 夜雨聆风
夜雨聆风





AI Agent 工具选择:CLI、MCP、Skill 到底用哪个?
你有没有算过,你的 AI Agent 上下文窗口里,有多少 token 是真正用来干活的,有多少是被工具说明吃掉的?
我上周算了一笔账:接了 GitHub MCP,80 个工具,55,000 个 token。而我实际用到的,只有 2 个工具。
这不是个例。现在很多人给 Agent 接 MCP,好像接得越多越厉害。但没人问一句:这三者——命令行(CLI)、MCP、Skill——到底有什么区别?什么时候用哪个?
今天把这三件事讲清楚。
先说说这三件事分别是什么
CLI(命令行) 最好理解。就是 cat、grep、git 这些命令。模型在训练时已经见过海量命令行示例,对这些命令的参数、用法烂熟于心。你让 Agent 跑 git log --oneline -10,它不需要任何人教就知道怎么用。
零额外开销,模型脑子里本来就有。
MCP(Model Context Protocol) 是 Anthropic 在 2024 年底发布的开放协议。它本质上是给 Agent 接了一套”结构化接口”——每个工具都有名字、说明、JSON schema。Agent 想用就调。
问题是,所有工具的 schema 在对话开始时就被全塞进上下文窗口了。你接了 GitHub MCP,80 个工具,55,000 个 token,全部加载。不管你用不用。
Skill 是我最想说的。它本质上是一个 Markdown 文件,里面写着:这个场景下应该怎么做、具体用什么命令、有哪些坑、怎么验证结果。
它不是告诉模型”有这个工具”,而是告诉模型”这件事怎么做”。
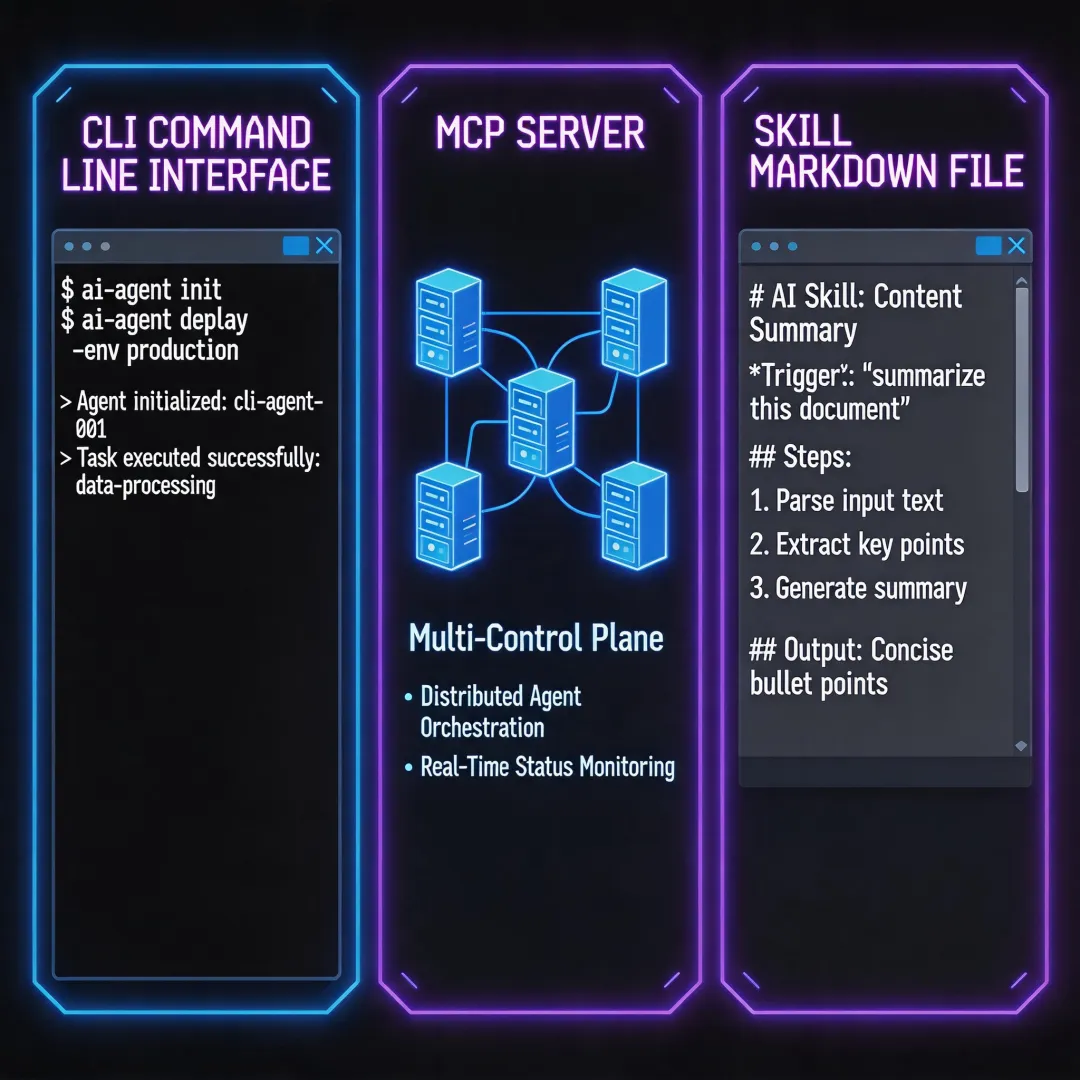
举个例子。我有一个 Skill 叫 youtube-subtitle-research,内容大概是:去 YouTube 搜某个关键词,筛选最近 24 小时的视频,下载字幕,去重处理,然后分析内容。里面写了具体用什么命令、文件存哪个路径、日期过滤为什么要做两遍、哪个 Python 脚本处理字幕效果最好。
这些知识不是模型训练数据里有的。是我自己跑过几次之后,踩了坑,总结出来的。
三件事的本质区别
用个比喻来说:
CLI 是你会开车。 模型本来就会,不需要额外学习。
MCP 是车上装了全套导航系统,80 条预设路线全加载好。 功能强大,但不管你去哪,80 条路线说明全在脑子里占着。
Skill 是副驾坐了个老司机。 到了特定路口才开口说”这个路口得走辅路,主路在修”。按需加载,不用的时候不占空间。
但 Skill 和前两者的本质区别不止是”按需加载”。
它会进化。
CLI 命令是操作系统定的,你改不了。MCP 服务器的 schema 是开发者写的,你也不太好动。但 Skill 是你自己的 Markdown 文件。踩了坑?加一行注意事项。发现更好的做法?改掉旧的步骤。
Hermes Agent 甚至有个自动管理功能,每隔几天给你的 Skill 库做一次体检:合并重复的、删掉过时的、给每个 Skill 打分。模型本身也会在对话结束后自动回顾,把新学到的东西更新到 Skill 里。
上个月我搞 YouTube 字幕下载的时候,第一次跑日期过滤出了 bug,修好之后 Agent 自己把修法写进了 Skill。下次再跑同样的任务,直接走正确路径。
这种”经验沉淀”是 CLI 和 MCP 都做不到的。
那到底该用哪个?
不是非此即彼。但我想给你一个决策框架:
| 场景 | 推荐方式 | 原因 |
|---|---|---|
| 文件操作、Git 操作 | CLI | 模型本来就会,零开销 |
| 抓渲染过的网页 | MCP | CLI 搞不定动态内容 |
| 调需要认证的 API | MCP | 结构化接口更安全 |
| 团队规范(如 commit 格式) | Skill | MCP 不会知道你们的约定 |
| 踩坑经验、最优路径 | Skill | 只有你自己知道 |
| 需要组合多个工具完成的事 | Skill | Skill 可以引用 CLI 和 MCP |
一个实战案例。
假设你要做一个”每日 GitHub 热门项目追踪”的任务:
- 用 **CLI** 就能搞定:`git clone` + `grep` 搜索关键词 + 写文件记录
- 如果你要用 GitHub API 查 star 数、issue 数,那就上 **MCP**
- 但如果你有一套自己的评判标准(”star 数短期内暴增才是真热门”、”要排除垃圾仓库”),这些判断逻辑写成 **Skill**,下次 Agent 直接按你的标准跑
三种方式组合着用,才是正解。
MCP 的 token 问题,有没有解?
有。但不是换个方式,而是换一种使用思路。
1. 只接你真正需要的 MCP 服务器。
不要什么都接。每个 MCP 服务器都是”全量加载”,接得越多,上下文窗口胖得越快。
2. 用 Skill 做”前置筛选”。
在 Skill 里写清楚:什么场景下用哪个 MCP 工具。Agent 加载 Skill 后,按需调用 MCP,而不是一开始全加载。
3. 等待 MCP 生态的改进。
Anthropic 已经意识到这个问题了。未来可能会有”按需加载 MCP 工具”的机制,而不是现在这样”一把全塞”。
在那之前,Skill 是你最好的缓冲层。
写在最后
如果你的 Agent 开始逆向工程一个 JavaScript 框架就为了读一个网页,那大概率是选错了工具。
如果你的 Agent 每次做同一件事都要重新摸索一遍,那大概率是缺一个 Skill。
三件事——CLI、MCP、Skill——不是竞争关系,是分层的:
- **CLI 是地基**:模型本来就懂,优先使用
- **MCP 是扩展件**:命令行搞不定的事,用它
- **Skill 是操作手册**:团队规范、踩坑经验、最优路径,写下来,沉淀下来
最好的 Agent 不是”接了最多 MCP”的那个。是知道什么时候用哪个、懂得把经验沉淀下来的那个。
你们现在用 Agent 时,上下文窗口一般用到多少?有没有因为接了太多 MCP 导致任务失败的?评论区聊聊。