 夜雨聆风
夜雨聆风





让 OpenClaw 演双人对话短剧:创建 tts-drama Skill
大家好,我是蜗牛AI。
上一篇,我们让小龙虾学会了把文字变成语音。
这次继续升级。
让它识别【男】【女】角色,用不同音色生成一段完整短剧音频。
整个流程是:
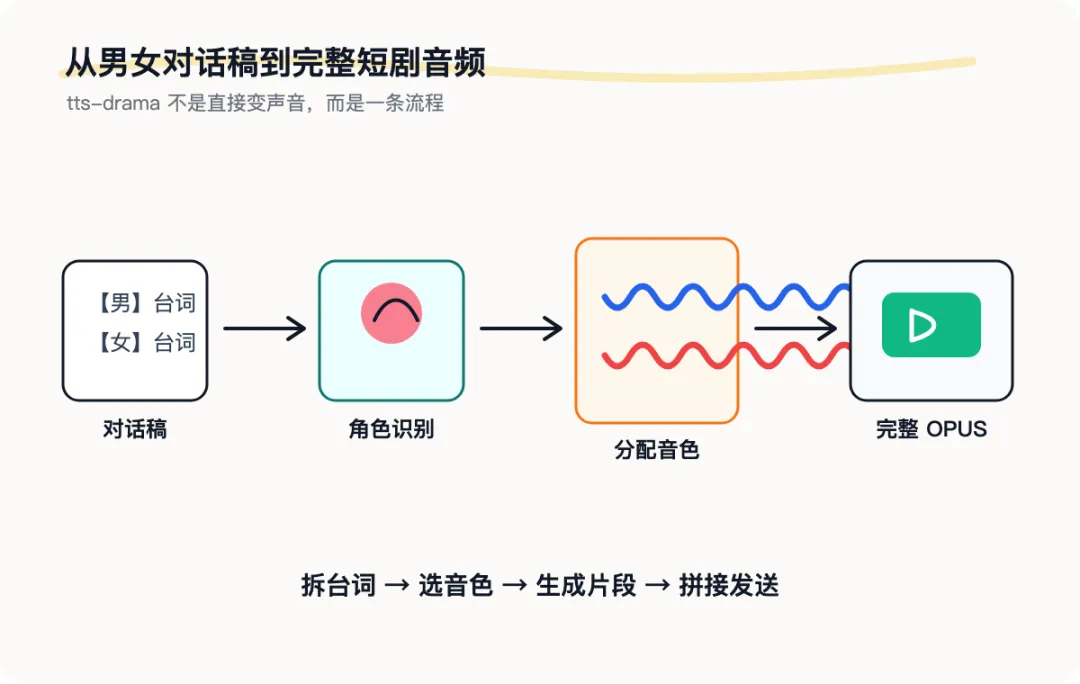
提供带【男】【女】标记的对话稿↓小龙虾调用 tts-drama Skill↓识别男声和女声台词↓分别使用对应音色生成语音↓按台词顺序拼接↓飞书收到完整短剧音频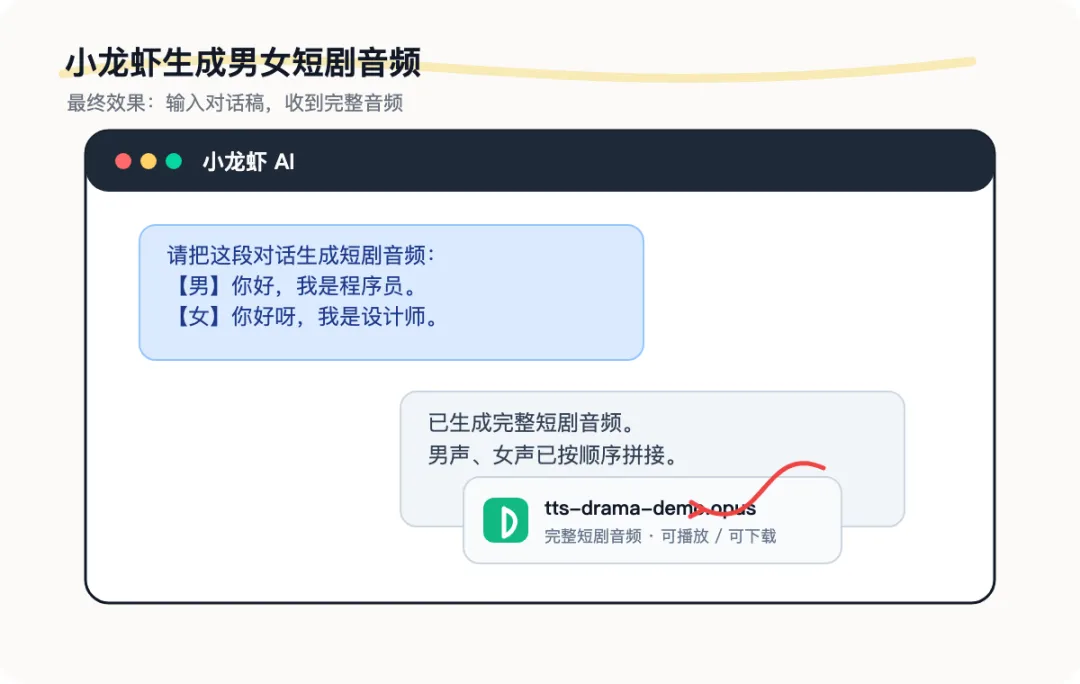
这篇文章只讲一件事:
创建 tts-drama Skill,把已有男女对话稿变成双人短剧音频。
自动读取文章、自动生成播客稿,先不讲。
为什么要做 tts-drama?
tts-momo 已经能生成语音了。
为什么还要再做一个 tts-drama?
原因很简单。
单人朗读和双人对话不是一回事。
单人朗读像一个人在读稿。
短剧对话更像两个人在交流。
如果男女台词都用同一个声音,听起来就会很别扭。
就像一个人一会儿装男生,一会儿装女生。
能听。
但不自然。
所以我们需要一个新的 Skill。
它专门处理多角色对话。
可以这样理解:
tts-momo:把一段文字读出来tts-drama:把一段男女对话演出来这里的关键不是“声音更花哨”。
而是让小龙虾理解角色。
谁说男声。
谁说女声。
顺序不能乱。
内容不能丢。
最后还要拼成一个完整音频。
tts-drama 到底做什么?
先说清楚边界。
这一版 tts-drama 不负责写对话稿。
它只负责把已经写好的对话稿变成音频。
输入内容必须长这样:
【男】你好,我是程序员。【女】你好呀,我是设计师。【男】你觉得 AI 能取代我们吗?【女】哈哈,那得先问问女主同不同意。
这里最重要的是两个标记:
【男】【女】这两个标记就是给 Skill 的信号。
看到【男】,就用男声音色。
看到【女】,就用女声音色。
然后它会按顺序处理:
读取每一行台词↓识别这句话属于男声还是女声↓调用 TTS 生成单句音频↓生成下一句↓把所有音频按原顺序拼接↓输出一个完整 OPUS 音频注意这里有几个要求。
第一,角色标记要稳定。
不要一会儿写【男】,一会儿写“男:”。
格式乱了,小龙虾就容易判断错。
第二,台词顺序不能乱。
短剧音频听的是节奏。
一句错位,整个对话就不对了。
第三,Skill 不应该擅自改写台词。
用户给什么内容,它就照着生成。
这一步不是创作。
这一步是制作音频。
让小龙虾创建 tts-drama
接下来,就可以让小龙虾创建新的 Skill。
这里不要只说一句:
帮我做一个双人语音。这句话太模糊。
小龙虾可能不知道你要的是短剧、播客,还是普通朗读。
更稳的做法,是把输入格式、角色音色、输出方式都说清楚。
我给小龙虾的要求可以这样写:
请帮我创建一个新的 Skill,专门用于生成男女短剧对话音频。要求:1. Skill 名称为 tts-drama。2. 输入是一段带【男】【女】角色标记的对话稿。3. 男声台词使用男声音色。4. 女声台词使用女声音色。5. 按原始台词顺序逐段生成音频。6. 最后将所有音频拼接成一个完整文件。7. 输出格式使用 OPUS,方便在飞书、微信等聊天工具中转发。8. 生成完成后,通过飞书把音频文件发给我。9. 音频发送成功后,清理服务器临时文件。10. 创建完成后先不要调用接口,请告诉我 Skill 的文件位置、目录结构和使用方法。男声音色:[填写实际男声音色]女声音色:[填写实际女声音色]
如果你已经确定了音色,就直接填进去。
比如男声用某个低沉一点的音色。
女声用某个更轻快一点的音色。
这里不要纠结音色名字本身。
重点是让两个角色能明显区分。
还是老规矩。
先让小龙虾创建。
不要一上来就让它调用接口。
先检查结构,再测试。
这样出问题时更容易定位。
创建完成后看什么?
小龙虾创建成功后,会返回类似这样的目录结构:
tts-drama/├── SKILL.md├── scripts/│ └── tts_drama.sh└── references/ └── api-docs.md这几个文件不用一上来全看懂。
先知道它们各自负责什么就行。
SKILL.md 是 Skill 的说明书。
它告诉小龙虾:
什么情况下应该使用 tts-drama。
输入格式是什么。
输出结果是什么。
scripts/tts_drama.sh 是真正干活的脚本。
它负责拆台词、调用 TTS、生成音频、拼接音频、发送文件。
references/api-docs.md 是接口参考文档。
它保存语音合成 API 的参数和调用方式。
看到这些文件,说明 Skill 的骨架已经搭起来了。
但这还不等于成功。
文件创建成功,只能说明“工具做出来了”。
真正成功,要看它能不能跑通。
第一次测试
第一次测试不要写太长。
越短越好。
先确认男女音色、顺序和发送链路都没问题。
可以这样发给小龙虾:
请使用 tts-drama Skill,把下面这段对话生成短剧音频,并通过飞书发给我:【男】你好,我是程序员。【女】你好呀,我是设计师。【男】你觉得 AI 能取代我们吗?【女】哈哈,那得先问问女主同不同意。这段测试稿很短。
但它足够验证核心能力。
它有男声。
有女声。
有来回对话。
也能看出顺序有没有错。
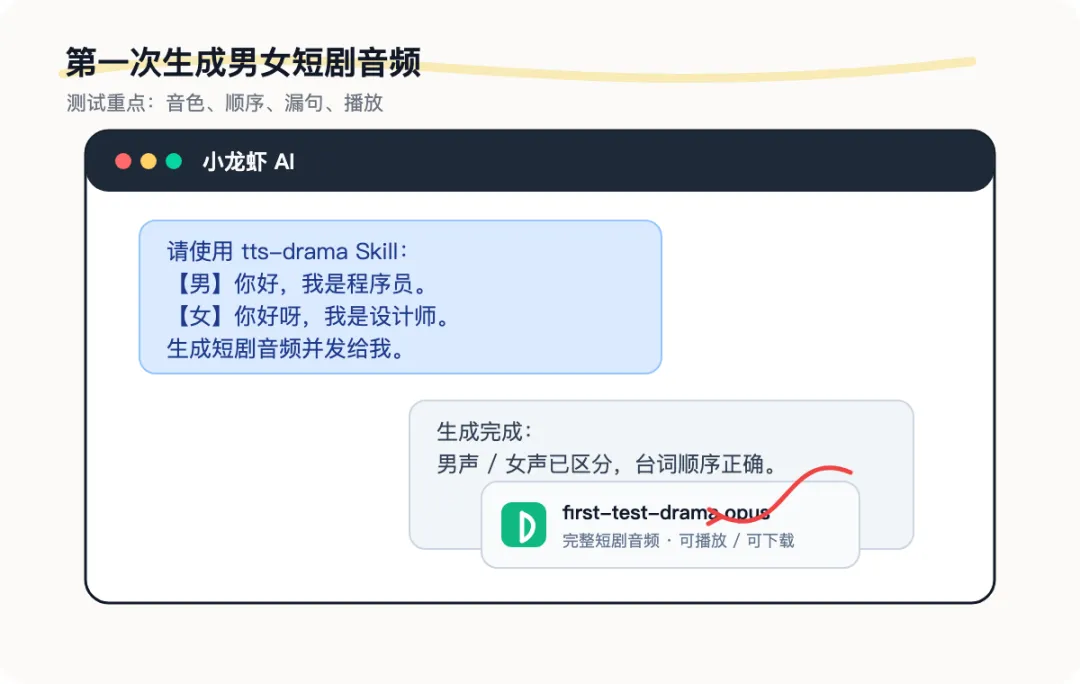
收到音频后,重点检查这几件事:
- 飞书是否收到完整音频
- 男声和女声是否能明显区分
- 台词顺序是否正确
- 有没有漏句
- 有没有把台词改掉
- 音频能否播放和下载
这几项都对,tts-drama 才算真正跑通。
如果只看到小龙虾说“创建完成”,但没有实际生成音频,那还不算完成。
为什么还用 OPUS?
这里继续使用 OPUS。
原因很简单:
短剧音频通常更长。
如果用 WAV,文件会比较大。
发送慢,也占空间。
OPUS 体积小,听感也够用。
更适合通过飞书、微信这类聊天工具转发。
但不同客户端支持不完全一样。
有的可以直接播放。
有的更适合作为文件下载后播放。
所以这里选 OPUS,不是追求最高音质,而是为了方便发送和分享。
这一篇做到了什么?
到这里,小龙虾已经从“会朗读”升级到了“会演对话”。
上一篇是:
文字 → 单音色 → 语音这一篇是:
男女对话稿 → 两个角色 → 两种音色 → 完整短剧音频它不只是多了一个声音。
而是把角色识别、音色分配、分段生成、音频拼接和文件发送串成了一条完整流程。
这才是 Skill 真正有用的地方。
下一篇,我们再继续升级。
现在对话稿还需要提前准备好。
下一步要做的是:
给小龙虾一篇财经文章。
让它自己提炼内容,生成男女对话稿。
然后再调用 tts-drama,做成一段完整双人播客。