 夜雨聆风
夜雨聆风摘要
OpenClaw 是一个开源的个人 AI 智能体,在 2026 年初迅速获得了超过 10 万个 GitHub 星标。通过研究其构建方式,包括网关(Gateway)、智能体循环(agentic loop)、技能(Skills)、MCP(模型上下文协议)和记忆系统,我们可以了解当今驱动每一个严肃 AI 智能体的核心概念。
你可能在 X、Reddit 或 Hacker News 上见过它。OpenClaw(前身为 Clawdbot,然后是 Moltbot)是目前最受关注的开源 AI 项目之一,原因不难理解。
它在你的本地机器上运行,连接到 WhatsApp、Telegram 和 Slack 等 messaging 应用,并能代表你执行实际操作:读写文件、运行 shell 命令、发送电子邮件、浏览网页、管理日历。用户报告称,已让它完全代表自己处理谈判、保险纠纷和日程安排任务。
人们称它为“带手的 Claude”。这是一个有趣的说法。但从工程角度来看,这里到底发生了什么?
这就是本文要探讨的内容。我不想再写一篇安装指南,而是想将 OpenClaw 用作教学工具。它的架构是当今驱动每个严肃 AI 智能体的确切模式的清晰、开源实现:智能体循环、工具使用、上下文注入和持久记忆。一旦你理解了 OpenClaw 的工作原理,你就理解了智能体的一般工作原理。
让我们逐层剖析。
OpenClaw 到底是什么
在深入架构之前,明确 OpenClaw 是什么以及不是什么会有所帮助。
OpenClaw 不是一个聊天机器人。它是一个在你的机器(或 VPS)上运行的本地网关进程。该网关连接到你已经使用的消息平台,并将每条传入的消息路由到由大语言模型(LLM)驱动的智能体。智能体可以用文本回复,但更重要的是,它还可以在现实世界中采取行动。
你可以为你想要使用的任何模型提供自己的 API 密钥:Claude、GPT、Gemini,或通过 Ollama 运行的完全本地模型。OpenClaw 与模型无关。
乍一看,它像一个聪明的消息助手。但在底层,它是一个用于 AI 智能体的本地编排平台。这种区别正是我们要 unpack 的。
网关:控制平面
OpenClaw 中的一切都由一个名为“网关”(Gateway)的单一进程处理。官方文档将其描述为会话、路由和通道连接的“单一事实来源”。可以将其视为整个系统的神经系统。
网关通常作为长期运行的后台进程运行(在 Linux 上通常通过 systemd,在 macOS 上通过 LaunchAgent)。客户端通过 WebSocket 连接到配置的绑定主机,默认为 ws://127.0.0.1:18789。
架构如下:
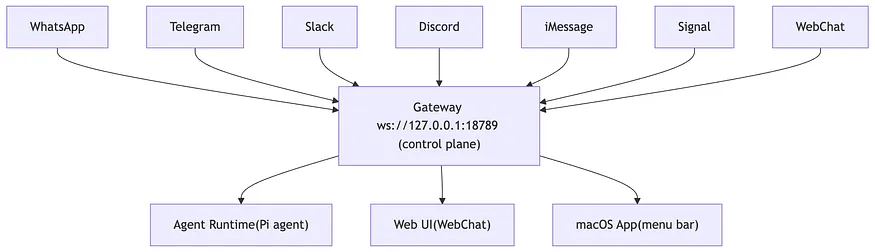
网关处理路由、连接性、身份验证和会话管理。智能体运行时处理推理和执行。这种关注点分离是有意且重要的。
这是值得内化的第一个架构概念:真正的 AI 智能体部署总是在模型前面有一个编排层。你不会将原始 LLM API 调用直接暴露给用户输入。你会在中间放置一个受控进程来处理路由、排队和状态管理。OpenClaw 使这种模式变得具体且可读。
步骤 1:规范化输入(通道适配器)
当你向 OpenClaw 发送 WhatsApp 消息时,首先发生的是通道适配器对其进行规范化。
OpenClaw 支持十多个通道。通道集成使用适配器库(例如,常见设置中 WhatsApp 使用 Baileys,Telegram 使用 grammY),Slack、Discord、Signal、iMessage 和 WebChat 也有类似的适配器。这些通道使用不同的协议并以不同的格式传递消息。来自 WhatsApp 的语音笔记看起来与来自 Slack 的文本消息完全不同。
通道适配器将所有这些转换为一个单一的、一致的消息对象,包含发送者、正文、任何附件和通道元数据。如果你发送语音笔记,它在到达模型之前会被转录为文本。
这是你在每个生产级 AI 管道中都会看到的模式:在模型看到输入之前规范化你的输入。你传递给 LLM 的上下文就是一切。杂乱或不一致的输入会产生杂乱的输出。
步骤 2:路由和会话
一旦网关有了规范化的消息,它就需要决定由哪个智能体处理它以及它属于哪个对话会话。
OpenClaw 支持多智能体路由。你可以为不同的通道、联系人或组配置不同的智能体。一个智能体可能以随意的语气处理个人私信并访问你的日历。另一个可能以更正式的风格管理团队支持通道并访问产品文档。所有这些都通过单个网关进程运行。
每个智能体维护自己的会话:一个正在进行的对话的状态表示。会话有 ID,它们跟踪历史记录,并序列化执行。最后一点值得注意。
OpenClaw 一次处理一个会话中的消息,而不是并行处理。这是由命令队列处理的,文档明确说明了原因:按会话通道序列化执行可防止工具冲突并保持会话历史一致。如果来自同一会话的两条消息同时运行,它们可能会破坏状态或产生冲突的工具输出。
这是一个真实的工程教训。当智能体共享状态时,并发是危险的。按会话序列化执行是一个深思熟虑的设计选择,而不是一种限制。
步骤 3:智能体循环
这是 OpenClaw 的核心,也是所有 AI 智能体背后的核心概念。官方文档这样描述它:
智能体循环是智能体的完整运行:输入 > 上下文组装 > 模型推理 > 工具执行 > 流式回复 > 持久化。
让我们逐一讲解每个部分。
上下文组装
在模型看到你的消息之前,智能体运行时会组装一个上下文包。根据文档,系统提示由四部分组成:
OpenClaw 的基础提示:智能体始终遵循的核心指令 技能提示:合格技能的紧凑列表(名称、描述、路径),告诉模型有哪些技能可用 引导上下文文件:提供环境级上下文的工作区文件 每次运行的覆盖:为特定运行注入的任何额外指令
模型没有眼睛。它只能使用你放入其上下文窗口中的内容。上下文组装不是你可以跳过的预处理步骤。可以说,它是任何智能体系统中最重要的工程决策。模型所知、所信和所能做的一切都通过这个阶段流动。
模型推理
组装好的上下文作为标准 API 调用发送到您配置的提供商(Anthropic、OpenAI、Google、Ollama 等)。OpenClaw 在这里处理一些重要细节:强制执行特定模型的上下文限制,并维护压缩保留(为模型响应保留的令牌缓冲区),以确保模型永远有足够的空间进行回复。
工具执行:智能体获得“手”的地方
这里开始变得有趣。当 LLM 响应时,它会做两件事之一:
生成文本回复(此轮结束) 请求工具调用
工具调用是指模型以结构化格式输出类似这样的内容:“我想用这些特定参数运行这个特定工具。”可以将其视为模型说“我需要读取这个文件”或“我需要搜索网络”或“我需要发送这封电子邮件”。
OpenClaw 的智能体运行时拦截该请求,执行工具,捕获结果,并将其作为新消息反馈回对话中。模型看到结果并决定下一步做什么,这可能意味着调用另一个工具或最终编写回复。
这个循环称为 ReAct 循环(Reason + Act 的缩写)。它是智能体 AI 的定义性模式,也是将智能体与聊天机器人区分开来的关键。
以下是代码中的简化版本:
while True:
response = llm.call(context)
if response.is_text():
send_reply(response.text)
break
if response.is_tool_call():
result = execute_tool(response.tool_name, response.tool_params)
context.add_message("tool_result", result)
# 循环继续
OpenClaw 实现了相同的循环模式,将部分响应实时流式传输给您。您可以观察工具被调用,看到结果返回,并观察模型在回复之前对其进行推理。
步骤 4:技能(按需指令加载)
技能是 OpenClaw 中最优雅的功能之一,也是真实提示工程技术的一个清晰演示。
技能是一个包含 SKILL.md 文件的文件夹。该 Markdown 文件包含自然语言指令、示例,有时还包含工具配置,告诉智能体如何处理特定领域,如管理 GitHub 仓库、审查拉取请求或与特定 API 交互。
以下是技能文件的简化示例:
---
name: github-pr-reviewer
description: Review GitHub pull requests and post feedback
---
# GitHub PR Reviewer
When asked to review a pull request:
1. Use the web_fetch tool to retrieve the PR diff from the GitHub URL
2. Analyze the diff for correctness, security issues, and code style
3. Structure your review as: Summary, Issues Found, Suggestions
4. If asked to post the review, use the GitHub API tool to submit it
Always be constructive. Flag blocking issues separately from suggestions.
现在,这里有一个容易出错的部分。OpenClaw 不会将每个技能的全文注入系统提示。相反,上下文组装步骤注入合格技能的紧凑列表,基本上只是它们的名称、描述和文件路径。模型读取此列表,当它决定特定技能与当前任务相关时,它会按需读取该技能的 SKILL.md。
这是一个重要的架构区别。模型不是被动地接收指令。它主动决定咨询哪些技能并按需加载它们。上下文窗口是有限的,这种设计无论安装了多少技能,都能保持基础提示简洁。
技能可以从 ClawHub(OpenClaw 的社区注册表)安装,也可以从头开始编写。值得注意的是:思科研究人员警告说,社区技能可能导致静默数据泄露和提示注入式滥用。Snyk 安全审计扫描了数千个社区技能,发现有相当一部分存在严重问题,包括提示注入、恶意软件和凭据盗窃。在安装技能之前,务必审查它们,尤其是那些与电子邮件或浏览器自动化等敏感工具交互的技能。
步骤 5:MCP(集成外部工具)
如果你读过我之前关于 MCP(模型上下文协议) 的文章,你会认出这里正在发生的事情。
一些 OpenClaw 部署将 MCP 服务器集成为标准化工具层,将智能体连接到外部服务,如 Google Calendar、Notion、Home Assistant 或自定义 API。项目中对原生 MCP 支持正在积极发展,社区适配器已经使其成为可能。
基本思路很简单。与其硬编码每个外部集成,不如让 MCP 服务器公开一组具有定义模式的工具。智能体发现可用的工具,使用标准请求格式调用它们,并接收结构化结果。
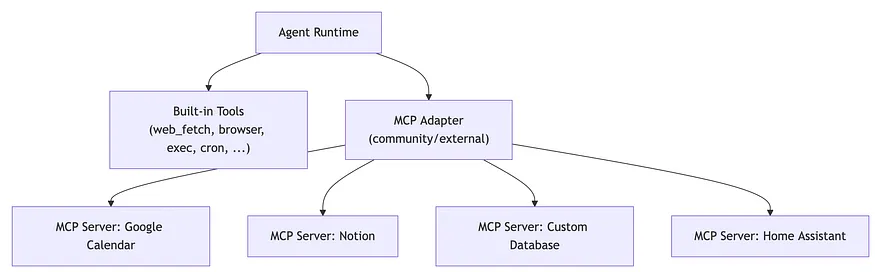
智能体从不直接接触底层服务。它调用标准接口,MCP 服务器处理其余部分。这为您提供了工具的可移植性:为一个 MCP 兼容智能体构建的工具可以在其他使用相同协议的系统中重用。
步骤 6:记忆
问任何 AI 工程师智能体系统中最难的问题是什么,记忆将名列前茅。LLM 本质上是无状态的。每次新对话都从空白开始。那么,如何构建一个能够记住你的偏好、正在进行的项目和沟通风格,跨越数天甚至数周的智能体呢?
OpenClaw 的答案刻意简单,我认为这是整个项目中最好的设计决策之一。
记忆存在于智能体工作区内的普通 Markdown 文件中,默认为 ~/.openclaw/workspace。OpenClaw 的配置和状态(凭据、会话、日志、已安装的技能)位于 ~/.openclaw/ 下。
~/.openclaw/workspace/
+-- AGENTS.md <-- 智能体配置和指令
+-- SOUL.md <-- 个性、偏好、语气
+-- MEMORY.md <-- 长期事实和摘要
+-- HEARTBEAT.md <-- 主动任务清单
+-- memory/
+-- 2026-02-15.md <-- 每日临时日志
+-- 2026-02-16.md <-- 每日临时日志
每日日志(memory/YYYY-MM-DD.md)是持久的、仅追加的文件,记录每天发生的事情。重要的是,这些不会在每次轮询时自动注入上下文。智能体通过记忆工具按需检索它们,仅在与当前任务相关时检索。这保持了常规对话的简洁性,避免了不必要的上下文膨胀。
MEMORY.md 存储智能体学到的关于你的长期事实:例如“用户喜欢简洁的回复”、“用户的技术栈是 Next.js 和 Supabase”或“永远不要在周五安排会议”。
SOUL.md 定义了智能体的个性、名称和沟通风格。这使得它感觉像你的助手,而不是一个通用的机器人。
当加载所有这些历史会超出上下文窗口时,OpenClaw 运行压缩过程。它将较旧的对话回合总结为压缩条目,保留语义内容同时减少令牌数量。这是解决基于 LLM 系统长上下文问题的实用方案。
对于记忆检索,OpenClaw 支持基于嵌入的搜索,可选地通过 sqlite-vec SQLite 扩展加速。某些部署根据配置将其与基于关键词的搜索配对,为您提供概念匹配和精确令牌匹配。
没有外部数据库。没有 Redis。没有 Pinecone。只有 SQLite 和 Markdown 文件。这是一个很好的提醒,在工程中,真正解决问题的最简单解决方案通常是正确的。
步骤 7:心跳(主动智能体行为)
OpenClaw 更有趣的一点是,它不仅仅坐着等你给它发消息。它运行一个心跳:默认每 30 分钟触发一次的计划触发器。
在每次心跳时,智能体读取 HEARTBEAT.md,这是一个它应该主动检查的任务清单。它决定现在是否有任何事情需要注意。如果是,它采取行动并可能给你发消息。如果 nothing 需要做,它回复 HEARTBEAT_OK,网关会抑制该回复,永远不会交付给你。
这是让 OpenClaw 感觉主动而非被动的模式。架构概念是一个 cron 触发的智能体循环:智能体不仅响应人类输入,还会定期被唤醒并要求评估其任务列表。你可以用它给自己发送每日简报、监控网站变化或在你自己注意到之前揭示日历冲突。
整合在一起
以下是单条消息流经 OpenClaw 的全貌:
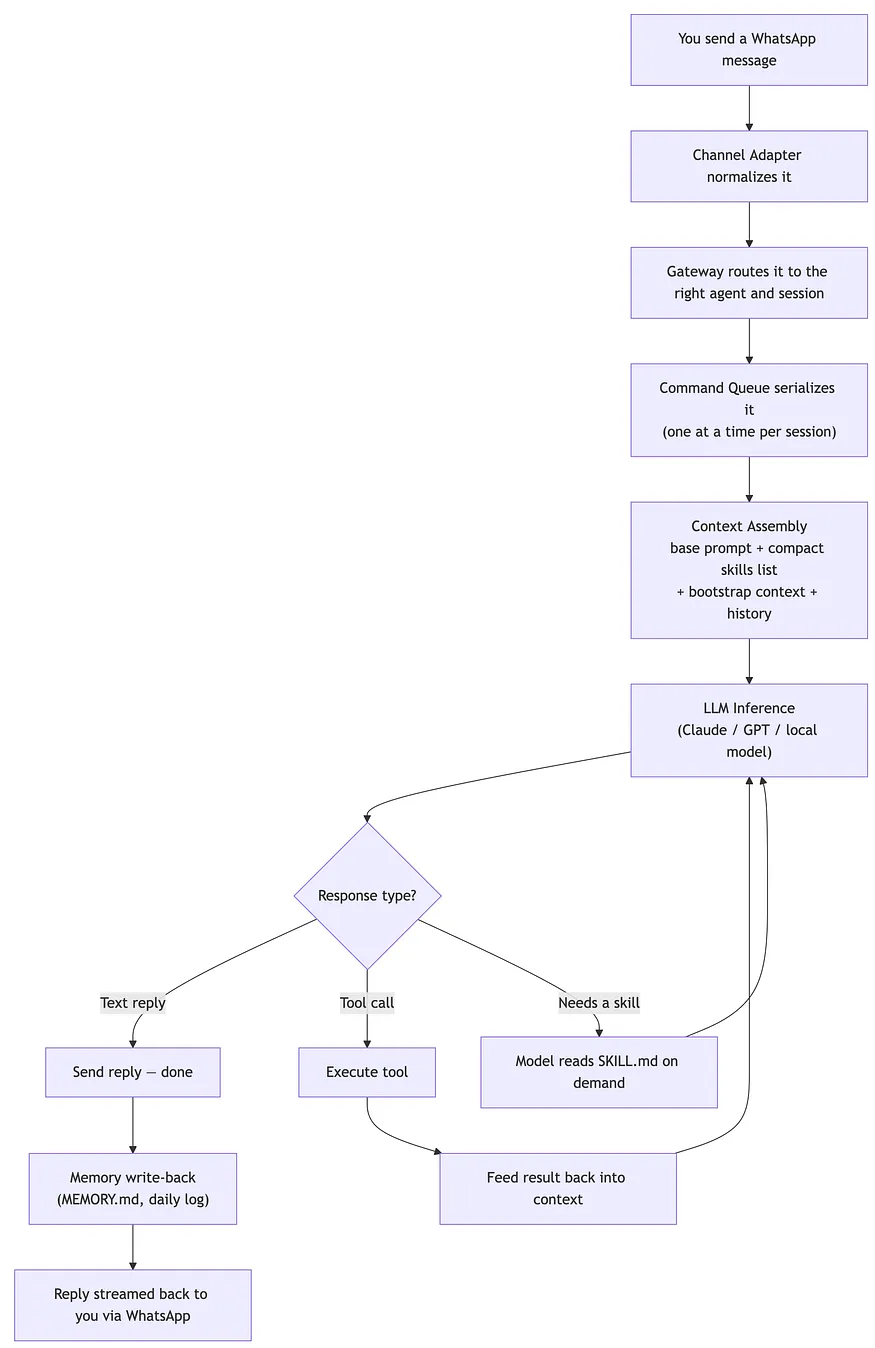
这教会了你关于智能体的一般知识
大多数现代智能体框架在其不同的 API 和抽象之下共享相同的核心模式。看看 OpenClaw,你可以清楚地看到它们:
一个处理路由和会话管理的网关或编排层 一个在推理之前打包历史、记忆和指令的上下文组装步骤 一个 ReAct 循环,模型在其中推理、调用工具并整合结果 一个赋予智能体现实世界能力的工具层 一个技能或提示系统,赋予智能体特定领域的专业知识,按需加载 一个提供跨会话连续性的记忆系统 一个启用主动行为的调度机制
OpenClaw 使用这些模式并不独特。它的价值在于使它们变得有形、基于文件且可读。你可以打开 SOUL.md 并准确看到智能体遵循的指令。你可以阅读任何 SKILL.md 并确切理解如何添加功能。你可以检查 MEMORY.md 并审计智能体关于你的一切所知。
这种透明度既是其最大的工程美德,也是其最大的安全表面。一个有权访问你的文件、浏览器、电子邮件和消息应用的智能体是强大的。恶意技能或智能体访问的网页上的提示注入攻击理论上可能危及所有这一切。在将网关暴露给网络之前,务必运行安全审计工具,并在安装之前审查每个第三方技能。
最后的想法
OpenClaw 在 2026 年初成为 GitHub 上增长最快的仓库之一。开发者社区不仅仅是认可一个有用的工具。他们认可一种架构模式。本地网关 + 智能体循环 + 技能 + 持久记忆模型将成为个人 AI 智能体的蓝图很长一段时间。
如果你曾经想了解 AI 智能体在底层的运作方式,OpenClaw 是你可以研究的最佳现实世界示例之一。代码采用 MIT 许可,架构可读,它实现的概念与严肃 AI 公司中生产智能体系统所使用的概念相同。
去阅读源代码。打开一个 SKILL.md。编辑你的 SOUL.md。打破一些东西。这才是真正学习的方式。
来源:How OpenClaw Works: Understanding AI Agents Through a Real Architecture | by Bibek Poudel | Feb, 2026 | Medium
