 夜雨聆风
夜雨聆风全市场AI人工智能ETF一共32只,总规模837亿,主要跟踪6大指数。
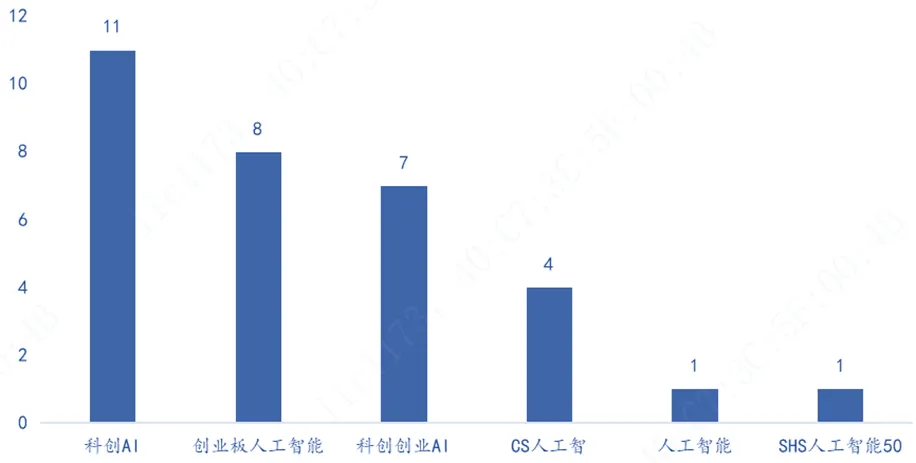
其中,跟踪科创AI指数的ETF基金数量最多,一共11只,跟踪CS人工智的ETF基金总规模最大,一共392.55亿,其中不乏百亿基金,比如人工智能AIETF(515070.SH)总规模107.75亿,人工智能ETF易方达(159819.SZ)总规模246.88亿。
图:跟踪指数的ETF基金规模
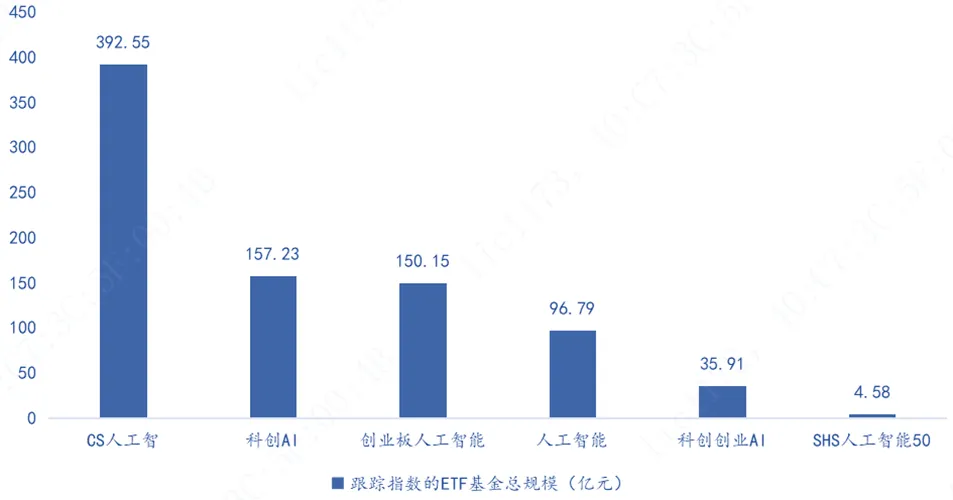
图:跟踪指数的ETF基金数量

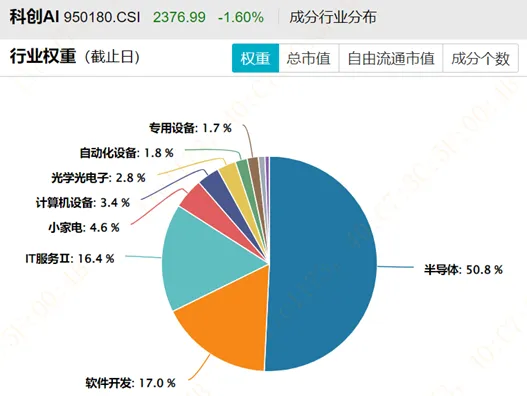
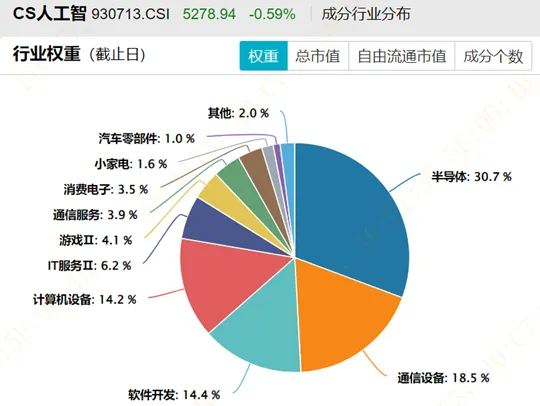
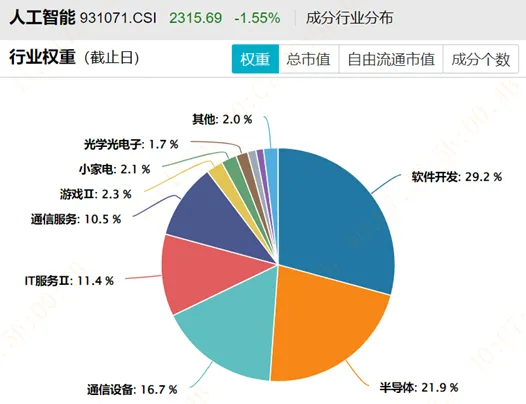
再如,创业板人工智能(970070) 高度集中于通信设备,合计权重42.4%,光模块“易中天”合计占比33%,更像是“AI算力基建指数”。
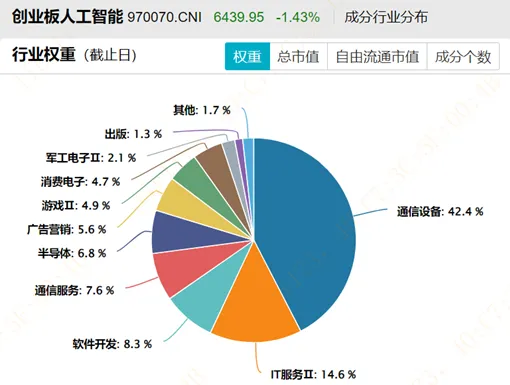
相比之下,CS人工智(930713) 和 人工智能指数(931071) 权重更分散,更能体现“AI全产业链”,也更符合人工智能主题基金的定义。
蝴蝶效应在2025年3月推出的全球首款通用AI智能体产品Manus,被视为“打响了国内 AI Agent的第一枪”,内测码一度被炒到10万元。根据口令可以自主调用多种工具,完成写代码、做旅行攻略、买票等任务。
3月产品上线,12月被收购。也就是说,蝴蝶效应从产品发布到卖掉一共仅耗时9个月。2025年末Meta宣布,将以数十亿美元收购开发AI应用Manus的公司蝴蝶效应。
openclaw不是第一款智能体,为何爆火?
真正的突破不在技术本身,而在生态模式。
2个有趣的比喻道出了2者的差别:
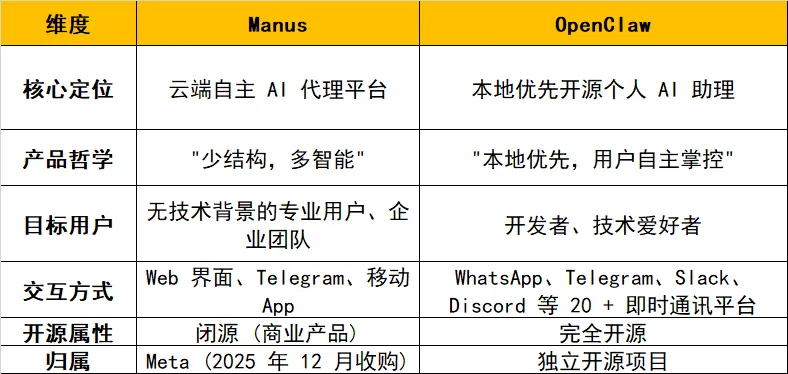
manus是租房,openclaw是买房;manus是苹果,openclaw是安卓。
如果说manus代表着"云端托管、开箱即用"的闭源商业化路线,那么openclaw则以"本地优先、开源自主"的理念占据优势。
openclaw开源带来了2个核心优势:
首先,免费;
其次,个性化,养成系。
openclaw本身不包含大模型,也不内置技能,需要开发者编写或下载。这使得其个性化程度更高,可以说,一千个开发者有一千个openclaw,这种养成系的情绪价值是manus无法比拟的。
表:manus和openclaw的对比
二、养龙虾所需的token到底是啥?
虽然openclaw是免费的,但是养龙虾依然是有成本的,具体而言:
1、硬件成本
本地部署:使用现有电脑或购置新设备费用
云服务器部署:租用云服务器也要费用
2、模型调用成本
传统对话推理基于单次请求-单次响应模式,整体Token消耗可控,而面向Agent的简单指令可轻易触发数十次循环,一个小任务轻松烧掉几百万甚至上千万Token,带来了Token消耗量的指数级增长。
3、网络成本
4、学习成本
其中,大头的费用就是调用大模型的Token消耗,它就像是开车的油费一样,动一下就是一个钢镚。
我们来看看这个token到底是啥,咋生产出来的呢?到底有啥生产成本,为啥不让我们免费用?
Token,原本译作“代币”,在 AI、大模型语境下,意为“词元”,是大模型处理和生成文本的基本单位 。用户调用模型按 Token 付费。
Token是大语言模型处理文本的最小单位。它不是"字",也不是"词",而是介于两者之间的语言碎片。模型在训练和推理时,看到的不是原始字符串,而是一段被切分好的 Token 序列,比如:
"Hello, world!" → ['Hello', ',', ' world', '!'] :4 个 Token
"大语言模型" → ['大', '语言', '模型'] :3 个 Token
模型处理过程:你的文字-> 分词-> [Token1, Token2, ...]-> 查表转数字-> [ID1, ID2, ...]-> 模型进行数学计算-> [IDx, IDy, ...]-> 数字转Token-> [TokenX, TokenY, ...]-> 拼接-> 模型的文字回复。
中文比英文更“费钱”。
比如deepseek的API文档中:一个英文字符=0.3个token;一个中文字符=0.6个token。

各大模型 API 的计费方式基本统一:输入Token + 输出Token分开计费,输出通常比输入贵。
还是以deepseek的API文档为例,百万token输出费用是3元,输入费用是0.2-2元。
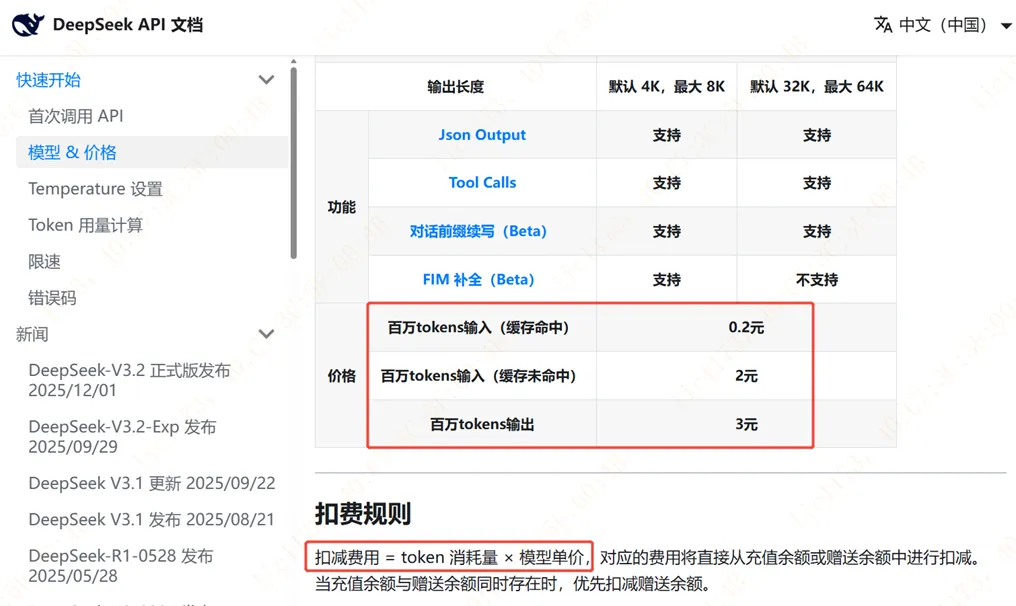
这里的输入百万token计费分为缓存命中和未命中,命中是0.2元每百万token,未命中是2元每百万token。这里的缓存命中、未命中的意思是:
缓存命中:系统直接从缓存中读取已计算的结果,无需重新执行模型的推理计算,消耗的算力资源极少,响应速度也更快。
缓存未命中:模型需要从头开始对输入的token进行完整的推理计算,消耗的算力资源较多,响应时间相对较长。
这时候有小伙伴要问了,咦,为啥我平时用豆包APP也没收费啊?是没消耗token吗?
不是的,这是平台为了引流,且普通的对话消耗的token很少,所以免费了。
如果你想通过平台制作视频,这时消耗的token就多了,可能你就需要订阅了。
这里还要做一个区分,APP和API。
token怎么生产的呢?原材料是啥?
电力和算力是 Token 的“原材料”。
Token 成本中,电力 + 算力占比超 70%,运维人力(15%-20%)、带宽(10%-15%,国际带宽更贵)。
中国在电力成本上有明显优势。工业电价约为美国 1/3,西部绿电(水电/风电/光伏)成本仅 0.2–0.3 元/度。
“东数西算”+GPU 集群 ,单位 Token 成本仅为欧美同行1/5–1/20。
图:国外大模型API的报价(3月,价格均为官方标准定价(Standard tier),不含缓存折扣及批量折扣,汇率参考1美元≈7.2元人民币)
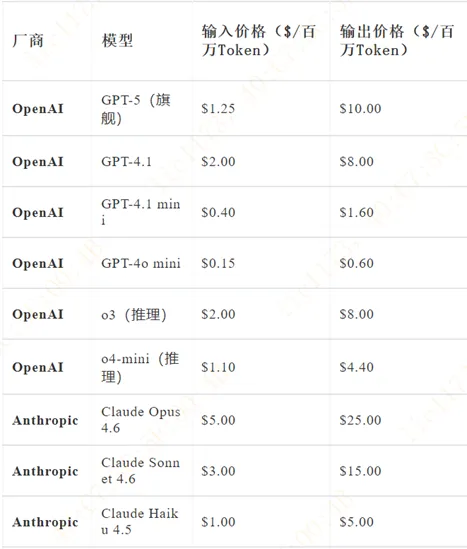
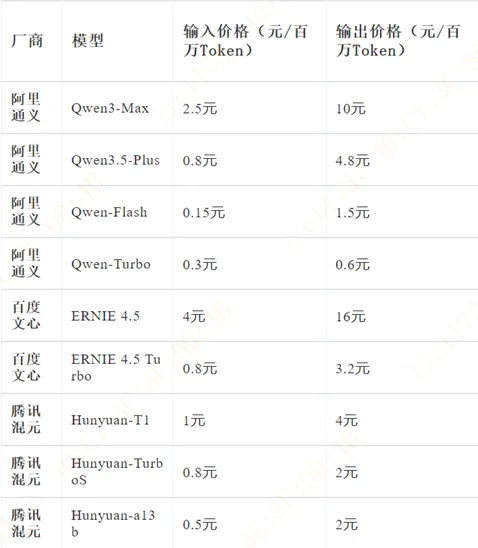
图:国内大模型API的报价(3月)
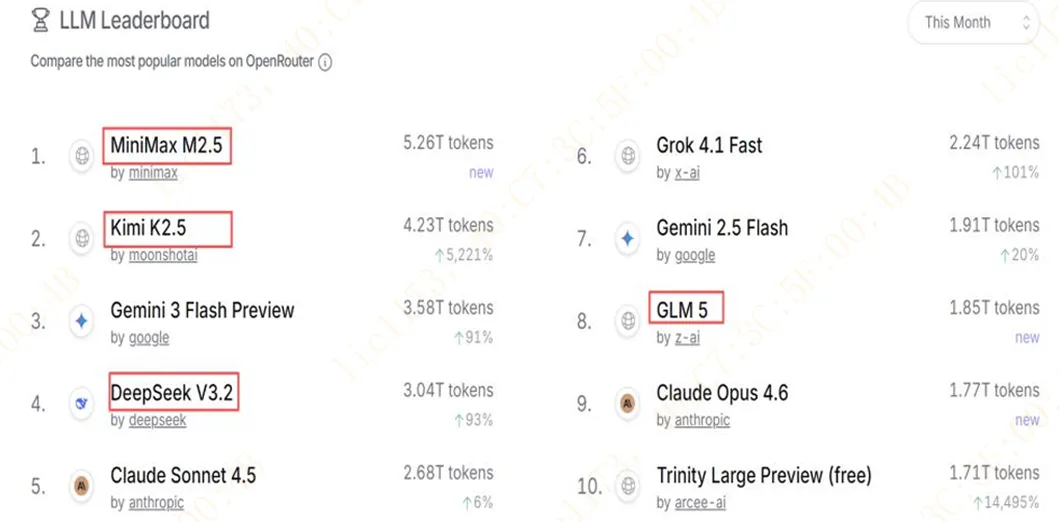
结果就是,全球开发者 “用脚投票”,我国大模型token用量占比大幅提高。
全球头部AI模型API聚合平台OpenRouter的数据显示,2026年2月,中国AI模型的调用量三周大涨127%,首次超越美国模型,全球前五中占据四席。
2月16日至22日的周榜单中,平台调用量排名前五的模型中,有四款来自中国厂商,包括MiniMax的M2.5、月之暗面的Kimi K2.5、智谱的GLM-5、DeepSeek 的 V3.2。
这四款模型合计贡献了Top5总调用量的85.7%。一年前,中国模型在这个平台上的份额不到2%。
图:2026 年 2月,四款中国大模型调用量显著增长(资料来源:OpenRouter)
上游是“AI养龙虾”的动力源泉,围绕算力供给、硬件适配等展开,直接决定openclaw的运行效率与场景覆盖范围,也是产业链中技术壁垒最高、资本投入最大的环节。算力基础设施分为云端与本地两大板块。
中游是“AI养龙虾”产业链的核心枢纽,大模型是openclaw的“大脑”,其适配能力直接决定执行效率。
随着工信部安全预警发布,安全加固成为中游刚需。
下游是“AI养龙虾”的价值落地端,场景需求的多样性直接决定了产业链的延伸空间。
图:Agent产业链上下游(资料来源:艾媒咨询)

四、智能经济首次写入政府工作报告,各地纷纷出台养龙虾政策


这也是为什么openclaw爆火以后,各地纷纷出台养龙虾政策的原因。
比如,3月6日,合肥高新区正式发布15条硬核举措,称全方位护航OpenClaw等开源AI项目落地深耕,致力打造“AI+超级个体/一人公司(OPC)”新业态标杆,最高予以1000万元资金扶持。
再如,3月7日,深圳市龙岗区人工智能(机器人)署发布《支持OpenClaw&OPC发展的若干措施(征求意见稿)》,包括10条支持内容。其中提出,鼓励市场化、专业化平台载体推出“龙虾服务区”,免费提供OpenClaw部署服务,符合条件的给予一定补贴等。
又如,3月9日,无锡高新区发布12条“养龙虾”政策,“单项支持最高达500万元”,常熟市推出13条硬核举措。
五、重视 openclaw“养龙虾”核心方向
政府工作报告首次将“算电协同”、“智能经济”纳入国家战略,“人工智能+”则是连续三年写入政府工作报告。按照2025年8月国务院印发的《关于深入实施人工智能+行动的意见》,2027年智能体应用普及率目标是70%,2030年要求是普及率90%。此次openclaw爆火,各地纷纷出台支持政策。智能体发展符合国家发展规划和要求,值得长期关注。
openclaw 作为当下用户关注度最高的项目之一,有望推动 AI 产业进入 Agent 时代,Token及国内大模型出海机遇来临。openclaw的部署和国内token出海,增强了对国内算力的需求,同时也拉动电力需求增长。有券商测算,OpenClaw应用在两年内或可创造最大25%的新增算力需求。《数据中心绿色低碳发展专项行动计划》要求到2025年底,国家枢纽节点新建数据中心绿电占比超过80%,算力需求增加也将大幅拉动绿色低成本电力需求,而储能作为调节装备也会成为刚需。
重视 OpenClaw“养龙虾”核心方向:
算力基础设施:AIDC(Artificial Intelligence Data Center,即人工智能数据中心)建设相关的国产AI芯片、服务器、液冷、网络。
电力支持:绿电、储能。
模型厂商:用户需求逐步转向解决复杂任务能力,高阶推理模型API有望迎来全面提价,技术壁垒的稀缺性逐渐凸显。
云厂商:算力需求激增,算力租赁服务需求提升,拥有AI云服务定价权并具备token出海业务布局的云厂商直接受益。
Agent安全:刚性需求,OpenClaw全面接管系统权限和业务流带来巨大安全风险,安全将逐步成为Agent应用落地的强制性前置条件。
