 夜雨聆风
夜雨聆风
 如果你的 AI 助手能记住一年前你们讨论的每个细节,会发生什么?
如果你的 AI 助手能记住一年前你们讨论的每个细节,会发生什么?
一、AI 的"七秒记忆"困境
我有个朋友,用 AI 写代码写了一个多月。前几周聊得火热,架构设计、代码规范、技术选型全都讨论过。结果某天他打开对话想问一个细节——AI 一脸懵:什么项目?选了什么技术栈?
这不是 bug,这是设计。
AI 模型的"脑子"有个硬限制:上下文窗口。以常见的模型为例,大概是 128K ~ 1M Tokens,相当于一本中等长度的小说。听起来挺多,但对话一旦变长,旧内容就会被挤出去。
就像往 10 升的桶里不停倒水——新水进来,旧水溢出。
真实场景里的痛点
开发一个项目:
周一讨论架构 周三写核心模块 周五调试,架构细节已经模糊了 下个月想优化性能,之前的讨论全没了
长期协作?不存在的。
二、现有的记忆方案:各有利弊
AI 的记忆问题不是新鲜事,业内已经有几种常见做法。
滑动窗口
最简单粗暴:只保留最近 N 条消息。
就像只记得最近 24 小时的事情。优点是实现简单,缺点是——旧内容彻底没了,找都找不回来。
向量检索(RAG)
把历史对话存进向量数据库,需要时检索。
像图书馆,想看什么就去翻。但问题是:检索不一定准。关键词没对上,可能漏掉关键信息。而且要搭向量数据库、配 Embedding 模型,架构比较重。
摘要压缩
对话长了,让 AI 把旧内容压缩成摘要。
像看书只记笔记,原文扔了。好处是保留了"大意",坏处是细节没了——而且摘要本身可能走样。
混合方案
很多产品组合着用:最近的完整保留,中间的压缩摘要,更早的存向量库检索。
但说到底,原始信息还是会有所损失。真正能做到"无损"的方案,一直是个空白。
三、lossless-claw:一个"不丢东西"的方案
2025 年,Voltropy 团队发了一篇论文,提出 LCM(Lossless Context Management)。OpenClaw 随后做了个插件叫 lossless-claw。
核心思路:原始消息一个都不丢,但对话上下文要控制住。
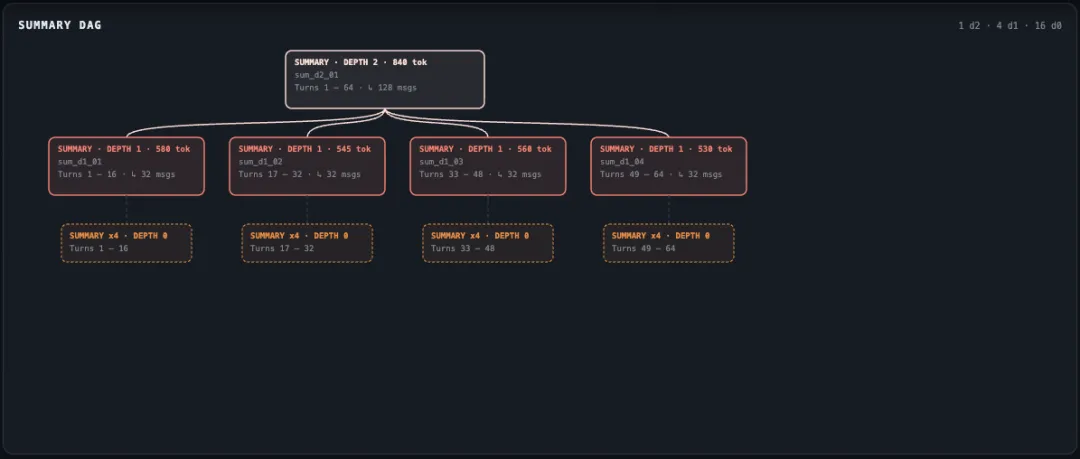
怎么做到的?分层摘要。
像整理一本书
想象你在整理百万字的手稿:
原始内容:每一句话完整保存 章节摘要:每几页压缩成一段 目录:每个章节摘要再压缩 总目录:更高层次的概括
重点是:每个摘要都留着指向原文的链接。
平时看目录就够了。需要细节?点进去看原文。
具体怎么运作
一个月的对话可能长这样:
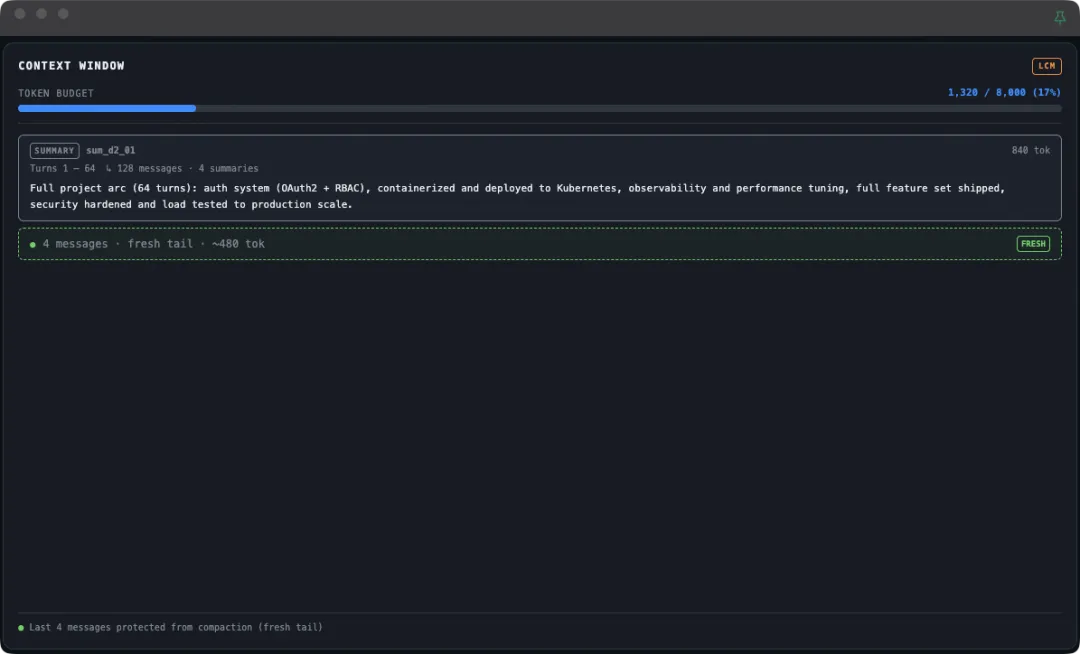
消息 1-500 → 叶摘要 A消息 501-1000 → 叶摘要 B消息 1001-1500 → 叶摘要 C叶摘要 A + B + C → 高层摘要 XAI 平时带着高层摘要 X 对话,上下文很短。但如果你问"那天讨论的数据库选型",它可以:
定位相关的高层摘要 展开对应的叶摘要 调取原始消息
全在 SQLite 里,不用向量库,不用 Embedding 模型。
四、三个工具,让记忆"活"起来
lossless-claw 给 AI 配了三个"回忆"工具:
lcm_grep
关键词搜索。在历史记录里搜"数据库选型"或"性能优化"。
lcm_describe
让 AI 了解某个时间段大概聊了什么,判断要不要深入。
lcm_expand
展开某个摘要,看背后的原始消息。
AI 既能快速浏览摘要,也能在需要时深挖原始记录。像配了个记忆助手。
官方做另一个非常形象化的原理动态演示(非常精彩),强烈建议去看下。
地址:https://www.losslesscontext.ai/
五、几个技术细节
压缩策略
Level 0:8-16 条原始消息 → 1 个摘要(800-1200 tokens)Level 1:4-8 个 Level 0 摘要 → 高层摘要(1500-2000 tokens)Level 2+:继续向上...越高层越抽象。叶节点保留时间线,高层节点关注主题和决策。
如果摘要质量不好怎么办?
三级兜底:
正常模式:标准提示词 激进模式:只保留硬事实 兜底模式:直接截断
稳定运行比优雅重要。
大文件处理
用户粘贴了 5 万字的配置文件?
系统会检测到,存到独立文件系统,生成简短摘要,消息里只留引用。AI 需要看原文时再调取。
六、安装配置
安装
openclaw plugins install @martian-engineering/lossless-claw配置
在 OpenClaw 配置中指定 contextEngine:
{"plugins": {"slots": {"contextEngine": "lossless-claw"}}}
推荐参数
{"plugins": {"entries": {"lossless-claw": {"enabled": true,"config": {"freshTailCount": 32,"contextThreshold": 0.75,"incrementalMaxDepth": -1}}}}}
freshTailCount: 32:最近 32 条消息保持原样 contextThreshold: 0.75:上下文用到 75% 时开始压缩 incrementalMaxDepth: -1:不限制摘要层级
会话保持
默认会话会在一段时间后重置。想利用长记忆能力:
{"session": {"reset": {"mode": "idle","idleMinutes": 10080}}}
会话保持 7 天,可根据需要调整。
七、优缺点
优点
原始消息永远可追溯 只需要 SQLite,架构简单 压缩在后台自动进行,用户无感 AI 可以主动搜索和展开历史 粘贴大文件不会撑爆上下文
局限
摘要质量依赖 LLM,模型差可能丢信息 历史消息占用磁盘空间 目前每个会话独立存储 不改变会话重置策略——会话被重置后需要重新导入历史
八、什么场景适合用
适合:
长期开发项目 需要追溯决策过程 技术文档、代码审查、方案设计 把 AI 当长期记忆助手
可能不适合:
一次性对话 资源受限环境 不想保留历史记录的场景
九、写在最后
AI 的记忆问题不只是技术问题。它关乎我们能不能和 AI 建立长期信任的关系。
lossless-claw 的思路是:记忆不该是非此即彼的选择——要么全记,要么全忘。它应该有层次、可追溯、按需展开。
像人类的记忆:大事记得清清楚楚,某个下午的对话细节需要时也能想起来。这种"有选择性的完整",可能才是对的方向。
如果你想让 AI 记住你说过的东西,试试 lossless-claw。
被记住的感觉,挺好的。
参考资料
lossless-claw GitHub: https://github.com/Martian-Engineering/lossless-claw
LCM 论文: https://papers.voltropy.com/LCM
OpenClaw 文档: https://docs.openclaw.ai
可视化演示: https://losslesscontext.ai
