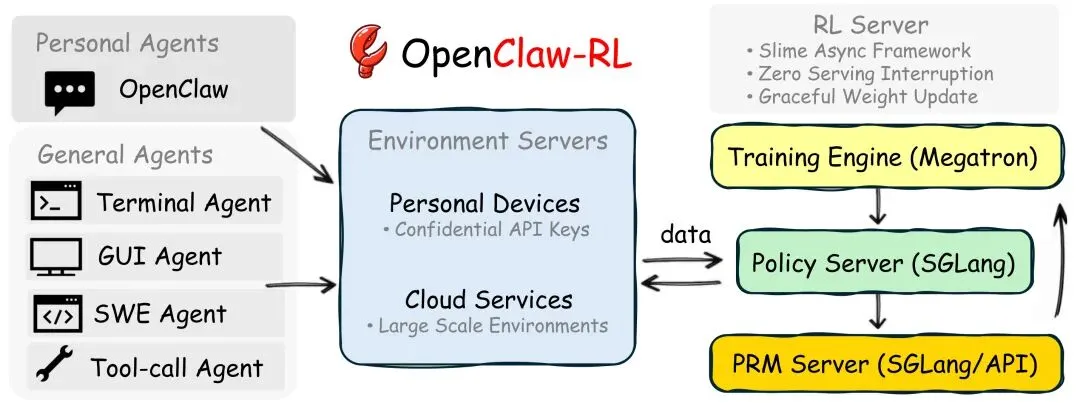
Princeton 提出 OpenClaw-RL:从用户交互信号中持续训练智能体的在线强化学习框架📌 一句话总结:本工作提出 OpenClaw-RL,一个利用 next-state signals(下一状态信号)进行在线强化学习的统一框架,使智能体能够在真实交互过程中持续学习,实现个人助手与通用 Agent 的统一训练。 🔍 背景问题:当前 Agent 强化学习系统通常依赖离线数据或终局奖励信号,存在两方面限制:1️⃣ 大多数 RL 训练依赖预收集数据或终局奖励,无法充分利用真实交互中的即时反馈信号;2️⃣ 不同类型 Agent(对话、GUI、终端、SWE、工具调用)通常采用不同训练框架,难以统一学习与扩展。 💡 方法简介:提出 OpenClaw-RL 框架,将真实交互中的 next-state signals(如用户回复、工具执行结果、GUI 状态变化等)转化为强化学习信号,实现在线持续优化:构建异步 RL 基础设施,由 policy serving、环境执行、PRM 评估和策略训练四个模块解耦运行,实现 在线训练且不影响推理服务;提出两种互补的学习机制:Binary RL:通过 PRM(Process Reward Model)将下一状态信号转化为二值奖励,实现基于过程奖励的策略优化;Hindsight-Guided On-Policy Distillation(OPD):从下一状态信号中提取纠正提示,构造 hint-enhanced context,通过 token-level advantage 进行蒸馏学习;将 Binary RL 与 OPD 结合,通过混合优势函数同时利用 评价信号与方向信号,提升训练效率与稳定性。 📊 实验结果:在个人助手场景中,仅通过几十次真实交互即可显著提升模型个性化能力,例如更自然的学生作业写作风格或更友好的教师反馈;在通用 Agent 任务中,框架支持 terminal、GUI、SWE 和 tool-call 等多种环境,并可通过并行环境扩展到大规模 RL 训练;实验表明,将 过程奖励与终局奖励结合比仅使用终局奖励获得更好的性能表现。 📂 开源链接:https://github.com/Gen-Verse/OpenClaw-RL📄 论文原文:https://arxiv.org/abs/2603.10165✨ 一句话点评:OpenClaw-RL 将真实交互中的 next-state signal 转化为在线强化学习信号,使 Agent 可以“边用边学”,为长期运行的智能体提供了一种可持续自进化的训练范式。
 夜雨聆风
夜雨聆风