 夜雨聆风
夜雨聆风





OpenClaw的Agent架构拆解
题外话,写在前面
总体来看,龙虾的架构设计还是有比较多成熟实践的,有学习的价值(虽然目前本体的仓库有往屎山发展的趋势)。
虽然引用鹅厂公众号的评价:技术框架并不是OpenClaw的亮点。


从最近各大厂商和机构的表现来讲,一个答案已经显而易见了:
龙虾这种形态的通用Agent盘活了卖token的商业模式,云/模型厂没理由不推
核心内容速览
本文主要切入的是OpenClaw的Agent相关架构。
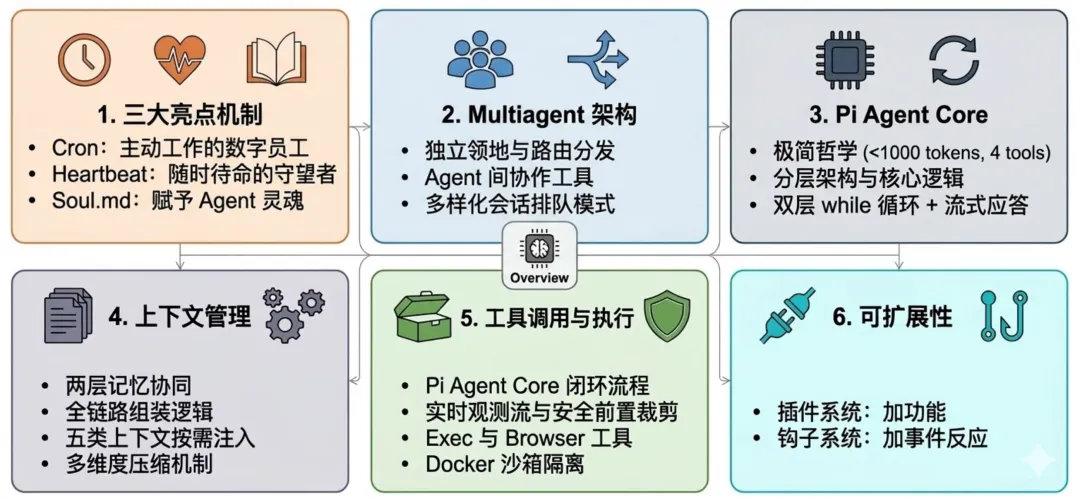
1. 三大亮点机制设计
Cron 定时调度机制
Cron 机制赋予了 Agent “计划执行”的能力。
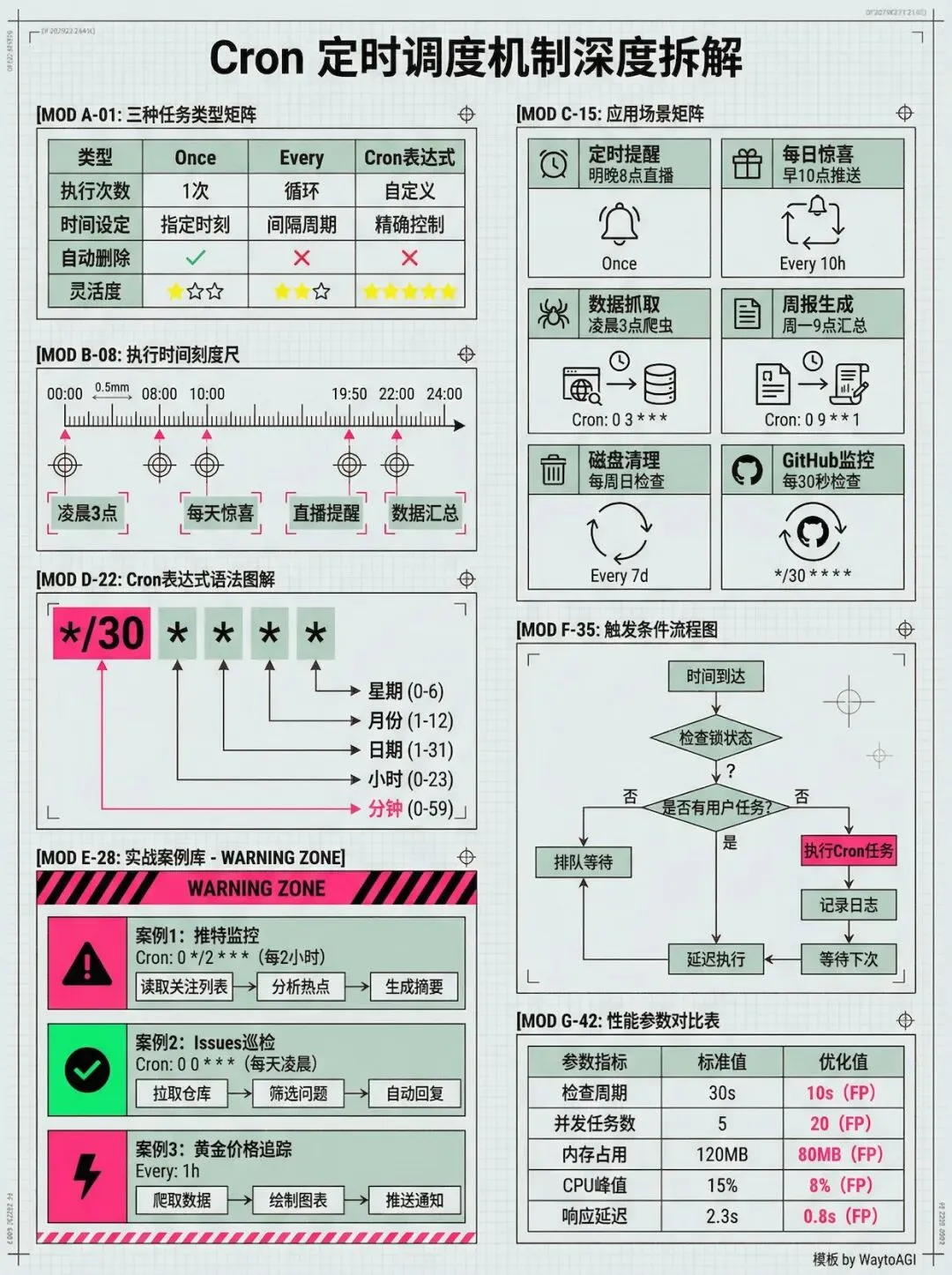
它支持三种灵活的调度模式:
- 一次性提醒
:“明天下午3点提醒我开直播” - 周期性任务
:“每天早上10点给我发送一份早报” - 标准 Cron 表达式
:满足更复杂的工程化调度需求
这些任务不需要用户手动配置。Agent 本身就有权限调用 Cron 工具,它可以根据对话上下文,主动给自己安排任务。比如你可以告诉它:“每天晚上12点去扫一遍这个开源仓库的 issues”,它就会自动添加一个定时任务,第二天当你问它时,它已经默默地把资料准备好了。
Heartbeat 心跳机制
这是让 OpenClaw 显得“有生命”的关键机制,也是它区别于传统 Agent 的核心所在(当然,也是烧 Token 的真凶)。
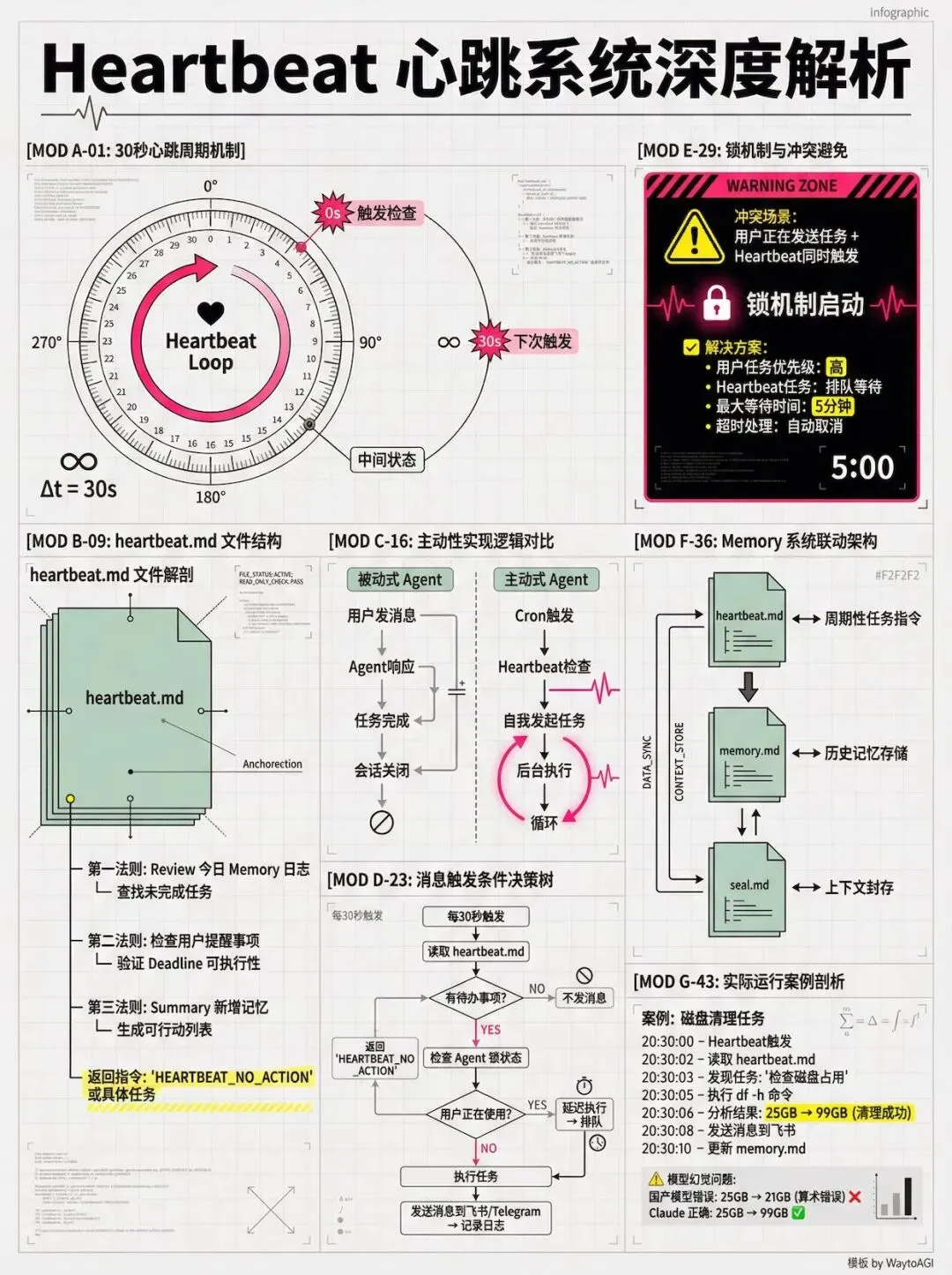
简单来说,系统每隔一定时间自动给 Agent 发送一条隐形消息,内容来自 heartbeat.md。这个文件记录着Agent 的待办事项和周期性检查任务。
收到心跳后,Agent 会快速扫描上下文和清单:
- 有事做
:立即执行任务(如检查邮件、监控服务器状态)。 - 没事做
:返回一个特定的静默关键词(NO_REPLY),系统收到后不会打扰你。
这种机制让 Agent 处于一种“随时待命”的状态,它不再是被动等待你唤醒,而是主动在后台为你守望。
Soul.md:赋予 Agent 灵魂
如果说 AGENTS.md 是 Agent 的操作手册,那么 SOUL.md 就是它的性格与灵魂。
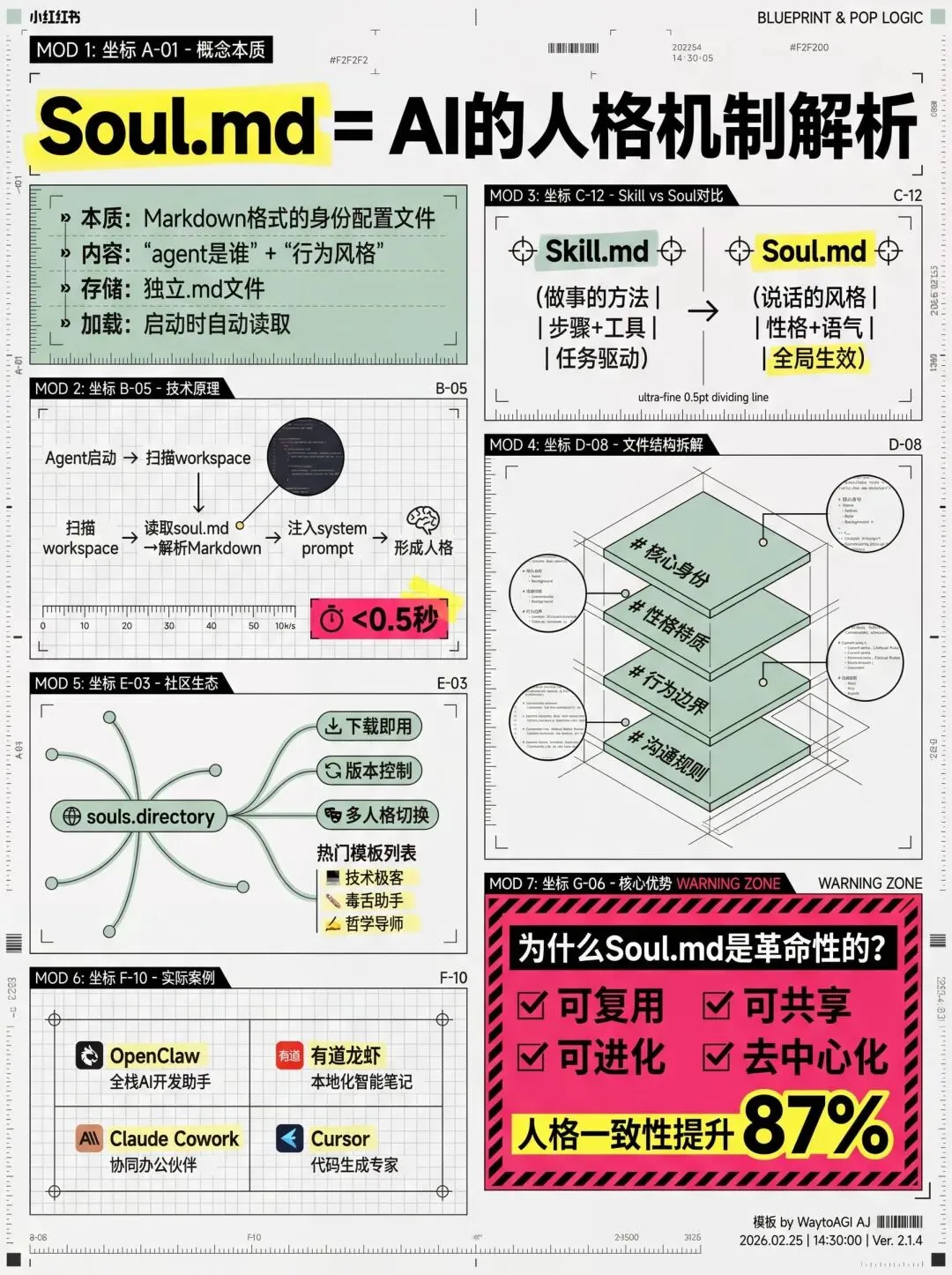
此章节图片转自通往AGI之路
在这个文件中,你可以定义 Agent 的语气、边界和优先级。
SOUL.md独立出来定义的创新实践,这种细微的性格调优,有效且高效的定义了Agent的“灵魂”。
2. Multiagent 设计
多 Agent 隔离与路由
在 OpenClaw 中,每个 Agent 都拥有自己的独立区域。位于 openclaw/agents/下各自的目录中,拥有独立的工作区、会话记录和记忆库。
比如你的“coding Agent”专注于项目开发(调用cc 🐶),而“私人 Agent”则打理你的日程和习惯,两者互不干扰。
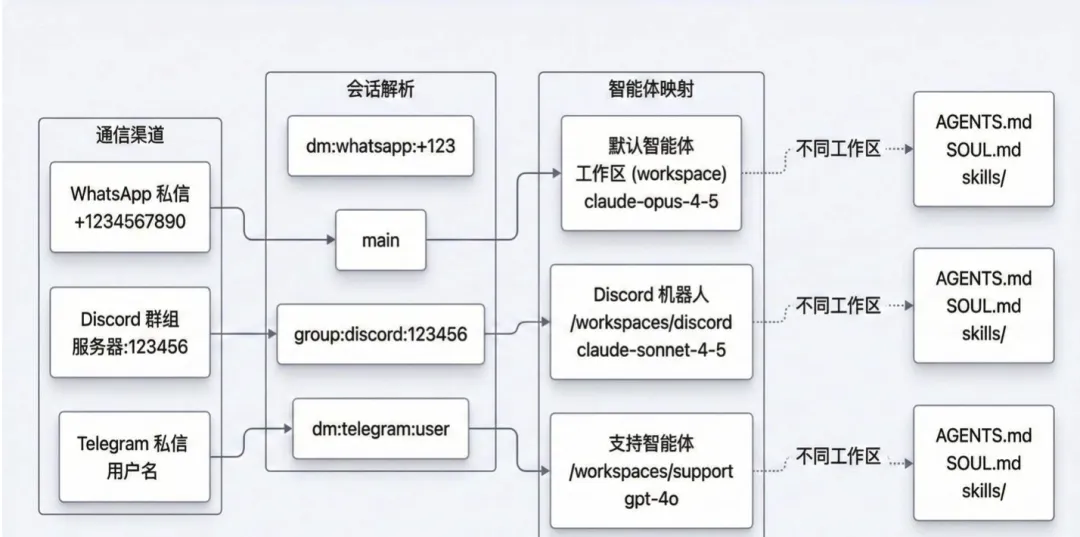
这种隔离通过 config.json 中的频道映射来实现。同一个 Gateway 充当了总机角色:你在 Telegram 上发给工作群的消息会被精准路由到工作 Agent,而发给私人频道的消息则直达私人 Agent。
隔离级别由 dmScope 参数控制。将其设为 per-agent 后,每个 Agent 只能访问属于自己的对话流。这意味着你可以在同一个 Gateway 上同时运行多个专职 Agent。
Agent 间协作会话工具
为了让这些独立的 Agent 能够配合工作,OpenClaw 提供了一套“会话工具”,让它们之间可以相互传话和协作:
- sessions_list
:查看当前有哪些活跃的会话 - sessions_send
:向另一个会话发送消息 - sessions_history
:查阅其他会话的历史记录 - sessions_spawn
:创建一个新会话来委派具体任务
对于单/多 Agent 会话排队的情况,支持的模式有
- sequential
:串行模式,同一会话的消息排队处理,避免并发冲突 - concurrent
:并发模式,允许同一会话下的多个 Agent 同时运行 - collect
:收集模式,对快速连续的消息进行防抖和批量处理 - Steer
:干预模式,将排队中的消息注入到当前正在运行的任务中 - Followup
:跟进模式,等待当前回合结束后再处理排队消息
3. Pi Agent Core(精简至上的Agent)
Pi Agent是OpenClaw的核心Agent引擎,由 Mario Zechner 开发(位于 badlogic/pi-mono)。它是一个极简、高效的编程 Agent,信奉前沿 LLM 经过 RL 训练后已足够理解“编码助手”的职责,因此不需要冗长的系统提示词和复杂的规划模块。
|
|
|
|
|---|---|---|
| 系统提示词 |
|
< 1000 tokens |
| 内置工具数 |
|
4个 (read/write/edit/bash) |
| 架构思路 |
|
极简运行时 & 文件驱动 |
Pi 仅凭 read、write、edit、bash 四个核心工具就覆盖了 90% 的需求。其 bash 工具支持自我调用,巧妙地以“可见的子进程”替代了传统 Agent 难以观测的“子智能体(subagent)”。
PI Agent 的核心运行流程
PI Agent 的核心运行流程可以概括为四个阶段: 入队与加锁 → 构建提示词 → 调用模型(含回退)→ 处理响应 。
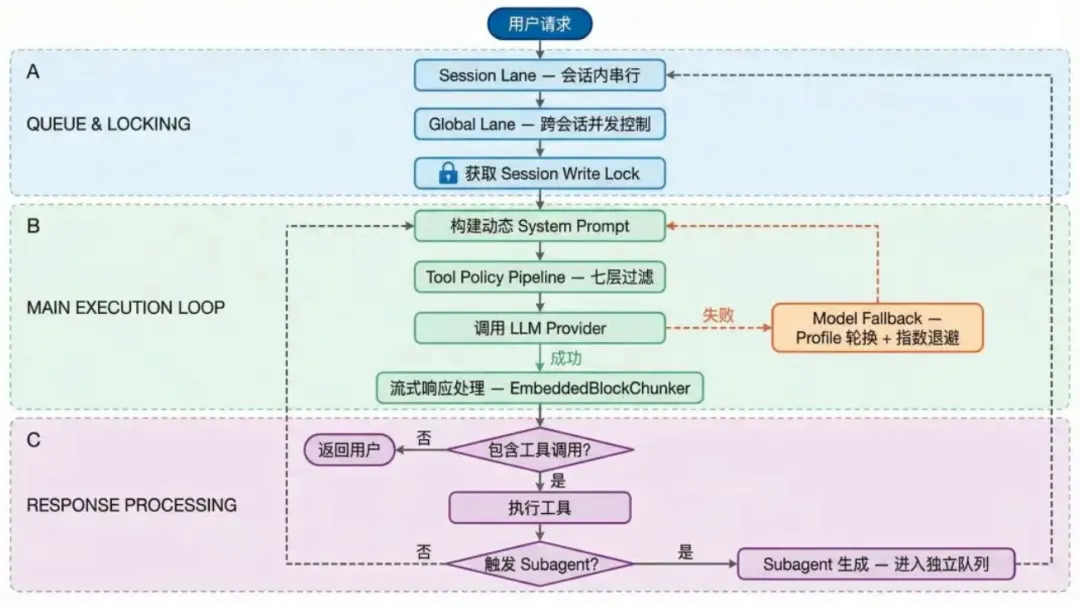
架构分层与核心逻辑
Pi 采用严格的分层架构,构建系统强制执行:Applications(应用层)→ Core(核心层:pi-agent-core)→ Foundation(基础层:pi-ai)。整个核心运行时仅由 5 个文件、约 1500 行代码构成:
- types.ts
:定义灵活的 AgentMessage,支持应用层扩展自定义消息,实现“最晚转换”策略(仅在调用模型瞬间过滤为 LLM 格式)。 - agent-loop.ts
:核心循环。 - agent.ts
:状态容器与消息队列,管理 Steering(干预)和 FollowUp(后续)队列。 - proxy.ts
:Web 带宽优化,仅传输 delta 事件。 - index.ts
:agent 包的统一导出入口
核心循环:双层 While 设计
agent-loop.ts 实现了 Mario Zechner 所说的 “LLM + tools + a loop”的简洁设计。其核心是双层 While 循环,实现了任务的自主推进与灵活干预:
1. 外层循环:由 FollowUp 消息驱动。处理完当前任务后,若有后续任务则重启内层循环,实现任务连续推进。2. 内层循环:由 ToolCall 和 Steering 消息驱动。负责“注入消息 → 调用 LLM → 执行工具 → 结果反馈”的闭环。
Steering 中断机制:当用户在工具执行期间发送消息时,内层循环会立即标记后续工具为“跳过”并中断,将干预消息注入上下文。这解决了主流 Agent 无法中途纠偏的痛点。
流式应答:最晚转换,保证上下文实时更新
streamAssistantResponse 是消息转换的唯一边界。它在调用 LLM 的瞬间才将 AgentMessage 转换为模型格式。更关键的是,它会将 LLM 的流式响应就地更新到 context.messages 数组中。这意味着无论何时发生重试或干预,模型看到的上下文永远是最新的实时状态,避免了逻辑滞后。
4. 上下文管理
上下文组装
OpenClaw采用了“分层 + 可插拔”的提示词组装策略,这个模块,我们基于full模式从以下多个维度解释。
维度1: 两层记忆的协同
每次运行时,Gateway 都会抓取 AGENTS.md、SOUL.md、USER.md、IDENTITY.md 以及当天的每日日志,在 LLM 看到你的消息之前将它们注入到上下文中。
这就是第一层:Bootstrap(引导记忆)。Agent 每次都能看到这些文件的内容,没有例外。但它们会消耗 Token。你在 Bootstrap 文件里塞得越多,每次请求就越贵。
第二层:Semantic search(语义搜索)。当启用记忆插件时,Agent 会通过向量索引搜索 MEMORY.md 和其他笔记,通过“含义”而不是“关键词”来寻找相关的块。
区别在于
-
Bootstrap 是 Agent 每次必看的内容。 -
语义搜索只在需要时提取当前相关的内容,不会持续消耗上下文,但它不能保证每次都能浮现出完全正确的事实。
典型注入文件
这几个被注入的 Markdown 文件来自 Workspace 的一组 .md 文件,每个文件都有独特的作用,而且易于读写:
- AGENTS.md
:操作手册。Agent 应该如何思考,何时使用哪个工具,遵循什么安全规则,按什么顺序做事。 - SOUL.md
:性格与灵魂。语气、边界、优先级。希望 Agent 简洁明了不给多余建议?写在这里。想要一个友好的助手?也写在这里。 - USER.md
:你的用户画像。如何称呼你,你的职业,你的偏好。Agent 在每次回复前都会读取这个文件。 - MEMORY.md
:长期记忆。绝不能丢失的事实。比如“我们只在 DEX 上交易,不用 CEX”、“主 RPC 是 Alchemy,备用是 Infura”。Agent 会自行写入,或者在你要求时写入。 - YYYY-MM-DD.md
:每日日志。今天发生了什么,哪些任务正在进行,你们讨论了什么。到了明天,Agent 会打开昨天的日志并接续上下文。 - BOOTSTRAP.md
:首次运行仪式(一次性,仅全新工作空间注入),如引导对话等。 - IDENTITY.md
:身份与氛围。很短的文件,但它奠定了整体的基调。 - HEARTBEAT.md
:定期检查清单。“检查邮件”、“看看监控是否在运行”。 - TOOLS.md
:本地工具提示。脚本存放在哪里,哪些命令可用。这样 Agent 就不需要去猜,而是确切知道。
OpenClaw 采用 2 种持久化的实体文件(MEMORY.md 与 memory/YYYY-MM-DD.md)来存储长期记忆,会话开始时会读取 MEMORY.md(仅主会话)和当日/昨日的日志文件作为初始上下文,运行中可通过 memory_search 工具将相关片段动态拉入上下文。
维度2 :提示词组装全链路
`get-reply-run` 先拼出 prompt(用户侧上下文)和 `extraSystemPrompt`(系统侧额外上下文)→ `runEmbeddedAttempt` 构建基础 system prompt→ 载入/清洗历史消息→ `context-engine` 二次改写(可加 system 前缀、可改历史)→ hook 最后改写(可 prepend user prompt、可覆盖/前后包裹 system prompt)→ `activeSession.prompt(effectivePrompt)` 发给模型。
说人话的话,步骤是
1. 组装用户输入上下文2. 生成基础系统提示3. 清理历史对话4. 语境引擎二次加工5. 插件/钩子最终改写6. 解析图片并发送模型
接下来我们详细拆解这个链路的每个部分
1) 用户侧上下文 user message 怎么拼
按顺序(典型即时执行路径):
1. 基础正文:baseBody,特殊情况下改成 reset 提示(/new、/reset)2. 前置“用户不可信元信息块”:buildInboundUserContextPrefix(…)3. 会话 hint 注入:applySessionHints(…)4. 系统事件文本前缀:drainFormattedSystemEvents(…) 后 prepend5. 不可信上下文附加:appendUntrustedContext(…)6. 线程上下文前缀(thread starter/history)7. 媒体说明与回复提示(有媒体时)8. 形成最终 commandBody,传给 embedded runner
2) 系统侧 extraSystemPrompt 怎么拼
顺序固定为:
1. inboundMetaPrompt(受信元数据 JSON)2. groupChatContext(群聊长期上下文)3. groupIntro(首次/激活行为引导)4. groupSystemPrompt(群配置系统提示)
然后 join(“\n\n”) 作为 extraSystemPrompt 传入 run。
3) 基础 system prompt 怎么拼
主要 section 顺序(full 模式):1. 身份行2. Tooling3. Tool Call Style4. Safety5. CLI Quick Reference6. Skills(可选)7. Memory(可选)8.Self-Update(可选)9. Model Aliases(可选)10. Workspace11. Docs(可选)12. Sandbox(可选)13. Authorized Senders(可选)14. Current Date & Time(时区信息)15. Workspace Files (injected) 标题16. Reply Tags / Messaging / Voice(可选)17. extraSystemPrompt(作为 Group/Subagent Context)18. Reactions(可选)19. Reasoning Format(可选)20. Project Context(注入文件内容+截断告警)21. Silent Replies(非 minimal)22. Heartbeats(非 minimal)23. Runtime(收尾)
4) runEmbeddedAttempt 内部:最终上下文组装顺序
顺序是:
1. 先构建基础 system prompt:buildEmbeddedSystemPrompt(…)2.applySystemPromptOverrideToSession(session, systemPromptText)写入 session3. 读取并清洗历史:sanitize/validate/truncate/repair,然后replaceMessages(…)4. context-engine assemble:– 可替换历史消息– 可prependSystemPromptAddition到 system prompt 前面5. prompt-build hooks:–prependContext加到当前用户 prompt 前–systemPrompt(legacy)可直接覆盖整个 system prompt–prependSystemContext/base/appendSystemContext组合最终 system prompt(顺序:prepend -> base -> append)6. 解析 prompt 内图片,最后执行:activeSession.prompt(effectivePrompt, {images?})
维度3 : 归纳成 5 类上下文 不同模式 按需注入
1. 基础系统规则上下文:agent 行为、工具、安全、runtime2. 会话/渠道系统上下文:inbound trusted metadata、group context、group intro、group system prompt3. 项目上下文:bootstrap/context files 注入内容4. 历史会话上下文:session transcript(经清洗/裁剪/修复)5. 本轮用户上下文:当前 prompt(含 untrusted metadata、system events、thread/media 信息、hook prepend)
关键上下文控制逻辑
PromptMode 开关:
- none
:仅保留第一行身份定义。 - minimal
:(常用于子智能体)自动跳过“用户权限”、“消息路由”、“语音”、“更新”等约 10 个无关章节。 - full
:包含上述所有完整章节。
过滤机制:
所有章节通过 lines.filter(Boolean) 处理,这意味着如果某个功能(如 Sandbox 或 Memory)未启用,对应的标题和内容会完全从最终字符串中消失,不留空白。
上下文压缩机制
OpenClaw的上下文压缩机制是内建pi agent compaction +预防性 memory flush + OpenClaw overflow 恢复叠加的方案。
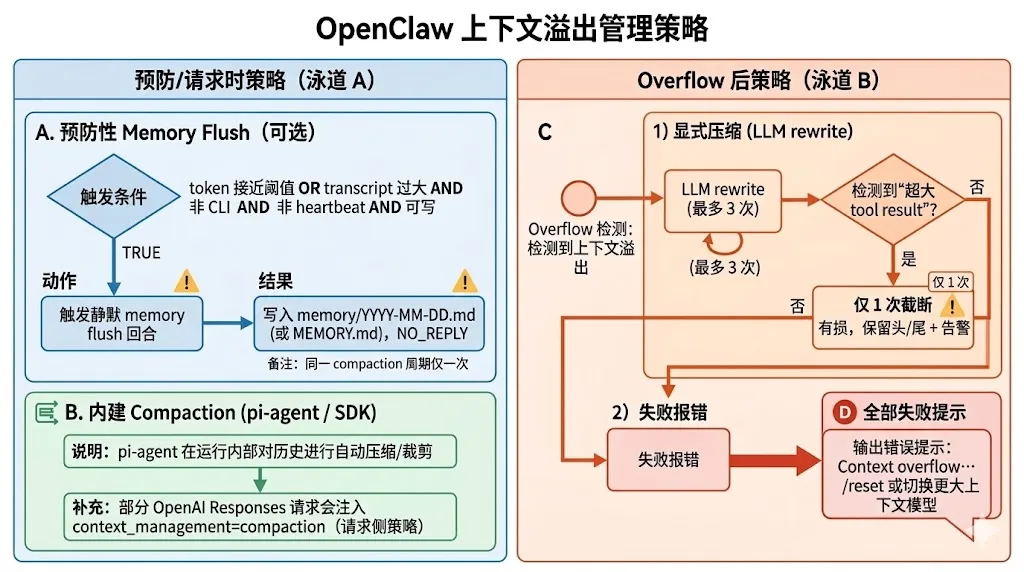
A. 内建 compaction(pi‑agent / SDK 级)
-
位置:一次运行内部(attempt 内),由 pi‑agent 处理会话历史的压缩/裁剪。 -
特点:属于“运行中的自动压缩能力”,在某些模型/请求路径还会启用 OpenAI Responses 的 context_management 作为请求侧 compaction。
B. OpenClaw 的 overflow 恢复策略
-
触发:模型报 context overflow。 -
顺序: 1. 显式 compaction(LLM rewrite,最多 3 次)
2. 仅当检测到“超大 tool result”时,执行一次截断(有损,保留头尾+告警)
3. 失败报错(提示 /reset 或切换更大上下文)
C. 预防性 memory flush(可选)
-
在接近阈值前触发一次“静默记忆写入回合” -
条件:token 接近阈值或 transcript 过大,且非 CLI、非 heartbeat、可写 -
写入:memory/YYYY-MM-DD.md(或 MEMORY.md),用 NO_REPLY 抑制输出 -
同一 compaction 周期只触发一次
5. 工具调用
OpenClaw中,工具调用的核心执行交由 Pi Agent Core,其内部逻辑遵循经典的闭环流程:tool_call → 执行工具 → tool_result → 继续调用模型。
但 OpenClaw 在此基础上增加了两层关键设计:
1. 实时观测流:工具执行过程中的 start、update、result 等生命周期事件,会通过 WebSocket 实时推送到前端。这让用户能看到工具卡片的动态变化(如正在安装依赖、正在读取文件),而不仅仅是最后的结果摘要。2. 安全前置裁剪:在将工具列表交给 Pi Agent Core 之前,OpenClaw 会先通过 Tool Policy Resolver 进行过滤。系统根据预设的 allow/deny 策略和分组规则,动态裁剪当前会话可用的工具集合。这意味着模型“看”不到它无权使用的工具,从而在执行前就确立了安全边界。
命令执行
exec 是其中最强大的工具,它可以运行 Shell 命令。Agent 可以运行脚本、安装包、处理文件、部署代码。但它也是最危险的。exec 有三种模式:
- sandbox
:在 Docker 容器内运行 Agent,与主系统隔离。 - gateway
:直接在服务器上运行,但受限于你定义的白名单命令。 - full
:无限制。适合用来做实验,但绝对不适合放了真实数据的生产服务器。
OpenClaw 通过 exec 工具执行 shell 命令,执行环境包括:
- sandbox
:默认,在 Docker 容器里运行命令 -
直接在宿主机(host machine)运行 -
在远程设备(remote devices)上运行 -
浏览器调用
6. 可扩展性
OpenClaw 的扩展分两套:插件系统负责“加功能”,钩子系统负责“加事件反应”。
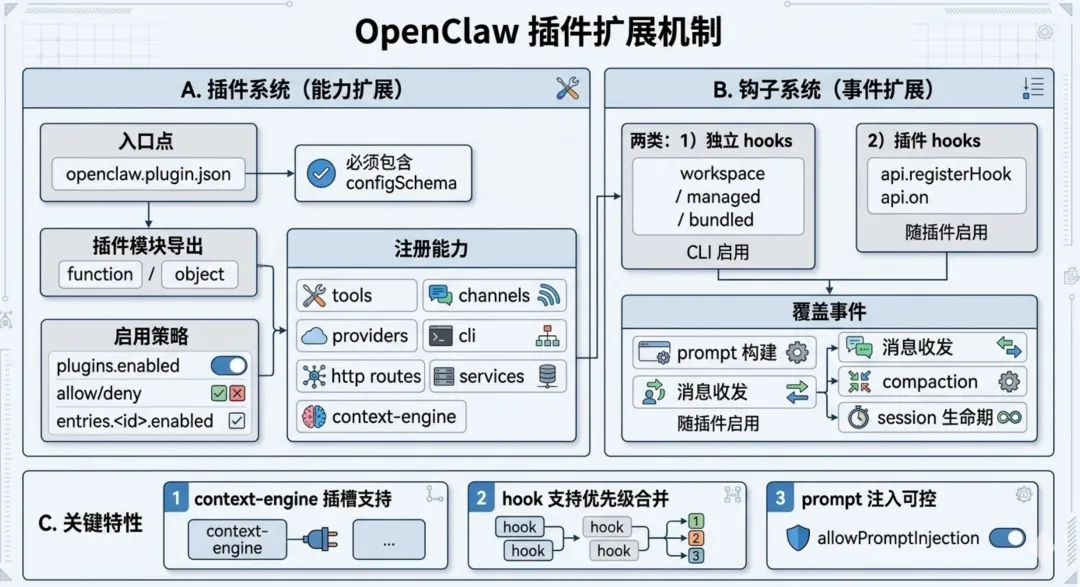
插件系统:
插件是功能包,必须带 openclaw.plugin.json,且需要 configSchema。
插件入口可以是函数,也可以是带 register 的对象(src/plugins/types.ts)。插件能扩展的能力主要包括:工具、渠道、模型 Provider、CLI 命令、HTTP 路由、后台服务、上下文引擎。
一般我们通过插件(Plugin)在四个方向上扩展:
-
渠道插件(Channel Plugin):添加新的IM,比如飞书、钉钉等 -
记忆插件(Memory Plugin):换一种存储后端,比如用向量数据库代替默认的 SQLite -
工具插件(Tool Plugin):添加自定义能力,比如除了内置的命令行、浏览器、文件操作之外的新工具 -
模型提供商插件(Provider Plugin):接入自定义的 AI 模型或自己部署的模型
插件是否启用由配置控制,总开关、allow/deny 清单、单插件开关都会生效。
钩子(hooks):
钩子分两类:
-
独立 hooks:放在 hooks 目录,用 CLI 启用(src/hooks/loader.ts) -
插件 hooks:插件运行时注册,随插件启用(src/plugins/registry.ts)
关键补充
-
插件可注册“上下文引擎”,参与/接管 compaction 与上下文组装(src/plugins/types.ts、docs/tools/plugin.md)。 -
钩子支持优先级与合并规则(src/plugins/hooks.ts)。 -
prompt 注入可按插件级开关禁用,降低风险(docs/tools/plugin.md、src/plugins/types.ts)。
总结
我认为我在zhi谱实习阶段的mentor对OpenClaw的定位很精确:“这种形态太终极了” 。
现有的架构实践、资源、模型能力还无法真正跑通这个形态,甚至需求本身在逻辑上还有诸多漏洞,未来依旧模糊
so,对于OpenClaw,我的态度依然是
1. 充分探索和理解市场对于自主Agent的需求
2. 不要花银子虾胡闹,体验过就好
3. 真正有提效需求的 好好鼓捣cc cx就行