 夜雨聆风
夜雨聆风





ai4protein论文推荐 | 2026-05-07
今日相关 / Relevant Today
AI4Protein 前沿追踪
AI 深度解读
本文提出了一种将流采样(Flow Sampling)框架扩展至黎曼流形的通用方法,旨在解决非欧几里得几何空间中的扩散模型采样问题。研究首先构建了黎曼流形上的扩散过程,利用指数映射和正交投影处理切空间内的随机微分方程,并推导了流形上的 Fokker-Planck 方程。针对流形上的插值路径,文章引入了测地线插值机制,并基于雅可比场理论推导了测地线映射的解析解及其雅可比矩阵的闭式表达。在此基础上,研究给出了黎曼流形上的条件漂移项的精确计算公式,该公式仅由秩 -1 矩阵构成,保证了计算的高效性。最终,通过最小化模型预测漂移与理论条件漂移之间的差异,实现了在黎曼流形上的流采样训练,为扩散模型在球面、双曲空间等非欧几里得几何中的应用提供了坚实的理论基础与算法支持。
中文摘要
摘要:从非归一化密度中采样类似于生成建模问题,但目标分布由已知的能量函数定义,而非数据样本。由于评估能量函数通常成本高昂,主要挑战在于学习高效的采样器。我们提出了 Flow Sampling,这是一个基于扩散模型和流匹配框架,专为无数据场景设计。我们的训练目标以噪声样本为条件,并回归至由能量函数构建的去噪扩散漂移项。相比之下,扩散模型的目标以数据样本为条件,并回归至加噪扩散漂移项。我们利用插值过程来最小化训练期间的能量函数评估次数,从而获得一种高效且可扩展的非归一化密度采样方法。此外,我们的公式自然地扩展到了黎曼流形,使得能够在欧几里得空间之外的几何结构中实现基于扩散的采样。我们推导了恒定曲率流形(包括超球面和双曲空间)上条件漂移的闭式公式。我们在合成能量基准、小肽、大规模摊销分子构象生成以及定义在球面上的分布上对 Flow Sampling 进行了评估,展现了强大的实证性能。
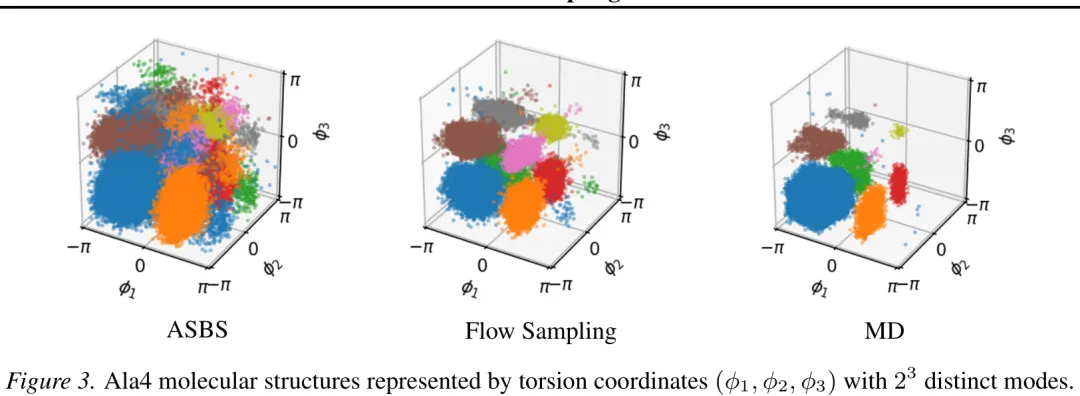
Paper Key Illustration
原文
Flow Sampling: Learning to Sample from Unnormalized Densities via Denoising Conditional Processes
Abstract: Sampling from unnormalized densities is analogous to the generative modeling problem, but the target distribution is defined by a known energy function instead of data samples. Because evaluating the energy function is often costly, a primary challenge is to learn an efficient sampler. We introduce Flow Sampling, a framework built on diffusion models and flow matching for the data-free setting. Our training objective is conditioned on a noise sample and regresses onto a denoising diffusion drift constructed from the energy function. In contrast, diffusion models’ objective is conditioned on a data sample and regresses onto a noising diffusion drift. We utilize the interpolant process to minimize the number of energy function evaluations during training, resulting in an efficient and scalable method for sampling unnormalized densities. Furthermore, our formulation naturally extends to Riemannian manifolds, enabling diffusion-based sampling in geometries beyond Euclidean space. We derive a closed-form formula for the conditional drift on constant curvature manifolds, including hyperspheres and hyperbolic spaces. We evaluate Flow Sampling on synthetic energy benchmarks, small peptides, large-scale amortized molecular conformer generation, and distributions supported on the sphere, demonstrating strong empirical performance.
链接:https://arxiv.org/pdf/2605.03984
AI 深度解读
本研究针对最大熵原理(MEP)在蛋白质序列建模中的核心问题展开探讨,重点比较了四种不同参数密度与熵值的 DCA 模型(eaDCA、bmDCA、edDCA、meDCA)在生成能力上的差异。研究首先通过理论分析指出,尽管各模型在拟合精度(Pearson 相关性)上表现相当,但其熵值存在巨大差异(相差约 37 个单位),这意味着高熵模型(meDCA)所采样的序列空间体积是低熵模型(eaDCA)的约 10^16 倍。随后,研究利用 AroQ 家族分支酸变位酶(CM)作为实验验证平台,通过高通量体内互补实验,测试了各模型生成的合成序列在不同序列分歧度(20%-65%)下的功能活性。实验结果表明,所有模型均能生成具有功能的新型酶,但在高分歧度区域,低熵模型的功能序列比例略低于高熵模型。进一步的跨模型评分分析揭示了一个关键不对称性:低熵模型对高熵模型生成的许多序列赋予极低的概率,而高熵模型则能覆盖低熵模型未能识别的序列区域。这一发现证实了高熵模型能够访问更广阔的函数序列空间,揭示了在保持生成质量的同时,模型熵值决定了其探索序列景观广度与多样性的能力,为理解蛋白质序列空间的拓扑结构提供了重要依据。
中文摘要
摘要:基于进化序列数据训练的玻尔兹曼机已成为人工蛋白质数据驱动设计的一种强大范式。然而,模型架构(特别是参数密度)与实验性能之间的关系尚不明确。本文以 chorismate mutase 酶家族为模型系统,对此关系进行了探究。我们将用于直接耦合分析(DCA)的标准全连接玻尔兹曼机(bmDCA)与通过渐进式边激活(eaDCA)和边删减(edDCA)生成的稀疏模型进行了比较。我们识别出沿删减轨迹的最大熵模型(meDCA),该模型在约束满足与概率分布的灵活性之间实现了最佳平衡。我们利用体内互补测定法合成并测试了来自所有模型的人工序列,发现无论稀疏程度如何,所有架构均能生成具有高成功率的功能性酶,即使与自然序列存在显著差异。尽管存在这种功能等效性,我们证明 meDCA 模型采样的可行序列空间比其低熵对应物大超过十五个数量级。此外,比较分析表明,高熵模型能够系统性地最小化过拟合,并更好地捕捉自然蛋白质周围的局部中性空间。这些发现表明,虽然满足共进化统计的各种模型均可生成功能性序列,但高熵玻尔兹曼机提供了对潜在进化适应度景观的更优表征。
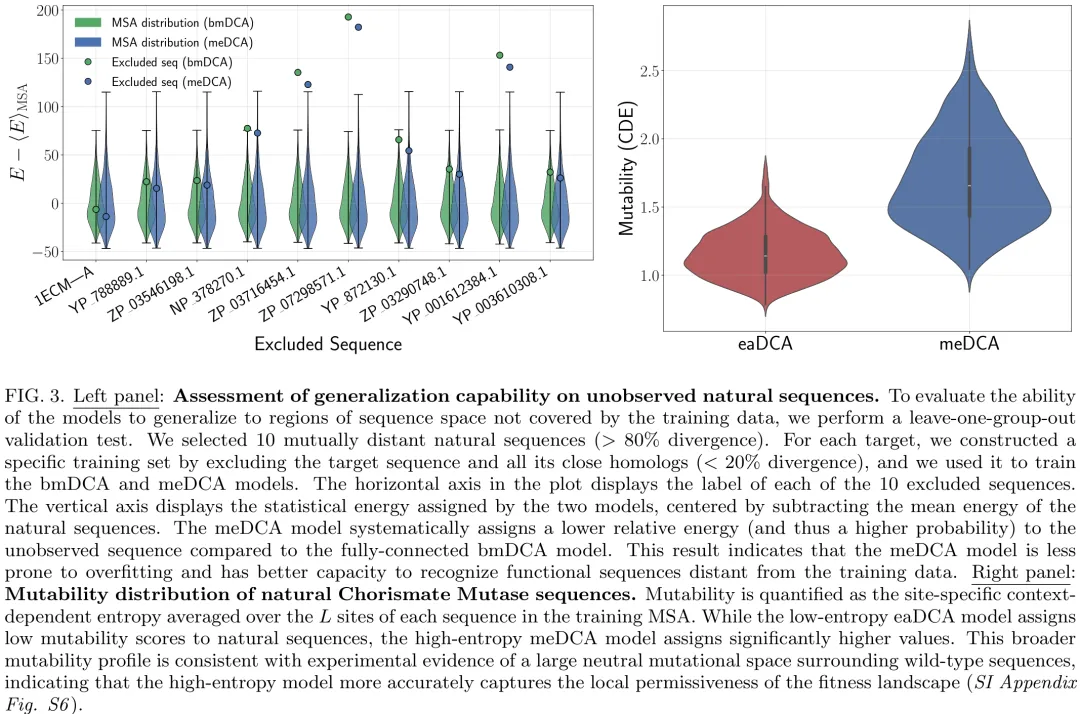
Paper Key Illustration
原文
Expanding functional protein sequence space using high entropy generative models
Abstract: Boltzmann Machines trained on evolutionary sequence data have emerged as a powerful paradigm for the data-driven design of artificial proteins. However, the relationship between model architecture, specifically parameter density, and experimental performance remains poorly understood. Here, we investigate this relationship using the Chorismate Mutase enzyme family as a model system. We compare standard fully connected Boltzmann Machines for Direct Coupling Analysis (bmDCA) with sparse models generated via progressive edge activation (eaDCA) and edge decimation (edDCA). We identify a maximum-entropy model (meDCA) along the decimation trajectory that represents an optimal balance between constraint satisfaction and the flexibility of the probability distribution. We synthesized and tested artificial sequences from all models using an in vivo complementation assay, finding that all architectures, regardless of sparsity, generate functional enzymes with high success rates, even at significant divergence from natural sequences. Despite this functional equivalence, we demonstrate that the meDCA model samples a viable sequence space that is more than fifteen orders of magnitude larger than its low-entropy counterparts. Furthermore, comparative analyses reveal that high-entropy models systematically minimize overfitting and better capture the local neutral spaces surrounding natural proteins. These findings suggest that while various models satisfying coevolutionary statistics can generate functional sequences, high-entropy Boltzmann Machines provide a superior representation of the underlying evolutionary fitness landscape.
链接:https://arxiv.org/pdf/2605.03578
AI 深度解读
针对蛋白质全原子协同设计任务,现有方法通常采用两阶段策略,即先生成结构再生成序列,难以捕捉结构与序列间的联合分布及原子类型与坐标的耦合关系。为此,研究提出了 A-CODE 框架,其核心在于构建统一的原子扩散模块,直接对全原子坐标与原子类型进行联合建模。该方法采用 atom14 表示法,将哑原子(Dummy Atoms)赋予专用原子类型(DMY)并纳入扩散过程,使残基身份能从原子级预测中自然涌现,从而解除了对标准 20 种氨基酸的硬性约束,支持非标准氨基酸扩展。在训练阶段,模型同时优化坐标扩散损失与基于掩码的原子类型离散扩散损失,并引入条件信息以增强生成能力。在采样阶段,为缓解侧链构象过早确定导致的空间位阻问题,研究引入了侧链去噪滞后策略,使侧链原子在早期步骤保持更高噪声水平,优先稳定主链拓扑结构。此外,通过保守解码策略和方差修正机制,进一步提升了采样鲁棒性与数值稳定性。该工作实现了结构与序列在单一生成过程中的紧密耦合,显著提升了蛋白质设计的灵活性与准确性。
中文摘要
摘要:我们提出了 A-CODE,这是一种完全原子化的统一单阶段蛋白质协同设计模型,能够同时优化离散的原子类型和连续的原子坐标。与主流的将结构设计与氨基酸水平序列设计级联的两阶段方法不同,我们的方法在统一的多元模态扩散框架内实现了完全原子化的设计,其中残基身份完全由原子级预测推断得出。基于强大的全原子架构,A-CODE 在无条件蛋白质生成方面实现了卓越的设计能力,优于所有现有的单阶段和两阶段设计模型。在结合子设计方面,A-CODE 与现有的最先进两阶段设计模型相媲美,甚至在某些方面表现更优;与现有的单阶段协同设计模型相比,在困难任务上的成功率提升了十倍。我们原子化公式固有的灵活性首次实现了对非标准氨基酸(ncAA)建模的无缝适配。我们的全原子框架为全原子生成建模建立了一个新的、通用的基础,并可自然地扩展至复杂的生物分子系统。
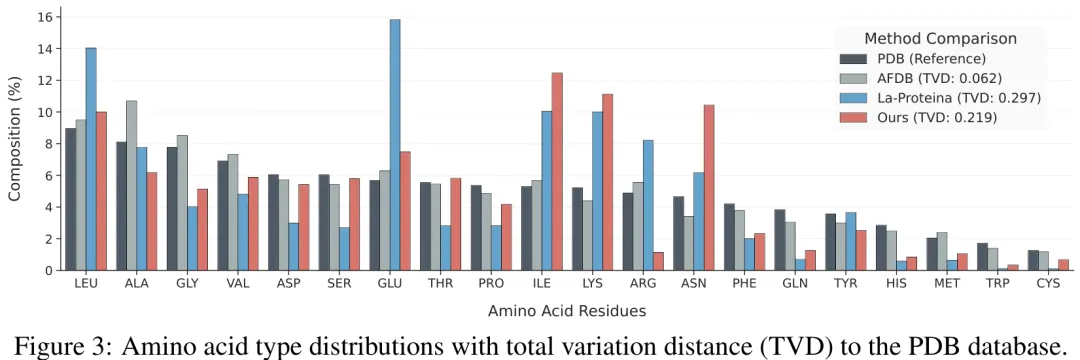
Paper Key Illustration
原文
A-CODE: Fully Atomic Protein Co-Design with Unified Multimodal Diffusion
Abstract: We present A-CODE, a fully atomic unified one-stage protein co-design model that simultaneously refines discrete atom types and continuous atom coordinates. Unlike predominant two-stage methods that cascade structure design with amino acid-level sequence design, our approach is fully atomic within a unified multimodal diffusion framework, in which residue identities are inferred solely from atom-level predictions. Built upon the powerful all-atom architecture, A-CODE achieves superior designability for unconditional protein generation, outperforming all existing one-stage and two-stage design models. For binder design, A-CODE rivals and even outperforms existing state-of-the-art two-stage design models and, compared with the existing one-stage co-design model, achieves a drastic tenfold improvement in success rate on hard tasks. The inherent flexibility of our atomic formulation enables, for the first time, seamless adaptation to non-canonical amino acid (ncAA) modeling. Our fully atomic framework establishes a new, versatile foundation for all-atom generative modeling that can be naturally extended to complex biomolecular systems.
链接:https://arxiv.org/pdf/2605.03360
AI 深度解读
针对分子对接评分函数存在的物理近似与可解释性缺陷,研究提出了一种基于代理智能体(Agentic AI)的替代范式。现有评分函数(如 AutoDock Vina、Smina 及各类机器学习模型)普遍采用经验加权求和或端到端映射,忽略了构象熵、溶剂重组及去溶剂化惩罚等关键热力学因素,导致其无法区分强氢键与高疏水接触等不同物理驱动机制,且缺乏对构象冲突与空间位阻的权衡能力。为填补这一‘可解释性缺口’,研究构建了 AgenticPosesRanker 框架:首先定义了一套独立的物理化学描述符(包括非共价相互作用质量、构象应变、空间冲突计数及极性原子埋藏状态等),这些描述符能捕捉评分函数中耦合的物理效应;随后利用工具增强的语言模型代理,通过‘观察 – 推理 – 行动’循环,结合思维链(Chain-of-Thought)技术对多源描述符进行上下文自适应的逻辑整合与仲裁。该框架旨在超越固定权重的线性评分限制,通过显式的推理痕迹阐明排名决策的物理依据,从而在无需依赖单一标量分数的情况下,实现对对接构象更严谨、可解释且符合物理规律的评估。
中文摘要
评分函数仍是分子对接中的主要瓶颈:它们通常无法将近天然构象排在诱饵分子之上,且其复合单分设计掩盖了每种排名错误的物理化学基础。我们提出了 AgenticPosesRanker,这是一个智能体 AI 框架,它结合了六种确定性的、基于物理的分析工具(相互作用指纹识别、溶剂可及埋藏、构象应变、空间位阻检测、未满足极性原子惩罚以及化学身份提取)与大语言模型(GPT-5)的思维链推理,以评估和排名对接构象。在一个经过精心筛选的基准测试中,包含十种蛋白质 – 配体系统(共 162 个构象),该基准通过构建在 Smina 评分函数的成功与失败案例之间进行了平衡,该智能体达到了 50.0% 的最佳构象准确率,与固定设计的 Smina 基线(50.0%)持平,并显著超过了 7.7% 的均匀随机基线(p < 0.001,单侧精确二项式检验)。平衡基准的准确率呈对称分解:该智能体保留了 Smina 成功系统中的 80%(5 个中的 4 个),并恢复了 Smina 失败系统中的 20%(5 个中的 1 个),因此整体 50% 的准确率反映的是由一次回归被另一次恢复所抵消,而非相对于 Smina 参考的任何净改进。决策归因分析显示,智能体自我报告的工具体重与所选构象的客观指标分离度之间具有高度一致性(中位数 ρ = +0.83),这种一致性在正确和错误的结果中均保持一致,表明性能上限取决于工具套件的覆盖范围,而非推理的不一致性。这些结果确立了一种方法论模板,用于在自然科学中评估智能体 AI 与客观真实基准的一致性,并将该框架定位为基于结构的药物设计中后期构象优化的可解释性筛选层。
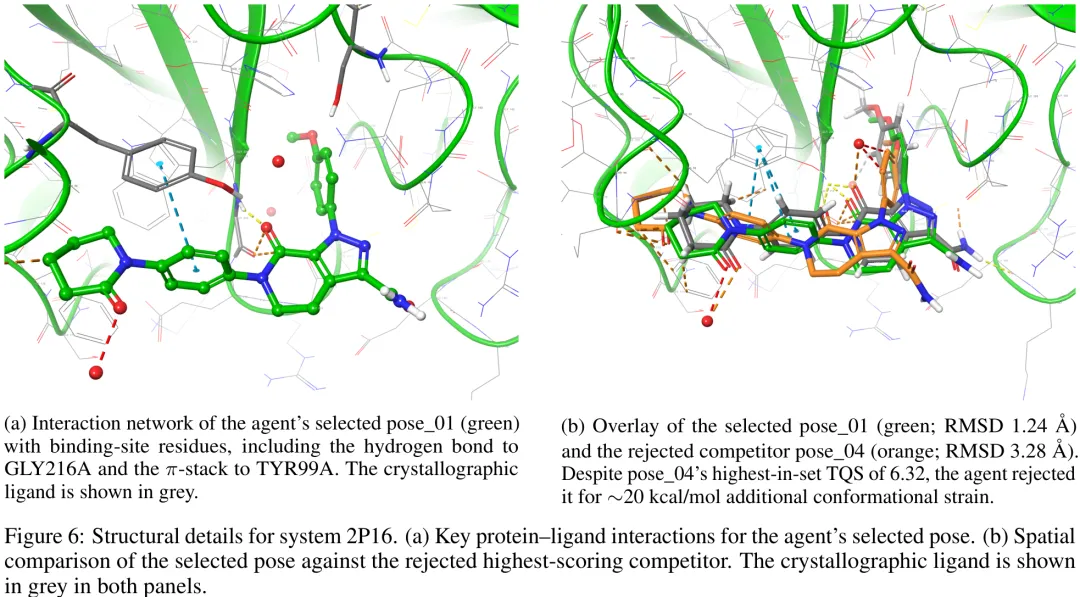
Paper Key Illustration
原文
AgenticPosesRanker: An Agentic AI Framework for Physically Grounded Ranking of Protein-Ligand Docking Poses
Abstract: Scoring functions remain the principal bottleneck in molecular docking: they routinely fail to rank near-native poses above decoys, and their composite single-score design obscures the physicochemical basis of each ranking error. We present AgenticPosesRanker, an agentic AI framework that combines six deterministic, physically grounded analysis tools (interaction fingerprinting, solvent-accessible burial, conformational strain, steric-clash detection, unsatisfied-polar-atom penalty, and chemical-identity extraction) with large-language-model (GPT-5) chain-of-thought reasoning to evaluate and rank docking poses. On a curated benchmark of ten protein-ligand systems (162 poses) balanced by construction between Smina scoring-function successes and failures, the agent achieved 50.0% best-pose accuracy, matching the design-fixed Smina baseline of 50.0% and significantly exceeding a 7.7% uniformly random baseline (p < 0.001, one-sided exact binomial test). The balanced-benchmark accuracy decomposes symmetrically: the agent retained 80% (4/5) of the Smina-success systems and recovered 20% (1/5) of the Smina-failure systems, so the aggregate 50% reflects one regression offset by one recovery rather than any net improvement over the Smina reference. Decision-attribution analysis showed high alignment between the agent’s self-reported tool weights and objective metric separations of the selected pose (median \r{ho} = +0.83), consistent across correct and incorrect outcomes, localising the performance ceiling to tool-suite coverage rather than reasoning inconsistency. These results establish a methodological template for evaluating agentic AI against objective ground truth in the natural sciences and position the framework as an interpretable curation layer for late-stage pose refinement in structure-based drug design.
链接:https://arxiv.org/pdf/2605.03707
AI 深度解读
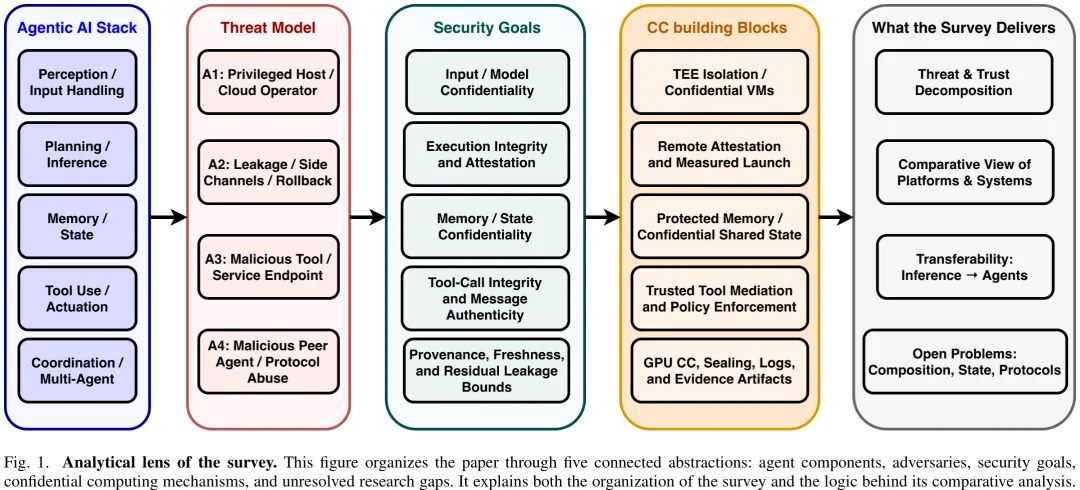
本文针对云、边缘及异构部署环境下的智能体(Agent)安全挑战,提出了一种聚焦于硬件隔离与远程证明的调研框架。研究明确区分了软件防御与密码学机制(如 FHE、MPC),将其仅作为对比基准,核心聚焦于受保护内存、工具执行及跨智能体信任建立等硬件级安全边界问题。
研究构建了三维分析透镜:功能层(感知、规划、记忆、行动、协调)、对抗者权限(外部攻击者、受损共租户、恶意基础设施运营者等)及部署边界(进程飞地、机密 VM、安全世界等)。同时,将智能体系统划分为四类操作形态:独立推理系统、使用工具的单智能体、工作流智能体及多智能体系统,并指出当前证据多源于机密 LLM 推理,向记忆、行动及协调等更广泛智能体栈的迁移存在局限性。
在方法论上,论文建立了严格的文献筛选与编码协议,将文献分为核心分析集与背景集。核心集仅纳入将机密计算作为核心机制、直接解决特定安全目标且具备技术细节的文献。每个入选系统均被编码为 TEE 底层、操作类别、受保护层、对抗者类型、安全目标及迁移状态。系统仅在被证实保护实际工具使用、工作流执行或跨智能体协调时,才被标记为“直接智能体”,否则视为“部分可迁移”。
研究定义了九类具体的安全目标以替代宽泛术语:输入机密性、模型机密性、执行完整性、记忆机密性、工具调用完整性、消息真实性、溯源性、新鲜性及侧信道抗性。这些目标不仅用于威胁建模与系统对比,更是构建可审计保证凭证的原始材料。
在智能体定义上,本文将其界定为通过规划循环自主执行多步任务的 LLM 驱动实体,并拆解为感知、规划/推理、记忆、行动/工具执行及协调五个功能层。研究通过图示展示了单智能体部署中,推理、本地记忆、凭证及工具中介被包含在单一证明边界内,而检索后端与外部存储处于边界之外;而在多智能体系统中,编排、委托及共享状态则跨越多个证明组件,显著改变了安全图景。该研究旨在填补当前机密计算在智能体全栈(特别是记忆与行动)应用中的空白,并为构建可信的智能体基础设施提供理论依据。
中文摘要
摘要:代理型人工智能系统,特别是能够进行规划、调用工具、维护持久化记忆,并通过 MCP 和 A2A 等协议将任务委托给对等代理的大语言模型(LLM)驱动型代理,引入了与独立模型推理截然不同的威胁面。代理会累积敏感上下文、持有凭证,并在没有任何单一方可完全控制的管道中运行,从而使得提示注入、上下文窃取、凭证盗窃以及代理间消息投毒等攻击成为可能。当前的防御机制完全运行在软件栈内,可被拥有足够特权的敌手(如被攻陷的云运营商)静默绕过。机密计算(CC)提供了一种基于硬件的替代方案:可信执行环境(TEE)可将代理代码和数据与特权系统软件隔离,而远程证明则支持跨分布式部署的可验证信任。本综述从四个方面综合探讨了设计空间:(i)六种 TEE 平台(Intel SGX、Intel TDX、AMD SEV-SNP、ARM TrustZone、ARM CCA 和 NVIDIA H100 CC)的统一分类法,涵盖其部署角色与性能权衡;(ii)以代理为中心的威胁模型,涵盖感知、规划、记忆、行动与协调五个层级,并映射至九个安全目标;(iii)基于 CC 的防御机制比较综述,区分哪些发现可直接从单次调用推理中迁移,哪些需要新的代理设计;(iv)六个开放挑战,包括多跳代理链的复合证明以及 LLM 规模下的 GPU-TEE 性能问题。尽管若干硬件信任原语已成熟到可用于针对性部署,但目前尚无广泛确立的端到端框架将这些原语整合为生产级代理型人工智能所需的连贯安全基础架构。
Paper Key Illustration
原文
When Agents Handle Secrets: A Survey of Confidential Computing for Agentic AI
Abstract: Agentic AI systems, specifically LLM-driven agents that plan, invoke tools, maintain persistent memory, and delegate tasks to peer agents via protocols such as MCP and A2A, introduce a threat surface that differs materially from standalone model inference. Agents accumulate sensitive context, hold credentials, and operate across pipelines no single party fully controls, enabling prompt injection, context exfiltration, credential theft, and inter-agent message poisoning. Current defenses operate entirely within the software stack and can be silently bypassed by a sufficiently privileged adversary such as a compromised cloud operator. Confidential computing (CC) offers a hardware-rooted alternative: Trusted Execution Environments (TEEs) isolate agent code and data from privileged system software, while remote attestation enables verifiable trust across distributed deployments. This survey synthesizes the design space in four parts: (i) a unified taxonomy of six TEE platforms (Intel SGX, Intel TDX, AMD SEV-SNP, ARM TrustZone, ARM CCA, and NVIDIA H100 CC) covering deployment roles and performance tradeoffs; (ii) an agent-centric threat model spanning perception, planning, memory, action, and coordination layers mapped to nine security goals; (iii) a comparative survey of CC-based defenses distinguishing findings that transfer from single-call inference versus what requires new agentic designs; and (iv) six open challenges including compound attestation for multi-hop agent chains and GPU-TEE performance at LLM scale. While several hardware trust primitives appear mature enough for targeted deployments, no broadly established end-to-end framework yet binds them into a coherent security substrate for production agentic AI.
链接:https://arxiv.org/pdf/2605.03213
AI 深度解读
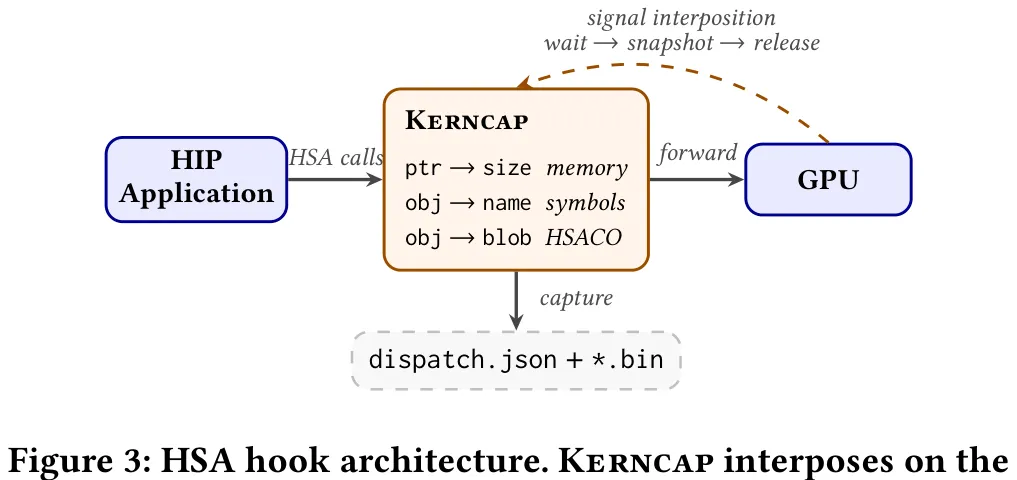
Kerncap 旨在解决异构计算环境中 HIP 与 Triton 两种不同抽象层级内核难以统一捕获与复现的问题。该工具通过统一的 HSA 级捕获流水线,将 HIP 的预编译二进制内核与 Triton 的运行时 JIT 内核收敛至同一处理流程。具体而言,Kerncap 利用 LD_PRELOAD 加载的共享库拦截 HSA 调度接口,在队列创建、内存分配、符号绑定及代码对象加载等关键节点进行钩子注入,以记录内核句柄、内存布局及 HSACO 二进制流。针对 Triton 特有的元数据缺失问题,Kerncap 引入轻量级 Python 编译钩子,在 JIT 编译阶段提取用户可见名称、类型签名及自调优配置,并建立基于 HSACO 哈希值的映射表,在调度时通过解析 AMDGPU 元数据恢复完整的调用上下文。最终,工具根据内核类型自动生成对应的复现项目:HIP 内核生成包含 Clang 虚拟文件系统覆盖层的自包含项目,而 Triton 内核则生成带有固定调参的 Python 脚本。通过字节级精确比对或数值容差验证,Kerncap 确保了复现结果的准确性,实现了从底层硬件调度到上层语言特性的全链路内核捕获与精准复现。
中文摘要
摘要:迭代式 GPU 内核调优受限于承载内核的应用程序规模。快速迭代需要隔离内核,使其能够在不重新构建整个应用程序的情况下进行编辑、重新编译和验证;然而,手动隔离需要人工重构构建标志、调度配置和运行时输入,因此开发者通常只能接受缓慢的原地编辑。我们提出了 Kerncap,这是一种自动化的内核提取工具,它拦截 HIP 和 Triton 在 HSA 运行时中的调度操作,并通过轻量级的 Python 编译钩子封装(shim)将 Triton 仅基于 JIT 的元数据桥接至 HSA 级别的捕获。Kerncap 对所有设备内存执行地址空间闭包——生成一个虚拟地址忠实的快照,该快照保留了嵌入式设备指针而无需 DWARF 元数据或指针追逐——定位内核源代码,并生成自包含的复现项目。HIP 复现项目使用 Clang 虚拟文件系统(VFS)覆盖层进行源代码级别的重新编译,而无需修改原始构建系统;Triton 复现项目则采用调优固定策略,将捕获的自动调优配置绑定到工件中,以保留 JIT 内核的数值契约。在涵盖传统高性能计算(HPC)和机器学习(ML)领域的六个真实世界 HIP 和 Triton 工作负载上,Kerncap 在三种 AMD GPU 架构(CDNA2、CDNA3、RDNA3)上成功提取并验证了从 152 MB 到 30 GB 不等的快照中的内核——其中包括通过指针间接访问捕获的 vLLM 混合专家权重池的虚拟地址忠实快照。在我们的 llama.cpp 案例研究中,Kerncap 的“编辑 – 重新编译 – 验证”循环相比传统工作流实现了 13.6 倍的速度提升,将内核隔离过程从数小时缩短为单个命令。生成的复现项目还可作为自动调优代理和需要快速隔离评估候选项的大语言模型驱动内核生成器的基础。
Paper Key Illustration
原文
Kerncap: Automated Kernel Extraction and Isolation for AMD GPUs
Abstract: Iterative GPU kernel tuning is bottlenecked by the scale of the applications that host the kernels. Rapid iteration requires isolating the kernel so it can be edited, recompiled, and validated without rebuilding the full application — but manual isolation requires reconstructing build flags, dispatch configuration, and runtime inputs by hand, so developers usually settle for slow in-place edits. We present Kerncap, an automated kernel extraction tool that intercepts dispatches at the HSA runtime for both HIP and Triton, bridging Triton’s JIT-only metadata into HSA-level capture via a lightweight Python compile-hook shim. Kerncap performs an address-space closure of all device memory — a virtual-address-faithful snapshot that preserves embedded device pointers without DWARF metadata or pointer chasing — locates kernel sources, and emits self-contained reproducer projects. HIP reproducers use a Clang VFS overlay for source-level recompilation without modifying the original build system; Triton reproducers are tuning-pinned, binding the captured autotuner configuration into the artifact to preserve the JIT kernel’s numerical contract. Across six real-world HIP and Triton workloads spanning traditional HPC and ML domains on three AMD GPU architectures (CDNA2, CDNA3, RDNA3), \textsc{Kerncap} extracts and validates kernels from snapshots ranging from 152~MB to 30~GB — including a VA-faithful capture of vLLM’s Mixture-of-Experts weight pool reached through pointer indirection. On our llama.cpp case study, Kerncap’s edit-recompile-validate loop achieves a 13.6x speedup over the traditional workflow, reducing kernel isolation from a multi-hour process to a single command. The resulting reproducers also serve as a substrate for autotuning agents and LLM-driven kernel generators that need rapid, isolated evaluation of candidates.
链接:https://arxiv.org/pdf/2605.03208
AI 深度解读
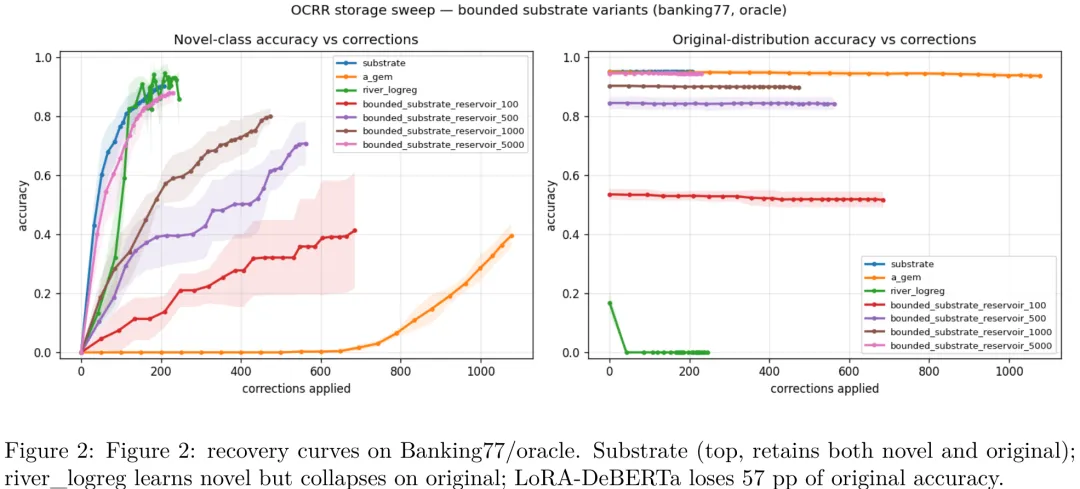
该研究针对持续学习中的灾难性遗忘问题,提出了一种基于投票规则的无参数化增量学习系统(Substrate)。研究在 Banking77 和 CLINC150 等数据集上,对比了包括 A-GEM、EWC、LwF 及 LoRA 在内的多种基线方法。关键结果显示,Substrate 在保持原有分布准确率(>90%)的同时,对新增类别的识别准确率显著优于所有参数化基线(最高提升 78 个百分点)。实验表明,传统的参数微调方法(如 LoRA)在适应新任务时极易破坏原有知识,而基于检索的无参数机制在固定内存预算下表现出极高的样本效率。此外,研究验证了该机制在稀疏校正策略下的鲁棒性,并证明其优势并非源于无限存储,而是源于其独特的投票决策逻辑与追加式账本架构。
中文摘要
摘要:静态基准测试衡量的是训练时冻结的模型性能。而现实系统面临分布偏移问题:出现新类别、查询改写、数据漂移等情况,并需通过用户修正在线恢复。目前尚无现有基准测试能衡量在修正流下的恢复速度。我们提出了 OCRR(在线修正恢复率)基准:该基准将语料库流式输入分类系统,对错误预测应用真值或随机修正,并报告两条曲线:新类别准确率与原始分布准确率随修正次数的变化。我们在 Banking77 和 CLINC150 数据集上,结合真值及稀疏修正策略,对底层架构(Substrate)与来自五个家族的九种基线算法(包括标准在线学习基线 River、持续学习方法 EWC/A-GEM/LwF、检索/参数混合模型 kNN-LM、15 亿参数编码器 DeBERTa-v3-large 的 LoRA 微调版本,以及一种哈希链式追加写架构 Substrate)进行了帕累托前沿扫描评估。结果显示,在同等内存预算下,Substrate 是唯一能同时恢复新类别准确率(88.7% ± 2.9%)并保持原始分布准确率(95.4% ± 0.8%)的系统,其新类别准确率领先次优的持续学习基线 32.6 个百分点,在保留性能上则超越 LoRA-on-DeBERTa-v3-large 达 84.6 个百分点。此外我们发现,即使近似最近邻检索的 recall@5 从 0.69 下降至 0.23(语料规模从 1 万增至 1000 万),分类准确率仍稳定维持在 99%,表明 Substrate 的“边距带多数投票”机制对检索不完美具有鲁棒性,而纯 top-k 召回率指标无法预测此类现象。代码与数据已开源:https://github.com/adriangrassi/ocrr-benchmark。
Paper Key Illustration
原文
OCRR: A Benchmark for Online Correction Recovery under Distribution Shift
Abstract: Static benchmarks measure a model frozen at training time. Real systems face distribution shift: new categories, paraphrased queries, drift: and must recover online via user corrections. No existing benchmark measures recovery speed under correction streams. We introduce OCRR (Online Correction Recovery Rate): a benchmark that streams a corpus through a classification system, applies oracle or stochastic corrections to wrong predictions, and reports two curves: novel-class accuracy and original-distribution accuracy versus correction count. We evaluate the substrate alongside nine baseline algorithms from five families plus seven bounded-storage variants of the substrate for the Pareto sweep, including standard online-learning baselines (river), continual-learning methods (EWC, A-GEM, LwF), retrieval/parametric hybrids (kNN-LM), parameter-efficient fine-tuning of a 1.5 B-parameter encoder (LoRA on DeBERTa-v3-large), and a hash-chained append-only substrate (Substrate). On Banking77 and CLINC150, under oracle and sparse correction policies, the substrate is the only system that simultaneously recovers novel-class accuracy (88.7 +/- 2.9 %) and retains original-distribution accuracy (95.4 +/- 0.8 %) beating the next-best published continual-learning baseline by 32.6 percentage points at equal memory budget, and beating LoRA-on-DeBERTa-v3-large by 84.6 percentage points on retention. We further find that classification accuracy remains stable at 99 % even as approximate-nearest-neighbour recall@5 degrades from 0.69 to 0.23 across 10 k to 10 M corpus scales, suggesting the substrate’s margin-band majority vote is robust to retrieval imperfection in a way that pure top-k recall metrics do not predict. Code and data are available at https://github.com/adriangrassi/ocrr-benchmark.
链接:https://arxiv.org/pdf/2605.03153
AI 深度解读
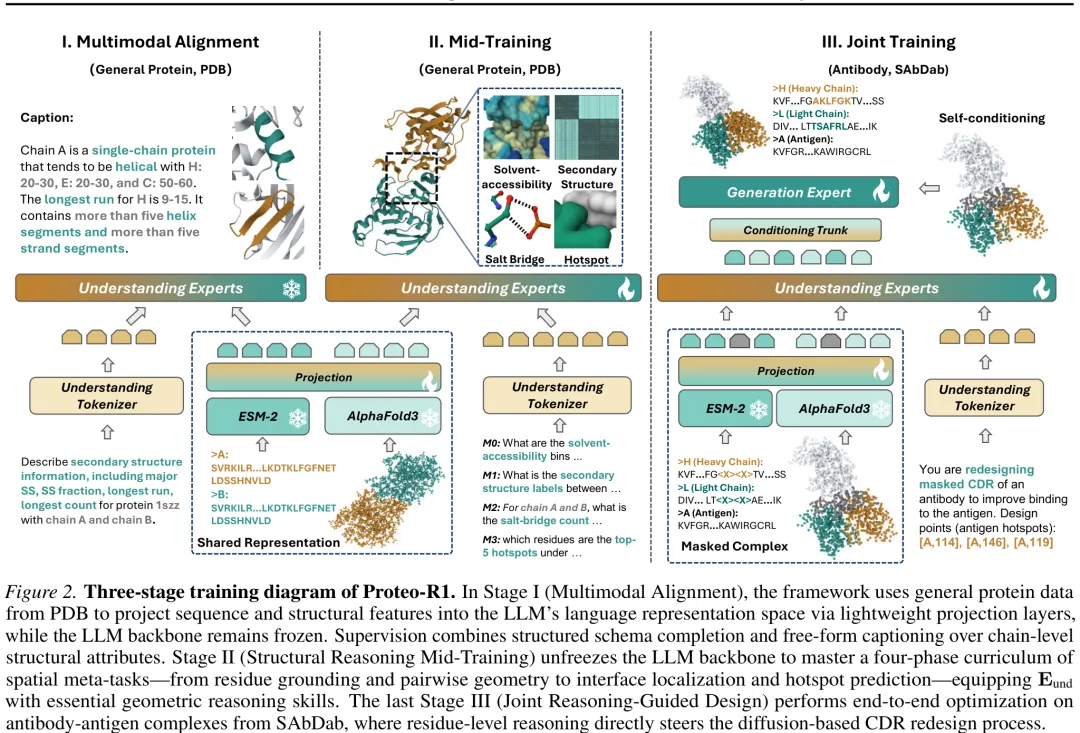
Proteo-R1 提出了一种结合推理与生成的蛋白质设计框架,旨在解决抗体 – 抗原复合物中互补决定区(CDR)的重设计难题。该研究首先构建了 Eund 专家模块,通过四阶段课程学习掌握空间元任务,使其具备从残基定位到热点预测的几何推理能力。在数据构建上,采用 CDR 掩码重折叠策略,利用 AF3 风格模型在保留非 CDR 骨架的前提下推断 CDR 结构,确保模型仅基于上下文而非真实几何信息进行推理,从而防止原生结构泄露。随后,系统通过多模态融合整合序列编码与结构特征,生成包含生化偏好与空间拓扑的残基级表示。在生成阶段,Proteo-R1 引入稀疏锚点机制,由 Eund 识别关键交互残基并预测其氨基酸身份,同时通过可微的表示级锚定将推理结果直接注入扩散模型(Egen),引导其在固定锚点约束下完成端到端的 CDR 重设计。该方法实现了从序列掩码到原子坐标生成的条件分布学习,有效平衡了生化约束与结构合理性,为抗体共设计提供了新的范式。
中文摘要
摘要:深度学习在从头蛋白质设计领域已实现了原子级精度。然而,现有模型仍主要缺乏深思熟虑性:它们直接合成分子几何结构,而未显式推理哪些残基或相互作用在功能上至关重要。因此,设计决策与连续采样动力学相互纠缠,限制了可解释性、可控性以及生化知识的系统性复用。我们提出了Proteo-R1,一个由推理引导的蛋白质设计框架,该框架将分子理解与几何生成显式解耦。Proteo-R1 采用双专家架构:多模态大语言模型(MLLM)作为“理解专家”,分析蛋白质序列、结构及文本上下文,以识别控制结合力和特异性的关键功能残基;随后,这些残基级决策作为硬性约束传递给独立的基于扩散的“生成专家”,该专家在尊重固定相互作用锚点的同时执行条件协同设计。这种因子化方式模仿了人类专家进行分子工程的方法:首先推理关键相互作用,然后在这些约束下优化几何结构。通过将推理操作化为显式的残基级承诺而非隐式的文本引导,Proteo-R1 实现了大语言模型推理与最先进几何生成模型之间稳定、可解释且模块化的集成。代码、数据及演示文稿可在 https://smiles724.github.io/r1/ 获取。
Paper Key Illustration
原文
Proteo-R1: Reasoning Foundation Models for De Novo Protein Design
Abstract: Deep learning in \emph{de novo} protein design has achieved atomic-level fidelity. However, existing models remain largely non-deliberative: they directly synthesize molecular geometries without explicitly reasoning about which residues or interactions are functionally essential. As a result, design decisions are entangled with continuous sampling dynamics, limiting interpretability, controllability, and systematic reuse of biochemical knowledge. We introduce \textbf{Proteo-R1}, a reasoning-guided protein design framework that explicitly decouples \emph{molecular understanding} from \emph{geometric generation}. Proteo-R1 adopts a dual-expert architecture in which a multimodal large language model (MLLM) serves as an \emph{understanding expert}, analyzing protein sequences, structures, and textual context to identify key functional residues that govern binding and specificity. These residue-level decisions are then passed as hard constraints to a separate diffusion-based \emph{generation expert}, which performs conditional co-design while respecting the fixed interaction anchors. This factorization mirrors how human experts approach molecular engineering: first, reasoning about critical interactions, then optimizing geometry subject to those constraints. By operationalizing reasoning as explicit residue-level commitments rather than latent textual guidance, Proteo-R1 achieves stable, interpretable, and modular integration of LLM reasoning with state-of-the-art geometric generative models. Code, data, and demos are available at https://smiles724.github.io/r1/.
链接:https://arxiv.org/pdf/2605.02937
今日热门 / Popular Today
ArXiv 高热度精选
AI 深度解读
本研究提出了一种基于非平衡热力学与信息几何的 AI 安全新范式,旨在解决传统异常检测中误报率高及缺乏物理可解释性的问题。研究核心在于将 AI 系统的‘安全行为’锚定于兰道尔原理(Landauer Principle)与费雪信息量(FIM),认为恶意攻击或系统失稳本质上是系统向高熵状态的非授权跃迁,这一过程伴随着必须消耗的最小物理功(能量耗散)。
在方法论上,研究构建了 Kerimov-Alekberli 模型,利用 KL 散度(DKL)量化当前系统分布 P(t) 与安全基准分布 P_safe 之间的信息距离。通过滑动窗口计算动态阈值 arδ(t),该阈值随系统正常波动自适应调整,有效区分了正常噪声与真实攻击。实验基于 NSL-KDD 数据集,采用主成分分析(PCA)降维与核密度估计(KDE)构建安全分布,并验证了模型在零日攻击场景下的有效性。
关键结果显示,该动态阈值方法在 NSL-KDD 测试集上取得了 96.8% 的准确率和 3.2% 的极低误报率,相比静态阈值和传统算法(如 One-Class SVM、Isolation Forest)显著提升了性能,AUC 达到 0.97。数值实验进一步证实,攻击发生时 KL 散度轨迹会突破动态阈值,且伴随费雪信息量的下降,这与热力学第二定律及兰道尔界限高度一致。
该研究的深层意义在于实现了 AI 对齐的‘物理化’:它将抽象的伦理约束转化为可测量的物理量(能量耗散与熵增),为实时拦截‘慢漂移’类异常提供了理论依据。这不仅为 AI 安全提供了客观的量化指标,更暗示了未来 AI 对齐应建立在普适的热力学定律之上,即任何偏离安全基线的行为在物理层面都是低效且结构破坏性的。
中文摘要
摘要:本研究介绍了 Kerimov-Alekberli 模型,这是一种新颖的信息几何框架,通过将非平衡热力学与随机控制形式化地关联,重新定义了人工智能安全,以实现自主系统的伦理对齐。通过建立非平衡热力学与随机控制之间的形式同构,我们将系统性异常定义为对黎曼流形的偏离。该模型以 Kullback-Leibler 散度为主要度量指标,其动态阈值由 Fisher 信息度量决定。我们进一步基于兰道尔原理(Landauer Principle)为该框架奠定物理基础,证明对抗性扰动通过增加系统的信息熵而执行可测量的物理功。在 NSL-KDD 数据集和无人机轨迹模拟上的验证表明,我们的模型通过 FPT 触发器实现了有效的实时检测,并在基准数据集上表现出优异的性能指标(例如高准确率和低假阳性率)。本研究为人工智能安全提供了严谨的物理基础,通过将伦理违规建立在可量化的物理功和熵信息之上,实现了从启发式、基于规则的伦理框架向基于热力学的稳定性范式的转变。
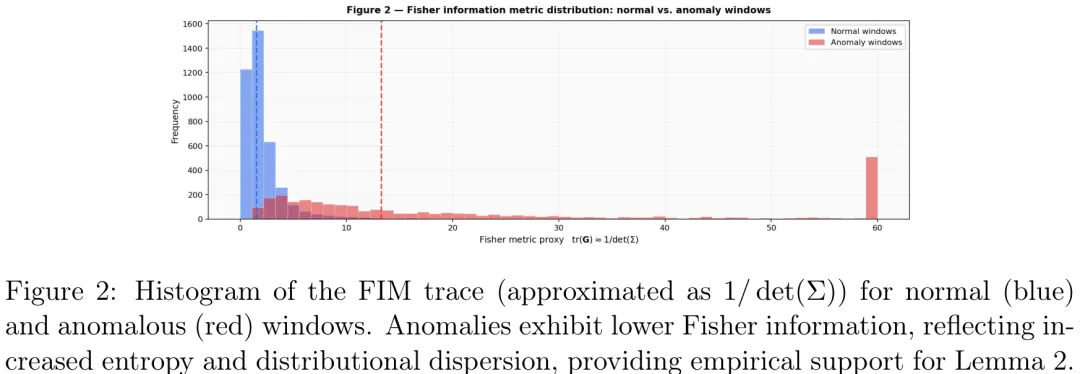
Paper Key Illustration
原文
The Kerimov-Alekberli Model: An Information-Geometric Framework for Real-Time System Stability
Abstract: This study introduces the Kerimov-Alekberli model, a novel information-geometric framework that redefines AI safety by formally linking non-equilibrium thermodynamics to stochastic control for the ethical alignment of autonomous systems. By establishing a formal isomorphism between non-equilibrium thermodynamics and stochastic control, we define systemic anomalies as deviations from a Riemannian manifold. The model utilizes the Kullback-Leibler divergence as the primary metric, governed by a dynamic threshold derived from the Fisher Information Metric. We further ground this framework in the Landauer Principle, proving that adversarial perturbations perform measurable physical work by increasing the system’s informational entropy. Validation on the NSL-KDD dataset and unmanned aerial vehicle trajectory simulations demonstrated that our model achieves effective real-time detection via the FPT trigger, with strong performance metrics (e.g., high accuracy and low FPR) on benchmark datasets. This study provides a rigorous physical foundation for AI safety, transitioning from heuristic, rule-based ethical frameworks to a thermodynamics-based stability paradigm by grounding ethical violations in quantifiable physical work and entropic information.
链接:https://arxiv.org/pdf/2604.24083
AI 深度解读
本研究旨在评估一种引入阻尼分母的广义稳定性评分公式相较于传统线性基准公式的优越性。研究基于包含 80 个模型 – 场景观测的基准数据集,涵盖了 DeepSeek-V3、GPT-4o、Gemini-1.5 及 Grok-3 等模型。在方法上,研究首先通过配对 t 检验和 Wilcoxon 符号秩检验对两种公式的稳定性得分进行对比,并辅以系数敏感性分析以验证结论在不同参数设置下的鲁棒性。关键结果显示,广义公式在所有 80 个观测中均优于传统公式,平均增益为 0.0299(95% CI: [0.0247, 0.0351]),且统计显著性极高(p < 0.001)。分析进一步揭示,熵值与稳定性得分呈强负相关,而稳定性增益与熵值几乎呈完全正相关,表明该公式能有效量化高不确定性条件下的性能提升。尽管不同模型基线表现各异(如 Gemini-1.5 增益最大,Grok-3 增益最小),但广义公式在控制条件下均表现出更优的数值集中度和系统性优势,证实了其在评估模型内部实证行为时的有效性。
中文摘要
摘要:随着大语言模型(LLMs)日益部署于高风险及实际运营场景中,仅基于聚合准确率的评估策略往往不足以表征系统的可靠性。本研究提出了一种受热力学启发的建模框架,用于分析大语言模型输出在不确定性和扰动条件下的稳定性。该框架引入了一种复合稳定性评分,整合了任务效用、作为外部不确定性度量的熵,以及两个内部结构代理指标:内部整合度与对齐反思能力。我们并非将这些量视为物理变量,而是将其作为一种可解释的抽象表述,用以捕捉内部结构如何调节无序对模型行为的影响。利用 IST-20 基准测试协议及相关元数据,我们分析了涵盖四种当代大语言模型的 80 个模型 – 场景观测数据。所提出的公式始终比简化的效用 – 熵基线产生更高的稳定性评分,平均提升为 0.0299(95% 置信区间:0.0247–0.0351)。在较高熵条件下观察到的增益更为显著,表明该框架捕捉到了一种对不确定性的非线性衰减形式。我们并不声称发现了基本的物理定律或建立了完整的机器伦理理论。相反,本工作的贡献在于提供了一种紧凑且可解释的建模视角,将不确定性、性能与内部结构统一于一个评估框架之中。该框架旨在补充现有的基准测试方法,并支持人工智能安全、可靠性及治理领域的持续讨论。
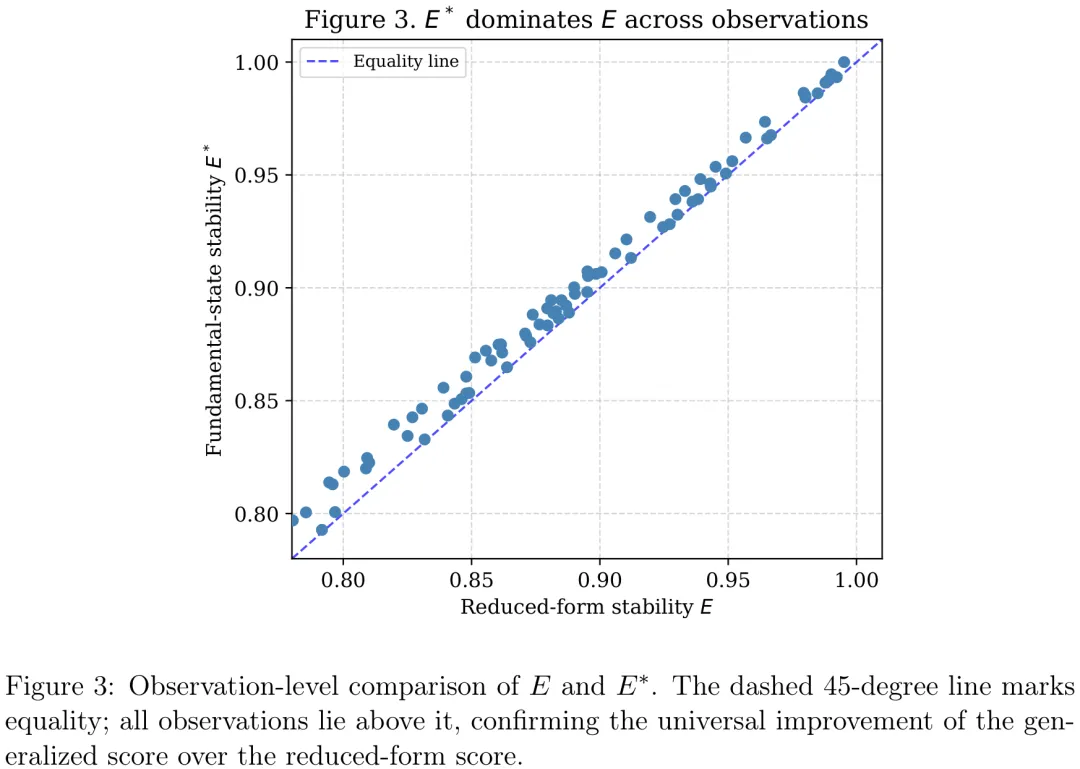
Paper Key Illustration
原文
An Information-Geometric Framework for Stability Analysis of Large Language Models under Entropic Stress
Abstract: As large language models (LLMs) are increasingly deployed in high-stakes and operational settings, evaluation strategies based solely on aggregate accuracy are often insucient to characterize system reliability. This study proposes a thermodynamic inspired modeling framework for analyzing the stability of LLM outputs under conditions of uncertainty and perturbation. The framework introduces a composite stability score that integrates task utility, entropy as a measure of external uncertainty, and two internal structural proxies: internal integration and aligned reective capacity. Rather than interpreting these quantities as physical variables, the formulation is intended as an interpretable abstraction that captures how internal structure may modulate the impact of disorder on model behavior. Using the IST-20 benchmarking protocol and associated metadata, we analyze 80 modelscenario observations across four contemporary LLMs. The proposed formulation consistently yields higher stability scores than a reduced utilityentropy baseline, with a mean improvement of 0.0299 (95% CI: 0.02470.0351). The observed gain is more pronounced under higher entropy conditions, suggesting that the framework captures a form of nonlinear attenuation of uncertainty. We do not claim a fundamental physical law or a complete theory of machine ethics. Instead, the contribution of this work is a compact and interpretable modeling perspective that connects uncertainty, performance, and internal structure within a unied evaluation lens. The framework is intended to complement existing benchmarking approaches and to support ongoing discussions in AI safety, reliability, and governance.
链接:https://arxiv.org/pdf/2604.24076
AI 深度解读
视频生成模型的研究核心在于解决从图像到视频的时空建模扩展、架构效率优化以及采样加速问题。在从图像生成向视频生成的过渡中,研究重点在于处理三维时空域(T×H×W)带来的计算复杂度立方级增长。早期方法通过直接膨胀二维卷积核至三维,虽保留了空间先验但导致参数量剧增;现代架构则采用因子化策略,将三维操作分解为独立的二维空间与一维时间操作(如 Video LDM),或在 Transformer 架构中引入时空分块(tubelets)与三维位置编码(如 Latte),以在统一注意力层中联合捕捉时空语义。主流生成框架通常由潜在压缩模块(如 3D 因果 VAE)、生成骨干网络(卷积 U-Net 或扩散 Transformer DiT)及多模态条件注入模块构成,后者支持文本、图像、音频及动作轨迹等多种控制信号。在高效建模方面,研究主要聚焦于两个方向:一是扩散模型蒸馏,通过步数缩减蒸馏(如 GPD)、一致性蒸馏(如 VideoLCM)及对抗性蒸馏,将采样步数从数十步压缩至一步甚至更少,显著降低推理延迟;二是长视界交互式建模,结合自回归、混合 AR-扩散及流式因果扩散范式,旨在支持实时交互与持久世界模拟。这些进展共同推动了视频生成在保持高保真度的同时,实现从离线生成向实时、长序列及多模态可控生成的跨越。
中文摘要
摘要:视频生成技术的快速演进使得模型能够模拟复杂的物理动力学和长时程因果性,将其定位为潜在的“世界模拟器”。然而,世界模拟的理论能力与时空建模的高昂计算成本之间仍存在关键差距。为应对这一挑战,本文全面系统地回顾了将效率视为实用世界建模关键要求的视频生成框架与技术。我们提出了一个涵盖三个维度的新颖分类体系:高效建模范式、高效网络架构以及高效推理算法。进一步研究表明,直接弥合这一效率差距可为自动驾驶、具身人工智能和游戏模拟等交互式应用赋能。最后,我们指出了高效视频驱动世界建模领域的新兴研究前沿,并论证效率是将视频生成器演化为通用、实时且鲁棒的世界模拟器的根本前提。
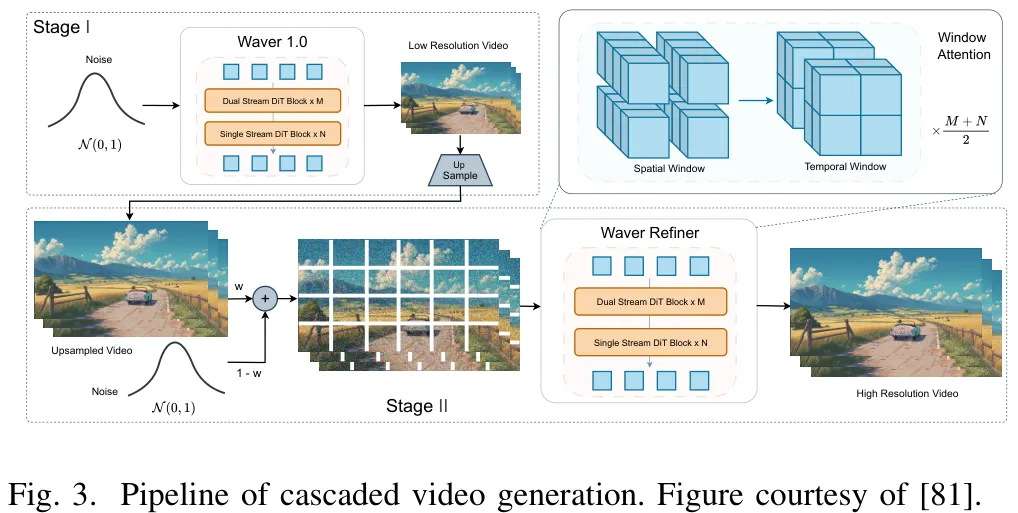
Paper Key Illustration
原文
Video Generation Models as World Models: Efficient Paradigms, Architectures and Algorithms
Abstract: The rapid evolution of video generation has enabled models to simulate complex physical dynamics and long-horizon causalities, positioning them as potential world simulators. However, a critical gap still remains between the theoretical capacity for world simulation and the heavy computational costs of spatiotemporal modeling. To address this, we comprehensively and systematically review video generation frameworks and techniques that consider efficiency as a crucial requirement for practical world modeling. We introduce a novel taxonomy in three dimensions: efficient modeling paradigms, efficient network architectures, and efficient inference algorithms. We further show that bridging this efficiency gap directly empowers interactive applications such as autonomous driving, embodied AI, and game simulation. Finally, we identify emerging research frontiers in efficient video-based world modeling, arguing that efficiency is a fundamental prerequisite for evolving video generators into general-purpose, real-time, and robust world simulators.
链接:https://arxiv.org/pdf/2603.28489
AI 深度解读
现有研究在基于人工智能的瑜伽体式识别领域呈现出明确的方法论趋势,主要依赖人体姿态估计技术结合机器学习或深度学习模型,从图像或视频数据中识别瑜伽体式。多数研究聚焦于提升分类性能,其中 Nayak 等人(2025)通过 BlazePose 框架提取骨骼关键点,对比了 CNN、DNN、随机森林及 LSTM 等多种模型,发现 DNN 在提取的骨骼特征上表现最佳;Tayal 等人(2025)则评估了 MobileNet、VGG19 和 EfficientNet 等卷积神经网络架构,证实 EfficientNet 配合 AdaDelta 优化器在图像分类任务中效果最优。此外,Gurav 等人(2025)利用 MoveNet 实现实时姿态检测与角度评估,Zaghloul 等人(2025)采用 MediaPipe 构建轻量级智能手机端识别系统,Nayak 等人(2025)亦将 BlazePose 作为预处理组件提取关键点。尽管深度学习架构在图像分类中占据主导地位,但现有研究普遍存在数据集多样性不足、缺乏时序动态建模、环境适应性差(如光照与背景干扰)以及实时反馈机制缺失等局限。针对上述问题,本研究提出一种混合边缘 AI 架构的瑜伽体式检测与纠正框架,旨在突破单一静态分类的瓶颈。该框架整合轻量级姿态估计、生物力学特征计算、时序深度学习及自适应反馈机制,通过五个核心阶段——数据采集与预处理、人体姿态估计与关键点检测、生物力学特征计算、时序体式分类、实时评估与反馈生成——实现高精度、低延迟的实时体式纠正。系统利用单目 RGB 相机采集视频流,经归一化、去噪及背景滤波等预处理后,输入轻量化模型提取骨骼关键点,进而计算关节角度等生物力学特征,利用时序模型分析动作连贯性,最终生成实时纠正反馈,有效解决了传统方法在泛化能力、计算效率及动态修正方面的不足。
中文摘要
摘要:瑜伽被广泛认为能够提升体能、柔韧性及心理健康。然而,这些益处高度依赖于动作姿势的正确执行。瑜伽练习中的姿势不当会降低训练效果,并增加肌肉骨骼损伤的风险,尤其是在自主指导或在线训练环境中。本文提出了一种基于边缘人工智能(Edge AI)的混合框架,用于实时瑜伽体式检测与姿势矫正。所提出的系统集成了轻量级人体姿态估计模型、生物力学特征提取以及基于 CNN-LSTM 的时间序列学习架构,以识别瑜伽体式并分析运动动力学。系统通过检测关键点计算关节角度与骨骼特征,并将其与参考体式构型进行比对,以评估姿势的正确性。此外,引入了一种定量评分机制,用于衡量对齐偏差,并通过视觉、文本及语音指导生成实时矫正反馈。同时,应用了模型量化与剪枝等边缘 AI 优化技术,以在资源受限设备上实现低延迟性能。该框架提供了一种智能且可扩展的数字瑜伽助手,能够提升现代健身应用中的用户安全与训练效果。
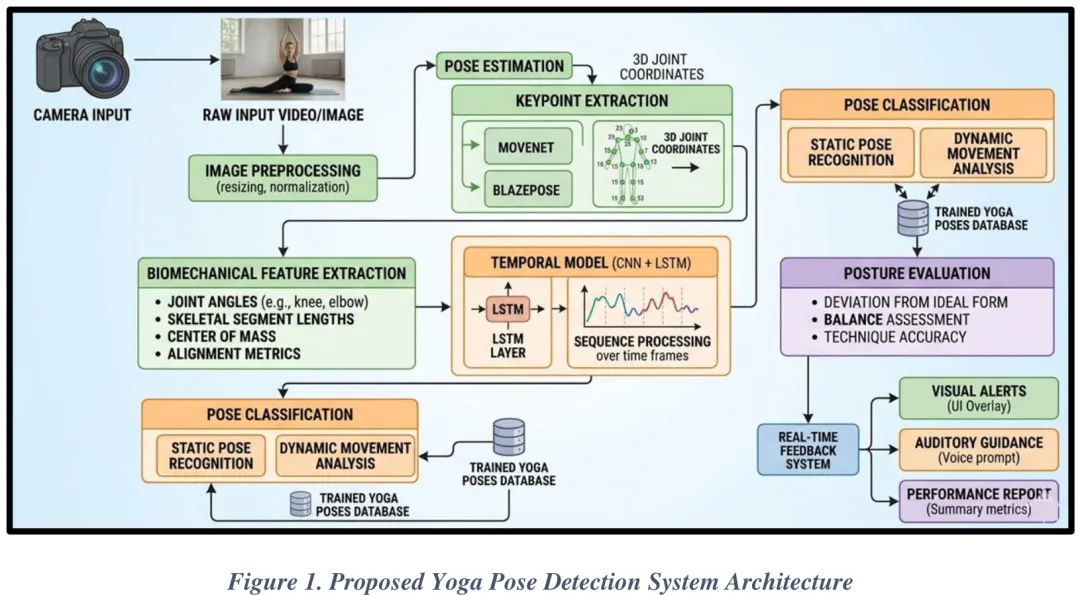
Paper Key Illustration
原文
An Intelligent Framework for Real-Time Yoga Pose Detection and Posture Correction
Abstract: Yoga is widely recognized for improving physical fitness, flexibility, and mental well being. However, these benefits depend strongly on correct posture execution. Improper alignment during yoga practice can reduce effectiveness and increase the risk of musculoskeletal injuries, especially in self guided or online training environments. This paper presents a hybrid Edge AI based framework for real time yoga pose detection and posture correction. The proposed system integrates lightweight human pose estimation models with biomechanical feature extraction and a CNN LSTM based temporal learning architecture to recognize yoga poses and analyze motion dynamics. Joint angles and skeletal features are computed from detected keypoints and compared with reference pose configurations to evaluate posture correctness. A quantitative scoring mechanism is introduced to measure alignment deviations and generate real time corrective feedback through visual, text based, and voice based guidance. In addition, Edge AI optimization techniques such as model quantization and pruning are applied to enable low latency performance on resource constrained devices. The proposed framework provides an intelligent and scalable digital yoga assistant that can improve user safety and training effectiveness in modern fitness applications.
链接:https://arxiv.org/pdf/2603.26760
AI 深度解读
该研究针对自动驾驶场景生成中的核心挑战——即如何在保持轨迹物理真实性和地图合规性的同时,有效暴露自车策略的脆弱性——提出了一套完整的解决方案。首先,研究将场景生成抽象为对抗性优化问题,旨在寻找能最大化自车失败概率的扰动,但指出直接求解单一目标仅能得到帕累托前沿上的单一点,无法实现灵活调控。为此,论文提出了分层组别偏好优化(HGPO)框架,通过解耦硬约束(地图合规)与软偏好(对抗性与真实性),利用组内采样构建包含‘可行 vs 不可行’及‘高优 vs 低优’的多层次偏好对,从而在离线设置下高效微调预训练模型,使其生成的轨迹既安全又具攻击性。进一步地,为突破固定偏好权衡的局限,研究设计了基于偏好混合物的测试时可控生成方法,使得模型能够在推理阶段动态调整对抗强度与真实性的平衡,从而连续生成覆盖整个帕累托前沿的可控对抗场景。这一范式不仅统一了现有轨迹优化、采样及扩散生成方法,更实现了从单一策略优化到连续策略谱系生成的跨越,为构建鲁棒且可解释的自动驾驶安全评估系统提供了关键支撑。
中文摘要
对抗性场景生成是一种用于自动驾驶系统安全评估的高性价比方法。然而,现有方法通常局限于单一且固定的权衡,难以在相互竞争的目标(如对抗性与真实性)之间取得平衡。这导致生成的模型具有行为特异性,无法在推理阶段进行引导,缺乏针对多样化训练和测试需求生成定制化场景的效率与灵活性。针对这一问题,我们将对抗性场景生成任务重构为多目标偏好对齐问题,并提出了一种名为可引导对抗性场景生成器(Steerable Adversarial scenario GEnerator, SAGE)的新框架。SAGE 能够在无需重新训练的情况下,在推理阶段对对抗性与真实性之间的权衡进行细粒度控制。我们首先提出了分层基于组的偏好优化方法,这是一种数据高效的离线对齐方法,通过解耦硬性可行性约束与软性偏好来学习平衡相互竞争的目标。与训练固定模型不同,SAGE 针对相反的偏好微调两个专家模型,并在推理时间通过线性插值其权重来构建连续的策略谱系。我们基于线性模式连通性视角为该框架提供了理论依据。大量实验表明,SAGE 不仅能够生成在对抗性与真实性之间具有更优平衡的场景,还能实现更有效的驾驶策略闭环训练。项目主页:https://tongnie.github.io/SAGE/。
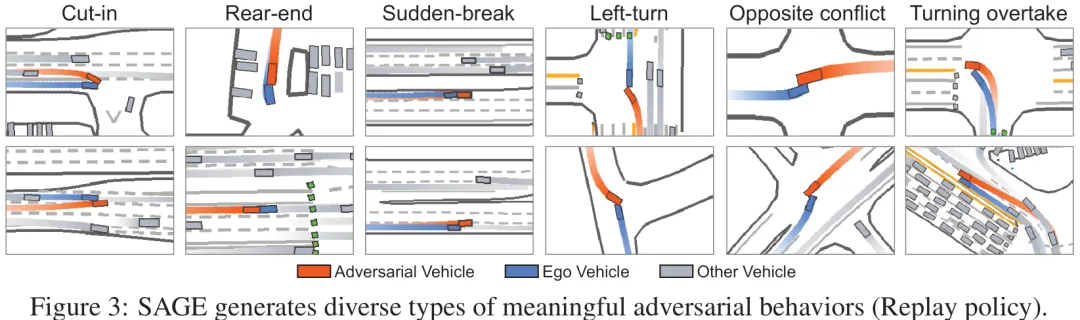
Paper Key Illustration
原文
Steerable Adversarial Scenario Generation through Test-Time Preference Alignment
Abstract: Adversarial scenario generation is a cost-effective approach for safety assessment of autonomous driving systems. However, existing methods are often constrained to a single, fixed trade-off between competing objectives such as adversariality and realism. This yields behavior-specific models that cannot be steered at inference time, lacking the efficiency and flexibility to generate tailored scenarios for diverse training and testing requirements. In view of this, we reframe the task of adversarial scenario generation as a multi-objective preference alignment problem and introduce a new framework named \textbf{S}teerable \textbf{A}dversarial scenario \textbf{GE}nerator (SAGE). SAGE enables fine-grained test-time control over the trade-off between adversariality and realism without any retraining. We first propose hierarchical group-based preference optimization, a data-efficient offline alignment method that learns to balance competing objectives by decoupling hard feasibility constraints from soft preferences. Instead of training a fixed model, SAGE fine-tunes two experts on opposing preferences and constructs a continuous spectrum of policies at inference time by linearly interpolating their weights. We provide theoretical justification for this framework through the lens of linear mode connectivity. Extensive experiments demonstrate that SAGE not only generates scenarios with a superior balance of adversariality and realism but also enables more effective closed-loop training of driving policies. Project page: https://tongnie.github.io/SAGE/.
链接:https://arxiv.org/pdf/2509.20102
Subscribe to arXiv’s Daily Preprint Notifications