 夜雨聆风
夜雨聆风





未来公司的文档,都应该变成可编辑、可检索、可调用的 HTML

公司每天都会产生很多文档。
制度、流程、会议纪要、项目资料、质量报告、培训课件、表格、图片、扫描件,最后大多以附件的形式留在系统里。
附件当然有价值。它保留了原始文件,也方便下载和归档。但如果企业知识长期停在附件状态,员工使用起来还是很累:要找到文件,下载文件,打开文件,在几十页里翻内容,再把有用的部分复制出来。
很多时候,文件已经上传了,知识还没有真正进入系统。
我们接下来要解决的,就是这件事。
上传之后,文档要先变成可用内容
未来无论从企业微信上传,还是从网页端、移动端上传,系统都应该先做一件基础工作:把文档解析成一份结构化的 HTML 内容。
这里说的 HTML,重点不在技术格式。它要解决的是:一份文档进入系统后,能直接阅读、局部编辑、检索和调用。
Word、PDF、PPT、Excel、图片扫描件,原始文件可以继续保留。但员工日常使用时,不应该每次都回到附件里翻找。系统应该把其中的标题、段落、表格、图片和关键结构提取出来,形成一份统一内容。
这样,文档才开始变成公司知识的一部分。
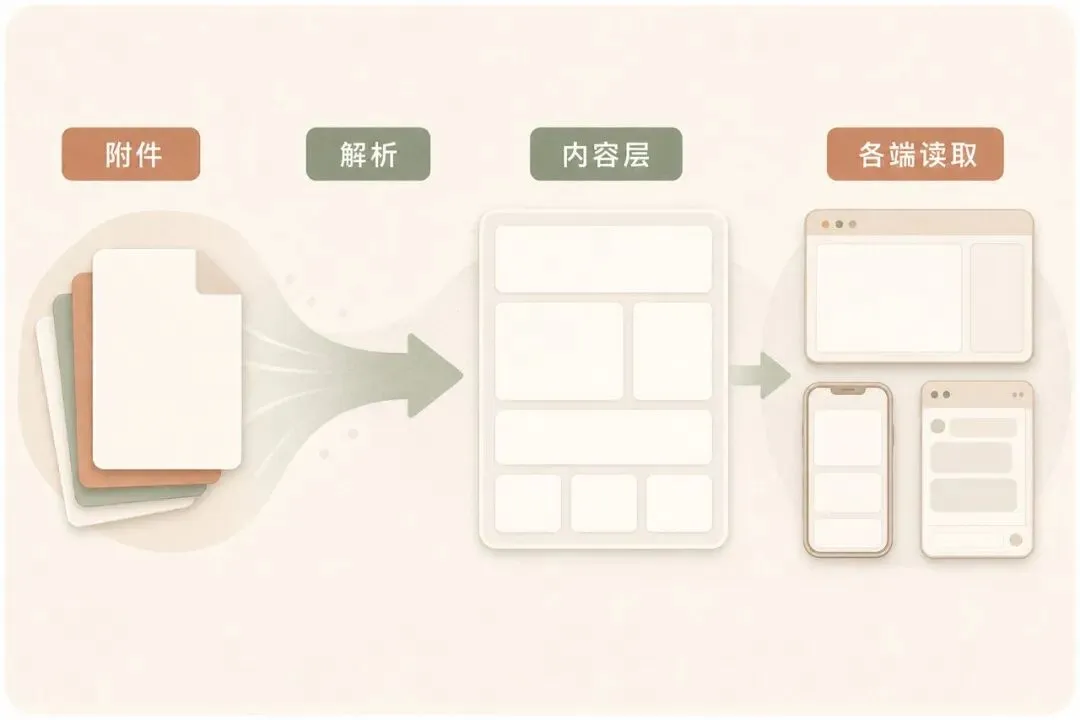
不同入口,看到同一份内容
以后公司会有多个使用入口。
员工可能在企业微信里问,也可能在网页端打开资料,未来也可能在 iOS 端查看、批注和编辑。
这些入口不应该各存一份内容。更好的方式是:后台只有一份统一的 HTML 内容,不同端只是根据场景展示它、编辑它、调用它。
•企业微信适合快速问答和临时查看。
•网页端适合完整阅读、编辑和整理。
•移动端适合现场查看、拍照补充和轻量确认。
•Agent 适合检索、摘要、问答、拆解任务和生成 Wiki。
入口可以不同,内容底座应该一致。
这会减少很多重复整理。今天在企业微信里问到的依据,明天在网页端打开,仍然能看到同一段原文;项目现场补充的说明,后续 Agent 检索时也能用到。
人要能改,Agent 也要能查
企业文档进入系统以后,不能只靠自动解析。
自动解析负责把文件变成初始内容,人负责校正和确认。比如标题有没有识别错,表格有没有断行,适用范围有没有写清,责任部门和更新时间是否需要补充。
这一步很重要。因为企业知识最终要被人使用,也要承担管理责任。系统可以帮忙整理,但关键口径仍然需要业务人员确认。
等内容被校正以后,Agent 才能更稳地工作。
它可以基于这份内容回答问题,也可以提取摘要,生成 FAQ,拆出流程步骤,整理成 Wiki 页面,或者在项目推进时调取相关制度和历史资料。
如果底层仍然是一堆附件,Agent 每次都要临时解析、临时判断,结果就不稳定。内容层稳定下来以后,检索、问答、编辑和复用才有基础。

文档会从“存放对象”变成“工作对象”
以前我们问得最多的是:这个文件在哪里?
以后更常见的问题会变成:
•这个制度适用于哪些部门?
•这个流程需要准备哪些材料?
•这份会议纪要里,谁负责下一步?
•这个项目资料里,有哪些未关闭问题?
•这份质量报告的原因、措施和验证结果分别是什么?
当文档变成统一内容后,员工不一定要完整打开原文件,也能先得到可追溯的答案。需要进一步确认时,再回到原文和原始附件。
这不是为了减少人工判断。恰恰相反,它是为了让人工判断有依据,让每一次查询、编辑和复盘都能回到具体来源。
第一版要把基础做扎实
这件事听起来很大,但第一版不需要追求复杂。
先把几个基础能力做稳:
•上传文件后,能生成结构清楚的 HTML 内容。
•标题、段落、表格、图片的位置尽量保留。
•HTML 内容可以在网页端编辑,并保留修改记录。
•企业微信、网页端、移动端读取同一份内容。
•Agent 回答问题时,可以引用对应来源。
•不同权限的人,只能看到自己有权查看的内容。
这些基础能力比界面花哨更重要。企业知识系统最怕的是看起来内容很多,真正用的时候找不到、改不了、追不回来源。
这是公司知识管理的底座工程
未来公司积累的知识,不会只来自正式制度。
一次会议、一次客户投诉、一次项目复盘、一张现场照片、一份 Excel 表格,都可能成为后面工作的依据。
关键是它们进入系统以后,能不能被整理成稳定内容,能不能被人继续修正,能不能被不同端读取,能不能被 Agent 检索和调用。
这就是把文档统一解析为 HTML 的意义。
它要做的事,是让公司每天产生的资料逐步变成可用的知识。资料进入系统后,人能看,人能改,Agent 能查,后续工作能接着用。
这一步做扎实,企业知识才会从“存过”走向“用得起来”。