 夜雨聆风
夜雨聆风





Nature 超越人类专家:科学软件将由AI自动编写

科学发现的周期常常因支持计算实验的软件创建缓慢且依赖人工而受阻。为解决这一问题,作者推出了经验研究辅助系统(ERA),这是一个人工智能系统,能够创建专家级的科学软件,其目标是最大化质量指标。该系统利用大型语言模型(LLM)和树搜索(TS)来系统地提升质量指标,并在庞大的可能解决方案空间中智能导航。当探索和整合来自外部来源的复杂研究想法时,ERA 能够取得专家级的结果。树搜索的有效性在各种任务中得到了证明。在生物信息学领域,ERA发现了 40 种用于单细胞数据分析的新方法,这些方法在公共排行榜上优于顶级的人工开发方法。在流行病学领域,ERA 生成了 14 个模型,这些模型在预测新冠住院人数方面优于美国疾病控制与预防中心的集成模型以及所有其他单独模型。ERA 还为地理空间分析、斑马鱼神经活动预测和积分数值解以及时间序列预测的新型基于规则的构建生成了专家级软件。通过设计并实施解决各类任务的创新方案,ERA 代表了在加速科学进步方面迈出的重要一步。
研究背景
在当代科学发现流程中,计算实验与数据驱动建模的地位日益核心。然而,支撑这些流程的实证软件(Empirical Software)的开发却严重依赖于科学家的手工编码,这一过程耗时、易错且难以扩展。实证软件旨在最大化某个可量化的质量指标,其典型代表包括密度泛函理论实现、分子动力学模拟引擎以及蛋白质结构预测工具等,这些工具已成为众多诺奖级成果的基石。尽管其重要性不言而喻,但当前科学软件的创建模式仍存在显著瓶颈:设计选择多基于直觉或经验,缺乏系统性的替代方案搜索;软件编写工作本身极度繁琐,严重限制了科学家探索假设空间的广度与深度。因此,亟需一种能够自动化、智能化地辅助或主导科学软件开发的新范式,以加速科学发现的循环。
当前,旨在自动化软件或模型开发的研究领域呈现多元化发展。遗传编程(Genetic Programming, GP)通过模拟自然进化过程,对程序群体进行变异和选择,但其变异操作多为随机语法变换,缺乏语义层面的智能。生成式编程(Generative Programming)旨在通过模板或领域特定语言生成程序家族,但灵活性受限。大型语言模型(Large Language Model, LLM)的出现,如AlphaCode和Codex,展示了从自然语言描述“一次性”生成复杂代码的潜力,但它们缺乏迭代优化与探索能力。自动机器学习(AutoML)聚焦于机器学习流水线的超参数与架构搜索,但其范围通常局限于既定框架。近期,结合LLM与搜索算法的尝试(如FunSearch、AlphaEvolve)开始崭露头角,证明了迭代式代码改进的威力。然而,现有工作或专注于单一领域(如数学发现),或未充分整合来自科学文献的外部知识。该研究正是在此背景下,提出一个能够横跨多个科学领域、系统性地整合外部研究思想,并具备专家级代码生成能力的通用框架ERA。
该研究将科学软件开发这一创造性的人类活动,转化为一个可计算、可扩展的“可评分任务”,并通过ERA系统实现了该过程的自动化。ERA不仅显著提升了多个科学问题上实证软件的性能(超越人类专家水平),更重要的是,它提供了一种通用范式,能够加速从生物信息学到流行病学、从神经科学到数值分析等广泛领域的科学探索。通过高效地探索代码空间和整合文献思想,ERA将原本需要数周甚至数月的试错周期缩短至数小时或数天,这对于加速科学发现具有深远的潜在影响。此外,该研究还开创性地展示了AI系统不仅能复现,更能重组和超越现有方法,为“AI驱动科学发现”提供了具体且可复现的实证。
科学问题
如何构建一个通用的AI系统,使其能够自动地创建并迭代优化旨在最大化特定质量指标的实证软件,并且该系统需具备有效整合外部复杂研究思想的能力,从而在多个不同科学领域的基准任务上达到或超越人类专家水平?这一问题可拆解为:如何将科学软件开发形式化为一个搜索问题?如何利用LLM实现“智能”而非随机的代码变异?如何设计搜索算法以平衡对已知高分的利用(开发)和对未知区域的探索?以及如何将科学文献中的抽象描述或思想,有效地注入到LLM的生成过程中,以引导搜索朝向更有前景的方向?
图文解析
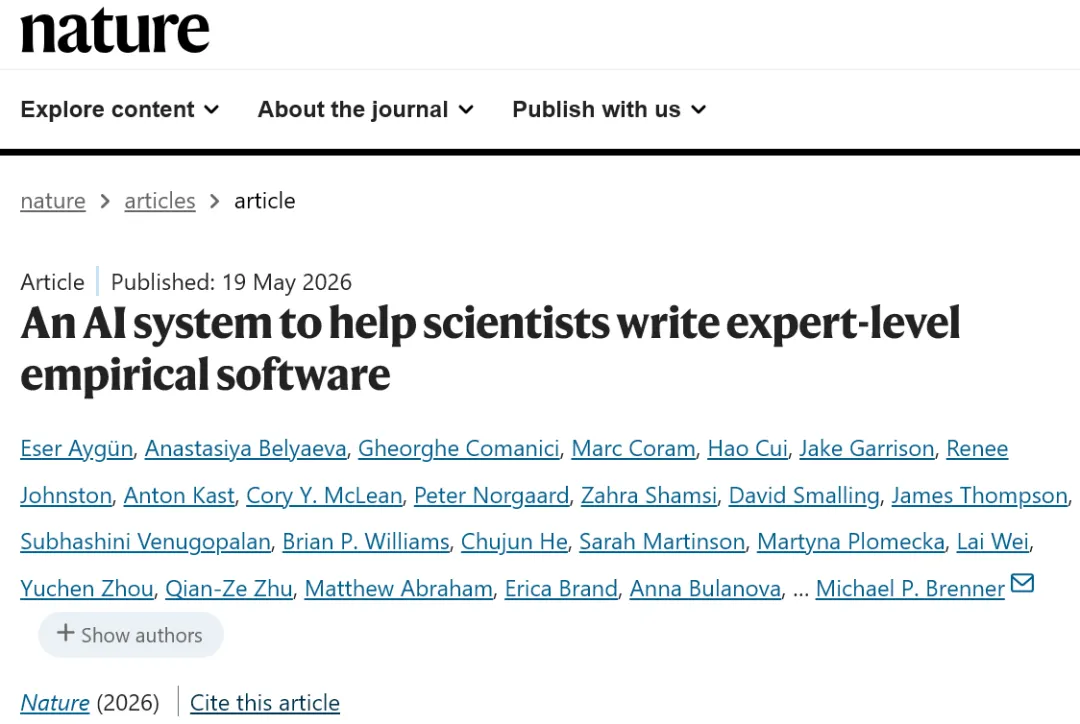
Figure 1ERA系统的架构及其在基础基准上的性能表现。
图a展示了ERA的核心工作流程。整个流程始于一个“可评分问题”和相关的“研究思想”。这些信息被整合成一个提示(Prompt)输入给一个大型语言模型。LLM根据提示生成对应的Python代码。该代码随后在一个安全的沙箱环境中执行,并基于预设的质量指标得到一个评分。这个评分与代码执行日志等信息被反馈回系统。系统核心是一个树搜索算法,它根据所有历史候选解的评分,决定是继续深入探索当前最有潜力的代码分支,还是回溯到之前的节点进行新的探索。被选中的代码将作为父节点,输入给LLM进行下一轮的改写与优化。这个循环持续进行,不断迭代改进代码质量,直到达到停止条件。
图b对比了ERA与多种基线方法在Kaggle Playground基准的16个竞赛任务上的平均性能(以公共百分位数排名衡量,数值越高越好)。结果显示,单次LLM调用(Single LLM Call)效果最差,而从1000次生成中取最佳(Best-of-1000 LLM Calls)虽有提升,但远不如ERA的树搜索(TS)方法。AIDE是另一种AI驱动的代码探索系统,其性能亦逊于ERA。在ERA框架下加入专家建议(TS with expert advice)或强制要求从头实现梯度提升决策树(TS with Boosted Decision Tree),性能得到进一步提升。这表明树搜索的“回溯”能力(当一条路径性能停滞时,能回溯到之前节点探索新分支)是其超越简单重复采样的关键,而注入领域知识能有效引导搜索。
图c概括了该研究如何将外部研究思想整合进ERA。主要途径有三条:一是利用LLM(如Gemini)总结已发表的科学论文,将其核心方法描述作为提示的一部分;二是将先前通过ERA生成的成功实现所蕴含的思想进行概念层面的“重组”,以创造出混合策略;三是使用“深度研究”或“AI共同科学家”等LLM驱动的智能体,自主地从更广泛的文献中生成新思想。所有这些途径获取的思想最终都被转化为自然语言指令,注入到提示中,指导ERA生成更优质的代码。
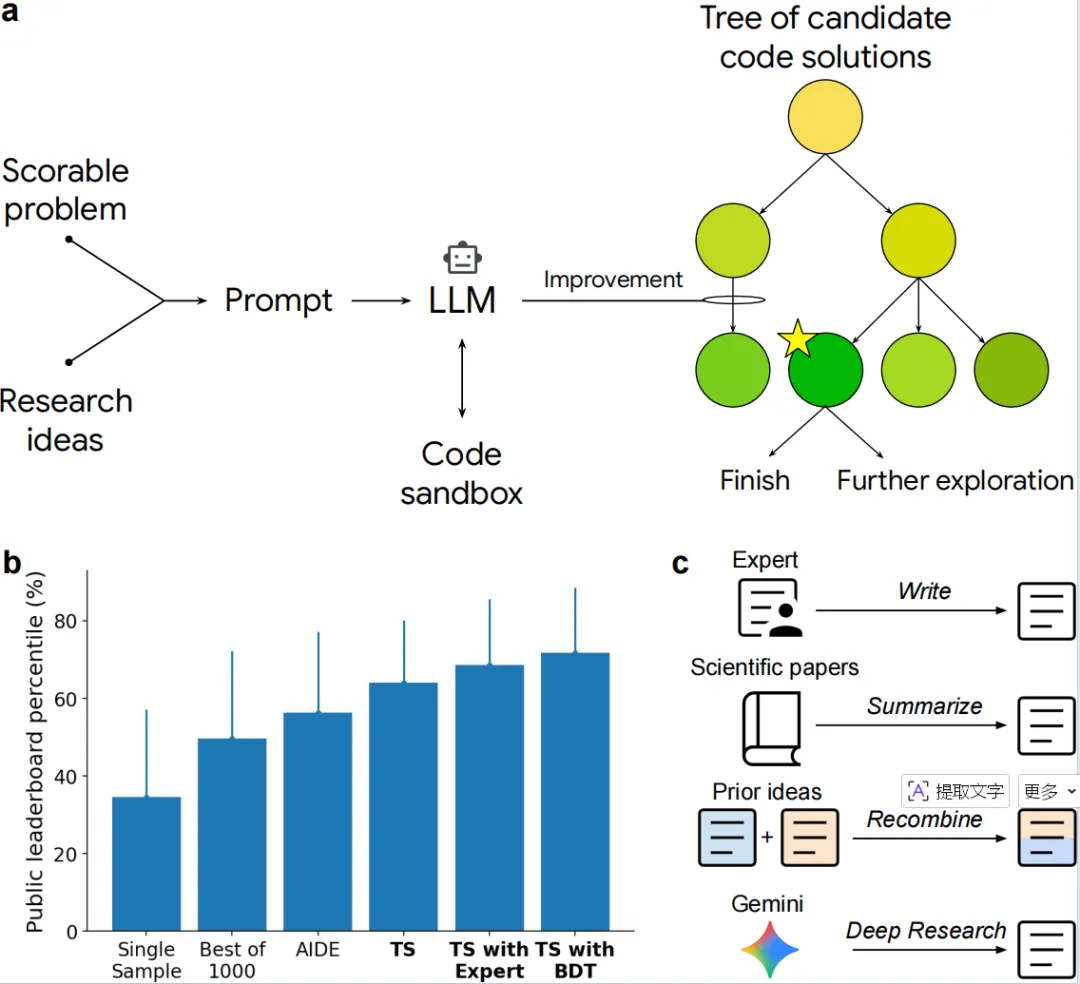
Figure 2ERA在单细胞RNA测序(scRNA-seq)数据批次整合这一生物信息学难题上的应用与成果。
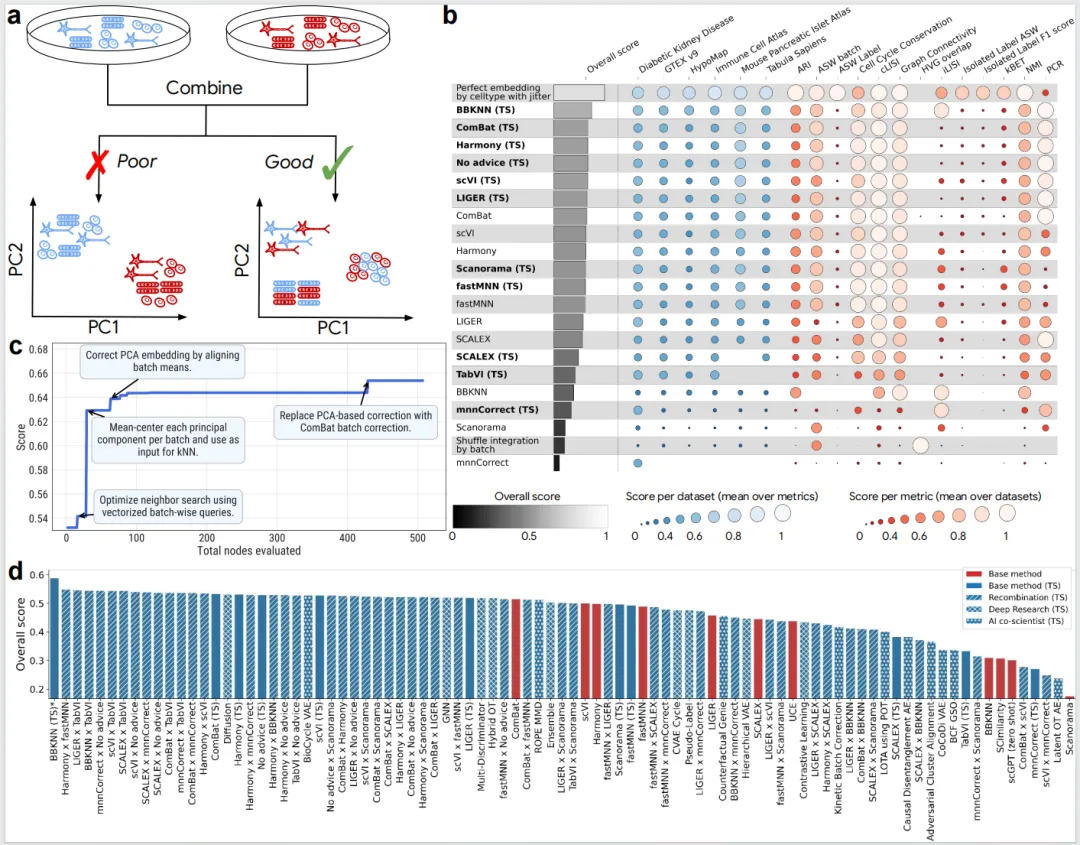
图a用示意图说明了批次整合任务的目标。图中展示了来自不同“批次”(分别以青色和红色圆点表示)的单细胞数据,这些数据由于实验条件等非生物学因素(批次效应)而存在分离。批次整合的目标是应用计算方法(由ERA生成的代码实现),将这些数据映射到一个新的低维嵌入空间(右侧“整合后的嵌入”),使得源自相同细胞类型(以不同形状表示)的细胞能混合在一起,同时保持不同细胞类型之间的生物学差异。
图b展示了ERA复现并优化现有方法的效果。该图为OpenProblems v2.0.0基准测试结果的热图。每行代表一个方法,包括原始发表的方法(灰色背景)和ERA通过树搜索实现并优化的版本(以“ (TS)”后缀和粉色背景标识)。整体得分(Overall score)和各数据集(Datasets)、各指标(Metrics)的得分显示,对于9种被测试的方法,有8种的ERA实现版本性能超越了其原始版本。特别是BBKNN (TS),其整体得分不仅远高于原始BBKNN,还超越了当时榜单上所有非控制方法,成为新的最优解。这表明ERA不仅能忠实复现算法思想,还能在实现细节上进行优化,带来显著性能提升。
图c剖析了最优方法BBKNN (TS)的具体创新点。图中展示了树搜索过程中,随着节点(尝试)编号增加,模型性能(Overall score)发生阶跃式提升的关键节点。节点429被特别标注,其描述为“使用ComBat校正的PCA嵌入进行BBKNN”。该图揭示,BBKNN (TS)的成功并非简单地复现BBKNN算法,而是在其基础上,创造性地将ComBat(一种基于经验贝叶斯的批次校正方法)预处理步骤与BBKNN相结合,先利用ComBat消除全局线性批次差异,再通过BBKNN处理局部非线性批次效应,从而实现了“1+1>2”的效果。
图d汇总了ERA通过不同方式生成的所有方法的整体得分分布。横坐标为不同类别:基础方法(Base)、方法重组(Recombination)、深度研究(Deep Research)以及AI共同科学家(Co-scientist)。图中每条水平线代表一个具体的ERA生成方法。黑色虚线标示了当时OpenProblems官方非控制方法的最优性能阈值。结果显示,共有40个ERA生成的方法超越了该阈值,其中重组方法表现尤为突出,大量方法分布在右上角的高分区域。这有力地证明了ERA不仅能利用现有思想,更能通过概念层面的重组和融合,系统性地创造出超越当前知识边界的新型高性能方法。
Figure 3ERA在另一个高影响力领域——美国COVID-19住院人数预测——的应用与成就。
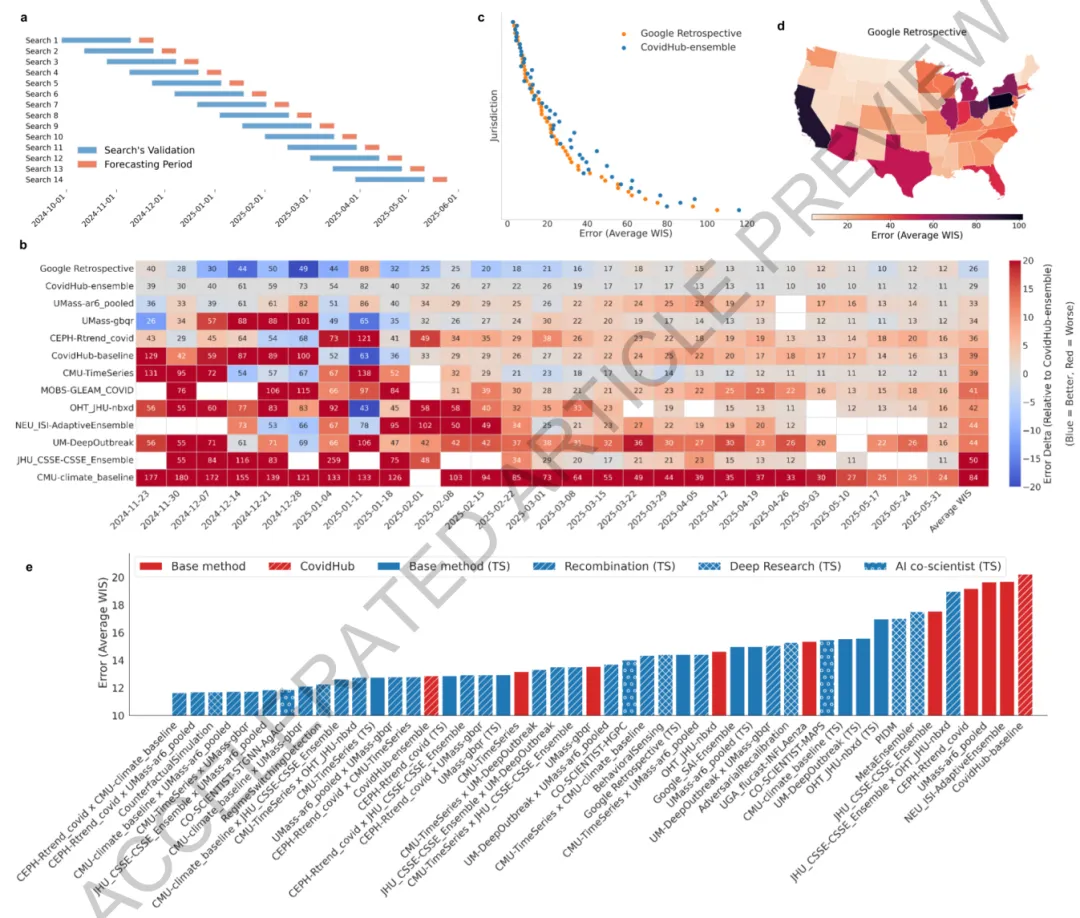
图a展示了该研究为回顾性预测实验设计的滚动验证窗口方案。横轴为时间线。每个独立的预测实验都使用预测期(橙色窗口,例如未来三周)之前的一段连续时间(蓝色窗口,例如六周)作为验证集。在蓝色窗口内,ERA运行树搜索,以加权区间分数(WIS,值越小预测越准)为目标,优化并选择最佳模型。随后,该选定的模型被用于预测紧邻的橙色窗口内的住院人数。通过在整个2024-2025流感季滑动这个“蓝色验证窗–橙色预测窗”对,该研究能够模拟真实世界的连续预测场景,并对模型进行严格的、时序一致的评估。
图b呈现了该研究提出的“Google Retrospective”模型与CovidHub集成模型及其他顶级团队在时间序列上的性能对比。表格的每一列代表一个预测周(参考日期),每一行代表一个预测模型,单元格内的数字是该模型当周的平均WIS(全美52个辖区及4个预测时窗的平均),颜色越蓝表示WIS越低(性能越好),越红表示性能越差。结果显示,在整个2024-2025流感季的多数周次,作者的“Google Retrospective”模型(位于表格底部)其单元格颜色普遍为蓝色,而官方集成的“CovidHub-ensemble”(位于表格顶部)单元格多为红色或白色。这表明ERA发现的模型在多数时间点的预测精度和校准度均优于官方的最强基准模型。
图c将聚合误差分解到地理辖区层面,直接比较了作者的模型与“CovidHub-ensemble”在整个季节的平均WIS。每个点代表美国的一个州或地区,落在对角线左下方(蓝色区域)的点表示作者的模型性能更优。结果显示,绝大多数点位于对角线下方,这量化了作者的模型在全美52个辖区中,于大部分地区都取得了更低的预测误差,优势具有地理上的广泛性。
图d以美国地图的形式可视化了作者模型在整个季节的平均WIS表现。颜色越浅(黄色)表示平均WIS越低,即预测性能越好。地图显示,除了少数几个州(如深蓝色的佛罗里达州)外,作者模型在全美大部分地区均取得了良好的预测效果(浅色区域),直观地展示了其预测能力的泛化性和稳定性。
图e比较了通过不同策略生成模型的预测性能。横轴为平均WIS,纵轴为不同的建模策略类别,包括基线(如CovidHub集成模型)、ERA复现的已提交模型(Replication)、ERA重组模型(Recombination)、以及通过深度研究和AI共同科学家生成思想后由ERA实现的模型。每个点代表一个具体的模型。图中明确标注了有14个ERA生成的模型(主要来自重组类别)性能超越了官方“CovidHub-ensemble”(以黑色垂直线标示)。这表明,对于复杂的流行病预测任务,ERA通过系统性地重组不同建模思想(如将流行病学机理模型与纯统计时间序列模型结合),能够有效地创造出超越当前最优实践的新颖预测策略。
结论
该研究开发的ERA系统,成功地将大型语言模型与树搜索算法相结合,为自动化创建科学实证软件提供了一个强大且通用的框架。在涵盖生物信息学、公共卫生、时间序列分析、地理空间分析、神经科学及数值计算等多个截然不同的领域基准测试中,ERA均展现了达到或超越人类专家水平的性能。其核心优势在于:高效的树搜索机制能够避免陷入局部最优,并实现对广阔代码空间的系统探索;同时,系统具备灵活整合多层次外部知识的能力,能够从文献摘要、方法重组乃至AI生成思想中汲取灵感,从而创造出超越现有方法的新颖解决方案。该研究证明了,将科学软件开发形式化为一个可搜索的优化问题,并由具备代码生成与理解能力的LLM驱动,能够极大地加速“试错”过程,将数月的探索周期缩短至数天。尽管在自动化复杂工程流程的同时也带来了潜在的双重用途风险,但ERA无疑代表了向“AI驱动科学发现”迈出的重要一步,预示着在那些可由机器评分的科学领域,研究进程将迎来显著加速。
论文信息:
Aygün, E., Belyaeva, A., Comanici, G.et al.An AI system to help scientists write expert-level empirical software.
Nature (2026). https://doi.org/10.1038/s41586-026-10658-6
声明:本推文用于学术分享,如涉及侵权或不合适的说明,请联系小编删除。
