夜雨聆风
夜雨聆风先说结论:深度体验了一天,没感受到两者有什么大的差别。
至于为什么突然要换模型?
因为之前的充值(kimi2.5)余额,已经见底了,关键,还欠费了。

也就耍了短短 2 周时间而已,而欠费的后果就是:
[agent/embedded] embedded run agent end: runId=a00a8aac-52ce-4a3e-b909-0a64dec986a6 isError=true model=kimi-k2.5 provider=moonshot error=?? API rate limit reached. Please try again later.
API 请求速率给你一限,啥也干不了。
得,确实有点用不起了,那咱换个更划算的。
0. 换模型
考虑到性价比跟 coding 能力,一番对比之后,找到了 MiniMax,据说很厉害,于是就订阅了下面这个,我暂时能负担得起的套餐。
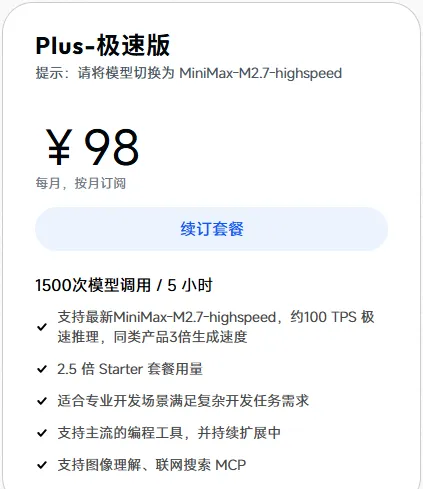
上周,就已经看到有很多文章在夸这个 MiniMax2.7 多么牛逼了,那这次换上,正好可以深度体验一下。
1. 如何配置
因为是修改「主模型配置」,经过这段时间的摸索,最靠谱的方式,是通过执行「openclaw config」命令来设置。
这里需要注意的是,目前我这个 Openclaw 版本(v2026.3.13)的配置界面,还只能显示 MiniMax2.5:
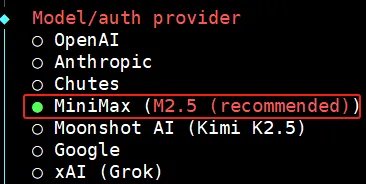
但没关系,先直接选(后面再把配置文件里面的 2.5,给改成 2.7)。
然后,选这个(直接用 API key):
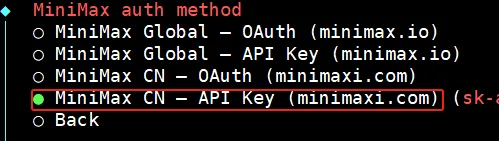
再然后,把你 2.7 的 API key 给粘上去:
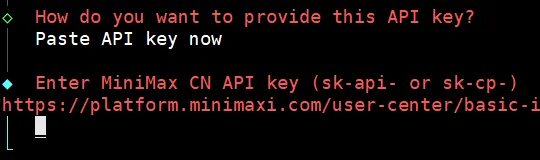
系统默认会给你选这两个,直接回车:

然后,模型就配置好了,但这个时候,你的龙虾显示还只是 2.5 版本的 MiniMax。
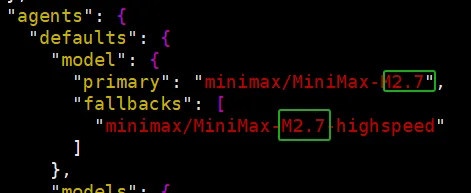
想要变成真正的 2.7,咱得改配置文件 ~/openclaw/openclaw.json,把里面所有的 2.5,替换成 2.7.
尤其注意这个地方,一旦改错,那对话就嗝屁了:
最后,重启 Openclaw agent,生效。
后续在你跟它的对话框里,就可以看到目前用的是 2.7.

2. 限速比较严重
目前这个套餐,可以让你在 5 小时内,提交 1500 次的模型调用,看着很多对不对?

而事实情况是,如果你一个人用,大概率用不完。
但是,这个模型调用次数,其实根本不是重点,重点是你 token 的请求速率,人家会限这个。
换上这个套餐之后,我大概也就用了不到半小时,界面就弹出了这样的告警:
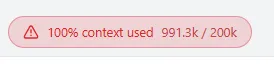
如果只是弹出上面这一个,对话还勉强能用。
但如果同时,页面又跑出下面这么个东东出来,那就完蛋:

对话直接瘫痪。
一看后台日志,直接给你封印住了:
16:41:06 [agent/embedded] embedded run agent end: runId=0a5f7c1a-f195-40aa-a409-1ed06ec86b93 isError=true model=MiniMax-M2.7-highspeed provider=minimax error=⚠️ API rate limit reached. Please try again later.
查看官网,人家确实有对应的限流规则:

超了,就限流,然后就只能等(至少几分钟),尤其是在高峰时间段。
而其实这个时候,我的模型调用次数,也才这么点:
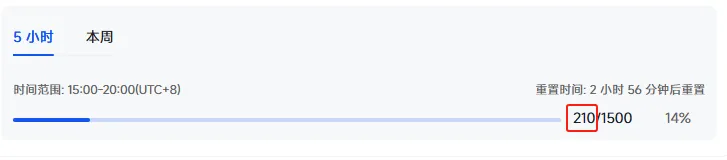
就,很蛋疼(处理长上下文任务的通病)。
这,也许就是贪便宜的后果吧(瞬间开始怀恋之前用 kimi2.5 不限速的日子了)。
3. 效果表现
通过这一天的体验,老实说,我并没有察觉出最新 MiniMax2.7 的所谓惊艳之处(跟之前的 kimi2.5 比)。
该犯的迷糊一样犯——漏掉关键的上下文信息;
该有的毛病也没见减少——昨天新增的页面功能,今天早上优化另一个的时候,就又把昨天新增的给丢了。
一句话总结效果就是(不包含限速这个因素):差强人意吧。
最后
这次给龙虾换模型,纯粹是出于「经济压力」,说实话,我一直都没有把「事情做漂亮」这个目标,完全寄希望在「更牛逼的模型」身上。
在我看来,想要 AI 帮你搞定一个「复杂」的项目,关键还得靠你自己的「掌舵能力」,你不可能通过几句外行的简单描述,就奢望 AI 把事情给你办得妥妥的。
哪里有问题,你要能给它指出来;
哪里不满意,你要会给出原因,以及优化方向。
否则,它就可能乱猜,然后把你的任务搅的一团糟。
你觉得呢?