 夜雨聆风
夜雨聆风





Mistral OCR 4来了,文档Agent有眼睛了
OCR 4 的重点不是识字,而是让文档 Agent 看懂版面和置信度。
Mistral OCR 4 发布,我怀疑很多人会把它看小了。

“哦,又一个 OCR 。”
不对。至少不只是 OCR 。
这次它新增边界框、块分类、逐页逐词置信度分数,支持 170 种语言、 10 个语系,可单容器自托管。在 OlmOCRBench 上得分 85.20 ,独立标注者偏好率平均 72%。价格是每 1000 页 4 美元, Batch API 半价。
这些数字看起来像产品参数,但背后其实是一件事:文档 Agent 终于开始有“眼睛”了。
识字只是第一层,看懂结构才值钱
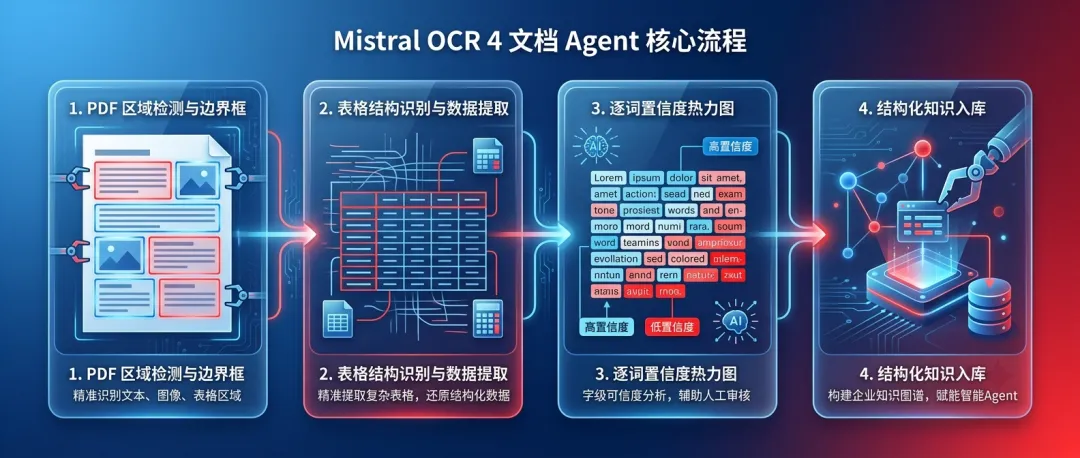
老式 OCR 像一个只会抄字的小学生。它能把 PDF 里的字抠出来,但不知道标题、表格、脚注、签名、公式之间是什么关系。
企业知识库最怕这个。
你把合同、财报、手册、扫描件全丢进 RAG ,模型回答时一本正经地引用错表格、漏掉页脚限制、把签名栏当正文。那种感觉像吃面吃到订书钉,嘴上没事,心里已经骂人了。
Mistral OCR 4 的块分类和边界框就解决一部分问题。它不只是说“这里有字”,而是告诉你“这里是一张表”“这里是标题”“这里可能是签名”。逐词置信度也很关键:模型终于能承认自己哪里看不清。
文档智能的分水岭,不是能不能提取文字,而是能不能知道自己哪里不确定。
Agent 做文件活,最缺的是置信度
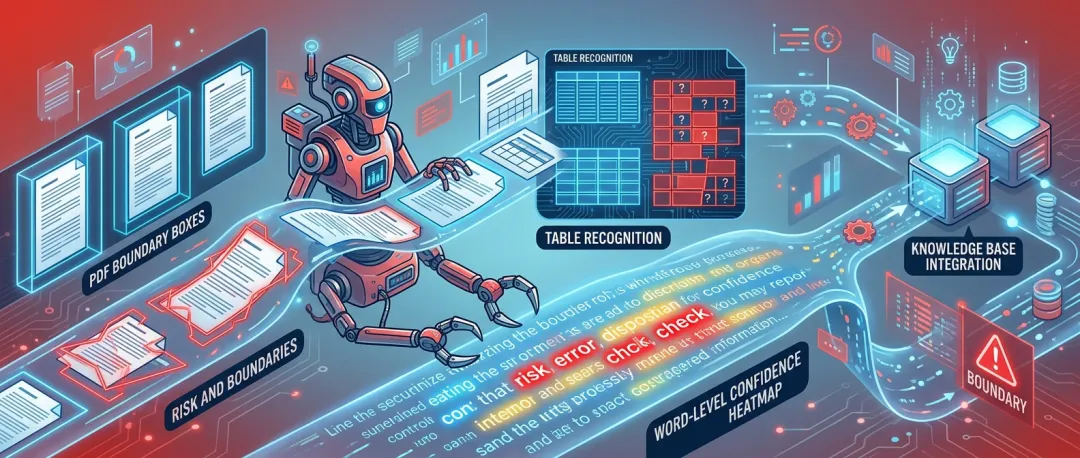
我见过太多文档 Agent demo :上传 PDF ,秒答问题,界面很漂亮。
然后一到真实业务就翻车。
为什么?真实文档不干净。扫描歪了,章盖住字了,表格跨页了,老合同里还有手写批注。 Agent 如果把低置信度内容当铁证,后面推理再聪明也白搭。地基歪了,楼越高越危险。
OCR 4 给逐页逐词置信度,这个设计很工程。你可以设规则:低于某个阈值不进知识库;关键金额、日期、条款如果置信度低,必须人工复核;回答用户时标注“该段识别可信度较低”。
这不性感。
但靠谱。
自托管也有意义。很多企业文档不能出域,尤其合同、医疗、金融、政府材料。单容器部署意味着它更容易塞进企业内网,而不是每份 PDF 都出门旅行一圈。
普通团队怎么用,别直接全量喂 RAG
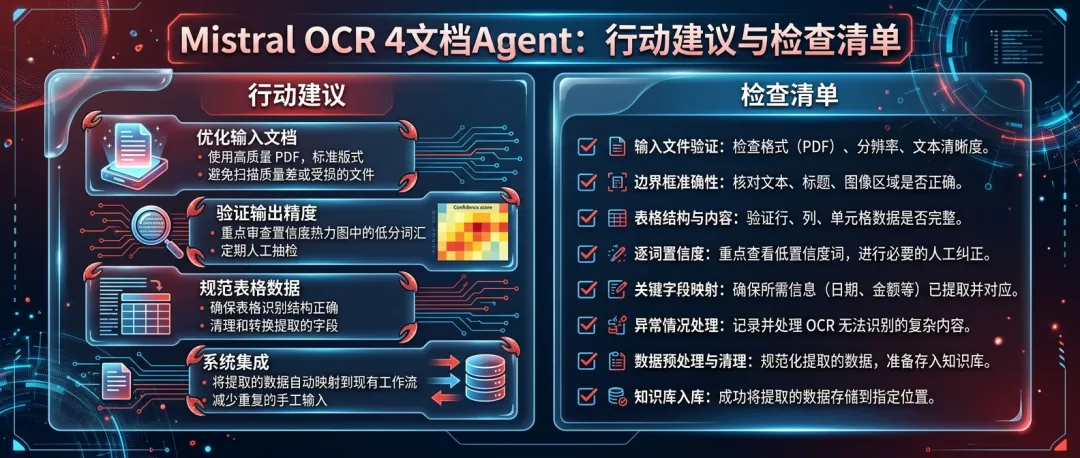
如果你要做文档 Agent ,我建议流程别偷懒。
第一步,先分类再入库。把标题、正文、表格、图片说明、签名块拆开,不要整页糊成一坨 markdown 。第二步,置信度分层。高置信度自动入库,中置信度标记,低置信度进入人工队列。第三步,表格单独处理。表格是 RAG 的事故高发区,别让它和正文混在一起做向量。
如果预算紧, Batch API 半价适合离线批处理;如果隐私敏感,自托管优先。别什么都 API ,别什么都本地,按场景选。
我对 OCR 4 的期待不是“识别更准”。准当然好,但行业真正缺的是可控、可审计、可回滚。
文档 Agent 以后会很强。
前提是,它先学会像人一样低头看清楚纸上到底写了什么。
备选标题:
1. Mistral OCR 4 来了,文档 Agent 有眼睛了
2. 别把 Mistral OCR 4 看轻了,真正变化在后面
3. Mistral OCR 4 背后, AI 行业正在换规则
摘要: OCR 4 的重点不是识字,而是让文档 Agent 看懂版面和置信度。
标签:人工智能、 Document AI 、 Mistral OCR 、 OCR 、知识库
素材来源: AIHOT : Mistral AI 发布 OCR 4 ,支持边界框、块分类、逐页逐词置信度, 170 种语言, OlmOCRBench 85.20 。