 夜雨聆风
夜雨聆风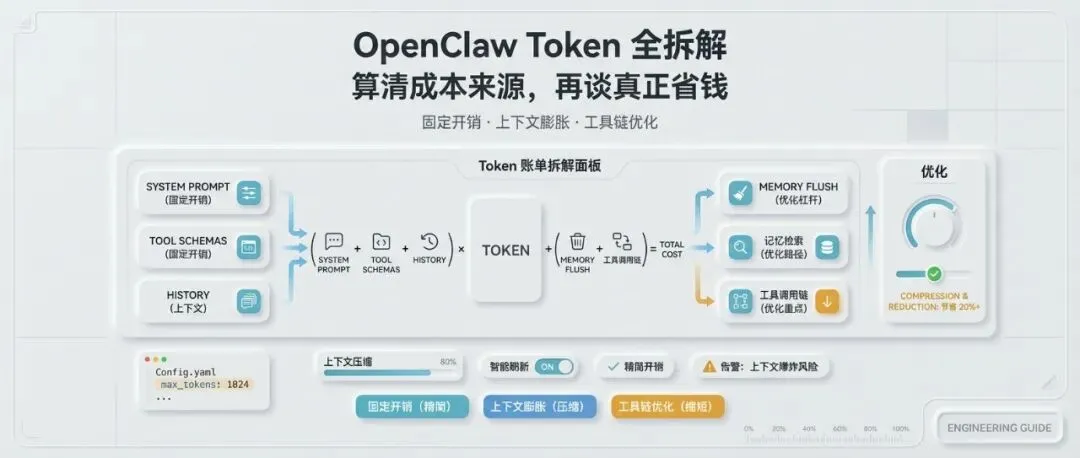
很多人觉得 OpenClaw “特别烧 Token”,但真正把账单拆开后会发现,问题并不只是模型单价高,而是请求里叠加了太多固定开销、上下文累积和工具调用链。若只盯着模型价格,很容易误判真正的成本来源。
更准确的理解方式是:OpenClaw 的一次请求,本质上是一笔由多层输入和多轮工具协作共同组成的复合账单。只有把这些成本拆清楚,后面的优化动作才有方向。
一、先记住这条总公式:OpenClaw 的 Token 不是一笔钱,而是六笔钱叠在一起
单次请求的总消耗,可以拆成下面这条公式:
OpenClaw Token 消耗 = System Prompt + Tool Schemas + 会话历史 + Memory Flush + 记忆检索结果 + 工具调用链
如果再加上模型最终输出内容,就会构成完整的双向计费账单。
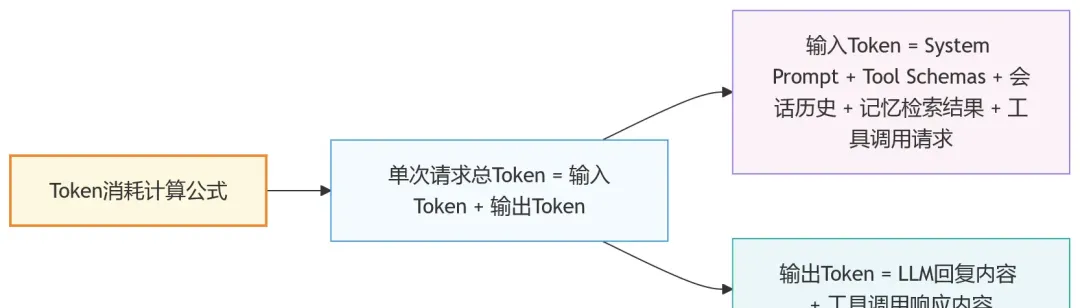
OpenClaw 单次请求的 Token 计算结构
从优化角度看,这六部分并不等价。有些属于固定成本,有些是配置不当造成的放大项,还有一些来自任务链过长后的叠加损耗。
二、六大成本项分别从哪里来,哪些是真刚需,哪些还能压缩
1. System Prompt:每次请求都要先交的“过路费”
OpenClaw 的系统提示词不是一小段固定文本,而是由基础指令、工具说明、运行环境信息和 Bootstrap 文件拼接出来的。只要 Agent 发起一次请求,这部分就会被完整送进上下文。
2. Tool Schemas:所有已启用工具的说明书都会被带上
只要工具处于启用状态,其 JSON Schema 基本都会成为输入的一部分。浏览器、命令执行、定时任务、节点协作等工具越多,固定 Token 成本越高。
3. 会话历史:不是一次花完,而是越拖越贵
很多人真正高估的不是单次模型调用,而是连续会话里的上下文膨胀。每多一轮交互,历史消息都会跟着累计,直到触发压缩阈值之前,这部分成本只会越来越高。
4. Memory Flush:压缩历史前,还要先额外再花一轮
OpenClaw 在触发历史压缩前,通常需要先做一次记忆整理,把值得保留的信息写入记忆层。这个动作本身就是一次额外 LLM 调用,因此会再吃掉一笔完整请求级别的成本。
5. 记忆检索结果:搜出来的内容也会继续占上下文
memory_search 并不是“免费查库”。检索到的文本片段、匹配度信息和路径说明,只要被回填到对话上下文里,就会继续计入输入 Token。
6. 工具调用链:每多走一步,请求和响应都会继续计费
一次看似简单的需求,只要触发了读文件、查记忆、发消息、写文档等连续动作,成本就会沿着调用链不断叠加。很多人以为花费集中在最终回复,实际上大量 Token 都消耗在工具之间的中间过程。
把六部分压成一张表,会更容易看清哪些地方值得优先优化:
成本模块 | 是否刚性 | 常见放大原因 | 优化方向 |
|---|---|---|---|
System Prompt | 是 | Bootstrap 文件过长、Skills 提示过多 | 精简基础配置 |
Tool Schemas | 部分刚性 | 启用过多暂时不用的工具 | 禁用冗余工具 |
会话历史 | 否 | 对话拖太长、压缩阈值过高 | 提前压缩上下文 |
Memory Flush | 否 | 自动触发过于频繁 | 调整触发策略 |
记忆检索 | 否 | 检索阈值过低、回填内容过多 | 提高筛选门槛 |
工具调用链 | 否 | 一个任务拆成过多工具往返 | 合并动作、缩短链路 |
三、记忆层的作用,不是“帮你省钱”,而是“避免上下文直接爆掉”
很多人会误以为,记忆层存在的目的就是减少 Token。这个判断并不准确。记忆层更像一种“延长对话寿命”的缓冲机制,它负责把旧信息折叠、转存、再按需检索回来,从而避免所有历史消息一直堆在主上下文里。
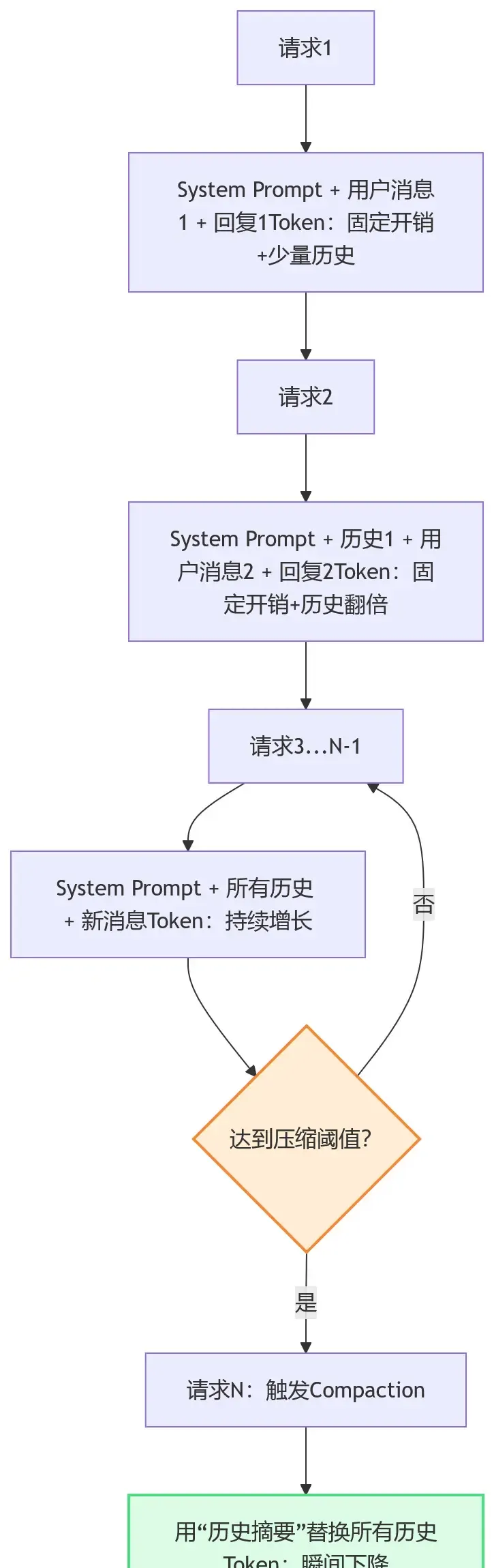
会话历史累积与压缩触发关系示意图
这套机制的真正价值在于两点:
让长对话还能继续进行,而不是直接撞上模型上下文上限 把“所有历史都常驻”改成“只在需要时回捞”
所以,记忆层本质上是在延缓成本爆炸,而不是让成本凭空消失。如果配置不合理,它甚至会因为频繁触发 Memory Flush 产生新的额外开销。
四、想真正把账单降下来,优先做这五件事
1. 精简 System Prompt 和 Bootstrap 文件
最先该动的通常不是模型,而是基础配置。只保留当前场景真正需要的约束文件,把不参与当前任务的补充说明移出默认加载范围,往往就能立刻看到单次输入成本下降。
2. 关闭冗余工具,别让不用的 Schema 跟着白跑
如果当前任务不需要浏览器、定时任务、画布、节点协作等能力,就不要让它们默认开启。关闭这些工具,既能降 Token,也能减少误调用带来的不确定性。
openclaw config set tools.browser.enabled falseopenclaw config set tools.cron.enabled falseopenclaw config set tools.canvas.enabled falseopenclaw config set tools.nodes.enabled false
3. 把上下文压缩阈值从“快爆了再压”改成“提前收口”
默认阈值太高时,会话历史会先疯狂膨胀,再在接近上限时被迫压缩。更合理的做法是把压缩阈值调到 60% 到 70% 左右,让历史更早开始收缩。
{ "agents": { "defaults": { "contextCompactionThreshold": 0.7, "bootstrapMaxChars": 8000 } }}
4. 控制 Memory Flush 和记忆检索的触发频率
记忆整理和检索不是越勤快越好。适当关闭自动 Flush、提高检索分数阈值、定期清理低价值记忆片段,都会直接减少隐形成本。
5. 把高价模型留给高价值任务
如果 OpenClaw 的大多数工作是日常整理、读写文件和简单工具调用,那么默认模型不必长期停留在最昂贵档位。将高价模型留给真正复杂的推理任务,性价比通常更高。
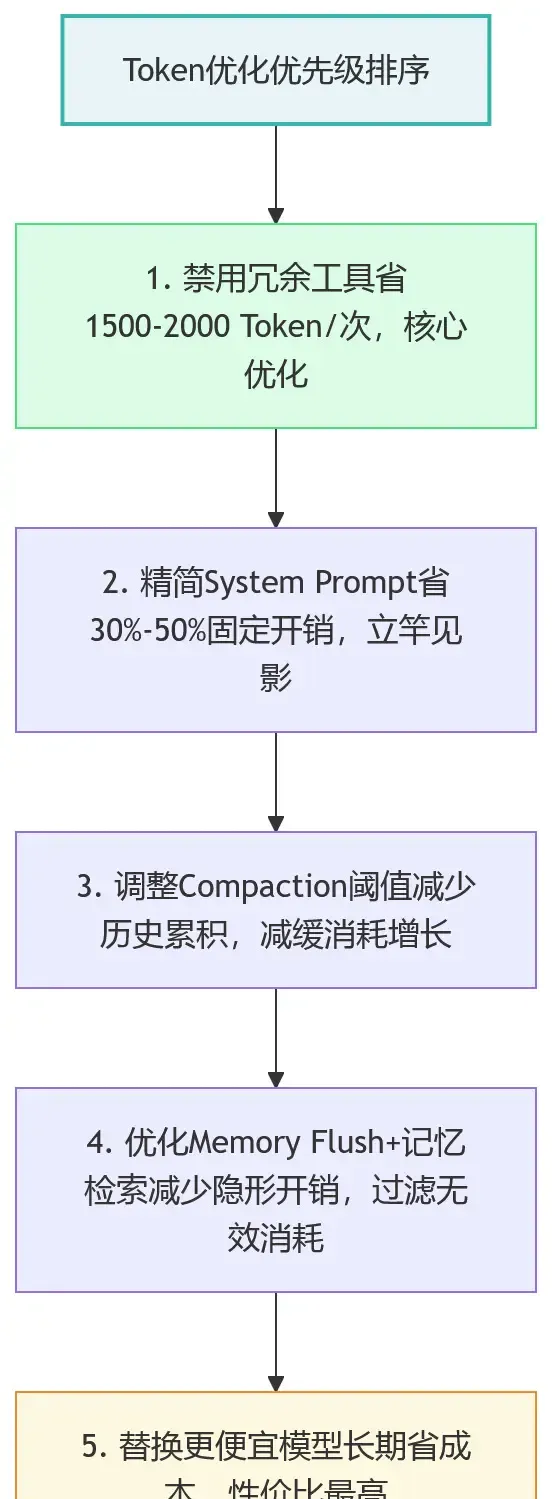
更实用的 Token 优化优先级排序
五、最容易忽视的一点:链路越长,成本越像滚雪球
一个简单例子就足够说明问题。假设需求是“读取接口定义文件,生成接口文档,再发到团队群”。如果 Agent 依次执行读文件、查记忆、发消息三步,那么成本不会只发生在最后那条消息上,而是整个工具链每一步都在累计输入和输出 Token。
这也是为什么很多团队明明没有开特别长的对话,却依然感觉配额掉得很快。真正吃掉预算的,往往不是单轮回复,而是隐藏在“工具来回跑”里的中间成本。
六、结论:OpenClaw 省钱的关键,不是少用,而是把固定成本和冗余链路收干净
如果把全文压成一句话,那么 OpenClaw 的优化思路其实非常明确:先处理固定开销,再压缩历史膨胀,最后缩短工具调用链。真正能把账单降下来的,不是盲目少用,而是让每一轮请求都尽量只带必要的信息、必要的工具和必要的动作。
理解了这一点之后,Token 管理就不再是模糊的“感觉很贵”,而是可以被拆解、被测量、也可以被持续优化的一套工程问题。
