现在我日常开发几乎 100% 依赖 AI Coding,哪怕是最简单的变量重命名、代码整理这类基础操作,也会交给 AI 处理。很多时候想手动修改代码,却总会纠结:交给 AI 是不是能做得更好?最后还是习惯性换成 AI 来处理。我暂时说不清这是好事还是坏事。虽然没有影响工作产出的质量和效率,但手写代码能力的退化、对自身手工编码能力的不自信,似乎是一个不可逆的趋势。这就像老一辈程序员不再需要手写机器码、汇编语言一样,传统手写编码能力,仿佛慢慢成了时代的印记。心里难免有些不舍,但技术和时代的向前发展,又让这种变化成为必然。或许 LLM 就是新时代的编译器,大幅拉高了编程的抽象层级,相当于在人类与计算机之间,搭建了一个更高效的自然语言翻译桥梁。编程语言本身的发展历程,就是不断走向更高抽象的过程:从机器码到汇编语言,再到 C 语言这类面向过程编程、C++/Java 这类面向对象编程;而如今借助 AI,我们可以直接用自然语言完成编程,这是又一次技术革新,让人类与机器的沟通变得愈发便捷。
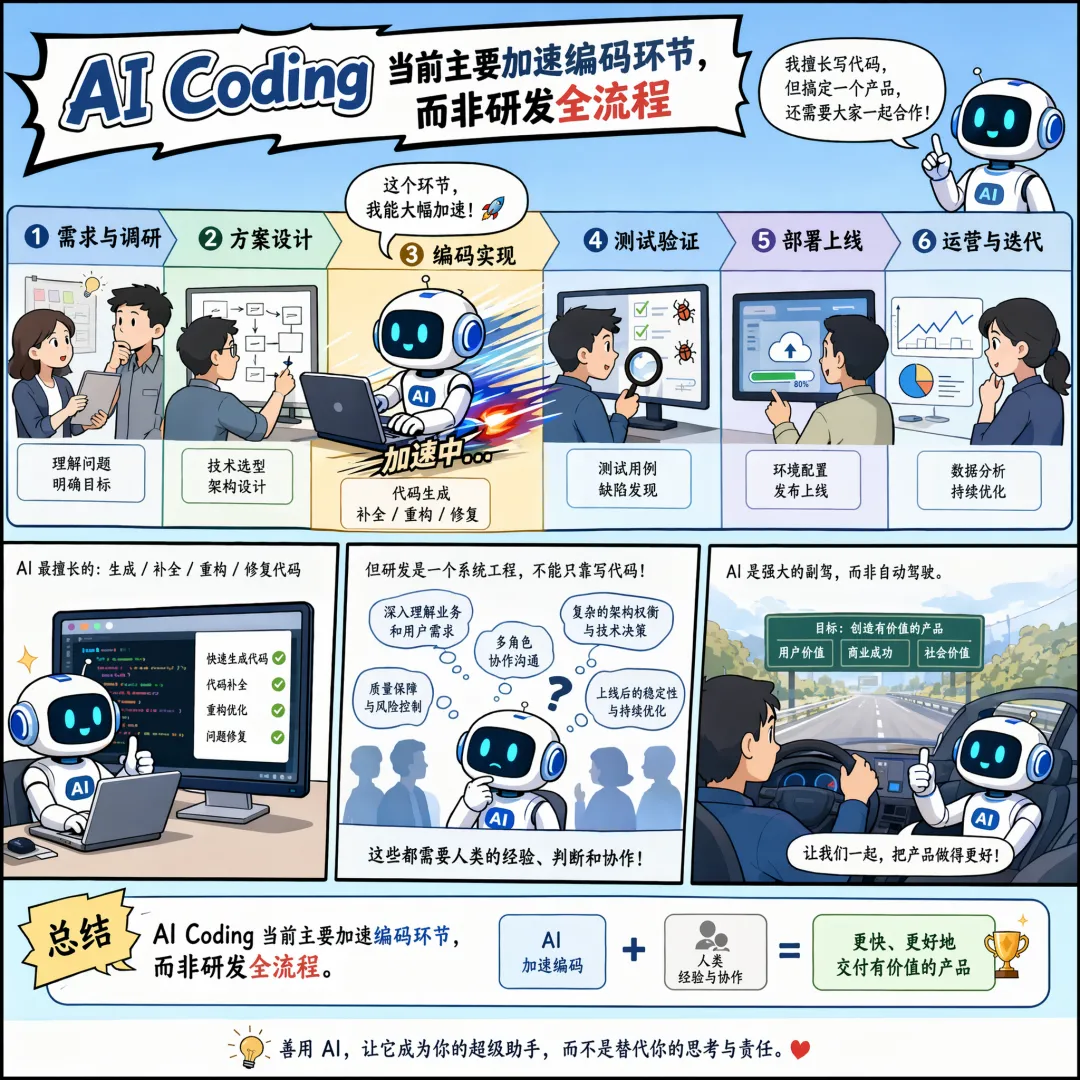
编码环节的效率基本已经被 AI 充分优化,但软件研发的整体瓶颈,更多集中在需求对接、方案设计、测试验证等前置后置环节。编码只是软件研发的其中一个子环节,只优化编码环节,很难实现整体流程大幅提效。研发工作中,我们大部分时间都消耗在前期需求方案制定、后期测试验证以及长期运维迭代上。只有实现全流程协同提效,才能真正放大 AI 的价值。而这一切的基础,都依赖于打通系统上下游、完善上下文链路,后续行业也大概率会围绕这个方向持续创新。
我的一些技巧
AI 解决的问题需控制在合理规模
面对大型项目重构,AI 无法一次性完成整体重构工作。最高效的人机协作方式是:先拆解大型任务,梳理清楚系统整体架构与核心骨架,再拆分出 AI 容易理解的小块任务,逐个击破。这样做有两大优势:一来适配 AI:如果任务规模过大,AI 模型的实际效果会大打折扣。受限于上下文长度、模型自身能力等因素,当前 AI 很难一次性承接大规模重构需求。二来方便人工:降低代码评审的心智负担。即便 AI 生成代码质量再好,上线生产环境前也必须经过人工评审。将大任务拆分成小模块逐一评审,既能减轻评审人的工作量,也能更早发现问题、及时纠正设计方向。
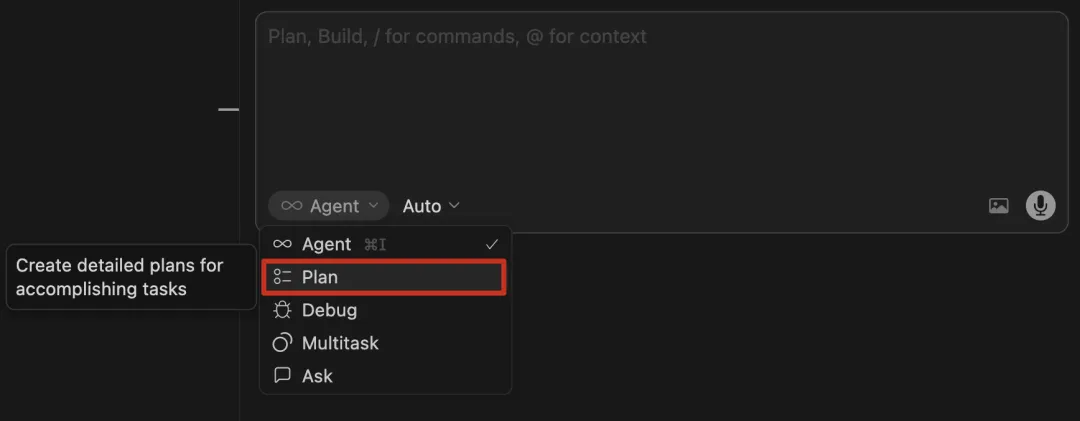
Plan Mode
不同类型的开发问题,适合搭配不同的 AI 协作模式:
小型问题:如简易代码重构、变量重命名等基础操作,直接用 Agent 模式,简洁高效。
中型问题:适合使用 Plan 模式,让 AI 动工前先对齐需求与实现方案,整体效率更高。
大型问题:如整项目重构,建议人工先把任务拆解为 AI 可理解、可落地的细分模块,再用 Agent 或 Plan 模式逐个解决。
我日常开发中,大约 80% 的场景会用 Plan Mode,剩余 20% 使用 Agent Mode。
Plan Mode 核心优势
提前对齐需求和实现方案,避免 AI 开发中途偏离预期,浪费 token 和开发时间。
将 Plan 文件归档到 Git 是极佳习惯
文中所说的Plan文件,指各类编码助手执行开发前生成的方案Markdown文档,类似Cursor的plan.md文件(一般位于 ~/.cursor/plans/ 目录下)。归档好处如下:便于人工代码评审如今 AI 生成的代码变更量大,大幅增加了评审难度。我做代码评审时,都会先通读 plan.md,理清本次代码变更的整体思路脉络,再看具体代码。便于后续追溯复盘现有代码的设计逻辑,往往源于过往的某次方案决策。归档后的文档,能为后续的迭代设计提供参考依据。我也观察到部分团队已经形成规范:让 AI 生成方案后,先将 plan.md 提交到 Git 进行方案评审,评审通过后再单独提交 AI 生成的业务代码。先文档对齐意图、再落地代码实现,足以看出 AI Coding 已经深度融入研发流程。
Plan 文件归档方式
借助现有工具
目前热门的 Openspec 就是一套成熟的 Plan Mode 方案,支持将 Plan 文件归档到 Git,方便人和 AI 后续查阅。但不少人反馈,Openspec 工作流会消耗较多 token。
自定义指令
如果不想使用复杂的 Openspec 工作流,追求轻量化归档,可以参考我的方式:自定义 Cursor 或 Codebuddy 归档指令,开发任务完成后,自动将 Plan 文档归档到项目指定目录。(文末会分享我常用的自制指令)
Bring Your Own Agent:借助 AI 参与代码评审
AI 生成代码的体量激增后,人工评审已经逐渐跟不上节奏,人反而成了研发流程、代码评审环节的瓶颈,用 AI 辅助做代码评审,已然成为刚需且高效的方式。可以将团队或个人的代码规范(包含安全规范、可观测性、测试覆盖率等标准)沉淀为通用的 skill,供 AI 直接调用。对评审人和代码提交人来说,AI 辅助评审都极具价值。对评审人而言可直接让 AI 拉取提交记录、对比代码变更,并按照既定代码规范完成初审。实际使用中,AI 往往能给出很有价值的优化建议。当然,人工评审不能完全依赖 AI。我通常会在 AI 评审的同时,同步人工逐行核对,避免遗漏关键细节。如果提交方同步上传了 plan.md,优先通读方案文档,对齐代码变更的核心目的,再评审代码,效率会大幅提升。对代码提交人而言正式提交代码前,可先让 AI 审核自身的代码变更,给出优化建议并自行修复完善。若开发过程使用了 Plan 模式或 Openspec,可同步提交 plan.md 等技术文档,进一步提升代码评审效率。
 夜雨聆风
夜雨聆风