 夜雨聆风
夜雨聆风





一、撰写产品需求文档PRD——用工程思想、产品思维重构AI软件开发
——以”个人私有知识库AI管理系统”为例
hi,屏幕前的朋友,你好呀,这里是锦。
距离上一篇文章发布已经过去了一个月,直到现在才发专栏的第二篇文章。更新如此之慢的原因主要有二,一是处理学校和公司的事情,二是为了写好这个专栏,除了打磨文章本身的组织安排,我还去恶补了很多相关知识,实在是希望能够写好公众号的处女作专栏。
目前由于学校和公司的事务尚未完结,所以我仍然是在挤时间出来写文章,这样缓慢的更新频率应该一直为持续到6月底,在这里对那些等待更新的朋友说声抱歉~
废话不再多说,马上进入正文吧。本文将近20000字,适合慢慢阅读,或者简单扫读。

用AI进行软件产品的开发,非常忌讳的就是上来给一段简单文字作为Promt,抛给Agent工具(Claude Code或者Codex等)来写代码。暂且先不谈CLAUDE.md,spec.md、rules这些规则性约束的缺席,就只说大部分人给的那一段文字,其中有关软件产品本身的信息量都是严重缺失的——对软件产品定义的缺失,却又想当即立刻开始开发,怎么办?AI只能开始猜测。
这里的猜测,包含系统架构、技术选型、性能环境、测试计划,目前的AI,没有办法在一次对话就把整套流程一次跑通且不出问题,如果开发者仍然不在接下来的任务安排中,将自己心中的需求和业务、产品原型和规则约束说明白,AI只能继续猜测,屎山代码会堆得越来越高。最后做出来的软件产品,尽管可以正常跑通,但其中的时间和Token预算花费早已超出预期,更糟糕的是,最终产品的模样和自己预期相差甚远。
问题的根源常常是,最开始的计划没做好、没做详细。在软件工程和产品研发中,这里说的计划会写在一份文档里写的非常详细——即产品需求文档(Product Requirement Document,PRD)。PRD写得好,需求明晰了,常常产品也就成功了四分之一。

千万不要小看文档,如今AI coding如此强,你马上就会明白”文档第一”的重要性。
本篇文章,就是在利用我所学到的知识,尽力为大家讲讲PRD是怎么写的。当然,如果纯粹讲理论,既脱离了AI编程的背景,对于读者来说也完全没那个必要。因此我打算用一个软件产品范例,来说说PRD的写法。
也许会有朋友说:我给一句话,PRD也让AI来写不就好了吗。我的想法是,你可以结合AI,但PRD的更多内容必须交由你自己来写,这是逐步明晰业务需求的重要过程,只有你自己知道你想要的究竟是什么。
本文是在借一个案例,来讲讲PRD的书写要点(或者,只是一篇为了便于阅读的简化后的PRD),并不是在写真正的PRD。真正的PRD,是事无巨细的、是非常具有专业性质的,远不止本篇公众号的两万字。但是,为了方便大家更好地学习,我还是在文章末尾给大家提供了关于”个人私有知识库AI管理系统”的PRD,以及相关的审阅报告,还有其他PRD范例。
本文思维导图
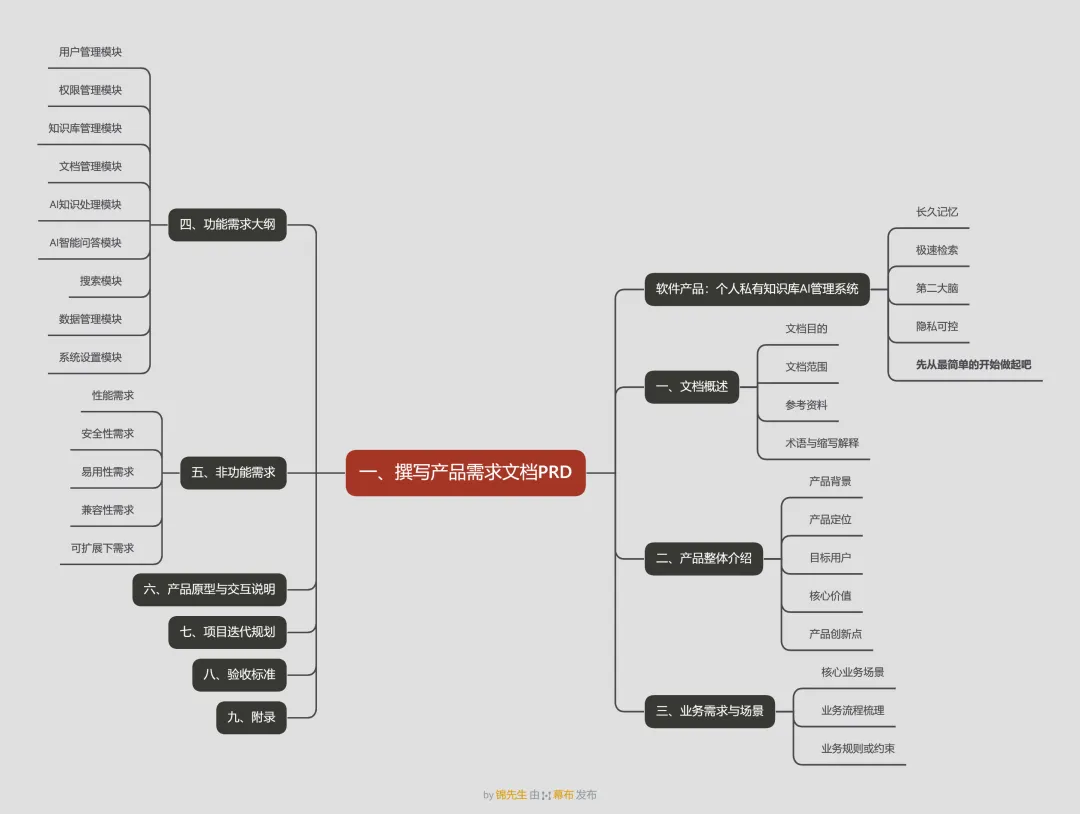
|
接下来,你可能还是会在本文看到许多之前没听说过的名词,不用担心,我会紧接着做一些知识补充。这些名词不少都是专业化的用语,还有技术名词,作为产品经理,最好还是能够了解一点,不需要理解原理,只需要知道作用是什么。或者,你也可以暂时放着不管,一些概念我们后面还是会提到,你用着用着也就理解了。 |
软件产品:个人私有知识库AI管理系统
我们从一个当今比较流行的软件产品开始吧。
我们要做的是一款”个人私有知识库AI管理系统”。名字有点长,拆开来看就四个关键词——个人、私有、知识库、AI。
过去几年,我积攒的笔记都散落在Notion、Obsidian、飞书文档、浏览器收藏夹、微信”文件传输助手”里。某天遇突然被问到:”你去年参赛时弄的资源列表和备赛策略还有吗?”我打开四个软件翻了十五分钟,最后是凭着聊天记录里的关键词搜索才勉强找到。那一刻我意识到:存了不等于记住了,记住了不等于找得到。
所以这个产品的目标就一句话:让你存下来的东西,未来真的能用上。
长久记忆
人的记忆衰减曲线是残酷的。艾宾浩斯遗忘曲线告诉我们,学完一个东西20分钟后就会忘记42%,一天后忘记67%。[1]
知识库要充当的,就是一个不会遗忘的外部大脑。你扔进去的每篇文档、每条笔记、每个网页剪藏,系统都能”记住”——不是记个标题那种记住,而是理解内容含义之后的记住。哪怕你半年后只记得”好像有个什么文档提到过微服务的容错设计”,输入这句大白话,系统能帮你定位到原文。
极速检索
“极速”不是一个虚词,必须量化。我们的标准是:搜索结果首屏加载不超过800毫秒,语义搜索不超过1.5秒。这跟普通全文搜索的区别在哪?关键词搜索是你记得这个关键词,所以要搜这个关键词;语义搜索是你不记得任何关键词,但你记得”那个讲人为什么会忘记东西的理论”,输入这句话,系统能帮你找到艾宾浩斯遗忘曲线的相关文档。
背后依赖的是向量化(embedding)技术——把文本转成一串数字向量,语义相近的文本在向量空间里距离就相近。这不是魔法,但在体验上确实很像魔法。
|
什么是向量化?在AI领域当中,向量是将文本、图像等非结构化数据转化为计算机可理解的固定长度数字列表(数组),而向量化则是通过模型将这些原始数据转换为上述数字列表的过程。 |
第二大脑
这个概念最早由Tiago Forte在《Building a Second Brain》中系统化地提出[2],核心思想是:人脑应该用来思考,而不是用来记忆。

我们设计这个产品时反复强调一点:知识库不是电子化垃圾桶,什么都往里扔就完事了;它应该是一个能跟你对话的工具。你问它”我之前研究过的那个微服务拆分原则是什么”,它能告诉你要点、出处、甚至当时你写下的备注。这种交互模式下,知识库才真正开始有”脑”的感觉。
这被很多人,称作知识的复利。
隐私可控
这一点几乎不用论证:谁都不想把自己所有的工作笔记、项目文档、学习心得传到某个云服务商那里。企业用户尤其敏感——内部技术方案、竞品分析、财报预测,这些都是泄露了就得出大事的信息。
我们的方案是:默认本地部署。数据存储在你自己的设备上,向量化和搜索都在本地完成。如果你选择使用云端AI服务(比如调用ChatGPT来做问答生成),系统只发送最小必要的检索片段,不传输完整文档,并且在设置页面明确告知用户”以下数据将被发送至外部服务”。不敢说绝对安全,但在透明度和可控性上,这是我们能做到的最优解。
先从最简单的开始做起吧
别一上来就想做一个Notion/Obsidian + ChatGPT + 飞书文档的缝合怪,就算是宇宙级大厂,也不会马上就想完成一个大目标。
Fred Brooks在《人月神话》里专门用了一章讲”第二系统效应”:设计师在做第二个系统时,最容易犯的错误就是把第一个系统里所有没实现的想法都塞进去,导致系统臃肿不堪。[3] 他的原话是:”第二系统是一个人设计过的最危险的系统……普遍倾向是过度设计。”

所以这个产品的MVP,功能列表短得可怜:支持Markdown和PDF导入、基础文档管理、语义搜索、AI单轮问答。没有多人协作,没有权限管理,没有移动端,没有插件系统。先把”存下来、找得到、问得出”这三个核心走通,再谈扩展和改良。
这既是为了让产品研发一步一个脚印慢慢进行,也是在给开发人员和产品经理(我知道,在我们的专栏里,这都是你一个人)提供自信心——毕竟看到写出来的东西能跑,自己还是开心的。
|
为了照顾公众号的运营,本专栏做的主要是MVP,后续的功能扩展会在番外的文章、或者以贴图的形式发表,当然,也欢迎你来和我交流。 |
一、文档概述
文档目的
说明白这份PRD服务于跨职能团队——产品、设计、开发、测试——让他们对”要做什么”有一致的理解。
一个容易被忽视的事实是:PRD不只是写给开发看的。设计师要通过PRD理解交互逻辑,测试要通过PRD编写验收用例,运营(如果有)要通过PRD准备推广素材。一份好的PRD让所有人都少开会、少吵架、少返工。我们常调侃的”需求理解偏差”,说到底就是PRD没写清楚。
苏杰在《人人都是产品经理2.0》里反复强调一个观点:需求分析优先于方案设计。[4] PRD的核心价值不是列出功能清单,而是把”为什么做这个”讲清楚。功能清单谁都会列,Excel一行行打出来就是了;但讲清楚背后的用户场景、业务逻辑和取舍依据,才是产品经理真正应该花时间的部分。

文档范围
本文档覆盖”个人私有知识库AI管理系统”的MVP版本(V1.0)完整需求,包括功能需求、非功能需求、交互说明、迭代规划和验收标准。
明确排除在V1.0范围之外的内容:
-
多用户协作与权限管理(规划在V2.0) -
移动端应用(规划在V3.0) -
浏览器插件/网页剪藏(规划在V1.5) -
第三方服务集成(如飞书、钉钉、企业微信等) -
开放API
把这些”不做什么”提前写清楚,比写”要做什么”可能还重要。因为在实际开发中,经常有人冒出一句”诶,顺手加个XX功能也不难吧?”PRD就是挡这种需求的盾牌。
参考资料
文档编写过程中主要参考了以下资料:
方法论类:
Frederick P. Brooks,《人月神话》(The Mythical Man-Month), 1975/1995周年纪念版——在概念完整性、第二系统效应、没有银弹等章节的框架下理解PRD的定位与价值。[3]
苏杰,《人人都是产品经理2.0》, 电子工业出版社——用户场景分析、需求优先级排序等产品方法论。[4]
IEEE 830-1998 / ISO/IEC/IEEE 29148:2011 软件需求规格说明标准——PRD结构设计和需求质量评估参考。[5]
技术类:
Lewis, P. et al., “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”, NeurIPS 2020——RAG技术的原始论文。[6]
LangChain / LlamaIndex 官方文档——RAG管道的最佳实践参考。
BAAI BGE系列嵌入模型文档(BAAI/bge-large-zh-v1.5)——中文语义向量化技术选型依据。[7]
Ollama / llama.cpp 项目文档——本地LLM部署方案参考。
竞品参考:
Notion AI、Obsidian(含社区AI插件)、Dify、FastGPT、AnythingLLM——功能设计和交互模式参考。
术语与缩写解释
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
二、产品整体介绍
产品背景
|
PRD要说明,产品因为什么才出现,是为了应对哪些场景,这些话对客户最有用。 |
信息过载不是一个新鲜话题,但AI时代的来临彻底改变了局面。
以前我们的烦恼是”找不到信息”,现在变成了”信息太多,需要的时候还是找不到”。各种笔记工具帮我们解决了”存”的问题——Notion、Obsidian、飞书、语雀、OneNote,任何一款都能让你轻松囤积上千条笔记。但”存”和”用”之间有一条巨大的鸿沟。你需要的时候要么记不得存在哪个文件夹了,要么记得文件夹但找不到具体内容,要么找到了内容却发现笔记记得太潦草完全没有上下文。
大语言模型的语义理解能力,恰好能填上这条鸿沟。它不需要你记住关键词,不需要你记得文件命名规则,不需要你维护完美的文件夹层级——你只需要用自然语言提问。
当然,如果只是根据模糊条件搜索文件的话,本产品似乎还是没有太多去做的必要。本产品的目标还在于,以自己积累的知识为原料,能够用AI大模型做驱动,培养出一个有自己行事风格的知识管理助手。
这就是做这个产品最根本的动因。
产品定位
|
PRD要明确软件产品的设计方向,这个时代,选择比努力重要。方向错了,对于公司或团队来说,后面花的钱和精力,都是打水漂。对于个人来说,这一点也最好看看,在将来需要的时候避免自己重复造轮子。 |
“个人私有知识库AI管理系统”定位为:面向个人用户的、本地优先的、AI原生的知识管理工具。
有三个关键限定词。第一,”面向个人用户”——不跟Notion抢团队协作市场,不跟飞书抢企业知识管理市场。第二,”本地优先”——数据主权归用户,离线可用,云端功能是可选的增强项不是必选项。第三,”AI原生”——不是传统笔记加一个AI按钮,而是从底层设计开始就把AI理解作为核心交互方式。
目标用户
|
对于公司来说,你需要考虑人群的需要,把这些人群描述写在PRD里。找准了产品定位和受众,就更能捕捉到细致的需求,产品的营销就有可能更加顺利。 当然,如果你只是做个软件自己玩玩,那这一节就可以不写。 |
我们的目标用户画像:
知识型工作者:程序员、产品经理、咨询师、研究者、学生、写作者。共性特征是对知识沉淀有高频需求,经常需要回顾过往的工作成果和学习记录,对检索效率敏感,对隐私有一定要求。
他们对现有工具的典型吐槽:
-
“存了几百条笔记,想找的时候一条都翻不出来” -
“关键词搜索太蠢了,必须记住原文用了什么词才能搜到” -
“不敢把工作文档传到云端笔记,万一泄露了就完了” -
“AI功能是好,但我不想把自己的数据库喂给别人的模型”
我个人最偏爱第三个吐槽——在一次用户访谈中,听一位做投行的前辈说:”我的笔记里可能有未公开的财务数据,别说上传云端,我连公司Wi-Fi都不敢连。”当然这是极端案例,但”数据应该在自己手里”的确是很多用户的底线。
核心价值
|
PRD要说明产品最核心的价值,对客户最直接的好处。 |
用一句话概括:让每一份沉淀过的知识,在你需要的时候都能被找到、被理解、被应用。
拆成三个层面看:
做一个记忆外包:大脑不再需要记住零散信息的存放位置,知识库就是你的外部记忆体。Brooks在《人月神话》中谈到,软件工程的核心困难不在于实现,而在于精确地描述需求本身——这正是”本质复杂性”。[3] 知识管理同理:困难的不是去做代码实现,而是知道记录了什么、怎么在需要时拿出来。
检索增效,查得更快:从关键词匹配进化到语义理解。你不需要回忆”那篇文档的标题里有个’架构’两个字”,你只需要问”之前有个文档讲微服务怎么拆的,还提到了DDD的那篇”——模糊的描述,精确的结果。
|
微服务和DDD都是软件架构,或者说两种模型,目前知道这个就足够了。 |
知识复用:沉淀的知识真正参与你的日常决策和创作。读到一篇好文章,做一个笔记,三个月后做方案时AI帮你把相关笔记调出来,还附上了带有你自己思考风格的概述或意见——这个闭环走通了,知识库才算有了”脑”的功能。
产品范例/产品创新点
|
对于初学者,很难说会有什么创新,为了学习,我们可以找一个市面上成熟的产品,以它为原型,写我们的PRD。 产品如果能有创新点,那就尽可能罗列一些。自然,这些话也是对客户说的,都是过场话。如果你只是做一个自己用的软件,这里当然可以不用写,自己清楚就足够了。 |
产品范例
可以看看Notion,Obsidian,语雀,飞书。这些都是非常典型个人笔记软件+AI来实现个人知识库AI管理系统。
屏幕前的读者可以尝试用一段时间,再来接着往下看即将要说明的业务需求怎么捋、功能模块怎么定义,这样可能才会体会地更深刻。
产品创新点
我们就从上面谈到的范例出发,来看看我们要做的软件产品可以有哪些创新。市场上知识管理工具很多,为什么还要做一个?
坦白说,大部分现有方案的思路是”在传统笔记上加AI”。Notion AI在编辑框里加了一个”Ask AI”按钮而且Notion调用的模型也只能是自家的云端大模型;Obsidian靠社区插件(比如Claudian)拼出一个AI功能,语雀的AI助手可以帮你总结文档——但本质上,这些产品大多都是在原来已经成熟的笔记软件基础上附加上了AI,底层架构仍然是为”人手动浏览和检索”设计的。
我们的做法不同:从设计之初就假设用户会通过AI来访问知识,而不是手动翻文件夹。这意味着:
-
搜索框是主界面入口,不是藏在菜单里的辅助功能 -
文件夹分类是可选的组织方式,不是唯一的依赖 -
AI不是功能列表里的一个”加分项”,而是贯穿整个产品的基础设施
隐私策略也是一个差异化点。”默认本地部署”这个决策在技术上限制了很多能力(比如跨设备同步变得复杂,移动端访问需要额外设计),但在隐私诉求上是一个明确的信号:用户的数据首先是用户自己的,其次才是可以被AI处理的。
三、业务需求与场景
核心业务场景
|
只有当你做了足够的调研,你才更清楚自己想要什么、客户需要什么,如果产品面向客户,这些调研出的业务场景,你也要写到PRD里。 |
苏杰在《人人都是产品经理2.0》中强调先有场景,再有功能[4]。功能列表要围绕用户真实的工作流展开,而不是为了”功能完整性”去凑数。
先看三个典型场景。
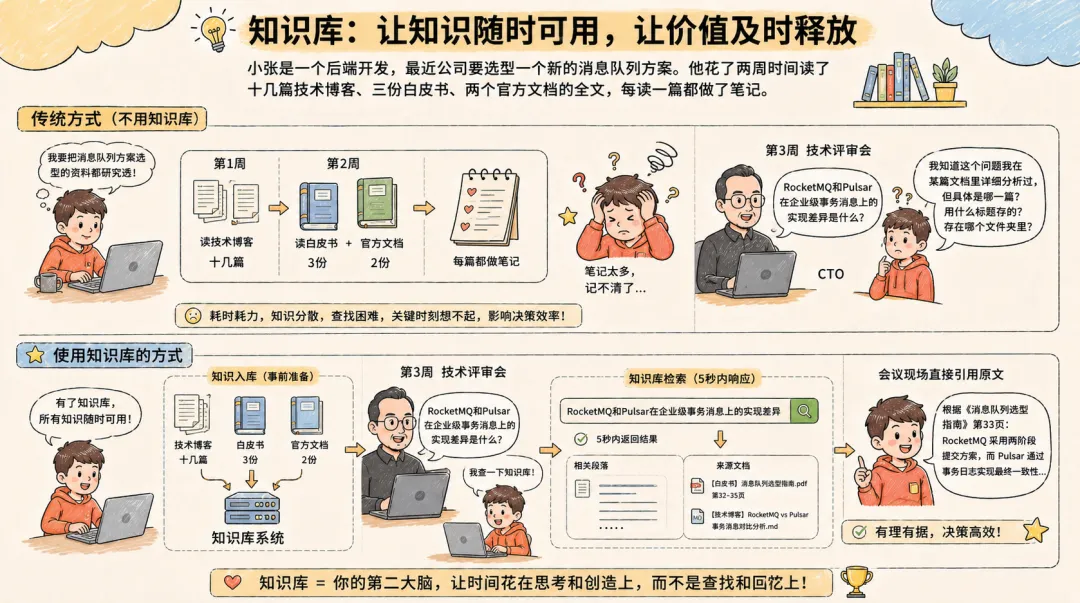
场景一:程序员的”技术调研噩梦”
小张是一个后端开发,最近公司要选型一个新的消息队列方案。他花了两周时间读了十几篇技术博客、三份白皮书、两个官方文档的全文,每读一篇都做了笔记。三周后技术评审会上,CTO问:”RocketMQ和Pulsar在企业级事务消息上的实现差异是什么?”小张知道这个问题他在某篇文档里详细分析过,但具体是哪一篇?用什么标题存的?存在哪个文件夹里?
用知识库的话,他的操作是:在搜索框输入”RocketMQ和Pulsar在企业级事务消息上的实现差异”,系统在5秒内返回相关段落,并标注来源文档。他可以直接在会议现场引用原文。
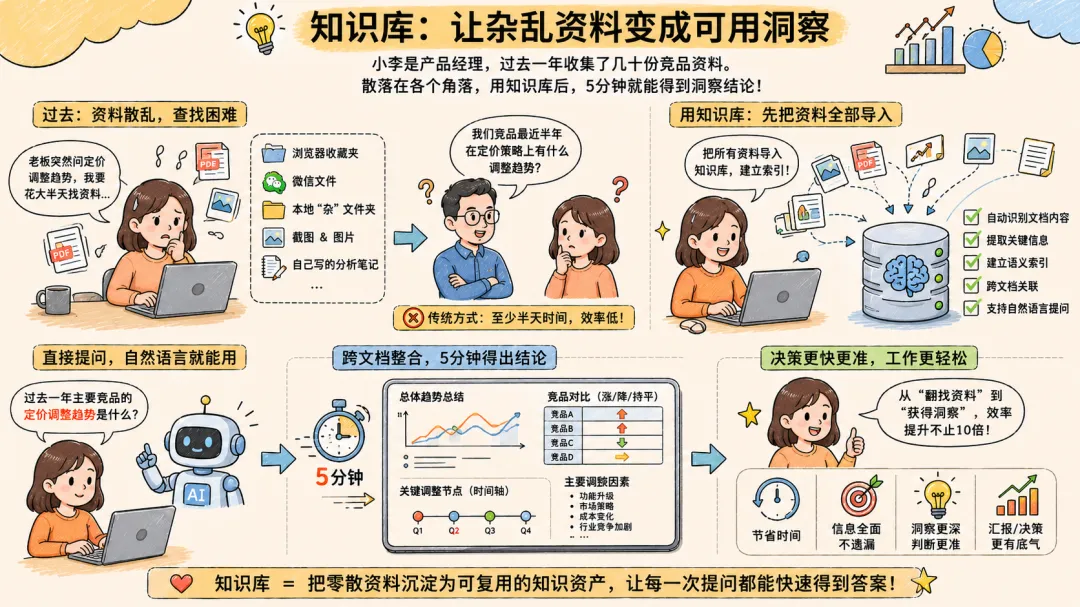
场景二:产品经理的”竞品调研碎片化”
小李是产品经理,过去一年陆陆续续收集了几十份竞品资料——行业报告PDF、产品截图、用户评价截图、自己写的分析笔记。这些资料散布在浏览器收藏夹、微信文件、本地”杂”文件夹里。某天老板问:”我们竞品最近半年在定价策略上有什么调整趋势?”
用传统方式,她得花半天时间翻遍各个角落。用知识库,她导入所有资料后,直接问”过去一年主要竞品的定价调整趋势”,系统跨文档整合信息,五分钟内给出概要。
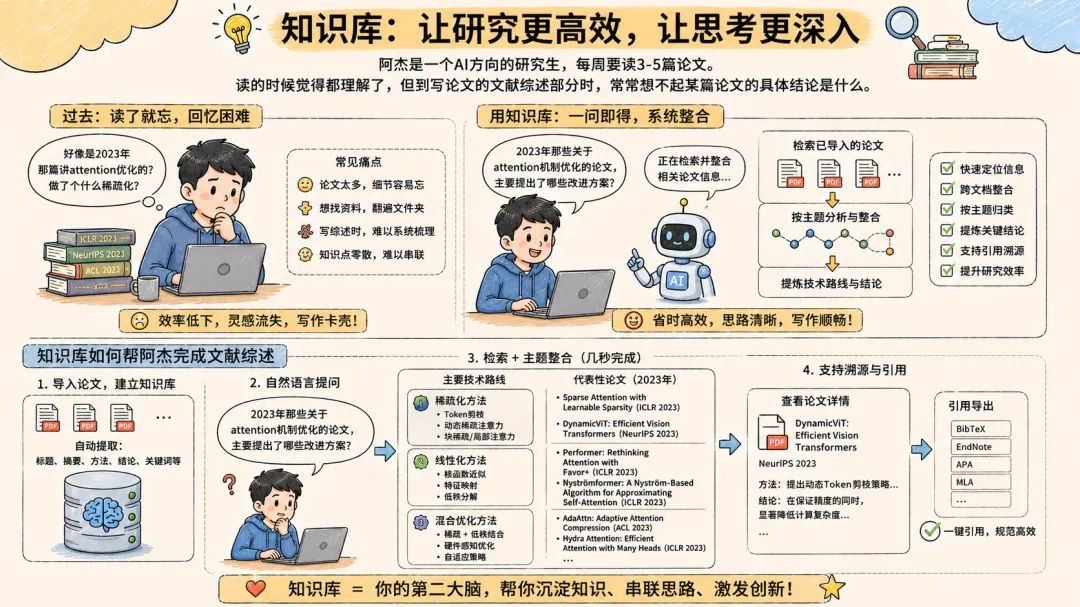
场景三:研究生的”文献阅读黑洞”
阿杰是一个AI方向的研究生,每周要读3-5篇论文。读的时候觉得都理解了,但到写论文的文献综述部分时,常常想不起某篇论文的具体结论是什么。”好像是2023年那篇讲attention优化的?做了个什么稀疏化?”
用知识库,他问:”2023年那些关于attention机制优化的论文,主要提出了哪些改进方案?”系统检索所有已导入的论文,按主题整合出几种技术路线和代表性论文。
这三个场景有一个共性:用户知道自己”有过某个信息”,但无法精准定位。传统搜索失效的原因是”用户已经不记得用什么关键词能搜到”,而语义搜索恰好解决了这个问题。
业务流程梳理
核心业务流程可以简化为四步:导入 → 处理 → 检索 → 应用。
导入:用户通过三种渠道把内容放入知识库——(1) 系统内新建文档,支持Markdown和富文本编辑;(2) 上传本地文件,支持PDF、Word、TXT、MD格式;(3) 手动粘贴内容(比如从网页上复制一篇文章)。
|
如果你还不会写Markdown,我很推荐你去学一学,他的写法非常简单。Markdown文档对大模型来说,阅读和书写都非常友好。 |
处理:系统在后台自动对文档内容进行向量化处理。过程对用户透明——文档拖进去,系统显示”处理中”,几秒到几十秒后(取决于文档大小)显示”已完成”。处理包括文本提取、分块、向量化、存储四个环节。
检索:用户通过两种方式获取信息——语义搜索(输入自然语言描述,返回相关文档列表及匹配片段)和AI问答(输入问题,系统基于知识库内容生成答案,并标注引用来源)。
应用:用户基于检索结果进行后续操作——查看原文、导出问答结果、基于搜索结果创建新笔记、将多个文档的相关内容整合为一份研究摘要等。
IEEE 830标准强调需求必须是可验证的。[5] 这意味着每个环节都需要有明确的成功标准。比如”导入”环节,”上传一个10MB的PDF文档,3分钟内完成向量化处理并显示在搜索结果中”就是一个可验证的需求。
业务规则或约束
|
PRD必须要定规则,不能让AI在之后的代码实现中随意发挥。我们会将这些规则约束,写成CLAUDE.md、rules、spec.md与Hook,如果可能,我们后面也会尝试上手Harness,时刻约束AI的行为。 |
MVP版本的核心约束:
文档格式支持范围:优先支持纯文本、Markdown、PDF、Word(.docx)、TXT。图片、视频、音频等多媒体内容暂不纳入——不是不重要,而是向量化多模态内容的复杂度远高于纯文本,需要先在文本层面把整个管道跑通。
知识库容量:单个知识库上限10GB(约5000-10000篇中等长度文档)。这是考虑到本地部署的硬件约束——你不可能指望一台8GB内存的笔记本处理百万级文档的向量检索。
数据备份:系统每24小时自动创建增量备份,保留最近7个备份点。支持手动导出完整知识库(包含原始文档+向量索引)用于迁移。
隐私边界:默认不使用任何云端AI服务。如果用户选择接入云端LLM(如OpenAI API),系统仅发送检索到的相关文本片段(最多k=5个片段),不发送完整文档。每次外部API调用前系统明确提示:”本次将发送约XXX字至外部服务,是否继续?”
四、功能需求大纲
在正式展开之前,有一句话值得先放在前面:Fred Brooks说过,概念完整性是系统设计中最重要的考量。”宁可缺失某些异常的特性和改进,体现一套完整统一的设计理念,也好过塞进许多好的但彼此独立且不协调的想法。”[3]

这个原则落实到我们的PRD上就是:每个模块的设计必须有清晰边界,功能之间不能互相矛盾,MVP版本要敢于”不做”某些功能,而不是什么都做一半,更不是什么都做。
|
对于一个软件产品,设计和开发的时候,大家广泛使用的方法是模块化。因此我们在PRD里,也可以逐个模块地来写。 我们将这些模块定义得越清晰,后续交由AI来做代码实现,就越是高效,越是可以接近心中所想,减少返工的次数。 |
用户管理模块
MVP版本做最小化处理。
理由是产品定位为”个人”知识库,不存在多用户体系。用户管理仅需支持单用户本地账号——或者说,干脆不需要账号系统。在本地部署模式下,可以用操作系统用户身份作为默认凭证,省去注册、登录、密码管理等一整套流程。
保留一个可选的远程访问密码设置:如果用户希望在同一Wi-Fi下从手机浏览器访问知识库,可以通过设置访问密码来保护连接。但这个功能属于”锦上添花”,MVP可以不实现——在迭代规划中放在V1.5。
权限管理模块
MVP版本不实现。
权限管理的前提是存在多用户体系。对于单用户产品来说,不存在”谁有权访问哪个文档”的问题。这个模块的详细设计规划在V2.0(团队协作版)中展开,届时将包含角色定义(管理员、编辑者、阅读者)、知识库级别的权限设置、文档级别的分享控制等。
在MVP的PRD里把这个模块写出来并标明”V1.0不实现”,至少有两个好处:一是让团队知道这个需求是被考虑过的,不是在画原型时才临时加的;二是给技术架构一个预警——数据模型和API设计要预留权限字段,别到时候重构。
知识库管理模块
用户需要能够创建和管理多个知识库。典型的用法是按项目/主题分:一个”工作-技术方案”知识库,一个”学习-AI论文”知识库,一个”生活-读书笔记”知识库。
核心功能:
-
创建、重命名、删除知识库 -
查看知识库基本信息(文档数量、存储空间、最后更新时间) -
最近访问的知识库快速入口 -
知识库级别的数据导出和备份
MVP不做文件夹层级结构。这个决定可能会有争议——”没有文件夹怎么组织文档?”答案是:依赖搜索和标签(V1.5引入)。在语义搜索足够强大时,文件夹层级的意义会大幅降低。Tiago Forte在《Building a Second Brain》里提出的PARA方法(Projects-Areas-Resources-Archives)也不依赖深层文件夹,而是用扁平结构和搜索结合。[2] MVP不做文件夹的另一个原因是:一旦用户习惯了文件夹组织,迁移到搜索驱动的使用习惯会更困难——这是一个行为设计问题,不只是功能问题。

文档管理模块
文档是知识库的基本单元。核心功能:
文档创建与编辑:支持在系统内新建文档,使用Markdown编辑器(MVP不做所见即所得的富文本编辑器,节省开发量)。Markdown在目标用户中接受度高——程序员几乎全部使用,产品经理中也越来越普及。
文件导入:拖拽或选择文件上传。支持PDF、Word(.docx)、TXT、MD四种格式。上传后自动提取文本内容(PDF需要文本层——扫描版PDF暂不支持,这是明确的能力边界)。
基本管理:文档列表查看(按时间排序,默认最新的在最前),文档删除(软删除,30天后自动清理),文档信息查看(创建时间、更新时间、文件大小、处理状态)。
不做版本历史。一个个人知识库产品不需要Git级别的版本管理——你改个笔记还要保留10个历史版本来回滚吗?不需要。这个判断可能有人不同意,但MVP就是做取舍。未来如果用户强烈需求,V1.5可以加。
AI知识处理模块
这是产品的技术核心,也是整个系统最复杂的部分。
当一个文档被导入后,系统自动执行以下处理管道:
第一步:文本提取。根据文件格式使用不同的解析器(PDF用PyPDF2或pdfplumber,Word用python-docx,MD/TXT直接读取)。输出纯文本内容。
第二步:分块(Chunking)。将长文档切分为适合检索的文本片段。分块策略的选取直接影响检索质量——分得太碎,上下文不够;分得太大,检索精度下降。
MVP采用递归字符分割策略(Recursive Character Text Splitting),分块大小默认512字符,相邻块之间重叠64字符(约12.5%)。分割优先顺序为:段落分隔符(\n\n)> 换行符(\n)> 句号(。)> 空格。这意味着系统会尽量在自然语义边界上切分,而不是粗暴地每512字符砍一刀。[8]
第三步:向量化。对每个文本片段调用嵌入模型,输出一个1024维(以BGE-large-zh-v1.5为例)的浮点数向量。这个向量的核心特性是:语义相近的文本,其向量在空间中也相近。
技术选型上,MVP使用BAAI/bge-large-zh-v1.5作为默认嵌入模型。这是BAAI(北京智源人工智能研究院)发布的中文嵌入模型,在C-MTEB中文基准评测中表现优异。[7] 在本地部署场景下,推理速度足够(普通CPU上每秒可处理约50个512字符片段),且支持通过ONNX加速。
第四步:存储。向量+元数据(文档标题、来源、时间戳、片段位置)+原始文本片段,一并存入向量数据库。
MVP使用Chroma作为默认向量数据库——轻量级、内嵌运行、零配置、Python原生支持。对于个人用户的文档规模(千到万级),Chroma完全够用。如果未来扩展到百万级文档,可以迁移到Milvus或Qdrant。架构上通过抽象数据访问接口来预留扩展空间。[8]
AI智能问答模块
基于RAG(Retrieval-Augmented Generation)技术实现对话式问答。Lewis等人在2020年NeurIPS上首次提出RAG框架[6],简单说就是把”搜索”和”生成”串起来:先从知识库里搜出相关内容,再把这些内容喂给大模型,让它基于这些资料来回答。
问答流程:
-
用户输入问题 -
系统将问题向量化 -
在向量数据库中检索Top-K个最相关的文本片段(默认K=5) -
将这些片段+用户问题组装为提示词(Prompt) -
发送给LLM生成回答 -
回答中标注引用来源(文档标题+相关片段)
我们当前MVP的”简陋”限制:
单轮问答,不支持多轮对话:问完一个问题,下一个问题不带上下文。这个限制的原因是多轮对话需要维护会话状态和上下文管理,比单轮复杂一个量级。先把单轮走通。
不做问题改写(Query Rewriting):用户问什么就用什么向量去搜。不考虑”用户问得太口语化了要不要改写一下”——那是优化的事。
不做流式输出:等LLM生成完整回答后一次性返回。流式输出的体验更好(逐字出现),但MVP阶段优先保证功能可用。
LLM接入:MVP默认使用Ollama本地部署的开源模型(如Qwen2.5-7B或Llama3-8B),不依赖外部API。[9] 这样就真正实现了”完全离线可用”的隐私承诺。同时保留接入外部API(如OpenAI、DeepSeek)的可选配置,让追求更好回答质量的用户自己选择。
|
这里说的”本地部署的开源模型”是指大多数人用自己电脑就可以跑的AI,而”ChatGPT/Gemini/Claude/DeepseekV4″等模型,想用的话基本上只能调用云端API,个人电脑是不可能跑得动的。 |
搜索模块
搜索是用户最高频的操作,两条技术路线并行:
语义搜索(主力):用自然语言查询,系统将查询向量化后在向量数据库中进行相似度匹配,返回Top-N个最相关的文档片段。这应该是用户的主要搜索方式。
关键词搜索(辅助):用传统的TF-IDF或BM25算法做全文检索。适用于用户明确记得某个专有名词或精确表述的场景——比如搜一个函数名、一个SQL表名、一个产品代号。
搜索结果页展示:文档标题、匹配片段的摘要(带高亮)、相关度评分、创建/修改时间、所属知识库。每页显示20条结果。
“极速检索”的具体指标:关键词搜索响应时间<500ms,语义搜索响应时间<1.5s(不含LLM生成时间),搜索结果Top-5至少3条相关(准确率≥60%)。这些数字需要验收阶段用1000+文档的知识库规模实际测试验证。
数据管理模块
处理知识的”进”和”出”。
数据导入:除单文档上传外,支持批量导入(选择一个文件夹,自动导入其中所有支持格式的文件)。
数据导出:支持单个文档导出(保留原始格式)、整个知识库导出(打包为ZIP,包含原始文档+元数据JSON)、搜索结果导出(将搜索结果列表导出为Markdown或TXT)。
备份与恢复:系统每24小时自动创建增量备份(存储在用户指定的备份目录),保留最近7个备份点。用户可在设置中调整备份频率和保留策略。支持从任意备份点恢复整个知识库,恢复后自动重建向量索引。
数据迁移:支持将知识库数据整体迁移到另一台设备——导出完整数据包,在新设备上导入。这个场景的典型用户是换了新电脑,需要把旧电脑上的知识库搬过来。
系统设置模块
提供个性化配置和系统管理:
通用设置:界面语言(中文/English)、主题(浅色/深色/跟随系统)、数据存储路径、备份路径。
AI设置:嵌入模型选择和配置(默认BGE-large-zh-v1.5,可切换)、LLM选择和配置(默认Ollama本地模型,可配置API endpoint和密钥)、检索参数(Top-K数量、相似度阈值)。
存储管理:查看各知识库的占用空间,清理临时文件和已删除文档,设置存储上限预警。
日志查看:系统运行日志、处理队列状态、错误报告。面向爱折腾的用户——出了问题自己能先排查。
五、非功能需求
Fred Brooks在《人月神话》的”没有银弹”一章中区分了”本质复杂性”和”意外复杂性”。[3] 非功能需求看似是辅助性的,但它们往往是”意外复杂性”的来源——你没把性能指标写清楚,开发照着”能用就行”的标准做,等到知识库大了之后才发现搜索慢得要命,改架构?那代价就高了。
因此,我们也要在PRD里明确这一部分的需求,这样有利于我们往后的技术选型和架构设计。非功能性需求通常有以下几个:
性能需求
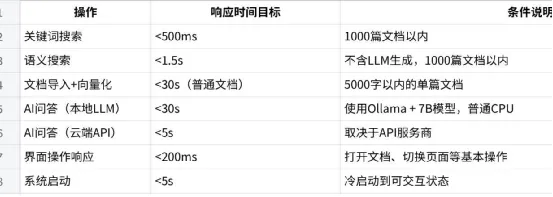
这些指标在MVP阶段是”目标”而非”强制承诺”。实际性能受硬件配置影响很大——一台16GB内存的MacBook Pro和一台4GB内存的旧ThinkPad表现不可能一样。PRD里写清楚”验证环境标准”(推荐配置:8GB+内存,SSD硬盘,4核+CPU),把测试条件明确下来。
安全性需求
安全性是这个产品的核心卖点之一,不能是走形式般写两句话。
数据存储安全:知识库数据默认明文存储在用户本地。提供可选的AES-256加密存储选项——开启后,所有文档内容和向量索引在落盘时加密,系统启动时需要输入解密密码。注意:开启加密后,语义搜索性能可能会有5-10%的额外开销。
数据传输安全:如果用户配置了云端API(如OpenAI、DeepSeek),所有外部请求强制使用HTTPS/TLS。系统不设置任何默认的外部API endpoint——用户主动配置并确认后方可启用云端功能。
访问控制:本地部署模式下依赖操作系统用户认证。可选设置应用级访问密码(系统启动时要求输入)。不设默认密码,不给用户一种”假安全”的错觉。
操作日志:记录知识库的创建/删除、文档的导入/删除、云端API调用记录(时间、调用量、发送字符数)。日志存储在本地,用户可以查看和清理。
易用性需求
目标用户是技术人员,但技术人员也需要好体验。
直观的首次使用体验:用户打开应用后,应该能看到一个”示例知识库”——包含几篇示例文档(比如一篇技术博客、一份产品说明、一篇读书笔记),用户可以直接体验搜索和问答。这比弹出一个”请创建您的第一个知识库”的空状态页面有用得多。
零配置启动:安装后即可使用,嵌入模型和向量数据库都内置了,不需要用户在命令行里折腾。对于进阶用户,设置页面提供详细的配置项——但不配置也能用。
这套设计思路背后是这样的考虑:苏杰在《人人都是产品经理2.0》里提到,好的产品应该”让用户感觉自己很聪明”。[4] 换句话说,用户打开你的产品后不应该产生”我是不是用错了”的怀疑情绪,而应该在一分钟内就体会到产品的核心价值。
清晰的系统反馈:文档导入中显示进度条和处理状态;搜索中显示loading动画;AI问答中显示”正在检索相关知识……正在生成回答……”的阶段提示。系统没有响应的状态一定要告知用户——”没反应”是最差的体验。
兼容性需求
操作系统:MVP优先支持Windows 10+和macOS 12+。Linux暂不支持——不是歧视,是资源有限。对Linux用户来说,他们一般技术能力更强,他们可以通过源码自行部署。
文档格式兼容性:如前述,支持MD、TXT、PDF(文本层)、DOCX。PDF扫描版和图片PDF在导入时给出提示:”检测到扫描版PDF,当前版本暂不支持OCR识别”。这个问题在V1.5中通过集成OCR能力来解决。
数据兼容性:知识库数据格式从V1.0起保持向后兼容。后续版本数据结构发生变化时,提供数据迁移工具。这是IEEE 830标准中”可修改性”的具体体现。[5]
可扩展性需求
架构上留三个扩展点:
模型可替换:嵌入模型和LLM通过配置切换,不硬编码。抽象出EmbeddingProvider和LLMProvider接口,新增模型只需实现对应接口。
向量数据库可替换:抽象出VectorStore接口,MVP使用Chroma,未来可切换到Milvus、Qdrant等。对于个人用户来说这个扩展性似乎多余,但考虑到未来可能的企业版本/团队协作是一个有价值的架构预留。
事件驱动的文档处理管道:文档导入后触发一个处理事件(DocumentImported),处理管道(文本提取→分块→向量化→存储)作为事件处理器运行。这样以后需要加新的处理步骤(比如自动摘要、关键词提取、实体识别)时,直接加一个新的处理器就好,不用改已有代码。
六、产品原型与交互说明
用户对产品的第一印象由什么来决定?那必然是整洁的、交互效果良好的界面——在软件开发当中,这通常被称为原型。
除了功能实现上的清晰严谨,原型界面上的赏心悦目同样很重要,因此我们也需要在PRD里把原型给定义好。而要定义原型,我们最好是用图片的方式做直观的展示。这里可以尝试墨刀、Auzre、Figma等原型设计工具。
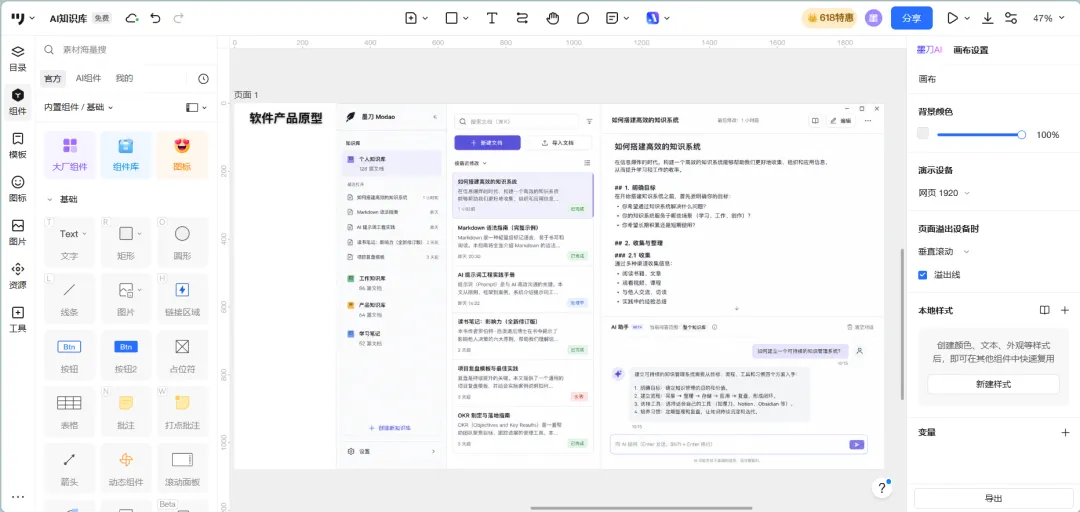
主界面采用经典的三栏布局,这个布局模式在Notion、Obsidian等产品中已经得到验证,用户学习成本低。
左侧栏——知识库导航:展示用户创建的所有知识库,点击切换。每个知识库下方显示最近打开的5篇文档(快捷入口)。底部有”创建新知识库”按钮和设置入口。宽度约240px,可折叠。
中间栏——文档列表:显示当前知识库的所有文档,按最近修改时间倒序排列,每条显示文档标题(超长截断)、前80字摘要、修改时间和处理状态(处理中/已完成/失败)。顶部有搜索框——这是整个界面的核心交互入口。支持新建文档和导入文档按钮。宽度约360px。
右侧主区域——内容/问答面板:上部约60%区域是文档阅读/编辑区。打开文档后显示Markdown渲染后的内容,点击编辑切换到编辑模式。下部约40%区域是AI问答对话框——输入框在最底部,对话历史在上方。用户可以在查看文档的同时进行AI问答,但需要注意:当前的问答范围是”整个知识库”,不是”当前打开的文档”(文档级问答在V1.5加入)。
关于设计决策,需要说明一点——为什么把搜索框放在中间栏而不是做一个全局搜索入口?因为它是最核心的功能,放在任何角落都不合适。用户打开应用看到的第一样东西就应该是”你想找什么?”输入框。我们甚至考虑过V1.5做一个类似Spotlight的全局快捷键唤起搜索窗口(比如Ctrl+Shift+K),但MVP阶段先把这个精力省下来。
交互细节就不事无巨细地写在这里了(交互设计文档会单独出),但有三个关键交互值得重点提一下:
搜索结果交互:用户输入查询后,搜索结果以列表形式展示在中间栏,点击某条结果后在右侧区域高亮展示匹配片段并打开原文档。搜索关键词在文档中以黄色高亮。
AI问答引用交互:AI回答中引用的文档片段以卡片形式展示,包含”文档标题 + 匹配片段摘录 + 相关度评分”。点击卡片直接跳转到原文档的具体位置(不是跳到文档开头,是跳到引用片段所在位置)。
空状态设计:知识库为空时,中间栏展示引导文案——”拖拽文档到此处开始,或点击+新建/导入”,配一张简单的示意插图。空状态下的设计容易被忽略,但这是用户的第一印象。一个空的”Excel表”和一个有引导的空状态,给用户的感受完全不同。
七、项目迭代规划
Brooks法则说了一句被无数产品经理当成座右铭的话:”向一个已经延误的软件项目添加人力,只会让它更延误。”[3] 背后的逻辑是:新人需要老人来培训,培训占用了老人的开发时间;同时团队通讯路径从n变成了n(n-1)/2。直接推论是:不要指望靠加人来追进度,要靠砍需求来保质量。
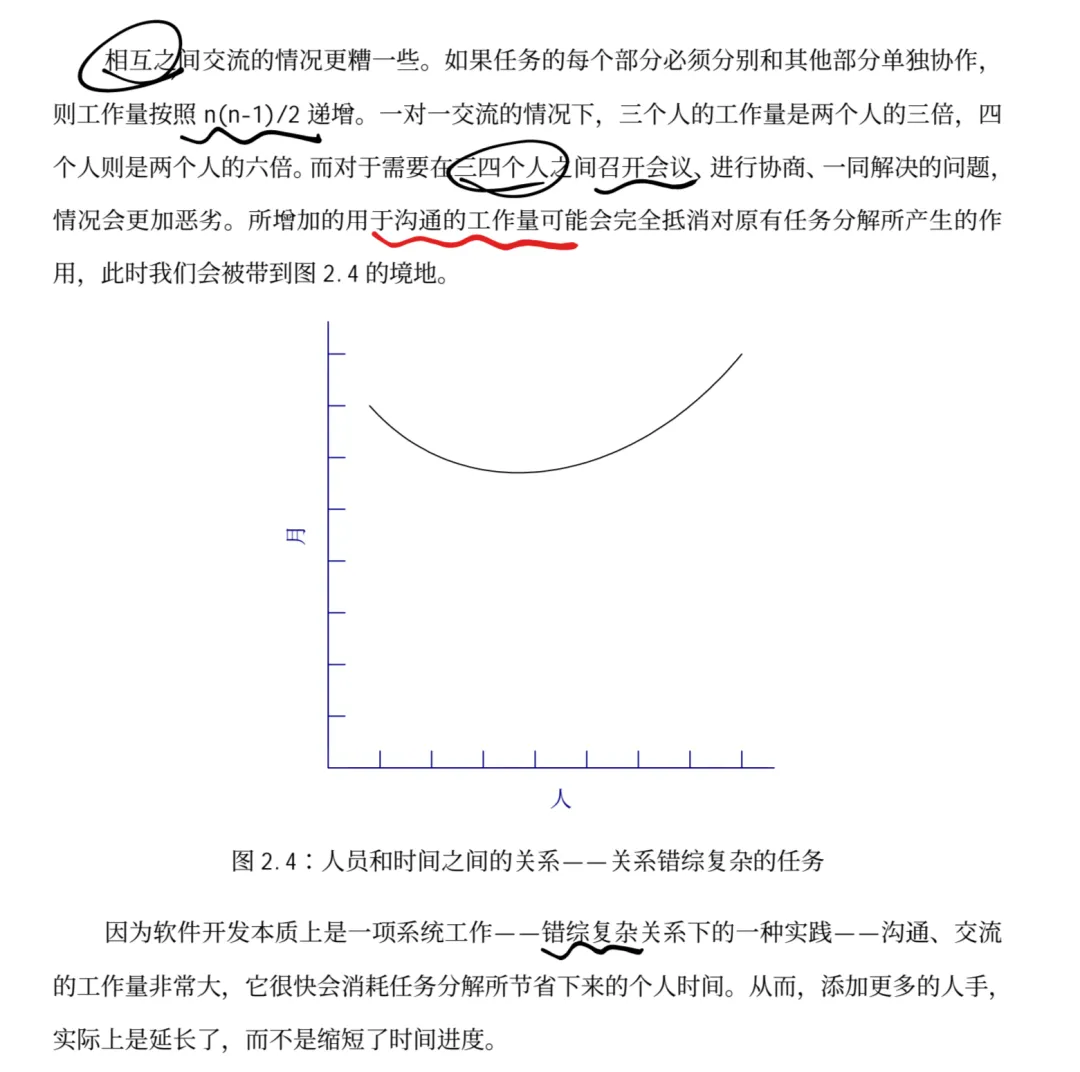
这也是为什么迭代规划不是”功能堆时间”而是”时间限制内做减法”。我们需要在PRD中做这些规划,每当因为各种主客观因素而导致拖慢进度时,我们要积极地去做减法。
|
下面做的日期限制,只是做一个示范,屏幕前的活动可以根据自己的实际情况,来制定自己的规划和时间限制。 |
V1.0(MVP)—— 8周
目标:验证”AI语义搜索+本地问答”这个核心价值是否成立。
功能范围:
-
单用户、单知识库(每个用户可以创建多个,但无共享) -
文档创建(Markdown)+ 文件导入(MD/TXT/PDF/DOCX) -
基础文档管理(列表、删除、查看) -
语义搜索 + 关键词搜索 -
AI单轮问答(基于RAG) -
本地数据存储 + 自动备份 -
Windows + macOS桌面应用
不做什么:多知识库间搜索、多轮对话、流式输出、标签系统、文件夹结构、浏览器插件、移动端、开放API。
验收节点:
第4周末:核心功能可演示(导入→搜索→问答闭环走通)
第6周末:功能冻结,进入测试
第8周末:发布MVP,招募20-30名内测用户
V1.5 —— MVP后8周
目标:根据MVP用户反馈优化体验,补充高频缺失功能。
重点改进:
-
多轮对话支持(基于历史上下文追问) -
流式输出AI回答 -
文档标签系统(替代文件夹作为主要组织方式) -
搜索结果按知识库过滤 -
问题改写(Query Rewriting)提升检索准确率 -
更多文档格式支持(HTML、EPUB) -
PDF扫描版OCR支持
V2.0 —— V1.5后12周
目标:从个人工具扩展到小团队协作。
新增能力:
-
多用户支持 + 权限管理(角色:管理员/编辑者/阅读者) -
知识库共享(分享链接+密码保护) -
评论与讨论(在文档片段上添加评论) -
移动端适配(PWA方案,暂不做原生App) -
版本历史(文档修改记录+差异对比)
V2.0的开发周期明显长于前两个版本,主要是多用户架构对后端的要求显著提高——数据库设计、并发处理、权限校验、数据隔离,每一项都需要充分的设计和测试。
八、验收标准
验收标准的设计受到IEEE 830标准的直接影响。这个标准定义了好的需求应该具备的八个特征:正确、无歧义、完整、一致、有优先级、可验证、可修改、可追溯。[5] 落到实操层面,最重要的是”可验证”——不能验证的需求等于没有需求。
功能性验收
文档管理验收:
上传一个1MB的Markdown文档,30秒内显示”处理完成”,搜索结果中可检索到该文档内容
上传一个10MB的PDF文档,3分钟内完成所有处理,文档列表中显示正确的标题和页数
删除一个文档后,搜索结果中不再出现该文档的内容
搜索验收:
准备一个包含500篇文档的测试知识库(涵盖技术、产品、生活等主题)
用10个预设的自然语言查询进行语义搜索,每个查询的Top-5结果中至少3条与查询意图相关
用精确关键词进行关键词搜索,100%的查询结果包含该关键词
AI问答验收:
准备20个基于知识库内容的预设问题(事实型、概念型、综合型各1/3)
AI回答在80%的问题上能给出基本正确的答案(不要求完全精准,毕竟受LLM能力限制)
所有回答都标注了至少一个引用来源
在回答”知识库中没有相关信息”的问题时,AI应明确表示”未在知识库中找到相关信息”,而不是凭空编造——这是很重要的思想,AI如果不知道或者不清楚,就尽可能不要让它猜测或编造。
这两条”不回答”和”不编造”比”回答得好不好”更重要——因为RAG系统最大的风险就是幻觉。
非功能性验收
性能验收: 测试环境:16GB RAM、SSD、4核CPU、1000篇文档的知识库。
语义搜索:20次搜索,平均响应时间<1.5s,P95<2s
关键词搜索:20次搜索,平均响应时间<500ms,P95<800ms
文档导入:20个不同大小的文档,最大处理时间不超过3分钟
连续运行24小时无崩溃、无内存泄漏(内存占用增长不超过初始的20%)
安全性验收:
开启加密存储后,用文本编辑器直接打开数据文件,内容不可读
未配置外部API时,系统不产生任何对外网络请求(用防火墙监控验证)
配置外部API后,抓包验证发送内容不包含完整文档,仅包含检索片段
验收形式: 所有验收测试结果形成书面报告,测试用例、执行结果、缺陷记录、修复验证全部归档。验收通过标准:功能性验收无P0缺陷,非功能性验收所有指标达标。
九、附录
附录部分收录正文中不便展开的补充信息,供团队成员按需查阅。当然,这里也只是面向团队做的一件事,如果你只是一两个人做开发,PRD里可以不写这部分内容。
附录A——技术选型对比分析:嵌入模型选型对比(BGE vs M3E vs text2vec)、向量数据库对比(Chroma vs Qdrant vs Milvus)、LLM部署方案对比(Ollama vs llama.cpp vs vLLM)、前端技术栈方案(Electron vs Tauri vs PWA)。每项对比包含技术方案简介、优缺点分析、MVP选型建议。具体对比表格在此不展开,但每一项选型都会附上决策理由和可替代方案。
附录B——竞品分析摘要:Notion AI、Obsidian社区AI插件、Dify、FastGPT、AnythingLLM的功能对比矩阵。梳理各竞品在知识管理+AI方向上的做法和差异点,确认我们产品的差异化位置。
附录C——用户调研记录:10位目标用户的访谈原始记录摘要,包括使用习惯、现有工具痛点、对AI功能的期待和顾虑、接受度评估。用户调研数据已做脱敏处理(隐去姓名和联系信息)。
附录D——术语索引:文档中出现的所有专业术语按字母顺序索引。
十、让AI不断质问你的PRD
|
你不可能第一次就把需求想得十分明白。你需要经过多轮和客户的反复对接,才能最终搞清楚所有的需求和业务流程——然后才有条件写出一份相对完善的PRD。 AI可以充当这个”客户”角色。一个人很难靠自己看到初版PRD的所有问题,无论是隐性的还是显性的。让AI不断追问你的PRD,指出还有哪些地方需要完善;你完善一遍,再让AI审一遍;重复几次,直到你自己满意、AI也看不出太多新问题。 |
为什么需要AI来”找茬”
写PRD最危险的状态不是”写不出来”,而是”写完了但全是漏洞但自己看不出来”。
这和Brooks描述的软件设计困境是一样的——”系统只有在被构建和测试之后,设计师才会发现那些本可以在设计阶段就发现的问题。”[3] PRD同理:只有当你把PRD交给别人审阅(或者你自己隔几天重新读一遍),那些模糊的定义、矛盾的描述、遗漏的边界条件才会浮现。但现实中,大多数个人开发者或小团队写PRD的时候,根本没有”别人”来审阅。老板?老板只关心什么时候能上线。同事?同事自己的活都干不完。
AI填补的就是这个”缺失的审阅者”角色。
AI能从哪些角度质问你的PRD
我自己试用下来,AI的质问可以覆盖这几个维度:
一致性质问:检查文档内部的自相矛盾。”你前文说MVP只支持单用户,但功能需求里提到了权限管理模块——这两者是否矛盾?权限管理在单用户场景下是否有意义?”这种矛盾在产品经理脑子里可能是”我知道它们不矛盾,但没说清楚为什么”,但对读到这段的开发来说,这就是一个让你困惑的坑。
完整性质问:找出遗漏的关键设定。”你在性能需求里提到了搜索响应时间,但没有说明这个指标基于多大的知识库规模。100篇文档和10000篇文档下的1.5秒含义完全不同。”
可行性追问:从技术实现角度挑战需求是否合理。”你要求AI问答使用本地LLM实现30秒内响应,但用户如果只有8GB内存、还在同时运行浏览器和IDE,7B的模型能否在30秒内完成推理?”
优先级质问:”为什么标签功能要等到V1.5?从你的用户场景描述来看,三个场景都暗示了用户需要超越时间排序的组织方式——是不是应该在MVP里至少提供一个基础的’收藏/标记重要文档’功能?”这种质问有时候会改变你的优先级排序,有时候不会——但迫使你重新思考一遍排序逻辑、给出合理的理由,本身就是有价值的。
用户体验质疑:”你在三栏布局中把AI问答放在了右下角,但从场景分析来看,对于前两个场景的用户(程序员小张和产品经理小李),AI问答是他们解决实际问题的首选入口,放在右下角是否太弱了?”这个质疑直接让我重新审视了交互方案——最终决定把搜索框和AI问答合并为统一的入口(类似ChatGPT的交互模式),而不是分离的两个区域。
实际操作:怎么让AI质问你的PRD
我摸索出一个比较实用的流程:
第一轮——全局审阅:把你写好的完整PRD丢给AI,提示词:”请以一名资深产品经理的身份,严格审阅这份PRD,指出其中存在的问题。从一致性、完整性、可行性、优先级、用户体验五个维度逐一分析。只提出问题,不需要给出修改建议。”
这一步只让AI找问题不给建议是有原因的——让AI同时找问题和给建议会稀释注意力。先集中精力把问题清单拉出来。
第二轮——角色扮演审阅:换一个视角,请AI分别扮演不同角色来审阅:”请以一名后端开发工程师的身份审阅这份PRD,关注技术实现的可行性和潜在风险,指出模糊不清或无法实现的需求。”
同理,再分别用测试工程师(关注验收标准是否可测试)、设计师(关注交互逻辑是否合理)、用户(关注使用场景是否真实)的视角来审阅。
第三轮——针对性修改:收集两轮审阅的所有问题,逐条评估。三条原则:确实有问题的,改PRD;AI误解但说明写的不清楚的,补充解释;AI的质疑不构成实质影响的(比如吹毛求疵的类型),在PRD附注里说明”已考虑,理由如下”——是的,这一步,全程都要由你亲力亲为,别怕麻烦。
第四轮——再审阅:把修改后的PRD再丢给AI:”请审阅修改后的PRD,对比上一轮提出的问题清单,逐条确认每个问题是否被妥善解决。”
通常经过两三轮这样的循环,PRD的质量会有质的提升。不是说它变得完美了——完美的PRD不存在——而是说它从”一个人能在自己脑子里想清楚的程度”提升到了”一个团队可以基于它高效协作的程度”。这中间的差距,就是AI帮我们填上的。
最后想强调一点:AI帮你审PRD,不代表AI能替代你做决策。它能告诉你哪里有问题,但”要不要改、改成什么”仍然是产品经理自己的判断。这和Brooks说的”没有银弹”是一脉相承的——AI是一个好用的审阅工具,但它没法替代你对用户和产品的理解。本质复杂性(或者说产品的模样)始终在你的脑子里,工具帮不了你思考,只能帮你想得更完整。
参考来源
[1] Hermann Ebbinghaus, Memory: A Contribution to Experimental Psychology, 1885. (艾宾浩斯遗忘曲线的原始研究)
[2] Tiago Forte, Building a Second Brain: A Proven Method to Organize Your Digital Life and Unlock Your Creative Potential, Atria Books, 2022.
[3] Frederick P. Brooks Jr., The Mythical Man-Month: Essays on Software Engineering, Anniversary Edition (Chapters 2, 4, 5, 16), Addison-Wesley, 1995. 中译本:《人月神话》(周年纪念版),清华大学出版社。
[4] 苏杰,《人人都是产品经理2.0:写给泛产品经理》,电子工业出版社,2017。
[5] IEEE Std 830-1998, IEEE Recommended Practice for Software Requirements Specifications. (已被ISO/IEC/IEEE 29148:2011取代并扩展)
[6] Patrick Lewis, Ethan Perez, et al., “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”, Advances in Neural Information Processing Systems 33 (NeurIPS 2020).
[7] BAAI (Beijing Academy of Artificial Intelligence), BGE Embedding Models. BAAI/bge-large-zh-v1.5. Model card available on Hugging Face. C-MTEB benchmark results accessible via MTEB leaderboard.
[8] LangChain Documentation, “Text Splitters” and “Vector Stores” modules. Official documentation at python.langchain.com. LlamaIndex Documentation for reference comparison of chunking strategies.
[9] Ollama, open-source local LLM deployment tool. ollama.com. GitHub: github.com/ollama/ollama.
本文是”用产品思维、软件工程思想重构AI软件开发”专栏系列文章之一。下一篇我们将尝试绘画各种业务图并开始设计软件的架构,这既是在进一步深入理解需求,也是在捋顺整套系统流程,同时也为后面AI写代码做足约束和铺垫。
PRD范例
链接:https://pan.quark.cn/s/7a7795e2e153 提取码:GryM