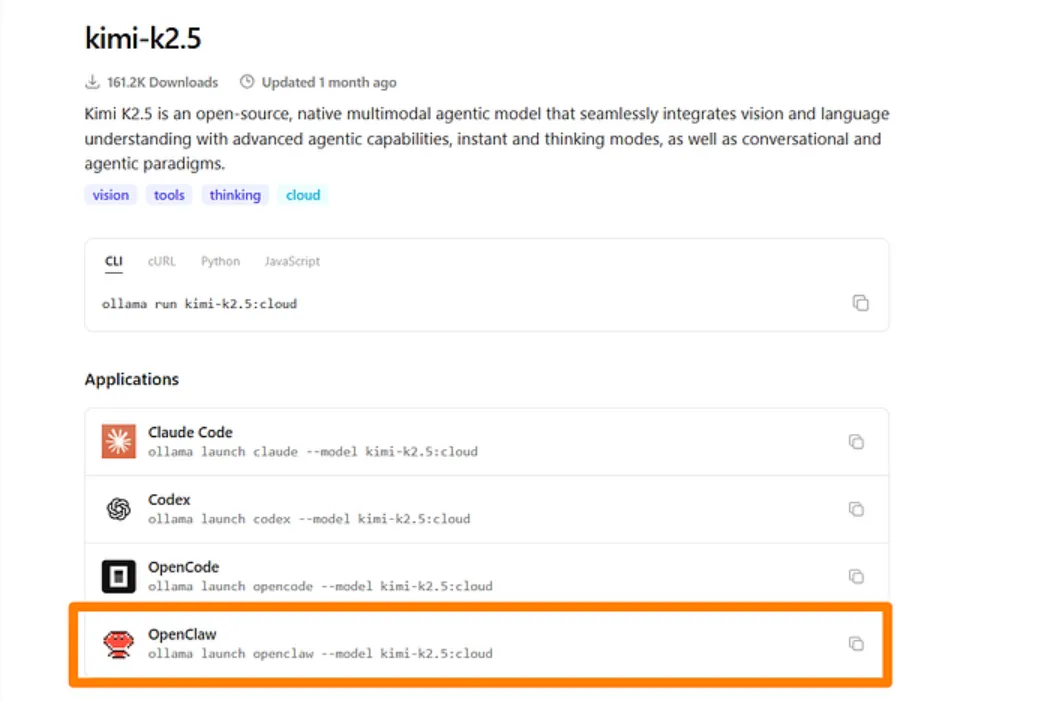
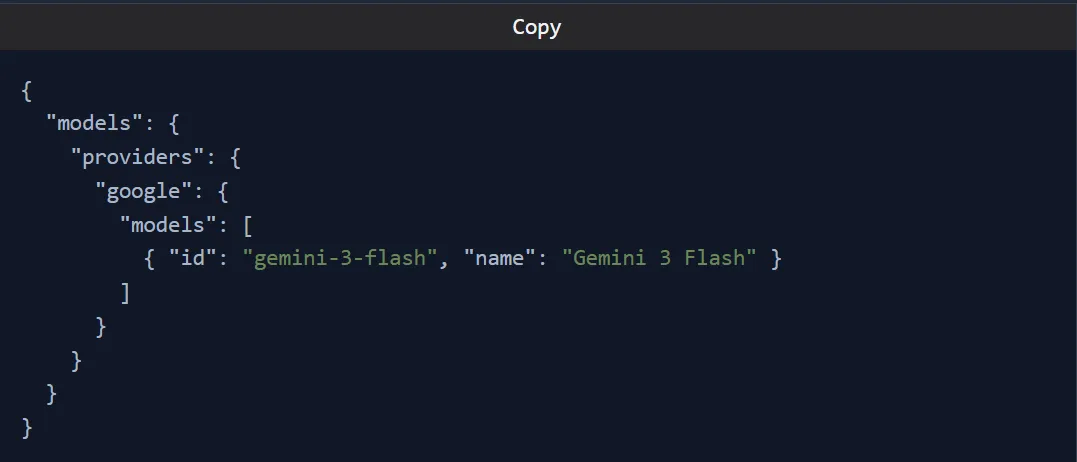
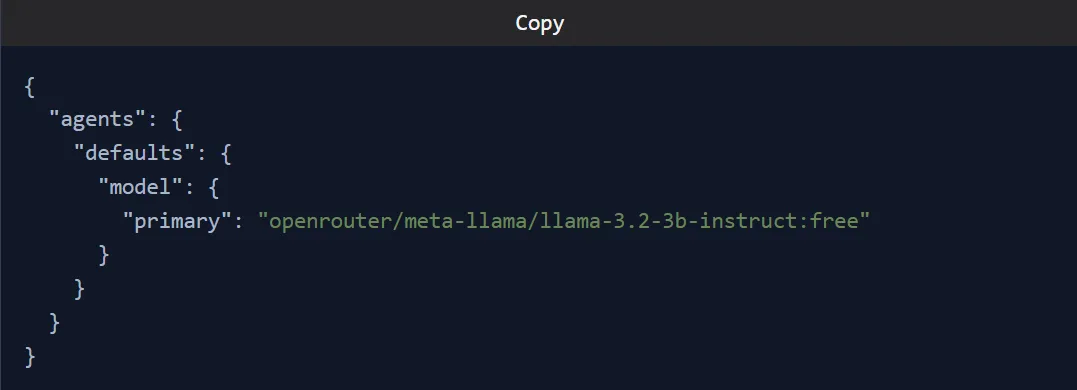
我在OpenClaw上使用的5个免费AI模型(大多数人都忽略它们)有报道称用户从上线第一周起就被标记。然后事情发生了——Anthropic 完全阻止了 Claude Max 代币在 OpenClaw 中使用。每天在OpenClaw上运行Claude Sonnet,API信用消耗比我预期的快。每条消息都会将完整的对话记录发送给模型。经过数周测试不同的模型、供应商和配置,我找到了5个支持OpenClaw的模型。有些是本地运行在你的机器上。还有些人用免费的云层,这些方案已经足够好,能完成工作。我学到——“免费”的含义会根据你走的路线不同而不同。本地模型每个代币不收费,但需要不错的硬件。无云层级会给你一个每天重置的配额。有些型号便宜到几乎归零。在这篇文章中,我将详细介绍我使用的5个模型,为什么使用它们,以及如何在OpenClaw中设置每个模型。Moonshot AI 的 Kimi K2.5 是目前 OpenRouter 上最受欢迎的免费模型。我开始把它当作临时备选,等我弄清楚自己的配置。它最终成为了我为OpenClaw制作的主要模型。128K上下文窗口可以处理较长的OpenClaw会话,同时不会丢失之前的消息。它非常适合负责阅读邮件、管理日历和运行自动化的座席Moonshot宣布其平台上将永久免费访问。OpenRouter的免费套餐大约每分钟有20个请求,每天重置。如果你用奥拉玛,还有一条更快的路线。Kimi K2.5 作为云端模型在 Ollama 上可用,所以你可以用 OpenClaw 直接一行启动它:最佳用途:通用代理工作、编码任务、调研和内容起草。如果你想要自由云推理,我推荐从这个模型开始。限制: 免费套餐的速率限制意味着重度用户在繁忙会话时会遇到瓶颈。大多数人在寻找免费OpenClaw模型时会跳过Qwen。OpenClaw 内置了 Qwen OAuth 流程的插件你只需通过设备代码认证一次,就能每天免费访问Qwen Coder和Qwen Vision的型号,免费请求达2000次Qwen 3.5 具备原生代理能力;它被设计成思考、搜索、使用工具和建造。登录后,你的型号参考看起来像是或qwen-portal/coder-modelqwen-portal/vision-model我不会带整个团队来做这件事。但对于处理编码任务、文件读取和日常自动化的个人OpenClaw代理来说,Qwen免费套餐能胜任任务。最佳使用场景:编程任务、基于愿景的工作流程,以及任何想要可靠免费方案、又不想同时管理多个API密钥的人。限制:如果OAuth令牌过期或被撤销,你需要重新运行登录命令。如果你想要一个大上下文窗口但又不想付费,谷歌的Gemini Flash是云推理的最佳免费选择。免费套餐每分钟提供15个请求,最多可获得100万个上下文代币对于较长的OpenClaw会话来说,这种上下文长度相较于大多数免费替代方案是真正的优势。我用 Gemini Flash 作为副型号。当 Kimi K2.5 达到速率限制时,Gemini 会加速。你需要谷歌的AI Studio GEMINI_API_KEY。免费套餐的API密钥生成大约需要两分钟。最佳使用场景:长时间的对话、文档摘要、调研任务,以及当你的主要免费模型达到每日上限时的可靠备选方案。限制:谷歌的免费套餐可能会使用你的数据进行培训。对于副业项目和学习来说,这应该没问题。对于专有代码或敏感客户工作,使用付费层级或本地运行。OpenRouter 不是一个模型,而是一个网关,通过单一 API 密钥让你访问来自不同供应商的数十个模型。它对 OpenClaw 有用的是 :free 后缀。将其附加到支持的模型上,你就能获得零成本的推断。可用的免费模型会随着时间轮换,但通常有相当不错的选择你通过OpenRouter配置Kimi K2.5作为主电源,添加一个Llama型号作为第一个备用,最后一个备份是GeminiOpenClaw 还内置了扫描器,用于检查当前 OpenRouter 上有哪些免费模型可用,并测试它们是否支持工具调用和图像支持:最佳使用场景:希望在免费模型之间实现最大灵活性和自动故障切换的用户。也非常适合尝试不同模型,而不用每次都更改供应商配置。限制:OpenRouter上的免费模型会变。今天免费的模特,明天可能就不行了。请回来查看,并持续更新你的备选方案。我目前讲过的每个模型都依赖别人的服务器。Qwen 3.5 是否能通过 Ollama 本地运行取决于你的硬件。我选择Qwen 3.5是因为阿里巴巴设计时考虑了代理式工作流程。它在工具调用、多步推理和代码生成方面表现优于大多数同规模的开源模型。9B版本运行在大多数配备16GB内存的现代笔记本上。27B版本需要32GB+,但在复杂任务中表现更好。如果你用的是M系列Mac或独立显卡,体验会很流畅。Ollama 最近为 OpenClaw 增加了一个命令启动功能。
这个单一命令会拉取模型,配置提供者,并将其连接到 OpenClaw。
如果你更喜欢手动控制,也可以单独安装 Ollama 版,用 ollama pull qwen3.5 拉出模型,然后自己接线服务商配置。但对大多数人来说,发射指令是可以的。
最佳使用场景:隐私优先的设置、离线工作、不信任任何云端的敏感数据,以及希望将成本尽可能降为零的开发者。限制:你需要不错的硬件。9B型号支持16GB内存,但在复杂的多步骤任务上表现不佳。总结
经过数周的测试,我最终确定了这个配置:
• 主教:Kimi K2.5 — 大部分日常任务免费完成
• 后备方案1:Qwen 3.5本地通过Ollama — 当速率限制达到时开始播出
• 后备 2:Gemini Flash——非常适合在100万代币背景下大量使用。
我停止用 Claude 模型运行 OpenClaw,因为有几个免费选项。
如果你正在尝试这些模型中的任何一个,欢迎在下方留言。我很想听听你用的设置。
让我们连接!
如果你是我内容的新手,我叫Taysic镒,一个Ai智能体架构师、Ai智能体产业应用顾问、超级个体模式深度实践者、Ara pace OPC创始人, 如果你对Ai项目感兴趣,可以扫描下方二维码进入我的Ai社区,欢迎加入成千上万的AI爱好者加入。
 夜雨聆风
夜雨聆风