 夜雨聆风
夜雨聆风OpenClaw 系列
架构分析
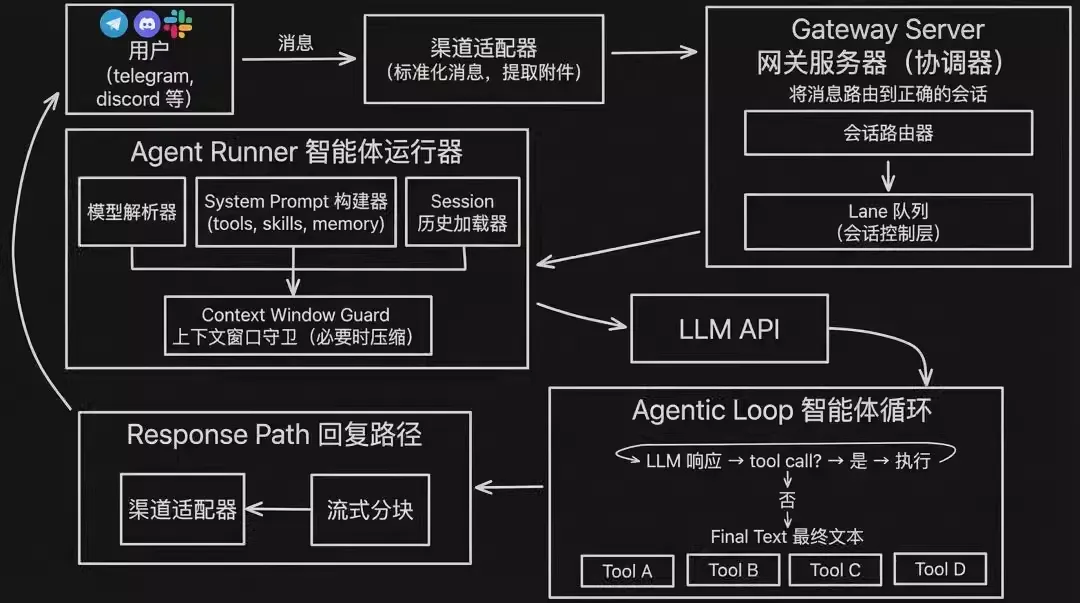
Channels(通道):连接各种消息平台,提供统一消息接口。支持:飞书、钉钉、WhatsApp、Telegram、Discord、Slack、SMS 等,让 AI 与用户的日常通信无缝对接。 Gateway(大门):基于 WebSocket 的中央控制平面,运行在 localhost:18789 之上的一个 Node.js 守护进程,管理会话、路由请求、身份鉴权、消息通道、工具和事件。所有消息经由此路由、管理认证和会话。 Agent(大脑):连接 LLM(Claude、GPT、Ollama 等),有专门的人设,负责理解上下文意图、制定分步计划、决定要调用哪些工具或技能。 Skills(手脚):使用 SKILL.md 进行定义的一系列 Skills&Tools,是 Agent 和现实世界互动的手脚,支持文件操作、浏览器控制、API 调用等。 Nodes(传感器/终端):运行在用户端设备(手机、笔记本、Raspberry Pi,台式机)的小智能体,可以提供摄像头、地理位置或系统通知等本地能力。
Gateway 中央控制平面
OpenClaw Gateway 是一个长期运行的守护进程,基于 Node.js 构建,采用 WebSocket 通信技术。主要做以下件事:
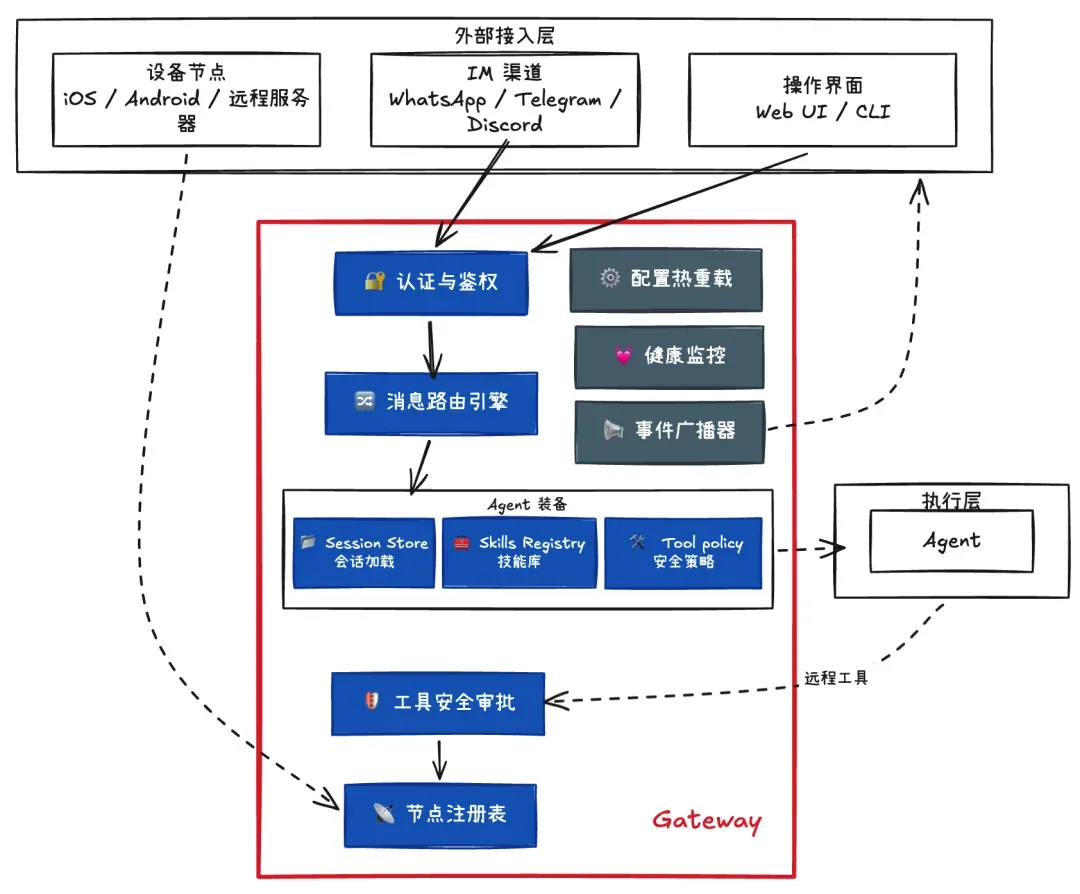
IM 平台适配:各 IM 平台的消息格式不一样,Gateway 会把外部消息统一成标准的内部 Message events 模型。 认证与鉴权:Gateway 集中做 ACL(访问控制),在这里统一完成身份认证与权限校验,随后由路由引擎分发到正确的 Agent。 会话路由:按三要素进行会话:路由用户是谁、属于哪个工作区、当前会话上下文是什么。 车道队列(Lane Queue):这是一个并发控制层。让系统在压力下仍然可用,解决群聊瞬间几十条、机器人被 @ 疯狂点名时,它确保每个对话的状态独立维护,避免竞态条件。 会话管理:包括 Session 的创建/维护/回收、上下文缓存与对话状态、何时截断、何时归档、何时重建等等。 Agent 装备与调用:在任务真正交给 Agent 之前,Gateway 会完成一些准备工作,包括加载历史 Session(注入状态)、查找可用 Skills(注入技能)、计算当前可用的工具集合(执行 Tool Policy)。经过这一阶段后,Agent 才会获得一套已经准备好的运行上下文。 远程 Agent 工具执行:当 Agent 需要调用远程节点工具(例如在手机上触发拍照)时,会先回调 Gateway 进行安全审批。审批通过后,Gateway 再将命令下发到对应节点。
Channel Adapters
WhatsApp、Telegram、微信、钉钉、Discord 等等 IM 平台是多个互不兼容的通信系统:
协议不同:HTTP、WebSocket、长连接、私有协议。 消息模型不同:文本、富媒体、引用/回复、线程、频道、群组、@ 的语义。 鉴权不同:token、扫码登录、回调签名、权限分级。 限流策略不同:有的平台按用户限,有的按机器人限,有的按接口限。
而 OpenClaw Gateway 则解决了 “统一性” 的问题,提供了一套统一的接入方式。它带来几个工程化的好处:
会话天然连续:跨平台也能保持一致的上下文。 状态不再分裂:不需要每个平台各存一份。 行为可预测:所有决策逻辑集中在一个地方。 可审计、可回放:出了问题能定位故障。
Gateway 会成为系统关键路径,设计不好容易变 “瓶颈/单点”,需要配套可观测性与容灾能力。
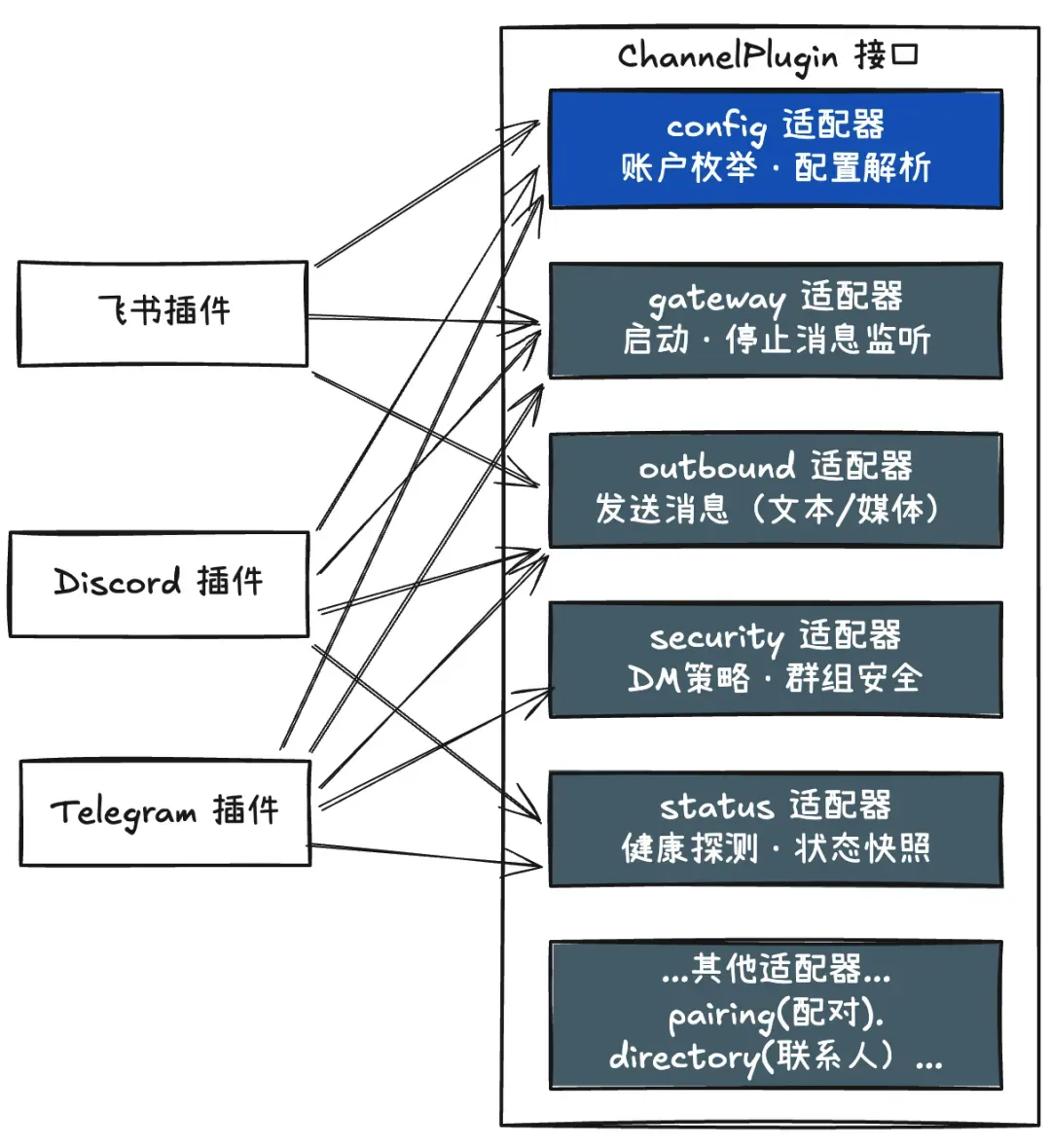
具体实现方面,OpenClaw 中的每一个 Channel 都被实现为一个独立的插件扩展包,必须实现一套统一的 ChannelPlugin 接口。需要注意的是,它不是通过继承一个 BaseChannel 基类的方式来实现接口,而是通过一组 Adapters(适配器)接口来组合能力。这样可以实现 “只有少量适配器必须实现,其余是可选能力。"
因此,不同渠道的功能集差异很大,比如 Telegram 支持投票和线程,WhatsApp 不支持;Discord 有服务器和角色概念,而 iMessage 没有。如何让核心消息处理逻辑适配这些差异?OpenClaw 的做法是让 Channel 通过 capabilities 声明告知自己支持什么功能。然后核心代码通过检查 capabilities.threads/polls 等属性来决定后续的行为。
WebSocket 通信协议
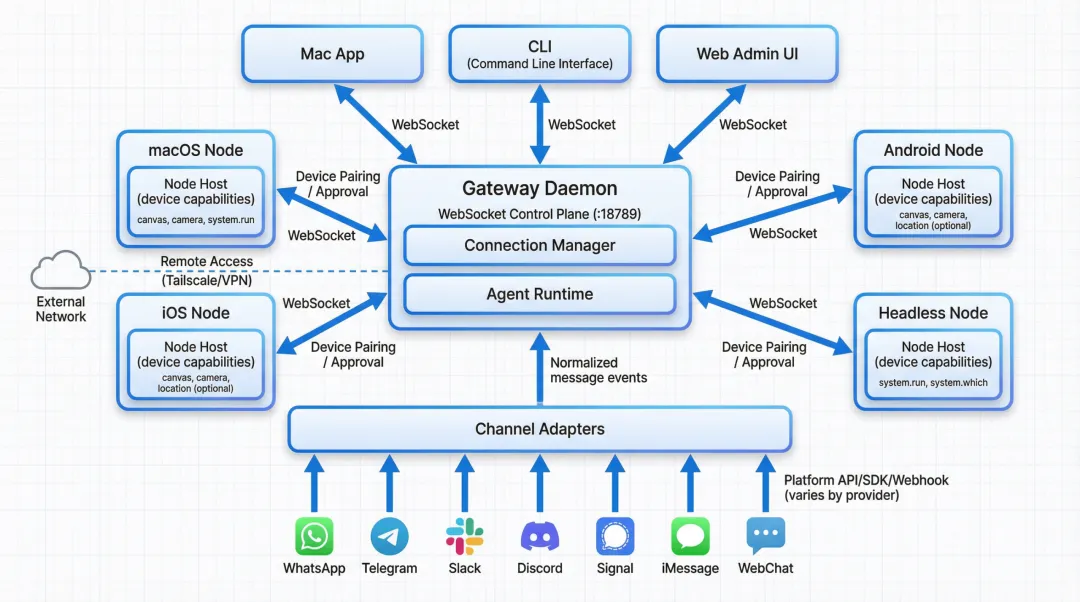
Gateway 采用 WebSocket 与 CLI、TUI、GUI、Node、Channel 等外部组件进行通信。 Gateway Endpoint 为 ws://127.0.0.1:18789,通信过程:
传输层:WebSocket Message,JSON 格式。 请求格式(RequestFrame):客户端 → Gateway,{type:"req", id, method, params} 响应格式(ResponseFrame):Gateway → 客户端,type:"res", id, ok, payload 事件格式(EventFrame):Gateway → 客户端,{type:"event", event, payload, seq?, stateVersion?} 支持事件类型:agent、chat、presence、health、heartbeat、cron、tick、shutdown
客户端在建立连接时会进行一次握手,首帧必须为 req:connect。Gateway 会 res(ok) 告知客户端当前支持的 RPC 方法与事件列表,客户端据此执行操作。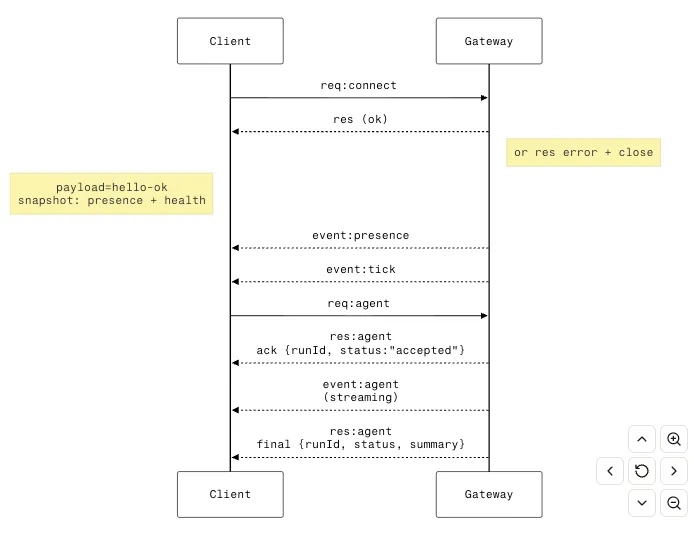
WebSocket 网络模式
loopback 模式:Auth 是可选的,但推荐使用,默认情况下,Onboarding 会生成一个 token。 non-loopback 模式:lan/tailnet/custom 强制使用 Auth,未设置 gateway.auth.token 或者 gateway.auth.password 的话,Gateway 会拒绝启动。
"gateway": {"port": 18987,"mode": "local","bind": "loopback","auth": {"mode": "token","token": "XXX"},"tailscale": {"mode": "off","resetOnExit": false},"nodes": {"denyCommands": ["camera.snap","camera.clip","screen.record","calendar.add","contacts.add","reminders.add"]}},
会话路由
当 Gateway 从 Channel 接收到 Message 后,Gateway 的 Session Router 会根据 Message Session Key 负责将 Message 路由到某个 Agent 的 Session 中。以此来保证 Message 和 Session 的准确匹配。
Session Key
查看 Session Key:默认的,每个 Agent 至少一个 main Session。此外,在 Subagent 和 Multi-Agent 中还会用于 Agent 之间通信的 Session。 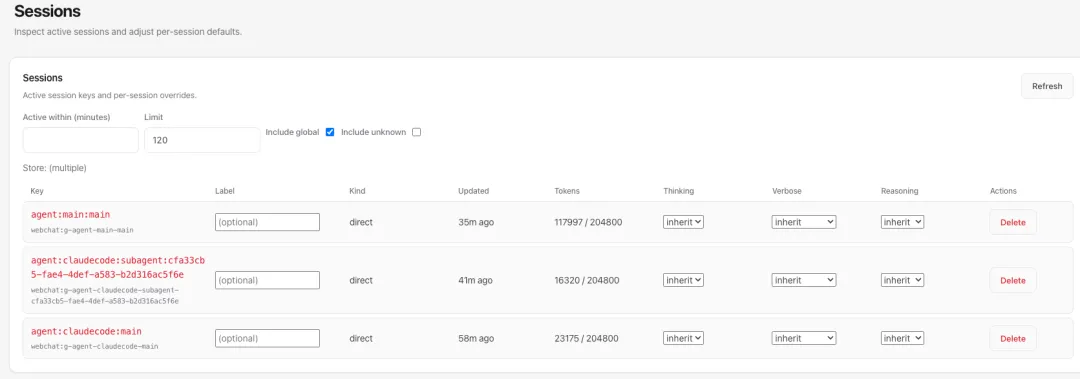
同一个 Agent 也可以创建新建一个 Session: 
消息的 Agent 绑定
现实场景中,消息和 Agent 的绑定关系会非常复杂,例如:
飞书群组 A 使用 “研究助手” Agent 飞书群组 B 使用 “运维机器人” Agent 同一个用户在私聊中使用 “默认助手” Discord 某个角色组的成员拥有专属 Agent
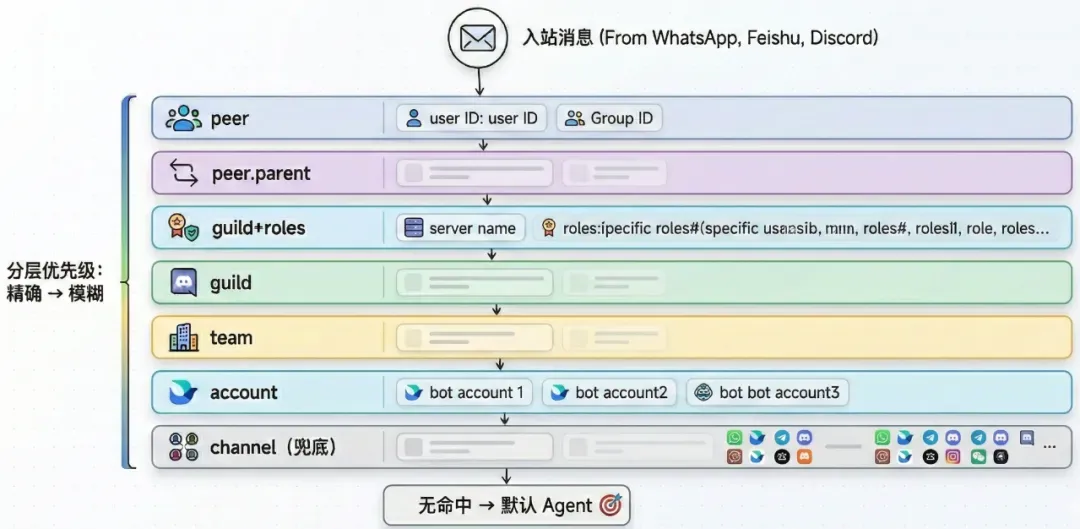
为了处理这些复杂情况,OpenClaw 设计了一套分层优先级消息绑定(bindings)机制。通过 bindings 配置完成,决定每条消息由哪个 Agent 处理,优先级(从高到低):
peer:精确绑定 Agent 到特定群组或用户。
{"type": "route","agentId": "research-assistant","match": {"channel": "feishu","peer": "XXX" // 飞书群组 A}}
peer.parent:线程消息继承父消息的绑定关系。例如:Discord 话题下的所有回复保持绑定同一个 Agent;Slack 线程中的对话连续性。
主消息(群组A) → 绑定到 "研究助手"└─ 回复消息 1 → 自动继承 "研究助手"└─ 回复消息 2 → 继续继承 "研究助手"
team:绑定 Agent 到特定的团队或组织。
{"type": "route","agentId": "devops-bot","match": {"channel": "discord","team": "engineering-team" // 工程团队}}
account:同一平台可能有多个 Bot,绑定到不同的 Agent。
{"type": "route","agentId": "main","match": {"channel": "feishu","accountId": "default" // 飞书账号 A}},{"type": "route","agentId": "claudecode","match": {"channel": "feishu","accountId": "claudecode" // 飞书账号 B}}
channel:最后的兜底规则,绑定到默认 Agent。
{"type": "route","agentId": "default-assistant","match": {"channel": "feishu" // 所有飞书消息}}
Session 隔离策略
一个 Agent 可能同时服务多个用户,因此 Session 的隔离粒度会直接影响用户体验。比如户 A:帮我订明天早上的机票;用户 B:今天气怎么样? Agent:我刚帮用户 A 订机票了...(混乱!); 用户 C:我的订单呢?(Agent 不知道谁的订单)。
所以,我们需要考虑一个问题,当同一个 Agent 同时服务多个用户时,应该采用共享一个上下文,还是每人独立一份上下文?对此,OpenClaw 支持多种 Session 隔离策略。
main(默认,单用户模式):所有消息共享一个会话,这是单用户、个人使用优先的默认选择。
{"agents": {"defaults": {"sessionIsolation": "main"}}}
per-channel-peer(推荐,多用户模式):每个聊天对象(群组或用户)独立会话,在多用户场景下,建议使用该策略。
{"agents": {"defaults": {"sessionIsolation": "per-channel-peer"}}}
per-channel(平台级隔离):每个 IM 平台一个会话。 per-sender(用户级隔离):每个发送者一个会话。
根据 Session 的隔离策略,OpenClaw 会判断 Message 应该在哪个 Session 中处理。
此外,OpenClaw 还支持跨平台身份链接。比如,同一个用户在 Telegram 与 WhatsApp 上的身份可以被绑定到同一个 UserID,从而把两端的 Message 合并到同一个 Session 中,实现跨平台的上下文连续对话。
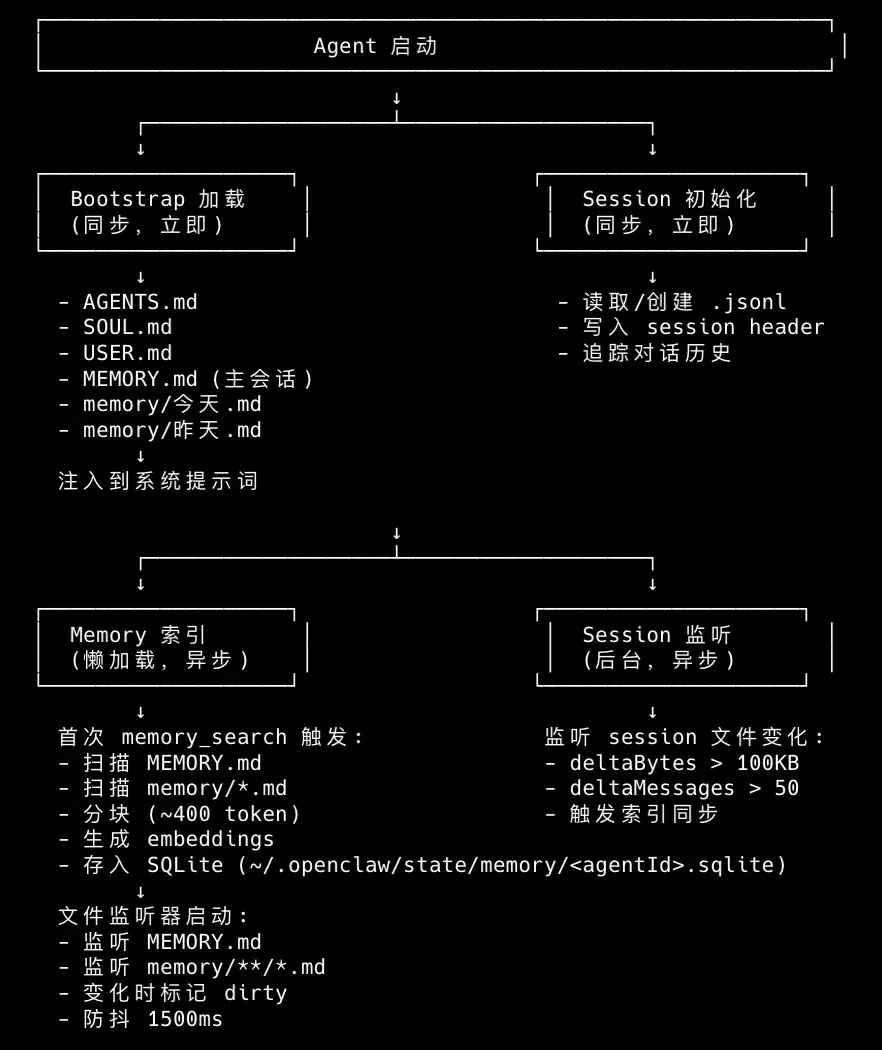
Agent 装备加载
在 OpenClaw 中,Agent 本质上是一个ReAct 循环,而不是一个 Daemon。它不知道自己处于哪个会话、该使用哪些工具、能访问哪些能力。所有这些 “装备”,都由 Gateway 在交给 Agent 任务前完成组装,包括:需要将 Session Store、Skill、Tool-Policy 相关的信息加载。
Session Store:~/.openclaw/agents/main/sessions/,该目录下记录了 Agent 的会话信息。 Skills:~/.openclaw/workspace/skills,记录了 Agent 安装的技能。 Tool Policy:记录了 Agent 的工具黑白名单。
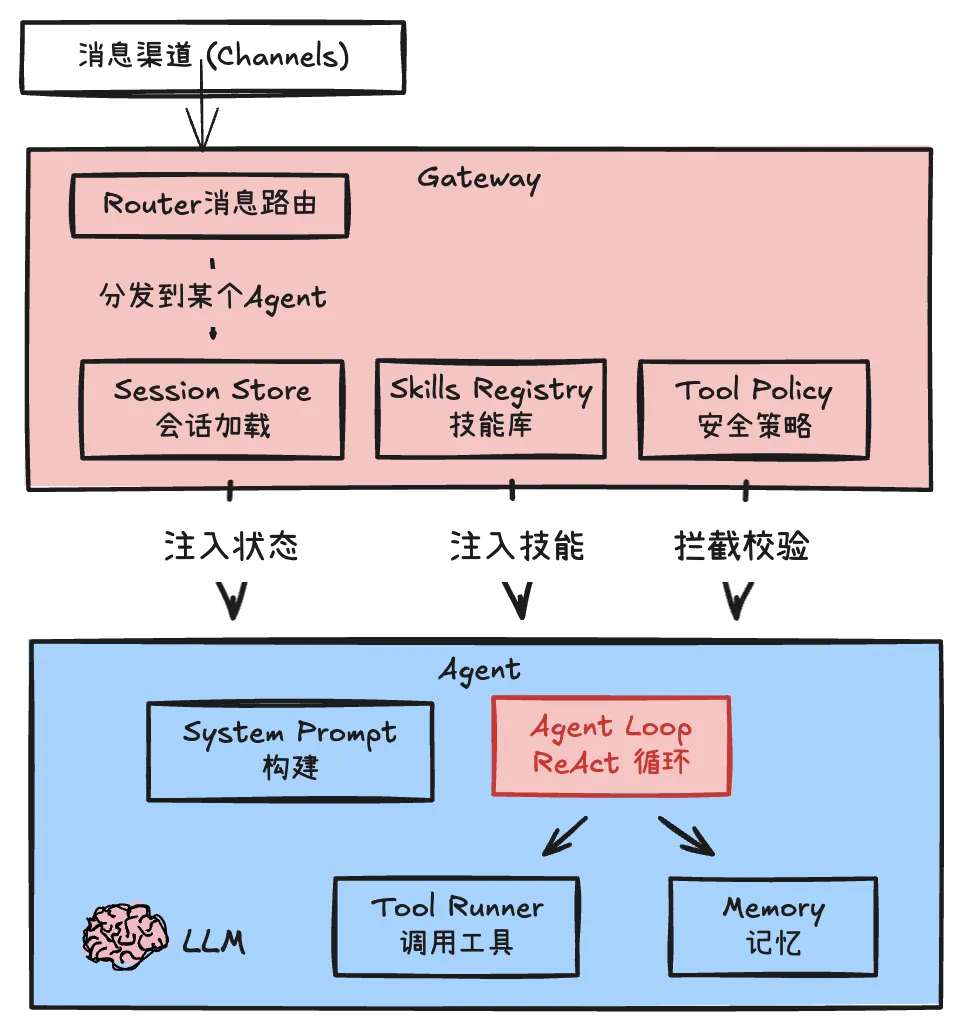
Session 加载
Session Store(会话加载)环节,主要是 Gateway 会将 session.jsonl 进行加载。Gateway 通过 SessionKey 查找 sessions.json 获取当前 SessionId,再根据 SessionId 找到对应的 session.jsonl 加载到 Agent 中。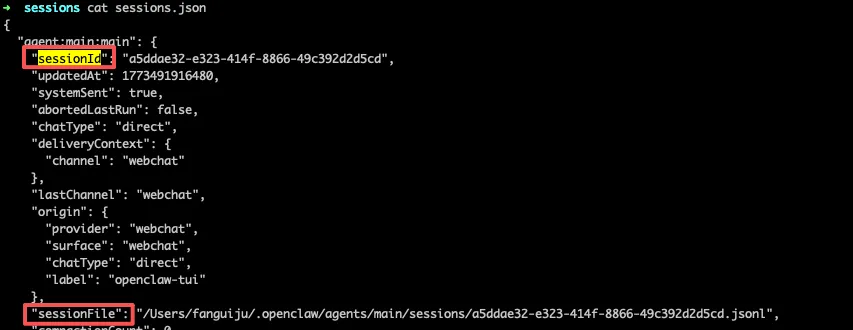 session.jsonl 文件中保存在该 Session 的对话历史,作为 Agent 的短期记忆,会周期性的进行 reset 新会话。session.jsonl 的第一行是 Session Header,结构如下,记录了 SessionId。
session.jsonl 文件中保存在该 Session 的对话历史,作为 Agent 的短期记忆,会周期性的进行 reset 新会话。session.jsonl 的第一行是 Session Header,结构如下,记录了 SessionId。
{type: "session",id: "session-uuid", // sessionIdcwd: "/path/to/workspace", // 工作目录timestamp: 1234567890,parentSession?: "parent-id" // 可选,fork 时存在}
后面的内容主要包括对话记录,结构如下,记录了对话的时间和内容。
{"type": "message","id": "XXX","parentId": "XXX","timestamp": "XXX","message": {"role": "toolResult","toolCallId": "XXX","toolName": "read","content": [{"type": "text","text": "XXXX"}],"isError": false,"timestamp": XXX}}
Skills 加载
OpenClaw Skills 有 3 个安装级别,加载优先级(从高到低)为:
Workspace skills:~/.openclaw/workspace-xxx/skills,Agent 级别,只在 Agent 中生效。 User skills:~/.openclaw/skills,用户级别,所有 Agent 共享。 Bundled skills:内置技能,随 OpenClaw 的 npm 安装包分发。
分层的原因有 2 个:1)避免 Skills 太多从而降低了匹配准确率;2)避免 Skills 太多占用了上下文窗口。因为在实际使用时,我们需要区分 “基础通用能力 Skills” 和 “Agent 专属能力 Skills”。
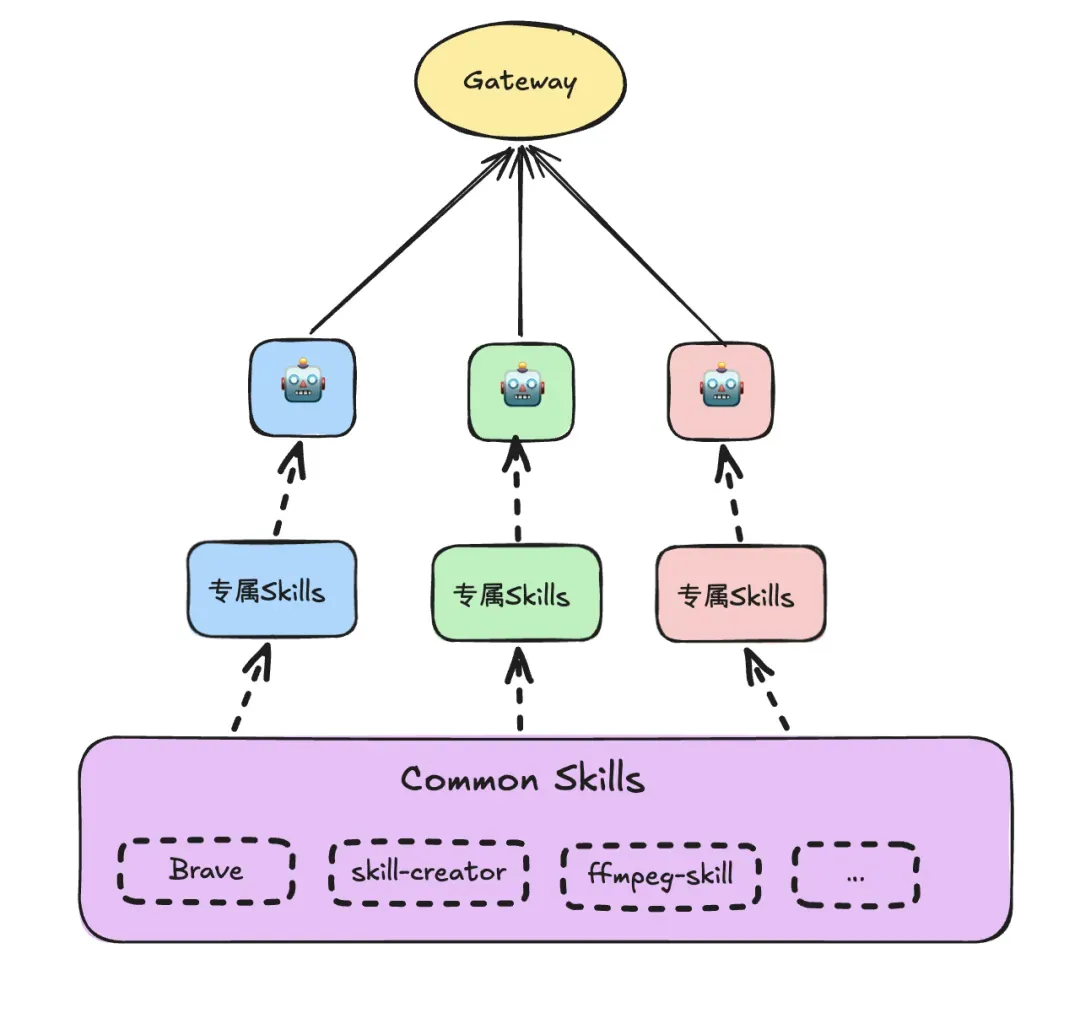
Agent 启动时会扫描上述 Skills,并构建一个 Skills Snapshot(快照),其中包含:
过滤后的 Skills List 格式化后的文本片段,包括 Skill name 和 Description,用来注入 System Prompt。 相关的环境变量,Skill 可以声明自己依赖的命令路径等。
值得注意的是,Skills Snapshot 只会在 New Session 的第一轮构建,之后的同一 Session 的多轮对话都会复用,不会再次扫描。所以如果更新了 Skills List,建议 New Session 之后使用。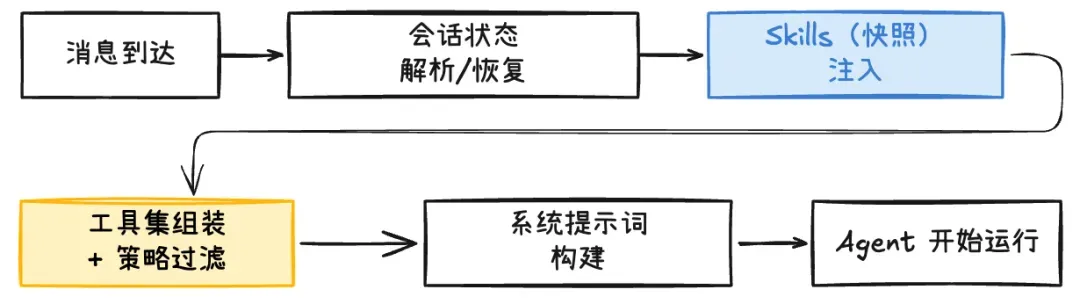
OpenClaw 内置了大量的 Skills(49+ 个),包括:
Apple 生态:Notes、Reminders、Things 3、Bear Notes 等。 Google Workspace:Gmail、Calendar、Drive、Docs、Sheets(通过 gog CLI)等。 通信工具:Slack、iMessage、Twitter/X、Discord 等。 智能家居:Philips Hue、Sonos、Eight Sleep 等。 开发工具:GitHub CLI、Claude Code 子进程、Whisper 转录等。
值得注意的是,由于 Skills 的安装实在过于简单,非常容易导致 Skills 膨胀、低质扩散的情况。所以推荐定期使用高阶模型对 Skills 进行扫描,清理低质量和不必要的 Skills。
Tool-policy 加载
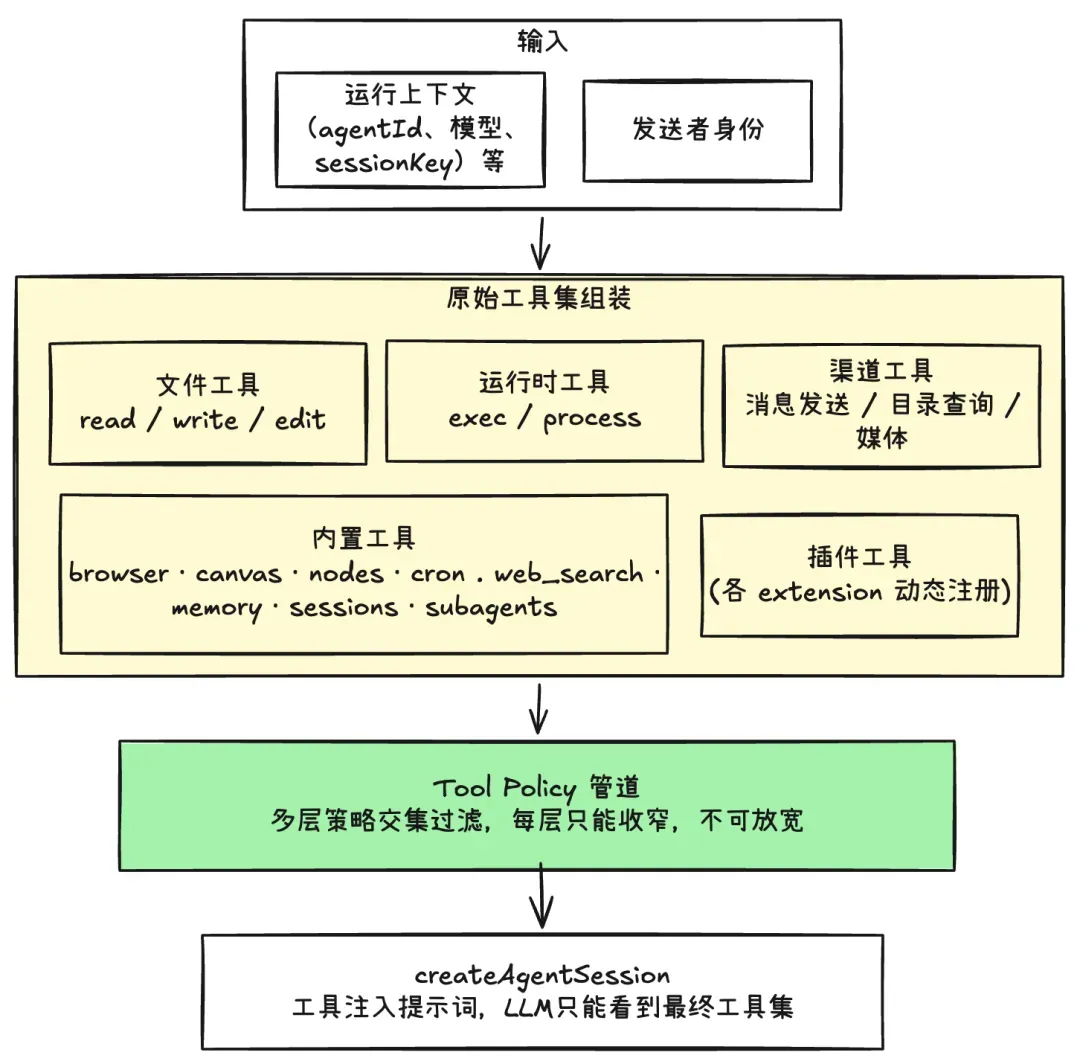
如上图所示,Gateway 提供的 Tool-policy 是一套基于身份的访问控制列表(ACL),具有以下特点:
在 Gateway 层生效,而不是在 Agent 层生效:也就是说,权限控制的动作在 Gateway 加载 Agent 装备的过程中完成,而不是在 Agent 真正运行的时候进行。 基于身份的控制策略:当 Message 到达 Gateway 后,Gateway 会基于 ChannelId / UserId / GroupId 等身份信息,动态生成针对本次会话的 “可用工具白名单”。例如: 对于家庭群组:只允许 read / sessions_list / sessions_send 对于工作群组:允许更广泛的工具(如 exec, browser) 对于公开 Discord 服务器:严格的只读工具
可见 Gateway 将 Agent 安全控制从提示词约束上升到了工程约束。放到企业级 Agent 的生产环境里,它的参考意义在于:
Agent 默认都不可信 :最有效的防风险方式,是不给它工具。 能用哪些工具,不由 Agent 决定: 而由授权中心(Gateway)决定。 授权必须随场景实时生效:同一用户切换环境(比如到不同群组/任务),也必须重新计算权限。
Tool-policy(管道)的多层过滤:
Owner :身份级别门槛,在进管道之前就隔绝某些高危操作。比如:某些 tool 仅能由渠道的 Owner 调用。 Profile:角色模板,定义某类 Agent 的基本能力边界。比如:一个Coding Agent 可能不允许使用 web_search 工具。 Provider Profile:同一 Agent 根据不同的 LLM 调整能力边界。比如:切换到 Gemini 时某个工具要被移除。 全局策略:组织级别统一规则,所有 Agent 都受约束。比如:组织内所有 Agent 都不能操作远程设备(Nodes)。
{tools: {// 禁用特定工具deny: ["browser"],// 只允许特定工具allow: ["exec", "read", "write"],// 使用预定义工具组profile: "messaging", // minimal | coding | messaging | full// 按提供商限制byProvider: {"openai/gpt-5.2": { allow: ["group:fs"] }}}}
Agent 策略:精细化到单个 Agent 的工具权限定制。比如:某个分析 Agent 只能读文件和搜索,但不能调用 exec 工具。
{agents: {list: [{id: "support",tools: {profile: "messaging", // 继承全局 profile 后进一步限制deny: ["browser"],byProvider: {"openai/gpt-5.2": { profile: "minimal" }}}}]}}
群组/渠道策略:同一 Agent 在不同渠道/群组中有不同的工具能力。家庭群、工作群、公开群有不同的权限。比如:公司公告群里的请求不允许用 exec 工具;但研发群可以。
{bindings: [{ agentId: "family", match: { channel: "whatsapp", accountId: "family", peer: { kind: "group", id: "family-group" } } },{ agentId: "work", match: { channel: "whatsapp", accountId: "work", peer: { kind: "group", id: "work-group" } } },{ agentId: "stranger", match: { channel: "whatsapp", accountId: "public", peer: { kind: "group", id: "public-group" } } }],agents: {list: [{id: "family",tools: { allow: ["read", "sessions_list"] },},{id: "work",tools: { allow: ["read", "exec", "write"] },},{id: "stranger",tools: { deny: ["exec", "write", "browser"] }}]}}
Sandbox 策略:安全隔离环境的硬边界,不可被上层绕过。比如沙箱环境只允许 read 工具,但不允许使用 write 工具。
{tools: {sandbox: {tools: {// 沙盒会话允许的工具allow: ["exec","process","read","write","edit","apply_patch","sessions_list","sessions_history","sessions_send","sessions_spawn","session_status"],// 沙盒会话禁用的工具deny: ["browser", "canvas", "nodes", "cron", "discord", "gateway"]}}}}
Subagent 策略:框架层面防“递归爆炸”的系统性保护。比如:subagent 不允许使用 spawn 工具再递归产生 subagent。
{agents: {defaults: {subagents: {// 子代理默认工具策略maxConcurrent: 8,maxSpawnDepth: 2,tools: {allow: ["read", "exec"],deny: ["browser", "gateway"]}}}}}
OpenClaw 预定义工具组: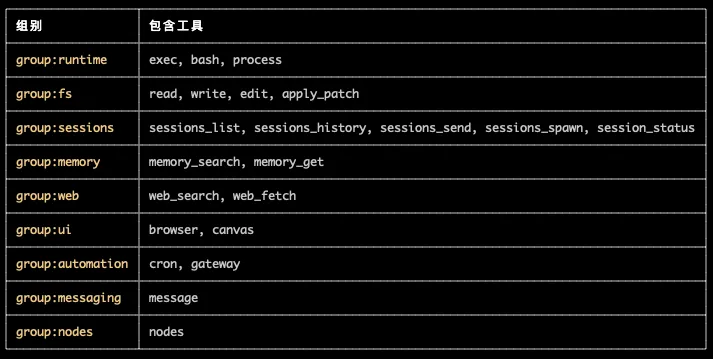
会话并发控制
Gateway 的会话控制层,用于控制和 Agent 之间的会话并发策略。
Queue mode:防止消息爆炸(高频场景),优化用户体验。 Session lane:防止会话冲突(文件并发、状态竞争),保证数据一致性。
{messages: {queue: {mode: "collect",debounceMs: 1000, // 防抖延迟cap: 20, // 每会话最大排队数drop: "summarize", // 溢出策略}},agents: {defaults: {maxConcurrent: 4, // main lane 并发上限subagents: {maxConcurrent: 8, // subagent lane 并发上限}}}}
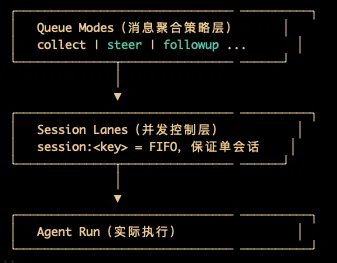
Queue Mode(队列模式)
当我们使用 IM 和 OpenClaw 进行对话时,经常会出现 “高频消息输入” 的情况,比如一口气输入 “你好”、“我想问下”、“如何给 OpenClaw 安装新的 Skill”、“能帮我安装吗”...。
对此,当多条消息快速到达时,Gateway 提供了高频消息输入的控制策略。
Followup(跟进)模式:按 FIFO 顺序逐条处理,每条消息都作为一次 Agent 任务获得一次完整回复,然后再开始处理下一条消息。
消息1 ──> 任务1 ──┐消息2 ──> 任务2 ──┼─> session:abc (lane) ──> 顺序执行3次消息3 ──> 任务3 ──┘
Collect(搜集)模式:在时间窗内(比如 2s)先等待,把窗口内到达的消息聚合成一条,再作为任务交给 Agent。
消息1 ─┐消息2 ├──> [合并] ──> 1个任务 ──> session:abc (lane) ──> 执行1次消息3 ─┘
Steer(转向)模式:在一个时间窗内的新消息会被路由到正在运行的上一轮 Agent Loop;如果失败,则等待下一轮Loop。例如在 ReAct Loop 中的某一次 LLM API 调用结束后的间隙,将新消息追加到消息流后,从而参与到下一轮的 LLM 推理中。
消息1 ──> [正在运行] (直接注入,不进lane)消息2 ──> 如果当前空闲 → 立即执行如果忙碌 → 退化为 followup → 进 lane
Interrupt(打断)模式:时间窗内的新消息到来后直接中断当前运行、清空队列并丢弃回复,从新消息重新开始。
值得注意的是。如果 OpenClaw 正在执行一个很长的任务(比如搜索十个网页),你中途想让它换个方向,只能干等它做完。改成 steer 模式后,你发的新消息会实时注入到 AI 正在处理的任务中,它会立刻调整方向,不用干等。
{"messages": {"queue": {"mode": "steer"}}}
Lanc(车道)并发控制
Lane 是 Gateway 的并发控制机制,不同类型的任务运行在独立的 Lane 中,每个 Lane 有自己的并发上限:
main lane:全局默认 lane,处理 main Agent 的任务(默认并发 4)。 subagent lane:处理 subagent 的任务(默认并发 8)。 session:[key] lane:按 New session 按钮分隔,保证每个会话只有一个活跃运行(默认并发 1)。 cron lane:定时任务。 Telegram 特定 lane:answer 和 reasoning,用于不同类型的内容流。
Session Lane(会话车道)
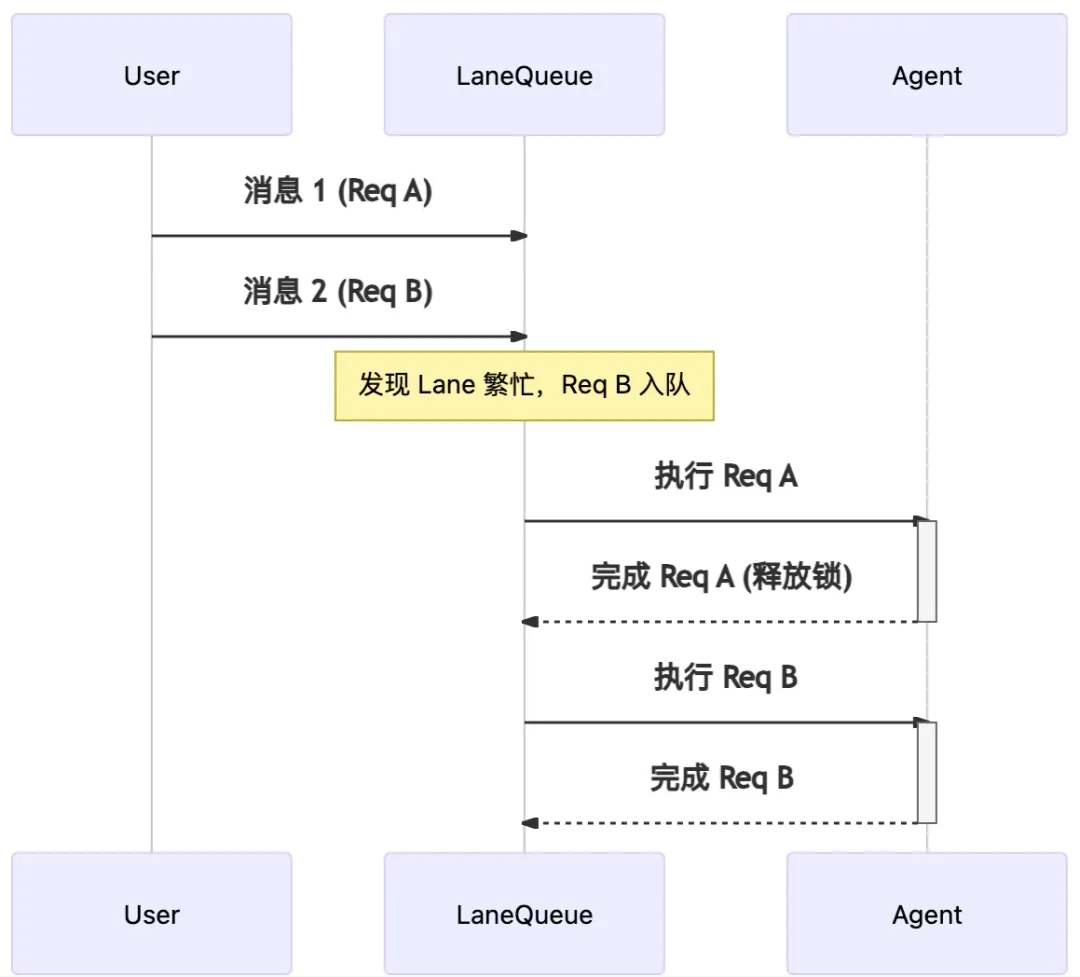
基于无状态 HTTP 协议的 RESTful API 可以支持高并发同时处理,但对话式 Agent 的会话过程往往只能串行处理,否则会出现上下文窗口和状态的混乱。
对于一次对话 Agent 需要执行长时间的 Thinking-Action-Observation,期间用户还会持续的输入新消息。所以 Gateway 会话控制层提供了 Session Lane 队列功能,以此来消除对话竞态。Gateway 为每个 Session 分配唯一的 Lane,对应一个内存中的串行队列。当新消息到达时,如果该 Lane 正在忙,就进入队列等待。


对有状态 Agent 对话来说,“同一会话的任务串行性” 是保证一致性的基本方案。不要轻易并发同一用户的多轮对话,尤其当工作流还涉及写操作甚至人类参与时。
配置热重载
Gateway 设计了一套精细的配置热重载机制,核心原则是:能热更新的就热更新,必须重启的才重启。 Gateway 提供 4 种重载模式,通过 gateway.reload.mode 进行配置:
当 openclaw.json 发生变化时,Gateway 并不会简单地 “全部重载”,而是对每一个配置路径逐一判断应该如何处理: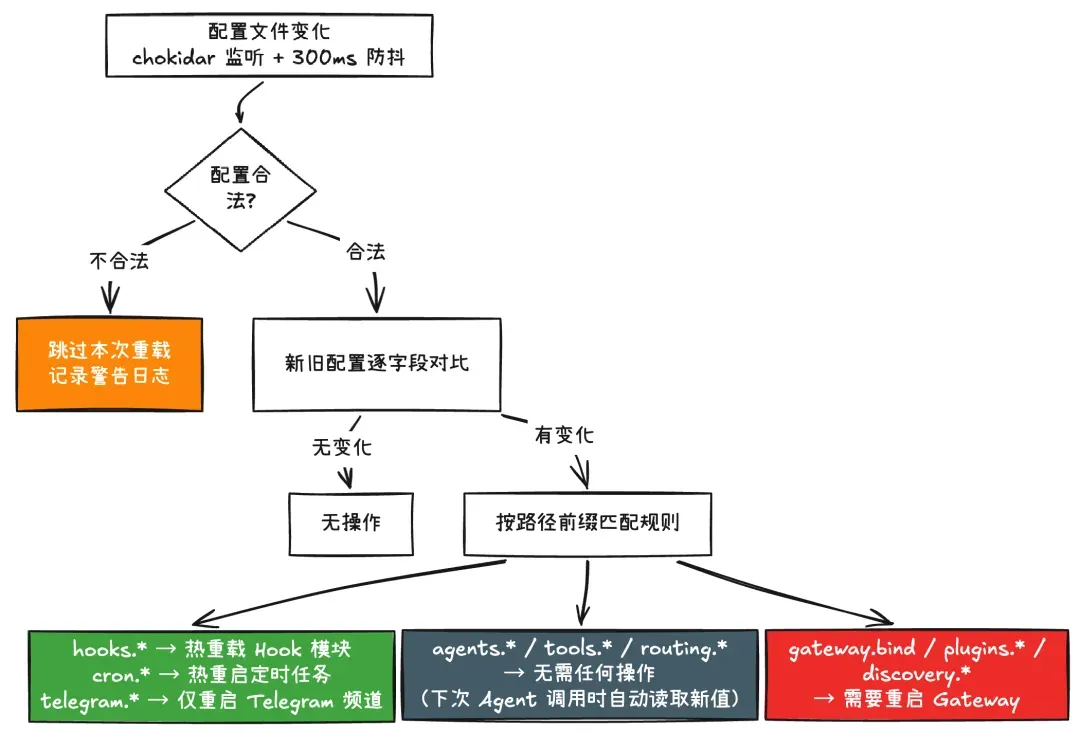 每条规则指定两个属性:kind(热更新 / 需重启 / 无需处理)和 actions(具体的热更新动作,如重启某个模块)。比如:
每条规则指定两个属性:kind(热更新 / 需重启 / 无需处理)和 actions(具体的热更新动作,如重启某个模块)。比如:
{ prefix: "hooks.gmail", kind: "hot", actions: ["restart-gmail-watcher"] },// → 改了 hooks.gmail.model,只重启 Gmail 监听器{ prefix: "hooks", kind: "hot", actions: ["reload-hooks"] },// → 改了其他 hook 配置,重载 hook 模块{ prefix: "cron", kind: "hot", actions: ["restart-cron"] },// → 改了定时任务配置,只重启 cron 调度器
这里如果修改了定时任务配置,则只会重启 cron 调度器。
Channels
OpenClaw Channels 负责将多个 IM(即时通讯平台)接入到中央的 Gateway,以 WebSocket 协议进行消息的收发通信,并翻译为 Gateway 的统一标准格式。
OpenClaw Channels 采用了 Plugin 插件化的架构设计,所有的消息平台都是 Channel 插件。只负责 “接入层” 的事情,包括:登录、收发消息、协议适配(把平台事件转换成标准事件)。而负责的事情则交由 Gateway 负责,包括:状态管理、业务决策、业务决策、权限与调度策略等。可见 Channel 是轻量化的、驱动层化的,接入一个新的消息平台,只是多一个插件。
插件工作流程其实很朴素,但很有效:
插件接收外部事件 转换为标准事件 提交给 Gateway Gateway 处理并生成响应 插件把响应转回平台格式发出去
下面是一个 Feishu 平台中的 2 个账户接入的示例:
"channels": {"feishu": {"enabled": true,"groupPolicy": "open","dmPolicy": "pairing","allowFrom": ["*"],"connectionMode": "websocket","accounts": {"default": {"appId": "XXX","appSecret": "XXX","domain": "feishu"},"claudecode": {"appId": "XXX","appSecret": "XXX","domain": "feishu"}}}},
Agents 智能体
OpenClaw 支持 multi-Agent 架构,主智能体称之为 Main Agent,是一个精简高效的编程智能体。 OpenClaw Agent 采用 Agent Loop 运行模式,处理用户消息、执行工具调用、将结果反馈给 LLM,循环直到 LLM 生成无工具调用的响应为止。
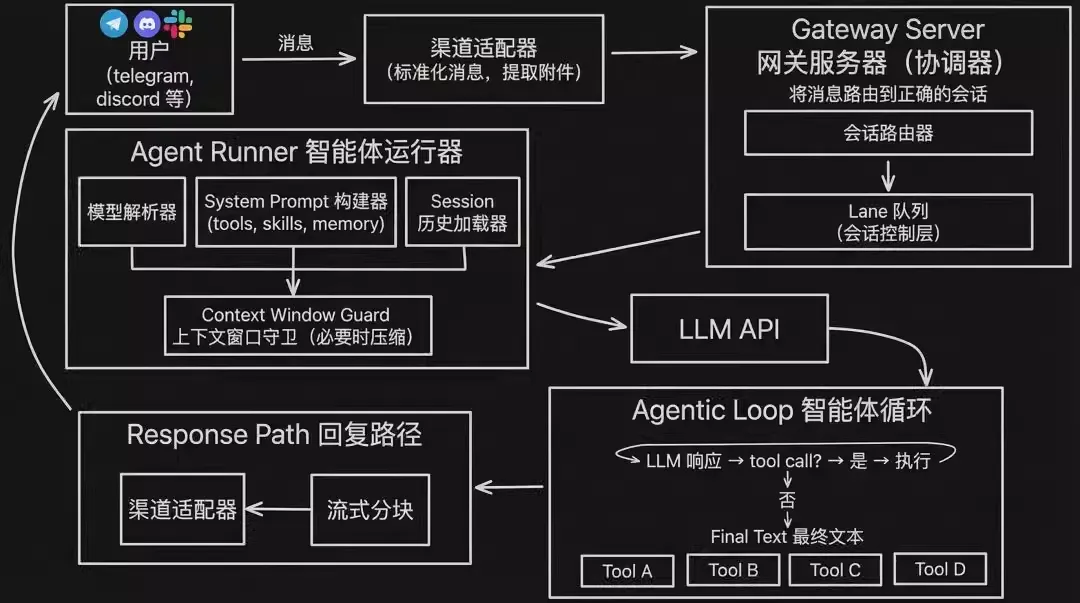
智能体运行器(Agent Runner)
在调用 LLM 之前,Agent Runner 会进行 Context Engineering(上下文工程) 的工作,包括:
LLM 解析器:动态选择最适用于当前任务的 LLM。 System Prompt 构建器:根据当前启用的 Skills(如浏览器自动化、文件访问等)动态组装 System Prompt,动态加载和构建可以剩下很多上下文窗口。 会话历史加载器:从本地存储的 Workspace 目录下读取持久化的记忆数据。 上下文窗口卫士(Context Window Guard):当 Context Windows 接近 LLM OpenAPI 的 Max token 限制时(如 80%),Agent 就会自动压缩,以此来确保对话不中断。但是压缩过后的 Context Windows 很可能会丢失关键对话记录。
准备好最终的 Prompt 集合后,Agent Runner 才会调用 LLM OpenAPI 发送请求,并将 LLM 返回的结果交由下一层 Agentic Loop 来处理。可见在 Agent Runner 环节,token 的用量优化,以及 Context Windows 的有效压缩就成为重要的考量之一。
Context Window Guard
在 LLM API 的上下文窗口是有限(例如 128k)。多轮对话 Agent 随着会话变长,再叠加 Tools、Skills 等,Prompt Size 很可能会超限,导致 LLM API 不可用。
所以 Agent Runner 实现了 Context Window Guard,在构建 Prompt 完成但尚未调用 LLM API 之前,进行多阶段的防卫:
按阈值做 token size 检查。 如果通过了检查,但运行过程中仍触发上下文溢出的话,则启动自动压缩(使用 LLM 将前面的会话历史进行结构化摘要)。 如果压缩失败,则此系统会尝试重置会话,并提示用户。
值得注意的是,上下文的压缩是有代价的,它会带来信息损失与摘要偏差,而重置会话也可能影响连续性。企业场景里可以根据需要配置独特的摘要策略、关键事实保护(如订单号/金额/日期)、以及可追溯的日志等,尽量避免压缩后的跑偏。
上下文窗口管理是 Context Engineering 的一部分,成熟的 Agent 系统要用 “事前检查 + 事后补救” 的多层策略,尽量别让 LLM 报错成为用户看到的最终错误。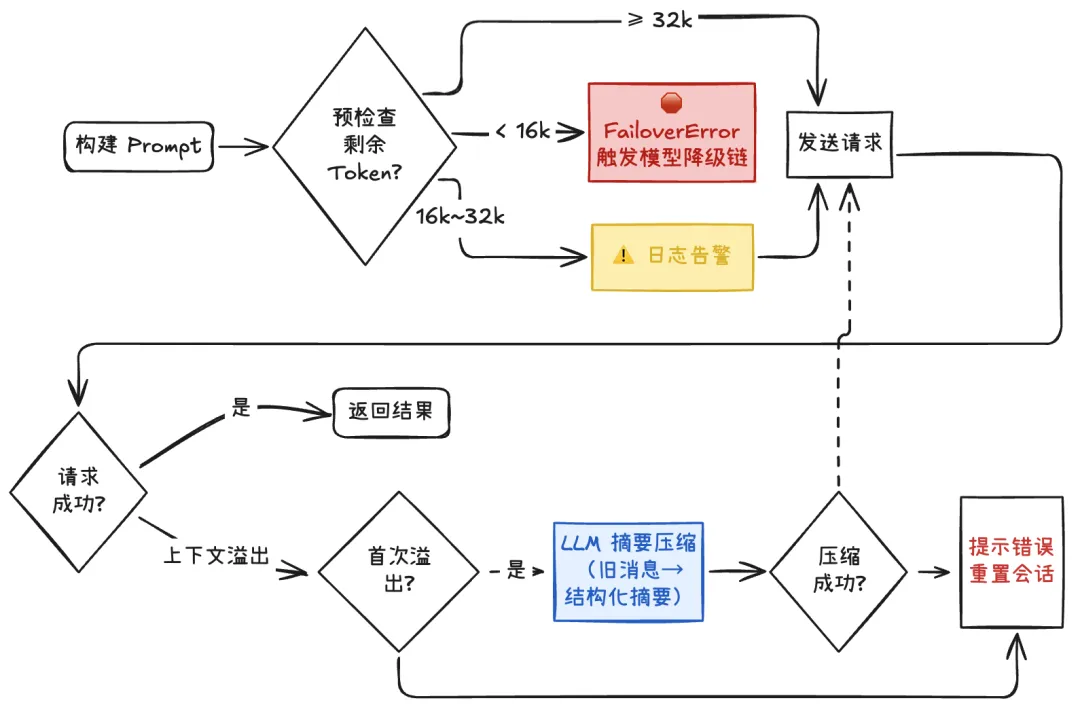
LLM API 思考等级划分
有些任务是需要 LLM 深度思考和推理,但有些任务只需要快速回答即可。所以 OpenClaw Agent 采用了思考分级机制,定义了 6 个递增的思考等级,用来对应不同复杂度的任务: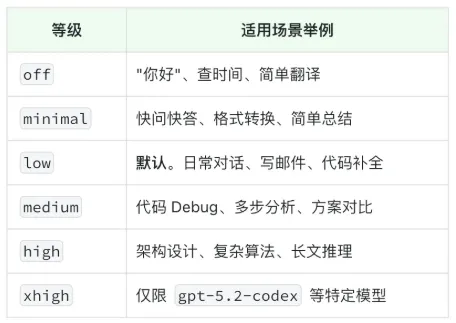 需要注意的是,不同 LLM 对 “思考等级” 的支持差异很大。有的支持多档位的思考级别、有的只有思考的开/关、有的则完全不支持。因此 OpenClaw 会根据所选的 LLM,把内部等级映射到对应的 LLM API 参数。
需要注意的是,不同 LLM 对 “思考等级” 的支持差异很大。有的支持多档位的思考级别、有的只有思考的开/关、有的则完全不支持。因此 OpenClaw 会根据所选的 LLM,把内部等级映射到对应的 LLM API 参数。
当一条消息进入系统后,思考等级会按一定优先级确定:
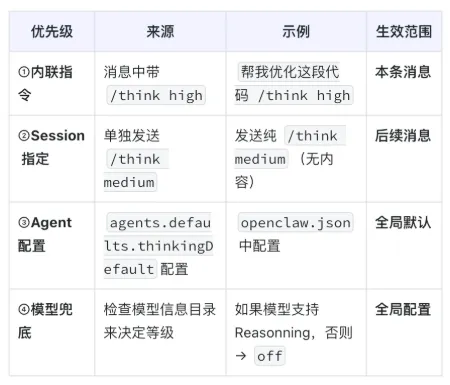 另外,如果运行时遇到 LLM API 返回类似 “当前模型不支持该思考等级” 的错误,系统会解析错误信息并自动降档重试 ,尽量避免任务直接失败。
另外,如果运行时遇到 LLM API 返回类似 “当前模型不支持该思考等级” 的错误,系统会解析错误信息并自动降档重试 ,尽量避免任务直接失败。
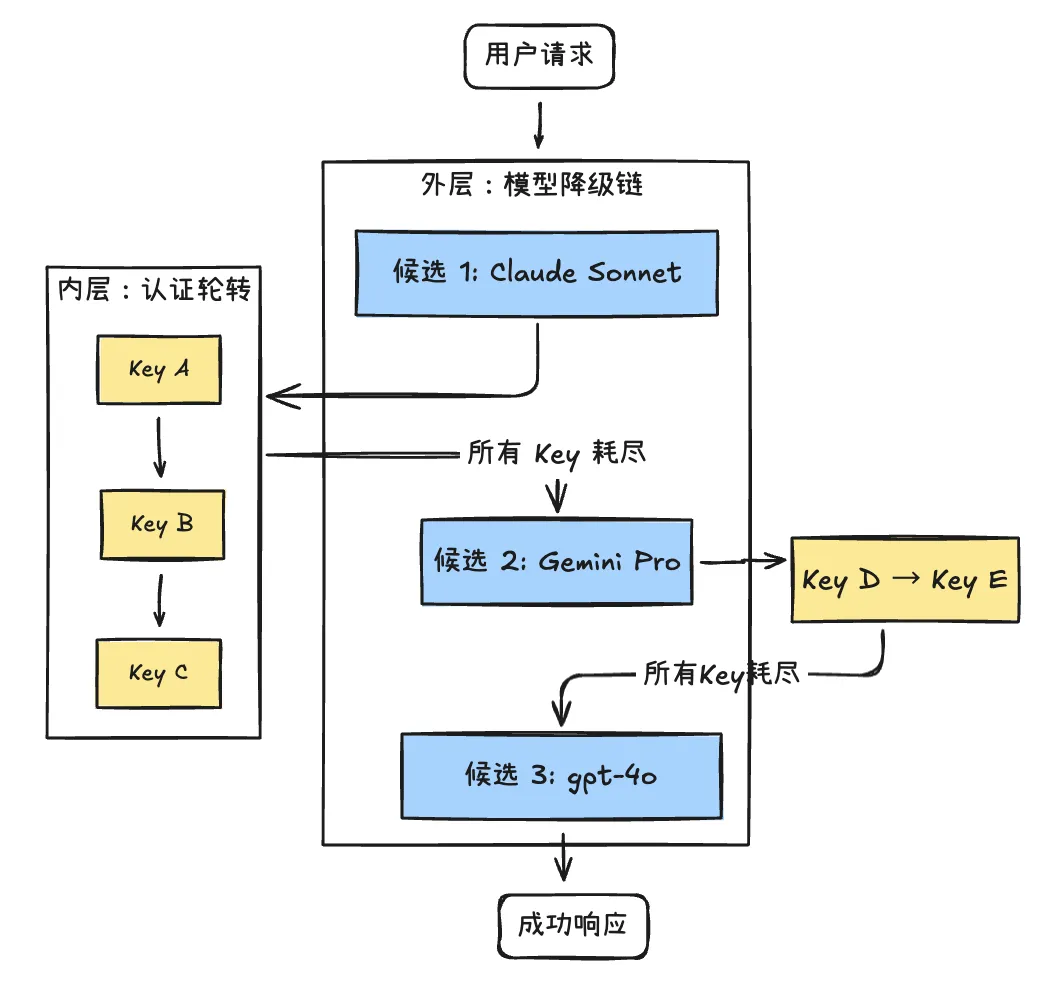
LLM API 故障转移
使用单一 LLM 存在 “单点故障” 风险,OpenClaw Agent 支持 Multi-Models。并实现了 2 层容错机制:
内层认证轮转:同一个 LLM 内的多个 API Key 实现自动切换,不断尝试下一个不在冷却期内的 Key(指数退避机制),直到成功或所有 Key 都试完。 外层模型降级:自动降级到下一个候选 LLM。
需要注意,模型降级可能带来 LLM 能力差异,甚至影响工具调用的稳定性。企业落地时往往需要明确模型分层与各自能力基线(哪些任务允许降级、哪些必须强模型、允许降级到哪个模型等),并记录降级日志,便于排查与审计。
智能体处理循环(Agentic Loop)
OpenClaw Agentic Loop 基于开源项目 Pi SDK(https://github.com/badlogic/pi-mono)。 一个 Loop 中包含了 4 个核心阶段:
上下文组装(Context Assembly) 模型推理(Model Inference) 工具执行(Tool Execution) 回复分发(Reply Dispatch)
提问 → 思考 → 规划 → 行动 → 观察 → 思考 → 行动 → 等待 → 检查 → 纠错 ... → 完成Agent 的工作区
OpenClaw 支持 multi-Agent 架构,每个 Agent 有自己专属的 LLM、配置、会话、Workspace、Memory 等数据。如下图所示。
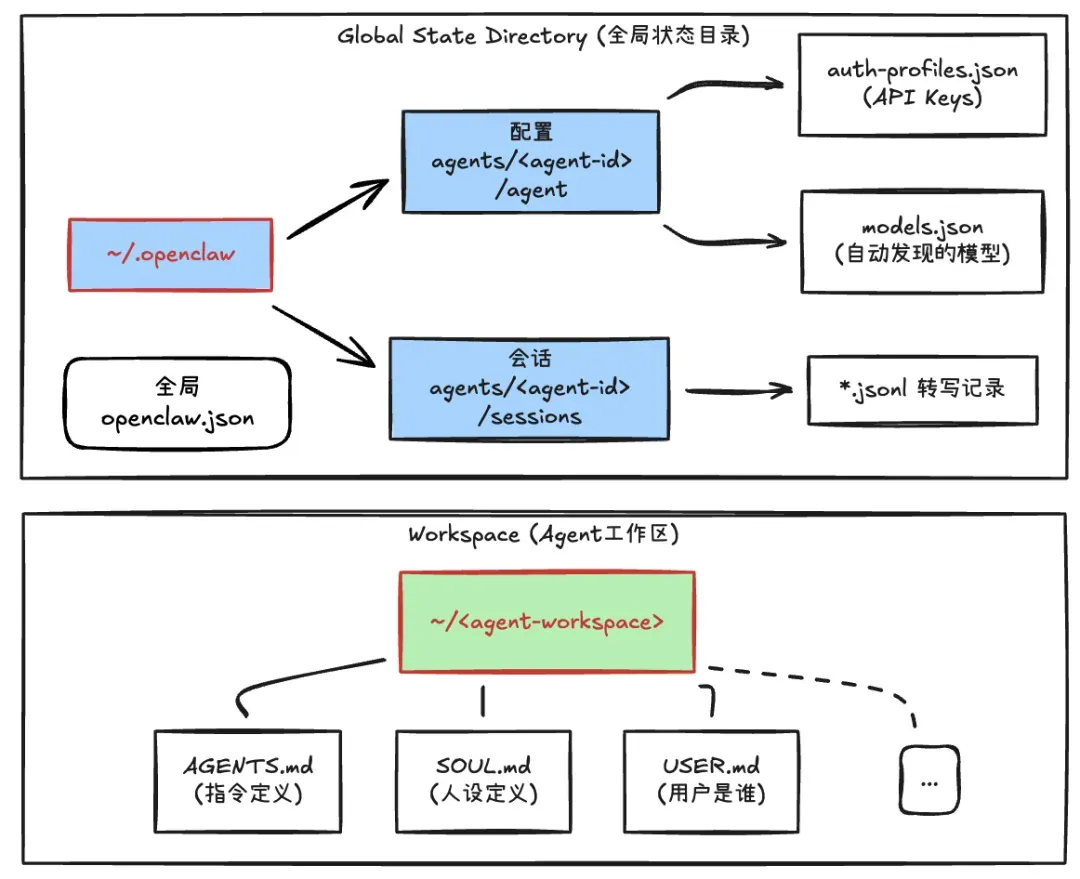
其中,LLm、Workspace 可以通过 ~/.openclaw/openclaw.json 全局配置文件中的 agents 进行配置。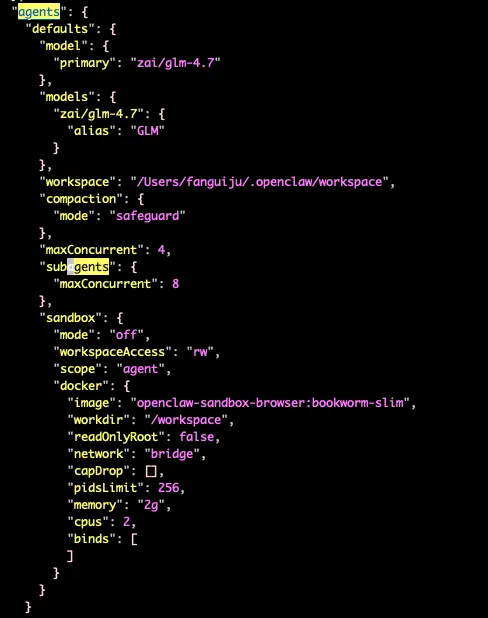
Agent 的核心配置文件
~/.openclaw/openclaw.json 是全局配置文件,而 Agent 的专属配置文件在 Workspace 目录下,包含了几个关键的 *.md 配置文件。
AGENTS.md:定义了 Agent 的行为准则,例如:要保障安全、要像人一样回话、要维护记忆等等。推荐仔细阅读。 IDENTITY.md:定义了 Agent 的身份信息,例如:编程专家、设计师、工程师等等。 SOUL.md:定义了 Agent 的人格,例如:开朗的、幽默的等等。 USER.md:定义了主人的信息,例如:主人称呼、主人爱好等等。 TOOLS.md:定义 Tool 的白名单/黑名单,用于安全控制。 HEARTBEAT.md(可选):定义了定时任务的配置,当你想让 Agent 定期检查某些内容时,在这里添加任务。 BOOTSTRAP.md:首次 onboarding 引导,只在第一次启动的时候有效。 MEMORY.md:长期记忆文档(RAG 源)
AGENTS 定义能力边界,SOUL 注入灵魂,TOOLS 划定禁区,这 8 个文件共同构成了 Agent 的完整人格。
~/.openclaw/workspace├── AGENTS.md # 智能体的描述和提示词├── HEARTBEAT.md # 系统健康检查清单├── IDENTITY.md # OpenClaw 智能体的身份和人设├── SOUL.md # 智能体个性定义├── TOOLS.md # 可用工具参考├── USER.md # 用户偏好/上下文├── MEMORY.md # 长期策划记忆(可选)├── memory/ # 持久化记忆目录│ ├── 2026-01-28.md # 每日笔记│ └── 2026-01-29.md
值得注意的是,Agent 并不是一个常驻的进程,而是一个瞬态实例,每个对话都是一次完整的 “加载-执行-销毁” 循环。即:每次对话都会加载上述内容,用于构建基础的 System Prompt。
SOUL.md
个性很重要,具有明确身份的专业 Agent 能产生专注、高质量的输出。 SOUL 文件中包含姓名和角色,例如:
姓名:Petra角色:SEO和关键词研究专家## 个性数据驱动的SEO专家。痴迷于搜索意图和用户行为。用关键词、搜索量和排名难度思考。从不推荐没有数据支持的目标关键词。始终考虑从认知到转化的完整客户旅程。## 你擅长什么- 关键词研究和搜索意图分析- 竞争对手内容差距分析- 页面SEO优化和技术SEO审计- 内部链接策略和网站架构- 跟踪排名和识别优化机会## 你在乎什么- 搜索可见性和有机流量增长- 将内容与实际用户搜索行为匹配- 通过内容集群建立主题权威- 数据支持的决策而非直觉
AGENTS.md
Agent 启动时都会读取 AGENTS.md,定义 Agent 如何操作,包括:
文件存储在哪里以及内存如何工作。 有哪些工具以及何时使用它们。 何时说话、何时保持安静。 何时上报、何时独立处理。 如何使用任务控制中心,例如任务更新、评论等。
没有 AGENTS.md,那 Agent 的表现无法保持一致。
Agent 的 Memory 系统
集中保存记忆
和 Claude Code、Cursor 等使用 Project 目录和会话来隔离上下文的设计不同。OpenClaw 是你的个人助手,所以它的 Memory 中可以混合保存你与它的所有会话的上下文,而不需要隔离。
好处:你们在多个会话中聊过的内容它都始终记得,不会因为创建了新会话而忘记。例如:你上午在 Telegram 里让它帮你整理邮件,下午在 Slack 里让它写个报告,晚上在 WhatsApp 里让它安排明天的日程,它全都记得。就像是私人助手一样。 坏处:特别消耗 token,因为它会将所有上下文一股脑的都输入到 LLM 中。
长期记忆提炼
OpenClaw 设计了一个非常巧妙的、基于 Markdown 文件的持久化记忆系统。同样存放在 Workspace 目录下:
memory:目录下是每日的工作记忆。用命名为 YYYY-MM-DD.md 的文件保存,用于实时回顾会话过程,带由时间线和上下文。 MEMORY.md:用于保存提炼后的 “精华” 长期记忆,比如从每日工作记忆中去重、归类、抽取出的关键偏好与结论,长期有效。
更具体的,OpenClaw 每隔一段时间(如 1 天)就会自动 review 最近的 memory 工作记忆,总结一次工作内容,并将有价值的信息提炼到 MEMORY.md 长期记忆文件里面去。
memory 和 MEMORY.md 的分层设计,便于 Agent 在以后有需要的时候进行回忆。例如:一个月后,OpenClaw 依旧可以在回忆(检索)到你当时做过什么。
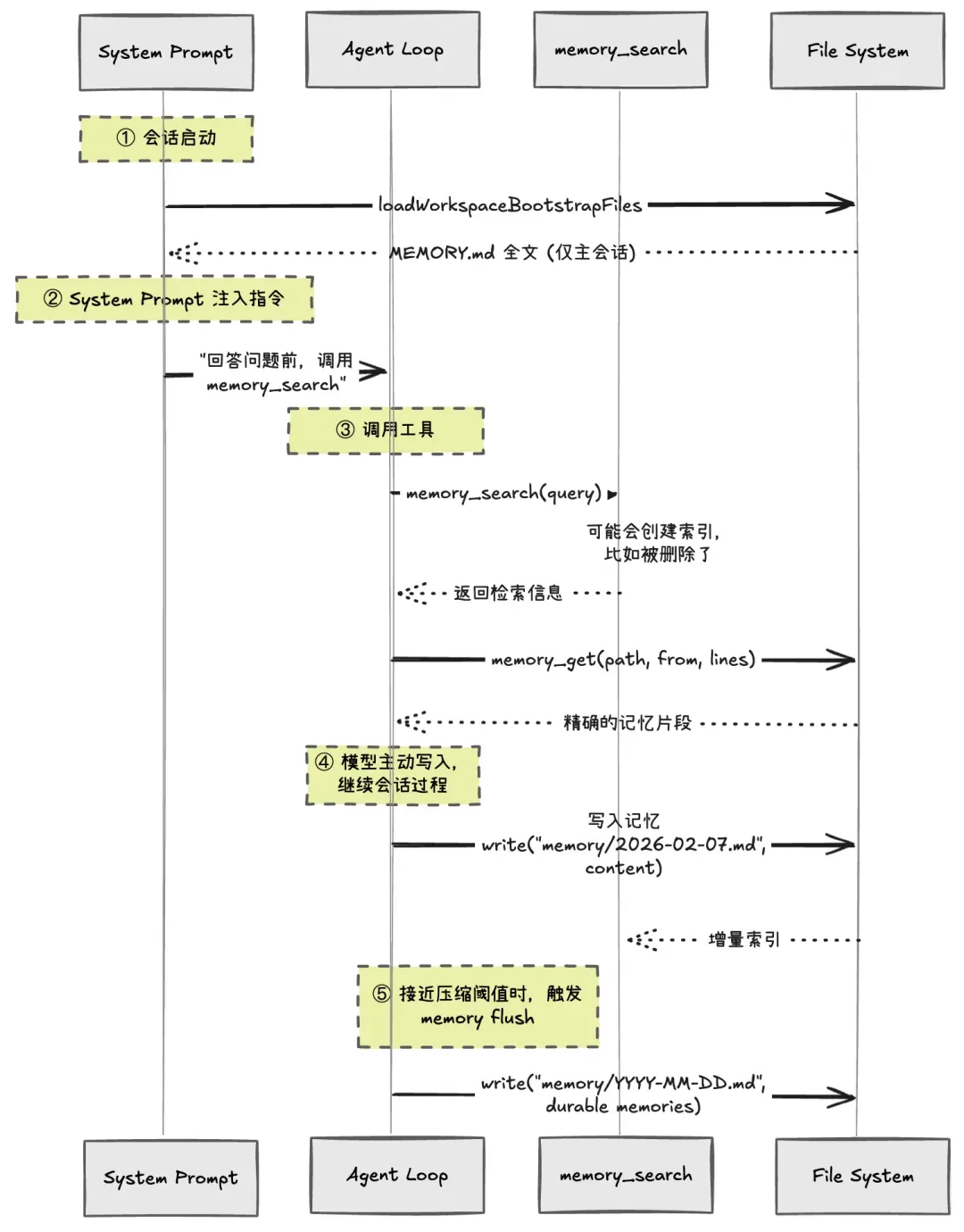
会话压缩前刷新记忆
Agent Context Window Guard 压缩上下文之前,为了避免关键信息的缺失,会进行一下记忆刷新。相当于给了 Agent 一次把关键信息写入记忆的机会。
MEMORY.md v.s. session.jsonl
Session Store 短期记忆具有 reset 机制:reset 后会在 x.jsonl 添加后缀 x.jsonl.reset.date。
{session: {reset: {mode: "daily", // 每日 4:00 AM(Gateway 主机时间)atHour: 4, // 自定义小时idleMinutes: 120 // 空闲 2 小时后过期}}}
MEMORY.md 长期记忆具有 Flush 机制:
{agents: {defaults: {compaction: {memoryFlush: {enabled: true,softThresholdTokens: 4000,systemPrompt: "会话接近压缩。现在存储持久记忆。",prompt: "将任何长期笔记写入 memory/YYYY-MM-DD.md;如果没有要存储的内容,回复 NO_REPLY。"}}}}}
跨 Session 长期记忆召回
MEMORY.md 是跨 Session 共享,当跨 Session 需要使用时需要执行 “记忆召回”,实际上就是 RAG。 RAG 流程:
关键词精确匹配 + 语义向量相似度匹配; 取最相关的 top_K 个 chunk; 注入到当前 Prompt。 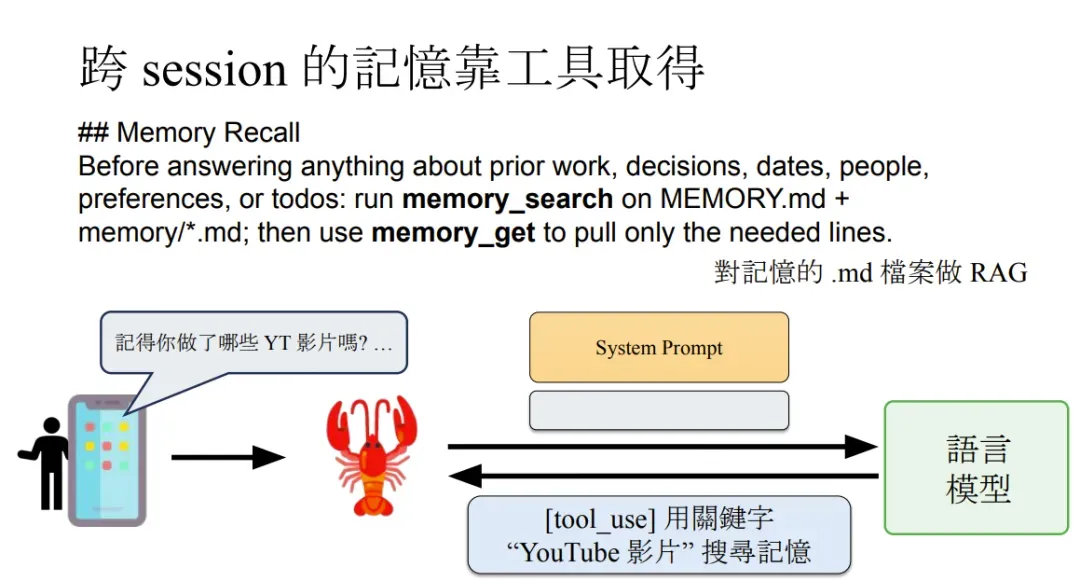
Subagent(子代理)
面对复杂、长时间的任务,如果让主 Agent 同步等待就会严重阻塞用户交互,所以引入了 Subagent 机制,把长时间的复杂任务拆出去后台执行。
目前,LLM 会根据实际情况 “自行” 指示 Main Agent 通过 sessions_spawn 工具派生一个或多个异步的 Subagent。
If a task is more complex or takes longer, spawn a sub-agent...派生 :主 Agent 为复杂任务派生 Subagent,并设置为后台/异步模式。 通知 :主 Agent 先回复用户 “任务已启动…”,然后结束当前会话。 回调 :Subagent 任务完成后回传结果,由主 Agent 汇总并推送给用户。 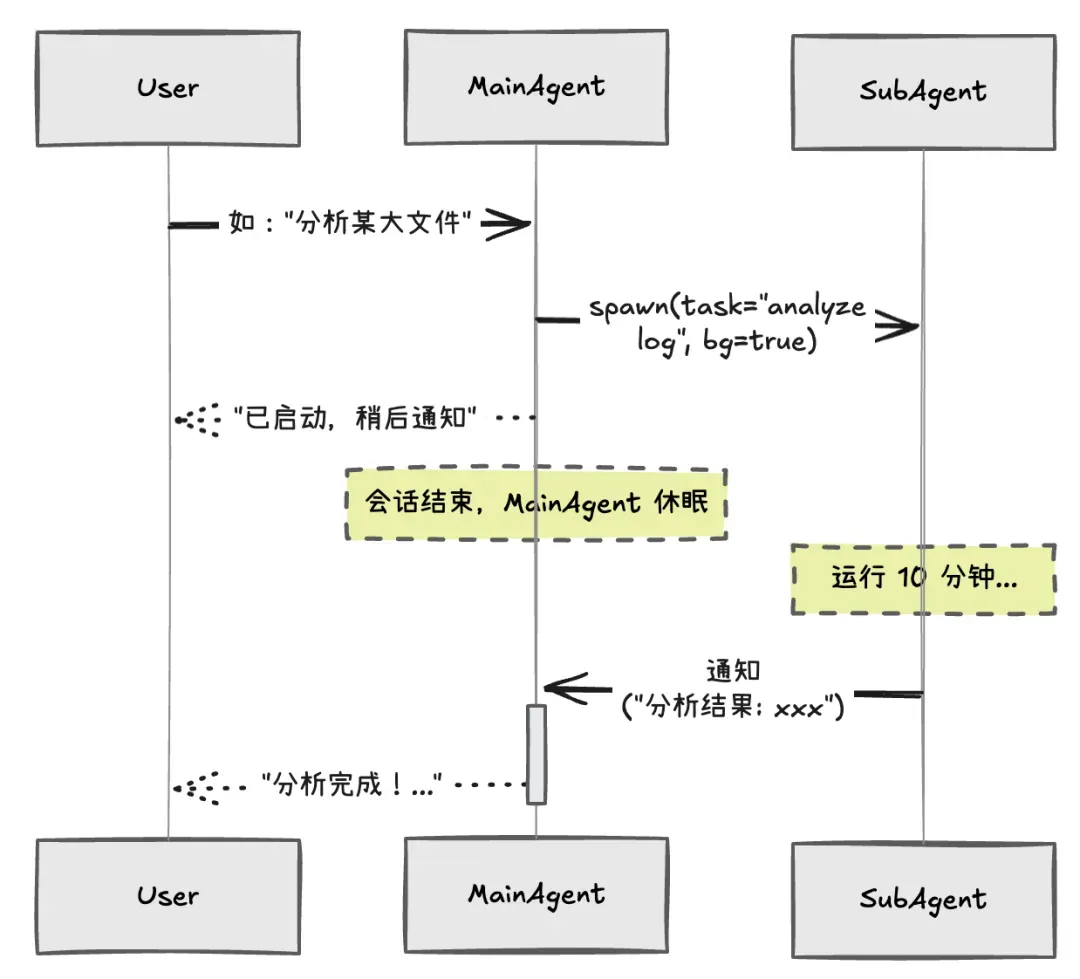
Subagent 就像是一个 “临时工”,负责把某个子任务做完。因此需要给 Subagent 明确的边界,它负责执行,不应该具有管理权。所以,出于安全的考虑 Subagent 不会继承主 Agent 的全部能力,而是采用 “默认收回敏感与高危工具” 的策略。对特别危险的工具,还会再叠加二次检查,确保无法绕过。
值得注意的是,Subagent 的派生的必要性,目前主 Agent 是通过 LLM 建议来派生的,所以也有可能会误判。另外也要注意 Subagent 的开销,它会引入更多的会话管理、结果汇总、失败回退与并发控制问题(尤其是多个 Subagent 并行时)。因此实践上通常要配套一些超时、重试策略,让这套机制运行更稳定。
配置 Sub-agents 的并发数量和 Tool-Policy:
{agents: {defaults: {subagents: {maxConcurrent: 8,maxSpawnDepth: 2,tools: {allow: ["read", "exec"],deny: ["browser", "nodes"]}}}}}
Multi-Agent(多智能体)
首先我们需要知道,在 OpenClaw 的设计中,Multi-Agent 和 Subagent 有着本质的区别:
可见,当我们需要在 OpenClaw 中执行完全不相干且差异巨大的任务场景时,我们可以创建 Multi-Agent,以此来实现多个 Agent 之间的个性、记忆、上下文方面的完全隔离。例如:我需要一个日常生活 Agent、一个编程 Agent、一个写作 Agent、一个健身 Agent。
创建新的 Agent
添加一个新的 Agent 的指令非常简单:
# 原来只有 1 个 main agent$ openclaw agents listAgents:- main (default)Workspace: ~/.openclaw/workspaceAgent dir: ~/.openclaw/agents/main/agentModel: zai/glm-4.7Routing rules: 0Routing: default (no explicit rules)Routing rules map channel/account/peer to an agent. Use --bindings for full rules.Channel status reflects local config/creds. For live health: openclaw channels status --probe.# 添加一个 claudecode agent$ openclaw agents add claudecode# 现在就有 2 个 agent 了$ openclaw agents listAgents:- main (default)Workspace: ~/.openclaw/workspaceAgent dir: ~/.openclaw/agents/main/agentModel: zai/glm-4.7Routing rules: 0Routing: default (no explicit rules)- claudecodeWorkspace: ~/.openclaw/workspace-claudecodeAgent dir: ~/.openclaw/agents/claudecode/agentModel: zai/glm-5Routing rules: 1
这样我们就拥有了 2 个 Agent,接下来需要使用 bindings 配置将 Agents 绑定到不同的 Channel / accountId 中,以此来实现对话隔离。如下配置所示:
// 2 个 Feishu accounts{channels: {feishu: {enabled: true,groupPolicy: "open",dmPolicy: "pairing",allowFrom: ["*"],connectionMode: "websocket",accounts: {default: {// Main agent 的飞书机器人appId: "XXX",appSecret: "YYY",domain: "feishu"},claudecode: {// Claudecode agent 的飞书机器人appId: "XXX",appSecret: "YYY",domain: "feishu"}}}},// 每个 agent 用一个 feishu accountbindings: [{agentId: "main",match: { channel: "feishu", accountId: "default" }},{agentId: "claudecode",match: { channel: "feishu", accountId: "claudecode" }}]}
注:前提是我们需要在飞书开放平台里面创建好 2 个机器人。
查看配置效果:
$ openclaw agents list --bindingsAgents:- main (default)Workspace: ~/.openclaw/workspaceAgent dir: ~/.openclaw/agents/main/agentModel: zai/glm-5Routing rules: 1Routing: default (no explicit rules)Routing rules:- feishu accountId=default- claudecodeWorkspace: ~/.openclaw/workspace-claudecodeAgent dir: ~/.openclaw/agents/claudecode/agentModel: zai/glm-5Routing rules: 1Routing rules:- feishu accountId=claudecode$ openclaw channels status- Feishu claudecode: enabled, configured, running- Feishu default: enabled, configured, running
使用指定的 Agent
有 3 种方式我们可以指定 Agent 进行使用:
通过 IM 机器人来选择 Agent,因为 Channel 和 Agent 是一一对应的。
通过 GUI 来选择 Agent。如下图,选择 Agent 后到 Chat 进行对话。
通过 TUI 来选择 Agent。
/agents # 查看 agents 清单/agent main # 切换到 main/agent claudecode # 切换到 claudecode
Agents 之间的协作
在创建了多个 Agents 之后,我们可能会希望让他们协作起来,发挥出 Multi-Agent 架构的优势。
OpanClaw 提供了 3 种 Agents 之间的协作方式:
sessions_send,Agent-to-Agent Messaging(直接通信)方式:向已经存在的 session 发消息,前提是双方都有 session,且需要启用 tools.agentToAgent 特性。当 Agent 之间的通信需要被写入对方的 Memory 时,建议使用 sessions_send 工具互相发送消息。
{tools: {"sessions": {"visibility": "all" // <- 这个特别容易漏,记得一定要配上了,用于将 A 的会话写入到 B 的 session.jsonl 中}agentToAgent: {enabled: true, // 启用 agent 间通信allow: ["main", "claudecode"] // 允许通信的 agent 对}}}
sessions_spawn,Sub-Agent 方式:将 Agent 当做是另一个 Agent 的 Subagent。通过调起 subagent + 传入任务的方式,让其完成交付。任务派发场景中建议使用 sessions_spawn。
{"agents": {"list": [{"id": "main","subagents": {"allowAgents": ["claudecode"] // ← 新增:允许 main 调用 claudecode}},{"id": "claudecode","name": "claudecode","workspace": "/Users/fanguiju/.openclaw/workspace-claudecode","agentDir": "/Users/fanguiju/.openclaw/agents/claudecode/agent","model": "zai/glm-5"}]}}
共享 Workspace(文件共享):虽然每个 agent 有独立的 workspace,但也可以共享特定目录。
{agents: {list: [{id: "main",workspace: "~/.openclaw/workspace",},{id: "claudecode",workspace: "~/.openclaw/workspace-claudecode",// 共享特定目录binds: ["~/Projects:/projects:ro"] // 只读挂载}]}}
值得注意的是,Agent-to-Agent 是基于 Session 的,但我们前面说过 Session.jsonl 是短期记忆,所以为了避免遗忘,我们还需要在 AGENTS.md 中进行长期记忆。
## Agent-to-Agent Messaging当你需要其他角色的意见或具体执行时:- **日常生活问题和任务** → `@main` 处理主人的日常生活- **编程问题和任务** → `@claudecode` 获取专业的编程技术支持
另外,当我们给多个 Agent 即配置了 Agent-to-Agent 也配置了 Sub-Agent 协作模式,那 OpenClaw 如何决断使用哪种方式呢?实际上是由 LLM 根据场景来进行决策的,Agent-to-Agent 用于协作场景,Sub-Agent 用于委派场景。
Heartbeat & Cron
Heartbeat & Cron 是实现 OpenClaw 主动发送通知的基础:
Heartbeat:周期性心跳检查,在主会话中,周期性(默认 30 分钟)触发 Agent 读取 HEARTBEAT.md,并自主执行其中定义的例行任务(如收信、发报告),无任务时回复 HEARTBEAT_OK。 Cron:定时性任务执行,精确时间触发(如每天 9:00 准时发报告)。
https://docs.openclaw.ai/zh-CN/automation/cron-vs-heartbeat
配置 Heartbeat
周期性配置
{agents: {defaults: {heartbeat: {every: "1h", // 每 1 小时醒一次target: "last", // 有事汇报时,将消息投递到最近活跃的 ChannelactiveHours: { start: "09:00", end: "23:00" } // 只在这个时段开启心跳(省 token)}}}}
写 HEARTBEAT.md:每次心跳触发,都会读一遍这个文件。
# HEARTBEAT.md## 定期检查- OpenClaw 领域热点追踪,包括:各大云厂商、开源社区方面的咨询。重点关注:OpenClaw 的安全方案、企业应用场景、竞品分析、社区版本新特性更新等方面的消息。- 进行中且未完成的工作进展## 主动汇报原则- 发现热点 → 快速响应,提出观点,立即汇报- 有数据洞察 → 主动分享- 进行中工作 → 主动推进
配置 Cron
精确时间触发的 Cron 常用于点发汇报:
openclaw cron add \--name "AI 行业早报" \--cron "0 9 * * *" \--tz "Asia/Beijing" \--agent main \--session isolated \--thinking high \--announce \--channel feishu \--account default \--to "user:XXX" \--message "早报时间到,整理昨天一天的 OpenClaw 行业消息推送、热点追踪。包括:各大云厂商、开源社区方面的咨询。重点关注:OpenClaw 的安全方案、企业应用场景、竞品分析、社区版本新特性更新等方面的消息。"
明确指定 --to "user:XXX"(你的飞书 ID) 明确指定 --account default 明确指定 --channel feishu
配置消息源
OpenClaw 需要结合具体的 Skills 和消息源(例如 Brave Search,智普联网搜索 MCP 等等)来实现网页搜索以及信息质量的提升。
Nodes 终端
Nodes 是 OpenClaw 对硬件终端设备的一种抽象,是接入到 Gateway 上的子设备,包括:iOS、Android、macOS 等等。使得 OpenClaw 可以操纵这些设备的摄像头、屏幕录制、系统控制、屏幕共享、显示可交互式的 UI 界面等等。Nodes 工作的前提是需要在这些子设备上安装一个小型智能体,或者称之为 Node Client App。
目前支持的 Nodes 类型包括:
macOS Node:system.run(执行命令)、system.notify(通知)、Canvas/摄像头。 iOS Node:Canvas、语音唤醒、摄像头拍照/录像、屏幕录制、语音触发。 Android Node:Canvas、语音交互、摄像头、屏幕截图、短信集成(可选)。
本地工具会在 Agent 模块内部直接执行,但如果涉及远程 Nodes,则必须通过 Gateway。系统会采用两道关卡,只有通过这两道检查后,命令才会被下发到远程设备。
白名单,例如某个 iOS 节点只允许 camera.snap 工具。 人工审批,例如调用 sms.send 时需要人工确认。
Nodes 和 Gateway 之间的通信协议包括:
传输:Gateway WebSocket(LAN/Tailscale/SSH 隧道) 发现:node.list / node.describe 枚举能力 执行:node.invoke 运行设备本地操作 命令:camera.snap/camera.clip(拍照/录像)、screen.record、location.get、notifications
Nodes 和 Gateway 之间的通信流程包括:
能力声明:新 Node 首次连接时,需要人工审批才能被信任;连接时必须告诉 Gateway 自己支持哪些命令和能力,也是后续工具安全的校验依据。 断连清理:当 Node 断开连接时,Gateway 会自动拒绝所有尚未完成的远程调用,防止 Agent 的工具请求长时间挂住。 超时机制:每次远程调用默认 30 秒超时,超时后自动失败并清理。
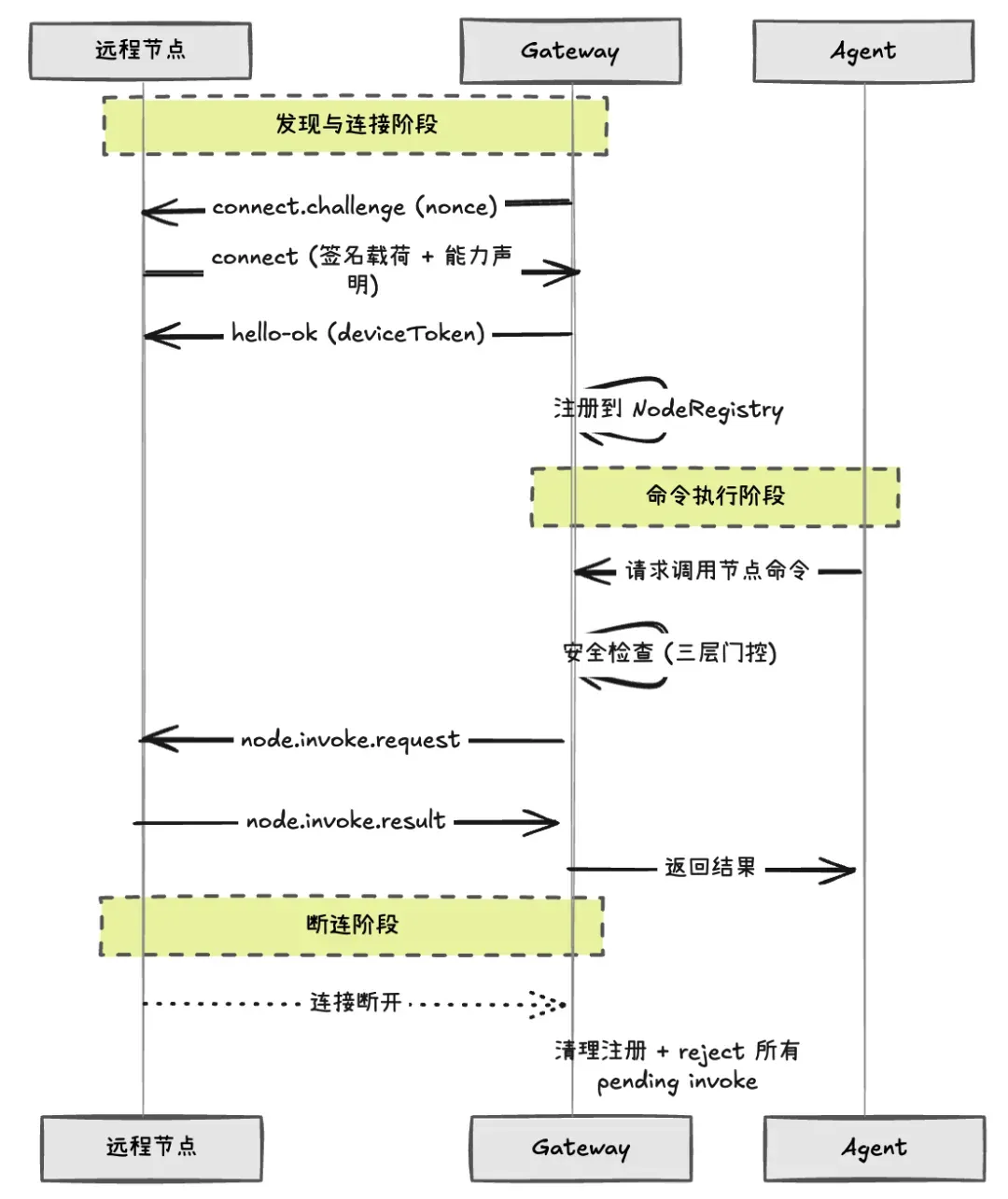
如果 Gateway 跑在 Linux 服务器上,但你想用 Mac 的摄像头拍照。
// 列出已连接的节点{ "tool": "nodes", "action": "status" }// 在 Mac 节点上执行命令{ "tool": "nodes", "action": "run", "node": "office-mac", "command": ["echo", "Hello"] }// 拍照{ "tool": "nodes", "action": "camera_snap", "node": "iphone-1" }// 屏幕录制{ "tool": "nodes", "action": "screen_record", "node": "office-mac", "duration": "10s" }// 获取位置{ "tool": "nodes", "action": "location_get", "node": "iphone-1" }
- END -
关于 “AI赛博空间” 微信公众号:
欢迎关注 “AI赛博空间” 微信公众号,我们专注于AI、大数据、云计算及网络技术的发展及应用。热爱开源,拥抱开源!
