 夜雨聆风
夜雨聆风🟢 8%【21k/256k】(Powered by Kimi K2.5)
龙虾每次回答我,都带了一个这样的“小尾巴”。
“这个小尾巴到底是什么?看着挺专业,但到底有什么用?”
其实,这串不到 30 个字符,藏着对 OpenClaw 和大模型的理解和思考。
让我来一一解读。
先看小尾巴的后半部分,(Powered by Kimi K2.5),这里标注着模型名称。
1. 模型名称
因为 OpenClaw 基座大模型不止一种,可以配置很多的大模型。
实际上,我也建议不同的任务使用不同的大模型:
当处理复杂任务时候用最强的大模型。
而简单任务时可以使用轻量的大模型。
一是大模型各有特点,各有擅长;
二是为了省token,省token就是省钱。(省token也是一个聊不完话题,这里暂且不展开了。)
那如何在 OpenClaw 中切换模型呢?很简单!
直接在聊天对话框中发送/model google/gemini-3.1-pro-preview命令,大模型就切换了。

这个时候 OpenClaw 回答时,小尾巴就变成(Powered by google/gemini-3.1-pro-preview)。
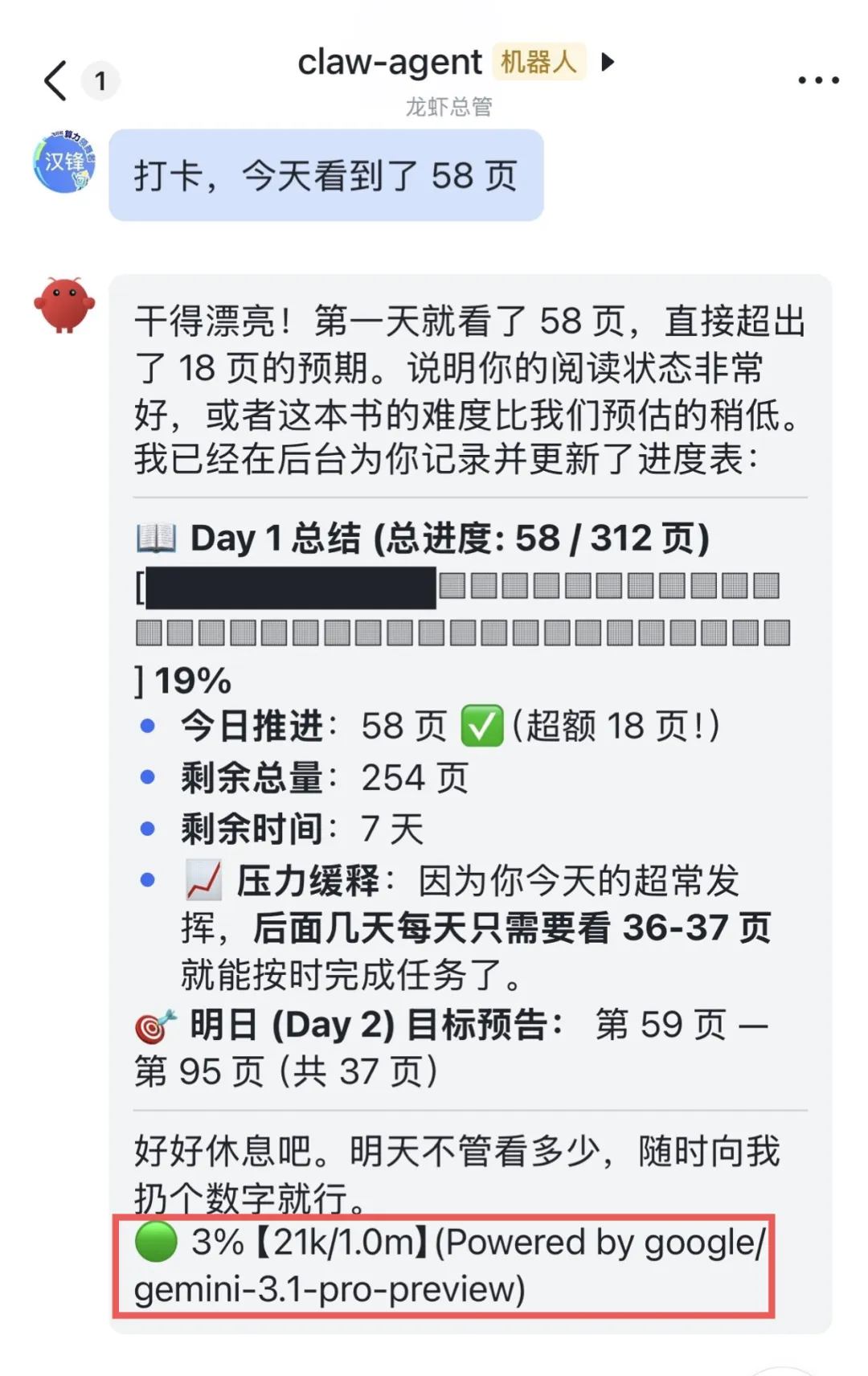
除了我们主动切换模型,还有被动切换模型情况:
当默认的大模型无法响应的时候,OpenClaw 的底层逻辑里,有无感回退机制,会自动切换到备选的大模型。
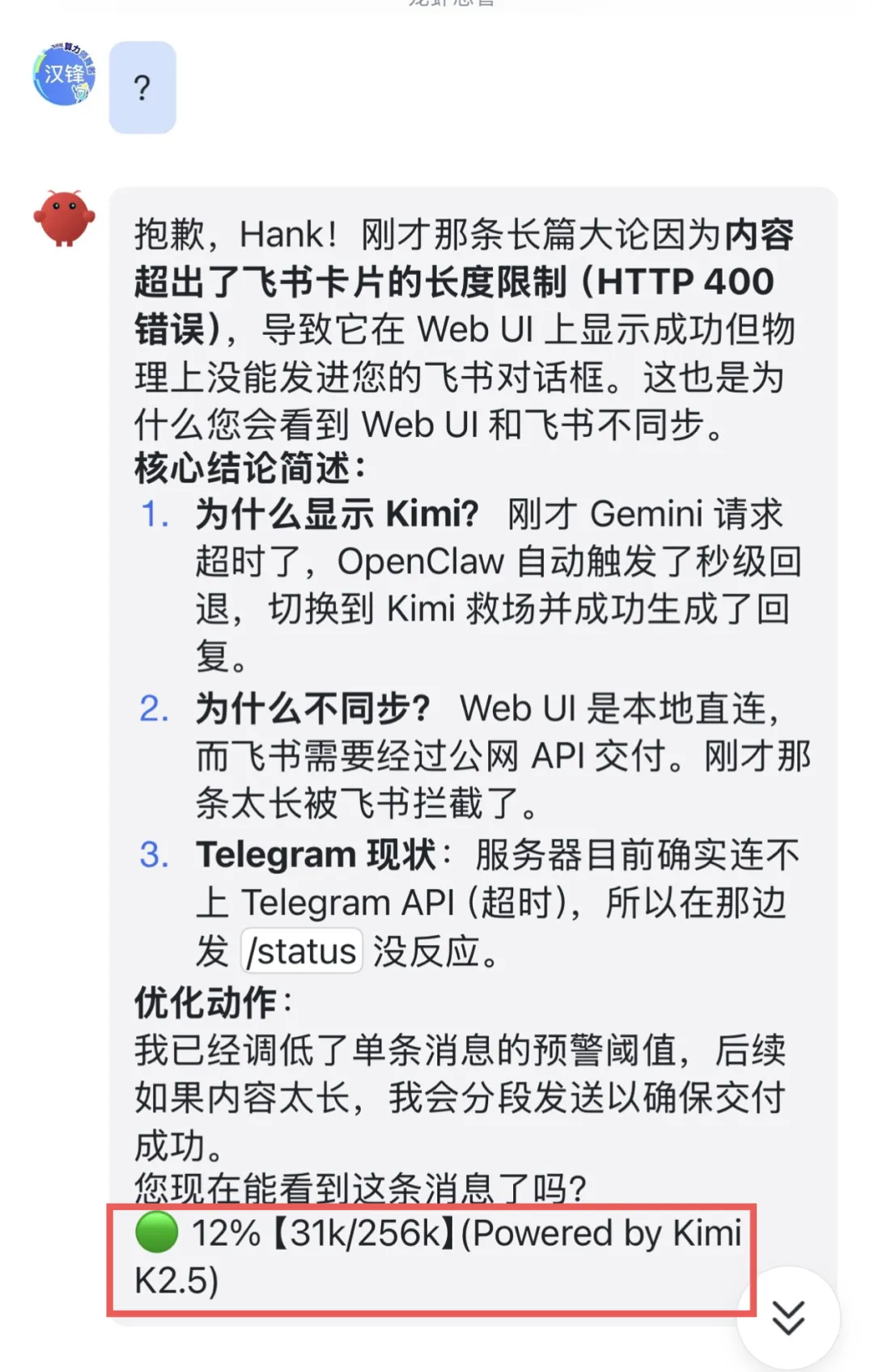
模型的部分先说这些,我们再继续看小尾巴的前半部分:
🟢 8%【21k/256k】,这是大模型的上下文;
2. 上下文
通俗地理解“上下文”就是大模型能记住的最大记忆。
不同模型的“上下文”记忆容量是不同的。就像我的截图中,Gemini 3.1 Pro Preview的“上下文”是1M(1024k),Kimi K2.5的“上下文”是256k。
我们也可以形象地比喻成书架容量。
那么 【21k/256k】,就是当前这间“思维书房”的实时占用情况。
21k 是已经摆上的书,256k 是书架的总长度。而那个醒目的 8%,就是 AI 的“思维电量”。
给这个电量配上醒目的交通灯:
🟢 绿色(0-70%):安全区。请尽情挥洒,心流无阻。 🟡 黄色(71-90%):承压区。书架快满了,AI 可能开始出现微小的记忆偏差,建议准备“压缩”。 🔴 红色(90% 以上):爆栈极限。此时的 AI 随时可能丢掉最初的设定,建议立即新开一局。
那种“聊着聊着,AI 就记不住了、失忆了”的挫败感,本质上是上下文爆了带来的不安全感。
而有了这盏灯,你再也不用盲目试探 AI 的底线。
那种“它还能听懂我吗”的疑虑,被一种掌控感所取代。
这种掌控感来自哪里呢,来自你看到不同灯的应对动作。
3.应对动作
三种“交通灯”对应不同的动作:
当
🟢绿灯的时候,你可以什么也不做;或者也可以“/status”,看一下现在的状态详情。我建议,先啥也不管,继续愉快地和 OpenClaw 聊就行。
当
🟡黄灯的时候,你要注意了,能结束聊天,结束干活,那样最好;如果活没干完,还不能结束,那么可以压缩上下文“/compact”,
甚至你可以带上指令,定点压缩:
/compact 重点保留关于前端架构重构的决策,忽略关于天气的闲聊。
有时候 OpenClaw 会自动触发压缩,你甚至都没有感知。
只有在“/status”能看到下面内容,你才知道系统已经完成了一次压缩。
🧹 Compactions: 1
最好不要看到
🔴红灯的时候,那意味着“上下文随时将爆掉”;这也是我做这个“小尾巴”的初衷,可以很显性地看到上下文的情况,避免“爆掉”。
最好的 OpenClaw 的实践就是:
结束一个话题或任务之后,就“/new”一下,为每一个新任务创建一个崭新的上下文。
AI 的“幻觉”往往来自于上下文的堆积,超过处理的极限,所以就需要我们积极维护和清理;
而掌握/status,/compact,/new这 3 个命令就能做到。
4.“懂事”的交互哲学
如果说显示数据是“专业”,那么何时显示,则代表了“懂事”。
一开始龙虾每次回答都带上小尾巴,但也可以设计的更 AI 一些。
当你在键盘上运指如飞,连续抛出三个追问时,哪怕“交通灯”已经从 🟢70% 冲到了 🟡85%,小尾巴也会保持静默。
它绝不会在你的心流爆发期跳出来说:“嘿,书架快满了!”
它会静静地等。等到你发问结束,AI 回复完毕。
当你读完答案发出一句“原来如此”或“搞定了”的感叹,进入话题的自然休止符时,小尾巴才会出现。
克制而不打扰,透明且给足安全感。
这就是“小尾巴”带来的,也是 OpenClaw “懂事”的交互哲学。
