 夜雨聆风
夜雨聆风





给 OpenClaw 装上声带:创建第一个 TTS Skill
大家好,我是蜗牛AI。
以前,我的 OpenClaw 小龙虾只能在飞书里回复文字。
这次,我给它接入了语音合成能力。
现在只要发送一段文字,它就能生成音频,再通过飞书发回来。
整个流程是:
发送文字↓小龙虾调用 tts-momo Skill↓阿里云百炼生成语音↓飞书收到可播放、可下载的音频这篇文章只做一件事。
创建一个名为 tts-momo 的 Skill,让云端小龙虾第一次开口说话。
TTS 是什么?
刚开始学习时,我连 TTS 是什么都不知道。
其实它很简单。
TTS 的全称是 Text To Speech,中文叫文本转语音。
例如输入:
大家好,我是蜗牛AI。TTS 会把它转换成一段朗读这句话的音频。
有声书、导航语音、短视频配音和智能客服,都可能用到 TTS。
所以 TTS 不是某一个软件,而是一类“把文字变成声音”的能力。
这次提供 TTS 能力的平台,是阿里云百炼。
为什么还要创建 Skill?
阿里云百炼已经能生成语音,为什么还要创建 Skill?
因为我不想每次生成语音,都重新研究接口、填写参数,再处理音频文件。
Skill 可以把这些重复操作固定成一套流程。
你可以把它理解成小龙虾工具箱中的一个专用工具:
API 文档:使用说明书API Key:进入服务的门禁卡Skill:整理好的完整操作流程创建 Skill 后,我只需要说一句:
把这段文字转成语音。小龙虾就知道该调用哪个模型、使用什么音色,也知道怎样把音频发回来。
开始前需要准备什么?
开始操作前,需要确认:
- OpenClaw 已经部署并正常运行
- 已经接入飞书,可以正常与小龙虾聊天
- 拥有可以登录的阿里云账号
- 能够打开阿里云百炼控制台
这次使用的是阿里云百炼的非实时语音合成能力。
它适合接收一段完整文字,生成一个可以下载的音频文件。
第一步:找到语音合成 API 文档
进入阿里云百炼控制台。
先找到语音合成页面,再打开非实时语音合成的 API 文档。
这份文档介绍了多个语音模型。
我们主要关注 Qwen-TTS 的非流式调用方式。
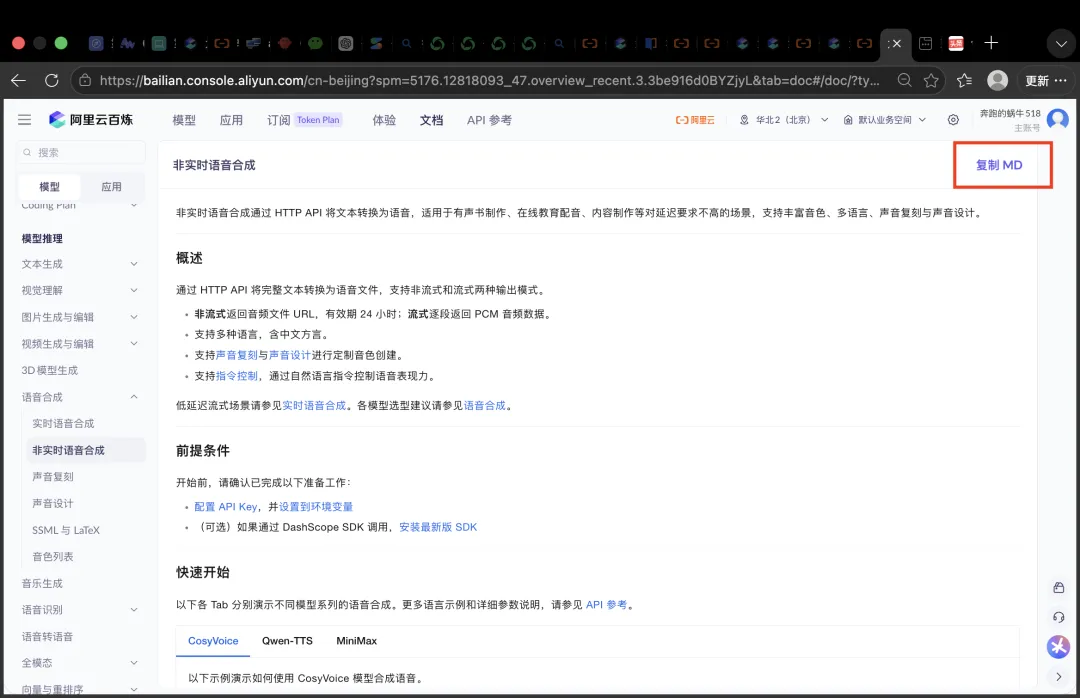
文档中需要能看到这些关键信息:
模型:qwen3-tts-flash文字参数:text音色参数:voice语言参数:language_type不用担心自己看不懂完整文档。
接下来,把文档交给小龙虾。
让它自己理解接口,再创建 Skill。
在文档页面复制 Markdown 内容。
做到这里,你应该已经拿到了一份完整的语音合成 API 文档。
第二步:让小龙虾创建 tts-momo
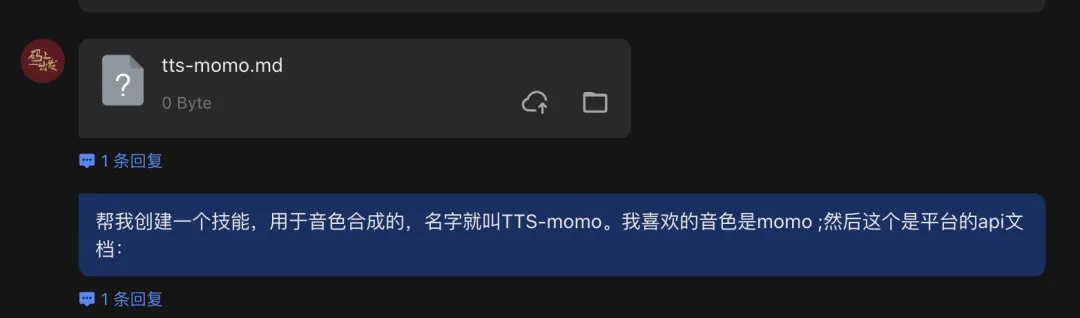
把刚才复制的 API 文档发送给小龙虾,再把下面的要求一起发给它:
先检查 Skill 是否创建正确,再进行真实调用。
这样出现问题时,更容易排查。
小龙虾创建完成后,返回了类似下面的目录结构:
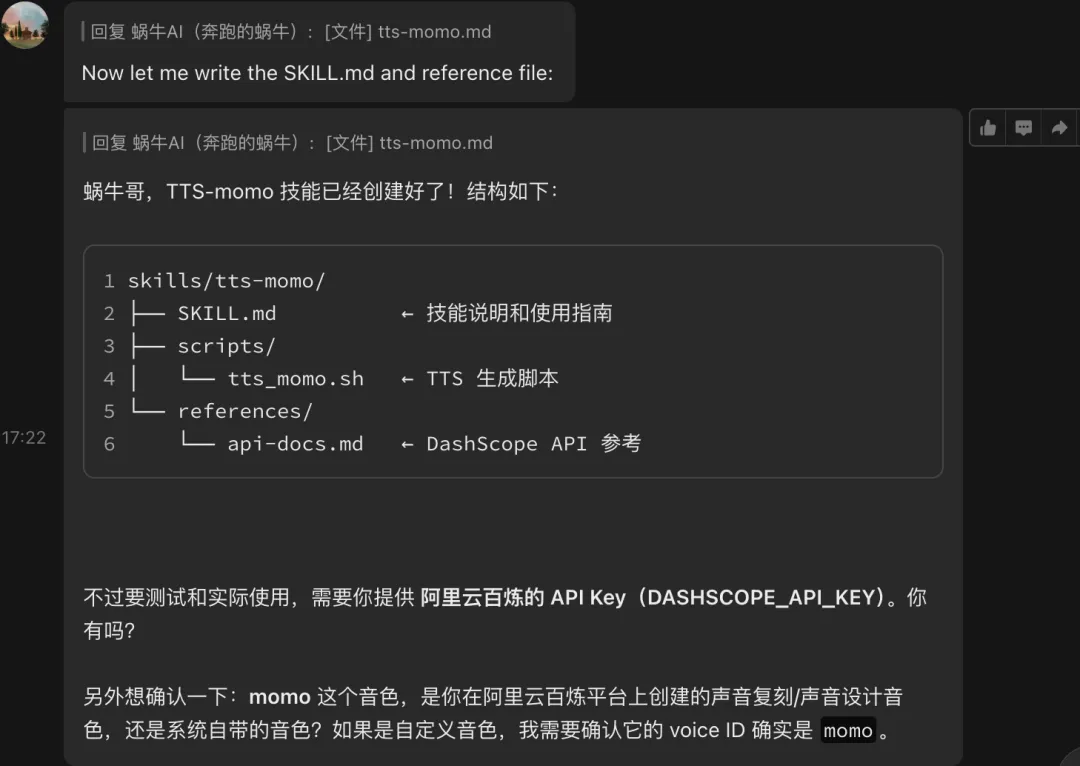
这些文件分别负责:
- SKILL.md:说明什么时候使用这个 Skill,以及如何使用
- tts_momo.sh:调用 TTS、处理音频和发送结果
- api-docs.md:保存接口参数参考
如果小龙虾返回了文件位置、目录结构和使用方法,说明 Skill 已经创建完成。
但此时还不能说明它真的能生成语音。
第三步:配置 API Key
小龙虾想调用阿里云百炼,需要配置 API Key。
API Key 可以理解成一张门禁卡。
它告诉平台:
- 谁在调用服务
- 是否拥有调用权限
- 调用额度和费用属于哪个账号
进入阿里云百炼的 API Key 管理页面。
创建一个 Key,或者选择已有的可用 Key。
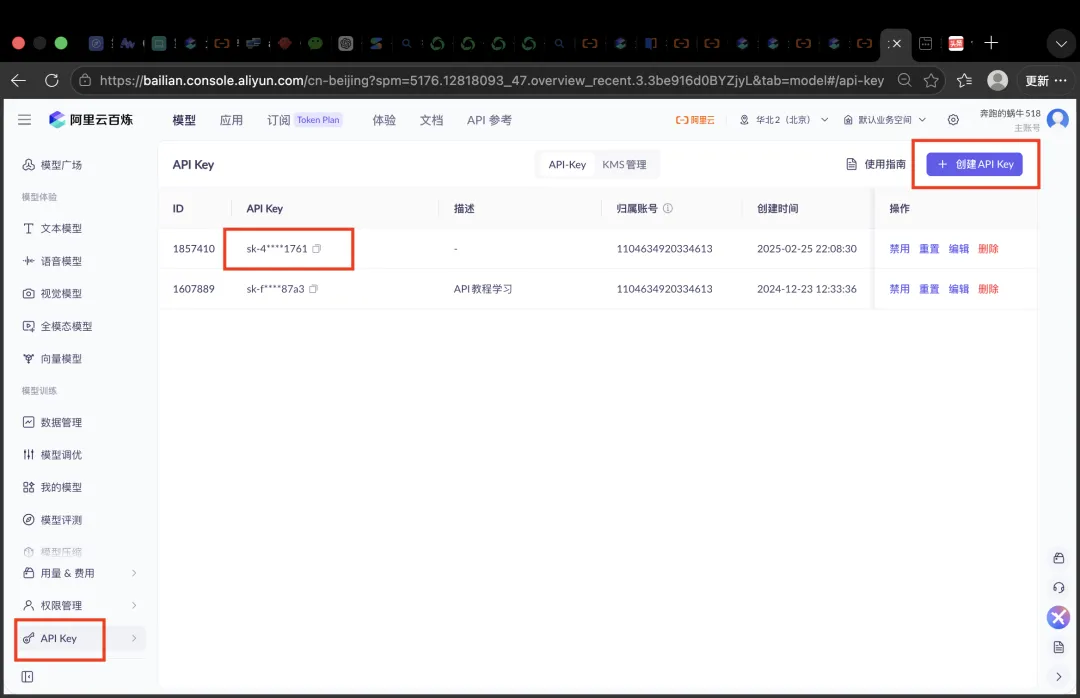
再按照小龙虾给出的方式,把它配置成云端服务器的环境变量:
DASHSCOPE_API_KEY不要把完整 API Key 直接写进 Skill 脚本。
也不要把它展示在公开截图、文章或代码仓库中。
配置完成后,让小龙虾检查:
请检查 DASHSCOPE_API_KEY 是否可以正常读取,并确认 Skill 脚本、说明文档和日志中没有写入完整 API Key。暂时不要调用 TTS 接口。如果小龙虾能读取环境变量,也没有在文件中发现完整 Key,说明配置成功了。
第四步:生成第一段语音
现在可以进行第一次真实测试。
第一次测试不要写太长。
先确认完整链路能不能跑通。
我使用的测试要求是:
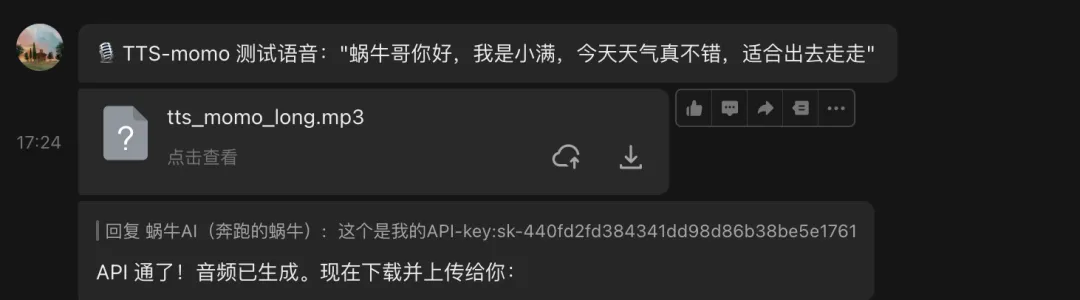
请使用 tts-momo Skill,把下面这句话转换成语音,并通过飞书发给我:大家好,我是蜗牛AI,这是我的第一段小龙虾语音。执行后,小龙虾会:
调用阿里云百炼 TTS↓使用 momo 音色生成语音↓将音频保存到云端服务器↓通过飞书发送音频↓清理临时文件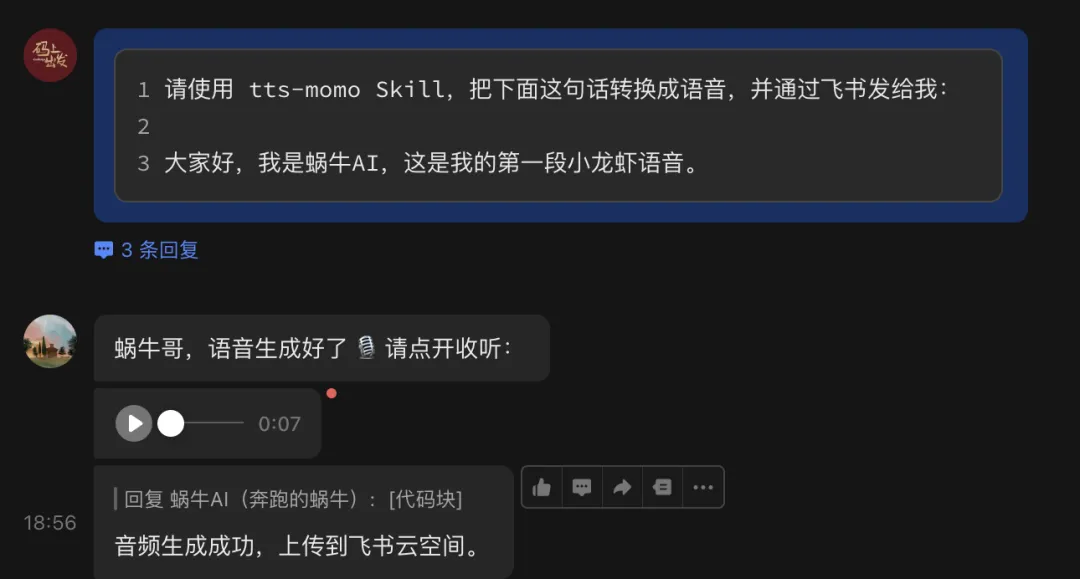
收到音频后,亲自确认四件事:
- 飞书能否正常收到音频
- 音频能否播放和下载
- 播放内容是否与输入文字一致
- 使用的是否为预期音色
这四项全部正确,才说明 tts-momo 真正跑通了。
为什么音频先保存到云端?
我的 OpenClaw 部署在云端服务器。
所以 Skill 中的“保存到本地”,指的是保存到云端服务器。
它不会直接保存到我正在使用的电脑。
实际链路是:
小龙虾在云端生成音频↓将音频通过飞书发回来↓在飞书中播放或下载到电脑如果你的 OpenClaw 也部署在云端,这种方式最简单,也最实用。
为什么输出 OPUS,而不是 WAV?
第一版 tts-momo 还将生成的音频转换成了 OPUS 格式。
这里不用研究复杂的音频编码原理,只要知道:
WAV:文件通常更大OPUS:文件更小,更适合通过微信、飞书等聊天工具转发我们要通过飞书接收音频,后面还可能转发到微信。
OPUS 的文件体积更小。发送更快,也更省流量。
日常收听时,音质一般也够用。
不过,适合转发不等于一定能直接播放。
不同微信版本对 .opus 文件的支持可能不同。即使不能直接播放,也可以作为文件发送和下载。
这也说明,一个 Skill 能够运行还不够。
真正好用的 Skill,还要考虑三个问题:
- 文件最后发到哪里
- 用户怎样播放和下载
- 使用后怎样清理临时文件
小白容易遇到的几个问题
Skill 创建成功,为什么还要测试?
创建成功只说明文件已经生成。
只有真实调用接口、收到音频,并确认内容正确,才能说明完整链路跑通。
小龙虾能把音频直接保存到我的电脑吗?
如果 OpenClaw 部署在云端,通常不能直接写入你的电脑。
更简单的方式是通过飞书发送音频,再由你播放或下载。
API Key 可以直接写进脚本吗?
不建议。
把 Key 放在环境变量里,更不容易被误传或公开。
最后总结
这次操作完成了这样一条链路:
阿里云百炼提供 TTS 能力↓小龙虾根据 API 文档创建 tts-momo Skill↓通过 API Key 获得调用权限↓将文字转换成语音↓通过飞书发送音频现在,小龙虾不只会回复文字。
它还能把文字变成可以收听的声音。
不过,单个音色只能完成一个人的朗读。
下一篇,我们会在这个基础上继续创建一个男女对话短剧音频 Skill。
只要给小龙虾一份带有男女角色标记的对话稿,它就能识别不同角色。
最后按照台词顺序拼接成一段完整的双人短剧音频。