 夜雨聆风
夜雨聆风





踩坑前想清楚:为什么要本地部署 OpenClaw(1)
OpenClaw依旧是经典的AI Agent工具,对我个人来说,定义为必须体验的产品。但其本地化部署存在环境依赖复杂、升级兼容差、配置复杂等问题。作为不完全懂技术的我来说,也是结结实实踩遍了坑。
如果不是非要确保数据不出本地,或像某人一样偏要主动走hard模式的话,也许你真的不需要本地部署的!不入局,就不会踩坑了~
但你很严谨,于是需要严格评估是否入局本地部署:
那么,先来理清 OpenClaw 本地部署的两种方式
A- 本地安装OpenClaw+使用云端的大模型
B- 本地安装OpenClaw+本地部署大模型
理解了A,基本就理解了B,理解了这两种方式,也许就会更清楚自身需求,也就是为什么要本地部署
先来张不完美的图,描述方案A:
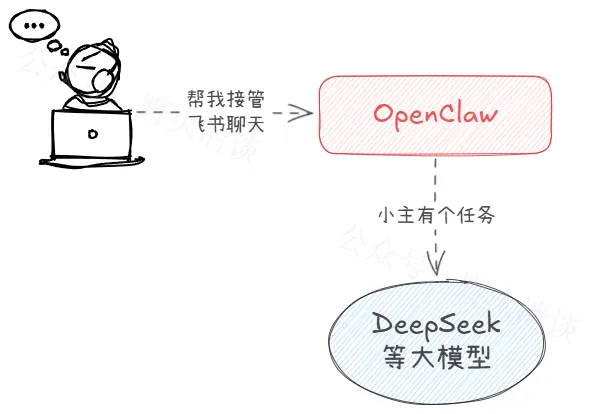
这就是你和OpenClaw、大模型之间的初遇交互,OpenClaw 本身不是大模型,它是一个 AI Agent 运行时(控制层+执行层)。
大模型接到你的消息,一顿思考后给出了解决方案,如果这些方案不是靠动嘴就能解决的话,那就需要OpenClaw集成的各种能力去做执行了。
我们知道最快速跑通OpenClaw的方式就是采用云端大模型,买上token,配置上key。这个简单的任务中,在云上发生的事情和过程中传递的数据就是这些:蓝色部分。
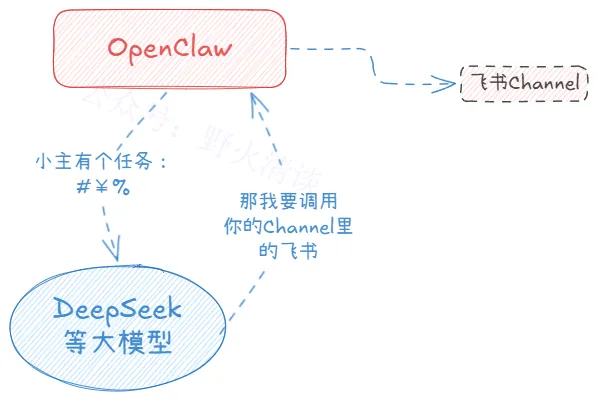
那么,对比全云端部署的方案,方案A:本地安装OpenClaw+使用云端的大模型的收益/成本是什么?
-
安装难度:⭐⭐⭐⭐(足以劝退全小白)
-
数据隐私:与全云端使用没有多少差异
-
本机文件:可访问,可处理
-
费用成本:
-
大模型Token:与全云端使用没有差异
-
OpenClaw运行环境:假设已经有办公电脑,全云端(服务器镜像版)需要租用服务器,小几百/年。
下篇我们继续聊透这个问题。

** 化繁为简 **
深度,基于核心基础
问题,是撬起AI的支点