 夜雨聆风
夜雨聆风
因为公众号平台更改了推送规则。记得点下右下角的大拇指“赞”和红心“推荐”。这样每次新文章推送,就会第一时间出现在订阅号列表里。
因为公众号平台更改了推送规则。记得点右下角的大拇指“赞”和红心“推荐”。这样每次新文章推送,就会第一时间出现在订阅号列表里。
配备48GB 内存的Mac Mini M4 Pro(新机售价 1599 美元)是本地LLM的理想选择——它能够流畅运行像Llama 3.1 70B这样拥有70亿参数的模型。24GB的M4基础配置(售价599 美元)能够处理7B至13B的模型。对于100B及以上的模型,需要128GB及以上的内存(售价3199 美元及以上)。二手的M2 Pro型号(配备32GB内存)起价约为800美元。苹果芯片的统一内存架构消除了基于GPU构建的系统VRAM瓶颈。
苹果的统一内存架构意味着CPU、GPU和神经引擎共用一个内存池——不存在PCIe 瓶颈,也无需在VRAM 和系统RAM 之间进行数据复制。这正是LLM 推理所需要的,这也使得Mac Mini 成为运行本地模型和像OpenClaw 这样的AI 代理极具吸引力的选择。
但究竟应该购买哪款Mac Mini 呢?而且是应该购买新品还是二手货呢?
笔者研究了所有搭载苹果芯片的Mac Mini 的配置情况,查阅了当前市场上各型号的价格,并精确地列出了在每种内存等级下可以运行的LLM 模型——包括使用本地模型运行OpenClaw 所需的条件。以下是完整的详细说明。
为何选择Mac Mini 用于LLM
Mac Mini 在本地AI推理方面占据主导地位有三个原因:
统一内存=可用内存。在配备独立显卡的PC上,用户受到显存(通常为8 - 24GB)的限制。而在Mac Mini上,用户所有的内存均可用于模型加载。一台48GB 的 Mac Mini 具有 48GB 的可用模型存储空间。
内存带宽。M4 Pro的内存带宽约为 273 GB/s。对于LLM的推理而言,内存带宽直接决定了每秒处理的token数。带宽越大,响应速度就越快。
能效表现。在AI负载下,一台Mac Mini 的耗电量约为 30 瓦。而一台配备双显卡的电脑系统则会消耗600瓦以上。如果设备需要全天候运行相关程序,仅节省下来的电费就能在一年内抵消购买一台 Mac Mini 的成本。
唯一的一条硬性规则是:模型必须能装入内存,否则无法运行。内存决定了模型是否能正常工作。芯片决定了其运行速度。请尽可能选择能够承担得起的最大内存容量——之后无法再进行升级。
新款Mac Mini 价格(所有M4 配置)
这是2024 Mac Mini 系列产品的当前苹果建议零售价。
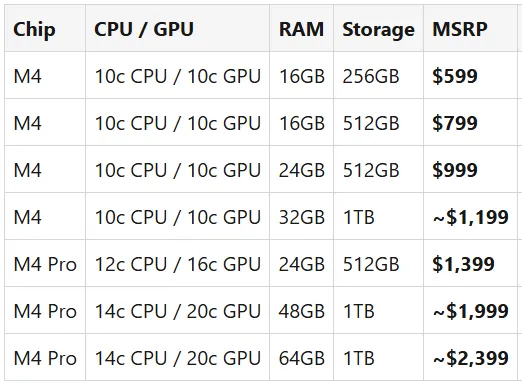
注意:M4 最大可扩展至32GB。如果需要48GB或64GB 的内存,就必须选择 M4 Pro——它还能提供约30%-50%更高的内存带宽,从而实现更快的token生成。某些配置(24GB 的M4、32GB 的M4、64GB 的M4 Pro)是定制生产的,仅可通过苹果官网购买。
二手商品与新品价格对比
二手商品的价格数据来源于Swappa、eBay 和Back Market 网站,数据截至2026年2月。
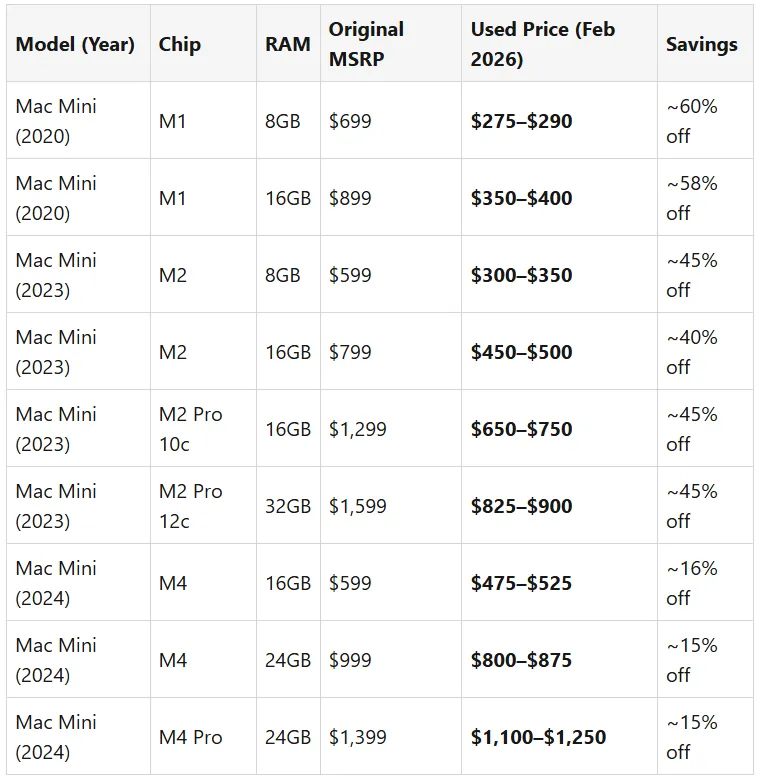
价格降幅最大的是M1 和 M2 型号——您能以原价的 45%至 60%的价格购买到这些产品。M4 型号的价格尚未大幅下降,因为它们才生产了不到两年的时间。
能运行什么?按内存等级划分的LLM 模型
macOS 为系统进程预留约4GB 的内存空间,因此实际可用的模型空间为内存减去约4GB。以下是每个等级适用的内容:
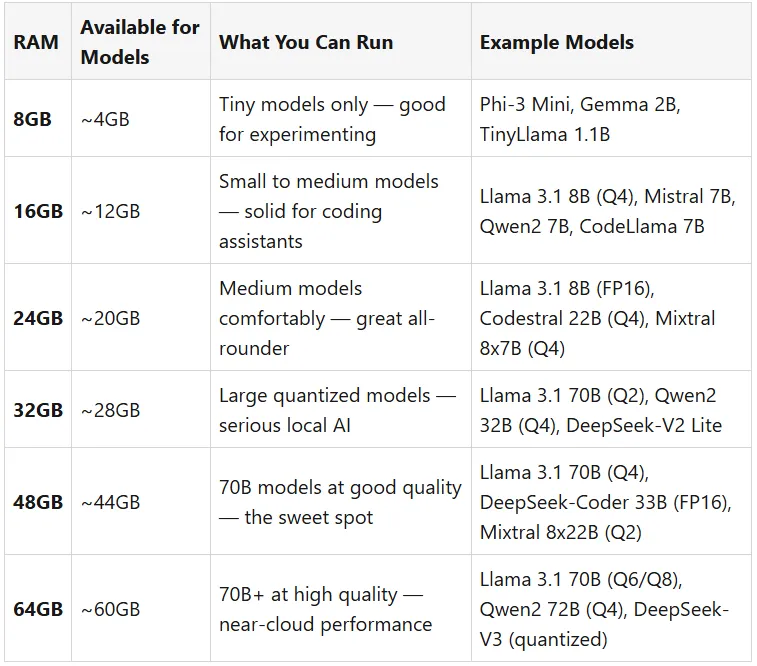
简单的一条经验法则:模型大小(以GB 为单位)≈ 需要的内存容量。在Q4 量化下,一个14B 参数的模型大约需要8GB 内存。一个70B 的模型在Q4 量化下则需要约40GB 内存。
量化级别意味着什么
Q2/Q3 — 重度压缩。会有明显的质量损失,但能节省更多的内存空间,适用于更大的模型
Q4 — 最佳平衡点。质量略有损失,但能显著节省内存
Q6/Q8 — 接近全质量。需要更多的内存,但输出接近原始模型
FP16 — 全精度。质量最佳,内存占用最大
按预算推荐
低于400 美元:M1 16GB(二手)——约375 美元
这是进入本地LLM的最经济的方式。它能很好地运行7 亿参数的模型,用于实验、小型模型的编码辅助以及RAG 管道。M1 的内存带宽较低(约68GB/s),因此生成token的速度较慢,但模型的加载和运行是正常的。
适用场景:学习、实验、轻量级代码辅助工具
价格低于900 美元:M2 Pro 32GB(二手)——约850 美元
对于专业本地语言模型的使用来说,这是性价比最高的选择。32GB 的内存容量能运行16GB 机器无法加载的模型。用户可以以高强度量化方式运行70 亿参数的模型,或者以Q4 标准轻松运行14 亿至32 亿参数的模型。
适用场景:适用于运行生产级别的代码辅助工具、中等规模的开放模型以及同时运行多个较小规模的模型。
999 美元 新品:M4 24GB
如果想要带有保修的全新产品,那么这就是一个不错的入手选择。24GB 的内存容量足以满足大多数实际型号(7B - 22B)的需求,并且还能为操作系统留出空间。M4 在内存带宽方面相较于M1/M2 有所提升,这意味着无论机型大小,生成token的速度都会更快。
适用人群:适合日常使用的设备,能够处理大部分本地AI任务,同时配备了最新的芯片以确保未来适用性。
M4 24GB 版本是定制配置选项——可在苹果官网进行设置。
~2000 美元 新品:M4 Pro 48GB — 本地LLM 爱好者的理想配置
这是大多数本地LLM 爱好者推荐的配置。48GB 的统一内存能让您轻松运行70B 量化模型。M4 Pro 的约273GB/秒的内存带宽意味着您不仅能快速加载模型,还能获得实用的响应速度——不仅仅是模型加载,还包括生成token的速度。
适用场景:本地运行Llama 3.1 70B、DeepSeek V3 等前沿开放模型及其他类似模型。适用于深度AI开发、微调实验以及运行多个模型。
~2400美元起:M4 Pro 64GB — 本地AI顶配
适用于运行70B 以上的模型,且在更高量化级别(Q6/Q8)下(输出质量可接近云端版本)。如果您想同时运行多个模型,或者在进行其他内存密集型工作时保持大型模型加载状态,此配置也很有用。
适用场景:追求最高模型质量、支持运行多个模型、进行专业的AI研究
64GB 配置款是定制产品——可在苹果官网进行个性化设置。
在Mac Mini 上运行OpenClaw
OpenClaw 是一款开源的AI代理,它能将Mac Mini 转化为一个可通过WhatsApp、Telegram、Slack、Discord、Signal 或iMessage 发送消息的个人AI助手。与简单的聊天机器人包装器不同,OpenClaw 能够在设备上实际执行各种操作——浏览网页、管理文件、运行shell 命令、执行定时任务以及与100 多个技能插件进行交互。
Mac Mini 已成为用于自主运行OpenClaw 的首选硬件,因为它体积小巧、运行安静、能耗低,并且能够在储物间内全天候运行。通过与Ollama 的本地模型相结合,将获得一个完全私密的AI 助手,且无需承担任何持续的API 费用。
重要提示:模型供应商服务条款
在使用OpenClaw 时,请谨慎选择使用的云模型。自2026 年初起,Anthropic(Claude)和谷歌(Gemini)均在其服务条款中禁止将他们的API 与OpenClaw 结合使用。用户报告称,这样做会导致其API 密钥被封禁。OpenAI 的政策较为宽松,但在连接任何云供应商之前,请务必查看当前的条款。
这就是为何本地模型路线对OpenClaw 来说如此有吸引力的主要原因——拥有硬件,拥有模型权重,而且无需遵守任何服务条款。如果打算仅使用本地模型来使用OpenClaw,那么以下的硬件要求才是关键因素。如果使用的服务供应商的条款允许这样做,那么根本不需要强大的硬件——即使是售价599 美元、配备16GB 内存的Mac Mini 也能正常运行,因为推理过程是在供应商的服务器上进行的,而Mac Mini 只需运行轻量级的OpenClaw 网关即可。
OpenClaw 的独特之处
OpenClaw 并非像Claude Code 或Cursor 那样是一款编程辅助工具——它是一款通用型生命智能体。你可以像与同事交流一样向它发送信息:
“汇总我的收件箱并起草回复”
“监控这个GitHub 仓库,并在有新问题时通知我”
“抓取这50 个网址并将数据放入电子表格中”
“每天早上9 点提醒我查看PR”
它通过界面连接到用户的消息应用程序,并使用本地(或云端)的语言模型作为大脑。技能系统允许用户精确控制代理在设备上能够和不能够执行的操作。
OpenClaw 硬件要求(本地模型)
以下硬件要求仅适用于运行本地模型的情况。如果使用的是允许的云API,那么 OpenClaw 本身就很轻便,可以在任何设备上运行。
对于本地推理而言,使用OpenClaw 比在Ollama 中运行单个模型的要求更高,因为该代理需要一个较大的上下文窗口(至少64K 个token)才能可靠地处理多步任务。这个上下文窗口会占用可用的内存空间,而不仅仅是模型权重所占用的空间。

适用于OpenClaw 的推荐模型
OpenClaw 需要具备强大的调用工具支持功能,并且需要至少 64K 的上下文容量。并非所有的模型都能很好地适用——该代理需要能够可靠地调用函数,而不仅仅是生成文本。经过社区测试的推荐模型有:
GLM-4.7-Flash(9 个活跃参数,128K 堆栈)——最轻量级的选择。工具调用性能出色,可在 16GB 及以上内存的设备上运行。在双机配置中作为备用模型也很不错。
Qwen3-Coder-32B(32B 参数,256K 堆栈)——社区一致推荐的用于编码任务的模型。工具调用极其稳定。在Q4 时需要约20GB 内存,另外还需要4-6GB 用于键值缓存。需要32GB 及以上硬件。
Devstral-24B(24B 参数)——强大的编码模型,可在Q4 时占用约14GB 的内存。介于GLM-4.7-Flash 和Qwen3-Coder 之间,是一个不错的中间选择。
MiniMax M2.1(通过LM Studio)——官方文档推荐将其作为当前最佳的本地栈选择,其堆栈大小为196K。
原文链接:
高端微信群介绍 | |
创业投资群 | AI、IOT、芯片创始人、投资人、分析师、券商 |
闪存群 | 覆盖5000多位全球华人闪存、存储芯片精英 |
云计算群 | 全闪存、软件定义存储SDS、超融合等公有云和私有云讨论 |
AI芯片群 | 讨论AI芯片和GPU、FPGA、CPU异构计算 |
5G群 | 物联网、5G芯片讨论 |
第三代半导体群 | 氮化镓、碳化硅等化合物半导体讨论 |
存储芯片群 | DRAM、NAND、3D XPoint等各类存储介质和主控讨论 |
汽车电子群 | MCU、电源、传感器等汽车电子讨论 |
光电器件群 | 光通信、激光器、ToF、AR、VCSEL等光电器件讨论 |
渠道群 | 存储和芯片产品报价、行情、渠道、供应链 |

< 长按识别二维码添加好友 >
加入上述群聊

带你走进万物存储、万物智能、
万物互联信息革命新时代

