五套机制一览
| | | |
|---|
| | | ~/.openclaw/workspace/memory/ |
| | | ~/.openclaw/workspace/memory/YYYY-MM-DD.md |
| | | ~/.openclaw/agents/<agentId>/qmd/ |
| | | ~/.openclaw/lcm.db |
| | | ~/.openclaw/workspace/.learnings/ |
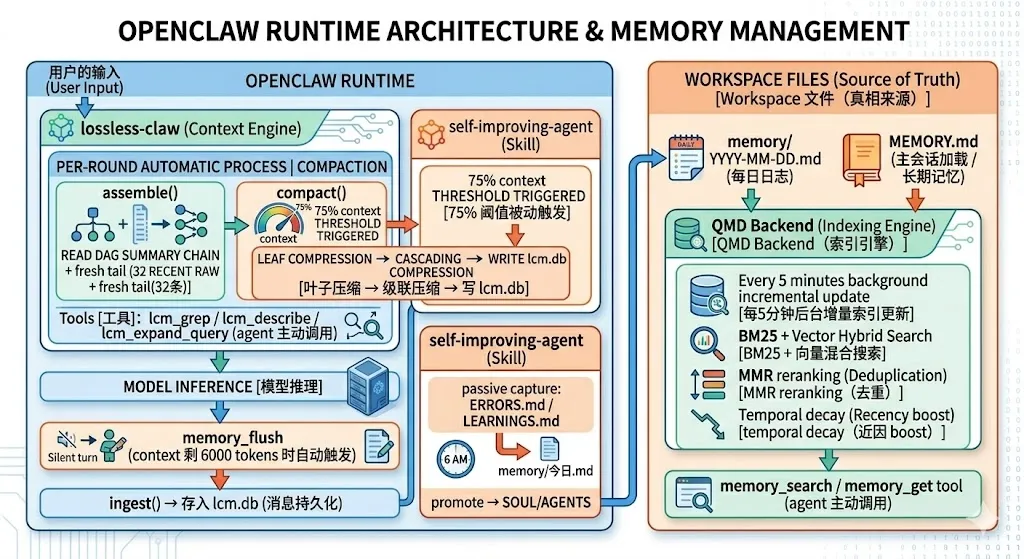
一、Workspace 文件(memory/)
是什么
Markdown 文件是整个记忆系统的最终真相来源。所有其他机制(QMD 索引、lossless-claw DAG)都是对它的派生和压缩。~/.openclaw/workspace/ ├── MEMORY.md # 精选长期记忆(仅主会话 startup 加载) └── memory/ ├── YYYY-MM-DD.md # 每日日志 └── *.md # 主题记忆文件(如 projects.md)
如何用
写入:agent 在任何时候觉得重要就主动写文件,没有固定格式要求
读取:触发时机
| |
|---|
| 加载今天 + 昨天 daily log;主会话额外加载 MEMORY.md |
| |
/new | |
二、memory_flush(预压缩静默写入)
是什么
在 OpenClaw 触发自动压缩之前,插入一个静默的 agentic turn,提醒 agent 把当前对话中值得保留的信息写入当日 memory/YYYY-MM-DD.md,然后回复 NO_REPLY(用户完全看不到这个过程)。如何用
无需人工干预,完全自动运行。agent 会收到系统 prompt 提示它写记忆,不需要用户做任何事。触发时机
context 窗口剩余约 6000 tokens → soft threshold 触发↓系统注入静默 turn(用户不可见)↓agent 被提示:"Session nearing compaction. Store durable memories now."↓agent 写 memory/YYYY-MM-DD.md → 回复 NO_REPLY↓继续正常压缩流程
局限
是"提醒式"写入,不保证记忆完整性,取决于 agent 当下的判断
三、QMD backend(记忆搜索引擎)
是什么
QMD 是一个本地搜索 sidecar,为 memory_search / memory_get tool 提供BM25 + 向量混合搜索 + MMR reranking + temporal decay能力。所有记忆文件在后台被索引(每 5 分钟增量更新),agent 通过 tool call 主动查询。如何用
// 语义搜索记忆(agent 主动调用)memory_search(query: string, maxResults?: number): MemoryResult[]// 精确读取文件行(agent 主动调用)memory_get(path: string, from?: number, lines?: number): string
触发时机:agent 认为需要查记忆时主动调用。没有自动触发,完全取决于 agent 自己的判断(比如用户问了一个涉及之前项目的事,agent 决定查一下记忆)。QMD 索引更新链路
memory 文件变更(write/edit)↓ (debounce 1.5s)标记 index dirty↓ (每 5 分钟后台定时)qmd update + qmd embed → 增量索引更新↓QMD SQLite DB 更新(BM25 + 向量)
关键配置(我的最简配置)
"memory": { "backend": "qmd", "qmd": { "update": { "interval": "5m" }, "limits": { "maxResults": 6 } }}
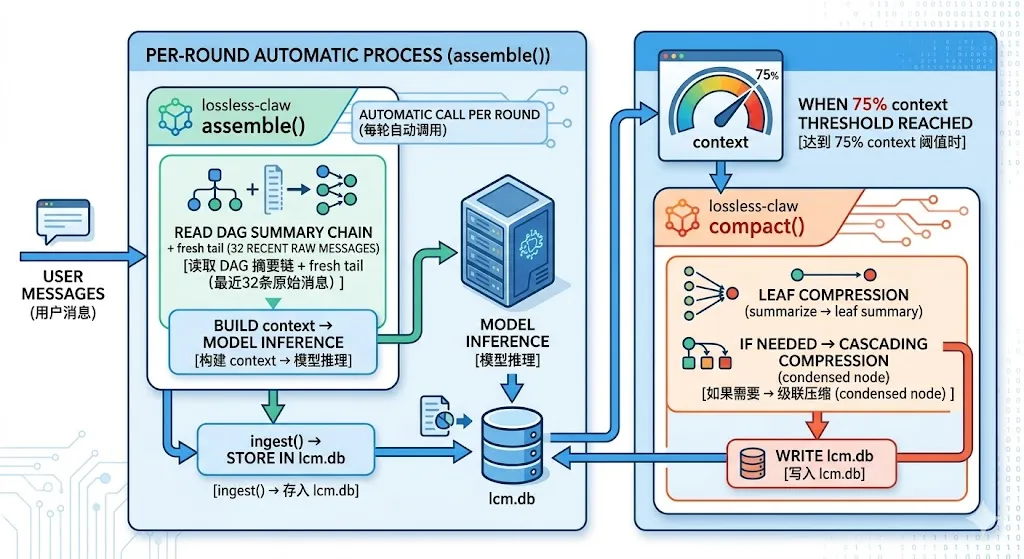
四、lossless-claw(对话历史 DAG 压缩引擎)
是什么
接管 OpenClaw 的 context engine 插槽,用 DAG 结构记住所有对话历史,永远不截断丢失。Raw Messages(叶子)↓ summarize(8条消息 → 1条 leaf summary)Leaf Summary (L1)↓ summarize(4个 leaf summary → 1条 condensed node)Condensed Node (L2+)↓ …级联上去…
如何用
// 跨历史搜索lcm_grep(pattern: string, ...): SearchResult[]// 查看 DAG 结构lcm_describe(summaryId: string): SummaryInfo// 展开摘要还原原始消息(spawn 子 agent)lcm_expand_query(summaryId: string, prompt: string): ExpandedResult
lossless-claw 运行链路
关键配置(你的)
"lossless-claw": { "enabled": true, "config": { "freshTailCount": 32, // 保护最近32条不被压缩 "contextThreshold": 0.75, // 75% 触发压缩 "incrementalMaxDepth": -1 // 无限制级联压缩 }}
⚠️ 重要澄清:lossless-claw 只管对话历史,不管记忆文件lossless-claw 的 DAG 存的是对话消息、memory/*.md 是 Workspace 文件,lossless-claw 不读写它们
五、self-improving-agent(持续改进日志)
是什么
一个基于事件的被动日志系统,捕获错误、纠正、最佳实践,在定时任务中沉淀到长期文件。如何用
| | |
|---|
| .learnings/ERRORS.md | error |
| .learnings/LEARNINGS.md | correction |
| .learnings/LEARNINGS.md | knowledge_gap |
| .learnings/LEARNINGS.md | best_practice |
| .learnings/FEATURE_REQUESTS.md | feature_request |
- 有价值的 → promote 到 SOUL.md / AGENTS.md / TOOLS.md / MEMORY.md
触发时机
命令执行失败 ──→ 自动写入 .learnings/ERRORS.md用户纠正 ──→ 自动写入 .learnings/LEARNINGS.md知识空白 ──→ 自动写入 .learnings/LEARNINGS.md每天 6AM ──→ cron 触发自检 + promote文件布局
~/.openclaw/workspace/├── .learnings/│ ├── LEARNINGS.md #纠正、最佳实践、知识差距│ ├── ERRORS.md #命令失败记录│ └── FEATURE_REQUESTS.md #功能请求└── SOUL.md / AGENTS.md / MEMORY.md ← promote 目标
完整协同链路图
一图总结:谁在什么时候跑
| |
|---|
| Session 启动 | 加载 MEMORY.md + 今天/昨天 daily log;lossless-claw 从 lcm.db 恢复 DAG |
| 每轮对话 | lossless-claw assemble() 构建 context;消息 ingest() 存入 lcm.db |
| agent 需要查记忆 | 调用 memory_search → QMD 搜索 → 返回结果 |
| context 剩 6000 tokens | memory_flush 静默触发 → agent 写当日 daily log |
| context 达到 75% | lossless-claw compact() 自动压缩 DAG |
| 命令失败 / 用户纠正 | self-improving-agent 自动写入 .learnings/ |
| 每天 6AM | self-improving-agent cron 自检 + promote |
| 每 5 分钟(后台) | |
关于 SaaS Memory 的个人思考 + 产品简介
矛盾的两种视角
观点 A(谨慎):Memory 即身份 - Memory + Skills 定义了这个 agent 是谁。把记忆放到 SaaS 上,等于把"培训好的员工"交给第三方——第二天可能服务没了、数据没了、账号没了。从来没有什么数字资产是真正可靠的。更务实的做法是先把本地机制搞清楚,理解每层存储了什么、怎么协同,再决定要不要把哪层外包。观点 B(务实):Memory 不该太重要 - 最近围绕 harness 的讨论揭示了一个更健康的范式:项目的 truth 应该在项目文件中,skill 应该自己迭代(self-improving-agent)。那么 memory 真正承载的只剩下个人偏好(我喜欢什么、习惯什么、如何纠正)。如果 memory 只是个"偏好缓存",那它就不需要精心维护——自动增长、自动遗忘、保持最小化才是合理的。
矛盾的解决:分层策略
| | | |
|---|
| 偏好层 | | memory 文件 + self-improving-agent | |
| 历史层 | | lossless-claw DAG(本地 SQLite) | |
| 知识层 | | | |
SaaS Memory 的真正价值不在于"帮我记住",而在于跨 agent 共享偏好——但这恰恰是我的 agent 已经通过 Workspace 文件 + QMD 本地解决的事。
所以,现阶段本地方案的判断
| |
|---|
| 用 lossless-claw 管理对话历史(本地 SQLite DAG) | |
| 用 memory 文件存个人偏好(本地 Markdown) | |
| |
| self-improving-agent 本地迭代 SOUL.md/AGENTS.md | |
SaaS Memory 的适合场景:多 agent 团队需要共享同一个用户的偏好记忆,而不是每个人单独训练。
SaaS Memory 产品一窥
Mem0() YC 孵化的通用 memory 层,定位"AI 应用的自我改进记忆"。已经有 Microsoft、NVIDIA、PwC、CrewAI 等企业客户,100,000+ 开发者接入。核心理念是 memory 应该"self-improving"——不只是存储,还要从中学习。声称可以降低 token 成本、提升个性化。有 SaaS 也有自托管版本。Supermemory() 定位"Context Infrastructure",比单纯的 memory 更宽——包含 5 层:用户画像、Memory Graph、检索、Extractors、连接器。声称在 LongMemEval、LoCoMo、ConvoMem 三个 benchmark 上都达到了 SOTA。有自定义的 Vector Graph Engine,不只是向量数据库。亮点是有 Chrome 插件做个人端收集(Save links, chats, PDFs 等),以及 MemoryBench 开源评测平台。也有自托管选项。两者都支持自托管,说明核心开发者也意识到纯 SaaS 的风险——但自托管版和 SaaS 版的体验、功能差异需要实际对比才能判断。
总结一句话:现在的判断是——用户的个人偏好值得本地维护(memory 文件),对话历史值得本地 DAG(lossless-claw),SaaS Memory 的差异化价值在于跨 agent 团队共享用户偏好,但这个需求目前对我来说不存在。等有多 agent 协作需求时再评估也来得及。观点是我的。文字ChatGPT帮我写的,图片AI生成的,难免有错,代AI向您道歉。 夜雨聆风
夜雨聆风