 夜雨聆风
夜雨聆风老王端着茶杯慢悠悠地走过来:“之前那篇从 OpenClaw 卸载切入到面试题的文章,我看反响不错。要不要再整一篇深度点的?飞书多应用接入、多 Agent 路由、Gateway 架构这些,都是面试官爱问的点。”
我说:“正有此意。上一篇文章刚发出去一个小时,阅读就冲到了 7000 多,点赞转发也很猛,说明大家对这种面试题拆解是真的有需求。”
上一篇在这里,没看过的小伙伴可以先补一眼:
https://mp.weixin.qq.com/s/z02mZYqn3Wv-euhhPIBYGQ
我说:“这次咱们从飞书多应用接入、dmPolicy 策略、Gateway 网关架构、消息排查实战,还有最新版本特性这几个层面,把 OpenClaw 扒个底朝天。”
老王笑了:“我就喜欢你这股子钻研劲儿。开始吧。”
01、飞书多应用接入
老王没让我铺垫太久,直接追问:“为什么要一个飞书应用跑一个 Agent?”
我说:“因为隔离。企业场景里最怕的不是配不起来,而是权限、路由、审计和故障域全搅在一起。一个 Agent 对应一个飞书应用,边界才清楚。”
多应用配置的核心逻辑
OpenClaw 的飞书插件支持多应用配置,核心在于defaultAccount字段。当你在openclaw.json里配置了多个飞书应用时,必须指定一个默认应用:
{
"channels": {
"feishu": {
"defaultAccount": "app1",
"accounts": [
{
"appId": "cli_xxx1",
"appSecret": "xxx",
"encryptKey": "xxx",
"verificationToken": "xxx"
},
{
"appId": "cli_xxx2",
"appSecret": "xxx",
"encryptKey": "xxx",
"verificationToken": "xxx"
}
]
}
}
}
老王打断我:“等会儿,这个defaultAccount到底起什么作用?”
我说:“当 Gateway 收到一条消息时,如果无法通过 bindings 规则匹配到特定 Agent,就会用 defaultAccount 指定的应用来响应。它是兜底策略。”
配对策略:让机器人认识你是谁
老王继续追问:“配对我知道。我想听的不是名词解释,而是它在企业场景里到底解决什么问题?”
我说:“配对是 OpenClaw 的一个安全机制。默认情况下,机器人不会响应任何消息,除非你主动完成配对。”
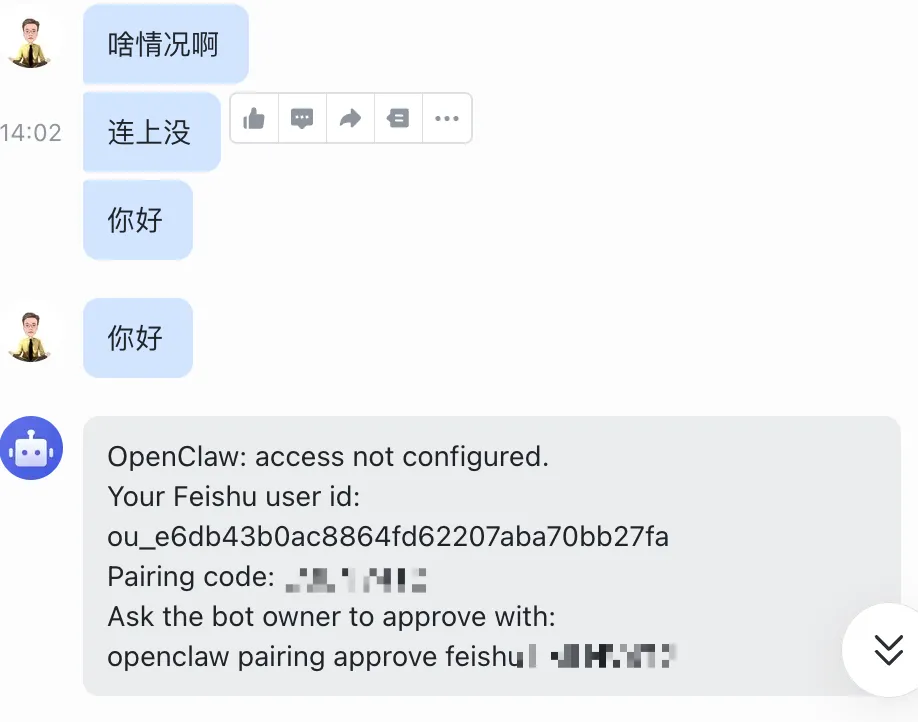
配对的方式有两种:
第一种,私聊配对。你在飞书里搜机器人,发一条私聊消息,机器人会回复一个配对码。把这个配对码告诉OpenClaw,你们就建立了一对一关系。
openclaw pairing approve feishu xxx
第二种,群组配对。把机器人拉到群里,@它发送配对指令。机器人会识别群 ID,把这个群加入白名单。
老王问:“为什么要这么麻烦?直接让机器人响应所有消息不行吗?”
我说:“安全第一。你想想,如果机器人对所有人开放,万一有人恶意刷接口,你的 token 分分钟被烧光。配对机制相当于加了一层访问控制。”
企业级部署的最佳实践
如果让我做企业级部署,我会这样规划:
开发环境:一个飞书应用,绑定测试群组 生产环境:一个飞书应用,绑定正式群组 专用 Agent:每个业务场景单独一个应用,比如代码审核 Agent、运维 Agent、客服 Agent
老王点点头:“这样确实清晰。那如果两个应用都加了同一个群,消息会发给谁?”
我说:“这就涉及到路由优先级了。OpenClaw 采用'最具体优先'原则——如果 bindings 里明确指定了群 ID 绑定到某个 Agent,就按 bindings 走;如果没指定,就用 defaultAccount 兜底。但两个应用同时响应同一个群,这种情况要尽量避免,容易乱。”
02、多 Agent 路由机制
老王放下茶杯:“刚才你说到 bindings,这个多 Agent 路由到底是怎么工作的?”
我说:“这里最核心的不是名词,而是组合关系。真正决定多 Agent 路由的,就是 dmPolicy 和 bindings 这两个点。”
dmPolicy:私信访问控制
dmPolicy 全称 Direct Message Policy,控制机器人如何处理私信。有三种策略可选:
{
"dmPolicy": {
"app1": "allow", // 允许所有私信
"app2": "deny", // 拒绝所有私信
"app3": "pairing"// 只允许配对过的用户私信
}
}
老王问:“实际场景中怎么选?”
我说:“看场景。如果是内部工具,用allow最方便;如果是面向外部用户的客服机器人,必须用pairing,防止被滥用;deny一般用于纯群组场景的 Agent。”
bindings:精准路由规则
bindings 是 OpenClaw 多 Agent 路由的核心机制。它定义了消息应该如何分配给不同的 Agent。
{
"bindings": [
{
"agentId": "CodeReview",
"match": {
"channel": "feishu",
"accountId": "cli_xxx1",
"peer": {
"type": "group",
"id": "oc_xxx"
}
}
},
{
"agentId": "DevOps",
"match": {
"channel": "feishu",
"accountId": "cli_xxx2"
}
}
]
}
老王指着配置问:“字段名我认识。你直接说,这几个字段是怎么参与路由匹配和优先级判断的?”
我说:“channel是消息来源,比如 feishu、wecom;accountId是飞书应用的 App ID;peer是发送者信息,type可以是 user 或 group,id是对应的 ID。”
“王哥,注意这个路由规则的优先级——bindings 采用最具体优先原则。如果一条消息同时匹配了两个 bindings,哪个 match 条件更具体,就用哪个。”
举个例子:
Binding A:只指定了 channel=feishu Binding B:指定了 channel=feishu + accountId=cli_xxx Binding C:指定了 channel=feishu + accountId=cli_xxx + peer.id=oc_xxx
如果消息来自 feishu 的 cli_xxx 应用的 oc_xxx 群,会优先匹配 Binding C,因为它最具体。
groupPolicy:群组策略
除了 dmPolicy,还有 groupPolicy 控制群组行为:
{
"groupPolicy": {
"requireMention": true, // 群组中是否需要@机器人
"allowAnonymous": false// 是否允许匿名消息
}
}
老王问:“requireMention 这个我遇到过。有时候群里@机器人它不理我,就是这个配置的问题?”
我说:“对。默认情况下,机器人在群里只响应被@的消息。如果你希望它监听所有消息,把requireMention设为 false。但要注意,这样会增加 token 消耗,也可能带来隐私问题。”
03、Gateway 网关架构解析
老王把茶杯往桌上一放:“配置层面先放一边。Gateway 才是核心,你从底层给我拆。”
Gateway 的核心职责
我说:“Gateway 是 OpenClaw 的'神经中枢',负责三件事:”
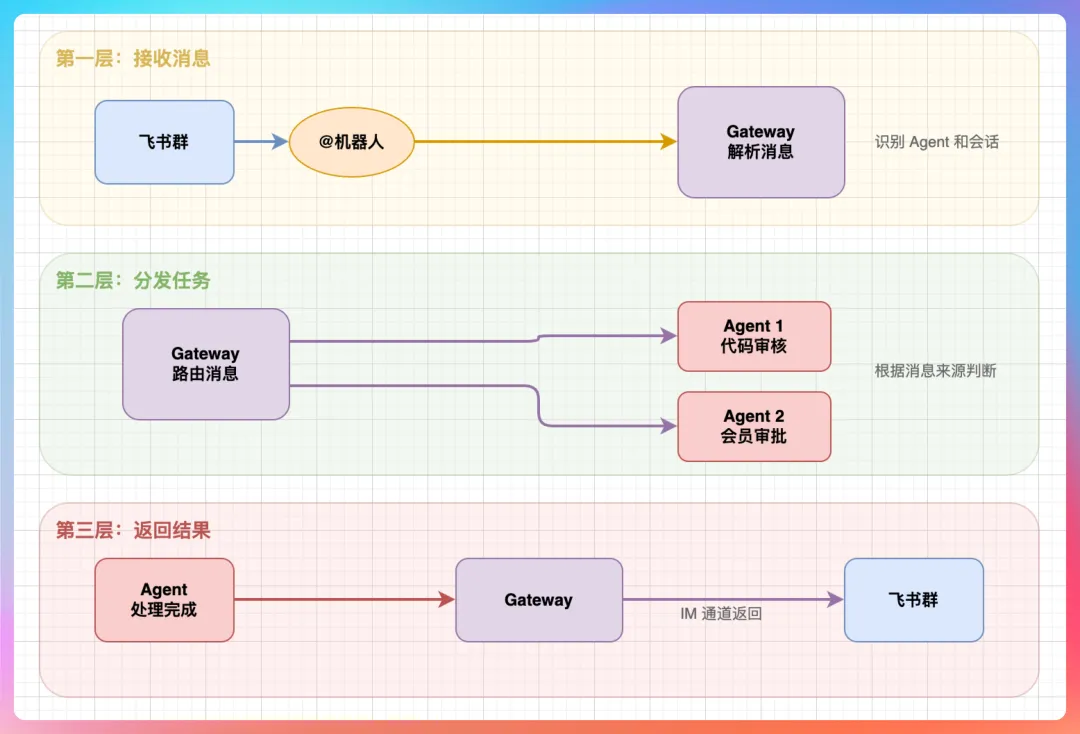
整个链路是这样的:
飞书消息 → Gateway → Agent → 大模型 → Agent → Gateway → 飞书回复
WebSocket 连接与 Token 认证
老王继续追问:“Gateway 和飞书之间到底怎么通信?别只说长连接,把关键链路讲清楚。”
我说:“WebSocket 长连接。飞书开放平台提供了事件订阅机制,Gateway 启动时会向飞书注册一个 WebSocket 连接。之后飞书有消息就会主动推过来。”
认证方式用的是 Token 机制。在openclaw.json里配置的verificationToken和encryptKey,就是用来验证消息来源和解密消息内容的。
{
"gateway": {
"port": 18789,
"auth": "token",
"host": "0.0.0.0"
}
}
老王问:“这个 auth 字段除了 token 还能填什么?”
我说:“目前主要是 token 认证。如果是企业内网部署,还可以配合 IP 白名单、TLS 证书等方式加强安全。”
高可用架构设计
老王继续压问:“如果真上生产,Gateway 单点怎么处理?你别跟我说‘官方以后会支持’。”
我说:“OpenClaw 官方目前没有提供原生高可用方案,Gateway 是单点的。但我们可以通过架构设计来实现高可用:”
方案一:Gateway 集群+负载均衡
部署多个 Gateway 实例,前面挂一个负载均衡器(如 Nginx)。飞书的 WebSocket 连接可以分发到不同实例。
飞书 → 负载均衡器 → Gateway集群(多实例)
方案二:会话状态下沉
把会话状态从本地磁盘迁移到 Redis,这样 Gateway 实例就变成无状态的了。任何一个实例挂掉,其他实例可以接管会话。
{
"memory": {
"storage": "redis",
"redis": {
"host": "localhost",
"port": 6379,
"db": 0
}
}
}
方案三:任务队列化
对于耗时任务,用消息队列(如 RabbitMQ)做缓冲,避免 Gateway 被阻塞。
老王点点头:“这些方案实施起来复杂吗?”
我说:“看团队能力。如果是小团队,建议先用单实例+监控告警;业务量大起来后,再考虑集群方案。不要过早优化。”
会话管理与压缩机制
老王没放过这个细节:“多轮对话的上下文到底落在哪里?Gateway 重启以后为什么还能接上?”
我说:“会话数据默认存在~/.openclaw/workspaces/<agent>/memory/目录下。每次对话会序列化保存,用 session_id 标识。Gateway 重启后可以恢复会话状态。”
但这里有个坑——会话数据会越积越多,尤其是长对话场景。OpenClaw 提供了压缩机制:
{
"memory": {
"compression": true,
"maxHistory": 20, // 保留最近20轮对话
"summarizeThreshold": 10// 超过10轮后自动摘要
}
}
老王问:“自动摘要是什么意思?”
我说:“当对话轮数超过 threshold 时,Agent 会把前面的内容压缩成一段摘要,只保留关键信息。这样可以控制 token 消耗,也能避免上下文窗口溢出。”
上下文窗口管理实战
老王继续追问:“别只讲压缩配置。上下文窗口真要爆了,线上你怎么兜?”
经验一:分层记忆设计
把记忆分成三层:
短期记忆:最近 5 轮对话,完整保留 中期记忆:6-20 轮对话,压缩存储 长期记忆:超过 20 轮,只保留关键摘要
{
"memory": {
"layers": [
{"type": "short", "rounds": 5, "compression": "none"},
{"type": "medium", "rounds": 15, "compression": "light"},
{"type": "long", "compression": "heavy"}
]
}
}
经验二:关键信息提取
在 BOOT.md 里告诉 Agent,哪些信息必须记住,哪些可以丢弃:
## 记忆策略
必须记住的信息:
- 用户身份和偏好
- 当前任务的上下文
- 关键的业务参数
可以丢弃的信息:
- 礼貌用语
- 重复确认的内容
- 临时性的中间结果
经验三:定期清理机制
设置定时任务,自动清理过期的会话数据:
# 清理7天前的会话
openclaw memory cleanup --before 7d
# 清理特定Agent的会话
openclaw memory cleanup --agent CodeReview --before 3d
老王听完感慨:“这些细节官方文档可不会写,都是踩坑踩出来的。”
Gateway 的生命周期管理
老王继续压问:“别只讲命令。Gateway 的启动、停止、重启,底层生命周期你给我拆开说。”
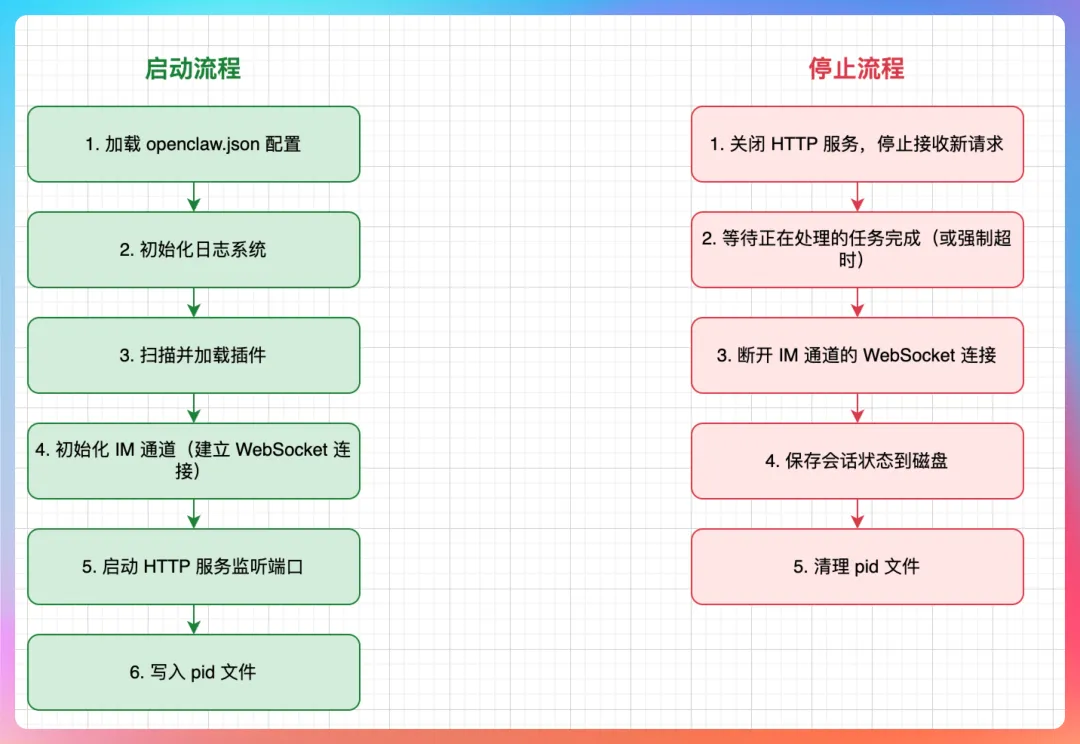
老王问:“如果 Gateway 崩溃了,会话会丢吗?”
我说:“看配置。如果开启了持久化,会话数据会定期写入磁盘,崩溃后可以恢复。但正在处理中的任务可能会中断。”
优雅关闭与信号处理
我接着说:“如果面试官继续追到优雅关闭,这几个点一定要答出来:”
停止接收新连接 等待现有连接处理完成(默认 30 秒超时) 保存会话状态 清理资源后退出
# 优雅关闭
kill -TERM <pid>
# 强制关闭(不推荐)
kill -9 <pid>
老王问:“如果 30 秒内任务还没完成怎么办?”
我说:“超时后会强制退出,未完成的任务会丢失。所以复杂任务最好设计成可重入的,支持断点续传。”
04、机器人收不到消息?
老王叹了口气:“我遇到过一个问题,机器人在群里@它没反应,私聊却正常。排查了半天才找到原因。”
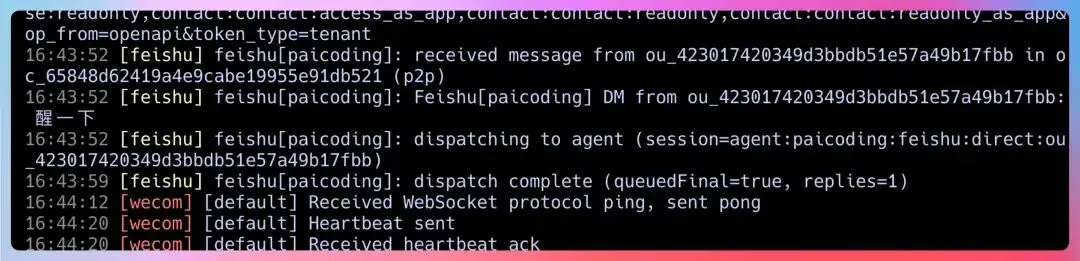
我说:“这种问题是 OpenClaw 使用中最常见的。我给你整一套系统的排查流程。”
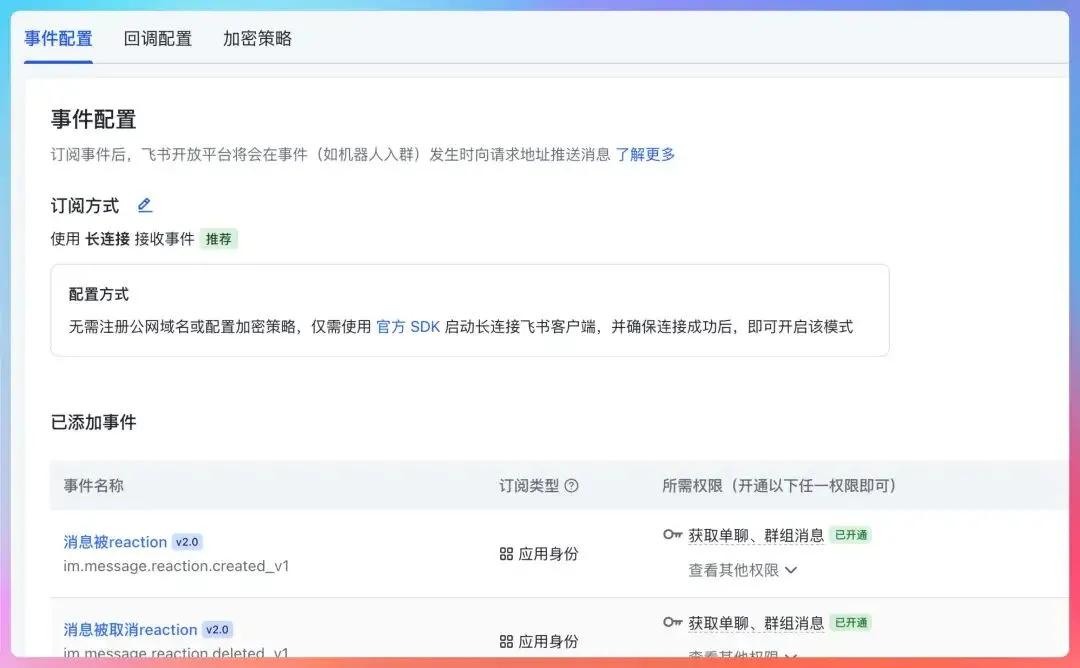
第一步:检查事件订阅配置
飞书机器人收不到消息,90%是事件订阅没配好。
这一段别靠感觉排查,直接对照官方飞书文档里的事件订阅配置最省时间。
打开飞书开放平台,进入你的应用,检查这几点:
事件订阅已开启:确认开关是打开状态 订阅方式选择正确:推荐用长连接模式(WebSocket),而不是 HTTP 回调 订阅事件已添加:必须添加 im.message.receive_v1事件
第二步:检查机器人权限
飞书应用需要申请特定的权限才能接收消息:
im:chat:readonly- 读取群组信息im:message:send- 发送消息im:message:receive- 接收消息
老王问:“权限申请了但还不行?”
我说:“权限申请后要发布版本才能生效。很多小伙伴忘了点'发布',权限一直处于待生效状态。”
第三步:检查 Gateway 日志
如果配置都没问题,看 Gateway 的日志:
openclaw gateway 启动,控制台可以看到。
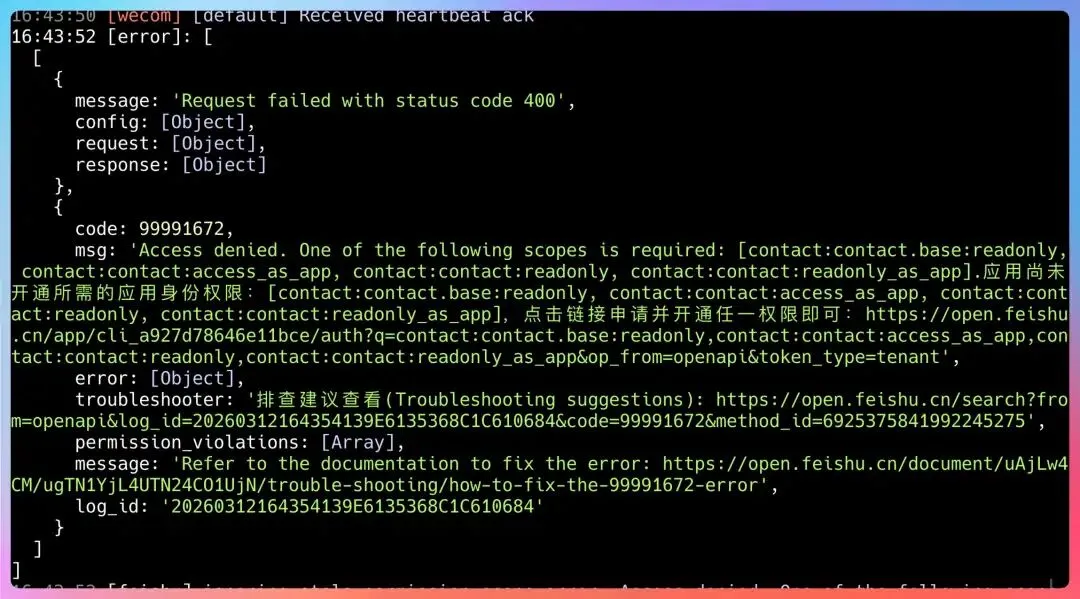
常见的错误有:
错误一:App ID 或 App Secret 错误
Error: Invalid app credentials
解决:去飞书后台重新复制正确的凭证。
错误二:Encrypt Key 不匹配
Error: Failed to decrypt message
解决:检查openclaw.json里的encryptKey和飞书后台配置的是否一致。
错误三:WebSocket 连接失败
Error: WebSocket connection closed unexpectedly
解决:检查网络连通性,确认服务器能访问飞书的 WebSocket 地址。
第四步:检查群组配置
如果私聊正常、群组没反应,检查:
机器人是否已添加到群组:在群设置里确认机器人成员存在 是否开启了@提及:检查 groupPolicy.requireMention配置群组是否被禁用:飞书企业版可能限制了机器人在某些群的使用
老王补充:“还有一个坑——飞书群的'仅管理员可@所有人'设置,可能会影响机器人响应。”
我说:“对,这个也要注意。另外,如果群里有多个机器人,可能存在消息竞争,建议一个群只放一个 OpenClaw 机器人。”
常见问题速查表
我干脆把排查思路收成一张速查表,递给老王:
im:message.group:readonly权限 | ||
requireMention | ||
老王点点头:“这个实用,截图保存了。”
第五步:网络连通性测试
如果以上都没问题,测试网络连通性:
# 测试飞书API连通性
curl -I https://open.feishu.cn/open-apis/auth/v3/tenant_access_token/internal
# 测试WebSocket连通性
wscat -c wss://ws.feishu.cn/
如果网络不通,检查服务器的防火墙、安全组、代理配置。
如果你本身就是走代理环境,别只测飞书 API,也顺手把 OpenClaw 的代理配置文档翻一遍,不然 WebSocket 看着像是连不上,其实是代理层没配对。
05、2026.3.11 版本新特性解读
老王继续追问:“3 月 11 号这波更新值不值得升?你别报菜名,直接挑最该盯的变更说。”
记忆能力升级
之前是放在md文件里的,现在放到了 sqllite 中。
GPT-5.4 支持
新增了对 GPT-5.4 的支持。配置方式:
{
"model": {
"provider": "openai",
"defaultModel": "gpt-5.4",
"profiles": {
"coding": {
"model": "gpt-5.4",
"temperature": 0.2
}
}
}
}
ending
老王听完,沉默了一会儿。
然后说:“你这一通讲下来,我发现 OpenClaw 的水挺深。表面看是个聊天机器人框架,底层涉及架构设计、路由算法、分布式会话、安全认证,全是硬核技术。”
我说:“这就是你们这些面试官爱问 OpenClaw 的原因啊。它把 AI Agent 工程化落地的方方面面都涵盖了,从配置到原理,从使用到排查,能考察的点很多。”
如果你能把今天这些内容吃透,面试时绝对能脱颖而出。
【技术的价值,不在于你用过多少工具,而在于你理解得有多深。】
OpenClaw 只是众多 AI Agent 框架中的一个。但透过它,你能看到 AI 工程化的完整图景——模型调用、消息路由、会话管理、权限控制、高可用设计,这些都是通用的能力。
掌握这些,换到其他框架也能快速上手。
工具会迭代,但底层的原理和思考方式不会变。
我们下期见,冲啊!
