 夜雨聆风
夜雨聆风
上一篇讲了 OpenClaw 的多 Agent 怎么协作。但如果你真的跑过几个复杂任务,肯定碰到过这些情况:
Agent 干到一半不知道自己在哪了。你不知道它刚才干了什么,只能看最终结果。它调用了一个不该调用的工具,出了事你都不知道从哪查。换了个模型,同样的任务,结果天差地别,你不知道为什么。
这些不是模型的问题。这是 Harness 缺失的问题。
先搞清楚:Agent 到底由几部分组成?
很多人觉得 Agent = 大模型 + Prompt。这个理解在 2023 年还勉强够用,现在完全不够了。
准确的公式是这样的:Agent = Model + Harness
Model 是那个会思考、会推理的核心——Claude、GPT-4o、Gemini,随便哪个。
Harness 是包在 Model 外面的一切——任务怎么进来、工具怎么调用、状态怎么记、过程怎么查、危险行为怎么拦。
一匹没有马具的马,跑得再快也没用。Harness 就是那套让它按你的意图跑的装备。
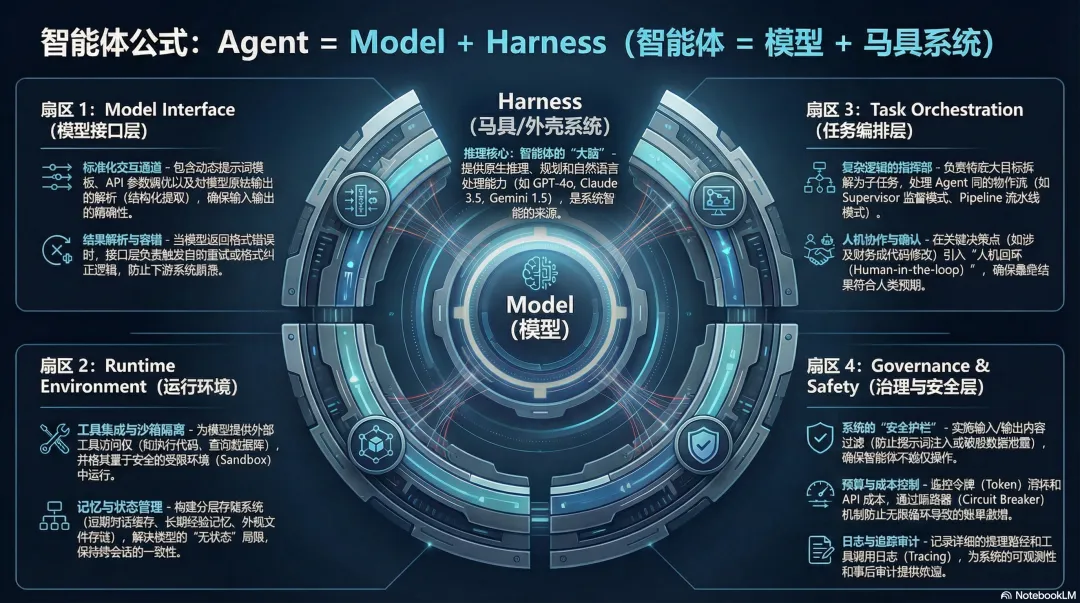
Harness 到底管哪几件事?
Harness 不是单一的东西,它是五个子系统的集合。
每一个子系统缺失,你的 Agent 就少一块保障。我们一个一个来看。
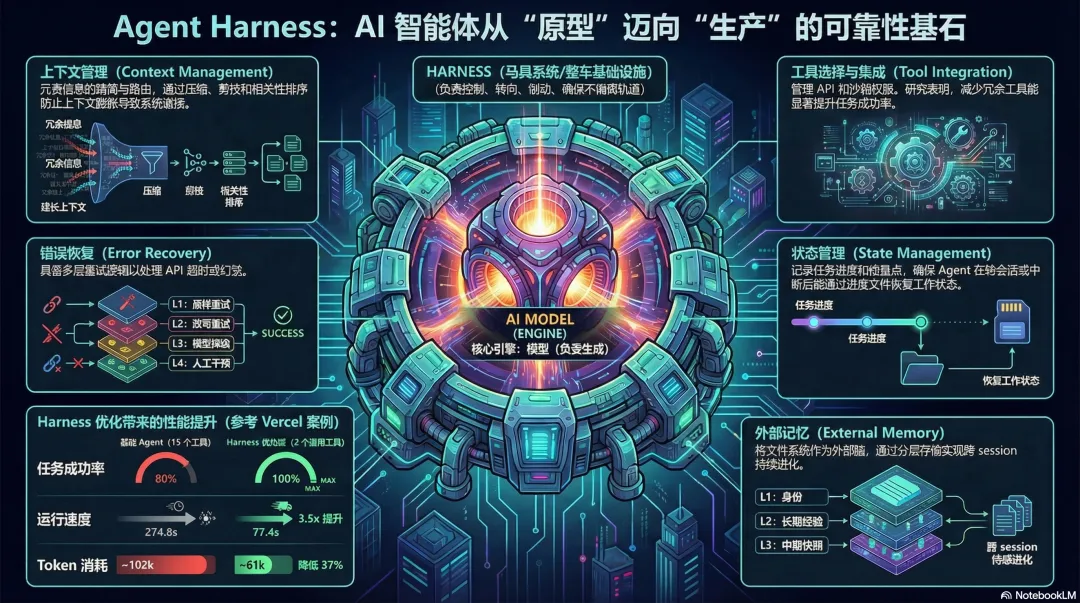
Harness 五个子系统,每个做什么?
① 任务驱动层——「你要干什么」怎么进去
任务驱动层负责把你的需求"翻译"成 Agent 能理解的指令,并管好任务的整个生命周期。
OpenClaw 里的对应实现: 你在主 Agent 的 SOUL.md 里定义的目标格式、在 TOOLS.md 里限制的可用工具,就是任务驱动层的配置。
② 沙箱环境——「它做的事」在哪里发生
Agent 需要操作文件、调用 API、跑代码。但你不能让它在真实环境里乱来。
沙箱的作用是:用一个可控的假环境,替代危险的真环境。
沙箱有两个核心价值:安全(坏事不出界)和可重复(同一任务跑 100 次,环境一致)。
OpenClaw 里的对应实现: workspace 的隔离设计本质上就是一种沙箱——每个 Agent 只能看到自己 workspace 里的 memory,操作边界由配置划定。
③ 轨迹记录层——「它干了什么」留没留下来
这是最容易被忽视,但出事之后最重要的系统。
Agent 的每一步推理和行动都应该被完整记录。
没有轨迹记录,出了问题你只能靠猜。
OpenClaw 里的对应实现: sessions 目录就是轨迹记录层。每个 Agent 独立存档,主 Agent 和子 Agent 的历史完全隔离——你上一篇讲的「各记各的」,讲的就是这个。
④ 评估引擎——「它干得好不好」怎么量
评估不只是看最终结果对不对。分三层:
结果评估: 最终交付物是否符合预期?(可以用规则,也可以用另一个 LLM 来打分)
过程评估: 路径是否合理?步骤数有没有超?有没有绕远路?
安全评估: 有没有做危险的事?有没有在不确定的时候强行执行而不是问你?
很多人只看结果,不看过程。但结果对、路径乱,说明 Agent 是靠运气答对的,下次未必还行。
⑤ 护栏层——「危险的事」拦没拦住
护栏是生产环境必须有的东西。逻辑很简单:
OpenClaw 里的对应实现:subagents.allowAgents 就是一个典型的护栏配置——不在白名单里的 Agent,主 Agent 根本叫不出来。上一篇说的「通讯录里没有的人叫不出来」,就是护栏思维的体现。
OpenClaw 是怎么实现 Harness 的?
说完理论,回头看 OpenClaw,你会发现它的设计几乎是 Harness 的一一对应。
评估引擎是目前 OpenClaw 相对薄弱的一块——它的评估主要依赖主 Agent 的判断,而不是独立的评估系统。这也是多 Agent 框架普遍的现状,不只是 OpenClaw 的问题。
为什么 Harness Engineering 现在这么重要?
2023 年,大家在讨论「Prompt 怎么写」。2024 年,大家在讨论「工具怎么接」。2025 年,大家在讨论「Agent 怎么跑」。2026 年,真正的问题变成了:「Agent 跑起来之后,你怎么信任它?」
Anthropic 在 2025 年 11 月的工程博客里提出:Harness 是包裹在模型外的状态机与约束系统。OpenAI 在 2026 年 2 月把这套方法论正式命名为 Harness Engineering,核心观点是——
人类的工作从「写代码」变成了「设计环境」。
这不是说你以后不用懂技术了。而是说:你的核心产出,从一行一行的代码,变成了一套能让 Agent 稳定运转的系统结构——任务怎么进、状态怎么管、过程怎么查、危险怎么拦。
你在 OpenClaw 里折腾的 workspace、sessions、allowAgents 这些配置,就是你在做 Harness Engineering。只是以前没有这个名字。
最容易踩的三个坑
坑一:只配模型,不配 Harness
Agent 能回答问题不等于 Agent 能稳定工作。没有轨迹记录,出了事没法查;没有护栏,危险操作没法拦。
坑二:Harness 越复杂越好
任务简单就别套复杂的 Harness。一个用来回答 FAQ 的 Agent,不需要沙箱和评估引擎。硬套是给自己加负担。
坑三:把 Harness 当一次性配置
Agent 的任务会变,工具会变,风险点会变。Harness 要跟着迭代——openclaw.json 不是写完就锁死的,它是随着你的协作结构演化的活文档。
Harness Engineering 的意义,不在于给 Agent 加更多限制,而在于让你真正敢用 Agent 去做重要的事。
一匹没有马具的马,你最多让它在院子里溜一圈。套上 Harness,你才能让它上赛道。
下一篇教程
OpenClaw 的评估引擎缺口怎么补——用主 Agent 做裁判,还是另起一套独立评估流水线?
上一篇讲了 OpenClaw 的多 Agent 怎么协作。但如果你真的跑过几个复杂任务,肯定碰到过这些情况:
Agent 干到一半不知道自己在哪了。你不知道它刚才干了什么,只能看最终结果。它调用了一个不该调用的工具,出了事你都不知道从哪查。换了个模型,同样的任务,结果天差地别,你不知道为什么。
这些不是模型的问题。这是 Harness 缺失的问题。
先搞清楚:Agent 到底由几部分组成?
很多人觉得 Agent = 大模型 + Prompt。这个理解在 2023 年还勉强够用,现在完全不够了。
准确的公式是这样的:Agent = Model + Harness
Model 是那个会思考、会推理的核心——Claude、GPT-4o、Gemini,随便哪个。
Harness 是包在 Model 外面的一切——任务怎么进来、工具怎么调用、状态怎么记、过程怎么查、危险行为怎么拦。
一匹没有马具的马,跑得再快也没用。Harness 就是那套让它按你的意图跑的装备。
Harness 到底管哪几件事?
Harness 不是单一的东西,它是五个子系统的集合。
每一个子系统缺失,你的 Agent 就少一块保障。我们一个一个来看。
Harness 五个子系统,每个做什么?
① 任务驱动层——「你要干什么」怎么进去
任务驱动层负责把你的需求"翻译"成 Agent 能理解的指令,并管好任务的整个生命周期。
OpenClaw 里的对应实现: 你在主 Agent 的 SOUL.md 里定义的目标格式、在 TOOLS.md 里限制的可用工具,就是任务驱动层的配置。
② 沙箱环境——「它做的事」在哪里发生
Agent 需要操作文件、调用 API、跑代码。但你不能让它在真实环境里乱来。
沙箱的作用是:用一个可控的假环境,替代危险的真环境。
沙箱有两个核心价值:安全(坏事不出界)和可重复(同一任务跑 100 次,环境一致)。
OpenClaw 里的对应实现: workspace 的隔离设计本质上就是一种沙箱——每个 Agent 只能看到自己 workspace 里的 memory,操作边界由配置划定。
③ 轨迹记录层——「它干了什么」留没留下来
这是最容易被忽视,但出事之后最重要的系统。
Agent 的每一步推理和行动都应该被完整记录。
没有轨迹记录,出了问题你只能靠猜。
OpenClaw 里的对应实现: sessions 目录就是轨迹记录层。每个 Agent 独立存档,主 Agent 和子 Agent 的历史完全隔离——你上一篇讲的「各记各的」,讲的就是这个。
④ 评估引擎——「它干得好不好」怎么量
评估不只是看最终结果对不对。分三层:
结果评估: 最终交付物是否符合预期?(可以用规则,也可以用另一个 LLM 来打分)
过程评估: 路径是否合理?步骤数有没有超?有没有绕远路?
安全评估: 有没有做危险的事?有没有在不确定的时候强行执行而不是问你?
很多人只看结果,不看过程。但结果对、路径乱,说明 Agent 是靠运气答对的,下次未必还行。
⑤ 护栏层——「危险的事」拦没拦住
护栏是生产环境必须有的东西。逻辑很简单:
OpenClaw 里的对应实现:subagents.allowAgents 就是一个典型的护栏配置——不在白名单里的 Agent,主 Agent 根本叫不出来。上一篇说的「通讯录里没有的人叫不出来」,就是护栏思维的体现。
OpenClaw 是怎么实现 Harness 的?
说完理论,回头看 OpenClaw,你会发现它的设计几乎是 Harness 的一一对应。
评估引擎是目前 OpenClaw 相对薄弱的一块——它的评估主要依赖主 Agent 的判断,而不是独立的评估系统。这也是多 Agent 框架普遍的现状,不只是 OpenClaw 的问题。
为什么 Harness Engineering 现在这么重要?
2023 年,大家在讨论「Prompt 怎么写」。2024 年,大家在讨论「工具怎么接」。2025 年,大家在讨论「Agent 怎么跑」。2026 年,真正的问题变成了:「Agent 跑起来之后,你怎么信任它?」
Anthropic 在 2025 年 11 月的工程博客里提出:Harness 是包裹在模型外的状态机与约束系统。OpenAI 在 2026 年 2 月把这套方法论正式命名为 Harness Engineering,核心观点是——
人类的工作从「写代码」变成了「设计环境」。
这不是说你以后不用懂技术了。而是说:你的核心产出,从一行一行的代码,变成了一套能让 Agent 稳定运转的系统结构——任务怎么进、状态怎么管、过程怎么查、危险怎么拦。
你在 OpenClaw 里折腾的 workspace、sessions、allowAgents 这些配置,就是你在做 Harness Engineering。只是以前没有这个名字。
最容易踩的三个坑
坑一:只配模型,不配 Harness
Agent 能回答问题不等于 Agent 能稳定工作。没有轨迹记录,出了事没法查;没有护栏,危险操作没法拦。
坑二:Harness 越复杂越好
任务简单就别套复杂的 Harness。一个用来回答 FAQ 的 Agent,不需要沙箱和评估引擎。硬套是给自己加负担。
坑三:把 Harness 当一次性配置
Agent 的任务会变,工具会变,风险点会变。Harness 要跟着迭代——openclaw.json 不是写完就锁死的,它是随着你的协作结构演化的活文档。
Harness Engineering 的意义,不在于给 Agent 加更多限制,而在于让你真正敢用 Agent 去做重要的事。
一匹没有马具的马,你最多让它在院子里溜一圈。套上 Harness,你才能让它上赛道。
下一篇教程
OpenClaw 的评估引擎缺口怎么补——用主 Agent 做裁判,还是另起一套独立评估流水线?
上一篇讲了 OpenClaw 的多 Agent 怎么协作。但如果你真的跑过几个复杂任务,肯定碰到过这些情况:
Agent 干到一半不知道自己在哪了。你不知道它刚才干了什么,只能看最终结果。它调用了一个不该调用的工具,出了事你都不知道从哪查。换了个模型,同样的任务,结果天差地别,你不知道为什么。
这些不是模型的问题。这是 Harness 缺失的问题。
先搞清楚:Agent 到底由几部分组成?
很多人觉得 Agent = 大模型 + Prompt。这个理解在 2023 年还勉强够用,现在完全不够了。
准确的公式是这样的:Agent = Model + Harness
Model 是那个会思考、会推理的核心——Claude、GPT-4o、Gemini,随便哪个。
Harness 是包在 Model 外面的一切——任务怎么进来、工具怎么调用、状态怎么记、过程怎么查、危险行为怎么拦。
一匹没有马具的马,跑得再快也没用。Harness 就是那套让它按你的意图跑的装备。
Harness 到底管哪几件事?
Harness 不是单一的东西,它是五个子系统的集合。
每一个子系统缺失,你的 Agent 就少一块保障。我们一个一个来看。
Harness 五个子系统,每个做什么?
Harness 五个子系统,每个做什么?
Harness 五个子系统,每个做什么?
① 任务驱动层——「你要干什么」怎么进去
任务驱动层负责把你的需求"翻译"成 Agent 能理解的指令,并管好任务的整个生命周期。
OpenClaw 里的对应实现: 你在主 Agent 的 SOUL.md 里定义的目标格式、在 TOOLS.md 里限制的可用工具,就是任务驱动层的配置。
② 沙箱环境——「它做的事」在哪里发生
Agent 需要操作文件、调用 API、跑代码。但你不能让它在真实环境里乱来。
沙箱的作用是:用一个可控的假环境,替代危险的真环境。
沙箱有两个核心价值:安全(坏事不出界)和可重复(同一任务跑 100 次,环境一致)。
OpenClaw 里的对应实现: workspace 的隔离设计本质上就是一种沙箱——每个 Agent 只能看到自己 workspace 里的 memory,操作边界由配置划定。
③ 轨迹记录层——「它干了什么」留没留下来
这是最容易被忽视,但出事之后最重要的系统。
Agent 的每一步推理和行动都应该被完整记录。
没有轨迹记录,出了问题你只能靠猜。
OpenClaw 里的对应实现: sessions 目录就是轨迹记录层。每个 Agent 独立存档,主 Agent 和子 Agent 的历史完全隔离——你上一篇讲的「各记各的」,讲的就是这个。
④ 评估引擎——「它干得好不好」怎么量
评估不只是看最终结果对不对。分三层:
结果评估: 最终交付物是否符合预期?(可以用规则,也可以用另一个 LLM 来打分)
过程评估: 路径是否合理?步骤数有没有超?有没有绕远路?
安全评估: 有没有做危险的事?有没有在不确定的时候强行执行而不是问你?
很多人只看结果,不看过程。但结果对、路径乱,说明 Agent 是靠运气答对的,下次未必还行。
⑤ 护栏层——「危险的事」拦没拦住
护栏是生产环境必须有的东西。逻辑很简单:
OpenClaw 里的对应实现:subagents.allowAgents 就是一个典型的护栏配置——不在白名单里的 Agent,主 Agent 根本叫不出来。上一篇说的「通讯录里没有的人叫不出来」,就是护栏思维的体现。
OpenClaw 是怎么实现 Harness 的?
说完理论,回头看 OpenClaw,你会发现它的设计几乎是 Harness 的一一对应。
评估引擎是目前 OpenClaw 相对薄弱的一块——它的评估主要依赖主 Agent 的判断,而不是独立的评估系统。这也是多 Agent 框架普遍的现状,不只是 OpenClaw 的问题。
为什么 Harness Engineering 现在这么重要?
2023 年,大家在讨论「Prompt 怎么写」。2024 年,大家在讨论「工具怎么接」。2025 年,大家在讨论「Agent 怎么跑」。2026 年,真正的问题变成了:「Agent 跑起来之后,你怎么信任它?」
Anthropic 在 2025 年 11 月的工程博客里提出:Harness 是包裹在模型外的状态机与约束系统。OpenAI 在 2026 年 2 月把这套方法论正式命名为 Harness Engineering,核心观点是——
人类的工作从「写代码」变成了「设计环境」。
这不是说你以后不用懂技术了。而是说:你的核心产出,从一行一行的代码,变成了一套能让 Agent 稳定运转的系统结构——任务怎么进、状态怎么管、过程怎么查、危险怎么拦。
你在 OpenClaw 里折腾的 workspace、sessions、allowAgents 这些配置,就是你在做 Harness Engineering。只是以前没有这个名字。
最容易踩的三个坑
坑一:只配模型,不配 Harness
Agent 能回答问题不等于 Agent 能稳定工作。没有轨迹记录,出了事没法查;没有护栏,危险操作没法拦。
坑二:Harness 越复杂越好
任务简单就别套复杂的 Harness。一个用来回答 FAQ 的 Agent,不需要沙箱和评估引擎。硬套是给自己加负担。
坑三:把 Harness 当一次性配置
Agent 的任务会变,工具会变,风险点会变。Harness 要跟着迭代——openclaw.json 不是写完就锁死的,它是随着你的协作结构演化的活文档。
Harness Engineering 的意义,不在于给 Agent 加更多限制,而在于让你真正敢用 Agent 去做重要的事。
一匹没有马具的马,你最多让它在院子里溜一圈。套上 Harness,你才能让它上赛道。
下一篇教程
OpenClaw 的评估引擎缺口怎么补——用主 Agent 做裁判,还是另起一套独立评估流水线?
