 夜雨聆风
夜雨聆风OpenClaw + ArcReel 创作 AI 漫剧:角色一致性、幻觉陷阱与一句话出片的万字拆解
我是宇辰,最近花了不少时间研究 AI 漫剧的技术链路,踩了一圈坑之后,把完整的认知框架和实操方案整理成了这篇万字长文。关注「宇辰AI编程」,后续还会更新同系列的进阶内容。
你可能已经听说了——2025 年被称为 AI 漫剧元年。
在投数量从 1 月的 234 部激增到 12 月的 17944 部,全年播放量超过 700 亿。日大盘 3500 万,其中 2500 万是解说漫。头部短剧公司的漫剧业务,好的时候单日流水过千万。有制作方一口气发了 100 部解说漫的招募令。
赚钱的故事很诱人。但如果你真的动手做过 AI 漫剧,大概率经历过这些:
- 男主的脸每隔三个镜头换一次,观众以为是三胞胎
- 每张分镜单独看都精美,放一起看角色跟走马灯似的换脸
- 同一个房间,窗户位置每帧都在漂移,桌上的杯子摔碎了下一帧又完好如初
- 花了 3 小时手动调 Prompt,出来的视频还是对不上
- AI 写的剧本,角色前后性格完全对不上,像是几个不同的人拼凑出来的
传统 AI 漫剧工具的分镜通过率只有 30% 到 50%。大量时间不是花在创作上,而是花在返工、重来、补救上。
核心问题不在工具,在认知。
这篇文章要讲透一个问题:AI 漫剧为什么这么难,核心技术坑在哪,行业在用什么方法解决。
读完你能拿到:
- 一套 AI 漫剧核心技术难题的完整认知框架——从此不再被"每一帧都好看但连起来全错"困惑
- 角色一致性、场景连贯、道具追踪、分镜逻辑的解法拆解
- 三种主流方案(手动 / 平台 / Agent)的对比和选择策略
- OpenClaw 通过 Skill 接入 ArcReel,对话式创作 AI 漫剧的完整实操
目录
- 01|AI 漫剧为什么这么难:不是生成问题,是控制问题
- 02|角色一致性深潜:上传参考图只解决了 1/6
- 03|场景、道具、叙事:三个更隐蔽的坑
- 04|分镜智能体:为什么需要"懂戏"的 AI 导演
- 05|三种解法对比:从手搓到全自动
- 06|Agent 驱动方案实操:对话式创作全流程
- 07|Prompt 工程与实战经验
- 08|下一步
01|AI 漫剧为什么这么难:不是生成问题,是控制问题
一句话总结:AI 擅长单点发挥,不擅长全局一致。它不是在"记住"你的角色,而是每次都在"重新做梦"。

◈AI 的本质:一台做梦机器
先理解一个底层逻辑。
AI 这东西,本质上是个做梦机器。你给它一个指令,它不是去"执行",而是去"幻想"——从大数据里抓一堆相关的片段,然后拼起来给你。
生成一张单图?没问题,它拼出来的东西看着挺合理。
写一段文字?也没问题,凑出来的内容读着挺顺畅。
但 AI 漫剧不一样。
AI 漫剧要求的是什么?连贯性。
- 同一个角色,在不同镜头里要保持一致
- 同一个场景,在不同角度下要保持统一
- 同一个故事,在不同时间点要保持逻辑
这跟 AI 的本质是冲突的。AI 擅长的是单点发挥,不擅长全局一致。你让它生成分镜,它会每一张都画得很漂亮,但把这些图放在一起一看——角色跟走马灯似的换脸。
每一帧都对,连起来全错。
这就是幻觉陷阱。
◈幻觉陷阱最坑人的地方
幻觉陷阱有个特点:它在你以为搞定的那一刻,才真正出现。
你让 AI 写剧本,写得挺好,你以为没问题了。
你让 AI 生成分镜,画得挺漂亮,你以为没问题了。
等你把这些东西放在一起,才发现连不上。
幻觉不是在生成的时候出现的,是在拼接的时候暴露的。你会被每一个单点的质量迷惑,以为搞定了,结果连起来全错。
这就是幻觉陷阱最坑人的地方——它在最后一步才收网。
◈所以核心是什么
AI 漫剧这东西,本质上不是一个生成问题,是一个控制问题。
- 不是让 AI 发挥它的想象力,而是限制它的想象力
- 不是让 AI 自由创作,而是给它设定边界
- 不是让 AI 做梦,而是让它照着做
所有的高效工作流,核心都在于:如何用最小的成本,把 AI 的幻觉控制在可接受的范围内。
角色设定图、场景设定图、结构化 Prompt、固定模板——这些东西的本质都是一样的:给 AI 一个锚点,让它每次都参考同一个基准,而不是每次都重新幻想。
理解了这一点,就理解了为什么有些人做 AI 漫剧效率高、有些人效率低。效率高的人,不是工具用得好,是知道怎么给 AI 定规矩。效率低的人,不是工具用得差,是被 AI 的幻觉牵着走。
工具谁都会用,理解幻觉才是核心竞争力。
02|角色一致性深潜:上传参考图只解决了 1/6
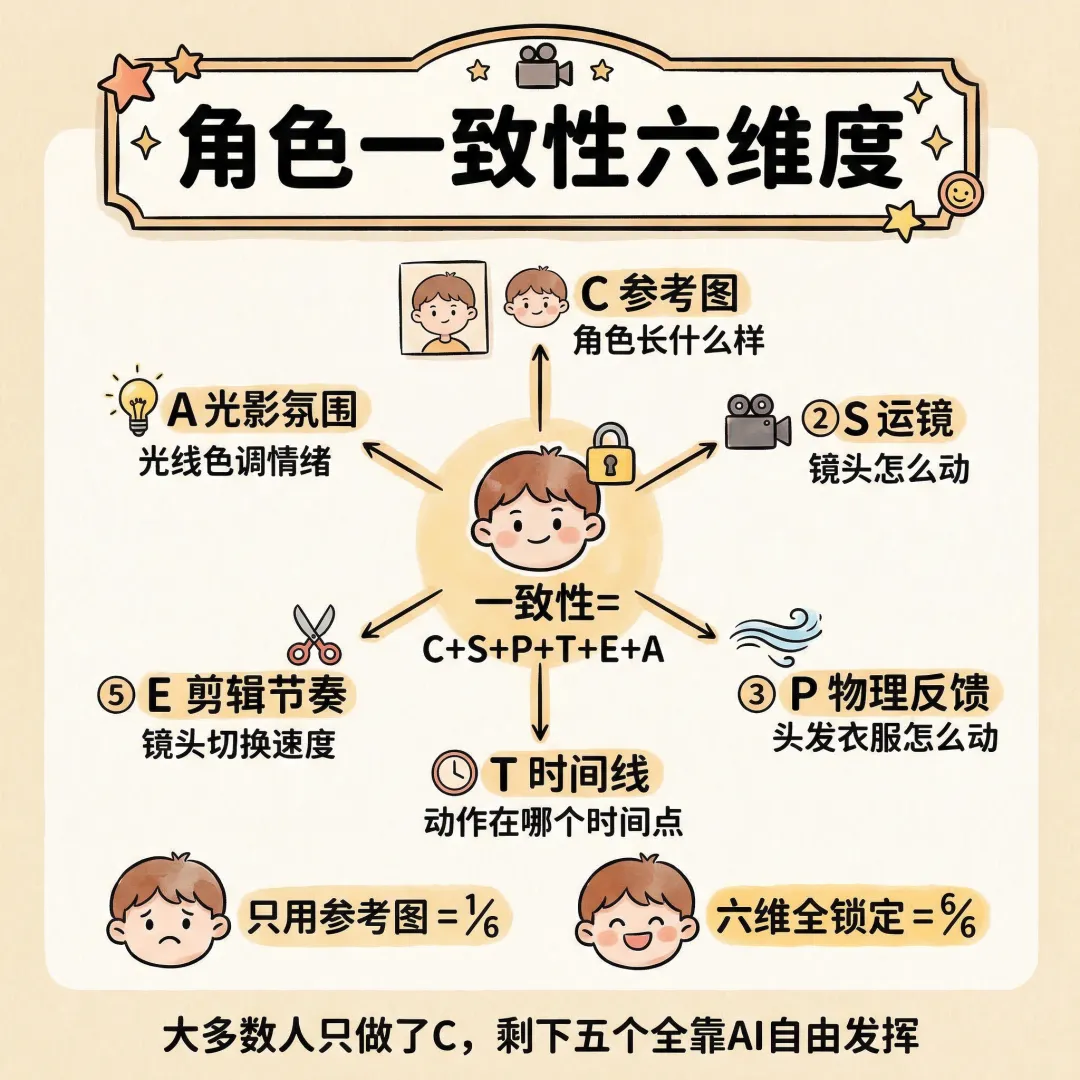
一句话总结:角色一致性需要六个维度同时锁定,参考图只是其中之一。
◈一个真实的翻车案例
我自己刚开始做的时候也踩了这个坑。做了个都市题材,女主第一集是职场精英,第二集变成了邻家少女,第三集直接成了路人大妈。明明用的同一张参考图,怎么就认不出来了?
后来才搞清楚:我只告诉 AI"这个人长什么样",但没告诉 AI"这个人怎么动、怎么站、什么光线、什么节奏"。
我后来专门研究了一圈,也反复测试了大量镜头,终于搞明白一个结论:
角色一致性 ≠ 参考图一致性。
参考图只解决了"长相"这一个维度。但 AI 生成视频,需要的是六个维度的完整信息。
◈六棱镜法:六个维度缺一不可
完整的角色一致性公式:
一致性 = C(参考图)+ S(运镜)+ P(物理反馈)+ T(时间线)+ E(剪辑节奏)+ A(光影氛围)
逐个拆解:
C - Context 参考图:角色长什么样
这是大多数人唯一做的事。上传一张定妆照,告诉 AI 角色的外貌特征。
但光有正面照不够。建议至少准备三视图(正面 / 侧面 / 45 度),外加常用表情库(微笑 / 严肃 / 愤怒 / 悲伤)和常用动作库(站立 / 行走 / 打斗 / 对话)。
重点:所有图必须用同一个模型、同一组参数生成。 混用不同工具生成的参考图,风格差异会导致后续一致性崩溃。
S - Shot 运镜:镜头怎么动
角度一变,AI 就可能认不出角色。你需要明确告诉它:
- 起始位:摄影机在哪
- 运动轨迹:是推进、拉远、环绕还是摇移
- 结束位:最终停在什么角度
没有运镜信息,AI 每次会随机选择镜头角度,同一个人从不同角度看起来就像不同的人。
P - Physics 物理反馈:头发、衣服、道具怎么动
"白袍向左翻飞"、"马尾辫水平飘动"、"剑身反射金光"——这些细节决定了画面的真实感和连贯感。
缺了物理描述,AI 会自己编:上一帧头发往左飘,下一帧突然往右,观众虽然说不出哪里不对,但就是觉得割裂。
实测经验:每个镜头至少要有 3 个物理反馈描述。
T - Time 时间线:动作在哪个时间点发生
- 总时长多少秒
- 0-5 秒做什么,5-10 秒做什么
- 关键动作在第几秒
没有时间线,AI 会把所有动作压缩到一起,或者拉得太长。同一个人的动作节奏不一致,观众会觉得是两个人。
E - Editing 剪辑节奏:镜头切换的速度和方式
- 节奏是均匀舒缓还是急促紧张
- 有没有变速
- 在哪里定格
这个维度是很多人忽略的"隐形杀手"。同一个角色,动作速度不一样,观众直觉上会觉得是两个人。
A - Atmosphere 光影氛围:光线、色调、情绪
- 光线方向(顺光 / 逆光 / 侧光 / 顶光)
- 色调(暖金 / 冷蓝 / 中性)
- 情绪基调(坚定 / 悲伤 / 紧张)
这是另一个大坑——同样的脸,在不同光线下看起来像完全不同的人。很多人调了半天参考图,结果问题出在光影参数不一致。
◈只给参考图 = 只锁了 1/6
六个维度,大多数人只做了 C(参考图),剩下五个全靠 AI 自由发挥。
AI 每次"自由发挥"的结果都不一样——这就是角色一直在变的根本原因。
◈手动解法 vs 自动解法
手动解法的完整流程:
- 用 MJ 或其他工具生成角色三视图(正面 / 侧面 / 45 度)
- 补充表情库(微笑 / 严肃 / 愤怒 / 悲伤)和动作库(站立 / 行走 / 打斗 / 对话)
- 每个镜头手动写 6D 工作笔记(场景 / 镜头 / 物理 / 时间 / 节奏 / 氛围)
- 把笔记翻译成一段连贯的自然语言流 Prompt
- 逐个镜头生成,每次手动引用参考图和所有约束
这套流程有效,但代价是巨大的人力投入——每个镜头都要手动写几百字的约束条件。
有没有更自动化的方式?有。
比如我们做的开源项目 ArcReel,思路是让 Agent 自动完成"建资产→注入约束"这个环节:你给一个主题,Agent 自动生成人物设计图,后续所有分镜和视频自动引用该设计图作为视觉约束。本质是一样的——给 AI 一个锚点——但执行方式从"人驱动"变成了"Agent 驱动"。
说实话:自动建的角色资产,精细度不如手动花几小时打磨的三视图 + 表情库。但对于大多数场景,"足够好的自动化"比"完美但耗时"更实用。如果你追求极致一致性,仍然建议手动打磨核心角色的资产库。
◈一个被忽略的细节:自然语言流 vs 列表式
这是反复测试后才发现的秘密。
当前主流的视频生成模型底层是语言模型,不是程序。它更擅长理解一段连贯的叙述,而不是一串编号列表。
实测数据:
- 列表式 Prompt(分成 9 个编号段落):生成 10 次,能用的 2-3 次
- 自然语言流(一气呵成的描述):生成 10 次,能用的 7-8 次
差距就是这么大。
所以在写 Prompt 的时候,不要这样:
1. 角色:白衣少侠2. 场景:悬崖边3. 动作:站立4. 光线:黄昏而要这样:
悬崖边,黄昏金光从 45 度角侧面打来,一位白衣少侠剑眉星目站在崖顶,长袍被风吹得向左翻飞,马尾辫水平飘动,镜头从上方俯视缓缓下降,5 秒后转为水平视角,沿右侧弧形环绕到侧脸特写,剑身反射金色夕阳光斑,神情坚定而深邃,暖金色调,舒缓均匀的节奏。一段连贯的、有画面感的叙述,AI 理解起来比分段列表好得多。
03|场景、道具、叙事:三个更隐蔽的坑
一句话总结:角色换脸容易发现,场景漂移、道具穿帮、叙事断裂才是真正的暗坑。
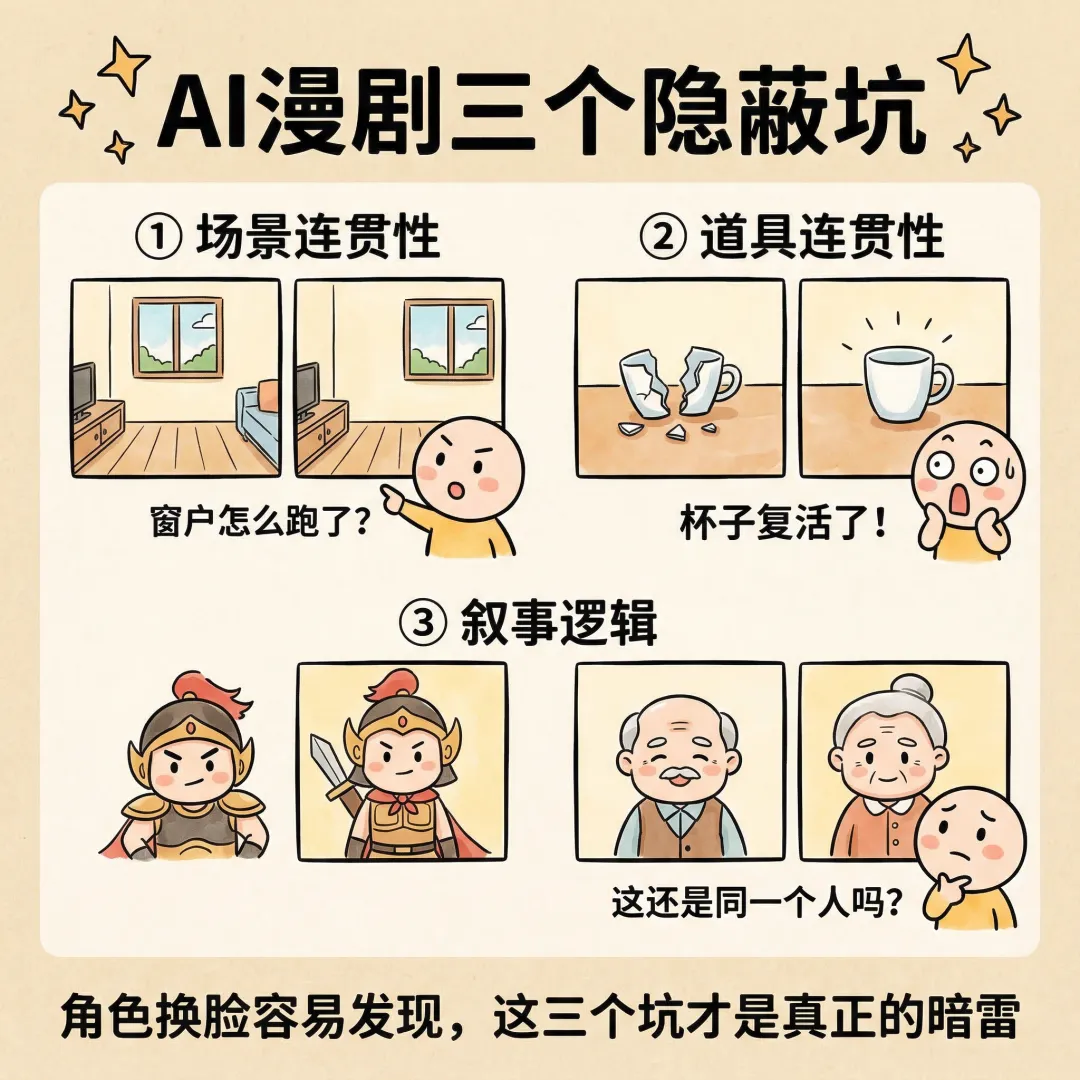
◈3.1 场景连贯性:窗户在跑,建筑在变
角色变脸很容易被注意到,但场景问题却很隐蔽。
同一房间里窗户位置在变。同一街道上建筑风格在变。同一森林里植被密度在变。这些变化不如角色变脸扎眼,但同样会让观众出戏——他们可能说不出哪里不对,但就是觉得"假"。
场景的幻觉比角色更难解决,因为变化的维度更多:光线、天气、视角、建筑细节、室内陈设……每一个都可能漂移。
而且场景涉及一个角色一致性不涉及的问题:正反打。
两个人对话时,镜头在两人之间来回切换。如果场景不一致,A 看向 B 时背景是窗户,B 看向 A 时背景也是窗户——空间关系就乱了。观众会立刻出戏。
业界的解法:多视图空间建模。
比如有些商业平台用了四视图空间建模技术:为每个场景建立四个基准视角(前 / 后 / 左 / 右)的空间档案。
核心能力:
- 空间锚定:确定场景中所有固定物体(家具、建筑结构)的绝对位置,建立三维坐标系
- 正反打约束:两人对话时,系统自动判断正确的背景关系,杜绝左右颠倒
- 深度一致性:人物在场景中的移动符合空间逻辑,不会"瞬移"或穿墙
在 ArcReel 中,场景连贯通过一个更轻量的方案实现:分镜图自动参考前一张生成。每生成一张新的分镜,系统会把前一张作为上下文传递给生成模型,确保相邻场景的画面衔接自然。这不如四视图建模精细,但在绝大多数场景下够用,而且完全自动化,不需要人工标注。
◈3.2 道具连贯性:上一幕摔碎的杯子,下一幕又完好了
道具穿帮是观众最容易注意到的细节问题——因为它直接破坏叙事逻辑。
上一幕角色把杯子摔碎了,下一幕杯子又完好地出现在桌上。上一幕角色手里拿着剑,下一幕剑不见了。上一幕角色受了伤,下一幕伤口消失了。
这些在传统影视制作中有"场记"这个岗位专门盯。在 AI 漫剧里,没有场记——所以道具穿帮几乎是必然的。
解法:道具全生命周期追踪。
核心思路是把每个关键道具当作一个独立实体来管理:
- 状态标记:道具当前状态是什么(完好 / 损坏 / 丢失)
- 位置追踪:道具在谁手里,在哪个位置
- 状态转移规则:什么条件下状态会变化(摔碎了就不能再完好出现)
在 ArcReel 中,这个功能叫"线索追踪"——关键道具和场景元素被标记为"线索",跨镜头保持视觉连贯。Agent 会自动维护这些线索的状态,在生成新分镜时把相关约束注入 Prompt。
◈3.3 叙事逻辑:AI 不是在"塑造"角色,是在"重新想象"角色
回到剧本层面。
很多人第一步就踩坑了,但往往到后面才发现。
让 AI 写剧本,它写得挺溜。角色有名字、有性格、有台词,看着都挺像那么回事。等你开始生成分镜,就会发现角色对不上。
比如你设定了一个"沉默寡言的退役军人",前几幕还挺对味,到了中段他突然开始跟人唠家常,到后面直接变成了热心居委会大爷。
剧本是 AI 写的,分镜也是按剧本来的,怎么角色对不上?
因为 AI 写剧本的时候,每次提到一个角色,都是从训练数据里抓一个相关印象。"退役军人"这个标签对应无数种人设,AI 每次抓的可能都不一样。
它不是在塑造一个角色,是在每次重新想象一个角色。
这个问题靠调 Prompt 或者调教 AI 是解决不了的,因为幻觉是 AI 的底层特性。只能用两种方式补位:
方式一:人工约束。 明确列出角色的性格特征、行为模式、说话风格,让 AI 每次都严格按照设定来写。不是让 AI 发挥,是让 AI 照着抄。
方式二:Agent 约束。 在 ArcReel 里,Subagent 专门负责剧本创作这种复杂多步推理任务。它会维护一个角色设定文档,每次生成新的剧本内容时,都会回查角色设定,确保一致。这不是完美的——AI 偶尔还是会"跑偏"——但比完全不约束好得多。
不管用哪种方式,剧本都必须人工审核一遍。 别跳过这一步。剧本是地基,地基歪了后面全白搭。
04|分镜智能体:为什么需要"懂戏"的 AI 导演
一句话总结:传统 AI 工具只是"把文字变成画面",分镜智能体是真正"理解剧情"的 AI 导演。
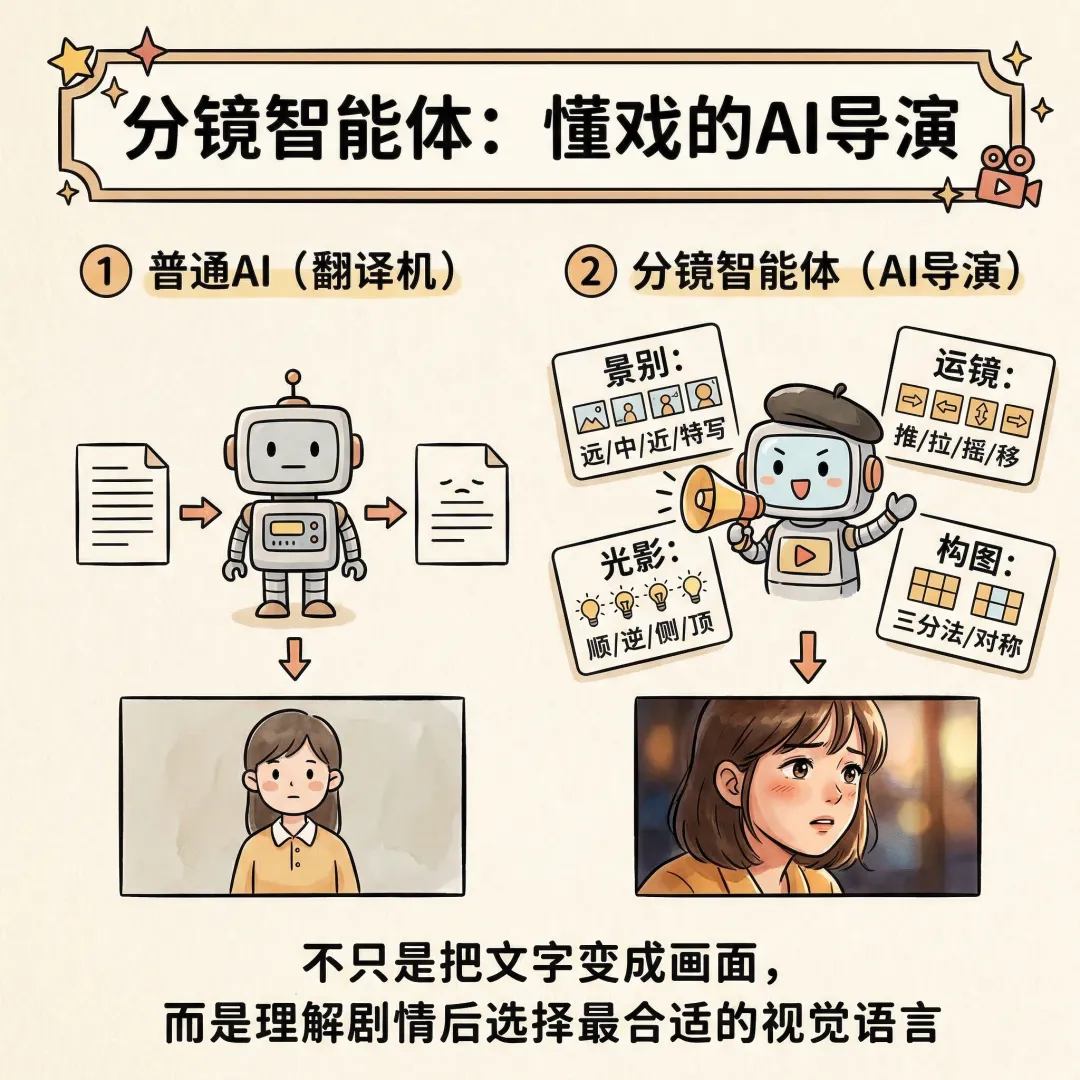
◈从"翻译机"到"导演"
最简单的 AI 漫剧工具就是一个"翻译机":你给一段文字描述,它生成一张图。
但一个好的分镜,不只是"把文字画出来"。它涉及:
- 景别选择:这个情节用远景交代环境,还是用近景表达情绪,还是用特写强调细节?
- 运镜语言:推镜头强调紧张感,拉镜头揭示全貌,摇镜头展示空间,移镜头跟随角色?
- 光影语义:顺光明亮正面,逆光剪影神秘,侧光立体有层次,顶光压抑沉重?
- 构图法则:三分法、对称构图、引导线、框架式构图?
- 剪辑节奏:动作连贯、情绪递进、平行蒙太奇、交叉剪辑?
这些是影视工业积累了上百年的专业知识。一个普通创作者不可能在短时间内掌握这些。
◈分镜智能体的"懂戏"能力
好的分镜系统会内置影视工业知识库:
| 知识类别 | 内容示例 |
|---|---|
| 景别语法 | 远景交代环境、中景叙事、近景表达情绪、特写强调细节 |
| 运镜语言 | 推镜头强调、拉镜头揭示、摇镜头展示、移镜头跟随 |
| 光影语义 | 顺光明亮、逆光剪影、侧光立体、顶光压抑 |
| 构图法则 | 三分法、对称构图、引导线、框架式构图 |
| 剪辑节奏 | 动作连贯、情绪递进、平行蒙太奇、交叉剪辑 |
有了这些知识,AI 不再是"你说什么我画什么",而是"我理解这段剧情想表达什么,自动选择合适的视觉语言"。
比如一段"男主得知真相后悲痛欲绝"的剧情,分镜智能体会自动选择:
- 近景到特写的推镜头(强调情绪)
- 侧光(增加面部立体感和情绪层次)
- 浅景深(虚化背景,聚焦人物)
- 缓慢的节奏(给情绪发酵的时间)
而不是用一个默认的中景正面平光——那样拍出来的分镜毫无情绪张力。
◈运镜系统的关键预设
一个完整的运镜系统应该覆盖:
- 固定镜头:正面、侧面、俯视、仰视
- 运动镜头:推、拉、摇、移、跟、升、降
- 特殊镜头:环绕 360°、一镜到底、快速摇移
- 转场方式:硬切、叠化、擦除、匹配剪辑
在 ArcReel 的多智能体架构中,这部分由 Skills 处理——每个 Skill 专门处理一种单步任务(生成人物设计图、生成分镜图、生成视频片段),而 Subagent 负责整体编排,决定每个镜头用什么景别、什么运镜、什么光影。
◈非线性编辑:打破"单行道"
传统 AI 工具是"单行道"——生成完了想修改,只能从头来。
这是非常痛苦的。你做到第 20 个镜头,发现第 5 个镜头的角色设定不太对,于是修改了角色设定图。然后……第 6 到第 20 个镜头全要重新生成。
好的漫剧生产系统应该支持非线性编辑:
- 任意跳转:在视频预览阶段发现问题,直接跳回分镜阶段修改,修改结果自动同步到视频
- 资产驱动更新:修改一次角色资产(比如换发型),全剧所有相关镜头自动同步更新
- 版本管理:每次修改都有版本记录,随时回滚
ArcReel 内置了版本历史和一键回滚功能,任何阶段都可以退回前一个版本。这在创作过程中非常实用——你经常会在第 8 步发现第 3 步的决定不对。
05|三种解法对比:从手搓到全自动
一句话总结:三种路线,核心区别在于"谁来做控制"——人、平台、还是 Agent。

◈5.1 纯手动工作流:豆包 + Seedance + 剪映
典型流程五步走:
- 找爆款题材:去抖音、快手找已经验证过的类型(霸总、真假千金、重生……曝过的还会曝)
- 用豆包生成剧本:输入题材和要求,生成完整剧本、分集大纲、每一集的分镜说明和台词
- 设计人物形象:用生图工具生成角色参考图,每个角色 2-3 张不同角度,确保颜值和气质到位
- 逐条生成视频:把参考图和分镜 Prompt 喂给 Seedance 2.0,一条条生成 15 秒视频
- 剪辑合成:导入剪映,调速度、剪镜头、加字幕、配音乐
这套流程已经有不少人跑通了,做到 10W+ 播放、40-50% 完播率的案例并不少见。
核心优点:
- 工具基本免费(豆包免费、Seedance 有免费额度)
- 每步都能精细控制
- 灵活度最高,想改哪改哪
核心痛点:
- 每一步都要人盯:找题材要人、审剧本要人、调参考图要人、写 Prompt 要人、逐条喂 Seedance 要人、剪辑要人
- 效率瓶颈在"拼接":AI 帮你干了每一步的活,但串起来还是得你自己来
- Seedance 2.0 单次只能生成 15 秒,长剧需要大量拼接
- 角色一致性完全靠手动维护,一不小心就崩
适合谁:预算有限、时间充裕、想精细打磨每个镜头的创作者。
◈5.2 专业平台(商业漫剧生产线)
部分商业平台采用了"资产驱动"的分层架构。
跟手动工作流最大的区别是:不是直接从剧本生成画面,而是先建立数字资产档案,再基于资产生成画面。
传统模式是"端到端"——输入剧本,直接输出画面。每次生成都是独立的随机过程,无法保证一致性。
资产驱动模式是"分层解耦"——先建好角色三视图、场景四视图、道具档案,然后所有生成都基于这些资产。
核心技术模块:
| 技术模块 | 核心创新 | 技术效果 |
|---|---|---|
| 三视图资产系统 | 多视角一致性建模 | 角色跨镜头、跨剧集不变脸 |
| 四视图空间建模 | 场景三维坐标系 | 背景不乱跳,正反打正确 |
| 道具全生命周期追踪 | 状态转移规则 | 道具不瞬移、不复原 |
| 分镜智能体 | 影视工业知识库 | AI 懂戏,90% 分镜可用 |
| 非线性编辑 | 资产驱动更新 | 修改一处,全剧同步 |
效果:分镜通过率从 30-50% 提升到 90%。
核心优点:工业级一致性,非线性编辑,效率碾压手动。
核心痛点:闭源商业平台,不可定制,受平台策略影响。
适合谁:追求工业级质量、愿意付费、不需要定制化的团队。
◈5.3 Agent 驱动:开源方案
核心理念:用 AI Agent 当导演,自动编排整个生产流水线。
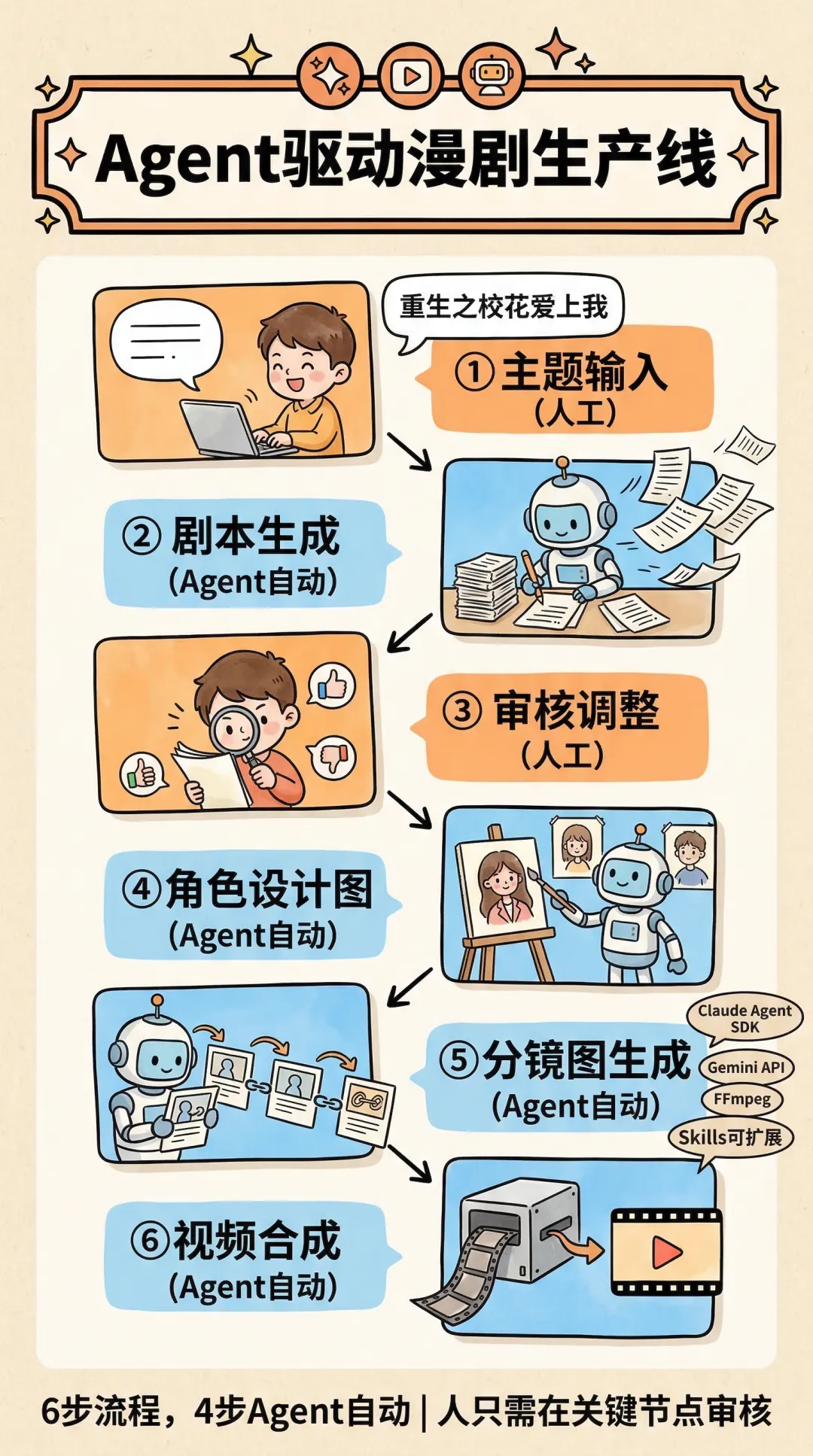
你给一个主题,Agent 自动规划并执行整条链路:写剧本 → 建角色资产 → 生成分镜 → 生成视频 → 合成成片。人只在关键节点审核和调整。
这条路线已经有商业验证——GitHub 上已经出现了靠 Agent 驱动的 AI 影视制作系统接单盈利的案例,漫剧解说剧都有。
我们做的 ArcReel 就是这条路线的开源实现。完整覆盖从剧本 → 角色设计 → 分镜 → 场景 → 剧集 → 视频合成的全链路,默认 9:16 竖屏比例,原生适配短视频平台。
有几个设计上的核心差异,值得展开说。
第一,对话式交互,大幅降低使用门槛。
传统的漫剧工具,你需要在各种面板里填参数、调配置、拖拽素材。ArcReel 通过 OpenClaw 集成后,整个创作过程就是跟🦞聊天——你用自然语言描述需求,Agent 自动拆解成具体的执行步骤。
"帮我把第三集的女主服装换成红色旗袍"——你说人话,Agent 去改参数、重新生成、同步更新。不需要你知道哪个接口叫什么、参数怎么填。
这意味着不会写代码的内容创作者也能用。你不需要懂技术栈,只需要懂内容和审美。
第二,原生支持 Skills 扩展,能力边界不固定。
ArcReel 基于 Claude Agent SDK 构建,天然支持 Skills 机制。每个 Skill 处理一种单步任务(生成人物设计图、生成分镜图、生成视频片段),Subagent 处理复杂多步推理(剧本创作、整体编排)。
关键是:Skills 是可插拔的。 你觉得默认的剧本生成 Skill 不够好?可以自己写一个替换掉。你想加一个自动配音的能力?写一个配音 Skill 挂上去就行。社区里有人做了好用的 Skill,直接装上就能用。
这跟闭源平台"给你什么你就用什么"的模式完全不同。平台的能力是固定的,ArcReel 的能力是可以不断扩展的。
第三,生成模型不绑定单一平台,持续接入更好的模型。
这是一个很实际的问题:AI 生图和生视频模型迭代非常快。今天最好的模型,三个月后可能就被新的碾压。
很多商业平台绑定了特定的生成模型——平台用什么你就用什么,你没得选。
ArcReel 的设计是模型层解耦。当前默认接入 Gemini 生态(Nano Banana 生图、Veo 生视频),但架构上不绑定任何单一平台。有更好的生图模型出来了?接进来。有更强的视频生成模型了?换上去。作为一个持续维护的开源项目,我们会不断把市面上效果最好的模型集成进来。
你不用担心"选错了平台,被锁死在一个越来越落后的模型上"。
核心痛点(也说实话):
- 需要配置 API Key(Anthropic + Gemini),有一定初始门槛
- API 调用有成本,需要控制预算
- 长剧集仍可能出现一致性漂移(这是当前所有 AI 生成模型的通用局限,不是 ArcReel 独有的问题)
适合谁:想要全流程自动化、不想被平台锁定、追求可扩展能力的创作者和开发者。
◈三种方案对比速查
| 维度 | 手动工作流 | 专业平台 | Agent 驱动(开源) |
|---|---|---|---|
| 交互方式 | 多工具切换 | 平台界面 | 对话式自然语言 |
| 一致性控制 | 靠人 | 平台自动 | Agent 自动 |
| 灵活性 | 高 | 低 | 高 |
| 效率 | 低 | 高 | 中高 |
| 成本 | 低(工具免费) | 平台订阅 | API 调用费 |
| 可定制 | 完全自由 | 不可定制 | 开源 + Skills 可扩展 |
| 生成模型 | 自己选 | 平台绑定 | 可替换,持续接入最新模型 |
| 上手门槛 | 低 | 中 | 中(对话交互降低了技术门槛) |
| 全链路覆盖 | 需手动串联 | 平台内闭环 | 自动串联 |
选型建议:如果你是新手想快速试水,从手动工作流开始。如果你追求工业级质量且不差钱,用专业平台。如果你有技术基础、想要全流程自动化、还想根据需求定制,Agent 驱动的开源方案是最灵活的选择。
06|Agent 驱动方案实操:对话式创作全流程
一句话总结:Docker 一键启动,配三个 Key,跟🦞对话就能跑通全流程。
这部分不展开每一步的详细操作(GitHub 仓库的 README 写得很清楚),重点讲怎么通过 OpenClaw 跟 ArcReel 交互,以及整体体验是什么样的。
◈准备和安装
你需要三样东西:Anthropic API Key(AI 对话推理)、Gemini API Key(生图 + 生视频,支持 API Key 和 Vertex AI 两种认证方式)、Docker 环境。
安装本身很简单:把 ArcReel 仓库 clone 下来,cp .env.example .env,然后 docker compose up -d,等容器启动完成就行了。打开本地服务页面,设置用户名密码,你会看到一个干净的工程管理界面。
当然你可以直接让OpenClaw帮你按照。
◈配置 Key 并接入 OpenClaw
进入 ArcReel 的设置页面,依次把 Anthropic Key 和 Gemini Key 填进去。然后点击"获取 API 令牌"按钮,生成一个 ArcReel 平台自己的 API Key——这个 Key 是🦞和 ArcReel 之间的身份校验令牌。
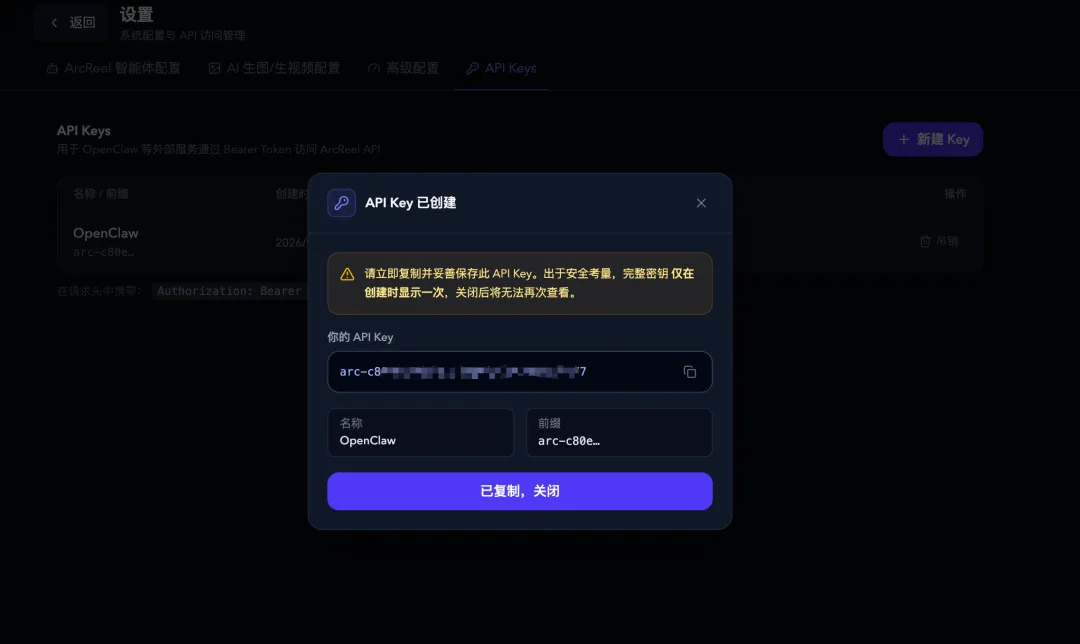
接下来是关键一步:让🦞学会使用 ArcReel。
在 OpenClaw 的任意对话渠道里,给🦞发一条消息:
学习 ArcReel 的 skill.md 然后遵循 skill,了解如何使用 ArcReel 创作视频🦞会自动读取 ArcReel 提供的 Skill 文件,理解所有可用的 API 接口和创作流程。然后你再把刚才生成的 API Key 直接发给它,它就完成了身份绑定。
从这一步开始,🦞就具备了调用 ArcReel 全部能力的权限——写剧本、建角色、生分镜、合视频,全都可以通过对话指令触发。
◈对话式创作:从一句话到完整漫剧
准备工作做完了,接下来就是最有意思的部分——跟🦞聊天做漫剧。
你不需要打开任何编辑器、不需要填任何表单、不需要在不同工具之间来回切换。整个创作过程就是一场对话。
第一步:给主题
直接在聊天框里说:
"主题是重生之校花爱上我"
就这一句话。你不需要给更多信息——当然如果你有具体想法,也可以说得更细:
"主题是重生之校花爱上我,男频向,15集,前三集要有强烈的身份反转和打脸桥段,女主是隐藏的豪门千金"
🦞收到主题后,不会立刻开始动手,而是先跟你确认创作方向:它可能会问你目标受众、风格偏好、集数规划。如果你觉得它问太多,直接说"全部交给你创作"就行,它会自己做决策。
第二步:剧本生成 + 审核
确认方向后,🦞自动开始创作。几分钟后你会看到:
- 故事梗概:整体剧情走向
- 角色设定:主要角色的名字、性格、外貌描述、人物关系
- 第一集分场大纲:每一幕讲什么、用什么场景、角色说什么
同时 ArcReel 的网页端会自动新建一个对应的项目,你可以在网页上更直观地查看所有内容。

这一步是你最需要花时间的环节。 前面讲过,剧本是地基——AI 生成的剧本很可能有角色性格前后不一致、情节逻辑不通顺的问题。你必须通篇读一遍。
发现问题?直接跟🦞说:
- "女主的性格太软了,改成更强势、说话带刺的那种"
- "第二幕的冲突不够,男主应该在这里被当众羞辱,为后面的逆袭做铺垫"
- "角色太多了,把配角 C 和 D 合并成一个人"
- "结尾的悬念不够强,换一个更抓人的 cliffhanger"
🦞会根据你的反馈自动修改剧本,改完你再看,不满意就继续调。这个"对话→修改→再对话"的循环可以反复多次,直到你觉得 OK。
在 ArcReel 网页端和🦞的聊天框里操作效果是一样的——网页端更适合通篇浏览,聊天框更适合快速提修改意见。
第三步:角色设计图
剧本定稿后,告诉🦞:
"开始生成角色设计图"
🦞会根据剧本里的角色描述,自动调用生图模型为每个主要角色生成设计图。这些设计图就是前面讲的"锚点"——后续所有分镜和视频都会自动引用它们作为视觉约束。
生成出来的角色不满意?继续对话调整:
- "女主的发型换成黑色长直发"
- "男主看起来太嫩了,换成更成熟的五官"
- "这个角色的服装风格不对,应该是高定西装不是休闲装"
每次调整后,🦞会重新生成设计图。确认所有角色的形象都满意后,进入下一步。
第四步:分镜图生成
告诉🦞:
"开始生成分镜"
这一步是全自动的。🦞会按照剧本的分场大纲,逐张生成分镜图。核心机制是链式参考——每生成一张新分镜,都会把前一张作为上下文传递给生成模型,确保画面衔接。
同时,前面生成的角色设计图会作为视觉约束注入每一张分镜,保持角色一致。关键道具和场景元素也会被自动追踪。
这个过程不需要你一张张盯,但你可以在网页端实时查看进度。如果中途发现某张分镜有问题:
- "第 5 张分镜的构图太平了,改成低角度仰拍"
- "第 8 张的背景跟第 7 张对不上,应该还是在同一个教室"
- "这张表情不对,女主这个时候应该是愤怒不是微笑"
🦞会重新生成有问题的分镜,后续的分镜也会自动基于修改后的版本继续生成。
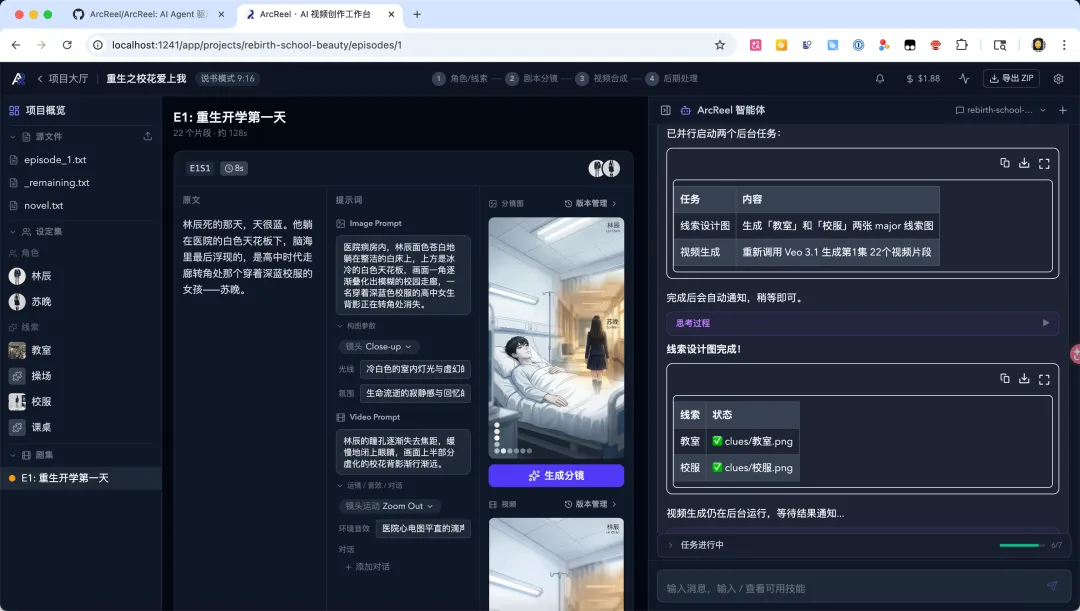
第五步:视频合成
分镜图全部就位后:
"开始生成视频"
🦞会以每张分镜图作为起始帧,调用视频生成模型(当前是 Veo)生成 4-8 秒的视频片段。所有片段生成完毕后,自动用 FFmpeg 拼接成完整的成片。
随时介入,随时回退
整个过程中有两个关键能力:
对话式介入:任何阶段都可以跟🦞说话调整。不只是在特定步骤之间,而是随时。你正在看分镜,突然觉得角色设计有问题?直接说,🦞会回退到角色设计阶段重新处理,然后自动重新生成受影响的分镜。
版本回滚:每一步操作都有版本记录。你在第五步发现第二步的剧本方向不对?一键回滚到第二步的版本,从那里重新开始,不需要从头来过。
这跟手动工作流最大的区别是:手动方案里你是"生产线上的工人",每一步都要亲自操作;Agent 方案里你是"导演",只需要在关键节点做决策,执行层面全交给🦞。
所有的交互都是对话。 你不需要知道 ArcReel 的 API 接口叫什么、参数怎么填——🦞替你翻译成机器能懂的指令。
07|Prompt 工程与实战经验
一句话总结:工具只是辅助,核心还是内容。这些经验能帮你少走弯路。
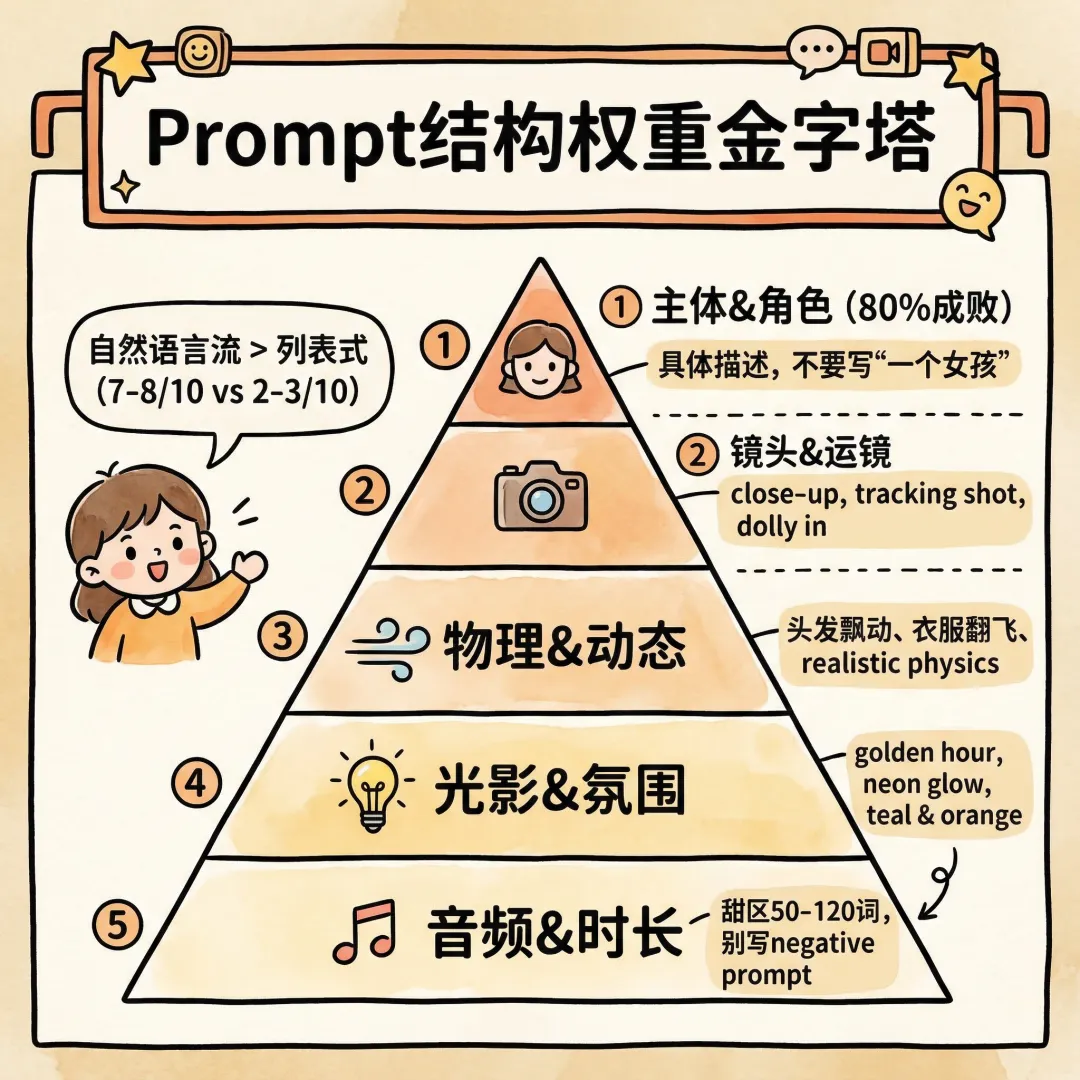
◈Prompt 结构最佳实践
当你需要手动调整某个分镜的 Prompt 时,按这个权重排序:
第一优先:主体 & 角色(决定 80% 成败)
具体描述角色特征,不要写模糊的"一个女孩"。
❌ a girl standing✅ 25-year-old Asian woman, long black hair, red hoodie, determined expression, athletic build用 @角色名 引用预先上传的角色档案(多角度照片),并明确写:maintain same face/body proportions。
限 1-2 个主要角色。角色太多,AI 顾不过来。
第二优先:镜头 & 运镜
这是当前视频生成模型最强的部分。高频有效词:
| 类型 | 关键词 |
|---|---|
| 景别 | close-up, medium shot, wide, over-the-shoulder, low angle, POV |
| 运动 | slow dolly in, tracking shot, panning, crane up, circling 360, whip pan |
| 节奏 | slow motion, quick cut, dramatic pause, handheld shaky |
| 连贯 | seamless transition, continuous motion, one-take feel, match cut |
多镜头写法:Shot 1: wide... → Shot 2: close-up... quick cut to Shot 3...
第三优先:物理 & 动态真实感
必加关键词:realistic physics, natural motion, accurate weight/momentum, fabric flowing, hair swaying in wind, believable impacts, no floating, motion blur on fast action
第四优先:光影 / 材质 / 氛围
| 子类 | 关键词 |
|---|---|
| 光线 | golden hour, neon glow, rim light, volumetric fog, god rays |
| 材质 | wet reflective street, cinematic grain |
| 色彩 | teal & orange, high contrast, desaturated moody |
| 情绪 | epic, melancholic, tense, dreamy |
第五优先:音频同步
with intense orchestral buildup, synced to beat dropsdiegetic sound: footsteps splashing, rain patteringlip sync: dialogue from @audio
长度甜区:50-120 个英文词。 太长后半部分会被忽略。别写 negative prompt(当前主流模型不支持,写了反而干扰)。
具体优于模糊:不要写 beautiful,写 Wes Anderson style, symmetrical composition。
◈我常用的三种 Prompt 写法
以下是我在实际创作中总结的三种场景模板,你可以按自己的题材替换具体内容。
场景一:情绪爆发(适合反转、摊牌、告白)
思路:近景推特写 + 侧光 + 慢节奏,给情绪发酵的空间。
@角色A, 25-year-old woman in white silk dress, standing in dimlylit room, slow push-in from medium to extreme close-up on eyes,single tear rolling down left cheek, soft side lighting castinghalf-face shadow, shallow depth of field, background blurred warmbokeh, hair slightly swaying from open window breeze, melancholicpiano, 8 seconds, natural motion.关键点:只有一个角色、一个情绪、一个镜头动作。越简单越稳。
场景二:对峙紧张(适合霸总、复仇、谈判)
思路:正反打 + 低角度 + 高对比,制造压迫感。
@角色A and @角色B face to face in dark office, over-the-shouldershot from behind 角色B looking at 角色A, low angle emphasizing角色A's dominance, sharp rim lighting on suit edges, tense silencethen 角色A slowly places document on desk, camera pushes inslightly, high contrast teal shadows, realistic fabric texture,10 seconds.关键点:正反打必须明确谁在前景谁在背景,否则空间关系会乱。
场景三:环境交代(适合开场、转场、结尾)
思路:远景 + 缓慢运镜 + 环境细节,建立空间感。
Wide establishing shot of rainy city street at dusk, camera slowlypanning right past neon shop signs reflecting on wet pavement,pedestrians with umbrellas walking, a lone figure @角色A in darkcoat standing still at crosswalk, volumetric fog, warm streetlampglow contrasting cold blue sky, ambient city sounds, 10 secondscontinuous motion.关键点:环境交代镜头角色占画面比例要小,不要让 AI 把人拍成大头贴。
◈题材选择:曝过的还会曝
做 AI 漫剧不要自己"原创"题材——至少不要在起步阶段这么做。
去短视频平台找已经验证过的爆款类型:霸总、真假千金、重生、复仇、甜宠……这些类型有成熟的受众基础,你只需要用 AI 换一个角度重新演绎。
做短视频的都知道:完播率比播放量更重要。平台根据完播率推荐视频,所以宁可做短一点(15-30 秒),也要保证观众看完。
每一集结尾必须留悬念:
- "就在这时,一个神秘男人出现了……"
- "她不知道的是,更大的阴谋正在等着她……"
这些技巧跟 AI 无关,是内容层面的基本功。工具再好,内容不行也白搭。
◈合规红线
这部分不能含糊:
- 不要用真人 IP 二创:最近即梦被迪士尼、华纳等告了,平台对真人 IP 和版权内容的限制越来越严
- 不要用明星脸:用 AI 生成的虚拟人物最安全
- 不要涉及敏感话题:政治、暴力、色情,平台审核直接枪毙
- 注意生成限制:部分平台限制了真人照片直接生成视频,需要先 AI 重新生成一遍,或者转成手绘风格
◈费用控制
Gemini API 按调用量计费,生图和生视频是主要成本项。
建议:
- 先小规模跑通:用 1-2 集验证全流程,确认效果满意后再批量
- 用费用追踪功能:ArcReel 内置了自动费用统计,每次 API 调用花了多少一目了然
- 先短片调参,再拉长:先生成 5-6 秒的短片确认效果,再拉长到 10-15 秒
- 控制角色数量:每个镜头限 1-2 个主要角色,角色越多生成成本越高、一致性越难维护
08|下一步
第一件:理解核心认知。
AI 漫剧是控制问题,不是生成问题。所有高效的工作流,核心都在于如何用最小成本把 AI 的幻觉控制在可接受范围内。角色设定图、场景设定图、结构化 Prompt、Agent 自动化——本质都一样:给 AI 一个锚点。
第二件:选一条路线。
手动工作流适合试水,专业平台适合不差钱的团队,Agent 驱动适合有技术基础且想要全流程自动化的人。没有最好的,只有最适合你的。
第三件:跑一个最小案例。
不管选哪条路线,今天就动手跑一个最小案例。第一次不求效果完美,目的是把链路跑通——从写剧本到出分镜到合视频,先走一遍完整流程。感受一下哪些环节 AI 能自动搞定、哪些环节还是得你亲自把关,然后再迭代。
这个行业还在早期。技术在高速迭代,AI 生成模型的一致性能力每隔几个月就上一个台阶。今天的很多痛点,明天可能就被新模型解决了。
但有一件事不会变:理解 AI 的幻觉本质、学会给 AI 设定边界——这个认知框架,不管工具怎么换、模型怎么升级,都是核心竞争力。
我是宇辰,如果这篇对你有帮助,关注「宇辰AI编程」,我会继续更新同主题的实战教程。加我的 AI 编程交流群一起聊:后台回复「交流群」即可加入。
