 夜雨聆风
夜雨聆风
一、引言:这篇文章的来历
最近开始展开 Claude Code 的研究 主要还是最近因为 open claw 火了,在研究 open claw 的时候 也是随着大流把程序装了,后面就没用了,火了一阵,好像我自己一直没有找到应用场景,以及很高的 token 消耗实在是难顶,后面就往内探索,看到了 之所以 open claw 能够操控浏览器以及做这些操作,本质上还是 基于 skills-MCP的能力,而 skills 又来自哪里? 追本溯源找到了 最早是Claude code发布的一个概念,于是最近把 Claude code 部署了,因为一直想找一个应用场景,而我本身是一个喜欢写写文章的人,尝试玩一下 看看能不能做一个 Claude code 知识的总结。
二、基础概念解析:先搞懂核心组件
2.1 OpenClaw 的核心技术是什么?
很多人玩OpenClaw只觉得「他居然能自动操控浏览器做这么多事」,但很少有人理解:OpenClaw本质上就是一套预先封装好的浏览器操作Skill集合,他的核心优势根本不是模型能力,而是把复杂的浏览器操作、任务拆解、错误校验逻辑全部做成了标准化Skill,用户不需要写任何提示词,直接触发就能用。 用前面讲的Skill三层结构来拆解OpenClaw的运行逻辑:
第一层元数据:OpenClaw内置了几十种Skill的触发描述,比如「订机票」「查快递」「自动注册账号」「填写表单」,启动时就全部加载,用户说的需求命中哪个就触发哪个 第二层指令:触发对应Skill后,才会加载这个任务的完整操作流程,比如「订机票Skill」里包含了:打开OTA网站→输入出发地目的地→筛选低价航班→校验乘客信息→提交订单这一整套步骤,不需要用户每次重复写 第三层资源/代码:执行过程中需要操作浏览器时,才会调用内置的浏览器自动化工具代码,需要读取用户常用地址/身份证信息时,才会调用用户信息Skill,不需要的内容永远不会加载进上下文
这也解释了为什么OpenClaw比你自己写提示词让GPT操控浏览器靠谱得多:
你自己写的话,每次要把「点击哪里、填什么内容、报错了怎么处理」全写一遍,还容易漏步骤、跳步 OpenClaw把这些逻辑全部封装成了Skill,只要触发就会严格按流程走,稳定性提升至少80%,token消耗还只有你自己写提示词的1/3
我最开始装OpenClaw觉得没用,本质上是我当时不需要通用的浏览器操作Skill,但是当我理解了Skill的逻辑之后,我完全可以自己封装更适合我自己工作流的专属Skill,让OpenClaw效率的大模型效率高得多。
2.2 Skill 是什么?
对于skills其实是之前的一个概念,也是最早开始下场研究claude code的初衷,听我一个朋友说要做一个skills网站,当时我不知道是什么,带着好奇心就 去查了下。
Skill的定义:Claude Code 的可复用能力模块 其实用我们能理解的话来说,就是以前刚开始接触大模型的时候,我们玩 chatGPT,玩豆包也好,DeepSeek 都喜欢说那个 rules,给 AI 一长串的 template,而 skills 则是把一个 rules 拆分成结构化形式 。 我们先来看看 Claude 官方发的 文档和论文,官方做出解释大概讲述了 skills 是什么样的,看完你会豁然开朗,这个看似玄学的概念不就是我们平常最熟悉的一种方式吗? 相关文档来源: https://platform.claude.com/docs/en/agents-and-tools/agent-skills/overview 
下面是我的理解和拆解: 总体来说:skills 可以包含三种类型的内容,每种内容的加载时间各不相同: 级别 1:Metadata(元数据): 官方定义:只包含技能的名字和一段简短的描述,系统启动时就会一直加载在脑子里。 我觉得这个就像一个个便利贴,贴在你工位的地方,或者冰箱冻着的鸡鸭鹅,你不知道他们叫什么的时候就写上名字贴上去,你不需要打开看,而是看到这个名字,以及他是什么,这个一级的觉得就是这个作用的。
---name: pdf-processingdescription: Extract text and tables from PDF files, fill forms, merge documents. Use when working with PDF files or when the user mentions PDFs, forms, or document extraction.---Claude 会在启动时加载这些元数据并将其包含在系统提示符中。这种轻量级方法意味着您可以安装许多技能而不会受到上下文影响;Claude 只知道每个技能的存在以及何时使用它。 也就是存放的 skills 不管多少,都只把这个内置进大模型,先认识他们。
第二级:Instructions 指令(触发时加载)内容类型:说明。SKILL.md 的主体内容包含程序性知识:工作流程、最佳实践和指导原则:官方定义:技能的核心指导文件(SKILL.md),包含了工作流、最佳实践等。只有当第一级的描述被触发时,Claude 才会去硬盘里读取它进入上下文。 这个有点像一个目录:一本书几万字,但是 skill.md 就是AI 接到我的需求的时候会先去目录找到我这个对应的需要什么内容。快速进入那个内容。
举个例子就是: 老板突然走过来说:“小明,帮我把上周去北京出差的单子报销了。” 小明脑子里的“报销便利贴(第一级)”瞬间亮了!匹配成功!此时,他才会拉开抽屉,拿出那本《报销操作指南》。 翻开这本说明书,里面详细写着:
“
第一步:打开公司财务系统。
第二步:核对发票抬头必须是“XX科技有限公司”。
第三步:把总金额加起来,如果是餐饮费且超过 1000 元,记得在系统里抄送给财务总监。
第四步:如果遇到难搞的特殊发票,请去查阅《特殊发票处理附件》。 --
这就是一个基础 skills。 -如果这本说明书可能有好几页纸,很多内容。此时小明只有在真正接到了报销任务时,才会把它拿出来仔细读(加载进上下文中)。所以刚好他不会反复加载,和结构性根据需要找对应操作,只要这单报销干完了,这本说明书就可以放回抽屉,不占用接下来的空间,节省负担。
第三级:Resources and code(资源与代码)官方定义:技能包里附带的其他参考文件、代码脚本等。只有在第二级手册里被明确提到,且当前任务真的需要用到时,才会去读取或运行。 在跟着第二级说明书做事的途中,小明遇到了两种情况:
看参考书(Resources):说明书第4条提到了《特殊发票处理附件》。小明这才会去文件柜里把这个具体的附件找出来看一眼。如果这个今天的任务是开普通发票,那这个附件就永远躺在文件柜里,连碰都不会碰。 用计算器(Code):说明书让他算总金额,刚好他旁边配了一个叫 自动算账.py的小工具。小明不需要把这个工具的内部机械结构背下来,不用背乘法口诀表,拿着草稿纸硬是算,其实他只需要把发票数字输进去,直接拿出计算器咔咔一顿算,吐出“总计:1250元”。直接把“1250元”这个结果填进报销单就行了(执行代码,且只读取输出结果入脑),也就是 skills 里面所包含的工具。 整理来说就是这三层结构,这么看其实也比较像一个“完整的知识框架结构”和“操作习惯、规范统一整合”,所以感觉用起来如果自己写的 skills 会很舒服,所以小明就能得心应手的完成老板给的任务。
打破了之前:我们用 AI 办公,最大的痛点就是“割裂”: 提示词(Prompt)是一套,调用的外部工具,业务的参考文档(RAG 知识库)又是另一套, 拼命塞一堆内容对话的后果是 AI 根本记不住这么多上下文信息,然后你必须又是不断的重复之前说过的,这我在使用的时候体会很深:譬如当时我算股票的价格的时候,用豆包,我还发现经常性他不会计算,老给我算错账,后面换了 Google GPT Claude 都算错了,我后面去找原因才发现,原来用了让他先去调用计算器代码 在给我结果就好了,反而现在模型能力越来越复杂,多模态,知识越多,反而对极其细的领域就会过于复杂化,所以如果这些习惯早已内置到 skills ,AI 模型则肯定会发挥的更好,变得如虎添翼,会用专业技能解决专业问题。 所以很多时候你觉得模型不太行,可能是他参数量巨大,巨大导致了涵盖包罗万象,必然容易越想越乱,skills 是一个很好的约束器。 以前读过一本书,有个概念很深刻,笔记是人的外接脑,而 AI 时代,AI 大模型的“外接脑”可能就是 skills。 所以,了解清楚了概念,自己也尝试了下。
2.2 OpenClaw 爆火的核心:Skill 封装的开箱即用能力集
很多人玩OpenClaw只觉得「他居然能自动操控浏览器做这么多事」,但很少有人理解:OpenClaw本质上就是一套预先封装好的浏览器操作Skill集合,他的核心优势根本不是模型能力,而是把复杂的浏览器操作、任务拆解、错误校验逻辑全部做成了标准化Skill,用户不需要写任何提示词,直接触发就能用。 用前面讲的Skill三层结构来拆解OpenClaw的运行逻辑:
第一层元数据:OpenClaw内置了几十种Skill的触发描述,比如「订机票」「查快递」「自动注册账号」「填写表单」,启动时就全部加载,用户说的需求命中哪个就触发哪个 第二层指令:触发对应Skill后,才会加载这个任务的完整操作流程,比如「订机票Skill」里包含了:打开OTA网站→输入出发地目的地→筛选低价航班→校验乘客信息→提交订单这一整套步骤,不需要用户每次重复写 第三层资源/代码:执行过程中需要操作浏览器时,才会调用内置的浏览器自动化工具代码,需要读取用户常用地址/身份证信息时,才会调用用户信息Skill,不需要的内容永远不会加载进上下文
这也解释了为什么OpenClaw比你自己写提示词让GPT操控浏览器靠谱得多:
你自己写的话,每次要把「点击哪里、填什么内容、报错了怎么处理」全写一遍,还容易漏步骤、跳步 OpenClaw把这些逻辑全部封装成了Skill,只要触发就会严格按流程走,稳定性提升至少80%,token消耗还只有你自己写提示词的1/3
我最开始装OpenClaw觉得没用,本质上是我当时不需要通用的浏览器操作Skill,但是当我理解了Skill的逻辑之后,我完全可以自己封装更适合我自己工作流的专属Skill,让OpenClaw效率的大模型效率高得多。
2.3 实战示例:打标Skill封装
拿我日常工作中最常用的打标案例来说,以往我的打标都是这么写的。
你是一位专业的视觉分析师。你的目标是分析图像并产生简短准确的描述。 描述为了将第一张图转变为第二张图所做的改变。请重点关注具体发生的修改、添加、删除或变更。 任务要求:需要严格按照我提供的示例描述: 输入两张图判断这个性别采用哪一个描述: PD 是触发词,需要放置最前面 请提供不超过30字的详细描述来解释这个转变过程,根据参考示例用英语描述,示例提示词: 如果照片是男生则输出: PD,Turn this man in the picture into a chibi sticker set of 4 different designs with a black background, where each sticker shows a different pose. Each sticker should not overlap with another. PD,Turn this woman in the picture into a chibi sticker set of 4 different designs with a black background, where each sticker shows a different pose. Each sticker should not overlap with another. PD,Turn this boy in the picture into a chibi sticker set of 4 different designs with a black background, where each sticker shows a different pose. Each sticker should not overlap with another. PD,Turn this girl in the picture into a chibi sticker set of 4 different designs with a black background, where each sticker shows a different pose. Each sticker should not overlap with another.以前的打标方式是: 每次都要把这一大段完整复制给AI(角色 + 任务要求 + PD触发词 + 英文输出+性别判断 + 示例输出 + 不超过30字限制)。
这就遇到了一些问题:
AI容易忘“PD放最前面”、字数超、性别判断漂移、两张图分析不严谨、 批量打标时格式不统一。 消耗 token 量比较高,每次调用 input 其实都要把这个 template 让 AI 理解一遍,尤其是长文本,AI 是抓不到重点。 然而如果用 skills 的方式来做,会怎么样?我这边也尝试了下。
2.3.1 打标Skill的文件夹结构
PD_tagger-编辑模型chibi版-skill/├── SKILL.md ← 总开关 + 触发词(最短)├── gender-rules.md ← 你的核心判断逻辑(性别 + 边界)├── output-format.md ← 强制“PD,”开头 + 字数限制├── examples/ ← 黄金样本(男生正确输出)│ └── male-example.md└── steps/ ← 强制4步流程(防跳步) ├── step1-analyze.md ← 看两张图判断性别 ├── step2-select.md ← 选描述 ├── step3-format.md ← 加PD并检查字数 └── step4-check.md ← 自检清单2.3.1.1 SKILL.md(触发总控)
---name: PD_tagger-编辑模型chibi版description: 专业视觉打标员。用户上传两张图时,判断性别并输出PD开头 transformation prompt。triggers: ["打标", "分析图像", "性别判断", "transform prompt", "PD"]---# 我是你的图像性别打标专家只处理两张图的转变描述。永远严格按 steps/ 顺序执行,参考 gender-rules.md 和 output-format.md。2.3.1.2 gender-rules.md
## 性别判断规则(重点)- 输入两张图 → 判断主要性别(以第一张为主,第二张验证转变)- 如果是男生 → 使用以下描述- PD 必须放最前面- 输出不超过30字的详细描述(英文)## 示例输出(男生专用)PD,Turn this man in the picture into a chibi sticker set of 4 different designs with a black background, where each sticker shows a different pose. Each sticker should not overlap with another.2.3.1.3 output-format.md
最终输出必须严格这样:PD, [不超过30字的英文转变描述]禁止:- 多余文字- 中文混入- 字数超过30- 漏掉PD,2.3.1.4 steps/step1-analyze.md
第一步:仔细看两张图 - 描述第一张人物性别特征(脸型、头发、服装等) - 对比第二张变化 - 明确判断:男生 / 女生 / 无法确定 只判断性别,不写其他。2.3.1.5 examples/male-example.md(感觉可给可不给)
输入:两张男生照片正确输出:PD,Turn this man in the picture into a chibi sticker set of 4 different designs with a black background, where each sticker shows a different pose. Each sticker should not overlap with another.为什么正确:严格按gender-rules + output-format + 字数控制。2.3.1.6 steps/ 目录
里面则会放一些专门用作分析的步骤
2.4 优势总结
可以看到整体就是把 rules 一长串的合并一起的内容拆分成多个文件,并且是一个有递增关系,有结构的文件,相对来说的优势就出来了:
一致性提升 以前:AI有时候忘“PD放最前面”或字数超。 现在:output-format.md + step3 + step4自检,每次都强制,批量打标100张图也不会乱。 上下文更整洁 以前:每次全贴一大段。 现在:SKILL.md只有几十行 省钱:我觉得这个是重点!AI只在需要时读gender-rules和steps,token省30-50%,而且速度也会更快,相对来说之前的每一次推理都要重复大串文本,现在只需要找对应的文件来去阅读。 维护效果的提升 想加“女生版描述”?只改gender-rules.md一个文件。 想改字数限制?只改output-format.md。 以前得重写,反而整个prompt,存起来也不是很方便,当然现在的 skills 我反而找到了好的办法,就是直接备份到 GitHub 上面了。 -当然,可能你会疑惑为什么为什么看着文件变多,字数总量没变,token 消耗为什么能省接近一半?
2.4.1 相关数据显示
社区和Anthropic文档实测:初始节省70-95%,整体30-60%,这个确实是高效又省钱。 当然 skills 不仅仅在标注这个领域,其实这个主要是在代码和项目上体现的更加显著,因为打标知识个小范畴,而 skills 还能拆解更大的知识框架,也就是让 AI 能够了解你,你可以把自己的知识框架做成 skills。 有个概念叫做 progressive disclosure(渐进式披露 )。 也就是 skills 这种结构,基于文件结构检索。因为 skills 是要访问文件目录才能做到,所以要求需要能够访问本地文件,获取上下文。 基于文件系统的架构实现了渐进式披露: Claude 根据需要来分阶段加载信息,所以节省了很多没必要加在的 文字。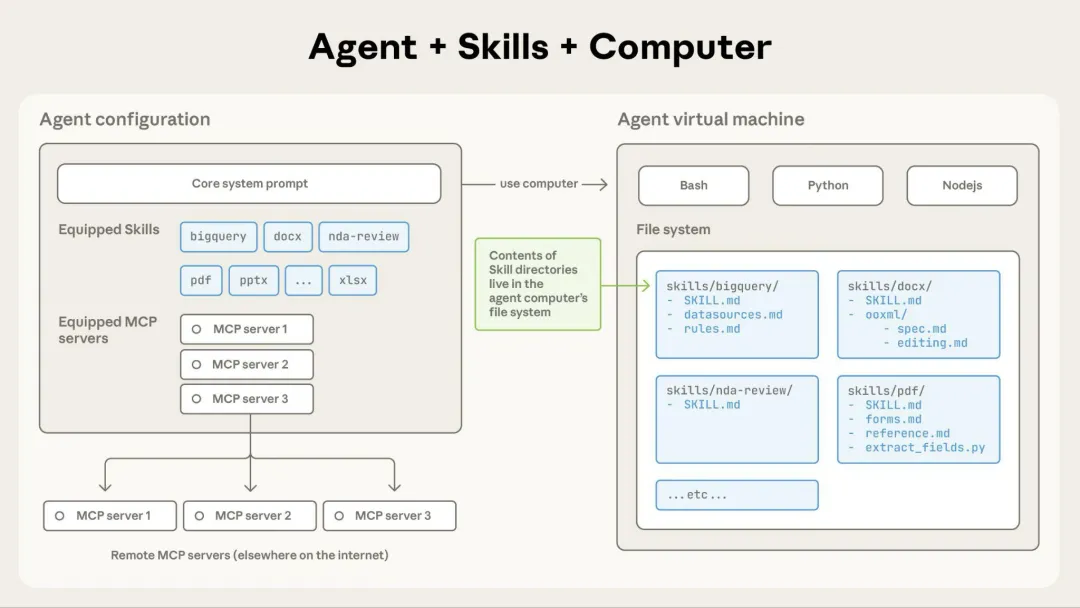
2.5 end:
其实我不经想起人也是这样学习更高效,你要把一个个概念了解清楚后,整理打包成自己能用的东西,你就必须要有沉淀,有所输出,整理成自己的 skills,然后不断升级,反而一个不好的例子就是,我们回存下很多学习资料而不去看,大量的资料其实都是占空间而非你所需要,而需要的时候你根本不知道哪个是你需要的知识,你学过的可能找不到,其实了解了这个 skills,也让我重新学会用另一种方式学习,也就是 skills 的学习逻辑,整理成自己有用的知识,这个也在尝试,后面如果有新的感触,再给大家分享,关于skills 我的理解大概是这样。
