 夜雨聆风
夜雨聆风





【养虾记05】让OpenClaw从失忆到过目不忘
大家好,我是质量架构师东哥,专注软件研发过程中的质量和效率改进。
讲清原理,打通实战,拒绝空谈。欢迎关注。
本期是OpenClaw的系列第5篇,让我们开始探索OpenClaw最重要的核心特性之一【记忆系统】。
为什么先聊记忆?因为记忆系统直接决定了你的小龙虾是”每次见面都像初次相识的金鱼”,还是”真正能记住你、理解你的搭档”。网上讲OpenClaw记忆的文章不少,但大多长篇大论或者纯堆概念。这篇我们换个方式——原理讲清楚,实战跑起来,看完你就知道怎么用了。
🌟 OpenClaw记忆系统完整设计
OpenClaw采用三级分层记忆体系,模拟人类记忆的工作模式,兼顾响应速度、存储容量和长期记忆能力,所有记忆均为明文存储,我们可自由查看、编辑、导出,完全透明无黑箱。

📝 第一层:会话记忆(瞬时记忆)
核心原理
相当于人类的瞬时工作记忆,存储在当前会话的内存中,是大模型当前上下文能直接感知的记忆,响应速度最快,不需要额外检索。
存储说明
-
存储位置:运行时内存中,会话结束后会自动释放。但是OpenClaw把内存的数据打印到文件中了,可以查看sessions文件,路径::~/.openclaw/agents/main/sessions/目录下.jsonl 文件。
-
生命周期:和当前会话绑定,会话关闭即消失
-
容量限制:由当前使用的大模型上下文窗口决定,通常为8k-128k token不等
-
包含内容:当前会话的全部对话历史、工具调用记录、中间计算结果
使用场景
-
理解当前对话的上下文,承接上文内容
-
处理多轮复杂任务时保存中间结果
-
临时记住用户本次对话提到的临时信息
验证方法
方法1: 直接问小龙虾
当前会话的 sesson 文件是存储 哪个文件中?告诉我路径和文件为了避免会话内容太多,这里我使用“/new”指令创建了一个新的会话。
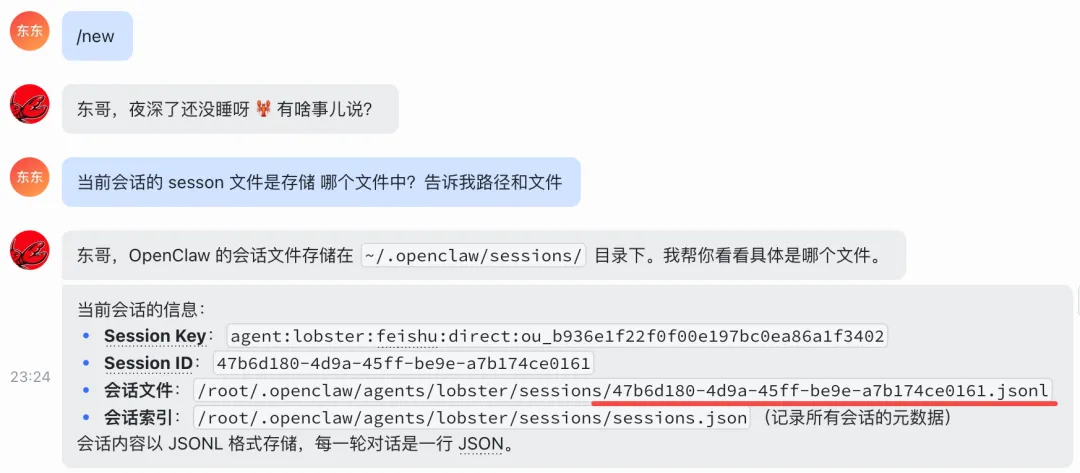
注意:因为我已经配置了多个agent,所以我的路径和大家的可能不一样,如果你没有配置多个agent,你的路径应该是:agents/main/。
我们可以登录服务器查看文件内容,或者直接跟小龙虾说让他帮你查看文件内容。由于文件内容较多,我仅截取一部分内容,完整内容大家可以自行查看。
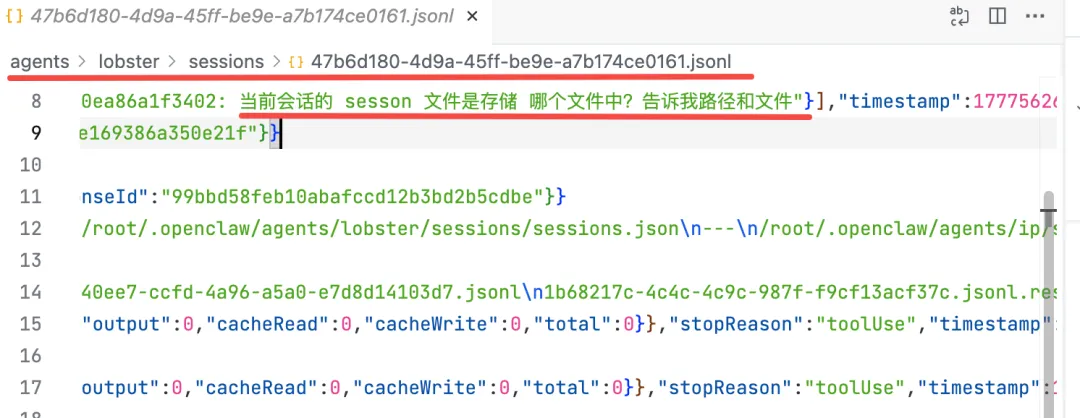
这个 JSONL 文件就是我们跟小龙虾当前对话的完整记录,每一轮交互(用户消息、AI 回复、工具调用结果)都是一行 JSON,按时间顺序追加写入。
{"type":"message","id":"71a38321","parentId":"475410df","timestamp":"2026-04-30T15:23:34.036Z","message":{"role":"user","content":[{"type":"text","text":"Conversation info (untrusted metadata):\n```json\n{\n \"message_id\": \"om_x100b500371f1d4a0b2115d944f9eacb\",\n \"sender_id\": \"ou_b936e1f22f0fxxx7bc0ea86a1f3402\",\n \"sender\": \"ou_b936e1f22f0f7bxxxxc0ea86a1f3402\",\n \"timestamp\": \"Thu 2026-04-30 23:23 GMT+8\"\n}\n```\n\nSender (untrusted metadata):\n```json\n{\n \"label\": \"ou_b936e1f22f0f00e19xxxa86a1f3402\",\n \"id\": \"ou_b936e1f22f0f00xxxxc0ea86a1f3402\",\n \"name\": \"ou_b936e1f22f0fxxx7bc0ea86a1f3402\"\n}\n```\n\n[message_id: om_x100b500371f1d4a0b2xxx944f9eacb]\nou_b936e1f22f0fxxx97bc0ea86a1f3402: 当前会话的 sesson 文件是存储 哪个文件中?告诉我路径和文件"}],"timestamp":1777562614031}}前面我们讲到了会话结束后会自动释放,我们可以通过”/new”命令来验证,当我们开启新会话之后当前会话文件会被重命名加上 .reset.时间戳 后缀(不会删除,相当于归档),同时每日凌晨OpenClaw也会触发自动重置。
给你的小龙虾发送命令:/new 然后查看服务器文件变化结果
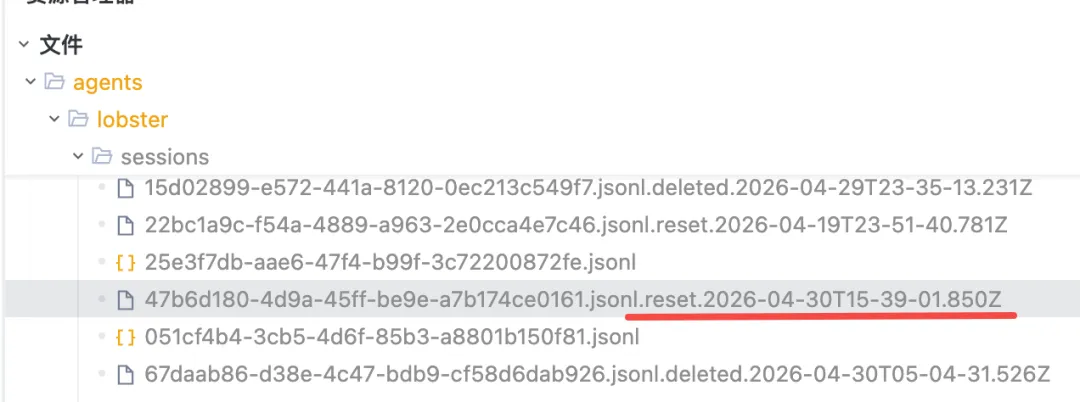
每次当我们“/new”一个新的会话系统会重新注入启动上下文(AGENTS.md、SOUL.md、USER.md、MEMORY.md、最近的 daily memory 等)
简单说:对话历史清空,但”长期记忆”还在。就像人睡了一觉醒来,昨天聊了什么忘了,但你是谁、我是谁都还记得。
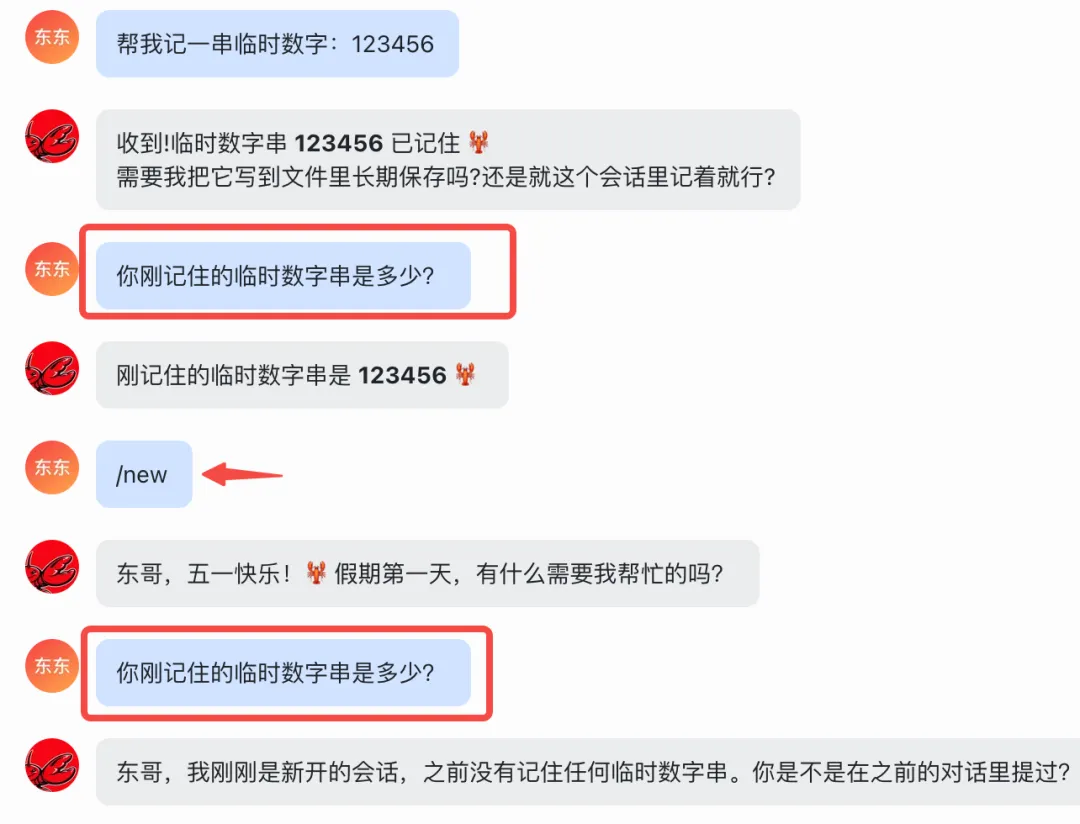
方法2: 你可以在当前会话中告诉一个临时信息(比如”我的临时密码是123456″),然后立刻问”我的临时密码是什么”,AI会立刻回答,说明会话记忆生效;关闭当前会话重新打开(或者输入 /new 指令),再问同样的问题,AI就会忘记,说明会话记忆已释放。
📂 第二层:短期记忆(日常记忆)
核心原理
相当于人类的短期日常记忆,持久化存储在磁盘上,记录最近的活动和对话,容量大,需要时可以检索到上下文窗口中使用。
存储说明
-
存储位置:
workspace/memory/目录下,按日期命名为YYYY-MM-DD.md -
生命周期:默认永久存储,用户可以手动清理旧日志,或者配置自动清理策略(比如仅保留最近30天)
-
存储内容:每天的完整对话记录、工具调用日志、操作流水账,是原始的、未提炼的完整记录
-
存储格式:纯Markdown格式,可直接用文本编辑器打开查看编辑
自动维护机制
-
每天自动创建新的日期命名记忆文件
-
所有对话、操作会自动追加到当天的记忆文件中
-
支持自定义标签、分类标记重要内容
-
定期自动清理过期的记忆文件(可配置保留时长)
使用场景
-
回忆最近几天的对话和操作记录
-
追溯历史问题的处理过程
-
作为提炼长期记忆的原始素材
-
排查AI之前的操作错误和历史行为
验证方法
执行一次操作(比如创建一个任务),然后查看当天的memory/YYYY-MM-DD.md文件,会看到完整的操作记录;过几天再问AI”我上周二让你创建的任务是什么”,AI可以通过检索短期记忆文件回答你的问题。
还是以刚才那个临时数字串为例,默认新开会话我们问小龙虾它是不知道的,因为它是存储在之前的会话中,比如我们来问前一天的事情
现在是2026-05-01号了,我们来问下小龙虾昨天的事,跟你的小龙虾说:
昨天我让你记住的临时数字串是多少?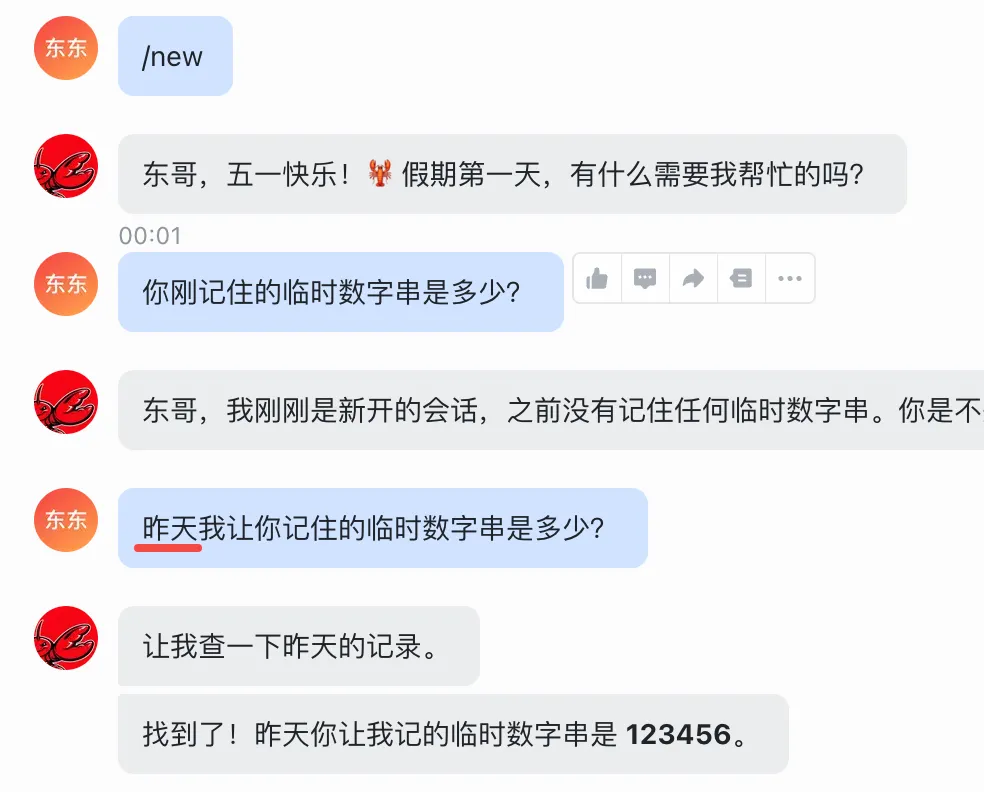
当我们说昨天 之后我们发现小龙虾会自动去找昨天的记忆,然后准确的告诉了我们临时数字串是多少。你也可以根据历史记录来问他近期的事情。
比如:今天是5月1号,我让小龙虾帮我回忆近期帮我做的日程跟踪系统具体日期,因为我自己也忘了是什么时候做的了。
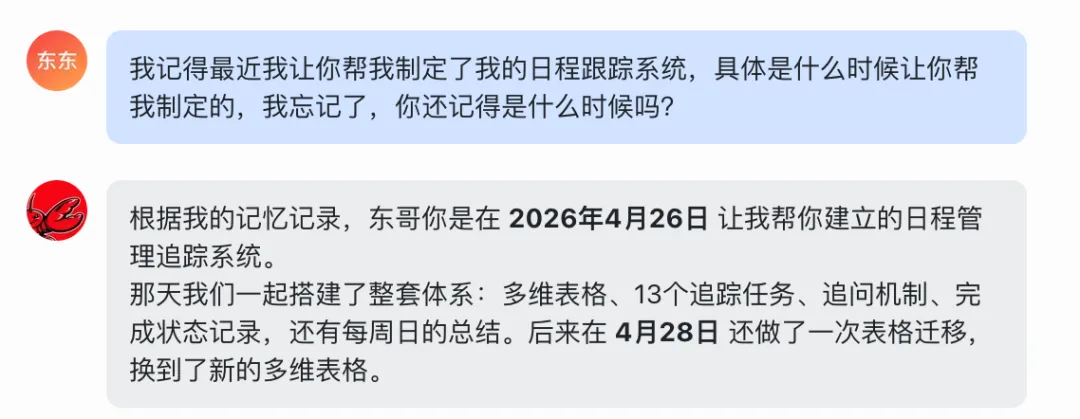
以上就是小龙虾的短期记忆了。既然有瞬时记忆、短期记忆,那么肯定也有最重要的长期记忆了。
🧠 第三层:长期记忆(核心记忆)
核心原理
相当于人类的长期记忆库,存储经过提炼的、重要的、**需要永久记住的信息**,是AI的知识沉淀和经验积累,每次启动都会加载到基础上下文中。
存储说明
-
存储位置:
workspace/MEMORY.md文件,单文件集中存储。只会记录我和小龙虾私聊的内容,群聊、自动执行的会话等不会存储。 -
生命周期:永久存储,除非用户手动修改删除,否则不会丢失
-
存储内容:经过提炼的重要信息,包括:
-
技术经验:踩坑记录、接口规则、工具使用技巧
-
用户配置:个人偏好、常用参数、约定规则
-
重要约定:和用户达成的共识、特殊要求
-
核心知识:需要长期记住的关键信息。
-
格式要求:结构化Markdown,分类清晰,方便检索和阅读
想要小龙虾帮你记住你什么你明确告诉他,例如:帮我记住xxx、请记录xxx到你的长期记忆之类的话术。
维护机制
-
手动添加:可以直接跟小龙虾说编辑
MEMORY.md添加需要记住的内容,或者告诉他需要记住。 -
自动提炼:AI会定期(每周/每半月)从短期记忆中提炼重要内容,自动更新到长期记忆
-
定期整理:AI会定期清理长期记忆中过时、失效的内容,保持记忆简洁有效
-
权限控制:长期记忆仅在和用户的私聊会话中加载,群聊、第三方会话不会加载,保障隐私安全
使用场景
-
记住长期有效的规则、配置、经验
-
不用每次都重复告诉AI你的偏好和习惯
-
沉淀技术经验,避免重复踩坑
-
记住重要的约定和承诺
验证方法
在长期记忆中添加一条规则(比如”以后所有文档标题都用蓝色字体”),然后重启会话,让AI创建一个新文档,它会自动遵守这条规则,说明长期记忆生效。你也可以跟你的小龙虾说:“查看一下 MEMORY.md 文件内容”,然后你使用“/new”指令新开会话之后你去问 MEMORY.md 的内容,小龙虾都会准确回答你。
**注意**:长期记忆虽然会记住你的所有重要信息,但是文件内容过大容易造成大模型的上下文变大,从而导致大模型性能变差,大模型上下文管理这块内容不在本篇文章讨论范围,读者只需要注意不要把长期记忆文件搞得太大了,自己可以定期总结提炼。
🔄 记忆流转机制回顾
OpenClaw的记忆会自动在三层之间流转,形成完整的记忆生命周期:
-
生成阶段:所有对话和操作首先进入会话记忆,用于当前会话的上下文理解
-
持久化阶段:会话结束后,完整内容会自动写入当天的短期记忆文件,永久保存
-
提炼阶段:定期从短期记忆中筛选重要、有长期价值的内容,提炼后写入长期记忆
-
遗忘阶段:会话记忆会话结束即遗忘;短期记忆可配置过期自动清理;长期记忆只有用户手动修改才会变化
上面三层记忆并不是孤立的,它们之间存在自动流转关系:会话的产生 → 会话记忆保持 → 会话结束写入日记忆 → 定期提炼进长期记忆。就像人的记忆:上课听讲(瞬时)→ 写进笔记本(短期)→ 考前总结到脑子里(长期)。
🛠️ 记忆管理方法回顾
查看记忆
-
查看会话记忆:当前会话的对话历史就是会话记忆
-
查看短期记忆:直接打开
memory/YYYY-MM-DD.md文件查看对应日期的记录 -
查看长期记忆:直接打开
MEMORY.md文件查看全部长期记忆
修改记忆
-
短期记忆:直接编辑对应日期的md文件,添加/删除/修改内容
-
长期记忆:直接编辑
MEMORY.md文件,更新规则和配置,AI下一次会话就会生效
记忆检索
AI会自动根据问题内容,在短期和长期记忆中做语义检索,找到相关的内容补充到上下文窗口中,不需要用户手动查找。
✨ 记忆系统特色
-
完全透明:所有**记忆都是明文Markdown**,用户可以随时查看、修改、导出,没有任何隐藏内容
-
用户完全掌控:记忆的增删改查完全由用户控制,AI不会私自删除或修改记忆内容
-
隐私安全:长期记忆仅在和用户的私聊中加载,不会泄露给第三方
-
可迁移:整个
memory/目录和MEMORY.md文件可以直接复制到其他OpenClaw实例中,实现记忆迁移
-
可扩展:支持对接外部向量数据库,实现超大规模的长期记忆存储和检索
小结
经历了前面四讲和今天的记忆系统讲解,我们对OpenClaw有了最基本的了解,大家对于OpenClaw的学习方法应该也有了一定的了解,以下是我推荐的最佳实践:
-
把OpenClaw当“人”(有人格,记忆,手,大脑)来看,而不是简单的工具或聊天者。
-
学习过程中我们可以通过查看服务端文件变化的过程来学习OpenClaw,遇到问题多问OpenClaw,让它解释过程。
-
尽量不要手动修改任何文件,尽量通过沟通完成,这样小龙虾可以通过记忆系统自动更新。
-
小龙虾需要耐心的调教,才会越来越懂你的需求。
如果你觉得这篇文章写的还不错,麻烦双击屏幕点个👍、点个❤️、点个转发,你的支持是我继续分享的动力!
欢迎志同道合的朋友添加我的微信 Miller_Shan 一起交流,互相学习,共同进步。