 夜雨聆风
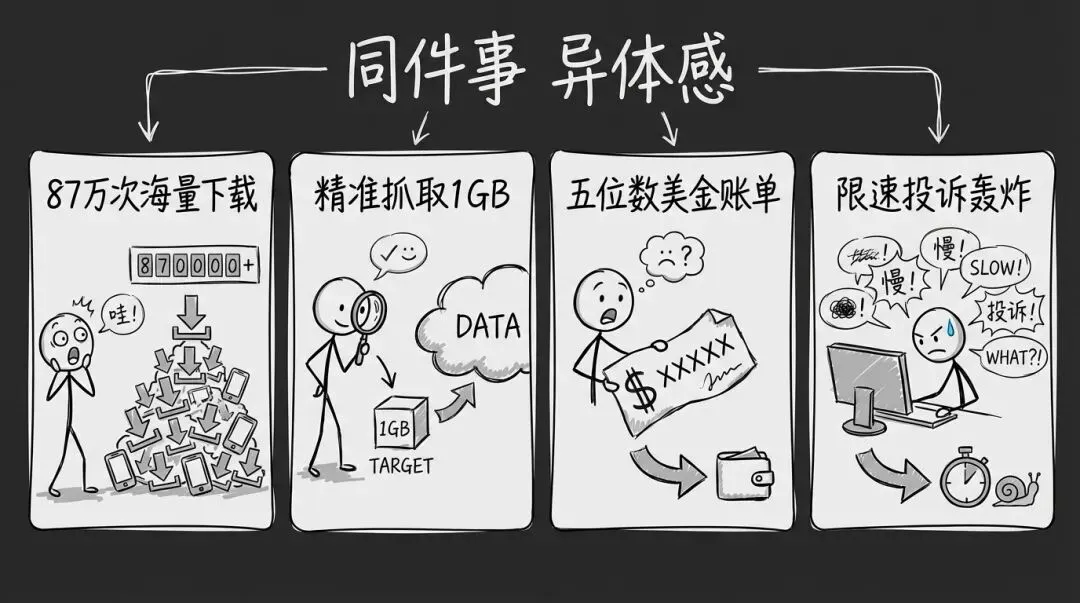
夜雨聆风某大厂说,SkillHub第一周分发了180GB流量、87万次下载,但实际只从ClawHub抓了1GB数据,这是在帮原站分担压力。
OpenClaw创始人Peter Steinberger说,你们的抓取让我服务器成本飙到五位数美元,还收到你们抱怨"限速太慢影响抓取"的邮件。
同一件事,为什么双方感受完全相反?
这不是一场简单的"抄袭"指控,而是AI时代开源社区和平台公司第一次正面冲撞:公开生态的价值,到底该由谁拿走?
"公开数据"≠可以随便拿
很多人第一反应是:ClawHub数据本来就公开,某大厂又标了来源,这有什么问题?
问题就在这。
"公开可见"从来不等于"允许第三方大规模抓取、镜像、再分发,并据此构建新平台"。
ClawHub是什么?
它是OpenClaw生态的技能目录,包含13000+技能的描述、分类、标签、排序、推荐。
这些不是天上掉下来的,是OpenClaw团队维护服务器、处理社区贡献、审核质量、优化索引换来的。
某大厂做了什么?
推出SkillHub,直接承接整个生态成果——1.3万个技能、分类体系、榜单排序、中文包装、下载加速。
从技术角度看,这确实是"本地镜像";但从生态角度看,某大厂拿走的是ClawHub辛苦建立起来的分发入口。
上游做苦活,平台吃入口。这是最让开发者不爽的地方。
标了来源就够了吗?
某大厂最强的defense是:我们明确标注了来源,没有洗白成原创。
但这只解决了"冒名顶替"问题,解决不了"无偿搬运"问题。
想象一个场景:
你花两年时间写了一本技术书,放在自己网站免费公开阅读。
某天一个大公司把你的书全文复制到他们平台,流量暴涨,他们在页面底部写了一行"内容来源于XX网站"。
法律上,可能没问题。
伦理上,你会爽吗?
更重要的是:他们有没有提前跟你商量?有没有问你服务器扛不扛得住?有没有建立合作分发机制?有没有任何形式的回馈?
如果答案全是"没有",那标注来源只是最低限度的体面,不是值得夸奖的美德。
180GB流量 VS 五位数成本:谁说得对?
某大厂说:"我们分发了180GB,只抓了1GB,帮你分担了99%的流量压力。"
Peter说:"问题不只是最终流量,而是抓取方式、频率、索引成本、同步行为给原站造成的持续压力。"
如果某大厂的数据属实,从结果看,镜像站确实可能降低了源站下载流量。
这对中国用户体验有真实价值——ClawHub本来就有严重的rate limiting问题,VPS环境几乎无法使用。
这里有个更深的问题:
镜像技术本身不是问题,抓取策略和协商机制才是问题核心。
如果某大厂:
提前跟Peter沟通,建立官方镜像合作 采用合理的增量同步+缓存+限速策略 提供技术或资金支持帮助优化源站 在SkillHub页面把ClawHub写成"合作伙伴"而不是"数据源"
那这件事就是双赢的基础设施建设。
但如果没有这些,即便最终流量数据好看,过程中也可能把原站当成了免费API。
开发者最怕的不是小偷,而是"合法架空"
这件事在技术圈引发的共鸣,远超一次具体争议。
因为开源社区最怕的不是小偷,而是"合法合规地把你架空的人"。
我见过太多开源项目被大厂"合理利用"的案例。
套路都一样:
项目开源,社区贡献,作者维护 大厂看到价值,直接fork或镜像 包装成自己的产品,流量全走平台 原项目继续承担成本,平台享受收益
法律上可能没问题,因为开源协议允许。
但伦理上,这就是把社区当供应链,把原作者当矿工。
大厂最擅长的不是复制代码,而是复制入口。
Open: Pasted image 20260313224818.png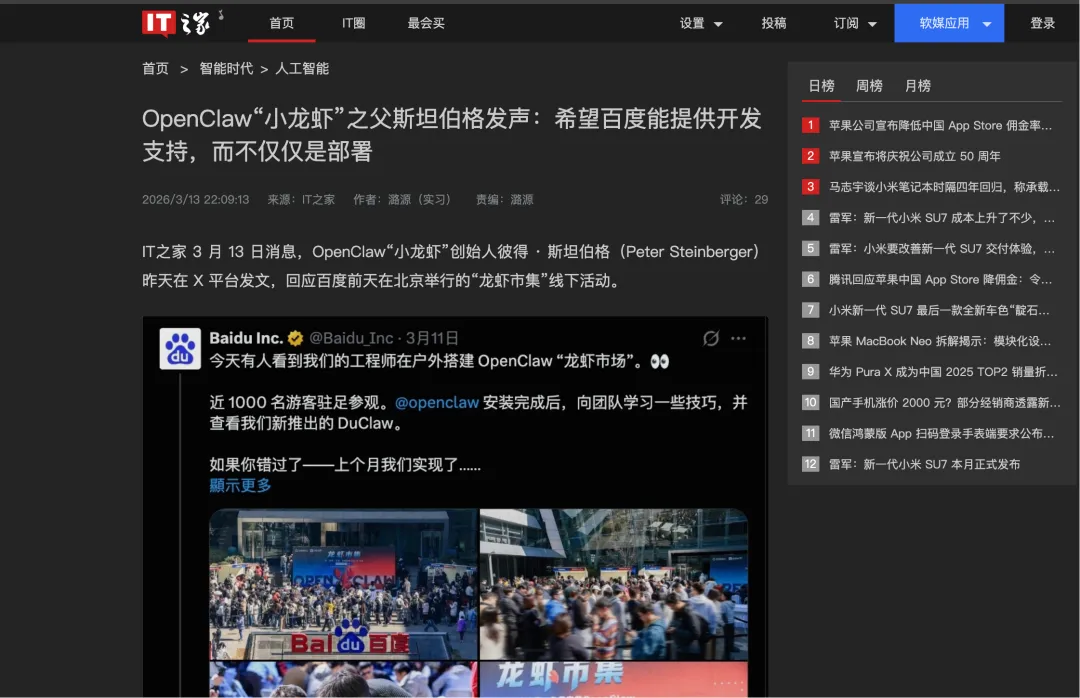
我的判断
回到这次争议,我的立场是:
某大厂做的事未必没有公共价值,但如果没有协商和回馈,它就很难摆脱"拿社区当基础设施"的质疑。
法律管不了灰色地带的伦理。
镜像技术本身中性。
但当一个开放生态被平台化分发时,谁来承担成本,谁来拥有入口,谁来定义公平——这才是商业文明问题。
Peter最不爽的可能不是数据被抓,而是整个过程中的"被动"——没有被问,没有被尊重,没有得到任何形式的support,却要承受抓取带来的成本压力。
某大厂可以说"我们技术上没问题",但这不代表伦理上没问题。
镜像站可以是基础设施,也可以是高级白嫖。区别只在于:有没有协商,有没有回馈,有没有克制。
未来AI Skills生态一定会出现更多镜像站、分发站、中文站。
问题不是能不能镜像,而是:
谁来承担成本,谁来拥有入口,谁来定义公平。
如果这个问题没有答案,那每一次"合法"的镜像,都可能是对开源生态的一次消耗。
疯狂是我,还有整个世界~
