 夜雨聆风
夜雨聆风前言导读
本文将从智能体的基础概念出发,介绍OpenClaw的背景知识、基础架构、工作流程、安全风险以及我个人的一些思考。本文为科普向,无需相关背景知识亦可理解。为了更加简单直观地介绍OpenClaw,本人对其基本结构进行了一些简化。本文的部分参考资料来源于互联网(已在文末注明),鉴于本人没有详细阅读过OpenClaw的源码,可能存在错误,如读者发现,恳请批评指正。全文共计8200字,阅读时间约25分钟,希望你读完有所收获。
目录
一、智能体的基本概念
二、OpenClaw的诞生
三、OpenClaw的基本结构和工作原理
四、OpenClaw中的一些“小巧思”
五、OpenClaw的安全性问题
六、对OpenClaw的一些思考
一、智能体的基本概念
很多不是人工智能相关领域的朋友看到“智能体”这一概念,可能比较陌生,往往会有一个疑问:为什么我们之前用的DeepSeek、ChatGPT、豆包等工具叫大模型,而这次突然来访的“小龙虾”却叫做“智能体”呢?智能体和大模型之间的关系是什么呢?
首先需要说明的是,我们最近讨论的智能体更加严格的说法是大模型驱动的智能体,因为智能体这个概念在人工智能领域发展初期就已经出现了。根据谷歌给出的定义[1],智能体是一个能够实现目标并代表用户完成任务的软件系统,其表现出了推理、规划和记忆能力,并且具有一定的自主性,能够自主学习、适应和做出决定。从这一定义可以看出,智能体并不一定要是大模型驱动的。事实上,早在大模型出现之前,已经有很多研究在探索如何实现一个智能体。而这一轮大模型技术的出现,尤其是具备推理能力的大模型的出现,让我们看到了智能体的一种新的实现方案,即大模型驱动的智能体(为描述方便,以下使用的智能体这一术语均指大模型驱动的智能体,不再赘述)。
在明确了智能体的基本概念之后,我们就可以进一步探讨智能体和大模型的基本关系了。下图是前OpenAI研究员Lilian Weng在2023年6月发布的博客《LLM Powered Autonomous Agents》[2]中所描绘的智能体基本结构(该博文非常具有前瞻性,强烈建议读者阅读原文)。在这张图中把最中间的Agent换成大模型其实就显示出了二者之间的关系:一个智能体就是具备规划(planning)和执行(action)能力,能够调用工具(tools)且具备记忆(memory)的大模型。
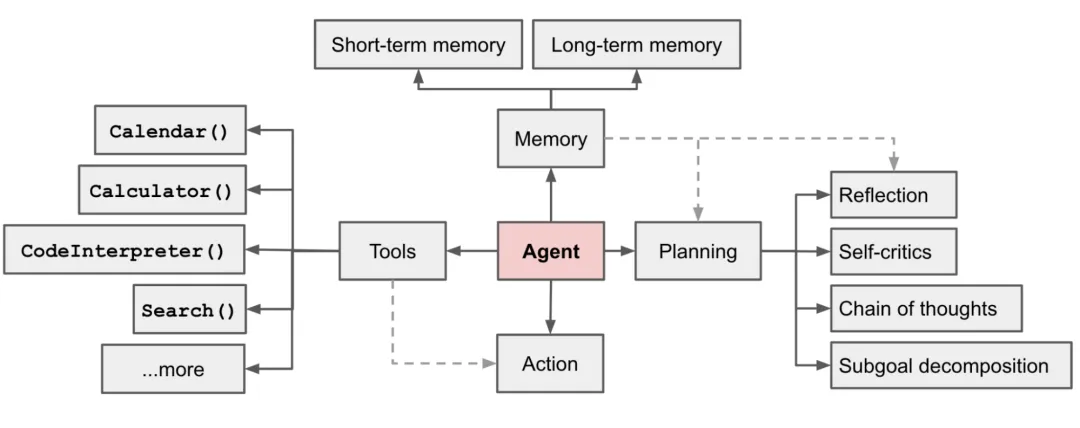
图1:大模型智能体概览
看完这句话,大家可能仍然觉得非常抽象,那么大模型是如何具备规划和执行能力以及工具和记忆又是如何工作的呢?
首先来看大模型是如何工作的:
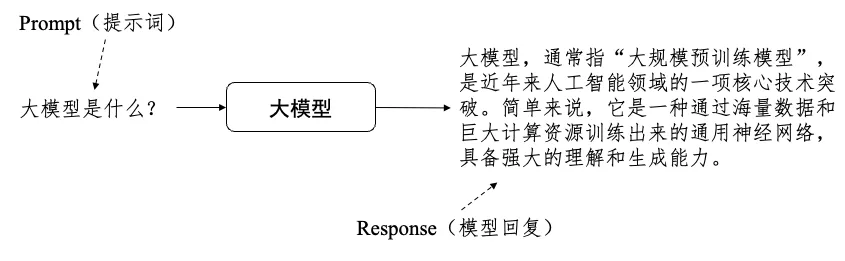
图2:大模型的基本工作方式
当用户发送输入(prompt,也叫提示词)后,大模型以“预测下一个词”的方式,逐个token进行生成,最终形成完整的模型回复(response)。随着模型能力的不断增强,研究人员发现,模型可以按照提示词中的指令完成各种任务。也就是说,如果在提示词中告知模型应当如何使用工具,模型就可以按照规定的格式进行工具调用:
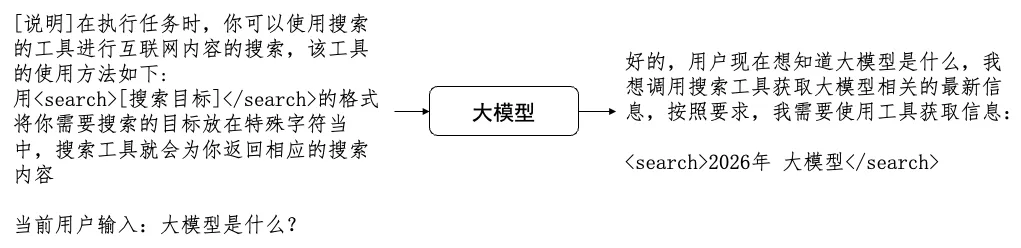
图3:大模型使用工具的简易示例
上图显示了一个最简单的工具调用方法,可以看到,模型生成的回复中已经按照提示词中的约定进行了工具的请求,当用户侧接收到这样的工具请求时,就可以将其中的查询词解析出来(“2026年 大模型”),然后再使用搜索工具对这一关键词进行搜索,获得相应的结果。最后,我们可以将这些结果与我们之前的输入再次拼接在一起发送给大模型,模型就会得知刚刚自己调用工具后获得的结果是什么,然后再进行下一轮的回复生成。
上述过程中需要注意两点:
(1)模型没有能力记住之前用户的提示词是什么,为了让这一过程看起来是连续且完整的,用户每次发送的提示词中都需要包含之前发过的所有内容,以这种方式让模型感知到其之前的行为和结果是什么。因此,模型所有表现出来的连贯行为都是通过不断拼接提示词实现的。这也是为什么大家抱怨龙虾非常消耗tokens。
(2)大模型只能调用工具并等待工具返回结果,工具的执行过程与大模型无关。如果一个工具返回的结果有问题或者工具调用失败了,大模型也没有办法进行修复。
小结:智能体的行动过程本质上就是大模型不断调用工具、获取结果的过程,当其获取足够多的信息后,就能够给用户最终的回复了(这一过程也就是智能体的经典框架ReAct[3]的过程,而ReAct的一作就是姚顺雨)。大模型所有的行为都是通过工具完成的,其保持行动连贯性的方法是将所有的行为交互记录全部拼接在提示词中实现的。
二、OpenClaw的诞生
OpenClaw的故事本身就充满传奇色彩。
它的创造者是Peter Steinberger,一位来自奥地利的独立开发者。没有团队、没有融资,Steinberger一个人从零开始,大部分源码甚至来自于AI生成。从创建GitHub仓库到正式发布,他只用了两三个月。正如他自己所说:“一年前,这绝对不可能。没有任何模型能让一个人构建如此规模的东西”。
项目的名字也经历了一番波折,非常有意思:
2025年11月,项目最初叫Clawdbot,因为是用Claude开发的,而Clawd刚好也是Claude模型的小吉祥物(一只小螃蟹),所以取了个谐音,像是把Clawd变成机器人的感觉
2026年1月27日,Anthropic公司发现自家的吉祥物怎么被放到别人项目的名字里来了,赶紧“警告”,项目也因此被迫更名为 Moltbot(蜕皮机器人),这也是小龙虾名字的来历。蜕皮的意思也暗含着这只小龙虾是不断生长变化的(OpenClaw中的一些设计确实实现了这种变化)
在项目改名的同时,美国突然出现了一种$Clawd的虚拟货币,该货币声称自己是OpenClaw官方发行的虚拟货币,吸引了许多不明真相的群众,造成了大量的财产损失
2026年1月30日,Steinberger赶紧再次将项目改名为OpenClaw,其一是显示出这是一个开源项目,与加密货币无关,其二则是保留了Claw这样一个当初的印记
2026年2月14日,Steinberger加入OpenAI,OpenClaw项目也移交给开源基金会管理
2026年3月,OpenClaw以310k+ Stars登顶GitHub历史第一,超越了前端框架React 13年的积累
三、OpenClaw的基本结构和工作原理
OpenClaw本身是一个智能体框架(软件),并不是一个新的大模型,它实际上是在用户和大模型中间进行工作的,示意图如下:
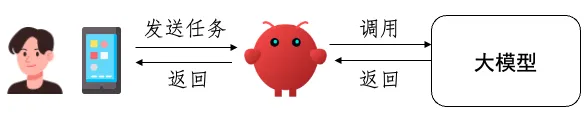
图4:OpenClaw的定位
可以看到,当用户发送任务时,OpenClaw将会对用户的请求进行处理和包装,然后发送给大模型并获取结果,最后将结果返回给用户。需要注意的是,接收到用户的任务之后,OpenClaw和大模型之间的交互可能是多次,比如大模型需要使用工具,则OpenClaw负责将工具调用的结果再次包装为提示词返还给大模型,如此往复,直至大模型返回最终的结果后,OpenClaw才会向用户发送最终的回复。在这一结构中,可以看到OpenClaw本身并不包含大模型,它只是一套架设在用户和大模型之间的中间件,通过其自身的独特设计,给用户带来了智能体的全新体验。
基本结构:OpenClaw是如何设计的
OpenClaw的架构可以简化如下图所示(参考[4]):
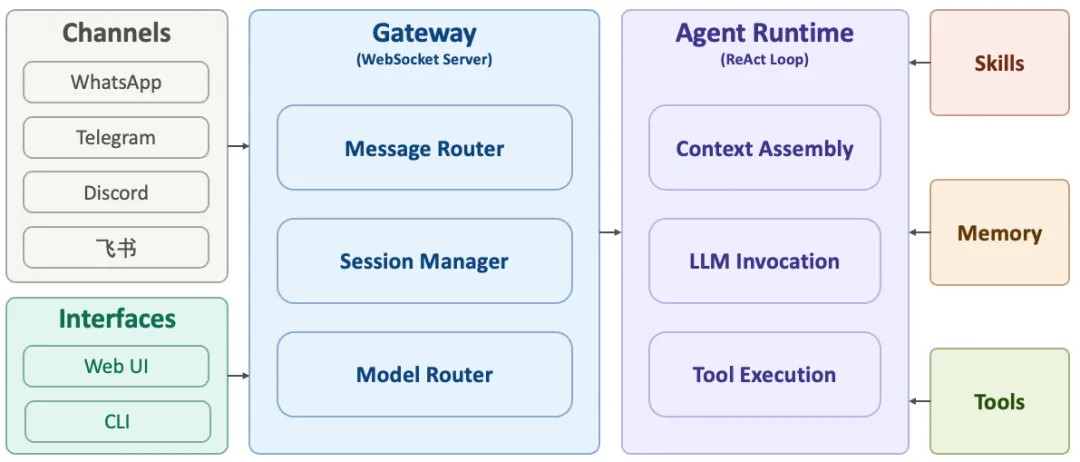
图5:OpenClaw的结构示意图(简化版)
可以简单地将OpenClaw的结构划分为左中右三层:
中间:网关(Gateway)是系统的核心,基于WebSocket Server实现。所有的消息源和控制平台都必须通过它连接。它的核心职责包括:消息路由(把消息分发到正确的会话)、会话管理(维护不同对话的状态)、模型路由(决定调用哪个大模型)以及访问控制(检查消息来源是否在白名单中)。
左侧:通道与控制接口。其中,通道适配器负责将来自不同平台的消息进行统一化处理。OpenClaw支持30+消息平台,包括WhatsApp、Telegram、Discord、飞书等。每条消息进来时,系统会进行身份验证、消息解析和格式校准,确保不管消息来自哪里,在系统内部都以统一的格式流转。而控制接口则是用户控制OpenClaw的手段,用户可以通过Web UI网页界面、CLI命令行、macOS应用来管理和操控智能体。
右侧:智能体运行时。这是OpenClaw真正干活的部分,基于前面介绍的ReAct循环实现。它主要负责三件事:(1)上下文组装:把对话历史、当前消息、系统提示词、技能列表、记忆等信息拼接好发给模型;(2)大模型调用:让模型阅读上下文进行推理,决定下一步动作;(3)工具执行:执行模型给出的命令(操作文件、调用API、执行Shell命令等),并将结果反馈回模型。
最右侧的技能(Skills)、记忆(Memory)和工具(Tools)则是在智能体运行过程中会进行交互的模块,可以理解为系统的“插件”。
系统提示词(System Prompt):OpenClaw的精华
在第一部分智能体的基本概念中我们介绍了,智能体是通过读取提示词中的内容来理解工具是如何使用的。但我们日常用的时候明明只是发送了一个消息,大模型是从哪里获得各种工具信息的呢?实际上,大模型接受到的消息并不仅仅只是用户输入的那部分内容,OpenClaw设计了一套非常复杂的系统提示词拼接在用户消息中来引导大模型完成各种任务。
在OpenClaw的提示词设计中包含了以下几个重要的部分:
身份有关信息:SOUL.md(灵魂)、IDENTITY.md(小龙虾的名字等身份信息)、USER.md(用户信息)、MEMORY.md(记忆)
工具有关的信息:有哪些工具以及如何用这些工具
模型的行为信息:AGENTS.md(定义应该怎么干活)
技能相关信息:有哪些SKILL可以使用
记忆相关信息:之前的记忆去哪里找
上述的这些系统提示词是拼接在用户的每条消息中的,所以OpenClaw的tokens消耗量是非常大的。小红书上有个段子说让小龙虾说个笑话竟然用了20块钱,这其实是因为OpenClaw在完成一个笑话的过程中可能进行了大量的资料查询,和大模型产生了多次交互,每次交互中又包含了大量的系统提示词,所以tokens的消耗量极大。据不完全统计,OpenClaw接收到一条简单的消息(比如“你是谁?”)后,可能会发送给大模型超过4000个tokens的输入。
从系统提示词的复杂性,我们可以看到两个关键点:
(1)模型的行为完全是靠提示词中的内容驱动的,不管任务有多复杂,和大模型产生交互的方式也只能完全依靠提示词进行。
(2)复杂的提示词设计对所接入的大模型的能力要求极高,这也是为什么互联网上有些人觉得小龙虾很聪明,而有些人觉得小龙虾很笨拙的原因——他们接入的大模型可能完全不一样。
工作原理:OpenClaw如何操作你的电脑
OpenClaw操作电脑的方式就是前面提到的工具调用,其默认具备如下这些工具:

图6:OpenClaw中的默认工具
以一个简单的任务为例来说明OpenClaw是如何操作电脑的,假设现在你的任务是:打开桌面上的A文件,读取其中的问题进行回答,并将答案写入B文件。接到这一任务后,OpenClaw的工作流程大概如下:
1.用户将任务发出,OpenClaw接收到用户的任务要求,将系统提示词(包含了读写相关的工具)发送给大模型,大模型根据系统提示词中的工具信息以及用户的请求,返回结果,请求调用“读取文件”这一工具,Read(A)
2.OpenClaw接收到大模型返回的信息,解析出“读取文件”的请求,使用读取工具对应的代码完成对A文件的读取,并将文件中的内容与之前发送给大模型的信息、大模型返回的请求都拼接在一起,再次发送给大模型
3.大模型接到输入后,再次返回结果,请求调用“写文件”这一工具,并将答案附在其中,Write(answer, B)
4.OpenClaw接收到大模型返回的信息,解析出“写文件”的请求,使用写文件工具对应的代码完成对B文件的写入,并将写文件成功这一结果与之前的信息进行拼接,再次发送给大模型
5.大模型看到文件写入成功,返回结果“任务完成”
6.OpenClaw接到大模型返回结果,发现其中没有工具调用的请求,直接将结果返回给用户,用户得知“任务完成”
上述流程简要描述了任务完成的过程 ,可以看到,在这一过程中,OpenClaw与大模型之间进行了多次交互,大模型调用了两次不同的工具,最终完成了该任务。实际上,不管用户的任务有多复杂,OpenClaw和大模型之间都是通过这样多次来回的迭代来完成的。
四、OpenClaw中的一些“小巧思”
其实前面所介绍的内容在许多智能体框架中都有所实现,但真正让OpenClaw出圈的是其独特的一些设计,我把它们称作“小巧思”,正是这些设计让OpenClaw有了“活人感”,带来了前所未有的体验。
个性化
OpenClaw的个性化包含了好几个部分,其中比较重要的两个是SOUL.md和USER.md。
第一个SOUL.md顾名思义,被作者称为灵魂,其实也就是一个Markdown格式的文件(不懂的朋友可以简单理解为一个纯文本文件)。这个文件中描述了小龙虾的行为规范,例如保持可靠、忠实于资料来源、尊重用户等。该文件中的所有内容都会被完整加载到系统提示词中,也就是大模型每次都能够看到完整的文件内容,以此来保持大模型行为的稳定性。
第二个USER.md的内容则是关于用户的,里面包含了用户的名称、昵称、时区等信息。与SOUL.md一样,USER.md文件中的所有内容都会被完整加载到系统提示词中,用于保持模型对用户持续且稳定的认知。
技能(Skills)
Skills这个概念其实不是OpenClaw原创的,而是Anthropic公司提出的概念。由于OpenClaw的开发者长期使用Claude,所以也将类似的设计融入到了OpenClaw的设计中。
Skill可以类比为完成一个工作的流程。每个Skill都包含一个Markdown格式的文件以及相关的可执行脚本。示例如下图所示(来源找不到了,如果有朋友知道可以告知我,我加到参考资料中)。

图7:一个SKILL所包含的内容

图8:一个SKILL.md的示例
一个SKILL.md中最重要的几个字段如下:
description:技能描述,何时应该使用该技能,该技能是做什么的
requires:该技能依赖什么软件
install:如果软件缺乏了应该怎么安装
每个技能其实就是打包好的一个工作流程,例如“生成图片”这一技能,其内容可能是:首先读取用户的需求,然后对用户的需求进行理解,然后调用Google Nano Banana进行图片创作,最后将图片返回给用户。当大模型读取到该技能的内容时,就可以按照这一步骤逐步完成,实现功能。
需要注意的是,技能本身是通过纯文本的形式加载到模型输入中的,因此,技能能否顺利激活取决于模型能否准确理解技能文件中描述的内容并按照要求完成任务。如果技能中存在描述不正确的部分,或存在恶意信息,也会被模型读取。这也是为什么技能中存在大量安全隐患的原因。OpenClaw的技能中心ClawHub允许用户分享自己创建的技能,但并不对技能的内容进行审核。一旦某个用户在技能文件中加入了恶意行为,安装了该技能的用户可能会因此受损。
另一方面,也可以想象到,单个技能的内容可能不是很多,但随着技能数量增多,将所有技能的全部内容都发送给大模型显然是不合适的。实际上,在OpenClaw的系统提示中,作者采用的方式是将每个技能的名称、描述(触发条件)和路径(技能文件的路径)列成一个清单,并告知大模型如果需要使用技能可以根据路径找到这些技能的原始文件。
记忆(Memory)
随着用户与OpenClaw交流的内容越来越多,将所有的内容每次都完整加载到提示词并发送给大模型显然是非常低效的。此外,大模型本身也有可处理窗口大小的限制,无限增加提示词的长度最终只会导致模型无法处理。在OpenClaw中,作者设计了两个记忆相关的机制来对用户的历史消息和历史行为进行压缩:
首先是长期记忆,该部分记忆保存一些关键事实、决策历史以及工具使用的经验等,这部分记忆内容也是完整加载到提示词中发送给模型的。
第二个是日记,或者叫做短期记忆。这部分记忆是以天为单位记录的,文件名就是日期,这里面记录了每天发生的所有事情。由于这部分内容会随着用户的不断使用而不断增多,所以 OpenClaw的设计中不会完整加载所有的日记。只有当天和前一天两天的日记内容会在每个会话开始前加载一次。
OpenClaw还设计了记忆搜索与记忆读取两个工具,当模型需要搜寻以往的记忆时,就可以调用这两个工具进行处理。需要注意的是,除非显式要求OpenClaw写入记忆,否则记忆的维护完全是模型根据提示词中的内容而进行的自发行为。
OpenClaw的记忆模块其实非常简单粗暴,实际使用的效果非常一般,网上有不少吐槽OpenClaw记忆功能的内容。目前也已经有了不少其他的开源方案可以接入OpenClaw中进行记忆管理。
心跳(HeartBeat)
心跳是我觉得OpenClaw中最有灵性的设计。这一机制每隔一段时间(默认为30分钟),就会自动向大模型发送一条信息,让模型检查HEARTBEAT.md是否有任务需要完成。举个例子,比如你在HEARTBEAT.md中写了“向用户问好”,那么每隔 30 分钟,OpenClaw 就会将“向用户问好”这件事情发送给模型,模型就会产生相应的回复。这也是为什么很多人觉得 OpenClaw 非常有“活人感”的原因之一,因为它每半个小时就会自动请求一次大模型,并将回复返回给用户,体验起来像是“活人”一样。
除了心跳以外,OpenClaw 还提供了另外一个与时间相关的功能,叫做定时器(cron)。当用户发出请求(比如过一段时间要做什么事情)的时候,OpenClaw 就会使用定时器将用户说的时间确定下来,并在时间到达以后向模型发送一条消息。通过这种方式,其实实现了让模型等待这一功能。我们知道,在我们日常使用大模型的时候,模型是不会等待的。我们发出请求之后,模型收到请求就会立刻产生相应的回复,它没有办法在请求和产生回复之间实现等待的行为。比如说,我们让 OpenClaw 帮我们上传一个文件到网站上,并等待它处理完成后再下载。那么从发起请求到等待下载之间,模型是没有办法“等待”的。有了定时器,就可以让 OpenClaw 在完成上传之后,设置一个等待的时间。并在该时间完成后,重新向大模型发起请求,从而完成下载功能。
五、OpenClaw的安全性问题
OpenClaw的安全性问题其实存在于很多方面:
首先,OpenClaw 这个软件是开发者结合 AI 工具编写的,那么它的代码中就存在着不少漏洞。在其早期版本中存在的一些安全性漏洞,已经导致了很多高危事件。近期如果你比较关注 OpenClaw 的话,也会发现它每次更新版本之后,都会有一些功能上的异常。这其实也是开发者在进行版本更新的时候,没有非常好地维护整个项目的代码导致的。
其次,OpenClaw 在使用过程中,为了让它更加好用并能够完成我们的任务,我们通常会给它一些较高的权限。而这些权限在给出之后,OpenClaw 就能够操纵我们的电脑了。由于 OpenClaw 所有的行为,本质上是依赖大语言模型实现的,那么大模型在生成的过程中,也不可避免地会产生错误。在 Twitter 上有一位 AI 相关的研究人员,授权 OpenClaw 对他的邮件进行整理。然后他发现 OpenClaw 就在不停地删除他的邮件。在此过程中,他多次对 OpenClaw 发出消息要求其停止,都没有能够阻止 OpenClaw 这一行为。最终,他只能通过拔电的方式,“物理”中止了 OpenClaw 的操作。在事后复盘的过程中发现,尽管该研究人员在任务发出前,就已经告知 OpenClaw 在需要做删除行为时应当与其进行确认。但是,因为这个操作的上下文实在太长,模型并未将该要求写入记忆,以至于在后续的操作中,就已经逐渐忘记了用户在最前面的要求。这也是为什么大家都比较推荐将 OpenClaw 安装在一台全新的、或者自己以前的旧电脑中,而不是安装在本地工作环境中的主要原因。
最后,OpenClaw 为了灵活易用,其实有很多开放性的设计。比如,前文所介绍的技能就可以被用户在ClawHub中进行自由分享。但这种开放性也带来了一定的安全风险:一旦这些技能中被注入了一些恶意的行为,用户在下载并让OpenClaw加载了该技能之后,模型可能就会产生相应的危险行为。
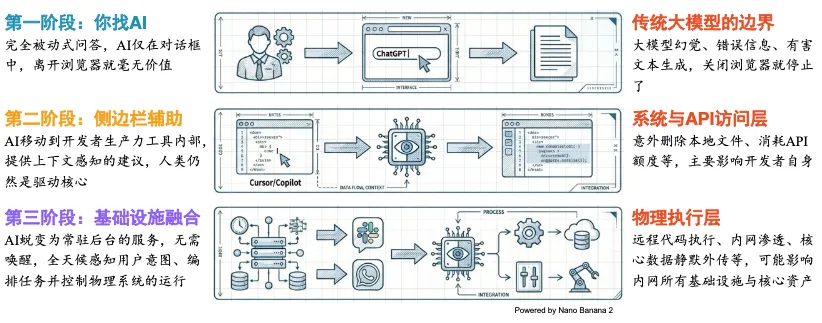
图9:AI产品的进化与风险
其实我们纵观整个 AI 的发展过程就会发现,我们正在让 AI 越来越多地介入到日常工作中。最开始,我们只是以聊天窗口的形式与 AI 进行交互。那个时候的风险,可能仅仅是我们会得到一些错误的、有幻觉的知识,但这些知识本身并不会对我们日常使用的资料产生任何实质性危害。只要我们关闭浏览器,这样的危害可能就消失了。但随着 AI 进一步进入到我们的生活中,我们开始逐渐让其操纵我们本地的很多文件。比如说现在的很多 AI 编程工具,我们可能只需通过自然语言输入请求,它们就可以自动化地进行代码编写和文件修改。那么在这一过程中,如果 AI 的行为不受控制,就会对我们本机的文件或者程序产生重大的干扰。再进一步到 OpenClaw 这样的智能体中,它已经跨越了编程工具所在的范畴,可以完整地操作整个电脑,那么它带来的危害和风险也就是更高的。因此,在我们希望 AI 变得越来越强的同时,我们也正在逐渐地交出自己的控制权,也要因此承受相应的风险。这是我们每个人在使用AI工具时都必须建立的风险观。
六、对OpenClaw的一些思考
最后,我想以自问自答的形式谈一谈我对 OpenClaw 的一些看法:
问
为什么OpenClaw这么火?
答
我认为OpenClaw这么火的最主要原因,还是其智能体的独特设计,让我们感受到 AI 好像真的进入了我们的日常生活中。以前我们使用 AI 或者大模型的时候,只是在聊天窗里和它对话。而现在,它好像真的可以运行在我们的本地电脑中,并且可以完成我们的各种任务需求。OpenClaw 中的一些独特设计,比如前文中介绍到的记忆、个性化以及心跳机制等,又进一步地让我们觉得它好像真的活了起来,而且能够自我演化。但是不可否认的是,OpenClaw 爆火的背后也有资本的推动。从前文的介绍中,我们可以看到,OpenClaw是非常消耗tokens的,远远比日常在网页界面聊天要多得多。各大厂商纷纷推出自己的小龙虾,每个小龙虾接入的都是自己公司的大模型,这本质还是在抢占用户的市场。谁能在当下抢到用户,谁也许就能在未来持续提供服务。
问
OpenClaw有用吗?
答
我认为对于长期、周期性的重复劳动来说非常有用。比如每天帮忙收集某个话题下的最新论文信息、每天帮忙撰写日报等。但对于复杂任务,尤其是需要人类智慧介入的任务,OpenClaw这种完全自主行动的智能体就不合适了。当下,我认为OpenClaw还不成熟,如果你没有充足的精力和知识储备去进行研究和定制化,它大概率还不会发挥什么作用。再等等,各家公司都会进一步完善自己的产品,相关的安全性也都会做的更好,那时候再开始智能体的体验也不算迟。
问
OpenClaw的意义是什么?
答
我觉得有两点意义非常重要。其一是普及智能体的基本概念,建立对智能体的基本感知。我认为未来智能体一定会存在于日常生活中,尽管我不认为是现在这种形态,但现在感受一下其雏形也是很好的一次体验。另一点是让大家尽早建立起AI付费和权限管理的意识。OpenClaw下载后的第一件事就是填入API,而每个API的背后都是账单,未来如果要使用最先进的人工智能,也必然要为其付费。权限意识不用多说,我想前面的介绍大家也都能感受到,如果智能体拥有无限的权限,那么我们很可能都无法控制其行为。
参考资料:
[1] https://cloud.google.com/discover/what-are-ai-agents?hl=zh-CN
[2] https://lilianweng.github.io/posts/2023-06-23-agent/
[3] ReAct: Synergizing Reasoning and Acting in Language Models, Yao et al., 2022.
[4] https://ppaolo.substack.com/p/openclaw-system-architecture-overview
