 夜雨聆风
夜雨聆风
编者按:
AI 圈爆火的OpenClaw 让 “养龙虾” 成潮流,这款开源智能体虽解锁了行动式 AI 的全新可能,却因指数级 Token 消耗让用户频遇天价账单。这只 “吞金小龙虾” 成了大模型产业的鲶鱼,倒逼用户摸索低成本使用技巧,推动国内外模型厂商开启价格战,更让 Token 成为 AI 时代的 “算力货币”,撬动产业从技术探索向效率与价值定价的深层变革。而模型成本的持续下探,也正让 AI 智能体走向更普惠的应用,唯有拥抱这场变化,才能抓住智能时代的发展机遇。
全文约4964字,建议阅读时长约13分钟
前言
如果你最近在社交媒体上刷到过“养龙虾”这个词,别误会,这不是水产养殖新风口,而是AI圈最火的个人智能体——OpenClaw。这个能让AI替你订机票、写邮件、甚至炒股的“数字打工人”,在GitHub上狂揽20多万星标后,突然画风一转:无数晒账单的帖子开始刷屏——“一周烧掉1300块”“6小时消耗9000万token,账单170美元”。开源免费?不存在的。免费的是门票,养AI的钱在后头。
OpenClaw就像个刚领回家的二哈,你以为它乖巧可爱,结果发现它一天能吃掉一袋狗粮。只不过这袋“狗粮”叫token,而且价格不菲。而这只“龙虾”的胃口,正在悄悄撬动整个大模型产业的价格体系。

很多人第一次接触OpenClaw时,内心活动大概是:不就是个聊天机器人吗?能花多少钱?然后月底看到账单,当场裂开。
问题的根源在于,OpenClaw不是那种你问一句它答一句的“佛系AI”。它是一个有手有脚、会主动思考的Agent。当你让它“帮我写一篇专访稿”,它背后做的事情是:先在电脑里翻找相关采访速记,然后打开浏览器搜索最新行业动态,接着调用大模型总结提炼,最后打开邮箱把稿子发出去。每一步都在消耗token,而且是大把大把地烧。
更狠的是,OpenClaw还具备“记忆力”和“主动性”。它会每隔一段时间自动醒来检查环境(这叫heartbeat),会把对话写入长期记忆文件,会在你睡觉时默默巡检群消息。有用户调侃:“我的AI比我还能卷,凌晨三点还在看log。”这些你看不见的后台操作,每小时都在烧钱。

有人算过一笔账:单个Agent的算力消耗是传统Chatbot的100到1000倍。一个中等规模的OpenClaw工作流,每天消耗1亿token不是什么稀奇事——这相当于让一个普通人连续不断读10年报纸的信息量。而按照目前主流模型的价格,1亿token就是几百块人民币。
在Reddit上,有个用户贴出账单:6小时,9000万token,170美元。底下评论一片哀嚎:“我以为开源就是免费,结果一看账单,冲到了几百美元。”更夸张的是,有人一个月光token就花掉400美元,换算成人民币近3000块。

面对高昂的token账单,用户们分成了几派。
第一派:佛系派。 这类人通常用免费或极便宜的模型,比如Qwen-8B。结果发现,OpenClaw倒是听话,但只会回答问题,不会执行操作——相当于养了只不会干活的懒猫。
第二派:精算派。 利用自己的技术能力疯狂工程优化。有人甚至写出了配置模板,精确到每个模型每天最多调用多少次。这套叫做“分层代谢”的玩法——就像人体有大脑、肌肉、心脏,AI也应该分层配置。复杂推理用Claude Opus,日常任务用Kimi K2.5,心跳检查用本地运行的Llama 3.1。这么一配,成本能降一大截。
第三派:氪金派。 通常是深度用户或创业者,他们信奉“一定要浪费token,才能探索边界”。有个前金融从业者用OpenClaw搭了个股票交易系统,第一天就赚了300美元。他坦言:“如果没有金融行业的经验,这个系统会差很多——比如我会让Agent跳过开盘前15分钟再交易,因为那段时间波动极大。”AI负责执行,人类负责经验,这才是正确的打开方式。
这种分化背后,其实揭示了一个本质问题:OpenClaw不只是一个工具,它是一个需要持续喂养的“数字生命”。就像养孩子,你不能指望他出生后就自己长大。同样,AI也需要“吃饭”——而token就是它的饭。

既然要养,就得学会精打细算。
结合各路“养虾大户”的血泪经验,这里整理了几条亲测有效的省钱策略,综合下来能把token消耗降低50%到90%不等。
策略一:给AI装上“节流阀”——心跳机制降频
OpenClaw默认每30分钟会“心跳”一次,检查环境、决定行动。这意味着即使你睡觉,AI也在默默烧钱。
实操建议:把心跳间隔从30分钟调到2小时,同时设置“活跃时间”(比如早8点到晚12点)。这样一来,每天的心跳次数从48次降到8次,光这一项就能省下不少。
更狠一点的玩法:把心跳改成“纯轻量检查”——没事只回复“HEARTBEAT_OK”,不触发任何模型调用。
策略二:QMD——把记忆检索成本打下来90%
OpenClaw的原生记忆系统有个大问题:每次查询都要加载全部记忆文件,哪怕只需要其中1%的信息,也会消耗完整token。这就好比每次找东西都把整个房间翻一遍。
QMD(本地语义搜索引擎)的解决思路是:用“BM25全文搜索+向量语义搜索+重排序”三层机制,只提取最相关的2-3句话进上下文。
实战效果:每次查找的token消耗从15000降到1500,节省90%;长会话(100轮)的消耗从50万token降到6万,节省88%。
策略三:Memos——让AI学会“记重点”
如果说QMD解决的是“怎么找”,Memos解决的是“记什么”。它通过“智能提取关键信息+按需召回+避免重复传输”三大机制,能把token消耗降低77%以上。
工作原理:普通场景中,每次对话都要传输完整历史记录。比如你第1天说“我叫张三,住在北京,喜欢吃川菜”(100 token),第2天问“推荐一家餐厅”(10 token),总消耗110 token。有了Memos后,第1天的关键信息被结构化保存,第2天只传输“用户住在北京、喜欢吃川菜+推荐餐厅”(25 token),节省77%。
策略四:收费模型调教 + 免费模型执行(省95%+的终极大法)
这是目前社区公认最狠的省钱套路:先用收费模型(如Claude Opus、Qwen3 Max)处理复杂任务,打磨流程、优化逻辑,最终生成本地可执行脚本;然后切换到免费模型(如cherry-aihubmix/coding-glm-4.7-free),直接调用脚本执行重复任务。
关键优势:脚本保留了收费模型的优化逻辑,免费模型只负责执行——既保证效果,又把token消耗打到近乎为零。这套打法尤其适合批量任务、定时任务——比如每天自动生成早报、监控竞品动态、处理邮件等。
策略五:其他“蚊子腿也是肉”的小技巧
· 上下文裁剪(contextPruning):超过5分钟的工具输出自动裁剪,省20-30%
· 连续消息合并(debounce):3秒内的多条消息合并处理,避免多次调用
· 定期重置会话(session reset):4小时没聊天就重置会话,避免上下文无限膨胀
· 子任务模型降级:cron定时任务用MiniMax-M2.1替代Claude Opus,费用只有1/3左右


用户们被账单折磨得嗷嗷叫的时候,模型厂商们却看到了机会。
第一个跳出来的是Kimi。今年2月,月之暗面推出了Kimi K2.5模型,定价还是“国产的”,但性能却是“进口的”——直逼Claude Opus。更狠的是,他们上线了“Kimi Claw”服务,专门优化OpenClaw的调用效率。据OpenRouter统计,Kimi的调用量一度冲到榜首,原因是用户发现:同样写一篇稿子,用Kimi花的钱只有Claude的1/9。

紧接着,MiniMax和智谱也坐不住了。MiniMax发布了M2.5模型,智谱推出GLM-5,两者都在编程和Agent任务上表现优异,价格却比欧美模型便宜一大截。有开发者调侃:“以前用不起Claude,现在用国产模型,感觉像从米其林降级到沙县小吃——但沙县居然意外地好吃。

阿里云更是直接甩出王炸:他们把Qwen3.5、GLM-5、MiniMax M2.5、Kimi K2.5打包成一个Coding Plan,新用户首月仅需7.9元,每月包含18000次请求。这意味着,你花一杯奶茶的钱,就能同时调用四款顶级模型。阿里云的算盘很明确:既然用户要换着模型用,不如我一次性打包,降低你的选择成本,顺便绑定你的使用习惯。小米、华为等也纷纷推出了自己的XX claw 服务加入战局。
这场价格战甚至波及到了欧美厂商。Anthropic虽然没明着降价,但悄悄优化了Claude Opus的上下文压缩算法,让同样任务消耗的token减少20%。OpenAI则在GPT-5-mini上推出“批处理模式”,批量请求价格打五折。
有分析师指出,这波价格战的核心驱动力正是OpenClaw这类Agent的爆发。传统Chatbot的token消耗是线性的,但Agent的消耗是指数级的。用户对价格的敏感度被瞬间放大,倒逼厂商必须在保证性能的同时拼命降价。这是典型的“需求倒逼供给”——Agent成了那个嗷嗷待哺的孩子,逼着大厂们内卷。

这场由账单引发的焦虑,正在催生一些意想不到的行业变化。
首先,代装业务火了。 OpenClaw的部署门槛让不少人望而却步,于是“代装”成了一门生意。海外平台SetupClaw明码标价,现场配置服务高达6000美元;国内闲鱼、小红书上,上门安装服务定价在300-800元不等,有的网店已售1000+,甚至出现1.6万元的天价批量安装订单。直到最近腾讯云工程师在深圳总部楼下排队为近千人免费装机,才让这股歪风稍微降温。
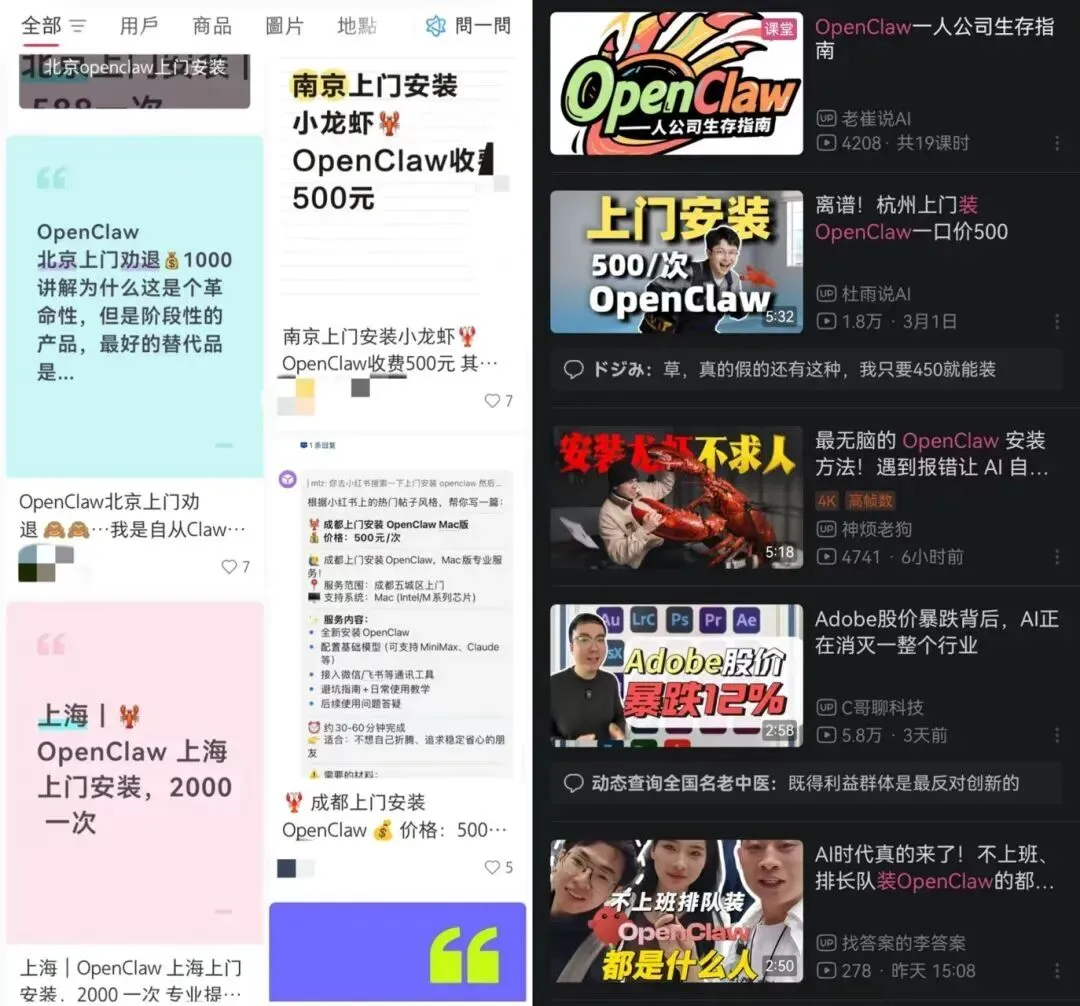
其次,大厂开始抢滩“一键部署”。 百度、阿里、腾讯相继推出OpenClaw一键部署服务,接入各自的大模型。表面上是帮用户省钱省事,背后其实是抢占AI时代的入口——谁掌握了“养虾人”,谁就掌握了未来的Token流量。
最后,Token正在成为一种新的计价单位。 过去我们为软件付费,后来为API调用付费,现在为“智能的思考量”付费。OpenClaw的创始人Peter Steinberger在一次访谈中直言:“大多数代码很无聊,只是数据转换。AI能帮你写,你就该让它写。但思考本身是有成本的。”这句话点破了本质:未来我们购买的,不是软件功能,而是AI的“脑力劳动”。

回顾这波OpenClaw热潮,最有趣的现象是:一个开源项目,居然成了整个AI产业的“鲶鱼”。它用惊人的token消耗,逼着模型厂商降价;用用户的吐槽,催生了分层代谢、QMD、Memos等一系列高效策略;用一个个疯狂的应用,展示了Agent的无限可能。

老黄在去年春节deepseek爆火时所提到的“杰文斯悖论”,狠狠击中了2026年的我们,模型成本的下降,最终会通过更多的应用形式、更多的应用领域让更多人养得起、用得好。
30年前,当年的80后们在各种课堂上勤奋学习如何踏上信息高速公路去收发电子邮件、浏览网络聊天室时可能还不懂得什么叫做“历史的推背感”,如今它又一次降临,而这一次我们遵循的准则却全然不同:当AI能够开始证明自己能干这一件事的时候,它就能以极快的速度做得越来越好,所以只有积极去拥抱它,你享受的才是推背感,而不是时代呼啸而过的阵风或者被车轮碾过的阵痛。


中心构建企业全周期培育体系,准备了初创孵化、成长加速、成熟赋能等各梯度资源对接项目,将为入驻优质科技企业提供个性化、年轻化、高效专业的定制化服务,同步还将搭建共性技术支撑平台、产业链资源对接网络、政策申报与融资等服务链路,形成全链孵化生态底座。中心将助力亦庄打造智能制造及其辐射产业的关键节点,致力于成为亦庄镇科创资源集聚、成果转化显著的科技型产业孵化高地。
📞 招商专属咨询:党女士13811802557(一对一解答入驻问题)
📍 园区地址:北京经济技术开发区亦庄镇亦庄智能制造国际科创产业园




