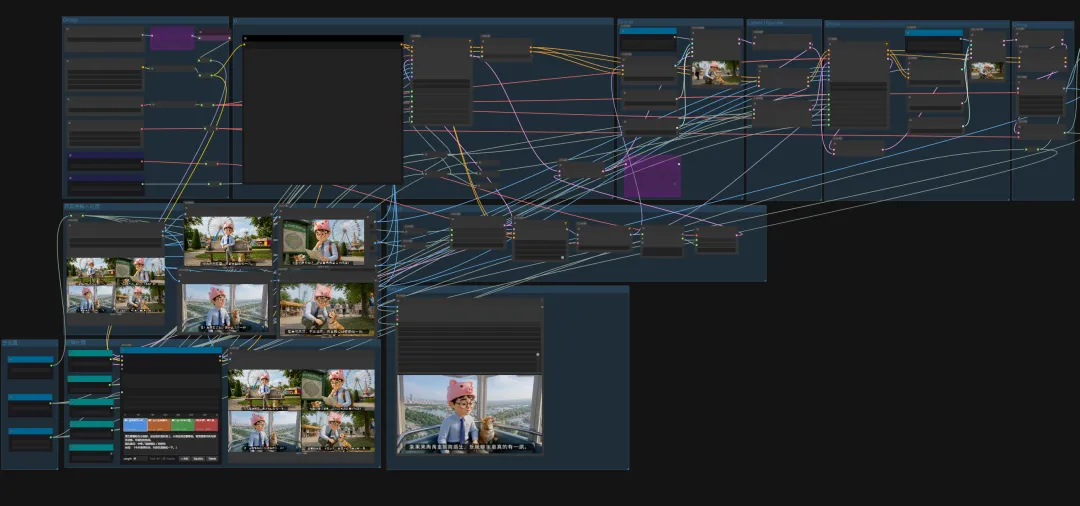
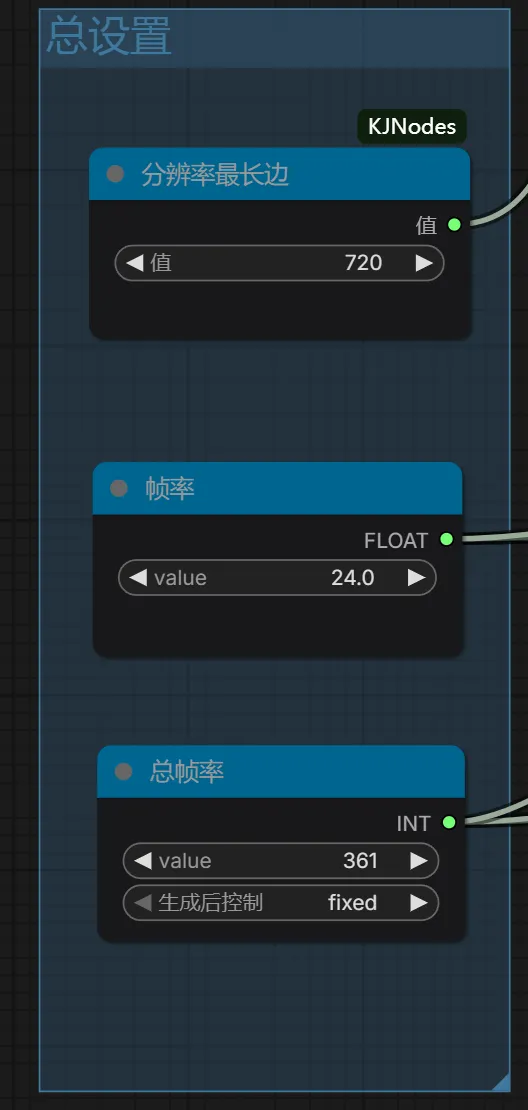
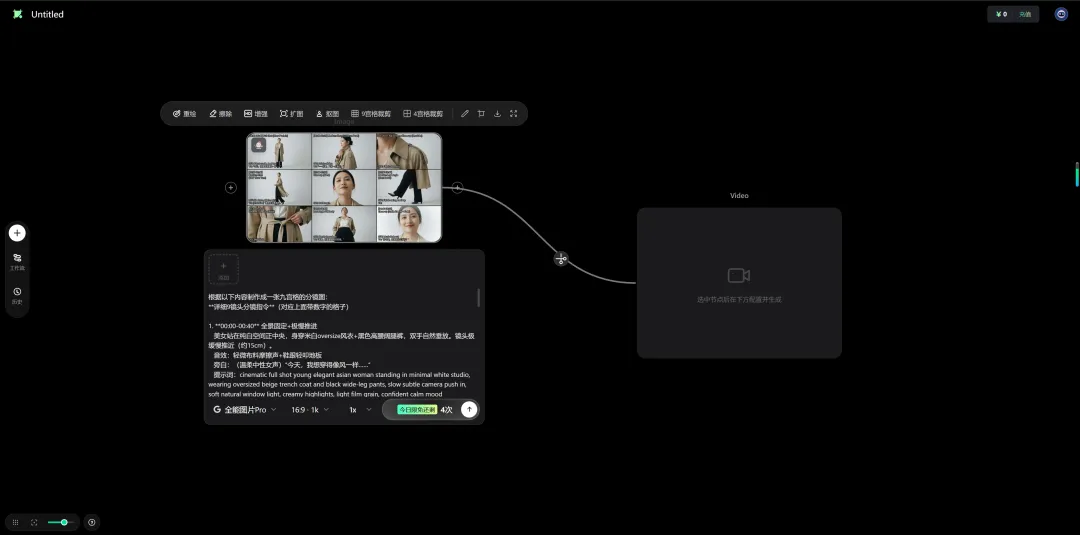
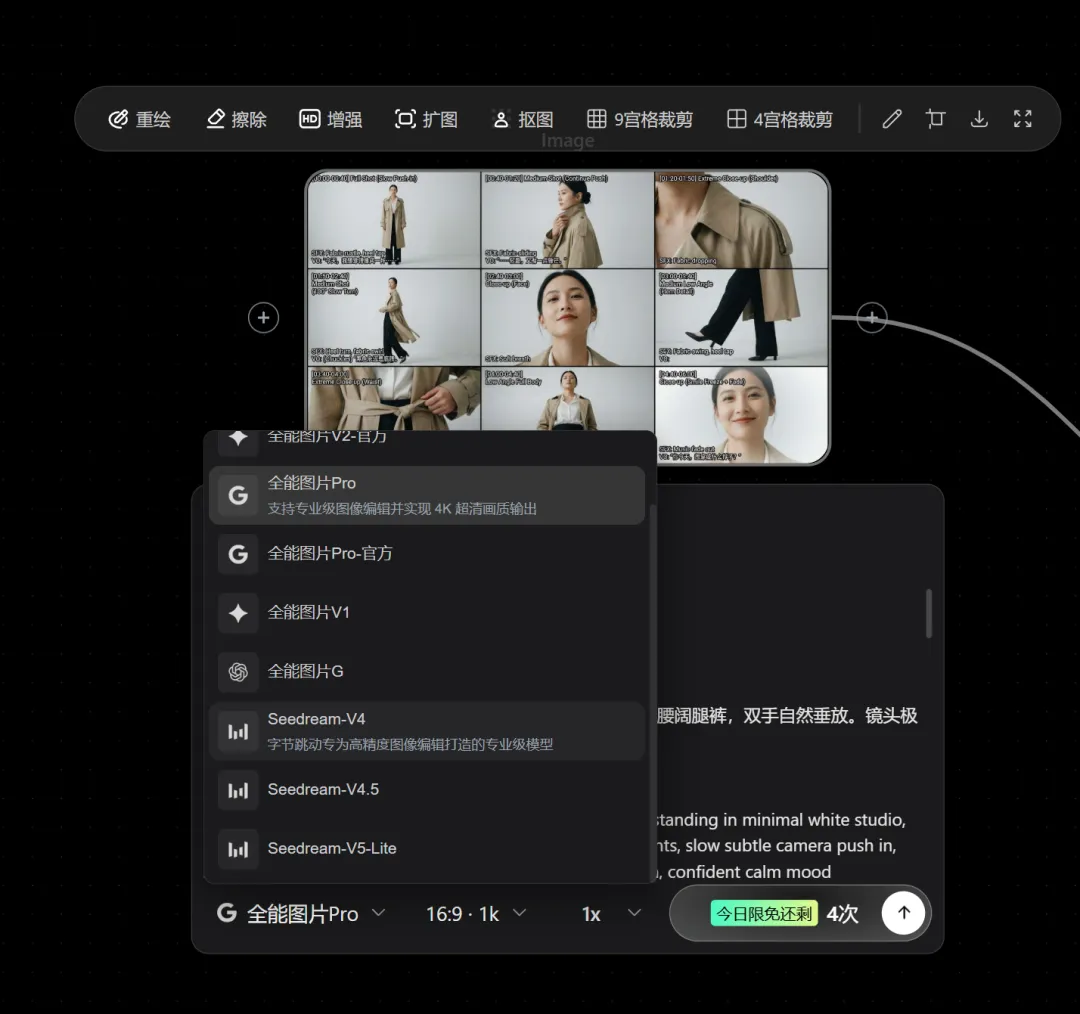
在图像与视频生成中,一个节点就能直接调用使用并生成。十分方便,且价格优惠。它通过集成闭源模型简化了工作流程直接输入即所得,速度很快。是一个不错的选择。通过注册地址:https://www.runninghub.cn/?utm_source=kol01-RH151 注册后打开无限画面
关于分镜我也在RH上生成了应用,可通过下方直接使用。
本地算力不够怎么办?
如果本地设备算力不好的小伙伴,推荐使用线上comfyUI来运行体验:runninghub.cn
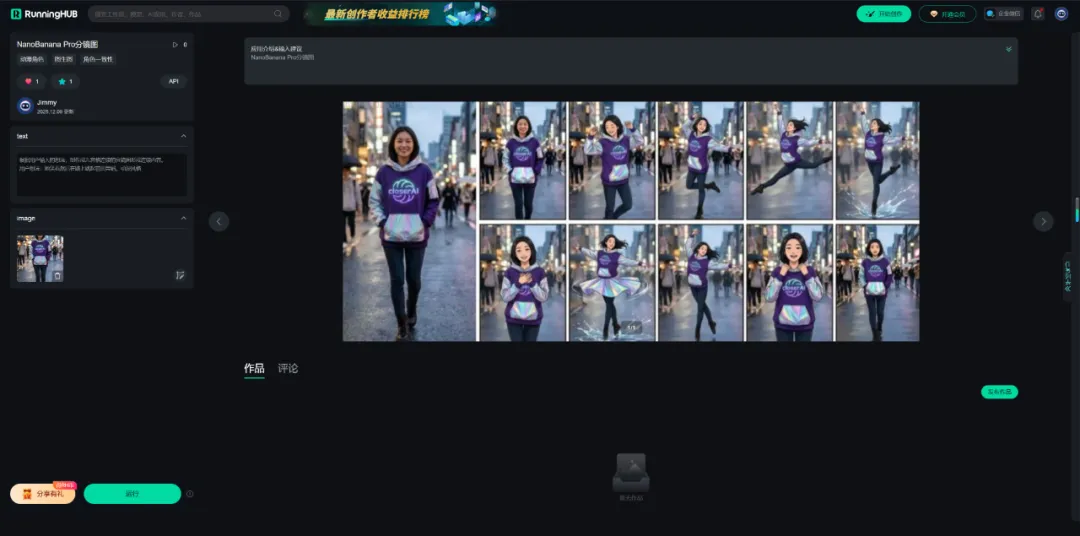
NanoBanana Pro分镜图应用体验地址:
https://www.runninghub.cn/ai-detail/1998278644248272898
最后几句:
如果对你有帮助,请一键三连支持下我,感谢
CloserAI 3D Pose Editor:http://aigc.douyoubuy.cn/2025/12/03/3448/closerAI-nanoPrompts:http://closerai.douyoubuy.cn/2025/11/24/3396/closerAI 分镜设计 软件(exe)本地运行版http://aigc.douyoubuy.cn/2025/11/22/3350/以下是closerAIwater节点:http://aigc.douyoubuy.cn/2025/10/22/3121/分镜分词器节点:http://aigc.douyoubuy.cn/2025/10/11/3080/json结构化提示词http://aigc.douyoubuy.cn/2025/11/05/3242/
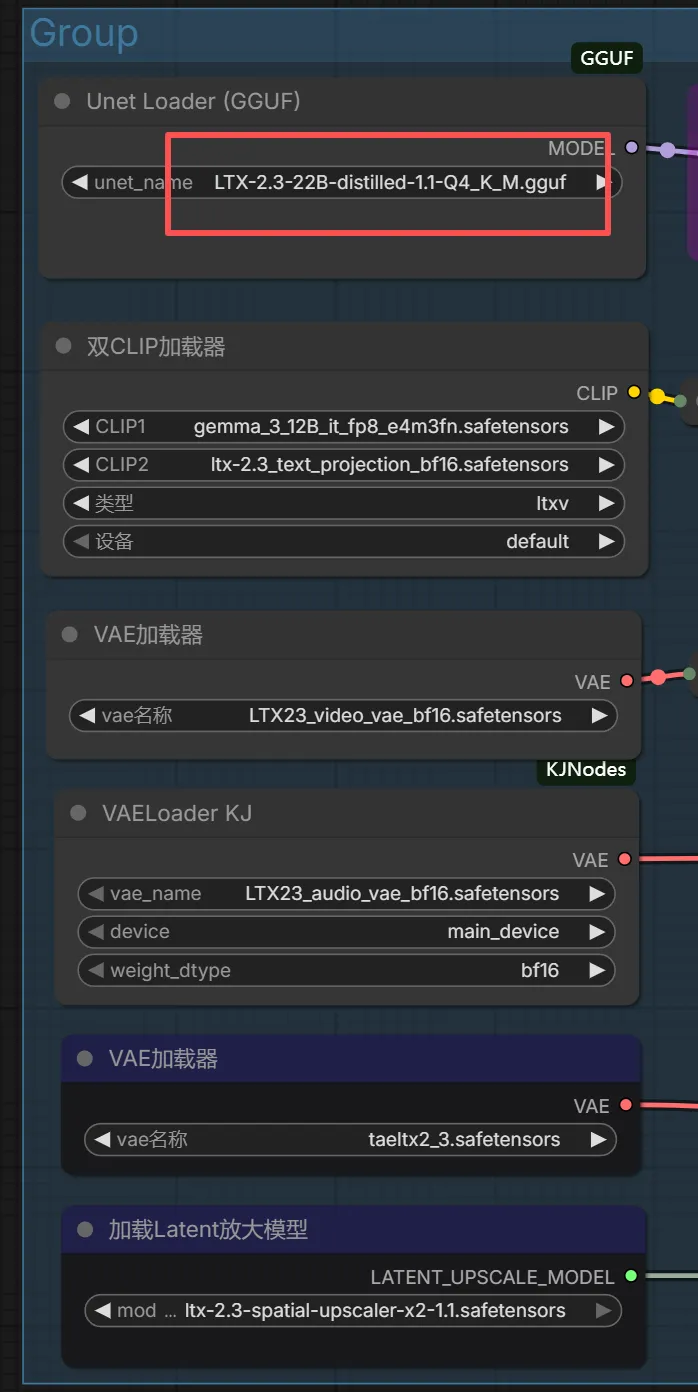
以上是closerAI团队制作的closerAI LTX-2.3四宫格图生视频工作流(GGUF版本)的介绍,当然,也可以在我们closerAI会员站上获取(查看原文)。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~谢谢你看我的文章,我们,下次再见。
>/ 作者:JimmyMo
更多AI前沿科技资讯,请关注我们: