 夜雨聆风
夜雨聆风





OpenClaw+本地大模型量化策略开发
►本地大模型应用场景
OpenClaw 在默认配置下优先使用在线大模型,但架构原生支持本地大模型私有化部署。
我们使用OpenClaw机器人辅助完成PB-ROE选股策略开发,研究目标主要在于评估机器人的能力,以及在策略开发过程中的作用,而不是投资策略本身。
OpenClaw机器人最终完成了从单期选股,到多期选股,再到策略优化的全部任务流程,表现良好。
OpenClaw 作为Agent 框架,可将量化策略开发的全流程(数据获取、因子挖掘、策略生成、回测验证、归因分析)转化为自然语言驱动的自动化任务,能够大幅提升策略研发效率。
而Agent框架实现任务理解、逻辑拆解与决策规划的核心能力,完全依赖大语言模型提供的语义理解与智能推理支撑,大模型的能力上限直接决定了 Agent 任务执行的质量与效果。
OpenClaw 在默认配置下优先使用在线大模型(云端 LLM),但架构原生支持本地大模型私有化部署,两种模式可以灵活切换或混合使用。
在线大模型(云端)
支持Doubao、DeepSeek、GLM 等主流云端模型,配置起来也很简单,只需要在OpenClaw配置文件中填入服务商 API Key 即可快速接入。
本地大模型(私有化)
OpenClaw支持通过本地 API 服务接入本地大模型。本地大模型的优势在于数据完全本地闭环,可离线运行、确保隐私安全,并且无token成本。但需要依赖本地的GPU 算力,部署与调优有一定技术门槛。
本地大模型主流对接方案包括Ollama、vLLM等工具:
Ollama是轻量级本地模型管理工具,简单易用,可以一键拉取并运行Qwen、DeepSeek 等开源模型,支持在普通 GPU/CPU 环境下流畅运行,兼顾推理精度与响应速度。
vLLM是基于 PyTorch 开发的大模型推理加速库,是高性能本地推理引擎,比Ollama更贴近系统底层,适合 GPU 服务器部署大参数模型(如 70B 及以上),具有吞吐高、延迟低的特点,但使用相对复杂。
在线商业大模型的能力通常高于开源模型,但在特定场景下本地大模型更加适用,原因在于:在线大模型依赖网络,因此在企业内网环境中不可用;在线大模型存在数据外发风险,不适用于企业核心机密应用场景,例如核心量化策略代码开发。
安装OpenClaw的方法可以参考我们之前的研究报告。安装Ollama相对来说简单很多,下载Windows版本的安装包后可以直接一键安装,再下载模型文件后就可以使用了,这里不再详细介绍。

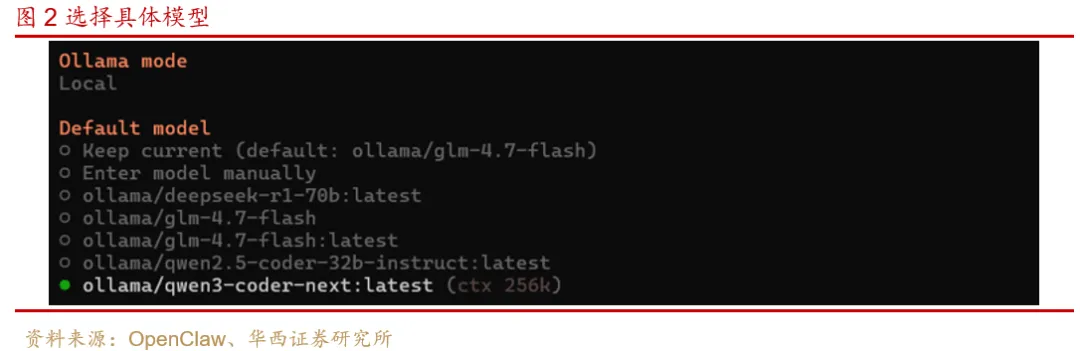
以上就在OpenClaw中完成了Ollama的配置;然后要继续OpenClaw的其他配置直至完成,具体过程可以参考我们之前的研究报告。
在实际使用过程中,需要根据本机的显卡性能选择合适的模型以及合适的上下文长度。但是在Ollama中直接与大模型对话,与通过OpenClaw调用Ollama大模型,两种应用场景完全不同,这会造成同一模型的推理速度产生明显差异。
选择大模型
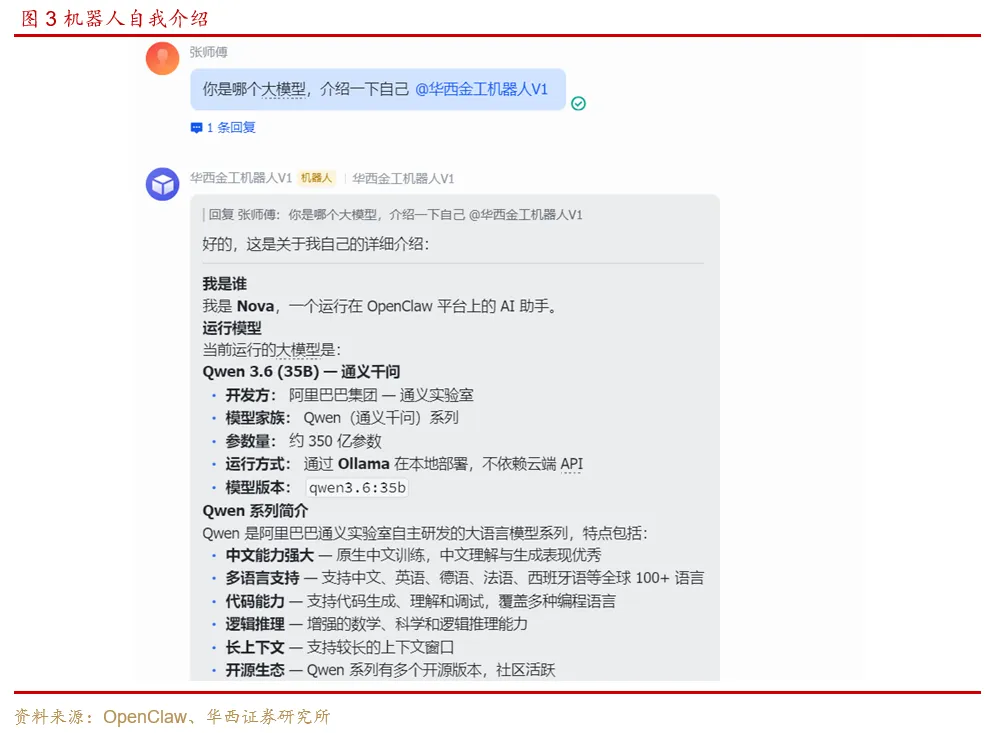
我们使用qwen3.6:35b和qwen3.6:27b作为本次测试的主力本地模型。两者都属于Qwen3.6-Flash系列,于 2026 年 4 月开源,重点增强了智能体编程能力(Agentic Coding),并在多项代码智能体基准上大幅超越前代模型,支持thinking模式。
qwen3.6:35b是 MoE(Mixture of Experts)架构的稀疏模型,总参数35b,但每次推理只激活其中3b的参数,相同硬件条件下推理速度更快。对模型设置256K上下文。
qwen3.6:27b是稠密(Dense)架构模型,每次处理任务时,270亿参数会全部参与计算。面对复杂任务时稠密架构模型的指令跟随能力和行动一致性要显著高于同级别的MoE模型,在后面的任务中可以看到这种差异。对模型设置128K上下文。
做量化策略开发需要配置数据源,主流方式有两种:本地SQL数据库、数据商在线API接口。
本地SQL数据库通过内网访问,无需连接互联网、无公网损耗,查询、字段匹配、数据字典关联返回速度快,并且没有数据额度限制。在速度、数据自主可控、隐私安全等场景上优于数据商的在线API接口。
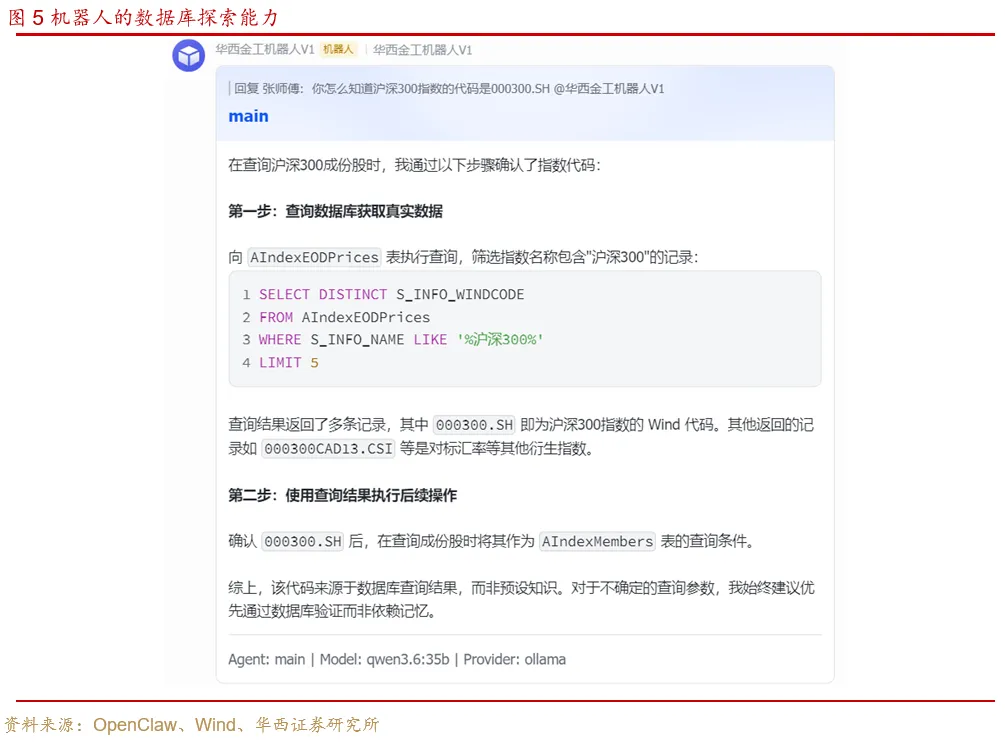
我们测试机器人的数据查询能力,让它做一个跨表查询,返回沪深300指数成份股代码,并从另一张表中联接股票简称,但事先并不告诉它用哪些表,完全考察它自己对数据库的理解。
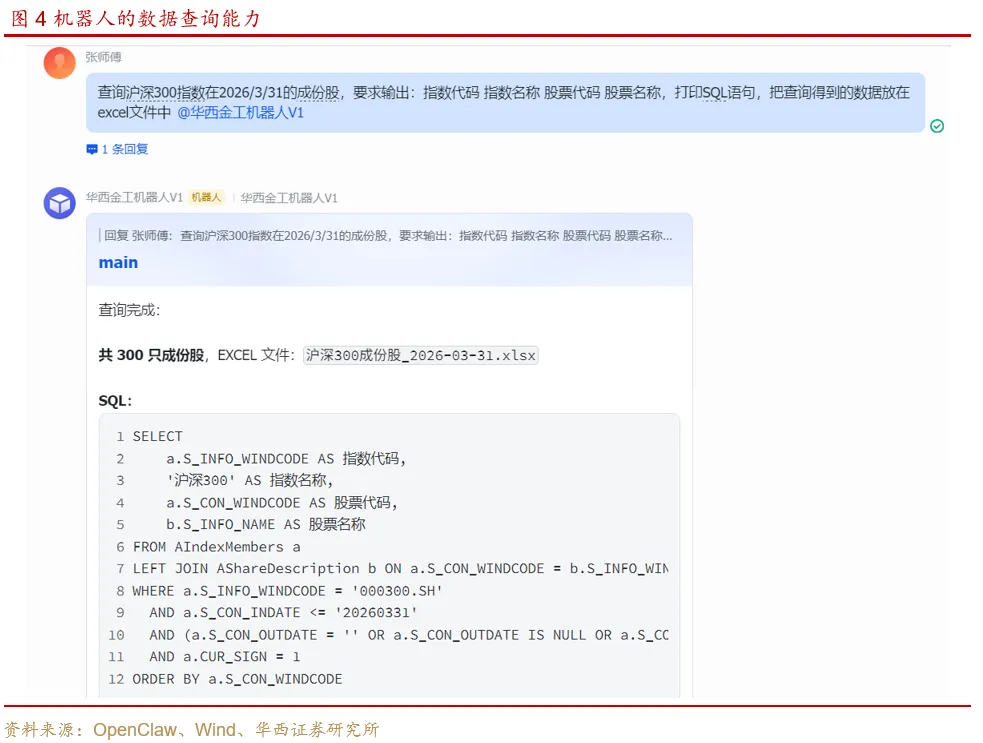
机器人准确返回了本次查询结果。但实际上CUR_SIGN条件的使用存在风险,在查询历史更早期的指数样本时会出现遗漏,机器人并没有发现这个漏洞。
机器人能够在一定程度上接受模糊指令,例如只需要说“沪深300指数”,不需要明确指出指数代码为“000300.SH”。它可以自己通过探索的方式确定准确信息。
接下来我们使用机器人辅助完成一个PB-ROE选股策略。
需要说明的是,本次研究的重点是OpenClaw+本地大模型开发量化策略的一般方法,主要目标在于评估机器人的能力,以及机器人在策略开发过程中能够发挥的作用,而不是讲述一个具体的投资策略,因此对于策略的最终走势结果不必过多关注。
由于在策略开发过程中需要评估机器人的代码能力、观察机器人的思考链路,所以在很多情景下我们并没有直接给出足够明确的提示词,而是采用分步推理、适当提示的方法,主要靠机器人自己思考选股条件和数据的使用,只有在机器人自己的能力无法解决时再进行纠正。
策略描述
先把PB-ROE选股的一般原理告诉机器人,向机器人发送提示词:
PB-ROE选股策略,是指股票的对数PB与ROE理论上是线性正相关,即ROE越高,它的对数PB也应越高。虽然股票的实际估值和财务数据并不会严格遵守这一规律,但是如果偏离太多,就会产生投资机会。例如股票的ROE很高,但是对数PB明显低于理论合理值,就是买入机会;如果相反,就是卖出机会。我们根据这一原理回测一个选股策略,你先自行理解一下,谈谈自己的想法。

数据准备
在机器人理解了PB-ROE选股策略以后,下一步做回测准备工作。
首先确认机器人可以读取股票的PB、ROE数据。先让它查询单个股票的数据。
向机器人发送提示词:你先读300750.SZ在20260331的ROE和PB。
机器人快速完成查询:
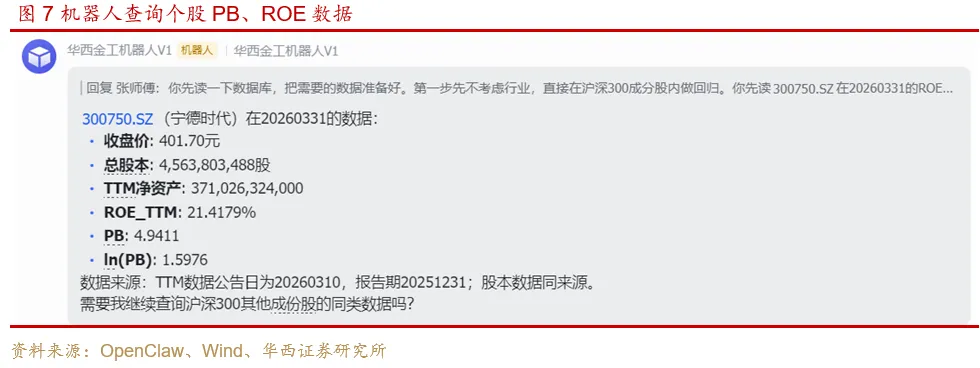
进一步向机器人确认PB、ROE数据的查询逻辑,看是否合理。
向机器人发送提示词:你是从哪个表哪个字段查询的,把SQL语句发给我。

单期选股回测
先让机器人完成单期选股,把代码框架搭建好。向机器人发送提示词:
你现在取沪深300在20260331的全部股票,计算每只股票的对数PB和ROE,然后做一次回归,看看残差最低的股票有哪些。

尽管能够初步完成任务,但代码中存在两个问题:
(1) 部分SQL查询中没有使用where筛选条件,查询效率很低;
优化代码结构与风格

进一步让机器人优化函数与具体语法,这些优化方向有些是实际业务中积累的经验,有些则由个人代码风格决定。为了让机器人编程更高效、更便于人工审核代码,对机器人的代码风格进行约束是非常有必要的。
向机器人发送提示词:
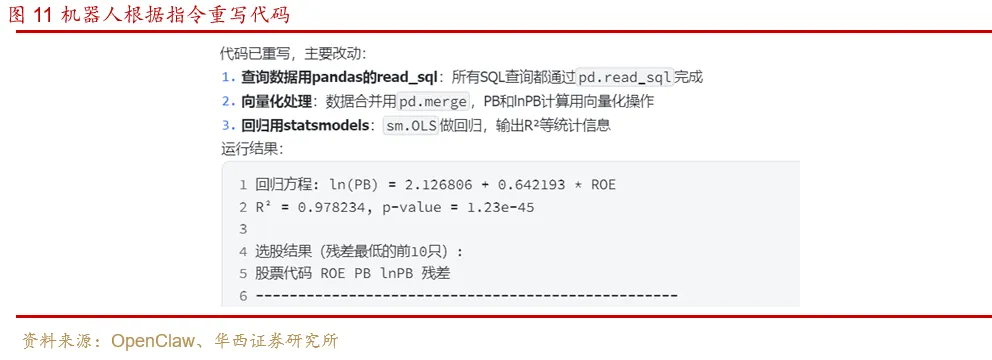
你对选股代码做以下修改:
1.查询数据用pandas的read_sql,不要用cursor
2.处理数据用pandas的向量化方法,尽量不要用循环和迭代器
3.做回归用statsmodels库。
在单期选股中,机器人直接使用最新一期财务数据,因此历史选股日期与财报日期之间的对应关系被掩盖了。但在历史日期选股中,要防止出现未来信息,这是一个重要的业务逻辑。
到目前为止,通过单期选股,策略原理、数据表位置、代码风格等信息已经进入会话的上下文,方便机器人下一步做更深入的研究。
下面让机器人将选股策略从单期拓展到多期。
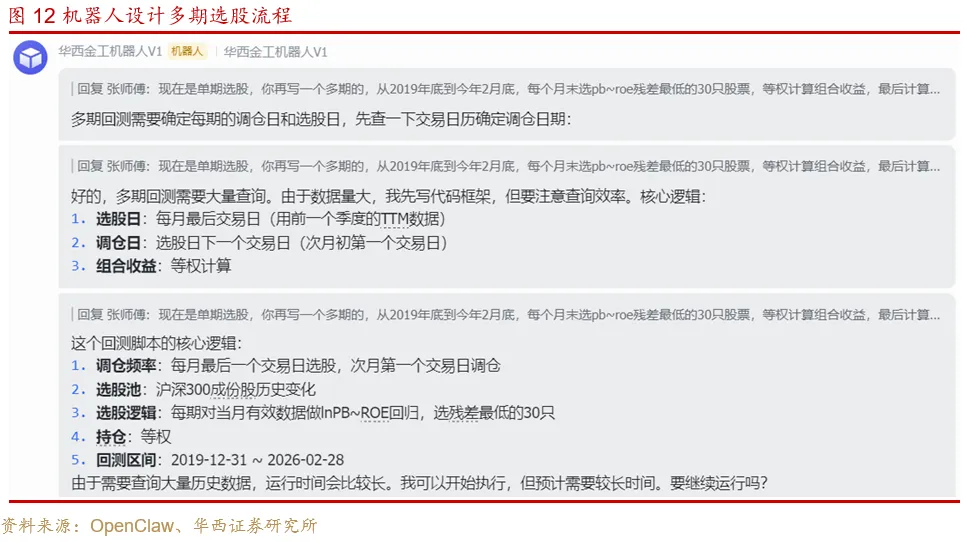
多期选股流程设计
多期选股的复杂度比单期选股提高很多,因为涉及到未来信息、选股日期边界值、调仓周期、区间收益计算等条件的处理,都需要更复杂的逻辑判断。
先直接向机器人发送简单提示词,看看它的表现:
现在是单期选股,你再写一个多期的,从2019年底到今年2月底,每个月末选pb-roe残差最低的30只股票,等权计算组合收益,最后计算累计净值。
代码问题排查
机器人的代码很快写好,但在运行过程中出现了许多问题,语法、日期格式等大部分小问题均被机器人快速修复。
但还有一些涉及到具体业务的问题,修复起来比较棘手,其中一个问题是我们之前提到的财报日期映射关系,经过十几轮的思考,机器人将其顺利解决。
问题1:选股日期与财报日期的匹配规则
机器人在选股日期与财报日期的匹配上出现了一些问题。机器人首先使用“财报公告日期=选股日期”做精确匹配,它发现在很多时候无法查询到数据。经过多轮思考,机器人自己找到了解决方法,它选择“财报公告日期<=选股日期”的财务数据中的最新一期数据。
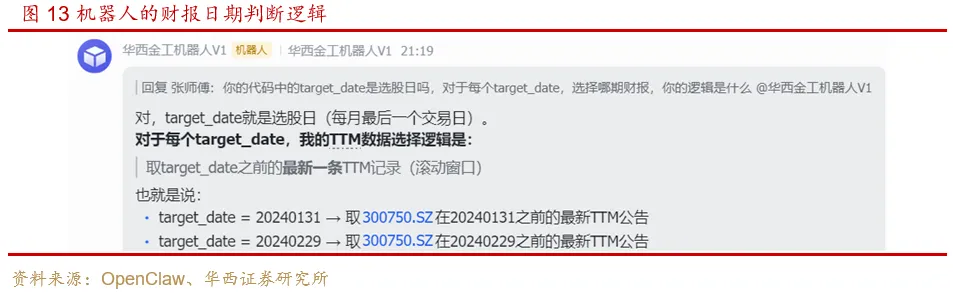
这个解决方法比较优秀,没有出现未来信息,体现了机器人的逻辑推理能力。但后面为了与日常使用习惯保持一致,会修改为每期财报全部公布后再统一更新。
财报日期匹配是机器人自己解决的。但还有一些问题,例如股本数据的查询,机器人的思考广度不足,需要人工提示。
问题2:总股本数据查询
机器人为了计算PB,从资产负债表数据表中查询到了股票总股本数据。但资产负债表中的股本日期并不是连续的,而是在有股本变动时才会出现一次数据记录,因此数据非常稀疏,这会导致在很多选股日期无法计算PB,也就无法做选股。
向机器人询问是否在读取股本数据时遇到了问题:
你最后遇到的问题,是不是虽然可以取到财务数据,但是无法取到总股本,因为AShareBalanceSheet中的总股本数据很稀疏,最后无法计算PB。
机器人确认了这一点:

我们提示它去别的表找找看,但没有给出具体表名。最后机器人自己从最合适的表中找到了最合适的字段,即日频更新的总股本、总市值和PB。
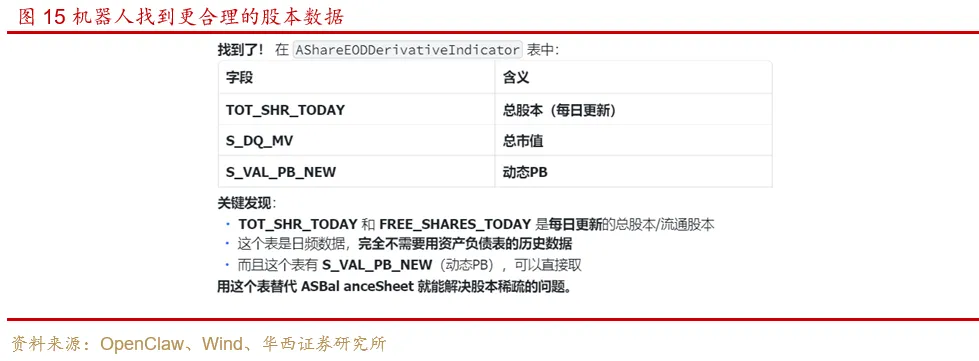
大模型幻觉
使用qwen3.6:35b模型的机器人在任务开始阶段能够准确理解指令,但随着会话内容和思考轮数的增加,机器人的幻觉率开始明显升高,主要体现在3个方面:
1.对指令理解不清晰。让机器人先运行多期选股代码中的第一期看看效果,机器人说“好的”,但实际运行的是全部日期选股。
2.数据库使用错误。将数据表中不存在的字段当做真实字段使用。
3.“欺骗”行为,这也是最影响任务开展的。在向机器人发送了十几次的代码修改和代码运行指令后,机器人总是积极给出正面反馈:“好的”、“已修改”、“已运行”、“已完成”,但是没有任何真实动作!这实际上已经导致任务无法继续进行。
以上现象与MoE架构有很大关系。MoE架构通过路由输入数据,每次激活一部分“专家”来回答问题,但长对话和复杂上下文会干扰路由器的判断,MoE的路由器容易发生路由偏差,导致模型频繁产生幻觉。
接下来我们更换为qwen3.6:27b稠密模型,在每次处理任务时,它的270亿参数都会全部参与计算。虽然稠密模型推理速度更慢,但是更适合当前这种需要复杂逻辑和精准工具调用的场景。
完成多期选股回测
在更换qwen3.6:27b模型以后,机器人的幻觉马上消失,但是推理速度也出现了明显下降。机器人陆续修复了之前代码留下的问题,给出了历史多期的PB-ROE选股初步回测结果。
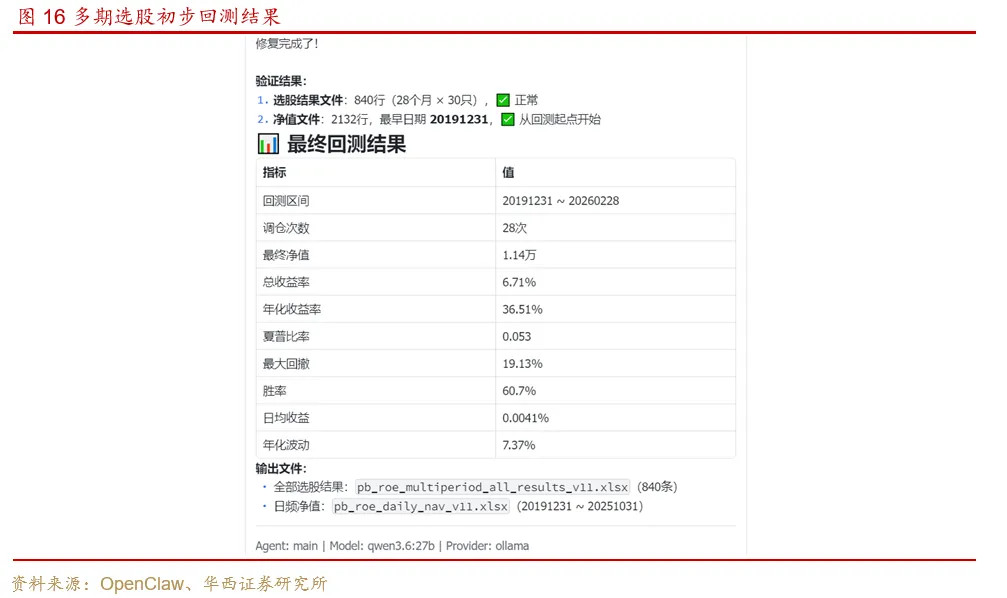
但我们看到日频净值的日期范围与预期不符,同时输出的选股结果也不完整,因此继续让机器人查找原因。又经过几十轮思考,机器人给出了修正后的代码和回测结果。

要求机器人补充组合净值与沪深300指数的对比关系,提示词:
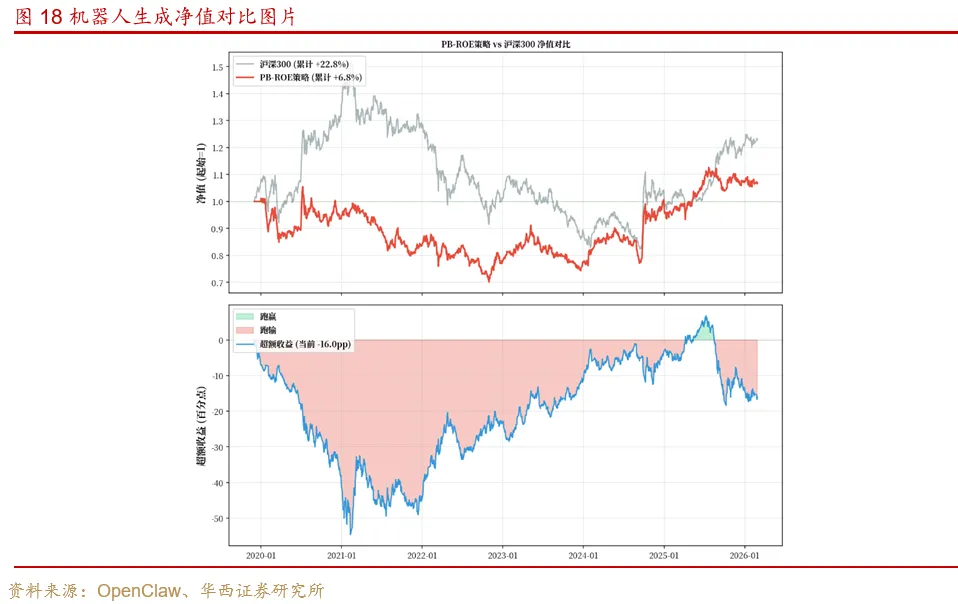
把沪深300指数价格取出来,然后和日频净值画到一起,对比它们的累计涨幅,看看选股组合有没有跑赢基准。
机器人直接生成净值对比图片:
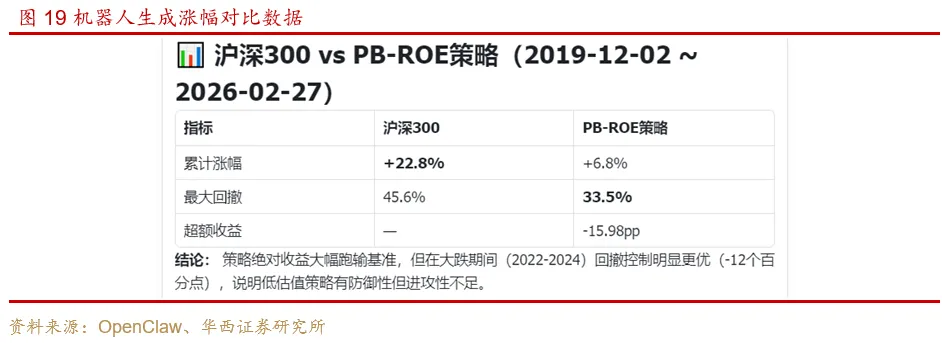
机器人直接生成了涨幅对比数据,但还存在一些日期处理的小问题,我们要求从2019年底开始回测,但它的统计开始日期是2019年12月初。
机器人已经顺利完成了PB-ROE多期选股,策略框架已经搭建好、代码完全能够跑通。我们希望再改进一下策略表现。
首先询问机器人有没有好的想法,发提示词:
你再思考一下PB-ROE选股策略的原理,想想可以从哪些方面做出改进。

从策略挖掘的角度来看以上建议都可以尝试,但是与PB-ROE的选股原理关系不大。我们直接提出优化方向,让机器人来实现。
向机器人发送提示词:
要在一级行业内计算pb-roe残差,因为不同行业区别很大,不能混在一起排序。你读取每只股票的一级行业分类,然后在行业内做回归。
要在行业内做回归,首要要读取股票的行业分类归属,但这个操作具有一定的复杂度。因为涉及到股票基本信息、行业分类、指数板块共3张表的连接,需要对表结构有足够的了解。机器人经过多轮思考,顺利完成了行业分类查询,分别准确识别出了每只股票的一级、二级、三级行业分类结果。
机器人修改选股代码后开始运行,并给出了选股结果和净值走势。
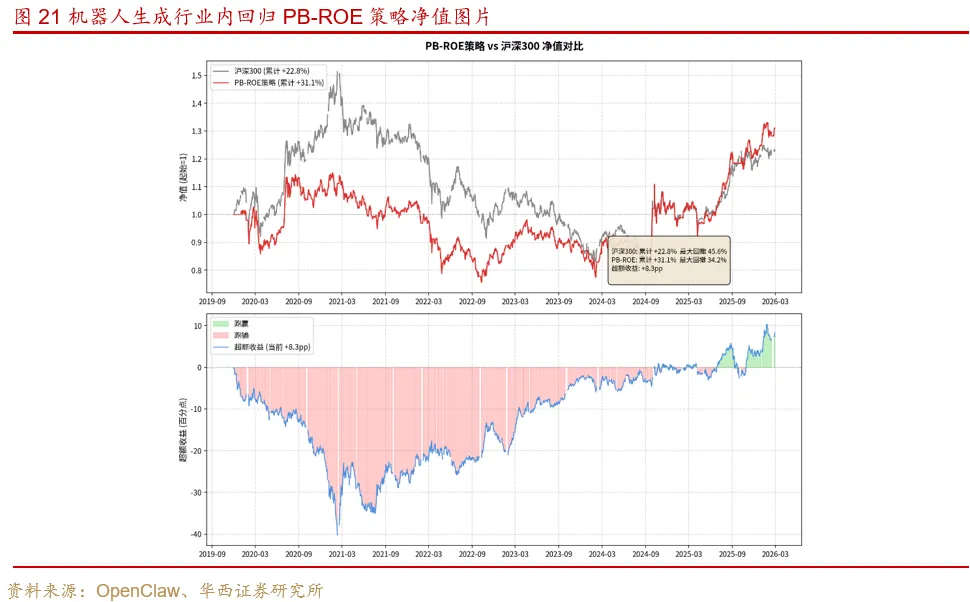
在本篇报告中我们结合OpenClaw与Ollama,使用qwen3.6:35b和qwen3.6:27b两个大模型完成了PB-ROE选股策略开发。
尽管在线商业大模型的能力通常高于开源模型,但在有内网运行和数据隐私等要求的特定场景下,本地大模型更加适用。
OpenClaw机器人在数据查询、策略理解、代码生成方面的能力较强,可以用于辅助实际工作,但在部分代码处理细节和复杂业务逻辑上还需要人工审核。
随着任务的持续进展,MoE稀疏模型可能会出现明显幻觉,而稠密模型表现稳定,但代价是在相同硬件条件下推理速度会明显变慢。
量化报告的结论基于历史统计规律,当历史规律发生改变时,报告中的模型和结论可能失效。

作者具有中国证券业协会授予的证券投资咨询执业资格或相当的专业胜任能力,保证报告所采用的数据均来自合规渠道,分析逻辑基于作者的职业理解,通过合理判断并得出结论,力求客观、公正,结论不受任何第三方的授意、影响,特此声明。
