 夜雨聆风
夜雨聆风





AI 编程时代,你的需求文档可能正在「制造幻觉」:Spec 必须可追溯!
当 coding agent 可以直接把需求文档编译成代码,spec 里每一条没有来源的断言,都可能变成系统里一个”看起来合理、实际上错误”的幻觉实现。一位开发者的观点在社区引发热议:spec 一半是意图工程,一半是考古——而考古结论必须能指回原始来源。GitHub、Anthropic、OpenAI 的最新实践,都在把 spec 推向同一个方向:可追溯。
一条帖子,把”需求文档”拉回聚光灯下
2026 年 5 月 8 日,开发者 David Boskovic 在 X 上发了一段话:
“specs are half ‘intent engineering’ (thanks @jonbell) and half archeology specs should never state an archeological fact without you being able to instantly reference the source”
「spec 一半是意图工程,一半是考古。任何考古事实,都必须能立刻指回来源。」
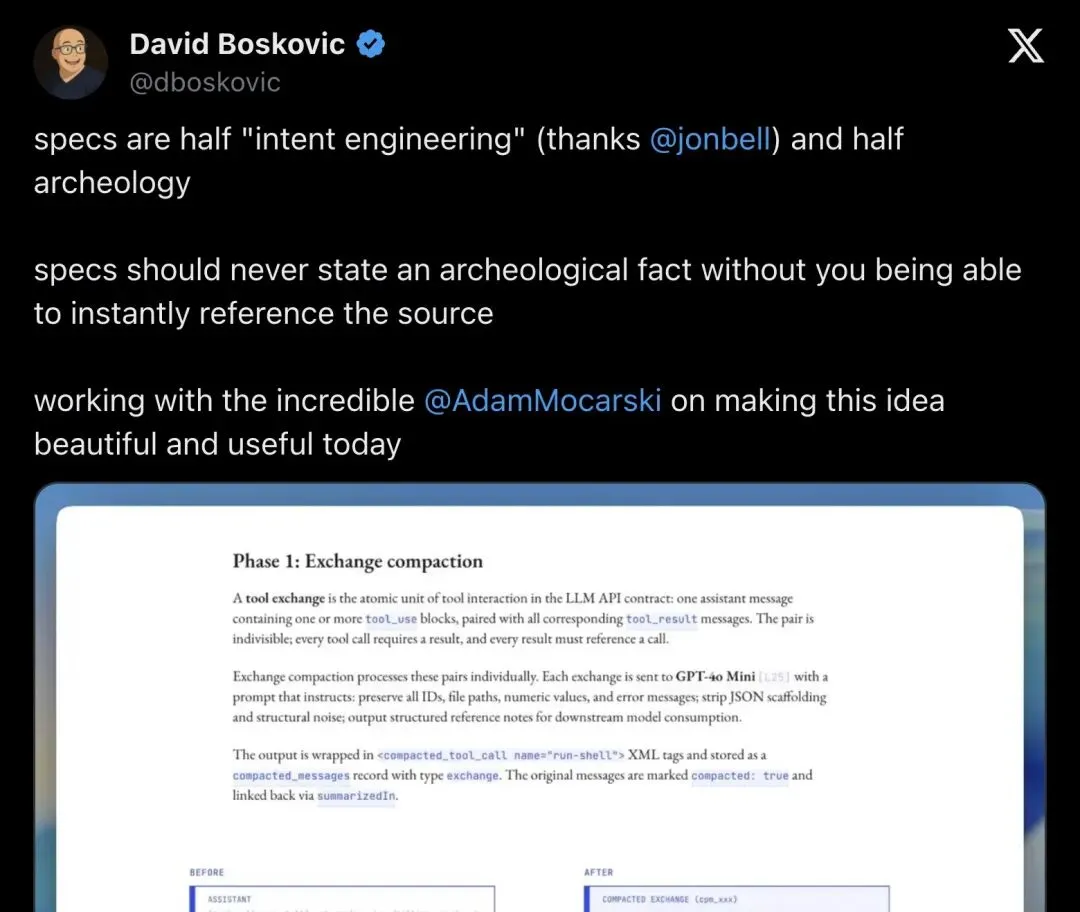
▲ David Boskovic 的原帖:spec = intent engineering + archeology
这个说法刺中了 AI 编程时代一个被严重低估的问题——当 agent 能把自然语言直接变成代码,需求文档本身的质量就决定了代码的质量。
他在回复里进一步解释:
“90% of the value is forcing the agent to cite. the remaining value is you being able to sanity check it.”
「90% 的价值在于强制 agent 引用来源。剩下的价值在于你能做 sanity check。」
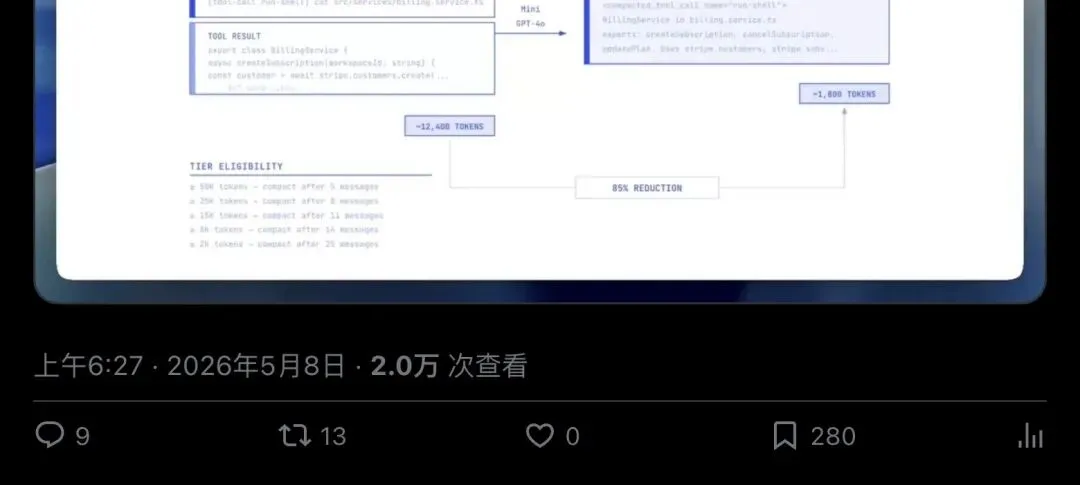
还有一个数据值得注意:他团队的分析显示,超过 50% 的 token 消耗被浪费在重复发现已知事实和修复本可避免的问题上。好的 spec 会前置研究成本,但能大幅减少下游错误。
“意图工程”:把人的目标变成 agent 能执行的输入
先拆第一半——intent engineering。
传统需求文档的读者是人。工程师看完 PRD,会追问 PM、读代码、查历史、开会对齐。模糊的地方,靠人脑补全。
但 coding agent 的工作方式完全不同。它拿到 spec,直接开始实现。模糊的需求到了 agent 手里,不会触发追问,只会触发猜测。
GitHub 在 2025 年 9 月发布了一篇博客和一个开源工具包 Spec Kit,把这个问题说得很透:
“That’s why we’re rethinking specifications — not as static documents, but as living, executable artifacts that evolve with the project. Specs become the shared source of truth.”
「我们正在重新定义 spec——它不再是静态文档,而是随项目演进的、可执行的活制品。Spec 成为共享的事实源。」
▲ GitHub Blog 文章:用 AI 做 Spec 驱动开发
GitHub 的核心判断是:vibe coding(描述目标→拿回代码)在原型阶段好用,但在严肃应用和既有代码库里靠不住。问题出在哪?我们把 agent 当搜索引擎用了,但它其实是一个”字面意义上的 pair programmer”——你说什么,它就照做。
所以 spec 必须从”给人看的文档”变成”给 agent 执行的合约”。GitHub Spec Kit 把这个流程拆成四步:
1.Specify:定义 what 和 why,用户旅程,成功标准 2.Plan:技术栈、架构选型、遗留约束、合规要求 3.Tasks:把 spec + plan 拆成可审查、可测试的小任务 4.Implement:agent 逐项实现,每步可回溯到 spec
▲ GitHub 开源的 Spec Kit 仓库,提供了从 specify 到 implement 的完整工作流
这套结构背后的逻辑是:intent engineering 要做的事情,是把”想做什么、为什么做、怎样算成功”表达成 agent 可以执行、人类可以验证的格式。减少模型猜测空间,就是在减少错误空间。
“考古”:旧系统里藏着的地雷,spec 不挖就会踩
再拆第二半——archeology。
每个有历史的代码库里,都埋着大量”只有老人才知道”的知识:
-
为什么这个接口不能改?因为三年前一个大客户的集成依赖了它 -
为什么这个字段叫 `legacy_flag`?因为当初数据库迁移时的临时方案变成了永久方案 -
为什么这个 edge case 要特殊处理?因为某次生产事故后加的 hotfix
这些知识藏在代码注释、commit message、旧 issue、wiki 页面、Slack 历史、甚至某个已经离职的工程师的脑子里。
当人类写代码时,遇到不确定的历史问题会停下来问。当 agent 写代码时,遇到不确定的历史问题会——补全。
它会根据命名规律、代码模式、训练数据里的常见做法,生成一个”看起来合理”的实现。这就是 Boskovic 说的”考古事实脱离来源”的危险:agent 在没有真实来源的情况下,制造出令人信服的虚假实现。
一位叫 tang 的开发者在回复中提到了一个现实场景:
CLAUDE.md(Claude Code 的项目级上下文文件)写了”always use X because Y”,但过了半年,没人记得 Y 是什么了。这条规则变成了一个没有来源的教条,agent 会遵守它,但没有人能判断它是否还有效。
这就是 reason drift——决策理由随时间消散,只剩下结论在系统里游荡。
上下文有限,所以来源比堆料更重要
Anthropic 在 2025 年 9 月发布的《Effective context engineering for AI agents》解释了一个关键约束:
“context engineering… curating and maintaining the optimal set of tokens…”
「context engineering 是选择并维护最佳 token 集合的策略。」

▲ Anthropic 工程博客:有效的 AI agent 上下文工程
context window 变大了,但信息回忆的准确度会随之下降。上下文必须被视为有限资源,边际收益递减。
这意味着什么?把旧需求、代码片段、会议纪要、设计稿全部塞进 spec,反而会让 agent 表现更差。
更好的做法是:把 spec 写成高信号索引。每条关键断言带出处,agent 需要时再去加载。
比如,不要在 spec 里粘贴三屏的 CSV 导入逻辑代码,而是写:
❌ “必须保留老用户 CSV 导入的兼容路径”(没有来源,agent 猜着实现) ✅ “必须保留老用户 CSV 导入兼容路径。来源:PR #1847、客户工单 SUPPORT-3291、导入日志样本见 /docs/csv-migration-2023.md”(agent 可以去读具体材料再实现)
Anthropic 关于 just-in-time context 的段落很贴合考古场景:agent 可以维护轻量级标识(文件路径、查询、链接等),运行时再动态加载相关数据。可追溯 spec 不需要把所有考古材料复制进来,它只需要让 agent 和人类在需要时能立刻找到源材料。
Agent 已经在读你的 spec 了——它读到了什么?
OpenAI 在《Building an AI-Native Engineering Team》中描述了 coding agent 在整个软件开发生命周期中的角色扩展:
“read a feature specification, cross-reference it against the codebase, and then flag ambiguities, break the work into subcomponents, or estimate difficulty.”
「读取 feature specification,与代码库交叉引用,暴露 ambiguity,拆分子任务,估算难度。」

▲ OpenAI 开发者指南:构建 AI 原生工程团队
这段话的含义很明确:agent 会拿你的 spec 去和代码库做交叉验证。
如果 spec 里写了”这个字段有历史原因不能删”,但没有指向具体的 PR、issue 或事故报告,agent 面对的就是一条不可验证的断言。它不知道自己应该验证事实、实现需求,还是沿着一条过期的 spec 继续构造错误。
Claude Code 的最佳实践文档也给出了操作层面的建议:
“Point to sources. Direct Claude to the source that can answer a question.”
「指向来源。把 Claude 引导到能回答问题的源头。」
具体包括:
- 给 agent 验证方式
:测试、截图、预期输出——没有明确的 success criteria,模型可能产出”看起来对但跑不通”的结果 - 先探索、再计划、再编码
:把 research 和 implementation 分离 - 指向具体文件、约束和模式
:不要让 agent 盲搜
强制 agent 引用来源,改变的是整个工作流:先从指定来源探索,形成计划,再实现并验证。Spec 的价值在于约束 agent 的搜索路径、事实来源和验收方式。
当心”幻觉链接”:LLM 做追溯也会出错
这里必须加一个警告。
有人可能会想:既然 agent 能读代码库、能做交叉引用,那让 AI 自动建立追溯链不就行了?
一篇 2025 年的 arXiv 预印本(2506.16440)专门评估了 LLM 做 documentation-to-code traceability 的能力。结果是:
-
最佳模型的 F1 值达到 79.4%–80.4% -
但 relationship explanation 的完全正确率只有 42.9%–71.1% -
错误类型包括:naming-based assumptions(因命名相似而误连)、phantom links(幻觉链接)、overgeneralization(架构模式过度泛化)
“false positives stem from naming-based assumptions, phantom links, or overgeneralization of architectural patterns.”
「误报来自基于命名的假设、幻觉链接或架构模式的过度泛化。」
什么是 phantom link?模型看到文档里提到”用户认证模块”,代码里有个文件叫 `auth_handler.py`,就自信地说”这里有追溯关系”——但实际上文档说的是 OAuth 授权流程,代码里的是内部 API 鉴权,两者毫无关系。
AI 可以辅助发现追溯链接,但不能完全自动化。追溯链本身也会被模型幻觉污染。所以 spec 的追溯链应该尽量绑定原始材料和可检查标识——靠 agent 自行推断,靠不住。
可执行清单:一份可追溯 spec 应该包含什么
回到实践层面。综合上面所有来源,一份面向 AI 编程时代的 spec 至少应该覆盖这几个维度:
Intent(意图层)
-
用户/业务目标 -
非目标(明确排除什么) -
成功标准和可观察验收方式
Archaeology facts(考古层)
-
为什么保留某旧行为 -
某接口/字段/流程不能改的原因 -
历史异常的上下文
Sources(来源层)
-
文件路径 + 行号 -
Commit / PR / Issue 链接 -
工单、设计稿、客户反馈 -
法规条款、日志样本、监控指标
Verification(验证层)
-
测试用例 -
预期输出 / 截图 -
性能指标 -
人工审查点
Drift control(漂移控制)
-
每条来源的时间戳 -
“这个结论是否仍然有效”的检查入口 -
过期标记机制
回复区里一位叫 BLANPLAN 的开发者提到,他们团队已经在实践一种做法:每条 spec 断言都带 file:line citation。这不是行业标准,但方向和 Boskovic 的观点高度一致。
另一位开发者 Shreyas Shinde 提出了一个有价值的补充:”Don’t cite code though.”(不要只引代码。)很多需求的来源可能是用户研究、产品决策、设计系统或法规——可追溯应该指向恰当的来源类型,而不只是代码。
最后看回这件事
AI 编程正在重新定义”需求文档”的角色。
过去,spec 写得模糊,最坏的结果是工程师多问几轮、多开几次会。现在,模糊的 spec 会被 agent 直接编译成代码——错误进入系统的速度,比任何人类工程师都快。
GitHub 说 spec 要成为 source of truth。但 source of truth 如果自身没有来源,它就只是把未知的历史改写成了新的权威幻觉。
Boskovic 那条帖子的真正价值在于一个简单的要求:你写在 spec 里的每个”因为”,都应该能指回一个具体的”在哪里”。
意图工程决定 agent 往哪走。考古决定 agent 不踩哪些雷。可追溯决定这两者是否可信。
三个维度,缺一个,agent 就在猜。
— END —