 夜雨聆风
夜雨聆风你有没有想过,让 AI 帮你操作浏览器,自动完成那些需要登录、需要浏览的网页任务?
一、问题背景
作为要写公众号的生物信息工程师,必须啥都要会一点,我经常遇到这样的场景:
需要从某个网站批量获取数据,但网站没有 API 需要登录后才能看到的内容,爬虫搞不定 MCP 工具连不上,HTTP 模式有 session 限制
最近想用 AI 帮我查看小红书博主的粉丝数和笔记数据,结果发现:
- 小红书 MCP 工具
只支持 HTTP 模式,无法保持登录状态 - 直接爬虫
需要处理 cookies、验证码,太麻烦 - 手动操作
数据量大时效率太低
于是,我发现了一个神器 —— OpenClaw Browser Relay。
二、什么是 Browser Relay?
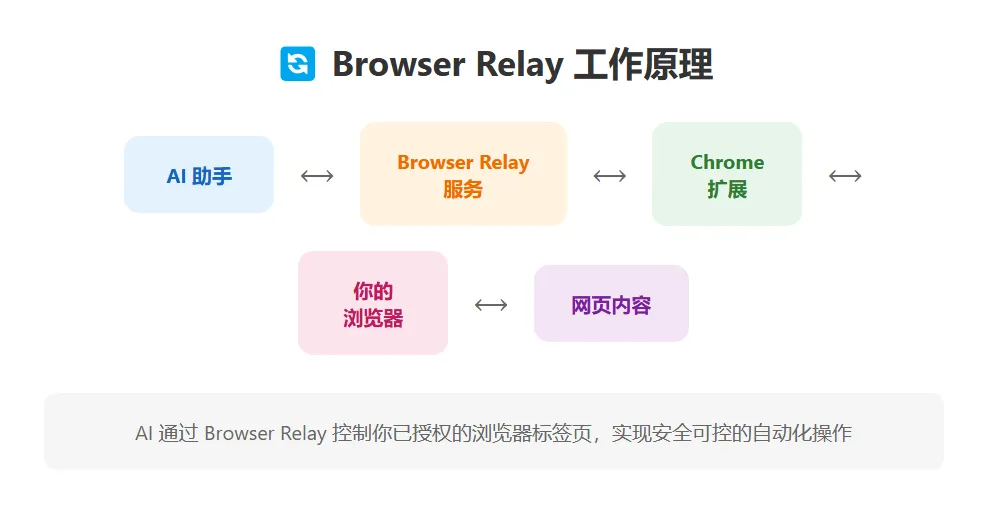
简单来说,Browser Relay 是一个 浏览器控制桥梁:
AI 助手 ⟷ Browser Relay ⟷ Chrome 扩展 ⟷ 你的浏览器 ⟷ 网页内容
核心优势:
| 安全可控 | |
| 无需登录 | |
| 实时交互 | |
| 支持动态页面 |
三、它能做什么?
📍 场景 1:数据采集
让 AI 帮你从网页提取数据,比如:
小红书博主粉丝数、笔记数据 电商网站商品价格对比 社交媒体账号信息
📍 场景 2:自动化操作
填写表单 批量操作 定时任务
📍 场景 3:信息汇总
浏览多个页面,汇总关键信息 对比分析不同来源的数据
四、与传统方案的对比
| Browser Relay | ||
| MCP 工具 | ||
| 爬虫脚本 | ||
| 手动操作 |
五、下一篇预告
在下一篇文章中,我会详细介绍 Browser Relay 的安装配置过程,以及遇到的一个关键问题:端口配置。
💡 关键发现:Browser Relay 端口 = Gateway 端口 + 3
本文是「让 AI 控制你的浏览器」系列第一篇,欢迎关注后续内容。
关于作者:专注基因检测和变异分析。正在从零开始学习 AI/ML,记录真实的成长过程。
