夜雨聆风
夜雨聆风





OpenClaw 拆解②丨Agent Loop 的三层重试循环,和 Linux 调度器用了同一个解法
这是 OpenClaw 架构拆解系列的第二篇。
上一篇我说了一个判断,Agent 框架正在重新发明操作系统。收到不少反馈说「你能不能展开讲讲」。
行,那今天就把第一个模块拆到底,Agent Loop。
大部分 Agent 框架的教程会给你画一个很简单的循环图。
用户说话 → Agent 思考 → 调用工具 → 返回结果 → 用户再说话。
一来一回,像个 chatbot。
但 OpenClaw 的 Agent Loop 完全不是这个逻辑。我第一次打开 run.ts 的时候,滑到主循环那一段(L931-1079),愣了大概十秒钟。
它是一个 三层嵌套循环。
最外层 L1 是 for(;;) 无限循环,处理 Provider 级别的故障转移。中间层 L2 是 while(true),处理 Model 级别的重试。最内层 L3 是 runEmbeddedAttemptWithBackend(),处理单次 API 调用。
L1: for(;;) // Provider 故障转移
└─ L2: while(true) // Model 重试 + Profile 轮转
└─ L3: attempt() // 单次 API 调用三层嵌套,每一层处理不同粒度的故障。
💡 做过 OS 的人看到这个结构会很熟悉。Linux CFS 调度器也是三级,CPU 间负载均衡 → 调度域内迁移 → 单 CPU 时间片分配。
🎯 渐进式重试,不是简单的「再来一次」
这是我觉得 OpenClaw Agent Loop 里最精妙的设计。
当 L3 的 API 调用失败后,L2 的重试不是简单地把同样的 Prompt 再发一遍。它会往 Prompt 里追加一条「修正指令」,告诉 LLM「你上次做错了什么」。
第一次失败,追加 ackExecutionFastPath 修正。
第二次,追加 planningOnlyRetry。
第三次,reasoningOnlyRetry。
第四次,emptyResponseRetry。
每一轮的 Prompt 都比上一轮长一点,多了一条诊断信息。就像医生看病,第一次量体温,第二次加验血,第三次加 CT,每次多一个维度的诊断数据。
反直觉 重试的 Prompt 越来越长、越来越贵。但这是对的。因为简单的重发不能解决非幂等的失败(比如 LLM 理解错了指令),而追加修正指令可以。
这让我想到 TCP 的拥塞控制。
TCP 丢包后也不是简单重发。慢启动、快重传、快恢复,每一次重传都带着对网络状态的新认知。丢包不是随机事件,它是网络在告诉你「你的发送速率太高了」。同样,LLM 的失败响应也不是随机事件,它是模型在告诉你「你的指令不够清晰」。
OpenClaw 的渐进式修正,就是 Agent 世界的拥塞控制。
🔑 Profile 轮转,多配 Key 不只是提可用性
读源码的时候,我花了不少时间搞清楚 Profile 排序的逻辑。
profileCandidates 的构建有三层优先级(run.ts L613-650)。
| 优先级 | 来源 | 逻辑 |
|---|---|---|
| 1 | lockedProfileId |
如果锁定了某个 Profile,只用这一个 |
| 2 | providerPreferredProfileId |
Provider 推荐的 Profile 排到最前 |
| 3 | resolveAuthProfileOrder() |
用户配置的默认顺序 |
然后,这里有一个特别反直觉的设计。
MAX 重试次数不是固定常量。它是 resolveMaxRunRetryIterations(profileCandidates.length)。你配了多少个 API Key,重试上限就有多高。
1 个 Key → MAX_RETRIES = N
3 个 Key → MAX_RETRIES = N × 3(大概)
5 个 Key → MAX_RETRIES = N × 5(大概)反直觉 多配 API Key 不只是提高可用性(一个挂了用另一个),还直接提升了单次任务的容错空间。就像 RAID 阵列,磁盘越多不只是容量大,冗余度也更高。
这是一个「资源量决定容错上限」的设计。我在分布式系统里见过类似的模式,Raft 协议的 quorum 数量决定了最多能容忍几个节点故障。OpenClaw 的 Profile 数量决定了最多能容忍几次 API 故障。
🌳 Failover 决策树,五个出口
当重试用完或者遇到特定错误,OpenClaw 需要做一个决定,接下来怎么办?
这个决定由 resolveRunFailoverDecision 函数做出。我读完这个函数之后,画了一棵决策树。
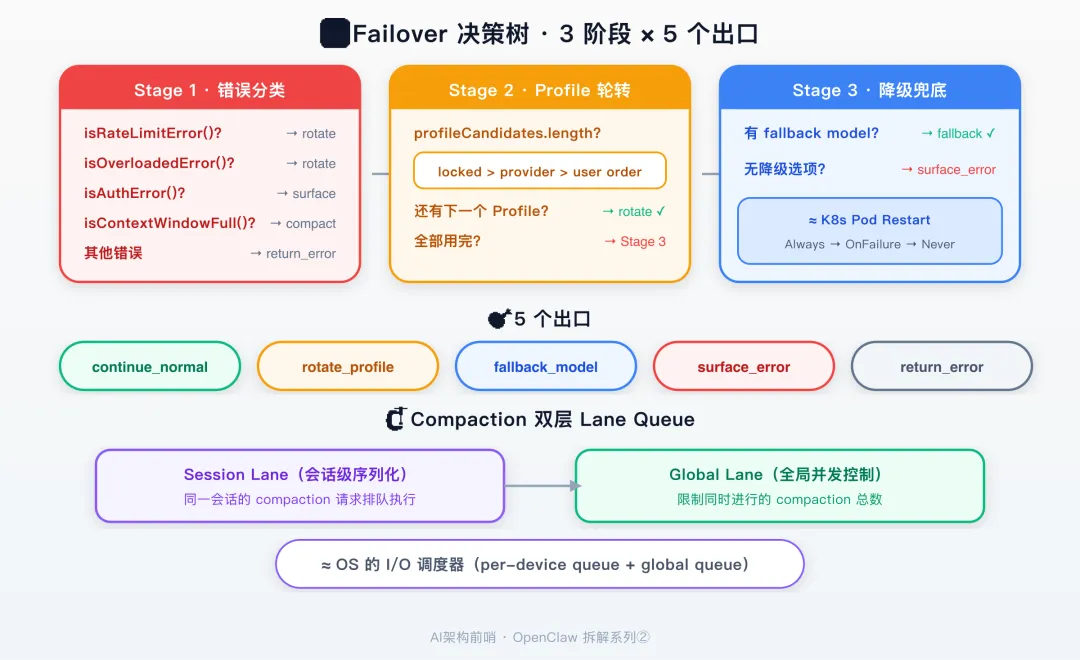
源码在 src/agents/pi-embedded-runner/run/failover-policy.ts。
三个决策阶段(对应故障发生的时机)
| 阶段 | 含义 | 典型场景 |
|---|---|---|
retry_limit |
重试次数耗尽 | L2 循环到达 MAX |
prompt |
Prompt 构建失败 | 模板错误 / 文件缺失 |
assistant |
LLM 响应异常 | 空回复 / 格式错误 / 超时 |
五个决策出口
| 出口 | 行为 | K8s 类比 |
|---|---|---|
continue_normal |
正常继续下一轮 | Pod Running |
rotate_profile |
换一个 API Key | 换 Node 重调度 |
fallback_model |
切换备用模型 | 降级到 BestEffort QoS |
surface_error |
放弃,告诉用户 | CrashLoopBackOff |
return_error_payload |
返回错误但不崩 | Failed 但不重启 |
决策输入参数(8 个布尔值的组合)
aborted、externalAbort、fallbackConfigured、failoverFailure、failoverReason、profileRotated、timedOut、timedOutDuringCompaction
8 个布尔值的排列组合理论上有 256 种,但实际上决策树通过三阶段嵌套把它收敛到了 5 个出口。
💡 从设计角度看,这棵决策树的关键约束是「外部中止永远优先」。无论在哪个阶段,只要
externalAbort为 true,直接surface_error。用户的取消操作高于一切自动恢复策略。这和 Unix 的 SIGKILL 不可被捕获是同一个设计哲学。
💓 Heartbeat,没有定时器的心跳
OpenClaw 有心跳机制。但当我去找 setInterval 或者 watchdog 线程的时候,啥都没找到。
心跳的实现在 src/agents/heartbeat-system-prompt.ts。它不是运行时触发器,而是通过 System Prompt 注入的「行为指导」。
三个前置条件(全部满足才注入心跳指导)。
- 1. 必须是 default agent(非 subagent)
- 2. Agent policy 中 启用了 heartbeat
- 3. Cadence 配置
every > 0(心跳间隔大于 0)
满足这三个条件后,System Prompt 里会多一段话,大意是「你需要定期向用户汇报进度」。
没有 timer。没有 interval。没有 thread。
就是一段提示词。
反直觉 Agent 的心跳不是代码控制的,是「语言契约」控制的。你告诉 LLM「你应该每隔一段时间汇报一下」,它就会这么做。
这是 Agent 架构特有的设计范式。传统系统用硬件中断驱动心跳,操作系统用 timer interrupt。但 Agent 的「CPU」(LLM)能理解自然语言,所以很多控制流机制可以「上移」到提示词层面。
我第一次意识到这一点的时候,觉得有点不靠谱。万一 LLM 忘了呢?
但仔细想想,传统的 cron job 也会因为系统负载太高而延迟执行。没有任何心跳机制是 100% 可靠的。LLM 驱动的心跳和 cron 驱动的心跳,可靠性可能没有你想象的差距那么大。
🔧 Compaction 与循环的并发控制
最后聊一个实现细节。当对话太长需要压缩(compact)的时候,Agent Loop 怎么处理?
答案是,在循环内部同步等待。
源码在 run.ts L1246-1312。当检测到 timedOut && !timedOutDuringCompaction 时,循环会在当前迭代暂停,等待 contextEngine.compact() 完成后再继续。
但这个等待不是简单的 await。OpenClaw 用了一个两层队列来防止并发问题。
enqueueCommandInLane(sessionLane, () =>
enqueueGlobal(async () => { ... }))Session Lane 保证同一会话的操作排队执行。Global Queue 保证全局级别的 compaction 排队,防止多个会话同时压缩导致内存峰值。
💡 这和 Go 的并发 GC 有异曲同工之妙。应用线程在 GC 标记阶段可以继续跑,但在特定安全点(safe point)需要暂停等待。OpenClaw 的安全点就是「超时且尚未压缩过」。不是完全的 Stop-The-World,但也不是完全无感知的后台操作。
这个设计的取舍很明确。完全异步的 compaction 可能导致压缩结果和当前对话状态不一致(因为压缩期间可能有新消息进来)。完全同步的 compaction 会让用户等太久。两层队列 + 安全点机制是一个中间方案,牺牲一点延迟换取一致性。
回到整体来看,OpenClaw 的 Agent Loop 是一个「三层嵌套 + 渐进修正 + 五出口决策树 + 队列化压缩」的复合系统。
它不是一个简单的 while 循环。
它是一个调度器。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~
谢谢你看我的文章,我们,下次再见。