 夜雨聆风
夜雨聆风





腾讯混元给 OpenClaw 装了个「第二大脑」
我觉的有时候也得多关注关注咱们国内的产品,比如腾讯混元团队这次专门针对 OpenClaw 新推出的「Hy-Memory」,对于开发者来讲就是一款非常不错的解决 AI Agent 持久化记忆问题的优秀插件。
我们都知道用 OpenClaw 的人今天跟龙虾聊了半天,把项目背景交代清楚了,需求对齐了,进展也同步了,感觉终于进入状态了。结果第二天一开新会话,它看你的眼神儿就像看着一个陌生人。
你是谁?
你要做什么?
你跟我说过什么吗?
全都给忘了…
有经验的朋友学会了一个土方法,就是在结束当天的会话之前,强制让龙虾把所有正在进行中的事情、讨论的上下文、当前的进展,全部整理进一个 Markdown 文件里,下次开会话再把这个文件先喂给它。
这个方法是有效的,但很麻烦,而且不可靠。万一上次没来得及写,或者文件里漏掉了关键信息,还是得重新讲一遍故事。
OpenClaw 本身有一个叫「梦境」的功能,就是在你晚上睡觉的时候用来处理「记忆」这件事儿的,但用过的人都知道,它的表现并不稳定。
这不是 OpenClaw 一家的问题,几乎所有 AI Agent 到今天都没有真正解决「记忆持久化」这件事儿。
而就在两天前,腾讯混元公布了一款叫「Hy-Memory」的插件,专门是为 OpenClaw 这类长期协作 Agent 设计的,定位是 Agent 真正的「第二大脑」。
这个赛道上其实已经有人在做类似的事儿了,先说两个有代表性的。
一个是 Claude-Mem。
仓库地址:
https://github.com/thedotmack/claude-mem
常用 Claude Code 的用户可能知道它,这是一个专门为 Claude Code 构建的第三方「记忆插件」,用另一个 AI 在旁边旁观你的编程会话,自动把每一个决策、每一次 bug 修复、每一个新功能都记下来,生成可搜索的开发日志。
说起来也叫记忆插件,但它记的是「你的 AI 做了什么」,本质上更像是一本项目工作日志,跟记住「你这个人是什么样儿的」是两件完全不同的事儿。
另一个我认为与 Hy-Memory 的定位更接近的,叫「Mem0」。

仓库地址:
https://github.com/mem0ai/mem0
它是专门给 AI Agent 提供通用记忆层的服务,已经有超过 9 万名开发者在用,既有开源版本也有云端托管版本,覆盖医疗、教育、电商、客服等各种场景。
Hy-Memory 的官网跑分对比表里专门把 Mem0 列进去做比较,从这个选择就能看出腾讯混元认为它们是最直接的竞争关系。
官方给 Hy-Memory 的宣传语是「记住一次,随处同行」。

它想做的事儿用一句话描述就是:把你这个人的长期偏好、重要事实、身份画像和行为意图,沉淀成一份儿可以跨会话、跨 Agent 共享的记忆资产。
它也明确说了自己不是单纯的检索工具,不是只会帮你找到之前说过什么,而是要让 Agent 真正理解你、持续认识你。
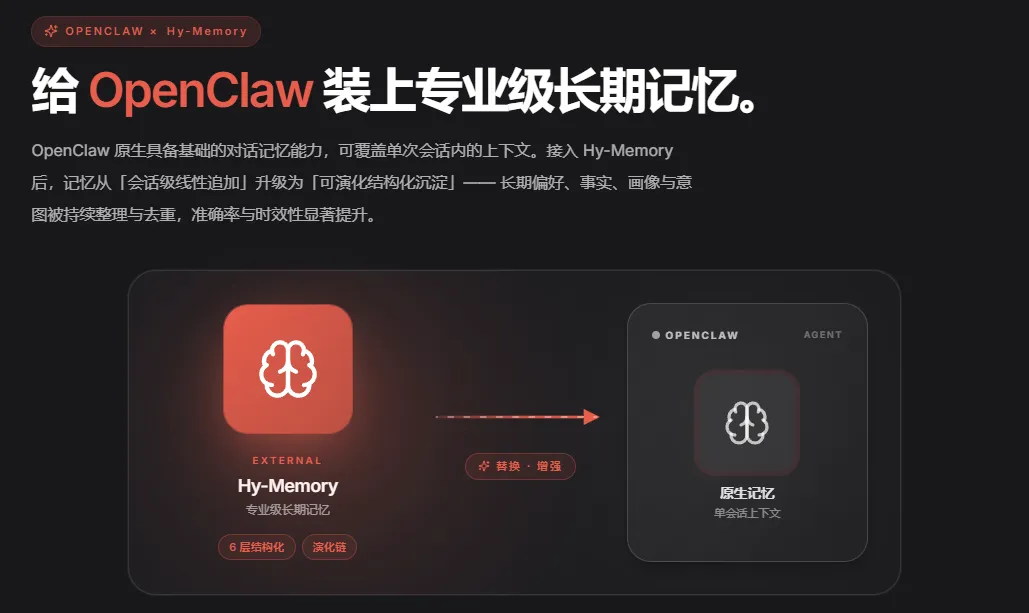
OpenClaw 本身有基础的对话记忆,但那只是当前会话的线性追加,会话结束就会清空,记忆无法跨越。
而接入 Hy-Memory 之后,OpenClaw 的记忆从「会话级线性追加」升级为「可演化的结构化沉淀」,这两种架构的差距,也是我认为最应该讲清楚的地方。
现在大多数记忆系统面临的根本问题不是记不住,而是记得越来越乱。
把所有对话信息都堆进一个数据库,等需要的时候再检索出来,这个思路听起来没问题,但用久了就会发现一个麻烦:
旧偏好与新偏好并存,相互矛盾的信息同时存在,系统不知道哪个更重要、哪个已经过时。
比如你曾经说过喜欢吃辣的,后来肠胃突然不好改口儿了,但旧记忆没有被更新,新旧信息同时出现在检索结果里,Agent 就会变得很困惑。
Hy-Memory 的核心创新叫「演化链」,用了一种叫 supersedes 指针的机制,让每一条记忆都跟它的前一条挂钩,形成一根因果链条。
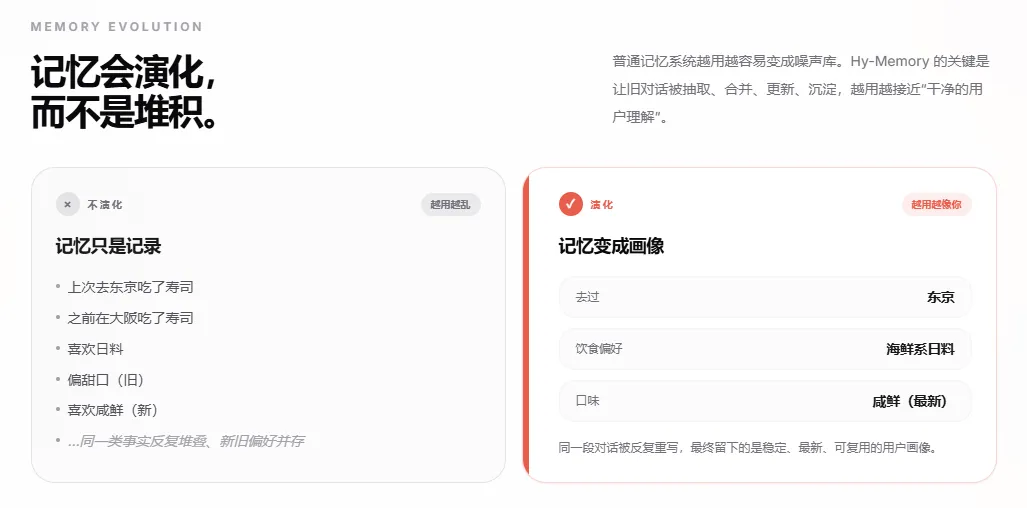
新信息不是简单堆在旧信息上面,而是明确告诉系统「这条记忆取代了那条记忆,原因是什么」。
记忆不是堆积的,是演化的。
官方用了一个「东京寿司」的例子来解释这个过程。
用户在对话里随口提了一句喜欢吃寿司,Hy-Memory 拿到这条原始对话,先把它提炼成一个原子事实「用户喜欢寿司」,然后跟已有的食物偏好信息合并,检查有没有冲突,最终把它沉淀进用户的身份画像里,变成「偏好日式料理」。

这只是一句随口的话,但五步之后它却成为了一个人物特征。下次用户提到要去日本旅游,Agent 会主动想到这一层,而不用用户再多说一个字。
另一个更能说明问题的例子是「独立民谣创作人」的故事。
设想一个用户,一开始喜欢流行音乐,后来转型开始玩儿民谣,再后来又开始自己创作了,慢慢成了一个独立音乐人。
在这个过程里,如果记忆系统用的是「覆盖删除」的策略,旧的喜好被新的直接替换掉,系统永远不知道这个人经历了什么样的转变;如果用的是「散落堆积」策略,三个阶段的记忆则都会保留,但检索时旧的和新的权重又一样,系统可能又会分不清楚现在的他更像谁。
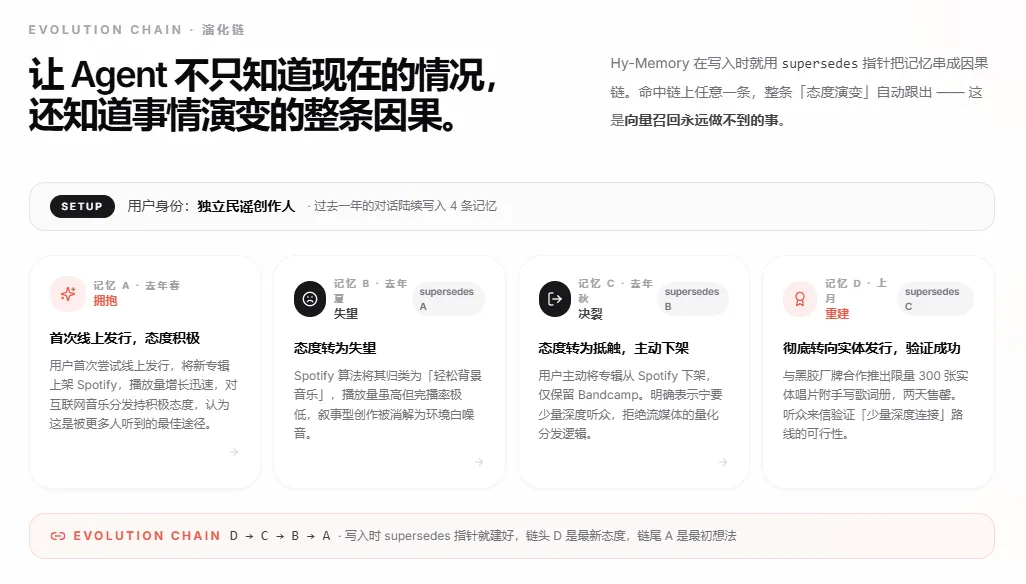
只有演化链的方式,每一步转变都通过 supersedes 指针串联在一起,系统能看到完整的因果历程,知道从「流行乐→民谣→独立创作人」是一条演化路径,而不是三个相互矛盾的人格。
这件事儿光是采用向量搜索是做不到的,因为向量搜索只能找到语义相似的信息,但没有办法理解「这条记忆其他已经被那条记忆所取代了」的这层逻辑关系。
说完演化链,再来看一下 Hy-Memory 的底层架构,不用了解太多技术细节,只要知道它的设计逻辑就够了。
它设计了一个六层的记忆框架,L1 到 L4 是 System1 实时处理的。
原始对话痕迹、提炼出的原子事实、身份画像、会话摘要,这四层在对话进行的时候就已经实时写入,毫秒级的响应。

L5 和 L6 是 System2 后台异步处理的。
心智模型和前瞻意图,这两层不需要实时,而是等你不用的时候在后台慢慢整理,把那些散碎的事实归纳成对你更深层的认知框架,甚至能预测你下一步可能想做什么。类似于 OpenClaw 或 Hermes Agent 中的「梦境」功能。
如果用一句话来打个比方,那就像:
你在说话,它在记录;
你不在了,它在思考。
两条路并行跑,合起来才是完整的「第二大脑」。
好,核心的东西基本说完了,咱们再来看看跑分情况。
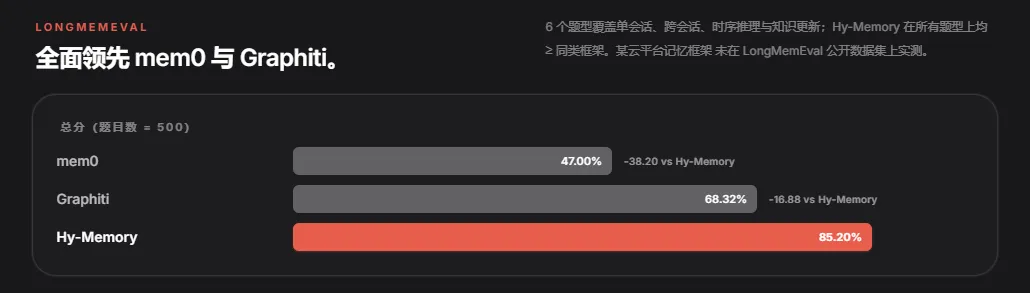
在 LongMemEval 这个专门测试 AI 长期记忆能力的评测集上,Hy-Memory 拿了 85.2% 的总分,Mem0 是 47%,Graphiti 是 68.3%。
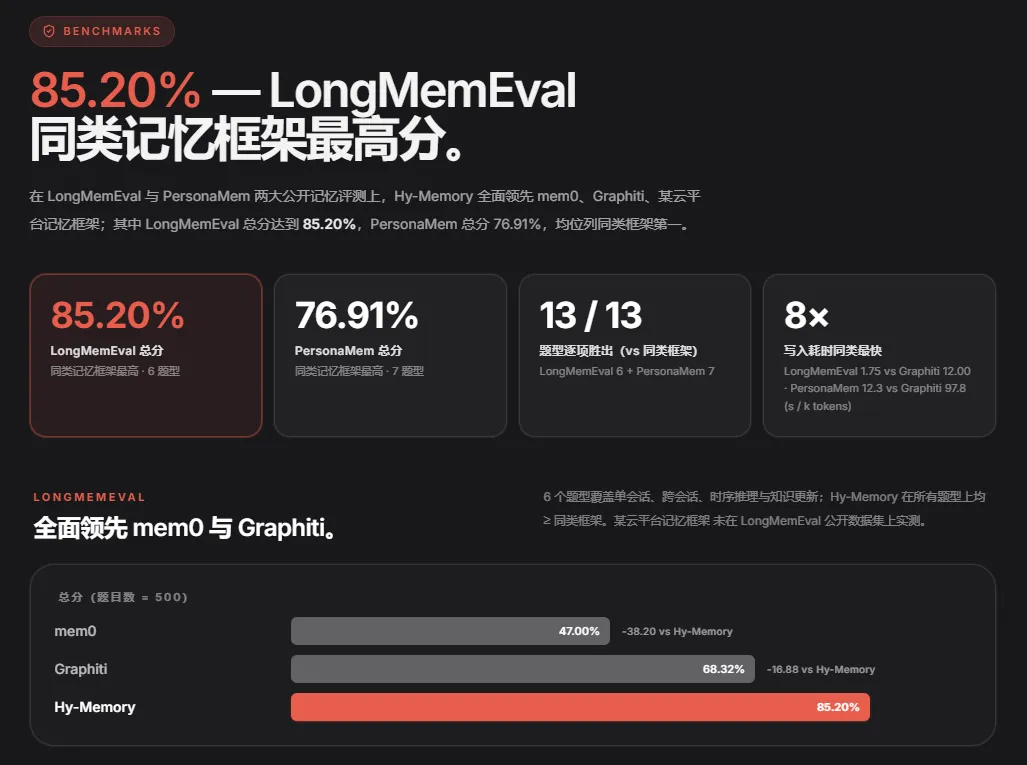
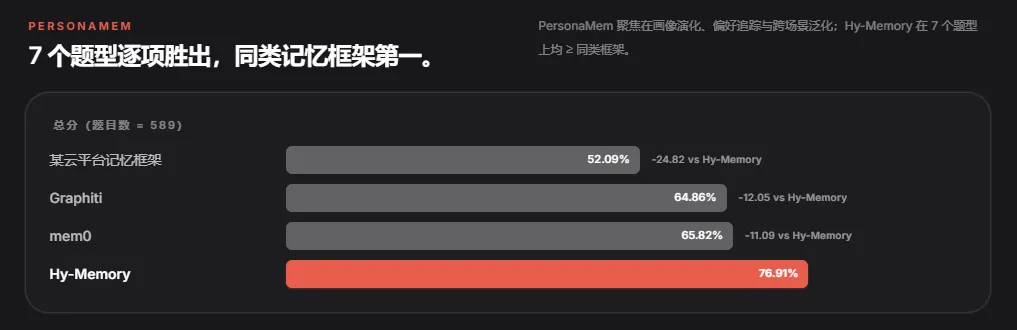
在另一个叫 PersonaMem 的评测集上,Hy-Memory 是 76.9%,同类框架里排第一。13 个题型类别,Hy-Memory 全部胜出,没有一个输掉的。
而写入速度方面,Hy-Memory 比 Graphiti 快 8 倍。
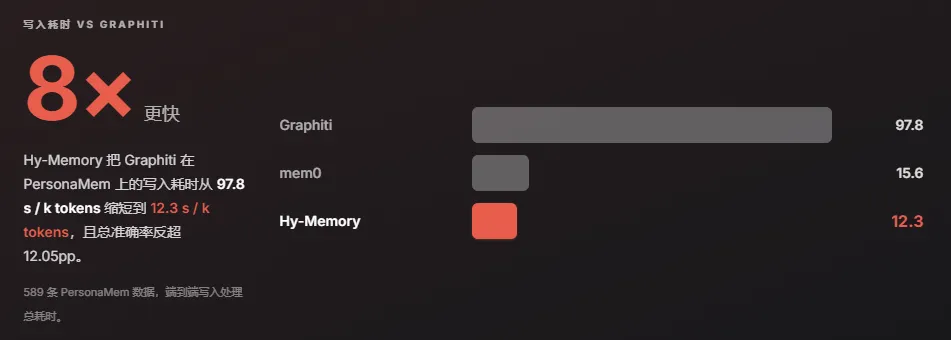
最反直觉的一组数据是记忆条数和信息密度的对比。Hy-Memory 平均每个用户只存了 82 条记忆,而 Mem0 是 309 条,Graphiti 是 362 条。存的最少,但准确率最高。

原因在于单条记忆的信息密度,Hy-Memory 每条记忆平均有 130 个 token,Mem0 是 52,Graphiti 是 89。同样的信息,Hy-Memory 压缩得更精准,而不是把所有原始文本一股脑塞进去,质量打败了数量。
最后说说怎么用。
Hy-Memory 的插件本身是开源免费的,任何 OpenClaw 用户都可以安装,安装命令就一行。但要真正跑起来,需要准备四样儿东西:
1、OpenClaw CLI 命令行工具(只要你装了 OpenClaw 都会自带)
2、Python 3.8 以上的运行环境(这个玩 AI 的一般机器里都会装)
3、一个 LLM 的 API key
4、以及一个 Embedding 的 API key
前两个就不展开说了,说说后两个。
LLM 服务起到的作用就是 AI 大脑。Hy-Memory 用它来读懂你的对话、提炼记忆、做整理和推理,官方文档里用的是通过 OpenRouter 接入混元 3.0 Preview,换成其他模型也行。比如 MiniMax、GLM、DeepSeek 的都可以。
Embedding 服务是另一回事儿。它不会说话,也不生成文字,它做的事儿是把每一条记忆给翻译成一串数字坐标,这样系统才能通过语义相似度来检索记忆。比如你问「我的饮食偏好」,它能找到「偏好日式料理」这条记忆,哪怕两句话一个字都不重叠。
以上这两个是独立的服务,要分别申请 API key。
官方推荐是用 SiliconFlow(硅基流动 https://siliconflow.cn) 平台的 BAAI/bge-m3 模型做 Embedding,这个平台对新注册用户有免费额度,日常用量基本不花什么钱。
详细说一下安装与配置过程。
第一步:安装插件
老用户需要先卸载
openclaw plugins uninstall openclaw-hy-memory全新安装(绝大部分用户都应该用这个)
openclaw plugins install openclaw-hy-memory --dangerously-force-unsafe-install第二步:初始化配置
运行 init 命令,按交互式提示输入 LLM 与 Embedding 服务的 model、apiKey、endpoint,插件会自动写入配置文件。
命令如下:
openclaw hy-memory init如果你想手动配置也支持,可以去下面官网详细了解一下,各种配置字段说明都有:
https://memory.hunyuan.tencent.com/openclaw/
第三步:重启网关
配置完成后,执行以下命令重启 OpenClaw 网关,Hy-Memory 即可开始为你的 Agent 服务。
命令如下:
openclaw gateway restart第四步:验证安装
网关重启后,执行 status 命令检查 Hy-Memory 是否成功注册并连接。
命令如下:
openclaw hy-memory status看到类似下方的输出即表示插件已就绪:
[plugins] openclaw-hy-memory: registered (user: tom001, server: http://127.0.0.1:19527, autoRecall: true, autoCapture: true)OpenClaw 2026.5.26 (10ad3aa) — Built by lobsters, for humans. Don't question the hierarchy.HY Memory Server: http://127.0.0.1:19527Status: ✓ healthyUser ID: tom001VDB: ok [chroma] (collection: agent_memories_1024, points: 0)Embed: ok (dims: 1024)LLM: okSDK Version: 1.2.5
另外 Hy-Memory 提供了三个档位可以按需选择。
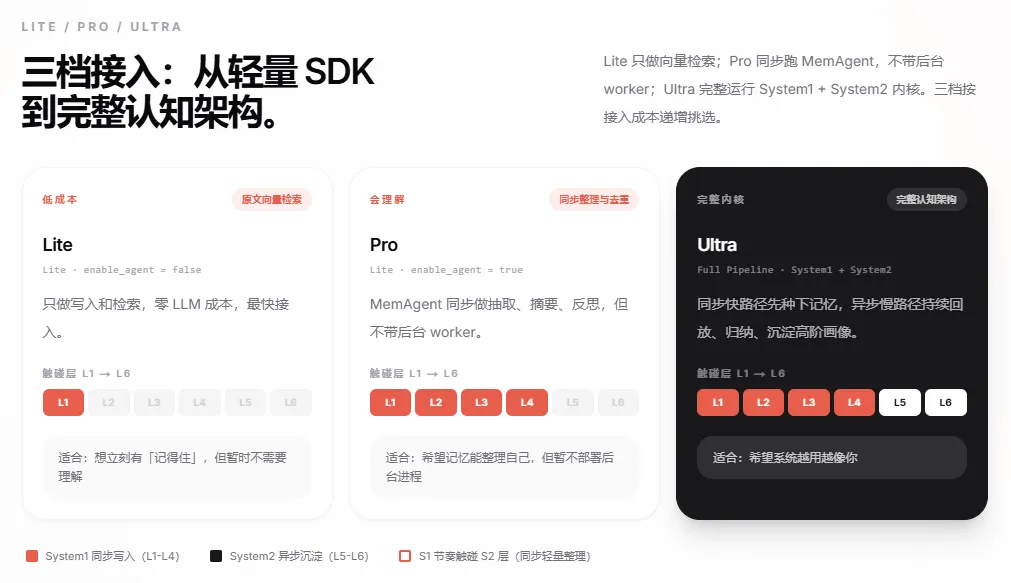
◆ Lite 档最轻量,只用向量检索,不需要 LLM 参与,零额外成本,适合想先感受一下效果的用户。
◆ Pro 档加上了 MemAgent 做同步整理,对话结束后会帮你把记忆归纳好。
◆ Ultra 档是完整的双系统架构,System1 加 System2 全开,适合重度使用 OpenClaw 的用户。
写在最后
坦白说,这套东西对真正的普通用户来讲门槛儿还是存在的,安装调试不是点几下就能搞定的,需要对命令行和 API 有一定了解。
如果你本来就是 OpenClaw 的活跃用户,这个门槛儿不算高;如果完全没有这类折腾的经验,可能需要多花一些时间进行摸索。
这次腾讯混元团队带着完整的技术架构和可对比的跑分数据入场,绝不是简单的来蹭热点,能看出来是真的想把这件事儿做好。
让 AI 真正的「认识你」,真正能给 Agent 带来持久化的记忆。
如果你一直在用 OpenClaw,还没放弃,值得持续关注并试一试。
既然看到这儿了,如果觉得还不错,帮忙随手点个「赞」、「在看」、「转发」三连;如果想第一时间收到推送,也可给我加个星标★,非常感谢!