 夜雨聆风
夜雨聆风





AI 为什么突然开始谈 Harness Engineering?一次讲清楚背后的变化
2026 年 5 月 5 日,频道“马克的技术工作坊”发了一条 37 分钟的视频,标题不算炸,但它试图回答一个这几个月在 AI 圈越来越常见的问题:为什么大家突然开始谈 Harness Engineering?
如果你最近一直在看 AI 工程类内容,你会发现一个很微妙的变化。
前两年,大家最热衷讨论的是 Prompt Engineering。再后来,讨论慢慢升级成 Context Engineering。而现在,话题又往前推了一步,变成了 Harness Engineering。
表面上看,这像是 AI 圈又在换新词。
但这支视频里最值得记住的判断,恰恰是相反的:
这不是一次简单的概念翻新,而是工程重点真的变了。
因为当模型开始不只是回答一个问题,而是要连续工作几十分钟、调用工具、改代码、跑测试、修错误、读日志、做决策时,你会突然发现,真正卡住它的,已经不只是“你这句话写得好不好”。
卡住它的,是它有没有一整套能工作的环境。
从“怎么问”到“怎么喂”,再到“怎么搭一个能干活的系统”
这支视频讲得很清楚,Prompt Engineering、Context Engineering 和 Harness Engineering,其实不是彼此互斥的三件事,而像是三个时代的重点。
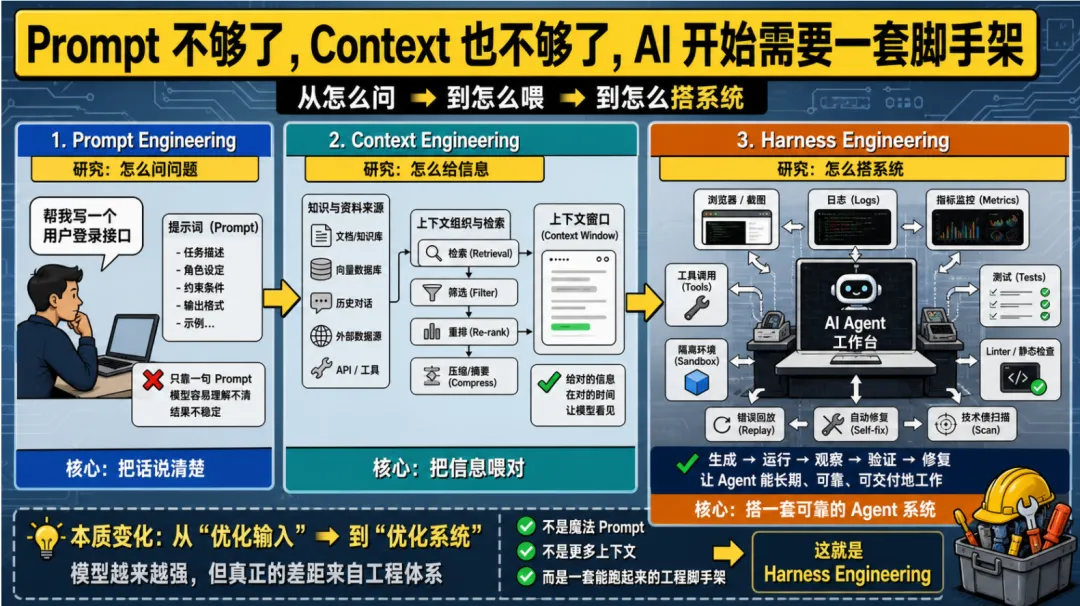
Prompt Engineering 解决的是最早的问题:怎么问。
你要把任务说清楚,把限制条件说清楚,把目标说清楚。模型不是听不懂人话,而是你得把话说成它更容易执行的样子。
后来大家发现,只靠一句 prompt 根本不够。
模型能不能做好事,往往取决于它到底看到了什么资料,记住了什么历史,又有没有拿到正确的背景信息。于是讨论升级成了 Context Engineering。
这时候,重点已经不是一句话怎么写,而是上下文怎么组织,记忆怎么保留,检索怎么接入,外部信息怎么送到模型眼前。
但到了 Agent 时代,问题又变了。
因为一个能长期运行的 AI,不只是“需要被喂信息”,它还需要:
-
有工具可以调用
-
有结果可以验证
-
有日志可以回看
-
有隔离环境可以试错
-
有机制避免越修越乱
这时候,工程师做的事就不再只是“提问”或者“喂资料”,而是在模型外面搭出一整套工作台。
视频里给出的定义非常直白:Harness Engineering 研究的,是如何构建和设计 Harness,也就是如何围绕大模型搭建一个完整可靠的 Agent 系统。
如果要把这个概念翻成更接地气的话,我会把它理解成:
给 AI 搭脚手架。
模型当然重要,但你不能只把一个很聪明的大脑丢进空气里,然后期待它自动交付结果。你得给它桌子、工具箱、监控器、测试台、返工流程,甚至还得给它一个能及时踩刹车的监督员。
OpenAI 不是让 Codex 更会写代码,而是让它更会自证
视频里第一个案例,是 OpenAI。
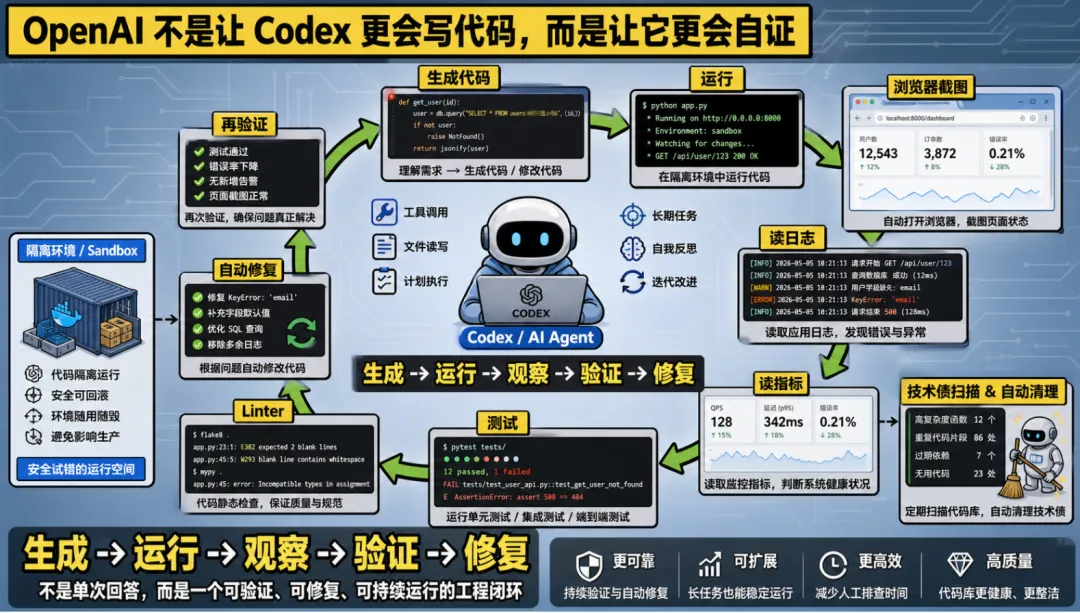
开头那句最抓人的话就是:OpenAI 用 Harness Engineering,在 5 个月里写了接近 100 万行代码。
这句话当然容易传播,但真正有价值的不是这个数字,而是它背后那套做法。
视频里反复强调,OpenAI 在 Codex 上做的核心工作,并不只是“把模型做强”,而是给它接上大量外部能力。
比如:
-
给 Codex 完整的工具调用能力
-
让它能读取日志、指标和系统状态
-
给它浏览器环境,能自己截图、自己观察页面
-
把每个任务放进隔离环境里跑
-
用 linter 和测试做第一层校验
-
让系统定期扫描代码库,自动修理偏离规范的地方
这背后其实是一种非常典型的工程思路。
你不再假设模型“一次写对”,而是假设它会犯错、会偏航、会留下技术债。既然如此,你就不要把全部希望押在模型本体,而是给它设计一个可回看、可验证、可修复的闭环。
这也是为什么视频里会说,到了 Harness Engineering 这一步,大家关心的已经不再只是 prompt 和 context,而是整个系统怎样确保一个 Agent 在真实环境里持续产出可靠结果。
说白了,OpenAI 做的不是“更会写代码的模型”,而是“更会证明自己写得对的系统”。
Anthropic 更像是在告诉你:Harness 不是模板,而是一轮轮试错
如果说 OpenAI 的案例像是“搭好一座高度工程化的工作台”,那 Anthropic 的案例更像是另一种现实主义:Harness 不是一个固定架构,而是试出来的。
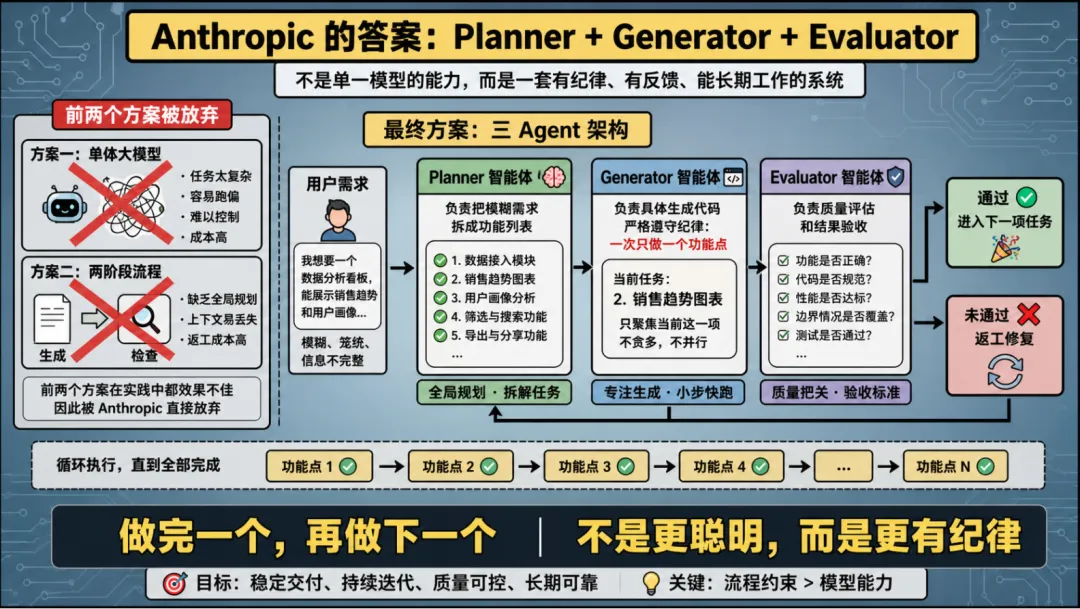
视频里讲 Anthropic 的部分,其实特别有代表性。
他们并不是一开始就拿到一个完美方案。相反,前两个方案都不满意,最后干脆废掉,重新做了第三个。
最终留下来的,是很多人现在已经很熟悉的三 Agent 架构:
-
Planner负责把模糊需求拆成清晰功能列表 -
Generator负责具体生成代码 -
Evaluator负责质量评估
这套架构听起来并不神秘,但视频里有一个细节特别重要:Anthropic 会在提示词里强制 Generator 一次只做一个功能点,做完一个再做下一个。
为什么要这么做?
因为如果让模型自由发挥,它很容易急于求成,一口气把所有功能都卷进去,最后留下一堆烂摊子。
这就是 Harness 的价值。
它不是给模型“增加智商”,而是给模型“增加纪律”。
很多时候,真正让系统稳定起来的,不是某个更大的参数量,而是一条很不起眼但很严格的工程约束。
你也可以把它理解成:Harness 的本质,是把“聪明”收编进流程。
这个词为什么会火?因为它踩中了一个时代情绪
视频后半段有一部分我很喜欢,它没有急着继续讲技术,而是回头追问:Harness Engineering 这个词,为什么突然火了?
作者给出的线索很有意思。
一方面,OpenAI 和 Anthropic 的文章把相关实践同时推上了台面。另一方面,Martin Fowler 网站上的那篇 Harness Engineering – First Thoughts,又把这个说法放大成了整个软件工程圈都能讨论的话题。
视频里还提到一个更早的名字:Mitchell Hashimoto。
也就是说,这个词并不是某天凭空降临的“官方学科”,它更像是工程圈先有了一堆散落的实践,后来终于被人用一个词打包了。
这很像很多技术名词的诞生方式。
先有问题。再有土办法。再有局部最优解。最后才有人回头说,原来这整堆东西可以叫一个名字。
所以大家才会觉得它既像真东西,又像包装。
说它像包装,是因为里面很多技术并不新。说它是真东西,是因为这些旧技术第一次被系统性地放到了 Agent 时代的主战场。
它不是噱头,但也不是终局
这支视频最成熟的地方,是它没有把 Harness Engineering 吹成下一场宗教。
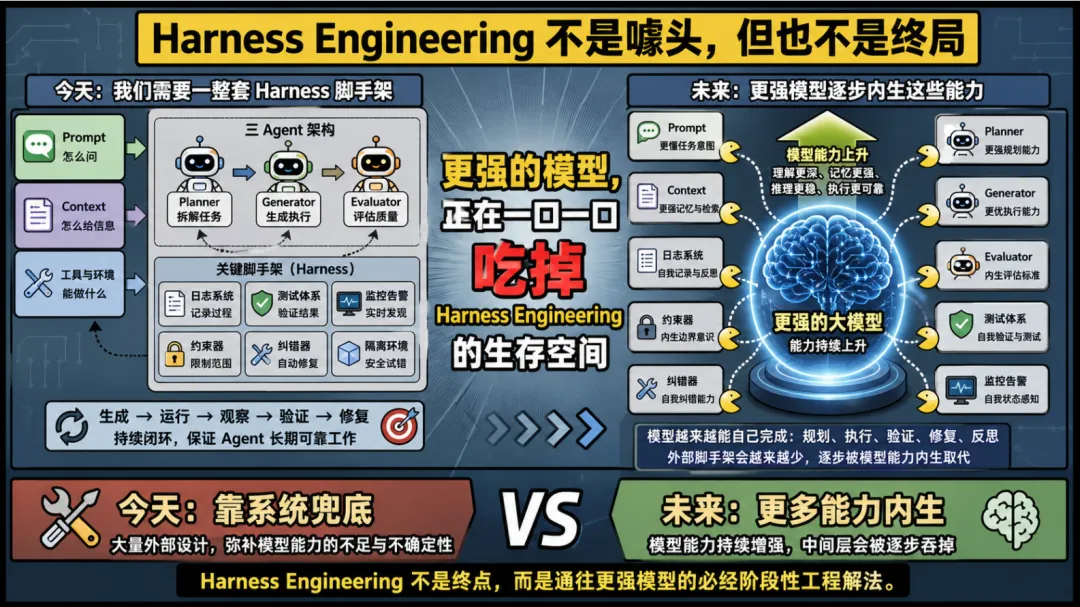
作者最后给出的判断非常克制:
Harness Engineering 不是噱头,但应该也不是终局。
为什么不是噱头?
因为无论是 OpenAI 还是 Anthropic,都已经靠这套方法拿到了真实收益。它不是停留在 PPT 上的概念,而是直接影响了长程 Agent 是否可用、是否稳定、是否能交付结果。
为什么又不是终局?
因为很多今天看起来必须依赖 Harness 才能解决的问题,本质上是在替模型能力不足打补丁。
当模型还不够稳、不够长程、不够自律的时候,你当然要靠外部系统去约束它、纠错它、监督它。
但随着模型继续变强,今天很多看似必要的脚手架,未来很可能会被模型本身慢慢吃掉。
视频里那句很有画面感的话是:
更强的模型,正在一口一口吃掉 Harness Engineering 的生存空间。
这句话听上去有点悲观,但其实它说的是一个更本质的工程规律:
很多中间层设计,都会随着底层能力的增强而被吸收。
今天你需要专门的约束器、拆分器、重置器和评估器。明天,也许模型自己就能干掉其中一半。后天,剩下来的那一半,会变成默认基础设施。
真正变的,不是一个名词,而是工程师的角色
所以看完这支视频,我觉得最值得记住的,不是 Harness Engineering 这个词本身,而是它背后暴露出来的角色变化。
过去,很多人把 AI 工程理解成“会写 prompt”。后来,大家发现还得“会喂 context”。现在,真正开始做长程 Agent 的团队已经发现,最后拼的其实是:
-
你怎么设计工具链
-
你怎么安排验证机制
-
你怎么处理失败回路
-
你怎么给模型建立纪律
-
你怎么把一个聪明但不稳定的系统,变成一个可持续工作的系统
这已经很像传统软件工程了。
只不过,这一次你面对的不再是一个完全确定的程序,而是一个会犯错、会跑偏、偶尔还会自作聪明的“概率型同事”。
于是,新的工程价值就出现了。
不是替模型写答案,而是替模型搭环境。不是追求一句神 prompt,而是设计一套能活下来的系统。不是迷信某个概念,而是老老实实把 Agent 放进真实世界里跑通。
这也是为什么我会觉得,这支视频讲的不是一个流行词,而是一种很现实的提醒:
AI 工程正在从“如何使用模型”,走向“如何驯服一个会工作的系统”。
这一步,才是真正麻烦,也真正有价值的地方。