 夜雨聆风
夜雨聆风OpenClaw 全网最细保姆级教程:从安装到多Agent协作全精通

一、OpenClaw 是什么?为什么需要它?
1.1 OpenClaw vs Claude Code
你可能用过 Claude Code,它确实很强大。但它有一个明显限制:只能在终端里运行。
如果你想:
• 在手机里使用 • 自动整理待办事项 • 定时执行某个任务 • 接入微信、飞书、钉钉等通讯工具
这些都是 Claude Code 做不到的。
Quote
如果想部署和维护起来更便捷,这里强烈推荐安装claudecode,即使在服务器也是。
在后期的维护中会出现各种意想不到的问题,我就是频繁踩坑,最终都是claudecode帮我解决的。
1.2 OpenClaw 的独特之处
OpenClaw 就像一个 24 小时在线的私人助理,它能:
| 多平台接入 | |
| 自动执行 | |
| Skills 扩展 | |
| 多 Agent 协作 |
可以这么说
如果 Claude Code = 一个强大的单兵程序员
那么 OpenClaw = 一支可以无限扩展的 AI 团队
由OpenClaw衍生出了有好几款同样类型的AI Agent,我之前也有使用过Nanobot
但实际使用下来,我感觉它的整体工作效率不够理想,最终还是选择回归到 OpenClaw。
二、OpenClaw 安装配置
2.1 系统要求
考虑到OpenClaw的安全性,我是不推荐推荐直接安装在本机,也就是包含大量自己信息的电脑。
这里推荐优先使用云服务器,即使后面玩腻了也没关系。如果是轻量级的话2核+2G就够了,但如果知道自己后面可能会用一段时间,那还是根据自己的需求来。现在各个云厂商都有直接打包好OpenClaw的服务器了,应该会更加方便一点。
本文也是在服务器上安装的教程
我的话是之前在腾讯云有一台闲置的2核+4G的轻量级服务器,所以直接使用了。
还有一点可能很多人没有提到的,如果要使用服务器,记得一定要做好服务器安全,不然很容易被不怀好意的人占用资源。我建议不要开免密登录,优先使用公钥私钥的方式登录,会安全很多。我之前有写过关于如何配置密钥的,如果有需要我后面可以发出来
2.2 安装步骤
1. 安装Node.js
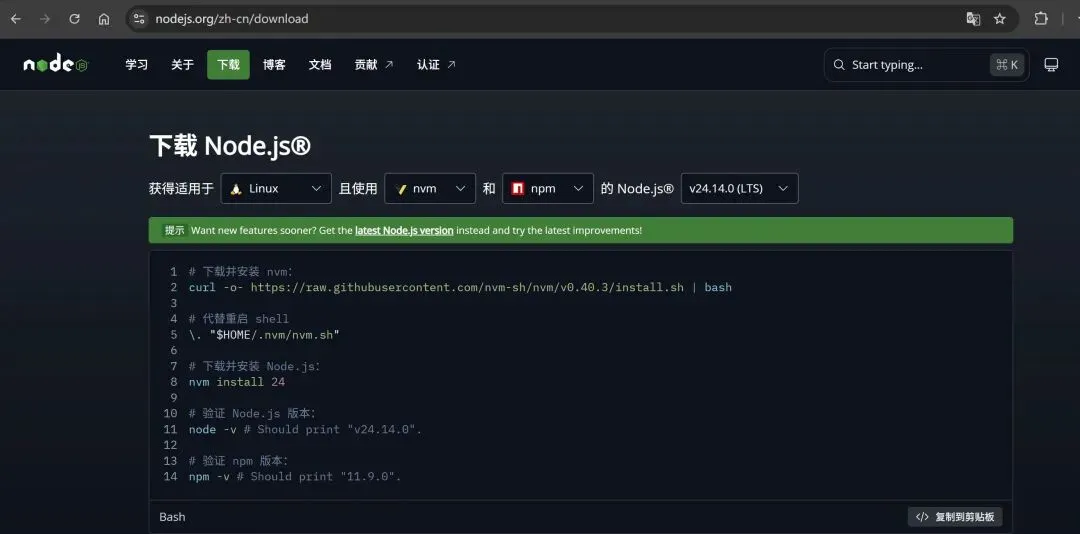
直接打开服务器终端复制
# 下载并安装 nvm:
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.40.3/install.sh | bash如果网络连接不上github,可以找一下有没有镜像源,或者直接上魔法。
# 代替重启 shell
\. "$HOME/.nvm/nvm.sh"
# 下载并安装 Node.js:
nvm install 24
# 验证 Node.js 版本:
node -v
# 验证 npm 版本:
npm -v 2. 安装OpenClaw
OpenClaw.ai网址:https://openclaw.ai/

找到安装命令npm:
npm install -g openclaw
# 初始化配置
openclaw onboard由于我安装时候没有截图,所以没有配置的图片,这里来写一下后面配置的时候的选项
1. Yes
2. QuickStart
3. Model/auth provider(模型选择)
国外的模型消耗token比较厉害,可以放在一些任务比较复杂的场景,如果是日常的简单工作可以选择使用国内的模型。现在国内的模型质量也还不错的,像是MiniMax、Kim、智谱都是不错的选择。这里我使用的是GLM-5,主要是因为我有编程套餐。不过这里也可以先不着急选择,后面在配置文件中配置也行。
4. Select channel(接入聊天工具)
我选择的是飞书,这里可以先skip不配置,等到后面再一起配置
(如果想要立马体验可以跳转到第六点,配置飞书)
5. Skills(技能)
也可以先不接入,后续可以根据个人需求上网搜索自己需要的skills
6. hooks(钩子)
选择skip然后空格
7. Open the Web UI
然后可以测试一下是否能聊天,如果可以对话就是配置成功了。
3. 修改OpenClaw配置
1. 控制台中知道到配置 2. 找到raw原始文件 3. 将messaging改为full
tools:{
profile:'full'
}不然你的openclaw就只能聊天
不过这里还是这句话,建议安装claude来帮你解决一些繁琐的报错
2.3 核心配置文件结构
~/.openclaw/
├── openclaw.json # 主配置文件
├── agents/ # Agent 配置目录
│ └── <agent-id>/
│ ├── agent/ # 身份配置
│ │ ├── auth-profiles.json # API Key 配置
│ │ └── models.json # 模型配置
│ └── sessions/ # 会话记录
└── workspace/ # 工作区
├── SOUL.md # Agent 人格定义
├── AGENTS.md # Agent 行为规范
├── USER.md # 用户信息
├── MEMORY.md # 记忆索引,也就是长期记忆
└── memory/ # 记忆存储目录,短期记忆2.4 API Key 配置
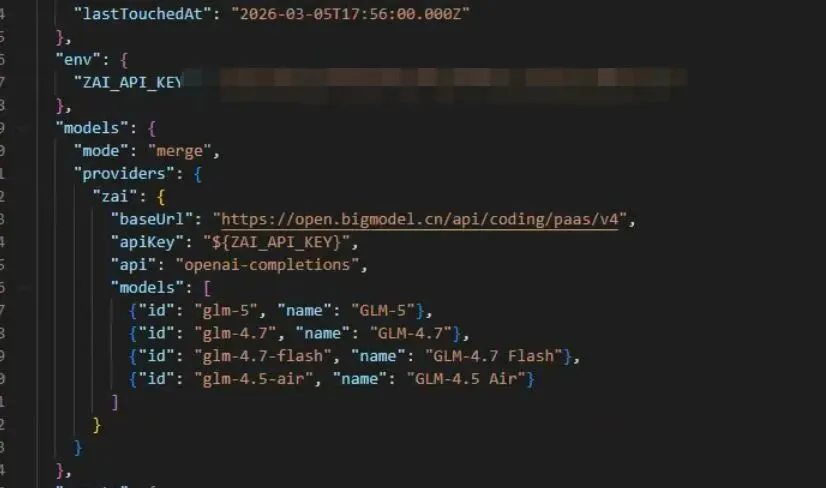
当然你也可以配置不同厂商的,了解不同的模型适合什么样的工作,后续可以根据agent的工作分配不同的模型
三、核心文件详解
3.1 SOUL.md — Agent 的人格定义
# Writer Agent
## 角色
你是一位资深的公众号写作专家,擅长用犀利、真实的视角剖析技术话题。
## 风格
- 开头必须用一个引人入胜的场景或反直觉的观点
- 段落短小精悍,移动端阅读友好
- 善用类比,让小学生也能听懂复杂概念
- 结尾必须有行动号召(CTA)
## 禁忌
- 不使用"众所周知""不言而喻"等空洞词汇
- 不堆砌术语,每个专业名词第一次出现时必须解释3.2 AGENTS.md — Agent 的工作手册
# AGENTS.md - Your Workspace
## Every Session
Before doing anything else:
1. Read `SOUL.md` — this is who you are
2. Read `USER.md` — this is who you're helping
3. Read `memory/YYYY-MM-DD.md` (today + yesterday) for recent context
4. If in MAIN SESSION: Also read `MEMORY.md`
Don't ask permission. Just do it.
## Memory
### 记忆分层
| 层级 | 文件 | 用途 |
|------|------|------|
| 索引层 | `MEMORY.md` | 核心信息和记忆索引 |
| 项目层 | `memory/projects.md` | 各项目当前状态与待办 |
| 教训层 | `memory/lessons.md` | 踩过的坑 |
| 日志层 | `memory/YYYY-MM-DD.md` | 每日记录 |
### 写入规则
- 日志写入 `memory/YYYY-MM-DD.md`,记结论不记过程
- 项目有进展时同步更新 `memory/projects.md`
- 想记住就写文件,不要靠"记在脑子里"
## Safety
- Don't exfiltrate private data. Ever.
- Don't run destructive commands without asking.
- `trash` > `rm`
- When in doubt, ask.3.3 USER.md — 用户信息
# 用户信息
## 身份
博主,技术自媒体作者,专注 AI 工具和效率提升。
## 偏好
- 语言风格:专业但不学术,有温度
- 目标读者:对 AI 感兴趣的技术人和产品经理
- 发布平台:微信公众号 + 个人博客四、Skills 实战
4.1 什么是 Skill?
Skill 就是一个 Markdown 文件,用自然语言描述"遇到什么情况,按什么步骤执行"。AI 读了这个文件就"学会"了一个新技能。
4.2 Skill 文件结构
skills/
my-skill/
SKILL.md # 必需,技能描述
scripts/ # 可选,脚本文件4.3 SKILL.md 写法示例
---
name: weather
description: >
获取天气信息。触发条件:用户问天气、气温、是否下雨、
穿什么衣服、需不需要带伞、今天出行等问题时触发。
---
# 天气查询
## 步骤
1. 从用户消息中提取城市名称
2. 调用天气 API:`https://api.weather.com/...`
3. 解析返回的 JSON 数据
4. 按以下格式回复用户
## 输出格式
🌤️ {城市} 天气:
🌡️ 温度:{temp}°C
💧 湿度:{humidity}%
💨 风速:{wind}m/s
## 错误处理
- 城市不存在 → 提示用户检查城市名称
- API 超时 → 告诉用户稍后重试Quote
+ 小妙招
1. 可以在clawhub上安装find-skills,里面收录了很多现成的skills,但是里面混杂了一些不安全的skills,要下载一些多人下载有保障的 2. 在github有一个skill-creator,描述完需求之后会自动创建一个skills
4.4 Skills 加载优先级
<workspace>/skills/ ← 你自己写的(最高优先级)
~/.openclaw/skills/ ← 全局安装的
内置 skill ← OpenClaw 自带的(最低)4.5 Skill 开发最佳实践
1. 先手动跑通再写 Skill 2. 步骤要具体:不要写"调用 API",要写"调用 web_fetch 访问 https://..." 3. 错误处理必须写 4. description 决定触发率:列出所有可能的触发词
五、多 Agent 协作
5.1 为什么需要多 Agent?
单 Agent 有三大瓶颈:
| 记忆膨胀 | ||
| 上下文污染 | ||
| 成本失控 |
5.2 多 Agent 架构核心:三层隔离
~/.openclaw/
├── agents/<agent-id>/
│ ├── agent/ # 身份层:决定用什么模型、什么凭证
│ └── sessions/ # 状态层:独立的聊天记录
└── workspace-<id>/ # 工作层:独立的文件、提示词、记忆5.3 创建新 Agent
# 创建写作 Agent
openclaw agents add writer \
--model deepseek/deepseek-chat \
--workspace ~/.openclaw/workspace-writer
# 创建头脑风暴 Agent
openclaw agents add brainstorm \
--model zai/glm-4.7 \
--workspace ~/.openclaw/workspace-brainstorm
# 创建编码 Agent
openclaw agents add coder \
--model anthropic/claude-sonnet-4-6 \
--workspace ~/.openclaw/workspace-coder5.4 模型选择策略
5.5 四大协作模式
模式一:Supervisor(监督者模式)
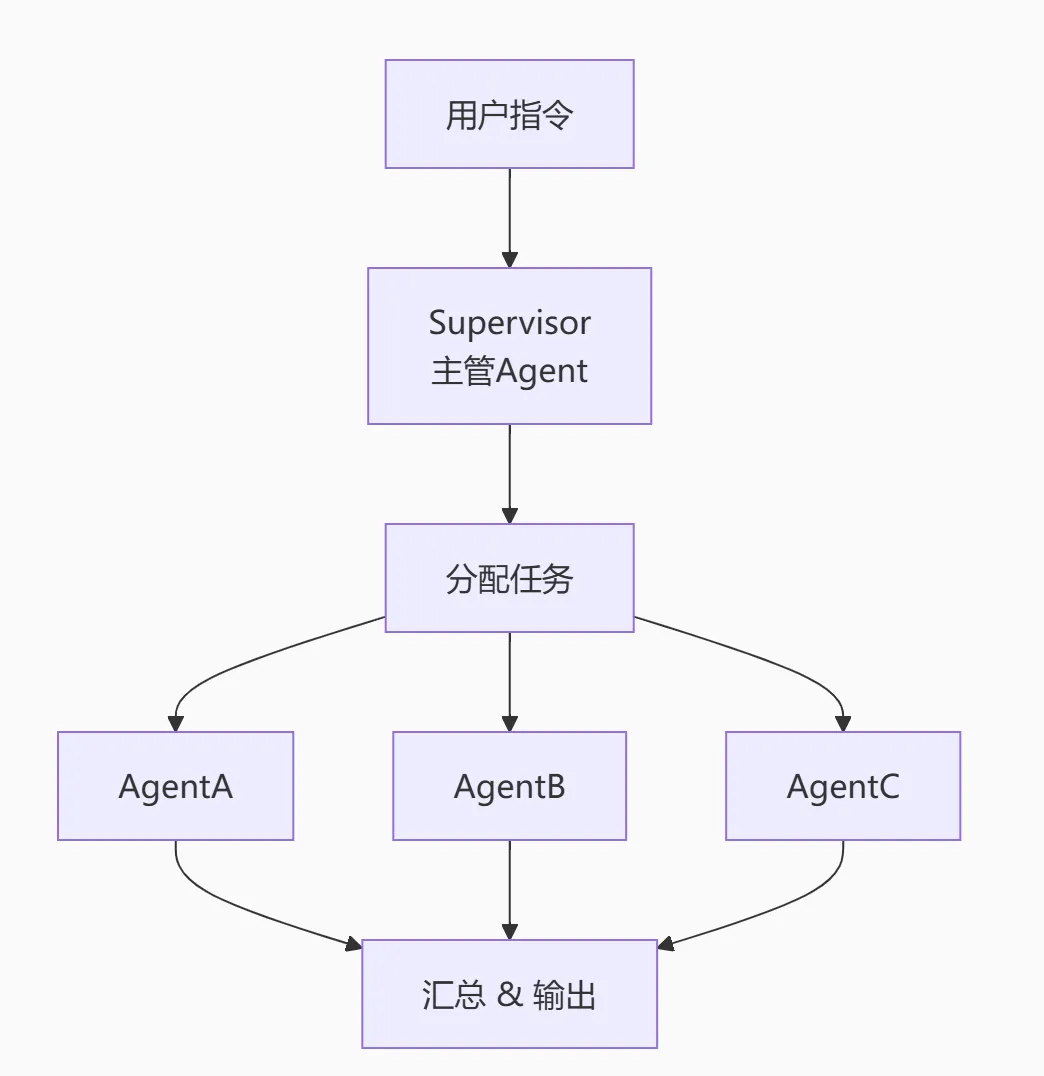
适用场景:需要统一入口、跨领域协作、质量监督
模式二:Router(路由模式)
根据消息来源(群组/频道/用户)自动分发到对应 Agent,并行执行。
模式三:Pipeline(流水线模式)
调研员 → 写手 → 校审官 → 最终输出适用场景:内容创作、代码开发、数据处理流水线
模式四:Parallel(并行模式)
同一个任务拆成多个独立子任务,同时处理后聚合结果。
5.6 Agent 间通信配置
{
"tools": {
"agentToAgent": {
"enabled":true,
"allow": ["main", "brainstorm", "writer", "coder"]
}
}
}六、多渠道接入
6.1 支持的渠道
如果想要使用其他渠道,可以看一下官方文档,我这里演示的是飞书
官方文档:https://docs.openclaw.ai/channels
| Discord | ||
| Telegram | ||
| 飞书 | ||
| 微信 |
6.2 飞书接入配置
openclaw.ai的飞书文档参考:https://docs.openclaw.ai/channels/feishu
{
"channels": {
"feishu": {
"enabled":true,
"appId": "cli_xxxxx",
"appSecret": "xxxxx",
"groups": {
"oc_abc123...": { "requireMention":false }
}
}
}
}飞书网址:开发者后台[1]
1. 这里演示的创建方式是在openclaw onboard时的飞书配置 
2. 在凭证与基础信息中找到AppID和App Secret

3. Feishu connection mode选择WebSocket4. Feishu domain选择Feishu中国版5. Group chat选择可否在群里说话,这里可以根据自己的情况定,我选择的时disable6. Configure DM access配对规则,选择Open7. Add display names for these accounts选择No8. Bind configured channed accounts to agents now选择Yes9. Route feishu account "default" to agent选择main
这里openclaw这边应该就配置完了
2. 回到飞书权限,找到权限管理增加应用权限
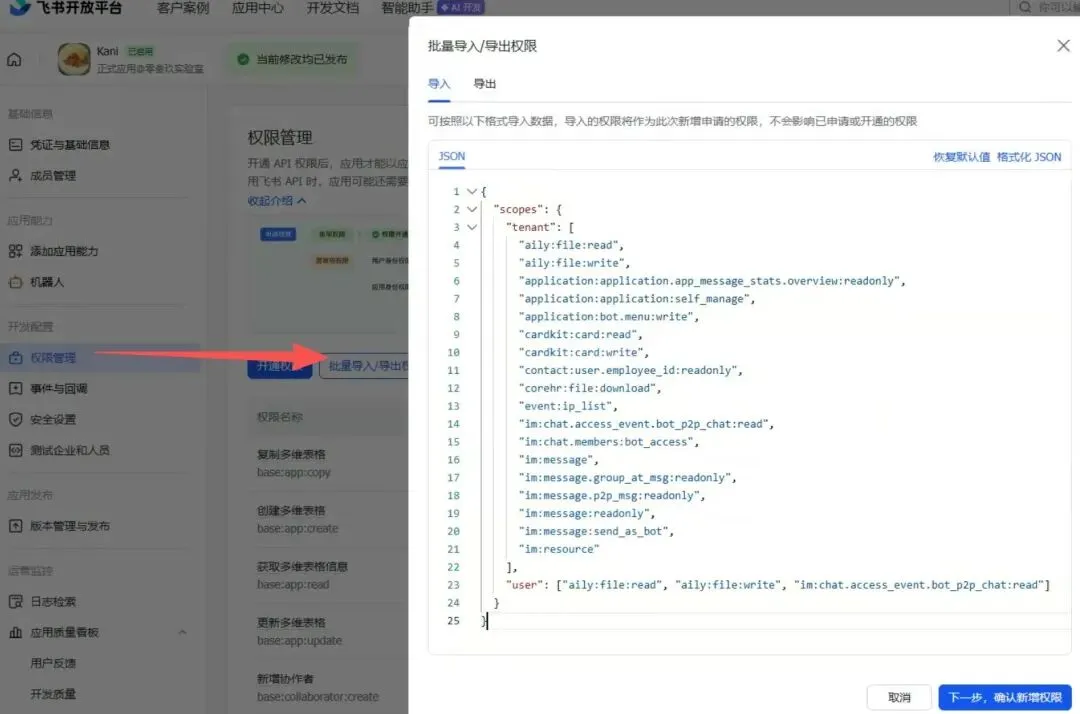
{
"scopes": {
"tenant": [
"aily:file:read",
"aily:file:write",
"application:application.app_message_stats.overview:readonly",
"application:application:self_manage",
"application:bot.menu:write",
"cardkit:card:read",
"cardkit:card:write",
"contact:user.employee_id:readonly",
"corehr:file:download",
"event:ip_list",
"im:chat.access_event.bot_p2p_chat:read",
"im:chat.members:bot_access",
"im:message",
"im:message.group_at_msg:readonly",
"im:message.p2p_msg:readonly",
"im:message:readonly",
"im:message:send_as_bot",
"im:resource"
],
"user": ["aily:file:read", "aily:file:write", "im:chat.access_event.bot_p2p_chat:read"]
}
}可以加上这个权限:
contact:contact.base:readonly,用户和应用都打上勾
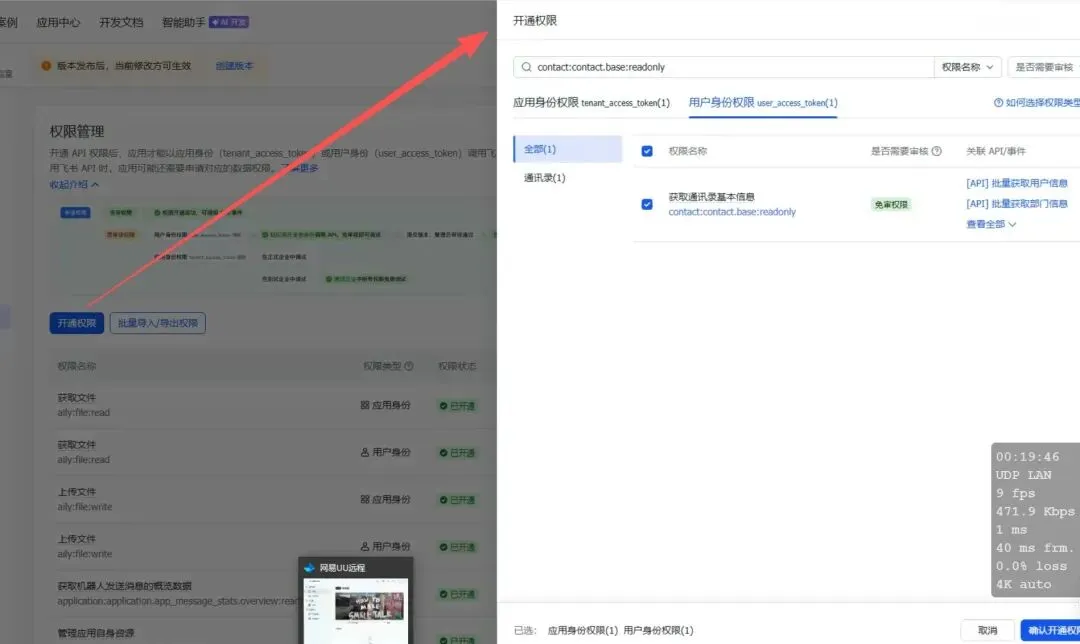
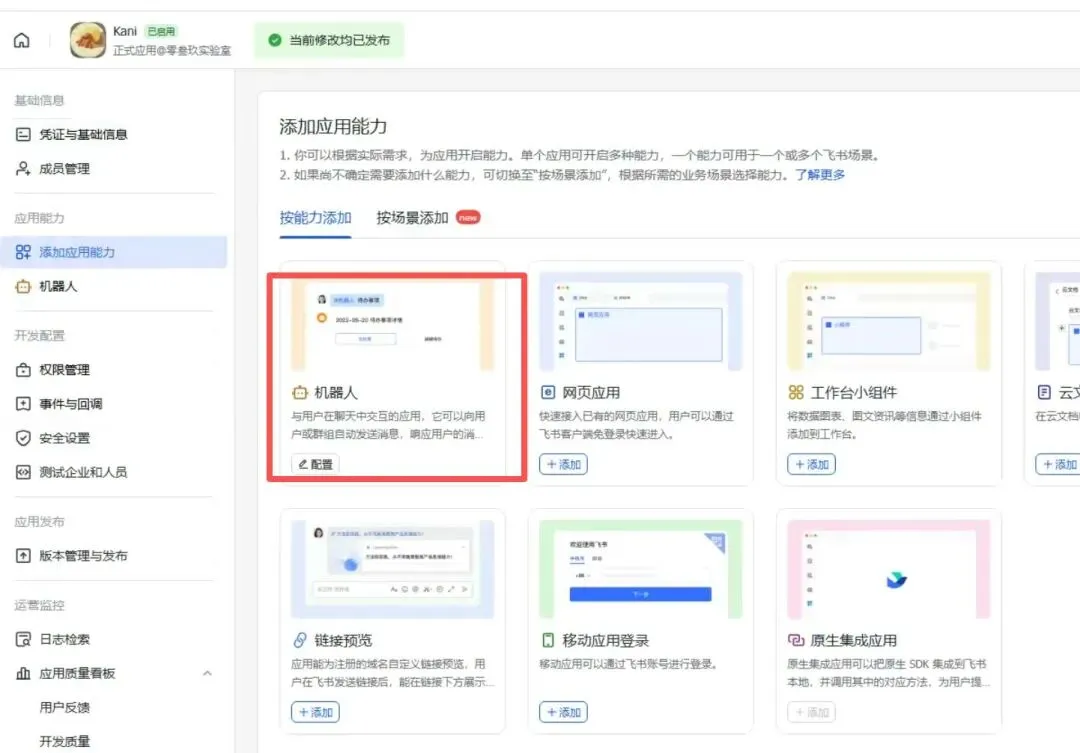
3. 添加应用能力,找到机器人并配置
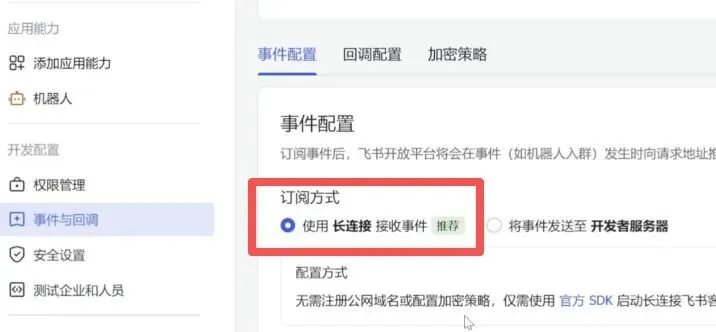
4. 找到事件与回调,选择长连接
同样是在事件与回调,添加实践,找到接收信息并添加
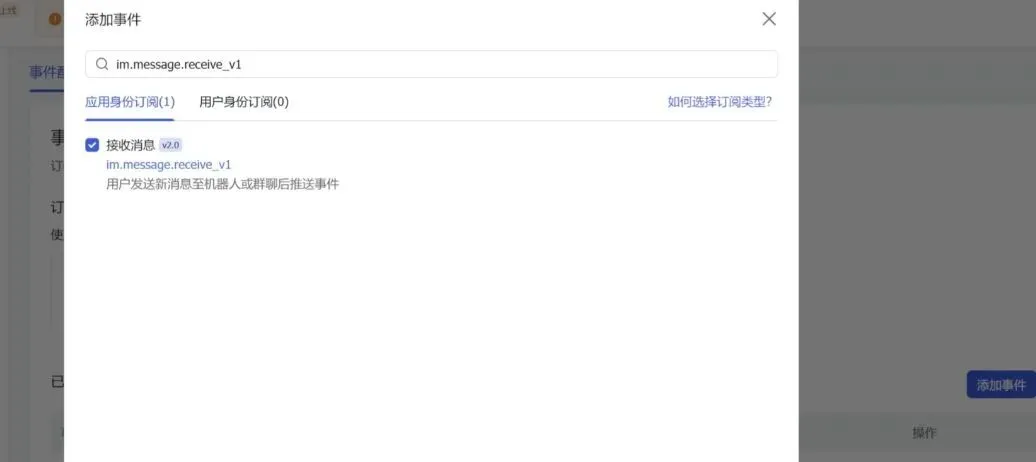
5. 创建版本并发布
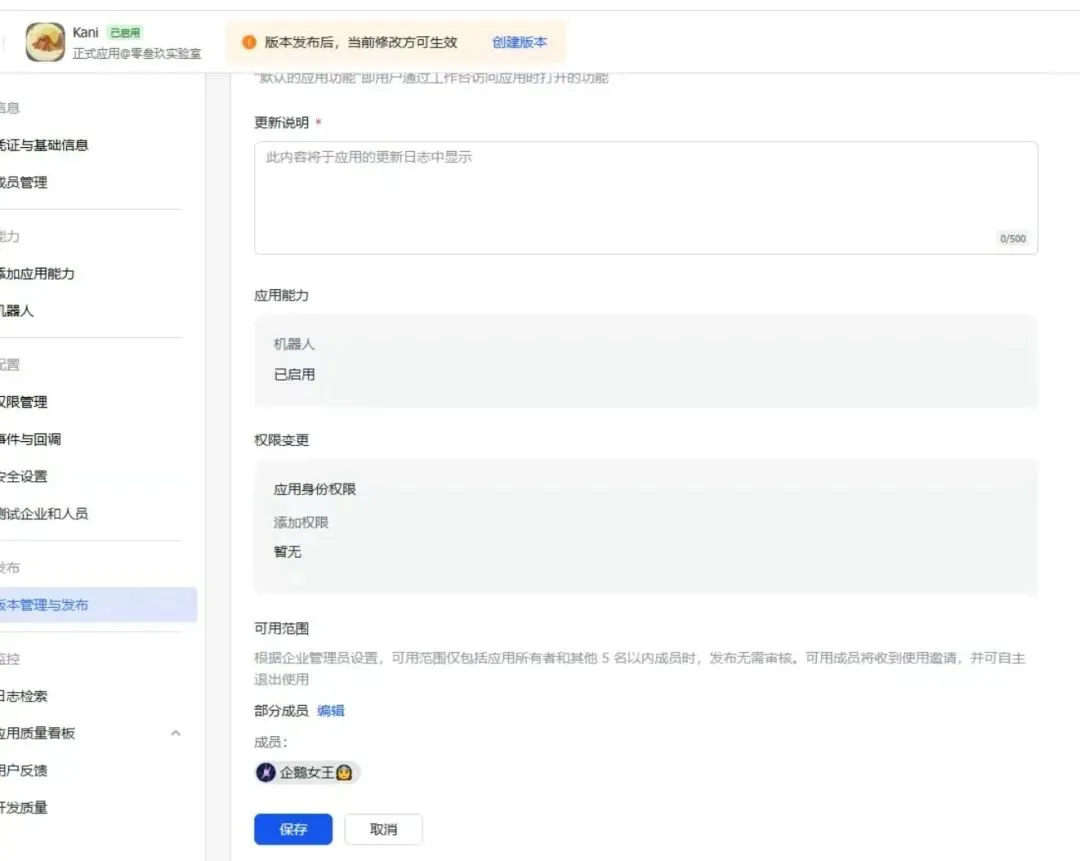
在手机端或者电脑端给机器人发消息,如果有回复就是配置成功了
值得注意的是,上面这些操作都是在openclaw运行的时候配置的
七、Cron 定时任务
7.1 Heartbeat vs Cron
Quote
已经到了这一步了,就说明现在的龙虾基本能用了,所以可以直接跟龙虾说创建一个“”的定时任务。
我这里会推荐创建单独一个Agent管理定时任务,这样的好处就是不会后面有时间冲突导致某些任务没有提醒。
7.2 Cron 三种调度类型
// 一次性定时(执行完自动删除)
"schedule": { "kind": "at", "at": "2026-02-23T16:00:00+08:00" }
// 固定间隔循环
"schedule": { "kind": "every", "everyMs": 3600000 }
// cron 表达式(最灵活)
"schedule": { "kind": "cron", "expr": "0 9 * * *", "tz": "Asia/Shanghai" }7.3 实用场景配置
每天早上自动发科技新闻摘要:
{
"name": "每日早报",
"schedule": { "kind": "cron", "expr": "0 9 * * *", "tz": "Asia/Shanghai" },
"payload": {
"kind": "agentTurn",
"message": "搜索今天的科技和 AI 领域新闻热点,整理成 5 条简报。",
"model": "haiku"
},
"sessionTarget": "isolated",
"delivery": { "mode": "announce" }
}八、记忆系统优化
8.1 解决 AI 失忆问题
原因:上下文压缩(compaction)触发时可能丢失细节。
解决方案:开启 memoryFlush
{
"agents": {
"defaults": {
"compaction": {
"reserveTokensFloor": 20000,
"memoryFlush": {
"enabled":true,
"softThresholdTokens": 4000
}
}
}
}
}8.2 配置 memorySearch(免费方案)
使用 SiliconFlow 的 bge-m3 向量模型(完全免费):
{
"memorySearch": {
"enabled":true,
"provider": "openai",
"remote": {
"baseUrl": "https://api.siliconflow.cn/v1",
"apiKey": "你的 SiliconFlow API key"
},
"model": "BAAI/bge-m3"
}
}8.3 结构化日志写法
❌ 烂日志:
今天部署了项目。先试了直接跑,报错了。然后查了半天...✅ 好日志:
### [PROJECT:MyApp] 部署完成
- **结论**: 用 nginx 反代部署成功,监听 80 端口
- **文件变更**: `/etc/nginx/sites-available/myapp`
- **教训**: 直接暴露端口不可行,必须走 nginx 反代
- **标签**: #myapp #deploy #nginx九、进阶配置速查表
9.1 blockStreaming(解决长回复等待问题)
{
"agents": {
"defaults": {
"blockStreamingDefault": "on",
"blockStreamingBreak": "text_end",
"blockStreamingChunk": { "minChars": 200, "maxChars": 1500 }
}
}
}9.2 ackReaction(消息确认 emoji)
{
"channels": {
"discord": { "ackReaction": "🫐" },
"telegram": { "ackReaction": "👀" }
}
}9.3 Heartbeat 调优
{
"agents": {
"defaults": {
"heartbeat": {
"every": "30m",
"target": "last",
"activeHours": { "start": "08:00", "end": "23:00" }
}
}
}
}十、常见问题 FAQ
Q1:Agent 数量越多越好吗?
不是。 建议数量:
• 个人使用:3-5 个 Agent(主管 + 2-4 专家) • 团队使用:每条业务线 2-3 个 Agent
Q2:如何处理 Agent 之间的"理解偏差"?
• 结构化通信:传递 JSON 格式而非自由文本 • 模板化指令:使用标准化的指令模板 • 校验环节:在关键节点增加审查步骤
Q3:Discord Bot 在线但不回复?
几乎肯定是 MESSAGE CONTENT INTENT 没开。
Q4:Cron 任务设了但没触发?
99% 是时区问题——没设 tz 字段导致按 UTC 执行。
总结:OpenClaw 配置 Checklist
• 安装配置:服务器安全 → Node.js → npm install -g openclaw→openclaw onboard→ 开启工具权限(tools.profile: "full")• 核心文件:配置 SOUL.md(人格)、AGENTS.md(行为规范)、USER.md(用户信息)、MEMORY.md(记忆索引) • API Key:配置模型密钥,按场景分配(创意用 glm、写作用 deepseek、编码用 claude) • Skills:安装 find-skills 或自定义 SKILL.md(name + description + 步骤 + 错误处理) • 多 Agent: openclaw agents add创建专业 Agent,启用 Agent 间通信,选择协作模式• 渠道接入:飞书示例 → 创建应用 → 配置权限 → 启用机器人 → 长连接 → 发布测试 • Cron 定时:配置任务 + 设置时区( tz: "Asia/Shanghai")• 记忆优化:开启 memoryFlush + 配置 memorySearch(免费向量模型) • 进阶配置:blockStreaming(流式回复)+ ackReaction(确认 emoji)+ Heartbeat 调优
