 夜雨聆风
夜雨聆风





OpenAI 公开了 MRC:一种为大规模 AI 训练设计的网络协议

5 月 4 日,OpenAI 在官方博客上公布了一项与 AMD、Broadcom、Intel、Microsoft、NVIDIA 共同研发了两年的网络协议——MRC(Multipath Reliable Connection,多路径可靠连接),并通过 Open Compute Project(OCP)将完整规范开源。这套协议已经在 OpenAI 当前最大规模的 NVIDIA GB200 训练集群上线,包括与 Oracle Cloud Infrastructure 合作的德州阿比林(Abilene)站点,以及微软的 Fairwater 超算。
这篇文章不打算给 MRC 加任何戏剧色彩,目的只有一个——把 OpenAI 这次公开的研究内容介绍清楚。
训练网络面临的两个核心问题

大规模模型训练通常采用同步预训练:成千上万张 GPU 锁步前进,每完成一步要做大量跨 GPU 的数据同步。这种工作模式让训练任务对网络延迟和故障非常敏感——只要任意一笔数据传输慢一点,所有 GPU 就要等它。集群规模越大,单个失败被放大的代价越夸张。OpenAI 在文章里把这种特性称为 failure amplifier(故障放大器)。
由此衍生出两个对网络的核心要求:
- • 尽量让网络核心区不出现拥塞。除了无法避免的瓶颈(比如多张 GPU 同时往一个目标写入),其他场景下应当从设计上消除拥塞。
- • 把链路与设备故障对训练任务的影响降到最小。规模够大的网络一定会有”背景级别”的链路抖动和交换机故障,过去单一故障常常意味着训练崩溃、回滚到上一个 checkpoint,或者长时间停顿等待网络重新收敛。
MRC 就是在这两条目标下做出来的。
MRC 是什么,已经部署在哪里

MRC 是构建在最新 800Gb/s 网卡里的网络协议,扩展自业界已有的 RoCE(RDMA over Converged Ethernet),并吸收了 Ultra Ethernet Consortium(UEC)的部分思路,再叠加 SRv6(IPv6 段路由)做静态源路由。它能把单笔数据传输拆散到上百条物理路径上同时跑,并以微秒级响应链路故障。
OpenAI 表示,这套协议已经在他们最大规模的 GB200 集群上跑了多次前沿模型训练(包括 ChatGPT 与 Codex 用到的某个前沿模型),合作部署方包括 Microsoft Azure、OCI、NVIDIA、Arista。同时他们与五家厂商联名发表了完整论文:“Resilient AI Supercomputer Networking using MRC and SRv6”。
多平面网络拓扑
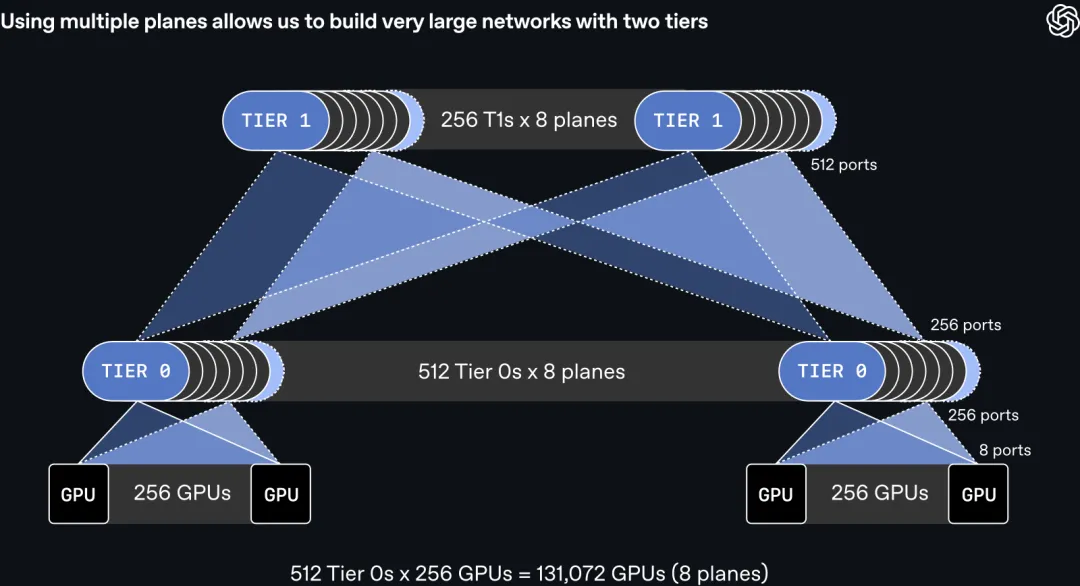
MRC 的第一层设计是把每张 GPU 的网卡接线方式变了。
按传统做法,一张网卡是一根 800Gb/s 的链路,接到一台高端交换机上。MRC 用的是多平面(multi-plane):同一张网卡被切成 8 个 100Gb/s 的端口,分别接到 8 台不同的交换机上。这 8 套交换机彼此独立、互不互通,相当于在物理上叠了 8 张并行的小网络。
这样切之后,一台原本只能接 64 个 800Gb/s 端口的交换机,可以接 512 个 100Gb/s 端口。容量密度提升 8 倍,让一个完全互联约 13 万张 GPU 的网络只用两层交换机就能搭出来。
多平面如何减少了硬件层数
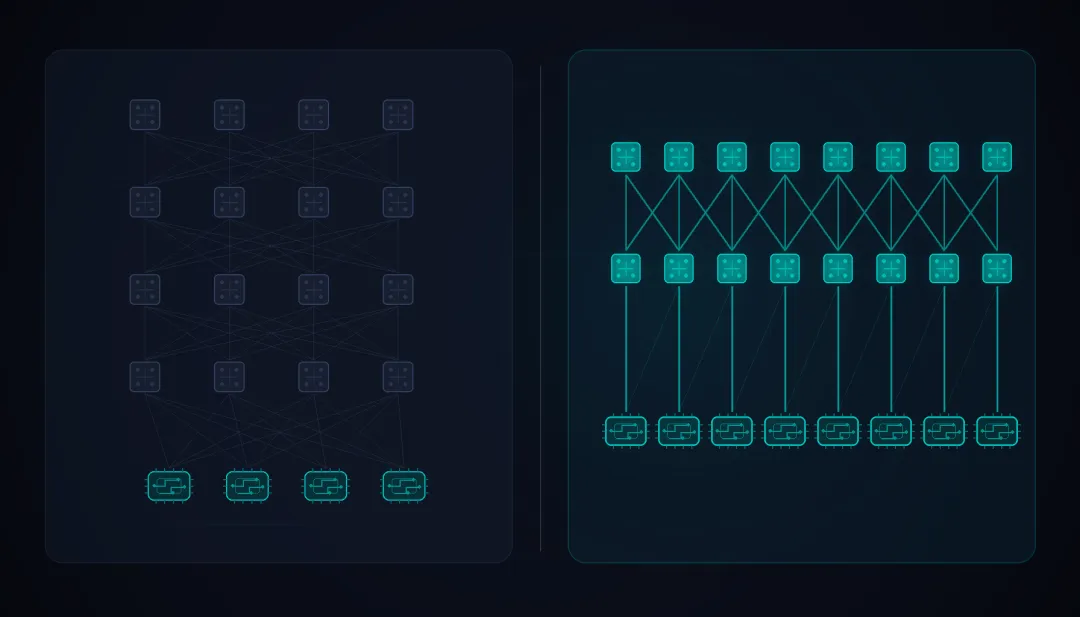
如果继续用传统单平面 800Gb/s 网络去连相同数量的 GPU,需要堆三层、甚至四层交换机。多平面把它压缩到两层,带来的影响是连锁的:
- • 总功耗下降;
- • 总组件数下降,意味着可能出故障的硬件更少;
- • 平均跳数减少,有更多通信能停留在 Tier 0 交换机本地;
- • 路径多样性变高,单根线坏了还有别的并行平面可以补位。
多平面网络的一个类比

可以这样想:传统 800Gb/s 单平面网络相当于一条很宽的高速公路,一旦中间某个收费站打结,整条路都会堵;多平面相当于把一条主路拆成 8 条独立的辅路并排走,任意一条辅路堵了,其他 7 条照常通畅,总宽度不变。
多平面下传统协议遇到的瓶颈
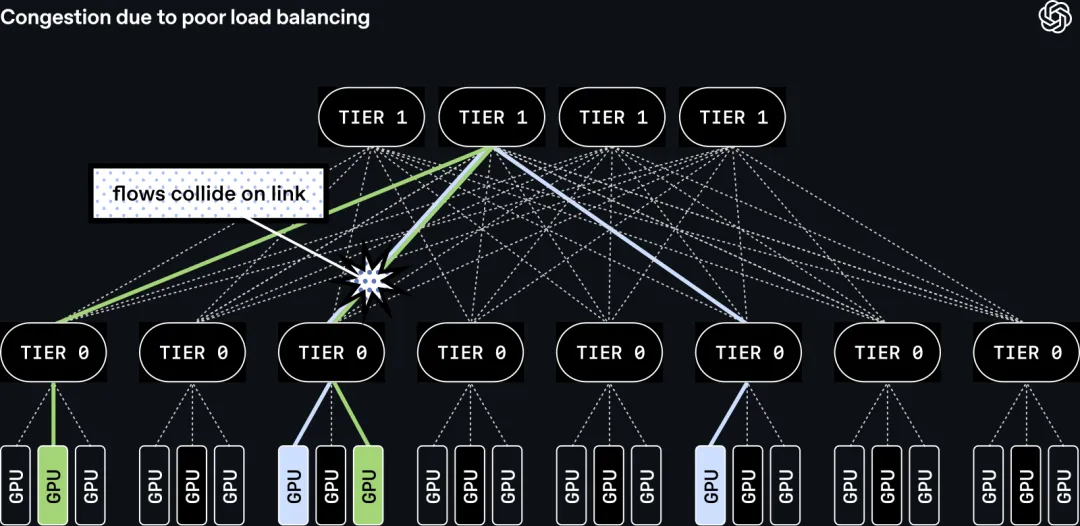
但多平面只是把”管道”准备好。问题是,传统的 AI 训练网络协议(比如经典 RoCE)为了保证包顺序,每一笔传输只走一条路径。这意味着:
- • 一笔流只能用 8 条平面里的其中 1 条,剩下 7 条空着;
- • 不同流量很容易在同一条链路上撞到一起,制造局部拥塞;
- • 同步通信对最差延迟(worst-case latency)极其敏感,局部拥塞会拉低整体训练速度。
如果不动协议层,多平面就只是一堆昂贵的、利用不起来的带宽。
跨多路径的包喷洒
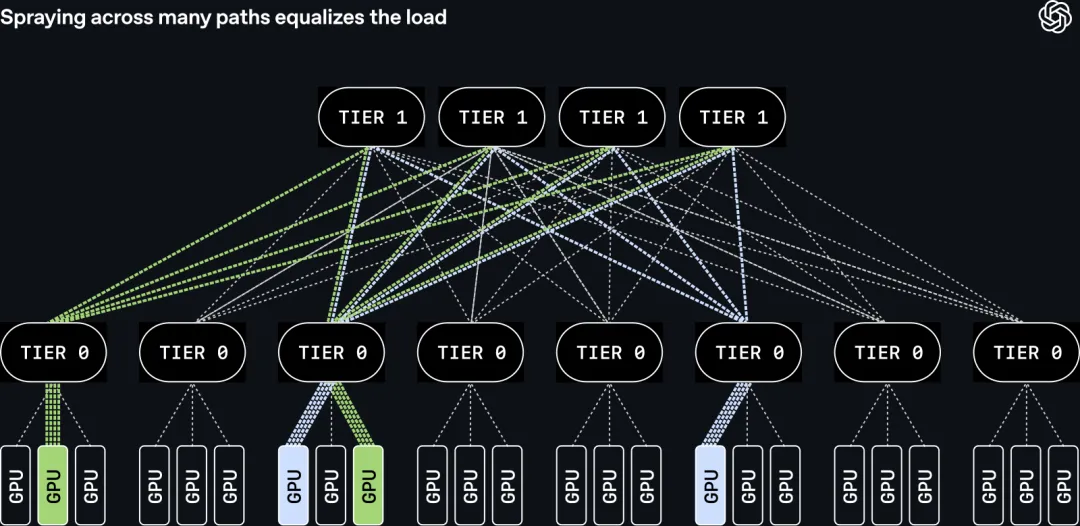
MRC 在协议层做的核心改动是 packet spraying(包喷洒):单笔传输的数据包不再走一条路径,而是同时散到上百条路径上、跨所有平面发出。
这要求接收端能处理乱序到达。MRC 让每个数据包都自带”目标内存地址”——也就是说,包不依赖到达顺序就能被对端正确写入到该写的位置。
包喷洒下的拥塞与故障处理

每条 MRC 连接会为它使用的多条路径维护少量状态:
- • 拥塞感知:如果某条路径开始变慢(出现拥塞迹象),就把流量挪到其他路径上,做主动负载均衡。
- • 快速避障:一旦在某条路径上发现丢包,立刻停用这条路径并重传可能丢失的包。MRC 默认丢包就是路径出问题。
- • 被动恢复:随后向被停用的路径发送探测包,确认是真坏了还是只是抖一下;好转后自动放回路径池继续用。
这套机制把链路故障的应对时间压到微秒级。作为对比,传统网络遇到大故障重新收敛、绕开故障,可能需要几秒甚至几十秒。
包修剪:区分拥塞与故障

光靠”丢包就停用路径”会出现误伤——并不是所有丢包都意味着路径坏了,更多时候只是接收端附近的瞬时拥塞。
MRC 配合的解决办法叫 packet trimming(包修剪):当交换机马上要因为缓冲区满而丢弃一个包时,它不直接丢,而是只截掉数据包的 payload,把包头转发给目的端。目的端收到这种”瘦身”过的包,就知道刚才发生的是拥塞而不是路径故障,于是显式请求重传,而不是把这条路径打入冷宫。
用 SRv6 静态源路由替换动态路由

有了 MRC 的端到端故障感知,传统交换机里跑的动态路由协议(比如 BGP)就显得多余且容易出问题。OpenAI 干脆把动态路由关掉,改用 SRv6(IPv6 段路由):
- • 由发送端直接在数据包的目标地址里编码这个包要依次经过哪些交换机;
- • 每台交换机只做一件事——查包头里下一跳是不是自己,把自己的标识从地址里”剥掉”,再按一张静态路由表把包转给下一跳;
- • 这张静态路由表是初次配置时写死的,之后不再变更。
这样做的好处是网络的控制面变得极其简单,从一个会自适应推理的复杂系统降级成”按表搬运”,从而消除一整类来自动态路由协议的诡异故障行为。MRC 用 SRv6 把数据包同时撒到多个平面、多条路径上;某条路径不可用时,发送端自己换路径就行,交换机不需要重新计算任何东西。
真实训练任务中的表现
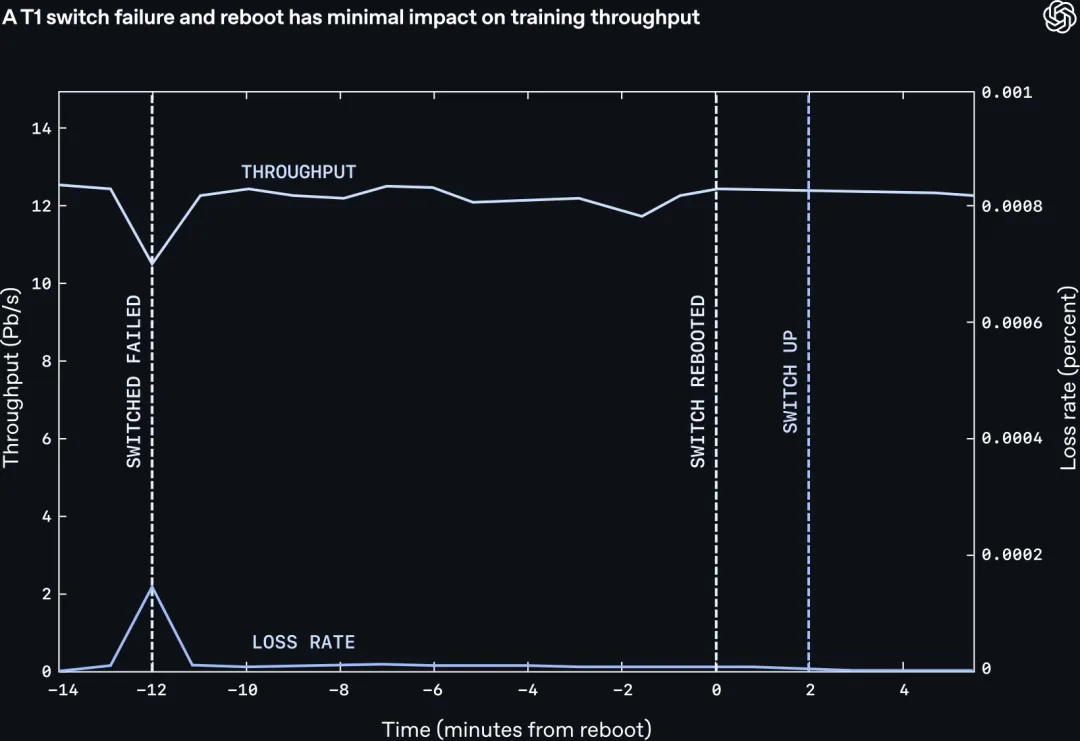
OpenAI 在文章里给出了一些生产环境的实测数字:
- • 他们的训练网络包含数百万根链路。规模到这个量级,每分钟在 Tier 0 与 Tier 1 之间都会观察到多次链路抖动。MRC 上线后,这类抖动对同步预训练任务没有可测量的影响,运维甚至不需要把这些链路列为优先维修对象。
- • 训练某个前沿模型期间,他们重启了 4 台 Tier 1 交换机。在 MRC 之前,这种动作需要和训练团队协调时间窗,小心避开训练;现在不需要事先通知,直接重启即可。链路维修也能在不停机的情况下完成。
- • 当一张 GPU 网卡的 8 个端口里坏了 1 个,最大速率下降 1/8。MRC 会在微秒级检测到,重新计算路径绕开那个失效平面,并通知所有对端不要往这个平面给我发数据。绝大多数链路在一分钟内自愈,自愈后 MRC 自动把它放回路径池。
上面这张原文图展示了一段真实训练运行时,吞吐和丢包率随交换机失效与重启的变化曲线:故障瞬间吞吐有一个短暂的小坑、丢包率有一个尖峰,之后很快恢复并稳定运行。
数据中心里的物理形态

MRC 解决的是软件协议层的问题,但它对应的物理基础设施是真实存在的。OpenAI 在文章里也放出了几张阿比林超算内部的近景照——成排的 GB200 服务器、密集走线的光纤跳线,以及在机柜上呈束状穿行的网线。MRC 要管理的,正是这种以百万根为单位计的链路集合。
三个核心改进

OpenAI 自己把 MRC 的价值归纳为三点:
- • 拓扑层:用多平面让一张超过 10 万张 GPU 的网络只需要两层 Ethernet 交换机,比等容量的三/四层单平面方案省电、省料、也更容易容错。
- • 传输层:自适应包喷洒使核心网络几乎看不到拥塞,因此同步训练里不同流的吞吐差异显著缩小,多任务共享集群时也不会互相拖累。
- • 控制层:SRv6 静态源路由让网络绕开故障的速度从秒级降到微秒级,并消除了一整类来自动态路由的运行期不稳定。
MRC 已通过 Open Compute Project 发布完整规范(OCP-MRC-1.0),任何想自建大规模 AI 训练集群的厂商都可以照规范实现,参与生态共建。OpenAI 表示,这是他们整体算力策略的一部分:把基础设施层的关键标准做成共享标准,整个行业才有机会跟上前沿模型扩张的节奏。